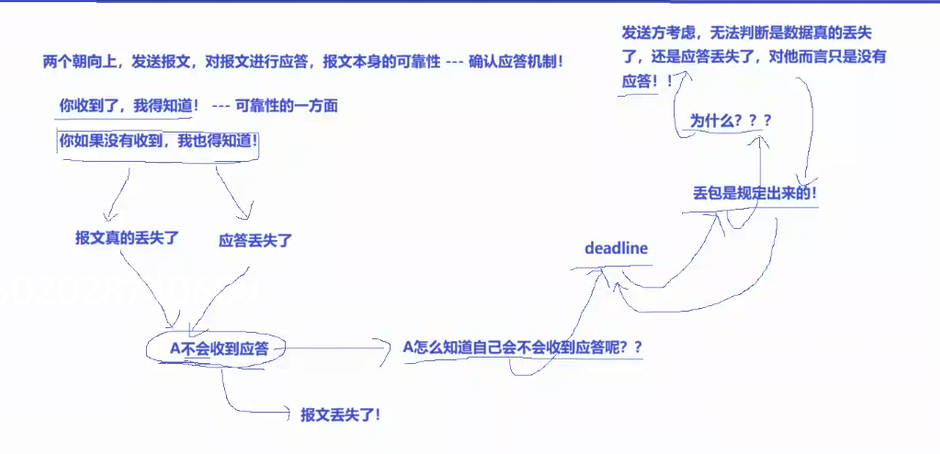
主机 A 向主机 B 发送报文后,想要确认对方成功接收,就需要 B 在收到报文后,向 A 回复对应的应答报文,只有 A 成功收到这份应答,才能百分百确认自己最开始发出的报文已经被 B 正常接收。顺着这个逻辑往下走,A 为了让 B 知道自己已经收到了 B 的应答报文,就又需要再对 B 的应答报文进行二次应答,以此类推,这个应答流程就会无穷无尽的循环下去,结果就是互联网里永远会有最新发出的报文,永远无法收到对应的收尾应答。所以严格来说,互联网环境里不存在绝对 100% 可靠的协议,最新发送的报文永远没办法获得最新的应答。
在了解了上面的内容后,我们才能真正理解 TCP 的可靠性。当发送方主机 A 迟迟没有收到对方的应答报文时,主机 A 本身无法百分百确定主机 B 有没有成功收到自己发送的数据报文。这时就分为两种情况:第一种是 A 发给 B 的原始数据报文在网络传输途中直接丢失了;第二种是 B 已经正常收到了数据报文,但 B 回复给 A 的确认应答报文在半路丢失。这两种完全不同的故障场景,最终都会让 A 收不到对应的应答,而 TCP 协议会将这两种情况都判定为丢包,随即触发报文重传操作。
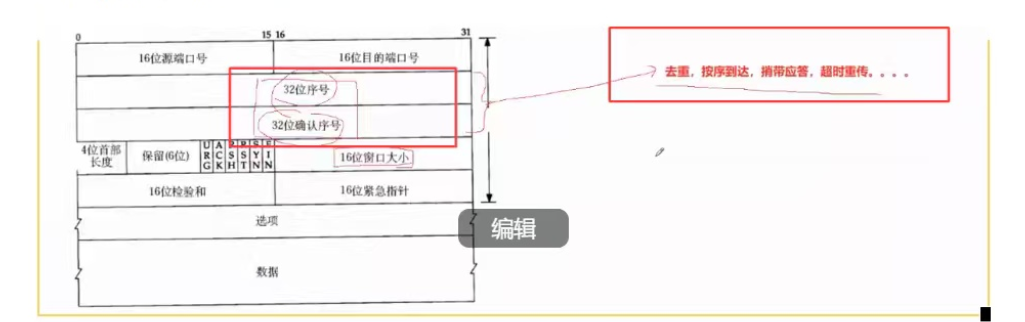
如果是原始数据报文丢失导致的异丢包常,那么 A 重传报文后,B 就能正常接收这份补发的数据。但如果是 B 回复的应答报文丢失导致的丢包异常,B 其实早就收到过原始数据报文,再次收到重传的报文后,就会出现重复接收数据报文的问题,既然重复接收,那就得去重。而 TCP 报头里的序号 字段,就是用来解决这种重复报文去重问题的核心,依靠序号就能精准识别重复数据,从而进行去重。
**第二种是 TCP 真实使用的批量连续发送模式,**也是高效并行传输方案。发送方主机 A 可以一次性连续向主机 B 发送多份数据报文,不需要每发一个就等待一次应答。接收方 B 收到批量报文后,统一进行确认和批量回复应答即可。原本单报文串行等待应答的空闲时间被充分利用,传输从串行排队变成了并行批量处理,极大压缩了整体等待耗时,大幅提升了数据的传输效率。
我们以第二种批量连续发送报文模式为例 : 主机 A 一次性向主机 B 发送多份数据报文时,A 发出报文的先后顺序,和 B 最终收到报文的顺序,并不是完全一致的。可能会受网络路由转发、链路传输差异等诸多因素影响,报文在传输过程中易出现乱序抵达的情况。如果接收方直接按照杂乱的到达顺序向上层交付数据,应用程序读取到的字节流就会错乱异常,如果读取数据错乱就会引发相关问题,而报文乱序本身,也是 TCP 传输可靠性需要解决的问题之一。
因此接收方主机 B 在收到一批乱序报文后,必须对接收数据做有序整理,而解决乱序问题的核心依据,正是 TCP 报头里的32 位序号字段。就像主机 A 依次发送序号为 1000、2000、3000、4000 的四份报文,网络传输后可能以 2000、4000、3000、1000 的混乱顺序到达接收端。接收方只需要根据每份报文自带的序号做升序排序,就能还原出发送端原本的发送顺序,保证数据按序完整交付,以此规避乱序异常,守住 TCP 可靠传输的特性。
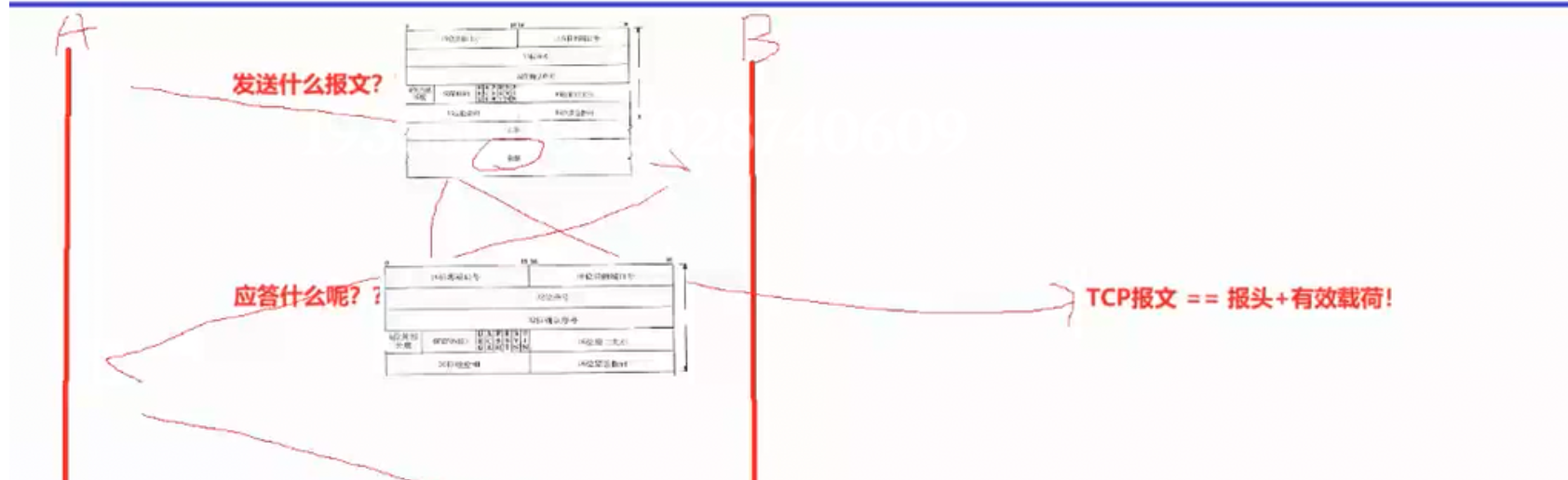
1. 主机 A 向主机 B 发送数据时,传输的是什么报文?主机 B 回复应答时,发送的又是什么报文?
站在传输层视角来看,通信双向发送的全部都是 TCP 报文 。TCP 报文 = TCP 报头 + 上层有效数据载荷两部分共同组成。发送方 A 主动传输业务数据时,报文既包含完整报头,也携带对应的有效载荷;而接收方 B 回复确认应答报文时,大概率不需要附带数据,也就是没有有效载荷,但必须携带完整的 TCP 报头 ,序号、确认序号、标志位等关键信息都封装在报头当中。无论是否携带业务数据,应答报文和数据报文在格式规范上本质都属于 TCP 报文,我们必须要有这个认知。
捎带应答机制
接着我们思考第二个核心疑问:主机 A 发送数据报文时,报头只需要填写 32 位序号,主机 B 回复应答报文时,只需要填写 32 位确认序号就足够,那为什么 TCP 报头里,每个报文都必须同时保留序号、确认序号两个字段 ,只用单独一个序号字段不行吗?
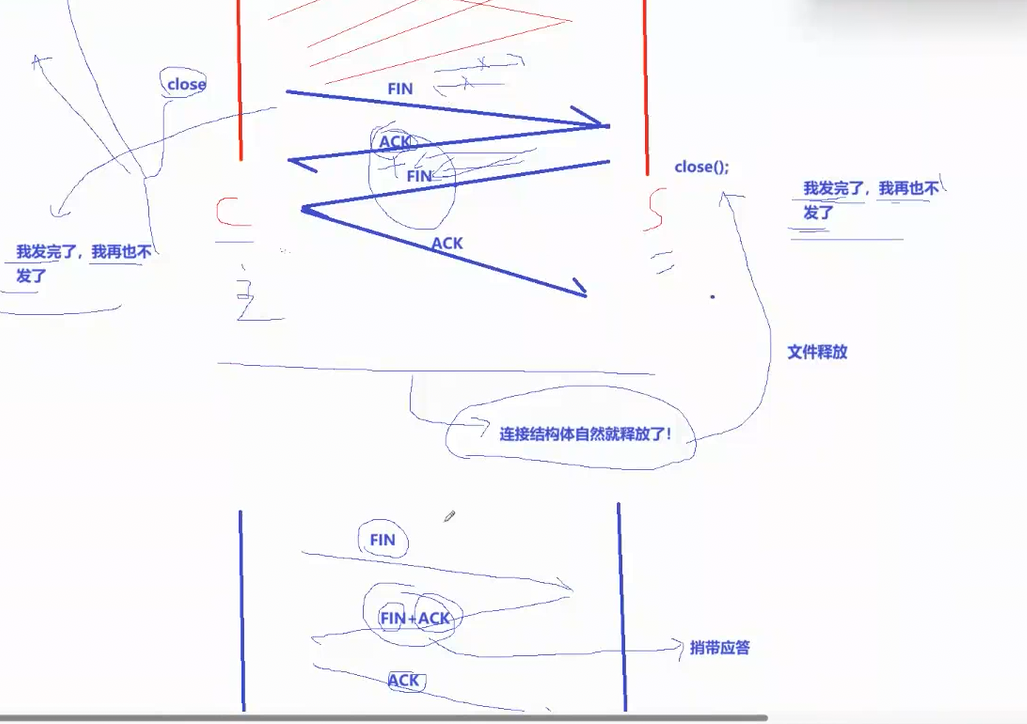
这就要结合 TCP 全双工通信 与捎带应答机制来理解。当 A 向 B 发送数据报文后,此时 B 刚好也有数据需要发送给 A (因为是全双工通信,A 和 B需要同时向对方收发消息),此时 B 就不需要单独发送一份数据报文给 A,而是直接把自己要发给 A 的数据,打包进回复 A 的应答报文中一起发送。这种双向数据同步收发、应答顺带携带业务数据的模式,就是 TCP 捎带应答机制。
在这种场景下,这个报文既需要用 32 位序号 标识 B 自己发给 A 的数据顺序,又需要用 32 位确认序号应答 A 之前发来的数据,两个字段缺一不可。序号负责标记自身传输的数据字节顺序,确认序号负责回复对方的应答报文顺序,二者配合就实现了 TCP 全双工双向的并发传输,大幅减少报文数量、提升通信效率。现实网络里这种捎带应答的场景十分普遍,这也是 TCP 每个报文报头,都必须同时携带序号与确认序号两个字段的核心原因。
我们先来讲解第一个核心标志位 ACK。就像主机 A 向主机 B 发送携带数据的报文后,B 需要向 A 回复对应的确认应答报文。而主机 A 判断收到的这份报文是不是应答报文,看的就是应答报文报头里的 ACK 标志位。只要 ACK 为 1,就代表当前报文具备应答功能 ,里面的确认序号正式生效;如果为 0,就代表这份报文不携带应答信息,不属于应答报文。结合我们之前学习的捎带应答机制,TCP 全双工通信里,绝大多数往来报文都会同时携带应答与数据,因此日常传输中大部分 TCP 报文的 ACK 标志位都固定为 1。同时 ACK 标志位也是三次握手建立连接、四次挥手断开连接流程里的核心标识,整个连接建立与断开全过程,都离不开 ACK 位的应答确认配合。
初识三次握手
接下来我们正式初识 TCP 的三次握手。三次握手本质就是 TCP 通信双方建立连接的过程。TCP 是面向连接的传输协议,主机 A 想要向主机 B 传输数据,绝对不能上来就直接发送消息,必须先通过三次报文交互完成连接建立,确认双方收发能力正常。
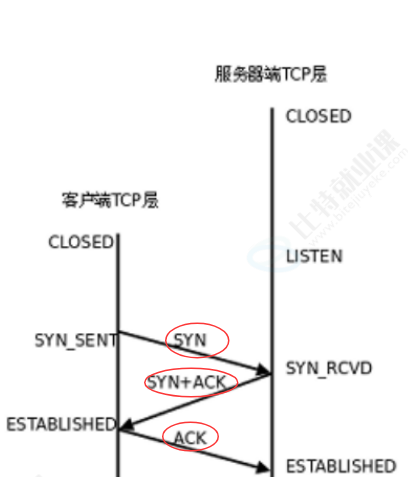
三次握手的流程依次是:首先客户端主机 A,向服务端主机 B 发送一个 SYN 标志位为 1 的同步报文,申请和对方建立 TCP 连接 。主机 B 收到这份连接请求后,确认自身可以建立连接,就会回复给 A 一份 SYN+ACK 两个标志位均为 1 的应答同步报文,既确认收到了 A 的连接请求,同时也同步自己的连接序号。主机 A 收到这份报文后,最后再向 B 发送一份 ACK 标志位为 1的确认应答报文,完成双向序号收尾确认。一来一回总共三次报文交互,因此被叫做三次握手,三次报文全部交互完成后,双方 TCP 连接就正式建立成功,进入可以正常传输数据的状态。
这三次交互的报文,我们都可以优先理解为只携带 TCP 报头、没有额外业务数据。其中第三次 A 发给 B 的 ACK 报文,可能会带有数据,但初学阶段我们统一理解为三次报文都以报头交互为主。三份报文里的 SYN、ACK 标志位,都会严格按照自身报文功能,对应置 1,以此区分连接请求、同步应答、最终确认三种不同报文身份。
TCP 连接结构体:
在三次握手顺利完成、TCP 连接正式建立之后,我们就要弄明白一个核心问题:TCP 连接到底是什么?
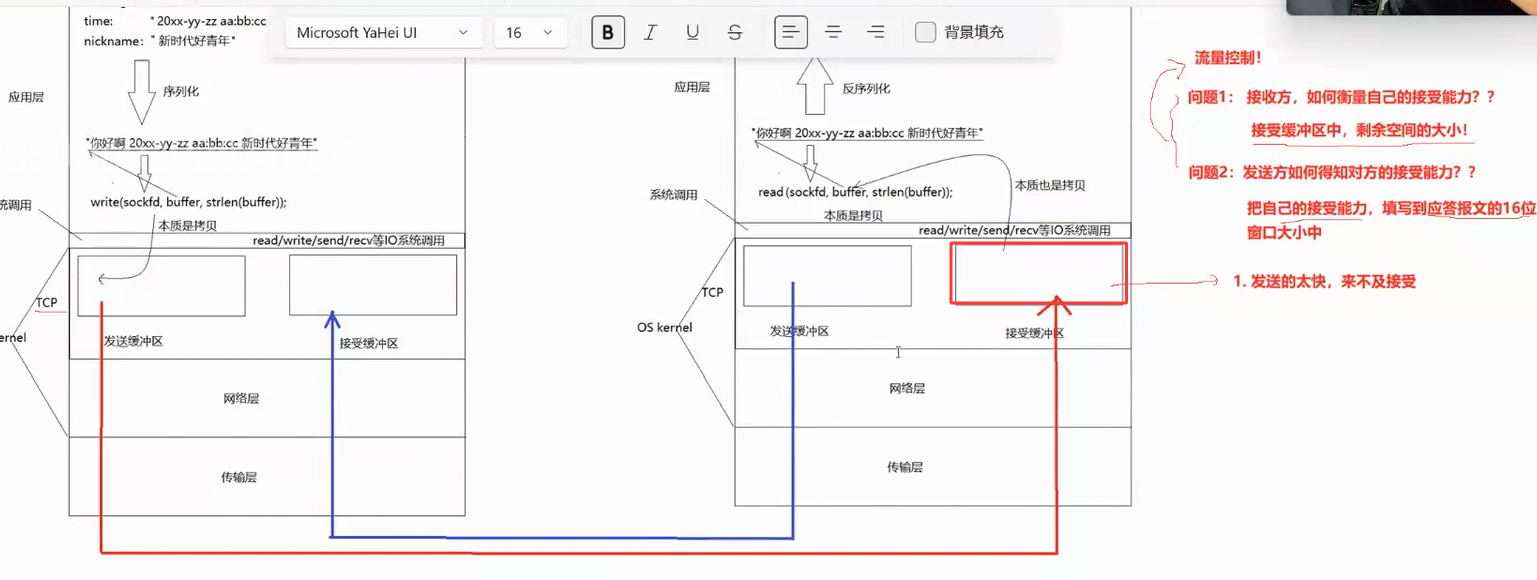
其实 TCP 连接的本质,就是操作系统内核里的一个专属结构体。inet_connection_sock 结构体,正是 Linux 内核里标准的 TCP 连接结构体,里面完整存储了这条连接的序号信息、超时定时器、窗口大小、拥塞控制参数、等待队列、状态信息等所有和这条 TCP 连接相关的全部数据。
也正因如此,TCP 建立、维护连接都需要消耗额外的内核内存与 CPU 时间资源,它的时间与空间开销,要远比无连接、不需要维护内核结构体的 UDP 协议大得多。
为什么要进行三次握手?
双方在正式通信传输数据前,首要前提就是保障双向网络是通畅的,而三次握手就是验证网络连通性最高效、次数最少的方案。TCP 本身是全双工通信协议,必须同时确认主机 A、主机 B 双向都具备正常发送、正常接收数据的完整能力。整个验证流程逻辑清晰:**A 先向 B 发送连接请求,确认 A 可以发送、B 可以接收;随后 B 向 A 同步应答,确认 B 可以发送、A 可以接收;最后 A 再次向 B 发送确认报文,让 B 明确知晓自己上一轮的应答已经被成功接收,彻底验证 B 的发送能力正常。**经过这三轮交互,双方双向收发能力全部核验无误,整条网络连通正常。三次就是验证全双工链路的最少必要次数,再多额外握手交互,都只会无端消耗网络资源、增加时延,属于完全没有意义的性能浪费。
SYN
讲完 ACK 标志位,我们接着讲解第二个核心标志位 SYN。SYN 标志位,就是专门用来标识TCP 连接建立请求的标志,只要报文报头里 SYN 位为 1,就代表这是一个同步 报文段,表示申请建立 TCP 可靠连接。TCP 三次握手整个流程,核心就是依靠 SYN 和 ACK 两个标志位配合完成。同时 SYN 报文不携带数据,只占用 1 个序号,这也是它和普通数据报文关键区别。
TCP 报文段就是我们说的 TCP 报文,是传输层经过完整封装后、在网络中独立发送的 TCP 数据包,整体结构由 TCP 报头与数据载荷两部分共同组成。而 SYN 标志位为 1 的报文,就被称作同步报文段 ,这类报文不会携带任何业务数据,唯一的作用就是让通信双方交换、对齐整条 TCP 字节流的起始编号,完成序列同步 。TCP 本身是面向连续字节流的协议,数据流里的每一个字节,都拥有独一无二的专属序号,在 TCP 连接正式建立之前,通信双方会各自生成一个专属的初始字节序号 ISN,这个用来约定字节流起点、在 SYN 报文中互相交换对齐的序号,就是同步序列号。客户端会通过 SYN 报文,把自己的初始同步序列号 发送给服务端,服务端也会通过 SYN 报文,把自身的初始同步序列号同步给客户端,双方互相确认、认可彼此的数据流起始编号,完成全双向的序号同步。
和 SYN 同步报文段类似,FIN 结束报文段同样不携带业务数据,只会占用一个字节的序号,专门用来发起连接断开请求。TCP 是全双工的,客户端与服务端两个方向的连接需要单独关闭、单独确认,因此 FIN 标志位配合 ACK 标志位,就构成了 TCP 断开连接四次挥手流程的核心逻辑。
初识四次挥手
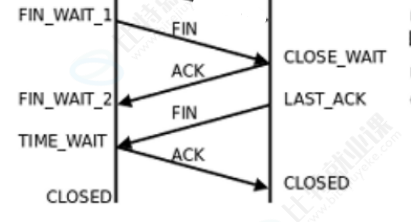
当客户端主动想要关闭 TCP 连接时,就会发起断开连接请求,先向服务端发送一份 FIN 标志位置 1 的结束报文段。服务端收到这份断开请求后,会立刻回复 ACK 应答报文,用来确认收到客户端的关闭请求,告知对方自己已知晓关闭意愿。此时服务端可能还有剩余数据没有传输完毕,等自身所有数据发送处理完成后,再向客户端发送 FIN 报文,告知客户端自己也已经没有数据需要发送,同样申请关闭自身方向的连接。客户端收到这份 FIN 报文后,最后再回复一份 ACK 确认报文。整个流程就像 A 向 B 提出断开连接,B 应答同意;B 再向 A 提出断开连接,A 最终应答确认,TCP 全双工双向连接,必须经过双方互相确认同意,才能完整断开。
核心原因就在于连接建立和断开的场景不同。建立连接时,客户端向服务端发起连接请求,服务端本身就是被动等待连接的角色,一定会无条件同意建立连接,因此服务端可以同时把ACK 应答报文和 SYN 同步连接报文,通过捎带应答合并在同一个报文里发送,直接减少一次交互,把四次流程压缩成三次握手。
但断开连接的场景完全不一样,主动方发起关闭请求后,被动方并不会立刻同意断开连接。因为断开连接和上层业务绑定,客户端发起 FIN 关闭请求时,服务端上层应用可能还有未处理完毕、未发送完成的业务数据,没办法马上响应断开。它必须先单独回复 ACK 确认收到关闭请求,等所有剩余数据全部处理传输完毕后,才能再单独发送 FIN 关闭报文。所以断开连接时 ACK 应答和 FIN 关闭请求无法合并捎带,不能压缩流程,因此常态下 TCP 断开连接就必须走完整四次挥手流程。
一份 TCP 报文由TCP 报头 + 上层有效数据载荷两部分共同组成。
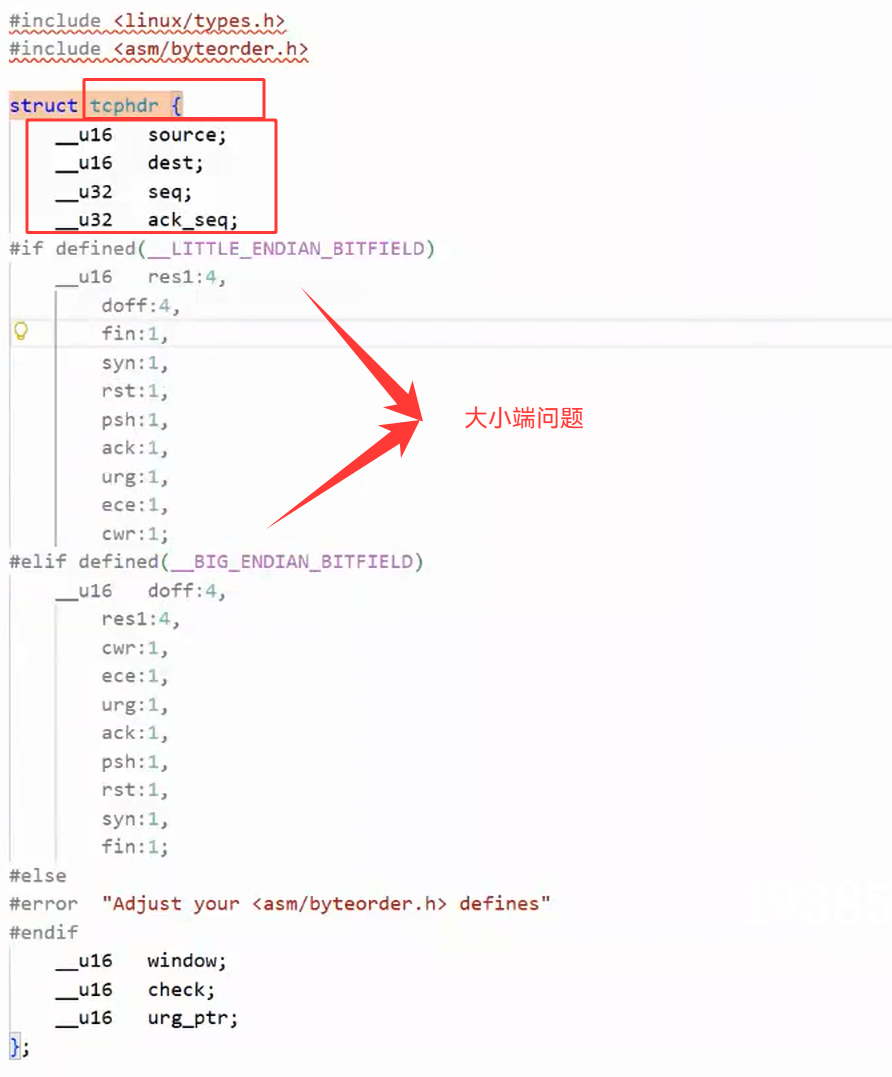
这里的 4 位首部长度,指的就是 TCP 报头中用4 个比特位来存储这个字段。4 个比特位的取值范围是 0~15,但它表示的长度单位不是 1 个字节,而是 4 个字节。
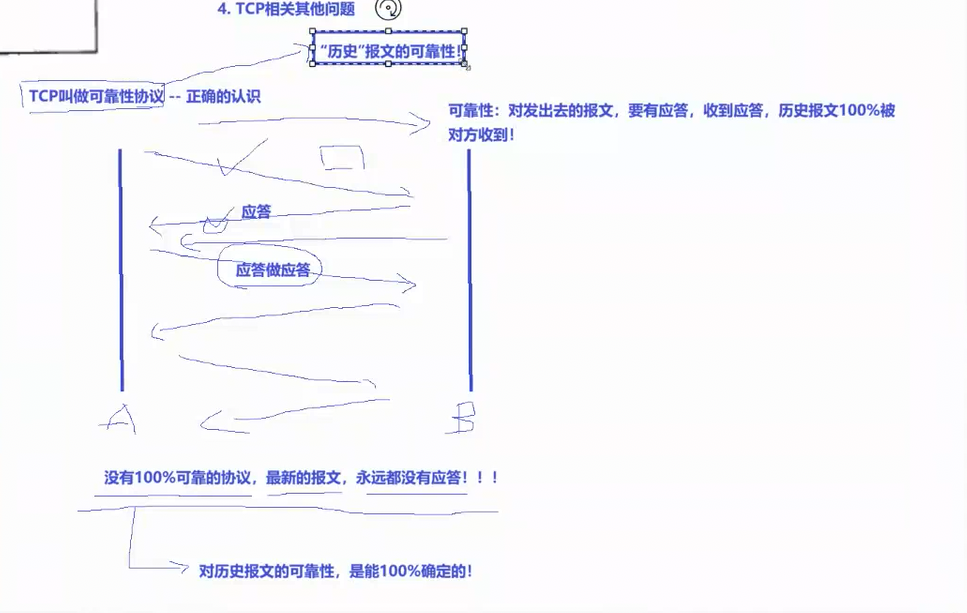 TCP 的传输可靠性是什么意思?我们用两台通信主机 A、B 举例来理解 :
TCP 的传输可靠性是什么意思?我们用两台通信主机 A、B 举例来理解 :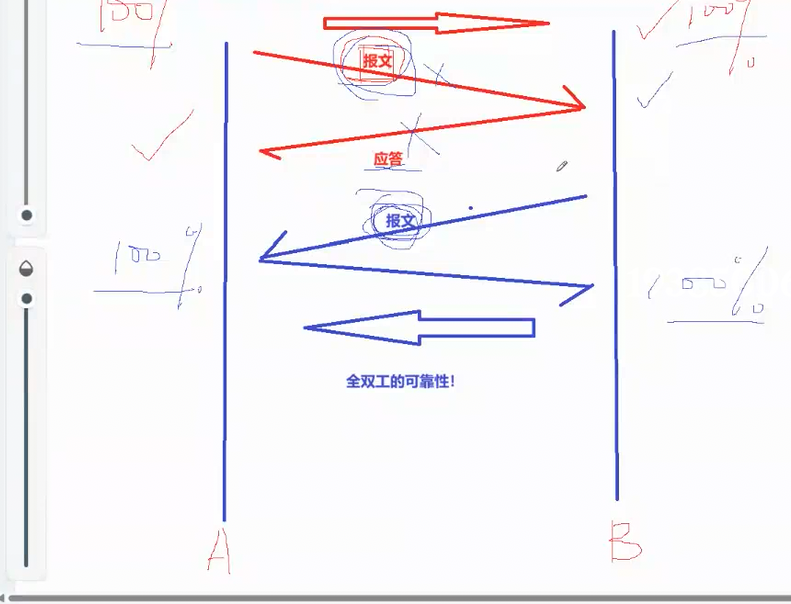






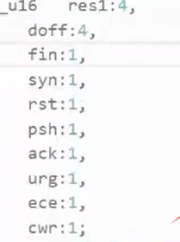
TCP 报头里最常用的就是上面 6 个核心标志位。严格来说底层内核结构体里一共有 8 个标志位,多出的 2 个标志位属于后期拥塞控制字段,日常常规通信、三次握手四次挥手、数据应答场景都不会用到,默认不用关注。同时 TCP 内核报文结构体里,本身就专门配套了对应的标志位字段,硬件和内核就是靠这个字段,识别每一份 TCP 报文的类型与功能。
inet_connection_sock 结构体,正是 Linux 内核里标准的 TCP 连接结构体,里面完整存储了这条连接的序号信息、超时定时器、窗口大小、拥塞控制参数、等待队列、状态信息等所有和这条 TCP 连接相关的全部数据。






recv的标志位OOB:
