目录
背影
支持向量机SVM的详细原理
SVM的定义
SVM理论
鲸鱼算法的原理及步骤
SVM应用实例,基于改进的支持向量机多分类预测研究
代码
结果分析
展望
背影
传统的支持向量机只能进行多分类,本文调用libsvm工具箱,并用鲸鱼算法改进参数,实现多分类
支持向量机SVM的详细原理
SVM的定义
支持向量机(support vector machines, SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;SVM还包括核技巧,这使它成为实质上的非线性分类器。SVM的的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。SVM的的学习算法就是求解凸二次规划的最优化算法。
(1)支持向量机(Support Vector Machine, SVM)是一种对数据进行二分类的广义线性分类器,其分类边界是对学习样本求解的最大间隔超平面。
(2)SVM使用铰链损失函数计算经验风险并在求解系统中加入了正则化项以优化结构风险,是一个具有稀疏性和稳健性的分类器 。
(3)SVM可以通过引入核函数进行非线性分类。
SVM理论
1,线性可分性

2,损失函数


3,核函数


SVM应用实例
鲸鱼算法
鲸鱼算法( Whale Optimization Algorithm )是根据鲸鱼围捕猎物的行为而提出的算法。鲸鱼是一种群居的哺乳动物,在捕猎时它们也会相互合作对猎物进行驱赶和围捕。鲸鱼算法提出时间并不长,也是一个新兴的优化算法,研究应用案例不多。
鲸鱼算法中,每个鲸鱼的位置代表了一个可行解。在鲸鱼群捕猎过程中,每只鲸鱼有两种行为,一种是包围猎物,所有的鲸鱼都向着其他鲸鱼前进;另一种是汽包网,鲸鱼环形游动喷出气泡来驱赶猎物。在每一代的游动
鲸鱼算法的参数
SearchAgents_no=20;%种群数量
Max_iter=50;%寻优代数
lb=0.0001;
ub=100;%范围
WOA-SVM的情感分类预测MATLAB代码
clc
clear
close all
load maydata.mat
input,inputps=mapminmax(num1',0,1);
output,outputns=mapminmax(num2',0,1);
input=input';
output=output';
nn= randperm(450);
% num2 = num2(nn);
P_train=input(nn(1:400)😅;
P_test=input(nn(401:450)😅;
T_train = num2(nn(1:400)😅;
T_test = num2(nn(401:450)😅;
NUM=2;%寻优参数为2个,核参数与惩罚参数
x,\~=woa_lssvm(NUM,P_train,T_train,P_test,T_test);
woam=x(1);woasig2=x(2);%
alpha,b= trainlssvm(P_train,T_train, woam, woasig2);
woa_result= simlssvm(P_test, P_train, alpha, b, woasig2);
woa_result=round(woa_result)
figure
stem((woa_result));
hold on;grid on
plot( (T_test), '*');
legend('期望输出', '实际输出');
title('woa-svm ')
hold off;
woa_result1,mx1 = sort(woa_result);
T_test1= T_test(mx1);
figure
stem((woa_result1));
hold on;grid on
plot( (T_test1), '*');
legend('期望输出', '实际输出');
title('woa-svm ')
hold off;
mat = confusionmat(woa_result,T_test);
% 各类精度
for i=1:8
disp('第',num2str(i),'类精度为',num2str(mat(i,i)/sum(mat(i,:))))
end
function alpha,b = trainlssvm(X, y, gam, sig2)
svmrow,svmcolum = size(X);
KerFunction=\[\];
for i= 1:svmrow
for j= 1:svmrow
a= 0;
for k= 1:svmcolum
a=a-(X(i,k)-X(j,k))^2;
end
KerFunction(i,j)= exp(a/(sig2^2));
end
end
A= KerFunction;
for i= 1:svmrow
A(i,i)= A(i,i)+1/gam;
end
m= ones(svmrow,1);
b= m'*inv(A)*y/(m'inv(A)m);
alpha= inv(A)(y-bm);
function yt= simlssvm(Xstar, X, alpha, b, sig2)
l= size(alpha,1);
m,n= size(Xstar);
for i= 1:m
temp= 0;
for j= 1:l
a=0;
for k= 1:n
a=a-(Xstar(i,k)-X(j,k))^2;
end
temp=temp+alpha(j)*exp(a/(sig2^2));
% yt(i)= temp+b;
end
yt(i,:)=temp+b;
end
function Leader_pos,Convergence_curve=woa_lssvm(dim,X1,y1,Xt,yt)
%% 参数设置
SearchAgents_no=20;%种群数量
Max_iter=50;%寻优代数
lb=0.0001;
ub=100;%范围
%% 初始化
Leader_pos=zeros(1,dim);
Leader_score=inf;
for i=1:SearchAgents_no
Positions(i,:)=rand(1,dim).(ub-lb)+lb;
end
Convergence_curve=zeros(1,Max_iter);
%% 主循环
for t=1:Max_iter
a=2-t ((2)/Max_iter);
a2=-1+t*((-1)/Max_iter);
for i=1:size(Positions,1)
r1=rand();
r2=rand();
A=2a r1-a;
C=2r2;
b=1;
l=(a2-1)rand+1;
p = rand();
for j=1:size(Positions,2)
if p<0.5
if abs(A)>=1
rand_leader_index = floor(SearchAgents_no rand()+1);
X_rand = Positions(rand_leader_index, 😃;
D_X_rand=abs(C X_rand(j)-Positions(i,j));
Positions(i,j)=X_rand(j)-AD_X_rand;
elseif abs(A)<1
D_Leader=abs(C Leader_pos(j)-Positions(i,j));
Positions(i,j)=Leader_pos(j)-AD_Leader;
end
elseif p>=0.5
distance2Leader=abs(Leader_pos(j)-Positions(i,j));
Positions(i,j)=distance2Leader exp(b.*l).*cos(l.2 pi)+Leader_pos(j);
end
end
Positions(i,:)=boundary(Positions(i,:),lb,ub);
fit=fitness(Positions(i,:),X1,y1,Xt,yt);
% 更新
if fit<Leader_score
Leader_score=fit;
Leader_pos=Positions(i,:);
end
end
Convergence_curve(t)=Leader_score;
end
figure
plot(Convergence_curve,'k-')
xlabel('迭代次数')
ylabel('适应度值')
function yt= simlssvm(Xstar, X, alpha, b, sig2)
l= size(alpha,1);
m,n= size(Xstar);
for i= 1:m
temp= 0;
for j= 1:l
a=0;
for k= 1:n
a=a-(Xstar(i,k)-X(j,k))^2;
end
temp=temp+alpha(j)*exp(a/(sig2^2));
% yt(i)= temp+b;
end
yt(i,:)=temp+b;
end
效果图
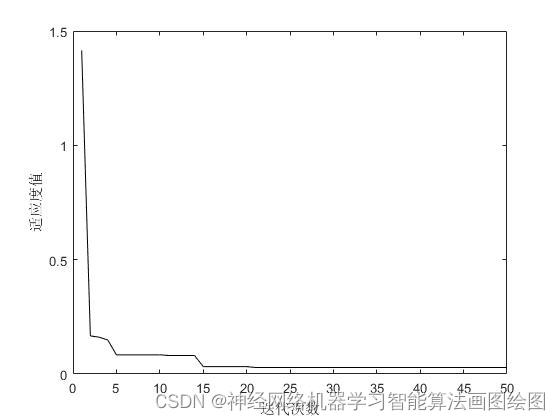
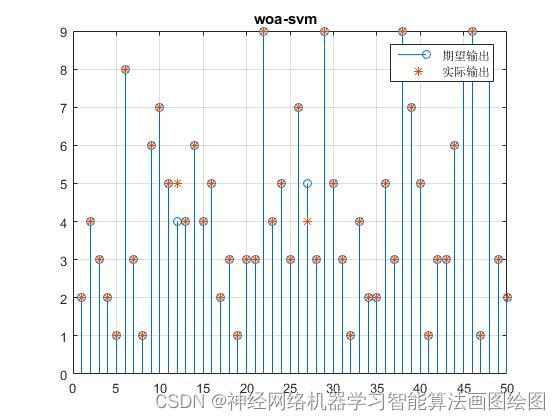
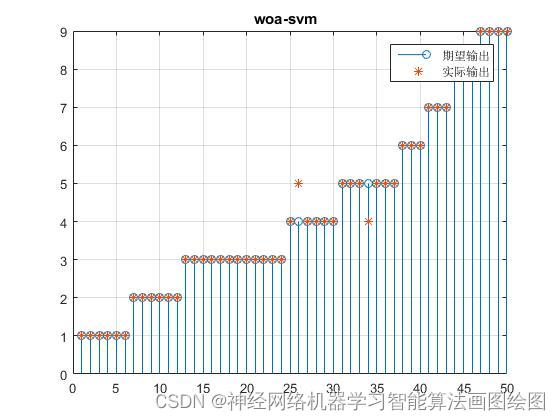
结果分析
从效果图看,鲸鱼算法改进的SVM分类准确率高很多,可以实现多分类的准确预测,分类准确率百分之98左右。
扩展
SVM是一种很好的分类,对应很多分类问题,特别小样本分类问题,拥有很好的分类能力,经过改进后可以应用的方面更多,下面是部分SVM可以应用的方面,如果有需要欢迎扫描二维码联系
