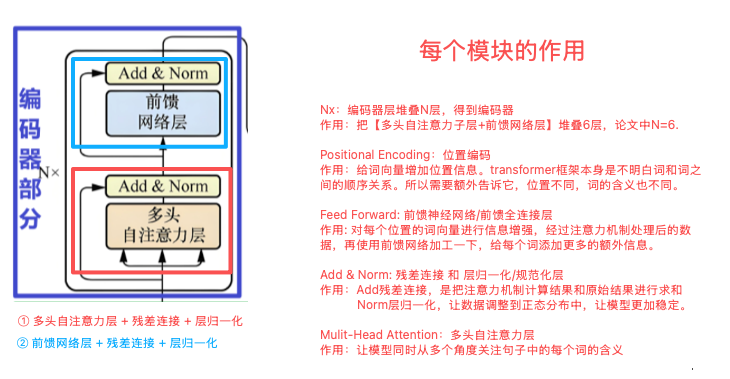
Transformer 编码器部分组成
代码部分:
1.单层编码器
python
"""
编码器层
由两部分组成
① 多头自注意力层 + 层归一化 + 残差连接
② 前馈网络 + 层归一化 + 残差连接
"""
class EncoderLayer(nn.Module):
def __init__(self, d_model, multi_head_self_attention, feed_forward_obj, dropout_p):
super().__init__()
"""
维度、多头自注意力、前馈网络、随机失活
"""
self.d_model = d_model
self.multi_head_self_attention = multi_head_self_attention
self.feed_forward_obj = feed_forward_obj
self.dropout_p = dropout_p
"""
第①部分
第②部分
"""
self.multi_layer = SubLayerConnection(self.d_model, self.dropout_p)
self.feed_forward_layer = SubLayerConnection(self.d_model, self.dropout_p)
def forward(self, data):
"""
# 1- 数据经过第一个层的处理:多头自注意力子层
这里data 输入数据,自注意力,data=Q=K=V
# 2- 数据经过第二个层的处理:前馈网络子层
第一个模块处理后的数据,带入前馈网络相关的第二模块
"""
multi_output = self.multi_layer(
data,
lambda x: self.multi_head_self_attention(query=x, key=x, value=x, mask=None)
)
encoder_output = self.feed_forward_layer(
multi_output,
lambda y: self.feed_forward_obj(y)
)
return encoder_output2.N层编码器层
python
"""
N层编码器层
"""
class Encoder(nn.Module):
def __init__(self, encoder_layer, N=6):
super().__init__()
"""
复制N分,深拷贝
"""
self.encoder_layer_list = clones(encoder_layer,N)
"""
【可选】最后输出做一次归一化层 处理,保证数据更加平稳。
"""
self.layer_norm = LayerNorm(encoder_layer.d_model)
def forward(self, data):
"""
输入数据进行 N层的 编码处理,最终输出
"""
for layer in self.encoder_layer_list:
data = layer(data)
return self.layer_norm(data)3.测试使用 N层编码器
python
"""
使用 N层编码器 -> 得到编码器输出
"""
def use_encoder():
position_data = use_positional_encoding()
d_model = 512
dropout_p = 0.1
num_heads = 8 #多头数 512/8 = 64 子维度
"""
多头自注意力对象
前馈网络对象
单层编码器对象
"""
multi_head_self_attention = MultiHeadAttention(d_model, num_heads, dropout_p)
feed_forward_obj = FeedForward(d_model=d_model, output_dim=1024, dropout=dropout_p)
encoder_layer = EncoderLayer(
d_model=d_model,
multi_head_self_attention=multi_head_self_attention,
feed_forward_obj=feed_forward_obj,
dropout_p=dropout_p
)
encder = Encoder(encoder_layer,6)
output = encder(position_data)
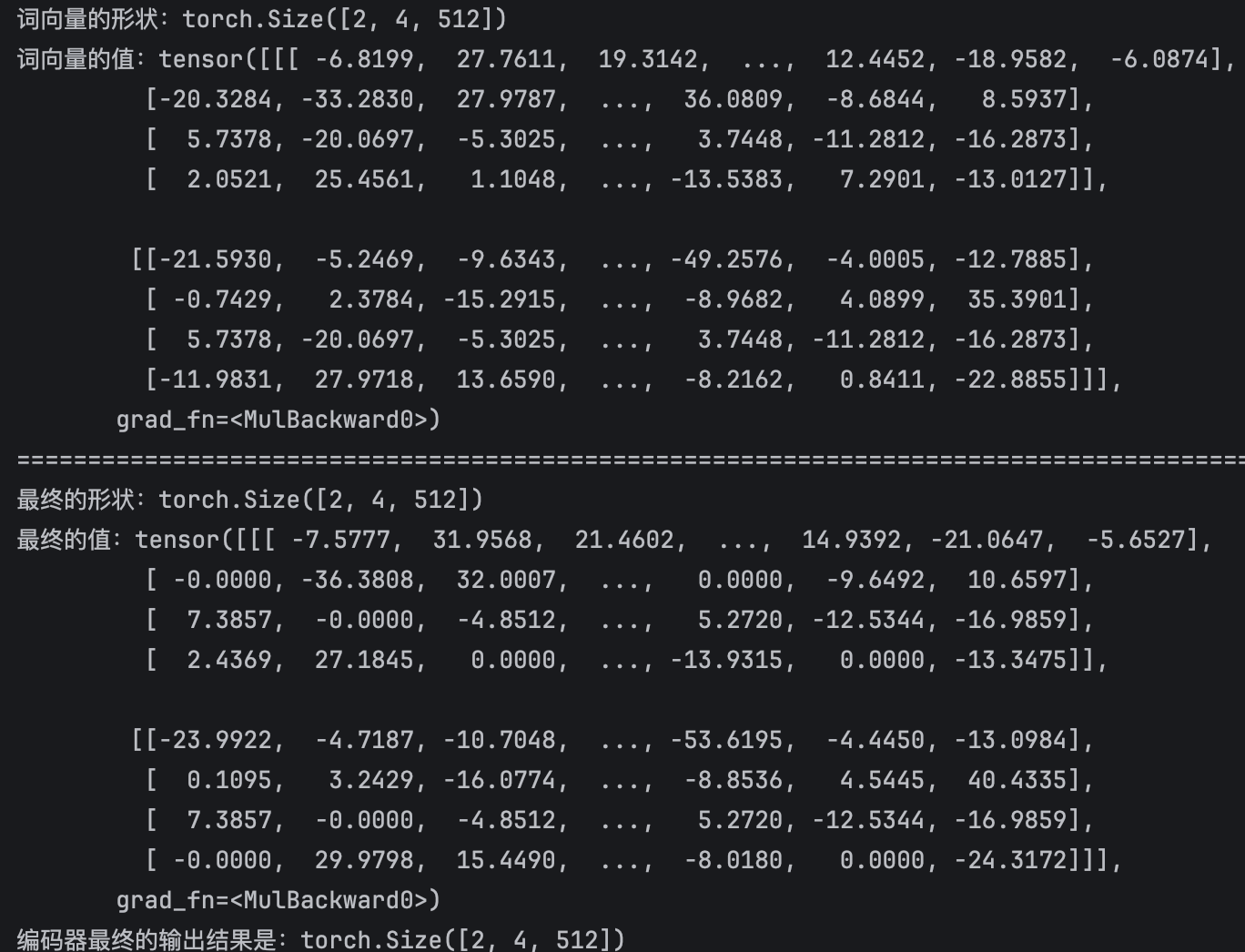
print(f"编码器最终的输出结果是:{output.shape}")
if __name__ == "__main__":
test_encoder()