
观众老爷们大家好 我是邪修KING 本文属于系列C++ 进阶篇 ,欢迎来到C++进阶篇博客 C++重点语法运用! 本文属于 《C++ 进阶篇系统教程》第 3 篇 ,上一篇我们讲透了多态的核心原理与 8 个致命坑点,今天我们进入数据结构与算法的核心篇章 ------二叉搜索树 (Binary Search Tree, BST)。 它是红黑树、AVL 树、B + 树等所有高级平衡树的基础,也是 STL 中map/set容器的底层原型,更是校招面试的必考题!
很多人觉得二叉树难,其实二叉搜索树是所有二叉树中最容易理解、最实用的一种。它完美结合了数组的快速查找和链表的快速插入删除 的优势,核心特性是中序遍历有序 ,这也是它能解决绝大多数有序数据处理问题的原因。
这篇文章我们从基础概念到底层实现,结合完整可运行的 C++ 模板代码,讲透二叉搜索树的插入、查找、删除三大核心操作,分析它的性能优势与缺陷,最后对比 key 模型和 key/value 模型的实际使用场景。
一、什么是二叉搜索树?
1.1 核心定义
二叉搜索树是一种特殊的二叉树,它满足以下三个性质:
1.左子树所有节点的值 < 根节点的值
2.右子树所有节点的值 > 根节点的值
3.左子树和右子树本身也都是二叉搜索树
注意:标准二叉搜索树不允许存储重复的 key,如果需要支持重复 key,可以在节点中增加一个计数成员变量,或者使用multiset/multimap。
1.2 核心特性:中序遍历有序
这是二叉搜索树最重要的特性:对二叉搜索树进行中序遍历(左→根→右),会得到一个升序排列的序列。
比如下面这棵二叉搜索树:
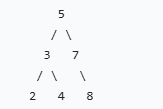
中序遍历的结果是:2 3 4 5 7 8,正好是升序排列。
这个特性让二叉搜索树天然适合处理有序数据的查找、插入、删除、范围查询等问题。
二、二叉搜索树的性能分析
二叉搜索树的性能完全取决于树的高度,我们分三种情况分析:
| 情况 | 树的形态 | 时间复杂度 | 说明 |
|---|---|---|---|
| 最好情况 | 完全二叉树 / 平衡二叉树 | O(log₂n) | 树的高度是 log₂n,所有操作都是对数级 |
| 平均情况 | 随机插入的二叉搜索树 | O(log₂n) | 随机数据下,树的高度接近 log₂n |
| 最坏情况 | 单链(所有节点只有左孩子或右孩子) | O(n) | 退化成链表,所有操作都是线性级 |
与其他数据结构的性能对比
| 数据结构 | 查找 | 插入 | 删除 | 有序性 |
|---|---|---|---|---|
| 顺序表 | O(n) | O(n) | O(n) | 支持 |
| 链表 | O(n) | O (1)(已知前驱) | O (1)(已知前驱) | 不支持 |
| 哈希表 | O (1)(平均) | O (1)(平均) | O (1)(平均) | 不支持 |
| 二叉搜索树 | O (logn)(平均) | O (logn)(平均) | O (logn)(平均) | 支持 |
二叉搜索树的核心优势 :同时拥有对数级的查找插入删除性能和天然的有序性 ,这是哈希表无法替代的。
核心缺陷:最坏情况下会退化成单链,性能骤降。这也是为什么后来出现了 AVL 树、红黑树等平衡二叉搜索树,通过旋转操作保证树的高度始终是 O (logn)。
三、二叉搜索树的三大核心操作
3.1 插入操作
插入逻辑
1.如果树为空,直接创建新节点作为根节点
2.如果树不为空,从根节点开始遍历,同时跟踪父节点
3.比较待插入 key 和当前节点 key:
key < 当前节点 key:去左子树,更新父节点和当前节点
key > 当前节点 key:去右子树,更新父节点和当前节点
key == 当前节点 key:插入失败(重复)
4.找到空位置后,创建新节点,根据 key 的大小挂到父节点的左或右孩子
代码实现
cpp
template <typename T>
bool BSTree<T>::Insert(const T& key) {
// 1. 树为空,直接创建根节点
if (_root == nullptr) {
_root = new Node(key);
return true;
}
// 2. 树不为空,遍历找到插入位置,同时跟踪父节点
Node* cur = _root;
Node* parent = nullptr;
while (cur != nullptr) {
if (key < cur->_key) {
parent = cur;
cur = cur->_left;
} else if (key > cur->_key) {
parent = cur;
cur = cur->_right;
} else {
// 3. key重复,插入失败
return false;
}
}
// 4. 创建新节点,挂到父节点的对应位置
Node* new_node = new Node(key);
if (key < parent->_key) {
parent->_left = new_node;
} else {
parent->_right = new_node;
}
return true;
}注意:必须跟踪父节点!因为新节点需要挂到父节点的左或右指针上,没有父节点就无法完成插入。
3.3 查找操作
核心逻辑
从根节点开始循环比较,直到找到目标 key 或遍历到空节点:
cpp
template <typename T>
bool BSTree<T>::Find(const T& key) const {
Node* cur = _root;
while (cur != nullptr) {
if (key == cur->_key) {
return true;
} else if (key < cur->_key) {
cur = cur->_left;
} else {
cur = cur->_right;
}
}
return false;
}3.4 删除操作(非递归版,最难!面试必考)
删除操作是非递归版最复杂的部分,核心难点是必须同时跟踪当前节点和它的父节点 ------ 因为删除节点时,需要修改父节点的指针指向。
核心步骤
1.遍历树,找到要删除的节点cur,同时记录它的父节点parent
2.分三种情况处理cur:
情况 1:cur 是叶子节点(左右都为空) :直接删除 cur,将 parent 的对应指针置空
情况 2 :cur 只有一个孩子 :将 parent 的对应指针指向 cur 的孩子,然后删除 cur
情况 3 :cur 有两个孩子 :用替换法,找到 cur 右子树的最小节点min_node,将min_node的值赋值给 cur,然后删除min_node(min_node一定是叶子节点或只有右孩子,转化为情况 1 或 2)
辅助函数:找右子树的最小节点及其父节点
cpp
template <typename T>
void BSTree<T>::FindMinNode(Node* root, Node*& min_node, Node*& min_parent) const {
min_node = root;
min_parent = nullptr;
while (min_node->_left != nullptr) {
min_parent = min_node;
min_node = min_node->_left;
}
}完整删除代码
cpp
template <typename T>
bool BSTree<T>::Erase(const T& key) {
// 1. 找到要删除的节点cur和它的父节点parent
Node* cur = _root;
Node* parent = nullptr;
while (cur != nullptr) {
if (key < cur->_key) {
parent = cur;
cur = cur->_left;
} else if (key > cur->_key) {
parent = cur;
cur = cur->_right;
} else {
// 2. 找到节点,开始删除
break;
}
}
// 没找到节点,删除失败
if (cur == nullptr) {
return false;
}
// 3. 分三种情况处理
// 情况1:cur是叶子节点(左右都为空)
if (cur->_left == nullptr && cur->_right == nullptr) {
// 特殊情况:删除的是根节点
if (cur == _root) {
_root = nullptr;
} else {
// 修改父节点的指针
if (parent->_left == cur) {
parent->_left = nullptr;
} else {
parent->_right = nullptr;
}
}
delete cur;
}
// 情况2:cur只有右孩子
else if (cur->_left == nullptr) {
// 特殊情况:删除的是根节点
if (cur == _root) {
_root = cur->_right;
} else {
if (parent->_left == cur) {
parent->_left = cur->_right;
} else {
parent->_right = cur->_right;
}
}
delete cur;
}
// 情况3:cur只有左孩子
else if (cur->_right == nullptr) {
// 特殊情况:删除的是根节点
if (cur == _root) {
_root = cur->_left;
} else {
if (parent->_left == cur) {
parent->_left = cur->_left;
} else {
parent->_right = cur->_left;
}
}
delete cur;
}
// 情况4:cur有两个孩子(最复杂)
else {
// 找到右子树的最小节点min_node和它的父节点min_parent
Node* min_node = nullptr;
Node* min_parent = nullptr;
FindMinNode(cur->_right, min_node, min_parent);
// 替换值:把min_node的值赋给cur
cur->_key = min_node->_key;
// 删除min_node(min_node一定是叶子节点或只有右孩子)
if (min_parent->_left == min_node) {
min_parent->_left = min_node->_right;
} else {
// 特殊情况:cur的右孩子就是最小节点(min_parent == cur)
min_parent->_right = min_node->_right;
}
delete min_node;
}
return true;
}3 个最容易踩的坑:
1.删除根节点的特殊处理:当删除的是根节点时,parent为nullptr,需要直接修改_root指针
2.替换法中最小节点的父节点处理:如果cur的右孩子本身就是最小节点(没有左孩子),那么min_parent == cur,这时候要修改cur->_right而不是min_parent->_left
3.删除有两个孩子的节点时,只需要替换值,不需要移动节点:这样可以避免修改大量指针,效率更高
3.5 中序遍历(非递归版)
非递归中序遍历需要借助栈来模拟递归的调用栈,核心逻辑是:
1.先把所有左孩子入栈
2.弹出栈顶节点,访问它
3.然后把该节点的右孩子入栈,重复步骤 1
cpp
template <typename T>
void BSTree<T>::InOrder() const {
cout << "中序遍历:";
stack<Node*> st;
Node* cur = _root;
while (cur != nullptr || !st.empty()) {
// 1. 把所有左孩子入栈
while (cur != nullptr) {
st.push(cur);
cur = cur->_left;
}
// 2. 弹出栈顶节点,访问
cur = st.top();
st.pop();
cout << cur->_key << " ";
// 3. 处理右子树
cur = cur->_right;
}
cout << endl;
}四、完整的二叉搜索树模板实现(支持 key 和 key/value 模型)
我们用 C++ 模板实现一个通用的二叉搜索树,既支持key 模型 (只存键),也支持key/value 模型(存键值对),包含插入、查找、删除、中序遍历、析构等所有核心功能。
五、key 模型 vs key/value 模型:使用场景与示例
二叉搜索树有两种最常用的使用模式,分别对应不同的业务场景:
5.1 key 模型:只存键,用于判断是否存在
key 模型中,每个节点只存储一个 key,核心作用是判断某个 key 是否存在于集合中。
典型使用场景
1.**单词拼写检查:**将所有正确的单词存入二叉搜索树,输入单词时查找是否存在
2.黑名单 / 白名单 :存储黑名单 IP 或手机号,快速判断是否在名单中
3.**数据去重:**插入数据时如果 key 已存在则插入失败,实现去重
4.**集合运算:**求两个集合的交集、并集、差集
代码示例:单词拼写检查
cpp
// key模型示例:单词拼写检查
int main() {
BSTree<string> dict;
// 插入正确的单词
dict.Insert("hello");
dict.Insert("world");
dict.Insert("c++");
dict.Insert("bst");
// 检查单词拼写
string word;
cout << "请输入要检查的单词:";
cin >> word;
if (dict.Find(word)) {
cout << "拼写正确!" << endl;
} else {
cout << "拼写错误!" << endl;
}
return 0;
}5.2 key/value 模型:存键值对,用于关联查询
key/value 模型中,每个节点存储一个pair<Key, Value>,key 是唯一的,value 是与 key 关联的数据。核心作用是通过 key 快速查找对应的 value。
典型使用场景
1.字典 / 词典:key 是单词,value 是单词的释义
2.学生信息管理:key 是学号,value 是学生的姓名、年龄、成绩等信息
3.缓存系统:key 是缓存键,value 是缓存的数据
4.统计词频:key 是单词,value 是单词出现的次数
代码示例:学生信息管理系统
cpp
// key/value模型示例:学生信息管理
int main() {
// 存储:学号 -> 姓名
BSTree<pair<int, string>> student_db;
// 插入学生信息
student_db.Insert(make_pair(2026001, "张三"));
student_db.Insert(make_pair(2026002, "李四"));
student_db.Insert(make_pair(2026003, "王五"));
// 通过学号查找学生姓名
int id;
cout << "请输入学号:";
cin >> id;
// 注意:pair的比较是先比较first,再比较second
pair<int, string> key = make_pair(id, "");
if (student_db.Find(key)) {
// 实际项目中会返回对应的value,这里简化为查找是否存在
cout << "找到学生:" << key.second << endl;
} else {
cout << "学生不存在!" << endl;
}
return 0;
}六、常见坑点与注意事项
1.不允许重复 key:标准二叉搜索树不支持重复 key,如果需要支持,可以在节点中增加_count成员变量,记录 key 出现的次数。
2.删除操作的替换法:删除有两个孩子的节点时,一定要用右子树的最小节点或左子树的最大节点替换,这样才能保证二叉搜索树的性质。
3.性能依赖树的高度:如果插入的数据是有序的,二叉搜索树会退化成单链,性能骤降。实际开发中一般使用红黑树(STL 的map/set)或 AVL 树等平衡二叉搜索树。
4.中序遍历的有序性:这是二叉搜索树最核心的特性,所有有序相关的操作(范围查询、找第 k 大元素、找前驱后继)都是基于这个特性实现的。
5.内存管理:二叉搜索树的节点是动态申请的,一定要在析构函数中递归释放所有节点,避免内存泄漏。
七、总结
1.二叉搜索树的核心性质:左子树 < 根 < 右子树,中序遍历有序。
2.三大核心操作:插入、查找都是 O (logn) 平均时间复杂度,删除分三种情况处理,最复杂的是有两个孩子的节点,用替换法解决。
3.性能分析:平均 O (logn),最坏 O (n),这也是平衡二叉树出现的原因。
4.两种使用模型:key 模型用于判断存在性,key/value 模型用于关联查询,覆盖绝大多数业务场景。
5.二叉搜索树是所有高级平衡树的基础:红黑树、AVL 树都是在二叉搜索树的基础上,增加了旋转操作来保证树的平衡,解决最坏情况的性能问题。
二叉搜索树是数据结构与算法的核心,也是 STL 中map/set容器的底层原型,更是校招面试的必考题。
本文属于 **《C++ 进阶篇系统教程》第 3 篇,**后续会持续更新:
AVL 树与红黑树深度剖析、STL map/set 底层原理、哈希表与 unordered_map、C++ 校招算法真题。
关注我,第一时间收到更新,不用自己零散找资料,跟着系列系统学,少走 90% 的弯路!
