1.动态库大体的调用过程
补充:静态库合并完后就没有用了,即静态库自己是不会加载到内存中的。
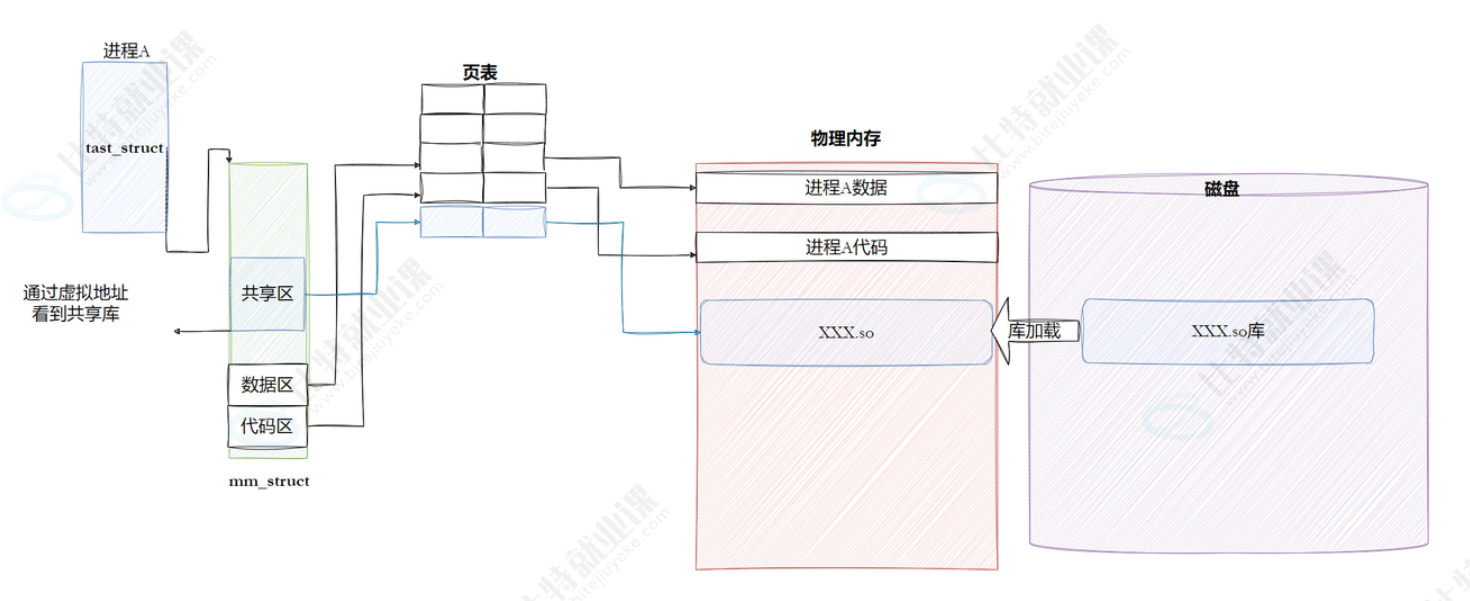
动态库自己本身也是EIF格式,因此其也会在页表上产生映射关系并加载到mm_struct的共享区中。在代码区中的指令要用到动态库时就会先跳跃到共享区的代码中,运行完再返回到代码区中。
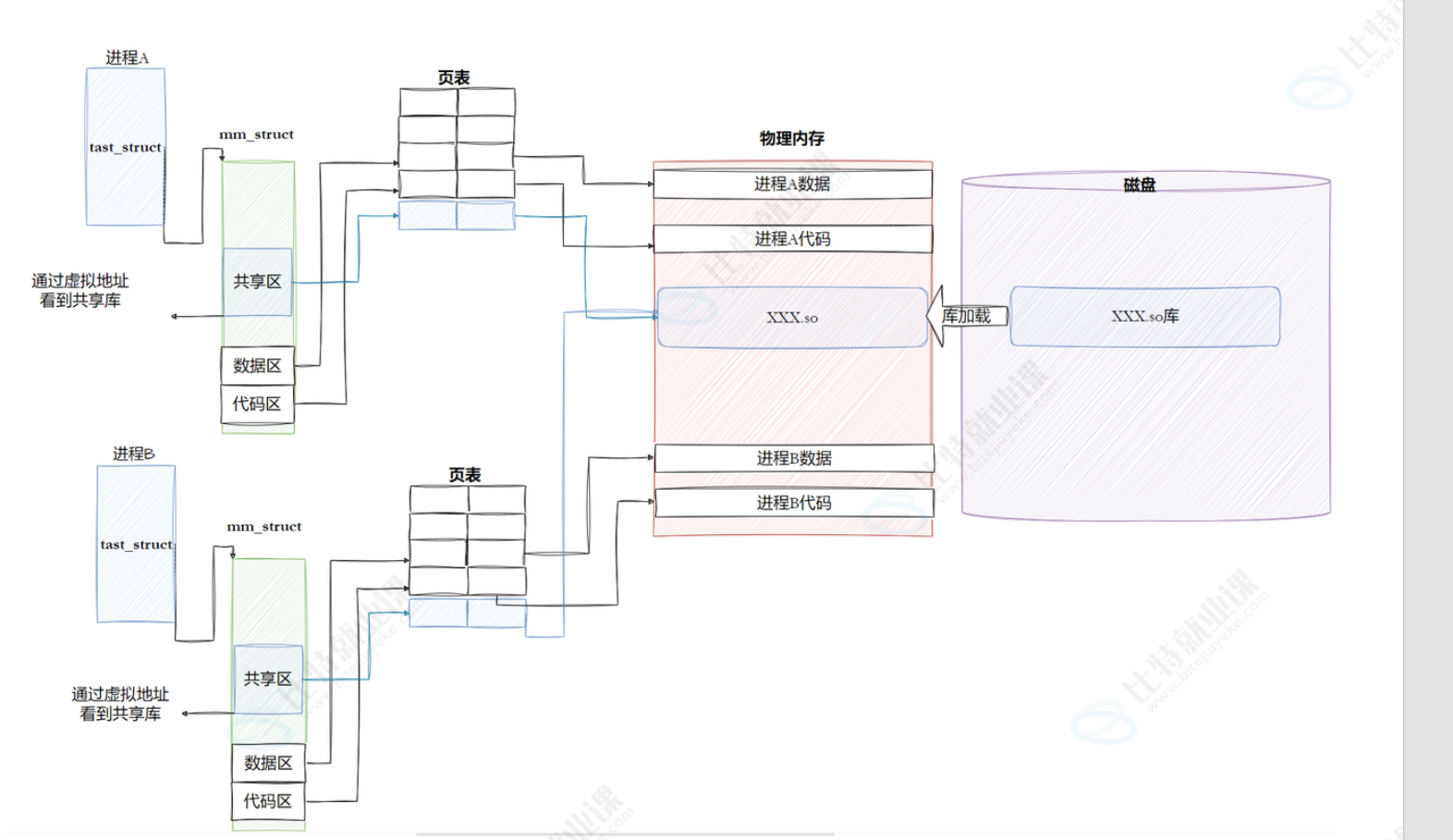
动态库其实就是公交车,多进程通过映射最后指向的动态库代码都是同一份。
2.动态库的加载过程
_start是链接器给我们提供的一个特殊函数。
用途为:(1)创建堆/栈区(2)初始化数据段(3)加载动态库
动态链接器:加载动态库进内存(搜索动态库所在路径就是用的环境变量和配置文件)
动态库也是EIF,地址编址方式也是起始地址(0)+偏移量。
因此动态库一个函数的地址就是其的偏移量,在共享区的映射地址就是该区的起始地址+该函数的虚拟地址(原因在于动态起始地址的0和一个进程起始地址的0不是同一个0,也就是进程的虚拟地址表不认为动态库的起始地址是该进程的起始地址,进程的起始地址存在该进程磁盘文件的EIF header中)
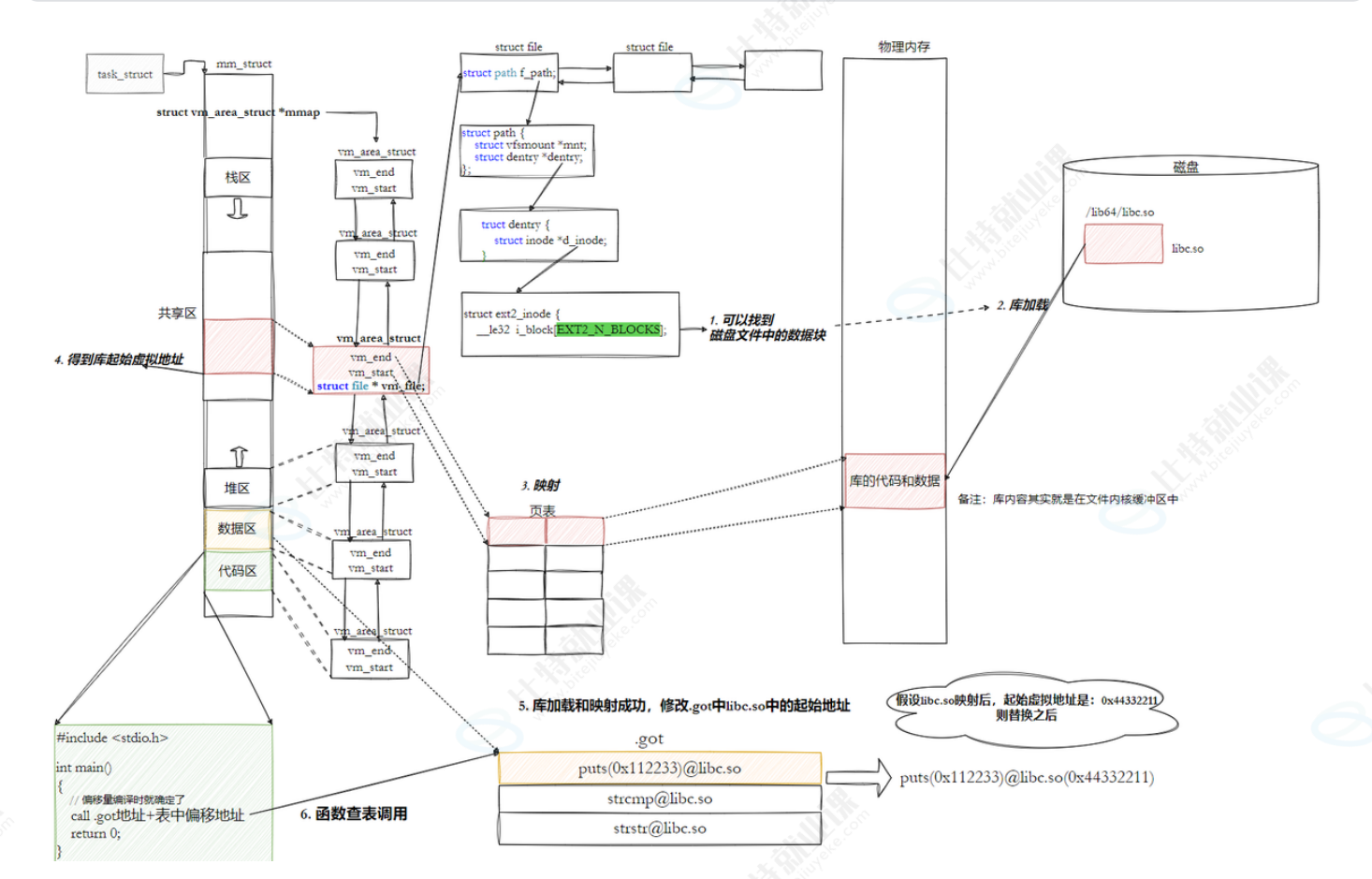
具体映射过程
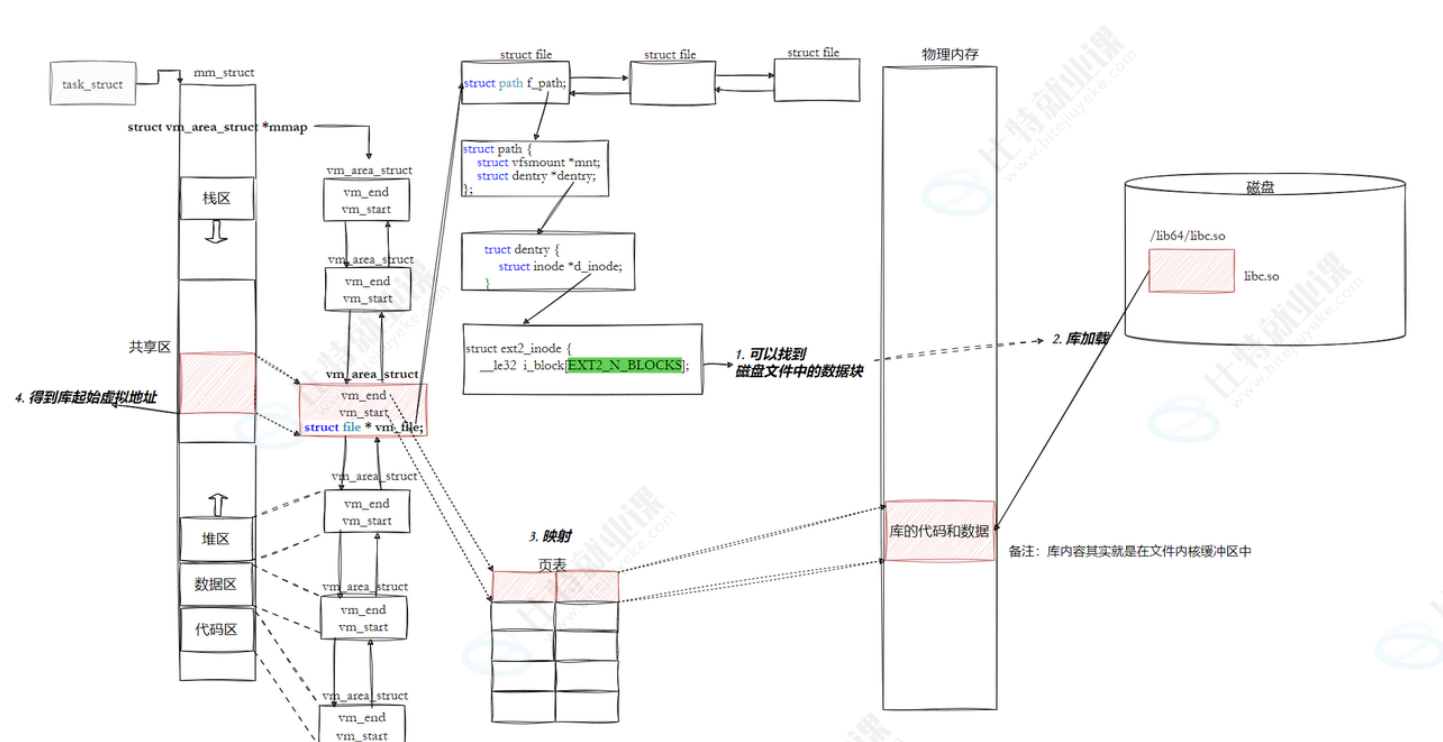
(1)在我们的代码需要调用动态库时,会在符号表中记录的对应动态库路径找到该库,为其生成struct file之后就加载库的数据和代码
(2)进程创建一个vm_area_struct储存该库的地址(就是该库的相对偏移地址)
(3)在页表中建立映射关系(页表只允许存储相对偏移地址)
(4)得到库在共享区的起始虚拟地址,加上库中方法的偏移量就可以调用对应函数了(vm_area_struct中有一个成员vm_file能找到初始化这个结构体的文件)
所以进程就是通过vm_area_struct来找到动态库的代码和数据的,调用库函数的过程总的来说就是该库在共享区的起始虚拟地址+方法的偏移量即可定位到该方法的位置。
下面层层递进找到动态库的真实调用过程
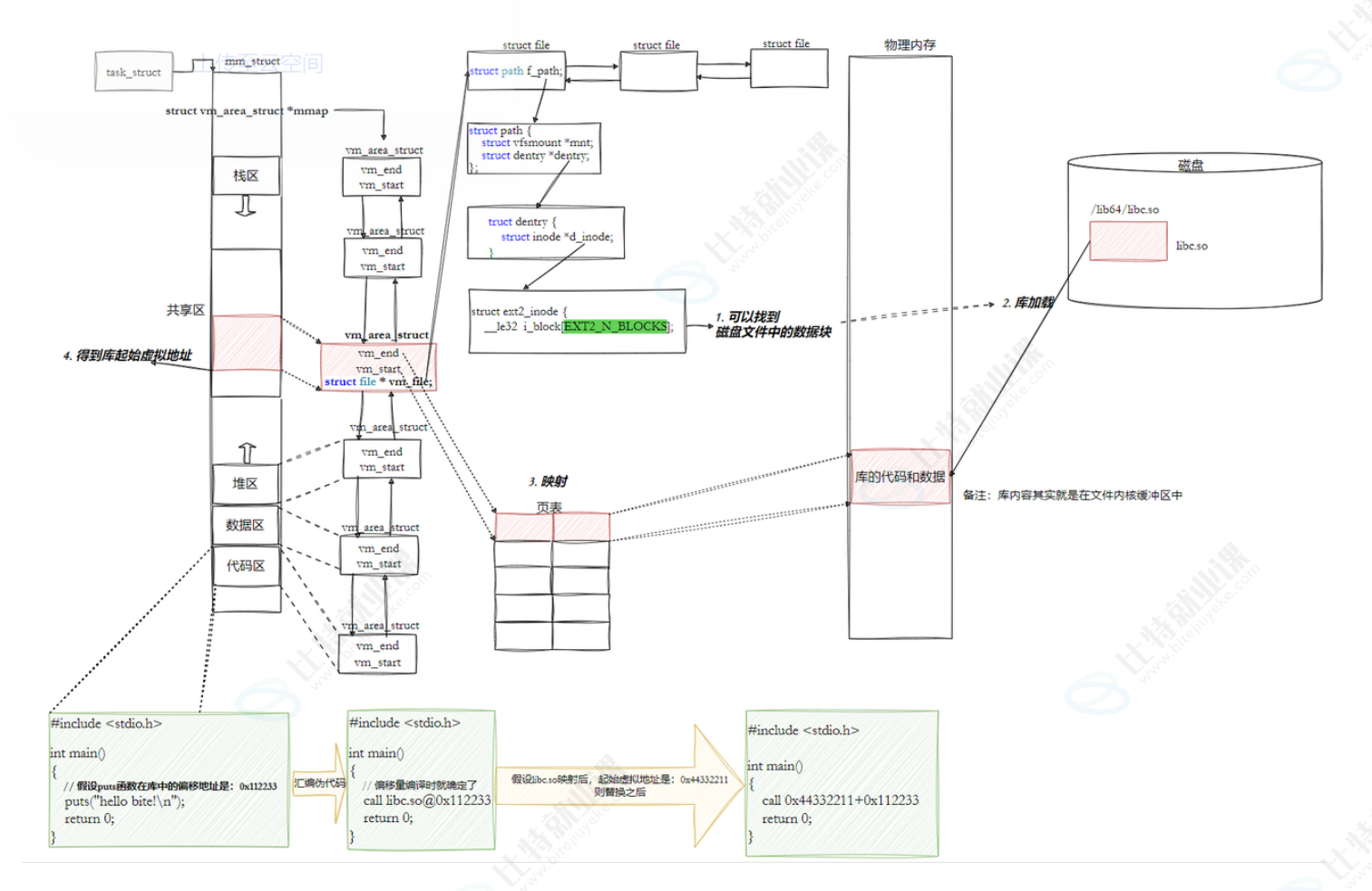
对于汇编时的call指令会先记录该函数的偏移量,然后在动态库加载完后在对call指令处的地址修改为起始地址+偏移量。也就是说在_start(有一步是加载动态链接的)运行完之前,我们的程序是不知道库函数在mm_struct的哪里的,只知道偏移量,只有库加载到mm_struct,对地址进行更新时才能实现跳转。这种对地址进行了二次修改的操作也是地址重定向。
但是如果直接对代码区的代码进行修改是不可能的因为代码区的数据只支持读。
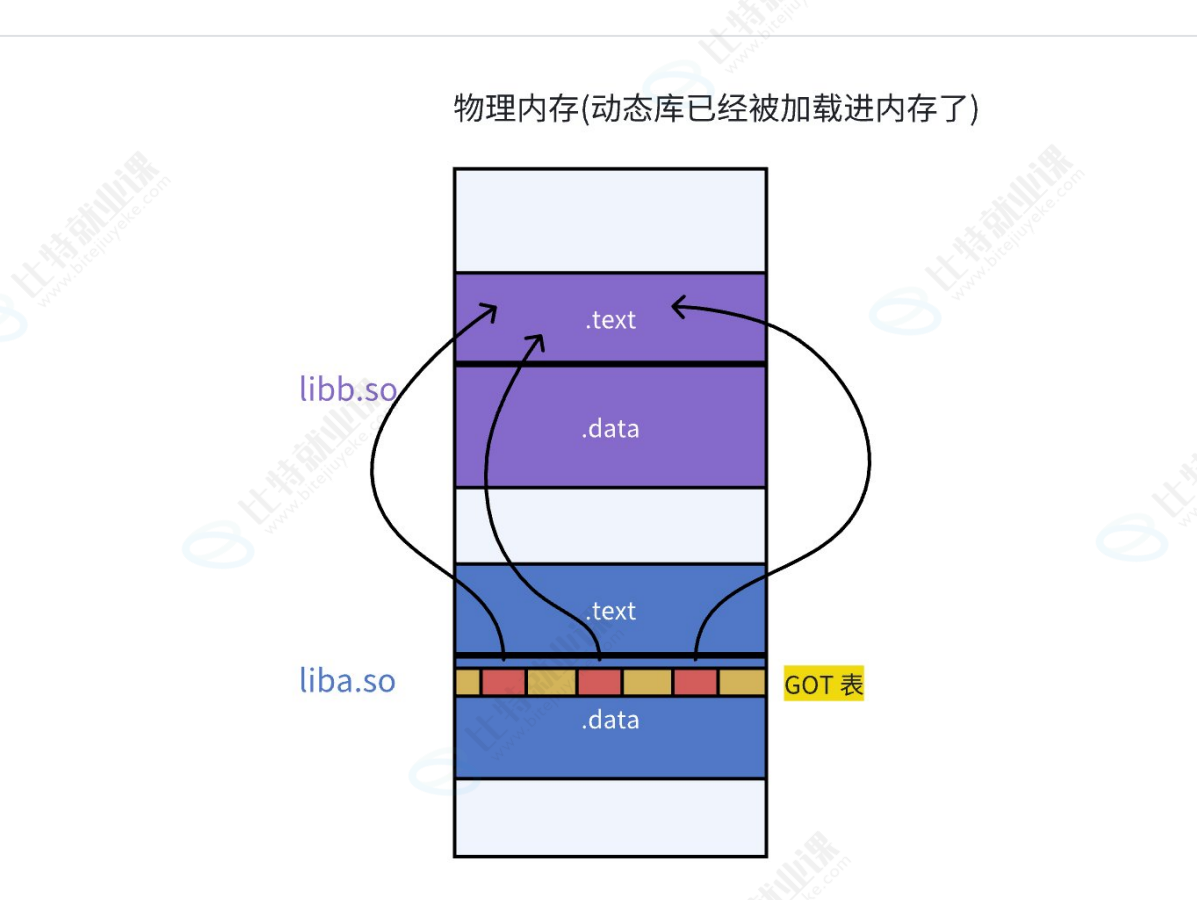
其实call指向的地址实际是存在.data区中的一个数组(GOT)中的,说白了代码区中call指向的其实是GOT的其实地址+对应函数在GOT表中偏移量(这个偏移量是固定的,在动态库加载时更新,这里的总和值与GOT中的函数位置是一一对应的)
因此地址重定位的操作就是在GOT中进行的:所有动态库的函数地址都是存在GOT表中的,然后call指向的是GOT对应方法所在的地址,最后库加载进来更新GOT的数据后,call指令就能通过GOT间接跳转到动态库的方法中了。
每一个进程都有一个独立的GOT,不同进程的GOT通过页表映射就可以指向同一个动态库的地址从而实现动态库数据的共享。
这种动态链接的方式叫PIC地址无关代码(采用相对编址的意思),也就是找动态库的方式为:PIC=相对编址(起始虚拟地址+偏移量)+GOT.
3.PIT是什么
ubuntu@VM-0-2-ubuntu:~/test$ objdump -d test
//..
1122: e8 19 ff ff ff call 1040 <__cxa_finalize@plt>
1127: e8 64 ff ff ff call 1090 <deregister_tm_clones>
//..
1160: e8 eb fe ff ff call 1050 <printf@plt>
//...发现实际观察反汇编call调用的并不是got,而是plt,那么plt是什么呢?
上面的解释其实已经算完善了,但还要补充。
(无关)路径依赖:库之间也是有依赖的,库也会调用其他库,也就是说库也是有自己的GOT的。
当大量函数地址进行函数重定位时效率会特别低,此时就有一个优化方案PLT,就是该函数第一次调用时才会进行函数重定位。
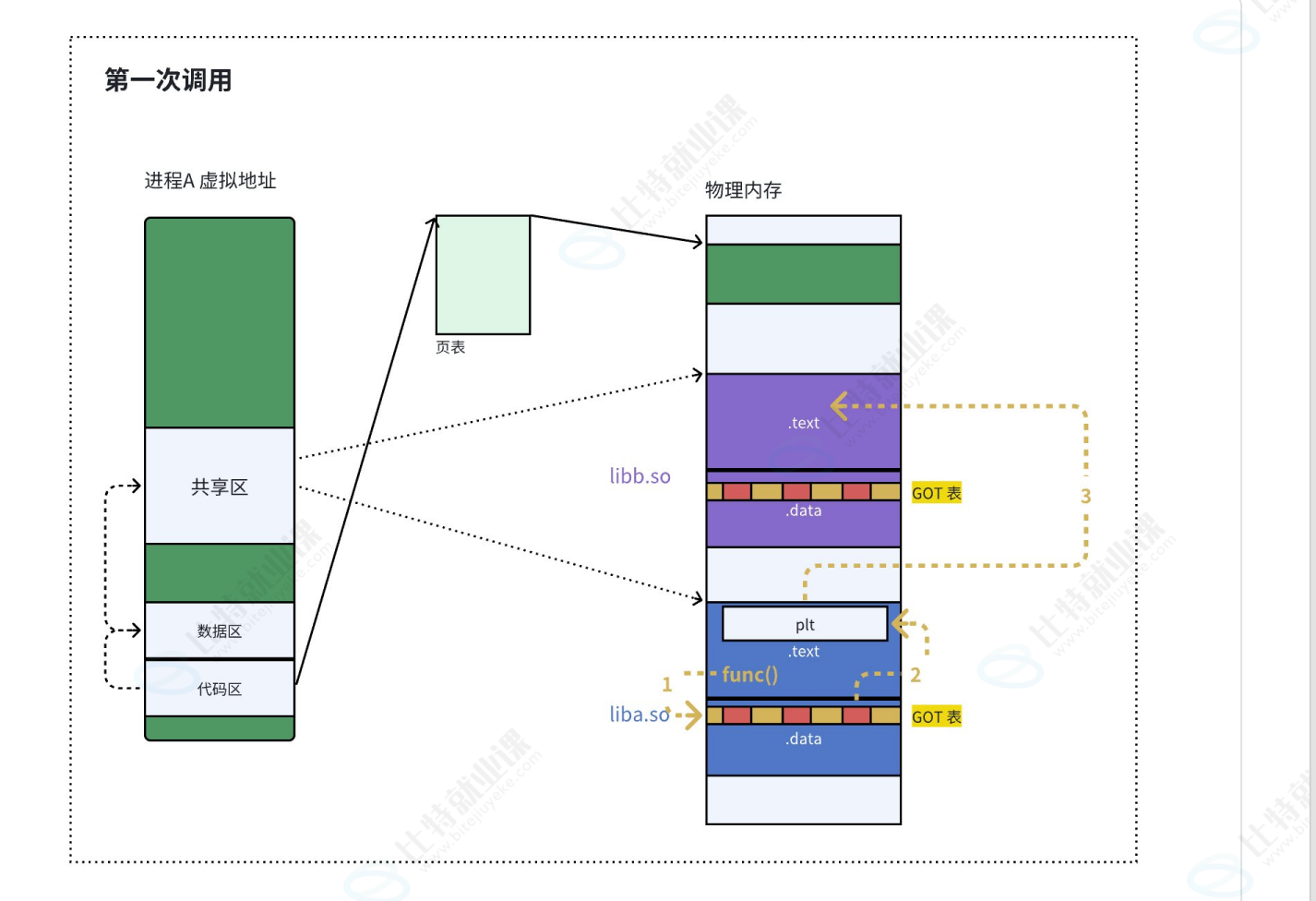
虽然GOT和call指令之间的映射关系依旧正常,但在call没有调用对应函数时,GOT中其实存的是一段指向plt(存在代码区,是一段柱代码),只有当调用库函数时,GOT才会通过这段柱代码去找到真正的对应函数的虚拟地址,然后再存进GOT中,后续用的都是实际的虚拟地址了。
总结库的所有
(1)EIF header最重要的就是记录program header table 和 section header table的位置和_start函数的地址
(2)program header table主要用于加载过程,section header table主要用于记录整个链接过程中所有section的情况
(3)除了EIF header都会进行合并且最后再修改EIF header的情况
(4)静态链接核心为合并加修改call地址
(5).exe加载内存后会有物理地址和虚拟地址填充进页表中形成映射结构
(6)初始化完mm_struct后,CPU找到该进程并拿到起始地址然后用CR3,MMV辅助实现虚拟地址到真实地址的转换
(7)动态库就是将同一段内存空间给多个进程使用,且其采用相对编址的方式,在共享区中的地址=在共享区的起始虚拟地址+偏移量,GOT表存储虚拟地址以便于修改实现地址重定向。
(8)-fPIC的本质就是生成GOT表和使用相对编址方式的声明。