目录
[一、IP 与端口](#一、IP 与端口)
[1. 源 IP 与目的 IP](#1. 源 IP 与目的 IP)
[2. 端口号](#2. 端口号)
[3. 端口号划分](#3. 端口号划分)
[4. Port 与 PID](#4. Port 与 PID)
[5. 源端口与目的端口](#5. 源端口与目的端口)
[1. socket 本质](#1. socket 本质)
[2. 为什么要抽象成文件](#2. 为什么要抽象成文件)
[三、TCP 与 UDP](#三、TCP 与 UDP)
[1. TCP 协议](#1. TCP 协议)
[2. UDP 协议](#2. UDP 协议)
[1. 为什么需要字节序](#1. 为什么需要字节序)
[2. 网络字节序](#2. 网络字节序)
[3. 转换函数](#3. 转换函数)
[五、Socket API](#五、Socket API)
[1. 常见接口](#1. 常见接口)
[六、sockaddr 体系](#六、sockaddr 体系)
[1. sockaddr](#1. sockaddr)
[2. sockaddr_in](#2. sockaddr_in)
[3. sockaddr_un](#3. sockaddr_un)
[4. sockaddr 的多态实现](#4. sockaddr 的多态实现)
[为什么需要 sockaddr?](#为什么需要 sockaddr?)
[1. ping](#1. ping)
[2. netstat](#2. netstat)
[3. pidof](#3. pidof)
一、IP 与端口
经过前几篇博客的铺垫,我们已经理解了数据包如何进行网络传输,并到达目标主机的网卡。但对计算机来说,跨网传输只是前半程,接下来数据必须进入操作系统,精准地投递给某个具体的应用程序
今天我们开始为真正的代码实战做准备,聊聊 Socket 编程的预备知识
1. 源 IP 与目的 IP
在网络上传输的每一个 IP 数据报的头部,都必定包含这两个核心字段。它们由网络层封装
-
源 IP 地址:发送端主机的网卡IP地址。它向接收方表明:这个数据包来自此处,如需回复请发送至该地址
-
目的 IP 地址:接收端主机的网卡IP地址。该地址向沿途所有路由器传递信息:请根据此目标地址为数据包指引传输路径
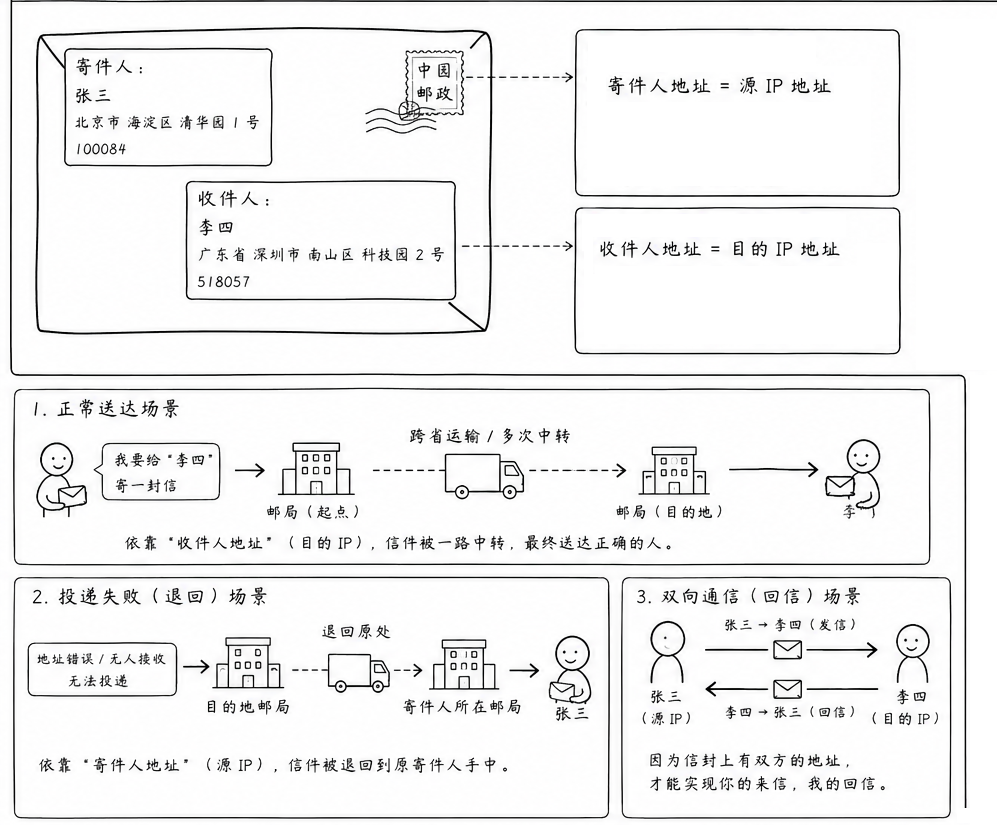
信封上的寄件人与收件人
当你去邮局寄一封挂号信时,信封上必须写明两组地址:
-
收件人地址(目的 IP):邮局的各级分拣中心会根据这个地址,把信件从北京中转到上海,再中转到某个具体的街道
-
寄件人地址(源 IP):如果收件人搬家了(传输失败),或者收件人收到信后想给你写回信,邮局和对方都需要知道信是从哪寄出来的
2. 端口号
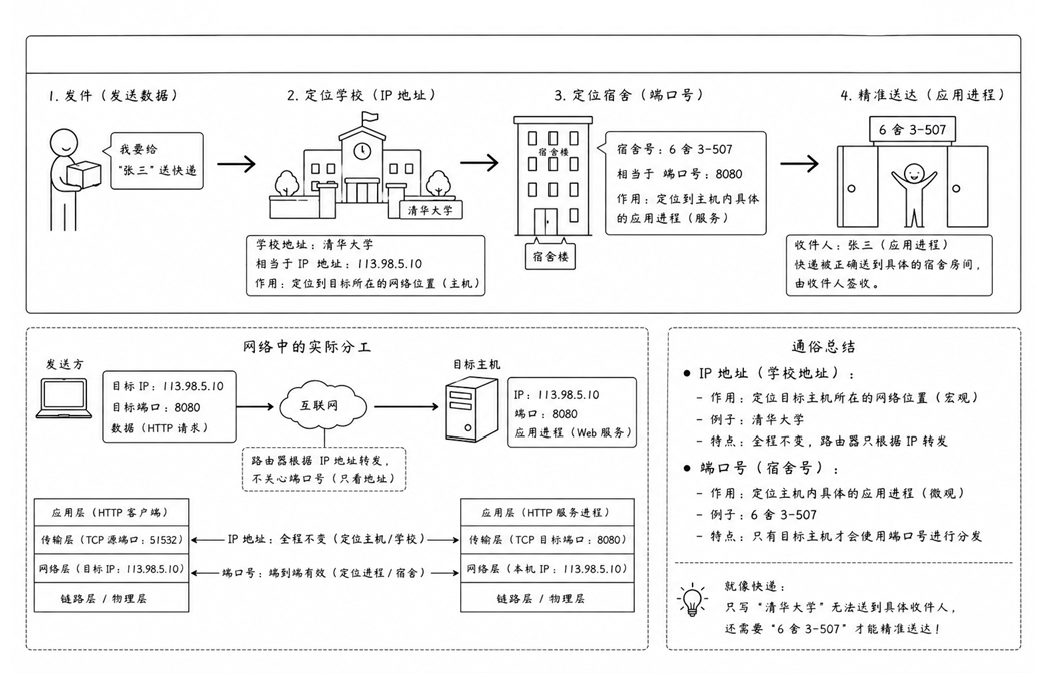
在网络层面上,IP 地址的作用是在全网中唯一标识一台主机
但是,把数据送到主机就结束了吗?并没有。电脑里同时运行着那么多需要联网的程序,操作系统怎么知道网卡刚收到的数据,到底是给 QQ 的,还是给浏览器的?
因此,仅仅定位到主机是不够的,我们必须定位到主机上的具体进程
为了解决 "数据该给哪个程序" 的问题,网络协议栈引入了端口号的概念
-
定义 :端口号是一个 16 位的整数 (2 字节),它的取值范围是 0 ~ 65535
-
核心作用 :在同一台主机中,端口号用来唯一标识一个需要进行网络通信的进程
IP 地址 + 端口号,就能够唯一标识全互联网范围内的某一个进程
IP 地址可以比做学校地址 (定位到宏观位置),而端口号就是你的宿舍号(定位到微观个体)。快递员光把包裹送到学校大门口还不行,必须根据宿舍号才能把快递精准送到你手上
3. 端口号划分
计算机系统中这 65536 个端口号并非随意分配,而是遵循严格的分类标准进行划分:
-
知名端口号:0 ~ 1023
-
这些端口已经被一些全球主流的、经典的底层应用占用了
-
比如:SSH 远程登录服务占用 22 端口,HTTP 网页服务占用 80 端口,HTTPS 占用 443 端口
-
Linux 系统安全规定 :如果你的程序想要绑定(bind) 0 ~ 1023 之间的端口,必须拥有 root 权限
-
-
动态端口号:1024 ~ 65535
-
这是留给普通应用程序和客户端的自由端口
-
当你写一个网络服务器时,通常会选择在这个范围里挑一个数字(比如经典的 8080、9090)。当你作为客户端去访问别人时,操作系统也会在这个范围里为你随机分配一个空闲端口
-
4. Port 与 PID
很多刚接触系统编程的同学会产生严重的逻辑混淆:"Linux 内核里不是已经有 PID 专门用来标识进程了吗?为什么网络通信还要多搞出一套 Port 来标识进程?它们有啥区别?"
这背后隐藏着极其精妙的高内聚、低耦合的设计哲学:
-
分工不同 :PID 是 操作系统管理层 的概念,负责标识本地的所有进程;而 Port 是 网络通信层 的概念,只负责标识需要跟外界网络打交道的进程
-
解耦需求:如果网络层直接使用 PID,那么一旦 Linux 操作系统修改了 PID 的生成规则(比如从递增改成随机),整个网络协议栈的代码全部得跟着大改。引入 Port 作为一个抽象层,可以让操作系统和网络解耦
-
确定性 :进程每次重启,系统分配给它的 PID 大率会发生改变。但对于服务器来说,它的网络入口必须是雷打不动的。例如 Nginx 服务器每次重启 PID 都在变,但它永远死守 80 端口,这样全世界的浏览器才能随时找到它
映射关系 :一个端口号在同一时间内只能被一个进程绑定 ;但一个进程可以同时绑定多个不同的端口号(比如一个程序既想提供网页服务,又想提供文件传输服务)
5. 源端口与目的端口
当我们抓取网络上传输的传输层报文时,会发现每一个报头的最前面,雷打不动地放着两个字段:源端口号 和目的端口号
-
源端口号:发送方进程的端口。通常是客户端操作系统随机分配的
-
目的端口号:接收方进程的端口。通常是服务器固定的知名端口(如 80 或 443)
结合网络层的 IP 地址,这四个元素共同构成了网络通信中的四元组:
(源 IP,源端口,目的 IP,目的端口)
无论是 TCP 建立连接还是操作系统分发数据包,都是靠这四个核心要素来精准识别一条唯一的通信链路
二、Socket
我们知道要找全互联网范围内的某一个进程,必须依靠 IP 地址 + 端口号
在日常技术交流中,我们经常把这个组合统称为套接字 (Socket) 。它的英文本意其实非常接地气------就是插座或接线孔
当两台机器要通信时,就好像在它们之间连了一根无形的电话线,而两端各自插着一个 "插座",这个插座就是 Socket
1. socket 本质
在 Linux 的世界里,Socket 的底层本质究竟是什么?
在 Linux "一切皆文件" 的哲学下,Socket 就是一个文件描述符(fd)
(1) 系统是如何创建 Socket 的
当你在代码中调用系统接口:
cpp
int sockfd = socket(AF_INET, SOCK_STREAM, 0);这个函数一旦执行成功,内核就会在当前进程的文件描述符表中,占位并返回一个小的正整数(比如 3 或 4)。这个整数就是 sockfd
(2) 内核动作
普通的 fd 指向的是磁盘上的数据块;而 Socket fd 指向的则是操作系统的网络驱动与网卡资源
当你获得一个 Socket fd 时,Linux 内核已经在幕后为你创建了一套复杂的结构,其中最核心的是两个缓冲区:
-
发送缓冲区 (Send Buffer):你写给网络的数据先存在这里,由内核伺机发往网卡
-
接收缓冲区 (Receive Buffer):网卡收到的网络数据先缓存在这里,等着你来读取
2. 为什么要抽象成文件
Linux 这种把网络接口硬塞进"文件接口"的设计,堪称计算机史上的神来之笔。它带来了巨大的好处:
(1) 统一接口使用
因为 Socket 变成了 fd,所以操作网络和操作普通的硬盘文件、打印机、甚至终端屏幕,用的是完全同一套系统调用!
-
往普通的文本文件写数据:write(fd, buf, len)
-
往千里之外的服务器发送网络数据:write(sockfd, buf, len)
不需要为网络通信专门学习一套操作命令,Linux 把底层的协议栈封装得像读写普通文件一样简单自然
(2) 进程级管理
既然是 fd,它就完美融入了操作系统的进程管理体系
- 当进程异常崩溃退出了,操作系统会自动回收该进程打开的所有 fd。这意味着,你的网络连接(Socket)也会被系统自动关闭,绝不会造成网络资源的永久泄漏
三、TCP 与 UDP
获取操作系统分配的 Socket 文件描述符后,在编写通信代码前,我们需要做出选择:使用 TCP 协议还是 UDP 协议?
这两种传输层协议的特性截然不同。选择不同的协议将直接影响 Socket fd 的读写行为
1. TCP 协议
TCP 是整个互联网赖以生存的基石。以稳重可靠著称
(1) 面向连接
-
逻辑:就像打长途电话一样。你在说话之前,必须先拨号,等对方接听确认,才能开始聊正事
-
技术体现:在代码层面,TCP 必须通过三次握手建立一条虚拟的双向通道。通道建立成功后,Socket 才能开始传输数据
(2) 可靠传输
-
逻辑 :TCP 协议确保数据的可靠传输,提供无差错、不丢失且顺序正确的数据交付
-
技术机制:为了实现这个特性,内核做了极其复杂的控制:
-
确认应答:每发一个包,对方必须回一个 "收到" 的信号
-
超时重传:如果发出去的包没有应答,TCP 会自动重新发送,直到对方收到
-
流量 / 拥塞控制:根据网络状况和接收方处理能力,智能调节传输速率,避免强行发送
-
(3) 面向字节流
-
核心概念:TCP 协议将数据视为连续的数据流,而非离散的数据包或消息
-
代码行为 :调用 write 写入了 1000 个字节,这 1000 字节就像水流一样流进了内核的发送缓冲区。至于对方是一次性 read 读完,还是分 10 次每次读 100 字节,TCP 协议并不关心
由于数据像水流一样混在一起没有界限,这就会导致应用层不得不去处理所谓的粘包问题(需要我们人为在应用层协议里划分边界)
2. UDP 协议
与 TCP 不同,UDP 追求的是极致的传输速度
(1) 无连接
-
逻辑:就像寄明信片或者发短信。我不需要管你在不在家,也不需要先确认你的状态,只要把目标的 IP 和端口贴在数据包上,直接发送到网卡即可完成任务
-
技术体现:UDP 无需握手即可直接发送数据,具有极低的传输开销
(2) 不可靠传输
-
逻辑 :UDP 只管发,不管结果。数据包在路上有没有被路由器丢弃?有没有因为网络抖动导致后发的包先到了?UDP并不关心,也不提供任何重传机制
-
现实定位:UDP 并非 "劣质协议"。在直播、网络游戏、视频会议等场景下,偶尔丢掉一两个像素点或者一帧语音根本无伤大雅,但如果因为 TCP 的超时重传导致画面卡顿几秒,那是绝对无法接受的
(3) 面向数据报
-
核心概念:UDP 协议具有鲜明的数据边界。其传输的数据如同一个个封装完整的快递包裹
-
代码行为 :应用层调用发送了一个 500 字节的包,对方就必须一次把这 500 字节作为一个完整的整体读出来。数据绝不会和上一个包或下一个包混在一起,天然不存在粘包问题
四、网络字节序
确定使用 TCP 或 UDP 协议后,当我们向 Socket 文件描述符写入整数数据时,计算机底层隐藏着一个极易被忽视的差异,这个隐患随时可能带来严重后果
这就是网络编程中无法回避的经典难题------字节序
1. 为什么需要字节序
在计算机中,我们常用的 int 类型占 4 个字节 ,short 类型占 2 个字节 。这就带来了一个问题:当你把一个多字节的数据放入内存时,这几个字节该按什么顺序排?
这就引出了计算机科学中著名的大端与小端的概念:
假设我们有一个 16 进制的四字节整数:0x12345678
-
这个数字的高位字节是 12,低位字节是 78
-
我们要把它存入起始地址为 0x1000 的内存中
(1) 小端模式
-
规则 :低位字节存放在内存的低地址端,高位字节存放在高地址端。简称 "低对低"
-
内存布局:
-
0x1000 -> 78 (低位)
-
0x1001 -> 56
-
0x1002 -> 34
-
0x1003 -> 12 (高位)
-
-
目前使用最多的 x86 / x64 架构的 CPU,底层统一为小端模式
(2) 大端模式
-
规则:高位字节存放在内存的低地址端,低位字节存放在高地址端。这非常符合我们人类从左到右的阅读习惯
-
内存布局:
-
0x1000 -> 12 (高位)
-
0x1001 -> 34
-
0x1002 -> 56
-
0x1003 -> 78 (低位)
-
-
某些特定架构的处理器或特定的网络设备会采用大端模式
(3) 异构系统通信
如果不联网,大家还能相安无事。可一旦联网,不同的机器就被连在了一起
-
场景 :一台小端模式的 PC(发送方)想给一台大端模式的服务器(接收方)发送整数 1
(16进制表示为 0x00000001)
-
发送方:因为是小端,内存里按字节排是 01 00 00 00
-
网线传输:网卡按照内存里的字节顺序 01, 00, 00, 00 挨个发到网上
-
接收方:大端服务器收到这四个字节,按顺序塞进自己的内存 01 00 00 00
-
大端服务器的 CPU 读取这个整数时,认为先看到的 01 是高位!它解析出来的数字变成了 0x01000000,也就是十进制的 16777216
总结 :我明明发了个数字 1,收到后却变成了 一千六百多万
2. 网络字节序
为了彻底终结这场 "大小端战争",TCP/IP 协议栈制定了一条铁律:
互联网上传输的多字节数据,统一使用大端模式
在网络编程中,大端字节序 也被直接称为网络字节序 。而本地机器本身的字节序(不管是大端还是小端),都被称为主机字节序
-
发送数据前 :不管本地 CPU 是什么模式,只要你打算通过网络发送一个多字节的整数(比如 IP 或端口),你必须先把它从 主机字节序 转换为 网络字节序
-
接收数据后 :刚从 Socket 读出来的多字节网络数据,必须先把它从 网络字节序 转换回你的 主机字节序,然后你的 CPU 才能正确读取
3. 转换函数
Linux 操作系统已经为我们准备好了转换接口。这些接口的名字本质就是一串缩写:
-
h 代表 host(主机字节序)
-
n 代表 network(网络字节序)
-
to 代表 转换到
-
s 代表 short(16位整数,通常用于转换端口号)
-
l 代表 long(32位整数,通常用于转换 IP 地址)
在 C 语言中,只需要包含 <arpa/inet.h> 头文件,就可以直接调用以下四个转换函数:
cpp
#include <arpa/inet.h>
// 1. 主机字节序 -> 网络字节序 (常用于服务器端口绑定或客户端连接)
uint16_t htons(uint16_t hostshort); // host to network short (16位)
uint32_t htonl(uint32_t hostlong); // host to network long (32位)
// 2. 网络字节序 -> 主机字节序 (常用于从网络抓出数据并解析)
uint16_t ntohs(uint16_t netshort); // network to host short (16位)
uint32_t ntohl(uint32_t netlong); // network to host long (32位)如果检测到当前系统本身就是大端(和网络序一致),这些函数在编译或运行时就会自动变成空操作,直接把原数字返回,不会带来任何额外的性能开销
字节序只针对多字节的数值型数据。如果传一个字符串(如 "hello"),由于字符串在内存中天然就是按字符顺序一个字节一个字节排列的,不存在大小端问题,所以不需要、也绝不能调用这些转换函数
五、Socket API
在进行 Linux 网络编程时,操作系统通过一组标准的系统调用向应用层暴露网络协议栈的功能。在深入完整的网络通信流程之前,我们需要首先熟悉几个最核心的 Socket API 接口的定义与作用
1. 常见接口
(1) socket:创建套接字
cpp
int socket(int domain, int type, int protocol);
核心参数:
- domain:指定协议族。常用的有 AF_INET(IPv4)和 AF_UNIX / AF_LOCAL(本地进程通信)
- type:通信语义类型。常用的有 SOCK_STREAM(面向字节流,即 TCP)和
SOCK_DGRAM(面向数据报,即 UDP)
- protocol:指定具体的协议类型,传入 0 即可,系统会根据前两个参数自动匹配默认协议
返回值:
成功时返回一个新的文件描述符(Socket fd),失败时返回 -1(2) bind:绑定本地地址
用于将一个已经创建的 Socket 文件描述符与特定的本地网络地址(包括本地 IP 地址和端口号)进行关联
cpp
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
核心参数:
- sockfd:由 socket 函数返回的文件描述符
- addr:指向包含本地 IP 和端口信息的通用地址结构体的指针
- addrlen:传入的地址结构体的实际内存大小
返回值:成功返回 0,失败返回 -1。服务器程序通常必须调用此接口以固定自身的监听端口(3) connect:发起连接
connect 函数主要由客户端程序调用,用于向远程服务器发起连接请求
cpp
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
核心参数:
- sockfd:客户端本地的 Socket 文件描述符
- addr:指向目标服务器网络地址(IP 和端口)结构体的指针
- addrlen:目标地址结构体的内存大小
返回值:
成功返回 0,失败返回 -1(4) sendto:发送数据
sendto 函数通常在无连接的协议(如 UDP)中使用,由于没有建立长期的连接状态,每次发送数据时都必须显式指定接收方的网络地址
cpp
ssize_t sendto(int sockfd, const void *buf, size_t len, int flags,
const struct sockaddr *dest_addr, socklen_t addrlen);
核心参数:
- buf:指向待发送数据缓冲区的指针
- len:待发送数据的字节数
- flags:传输控制标志,通常传入 0 表示常规行为
- dest_addr:指向接收方网络地址结构体的指针
- addrlen:接收方地址结构体的内存大小
返回值:
成功时返回实际发送的字节数,失败时返回 -1(5) recvfrom:接收数据
recvfrom 函数同样多用于 UDP 协议,它在接收网络数据的同时,还可以捕获发送方的网络地址,以便后续进行数据回传
cpp
ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags,
struct sockaddr *src_addr, socklen_t *addrlen);
核心参数:
- buf:指向用于接收数据的本地缓冲区的指针
- len:缓冲区能够容纳的最大字节数
- src_addr:一个输出型参数,指向用于保存发送方网络地址信息的结构体
- addrlen:一个输入输出型参数,传入时为结构体大小,传出时为发送方地址信息的实际有效大小
返回值:成功时返回实际接收到的字节数,若连接断开返回 0,失败返回 -1六、sockaddr 体系
sockaddr 体系是套接字编程中用于表示网络地址的核心数据结构体系,主要包含以下关键结构:
1. sockaddr
struct sockaddr 是所有 Socket 网络接口函数的标准参数类型。定义在 <sys/socket.h> 头文件中,其典型结构如下:
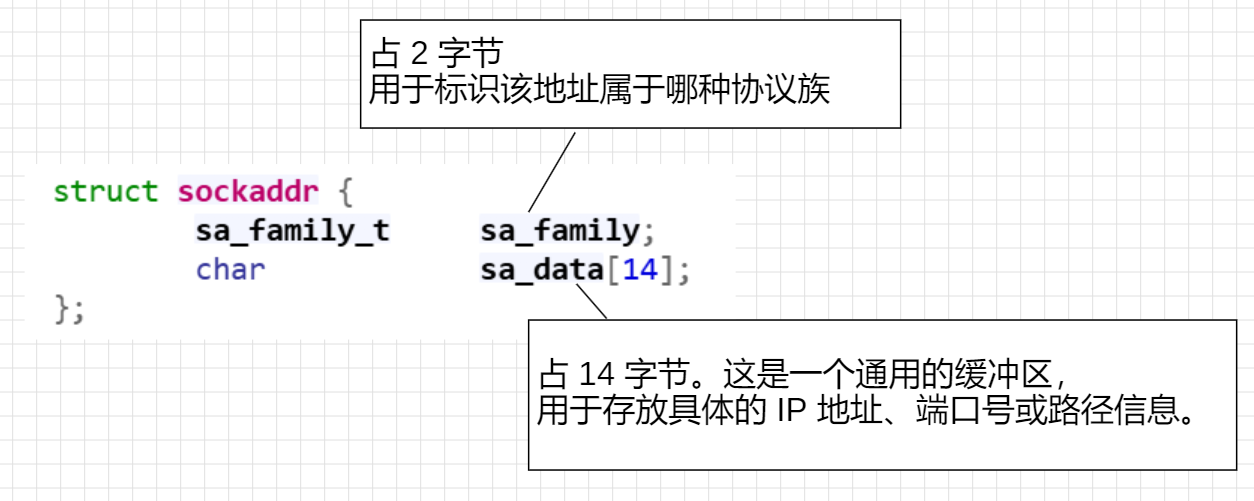
由于 sa_data 将 IP 和端口等关键信息混杂在了一个字符数组中,直接对其进行赋值和修改非常繁琐且易错。因此,在实际开发中,我们几乎从不直接定义和填充 struct sockaddr 变量,它仅作为系统调用接口的参数类型声明
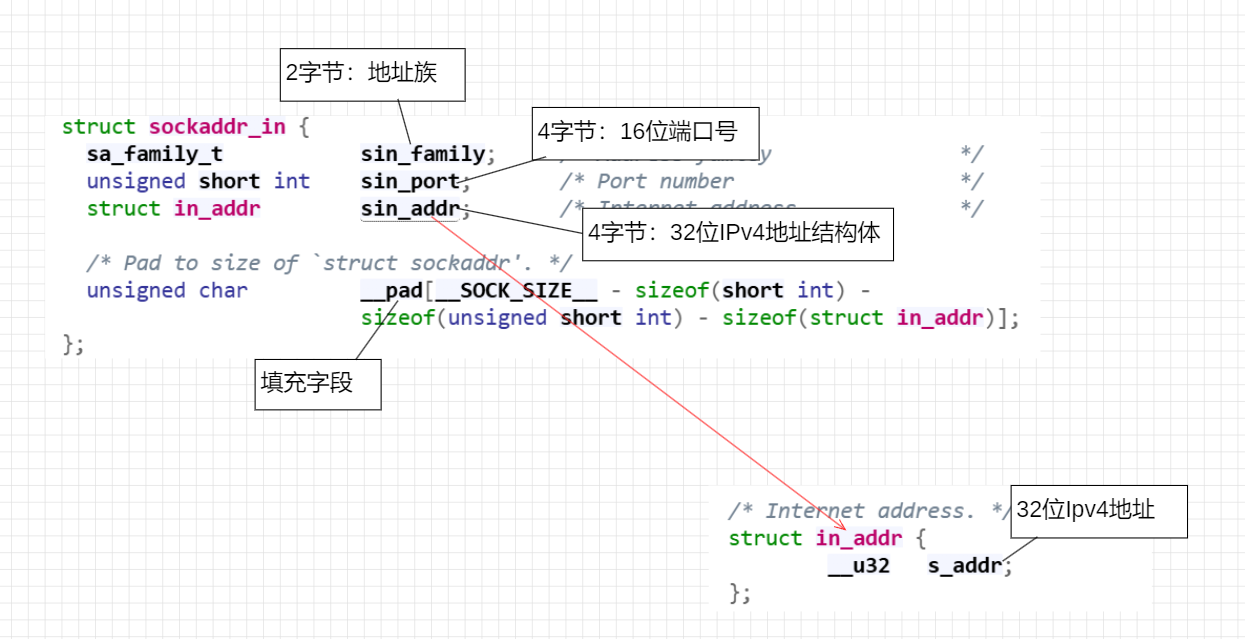
2. sockaddr_in
针对 IPv4 网络通信,系统提供了专门的结构体 struct sockaddr_in(定义在 <netinet/in.h>)。它的总大小同样为 16 字节,能够与 struct sockaddr 在内存布局上完美对齐
3. sockaddr_un
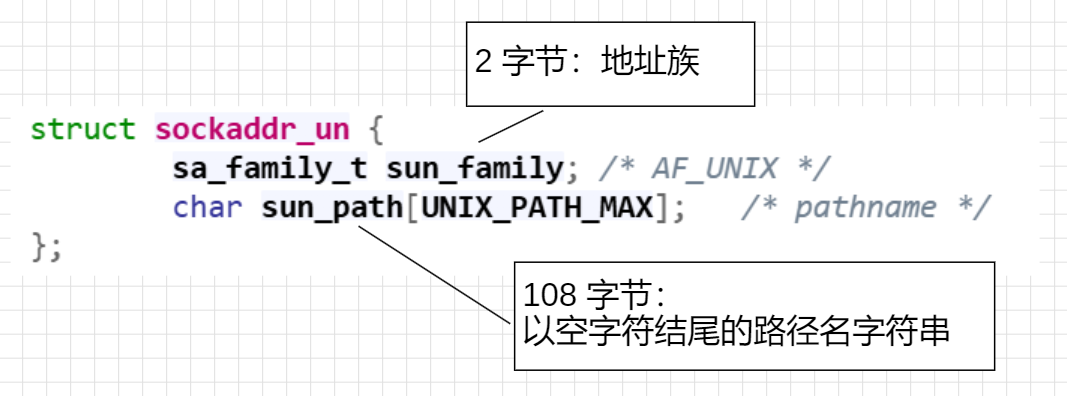
针对本地进程通信,系统提供了 struct sockaddr_un 结构体(定义在 <sys/un.h>)。它用于在本地文件系统中创建套接字文件
4. sockaddr 的多态实现
C 语言本身是一门面向过程的编程语言,并没有原生的类、继承和多态等面向对象特性。然而,在 Linux 内核及 Socket API 的设计中,工程师们利用 C 语言的结构体内存布局特性,精妙地模拟了面向对象中的多态机制
为什么需要 sockaddr?
Socket API 是一套通用的网络编程接口,它的设计目标是同时支持多种不同的网络底层协议和通信域。例如:
-
基于 IPv4 的网络通信(AF_INET)
-
基于 IPv6 的网络通信(AF_INET6)
-
基于本地域的进程间通信(AF_UNIX / AF_LOCAL)
这些不同的通信域,其所需要的地址信息格式完全不同。IPv4 需要 32 位 IP 地址和 16 位端口号;IPv6 需要 128 位 IP 地址和 16 位端口号;而 Unix 域套接字需要的则是一个路径字符串
如果为每一种网络协议都设计一套独立的系统调用接口(例如设计 bind_ipv4()、bind_ipv6()、bind_unix()),会导致 API 数量急剧膨胀,且无法做到协议无关性
为了解决这一矛盾,在设计时引入了类似于面向对象编程中的 "基类与派生类" 的思想:
-
设计一个通用的地址结构体 struct sockaddr 作为接口的统一参数类型(相当于面向对象中的抽象基类)
-
针对不同的通信协议,设计专门的结构体 (如 sockaddr_in、sockaddr_un)来实际存放地址数据(相当于具体的派生类)
-
在调用接口时进行类型擦除与重构:在调用 bind、connect 等接口时,将具体协议的结构体指针强制类型转换为通用结构体指针 struct sockaddr* 传入,并通过一个额外的参数告知内核该结构体的实际长度
多态的底层
C 语言能够成功模拟多态,完全依赖于结构体内存布局的确定性
在 C 语言中,结构体内部成员的排列顺序与代码声明的顺序严格一致,且结构体的起始地址与其第一个成员的起始地址完全相同
(1) 统一的 "虚函数表/类型标识"
如果我们对比通用基类与各个派生类的头部定义,会发现一个关键特征:
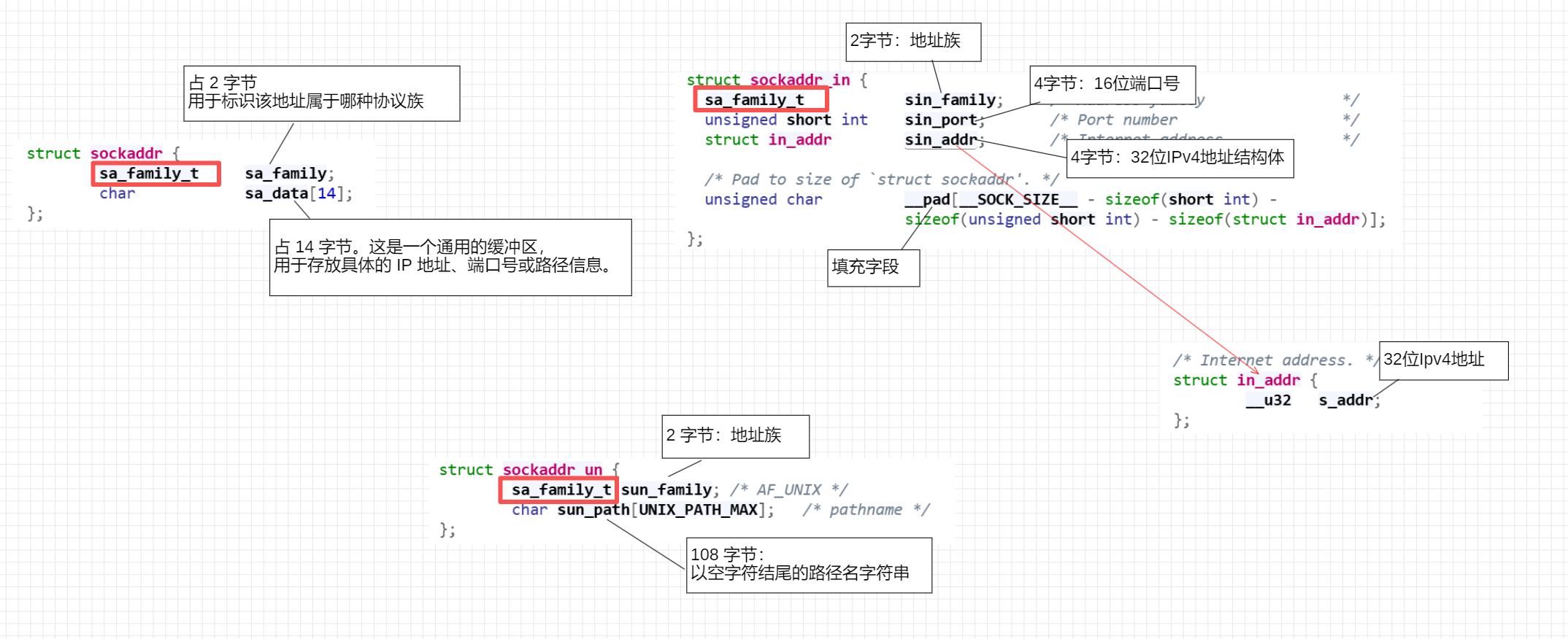
无论哪一个具体协议的地址结构体,其前 2 个字节永远是 sa_family_t 类型的协议族标识符。这就相当于面向对象编程中用于识别对象真实类型的标签
(2) 内核中的向下转型
当应用层代码将 struct sockaddr_in 的指针强制类型转换为 struct sockaddr* 并传递给内核系统调用时,内核的具体处理逻辑如下:
cpp
// 模拟内核内部处理伪代码
int sys_bind(int fd, const struct sockaddr *addr, int addrlen) {
// 1. 首先通过基类指针读取前 2 字节,识别出真实的"派生类"类型
switch (addr->sa_family) {
case AF_INET: {
// 2. 确认是 IPv4 类型,安全地向下转型 (Downcast)
struct sockaddr_in *addr_ipv4 = (struct sockaddr_in *)addr;
// 3. 调用 IPv4 协议栈专有的处理逻辑
return ipv4_bind(fd, addr_ipv4);
}
case AF_UNIX: {
// 2. 确认是 Unix 域类型,向下转型
struct sockaddr_un *addr_unix = (struct sockaddr_un *)addr;
// 3. 调用 Unix 域专有的处理逻辑
return unix_bind(fd, addr_unix);
}
default:
return -EINVAL; // 不支持的协议类型
}
}为什么必须传递 addrlen 参数?
C 语言的指针仅仅是一个内存地址,当它被强转为 struct sockaddr* 后,内核如果只看指针类型,会认为该内存区域只有 16 字节大小
对于大小为 16 字节的 sockaddr_in 而言,这不会引发问题;但对于大小高达 110 字节的 sockaddr_un,一旦内核直接按照 16 字节进行内存拷贝,就会导致严重的数据截断 ;反之,若内核盲目读取过多字节,又会引发内存越界访问
因此,addrlen 参数在 C 语言多态体系中扮演了显式大小边界指针 的角色。它显式地告诉内核:当前传入的 "派生类对象" 在内存中实际占用了多少个字节。内核据此分配准确的内存空间并完成数据拷贝,从而确保了多态行为的安全性
七、常用网络命令
在进行 Socket 编程和部署时,我们编写的网络程序运行在后台,很难直接观察到数据的流动或状态。为了高效地调试网络程序,Linux 系统提供了一系列强大的命令行工具
下面介绍三个在开发网络应用程序时最常用、最基础的网络调试与查看命令
1. ping
ping 命令是网络诊断中最著名的工具,用于测试本地主机与目标主机之间的网络是否连通,以及评估网络延迟
底层原理 :ping 不属于 TCP 或 UDP 协议 ,它基于网络层的 ICMP 协议。它通过向目标主机发送 ICMP 回显请求文,并等待接收回显应答来判断对方是否在线
bash
# 测试与目标主机的连通性(Linux 下会持续发送,可使用 Ctrl+C 终止)
ping www.baidu.com
# 限制发送数据包的次数为 4 次
ping -c 4 114.114.114.114输出关键信息:
-
ttl(Time to Live):生存时间,每经过一个路由器该值减 1,可大致推断中转路由器的数量
-
time(RTT,往返时间):数据包从发出到收到回复所消耗的时间,单位为毫秒,该值越小说明网络延迟越低
2. netstat
netstat 是一个极其重要的网络连接监控工具。在 Socket 编程中,我们经常需要确认服务器是否成功启动、是否正确绑定了端口、以及当前有多少个客户端连接了进来,这些都需要通过 netstat 来观察
常用组合参数: 在实际开发中,我们几乎总是使用以下这组固定的参数组合
bash
netstat -ntlp-
-n :直接显示 IP 地址和端口号,不将其解析为主机名或服务名,这可以极大加快命令的执行速度
-
-t (tcp):仅显示 TCP 协议相关的连接或套接字
-
-u (udp):仅显示 UDP 协议相关的连接或套接字(若要同时查看 TCP 和 UDP,可使用 -ntulp)
-
-l (listening):仅显示处于监听状态的服务器套接字
-
-p (programs):显示是哪一个进程在占用该网络连接
典型输出示例解析:
bash
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:8080 0.0.0.0:* LISTEN 12345/./my_server-
Local Address 中的 0.0.0.0:8080 表示该服务器正在本地的所有网卡上监听 8080 端口
-
State 处于 LISTEN,说明服务器已成功启动,正在等待客户端的连接
在较新的 Linux 发行版中,netstat 已经逐渐被更高效的 ss(Socket Statistics)命令所取代(例如使用 ss -ntlp),两者的参数语义基本一致,但 ss 在面对海量连接时拥有更快的查询速度
3. pidof
pidof 是一个系统管理命令,但在网络编程调试中却有着不可替代的辅助作用。它可以通过已知的进程名称,直接找出该进程在当前系统中的进程 PID
**为什么需要它?**当我们编写的网络服务器程序在后台运行,或者因为代码逻辑死锁、端口未释放导致程序僵死时,我们无法直接通过 Ctrl+C 结束它。此时,我们就需要快速获取它的 PID,并将其强行终止,以释放被它占用的端口
常用用法
bash
# 查找名为 nginx 的进程的 PID
pidof nginx总结
综上所述,从 IP 地址与端口号,到 TCP、UDP 与 Socket,再到网络字节序以及 sockaddr 地址体系,我们已经逐步完成了 Socket 编程前最重要的基础铺垫
其中,IP 地址用于定位网络中的主机,端口号用于定位主机中的具体进程,而 Socket 则是操作系统向应用程序提供的一套网络通信接口,本质上是应用层接入 TCP/IP 协议栈的入口。与此同时,通过 sockaddr、sockaddr_in 等结构体的统一设计,我们也进一步体会到了 Linux 网络接口在抽象与兼容性上的设计思想
而进一步思考会发现:
既然已经有了Socket接口,那么应用程序究竟是如何真正通过UDP发送和接收网络数据的?
这正是下一阶段要解决的问题
在下一篇中,我们将正式开始 UDP Socket 编程,真正编写第一个网络通信程序,深入理解 socket、bind、sendto、recvfrom 等核心接口的实际工作流程
