文章目录
- I/O密集型和CPU密集型
- [1个连接1个线程模型 VS 1个I/O事件1个线程模型](#1个连接1个线程模型 VS 1个I/O事件1个线程模型)
- 多线程+轮询非阻塞式I/O
-
- [I/O 多路复用](#I/O 多路复用)
- [Master-Worker 模式](#Master-Worker 模式)
- 轮询的弊端
- [select I/O多路复用](#select I/O多路复用)
- epoll
- [Multi-Reactor 模式](#Multi-Reactor 模式)
- 备注
I/O密集型和CPU密集型
上一篇博文提到了对于阻塞式I/O而言,进程/线程 一直卡在那里不干事也是一种资源浪费。但如果每个进程/线程每时每刻基本都在干事,那就不存在资源浪费的问题有可能效率反而更高,这就引出了当前服务器处理的请求中,这些线程要干的事是I/O密集型还是CPU密集型。
假设上一篇博文中最后的问题,1万个连接都在"真正的干事",那其实此时瓶颈更在于服务器硬件本身,这时可能需要将单一服务器拓展为服务器集群或者增加单一服务器的硬件配置(如:增加CPU的核心数)来使得这1万个连接都能被很快的处理掉,这种场景叫做CPU密集型。典型的如:图片压缩、加密、解密
反之,如果1万个连接,大部分连接建立之后线程把绝大多数时间用在I/O上,仅有几条连接偶尔会有数据传输,这种场景叫做I/O密集型。典型的如:应用服务器等数据库服务器查询结果、上传、下载文件
我们假设的背景是:在I/O密集型请求中,数千条或数万条连接,同一时刻仅有几条连接真正有数据,剩余的连接都在等着数据。
我们基于此背景要解决的问题是:在这个背景下,如何高效的找出真正有数据的连接呢?
1个连接1个线程模型 VS 1个I/O事件1个线程模型
上一篇 博文中使用的阻塞模型代码,其关键在于1个线程被绑定在1个连接上,线程在"等消息"这件事上被占用/阻塞,即使最后使用了线程池,依旧存在很快被耗光的场景。真正有意义的应该是有I/O事件之后,交给线程处理,这样多线程才能发挥作用,所以,应该让线程和I/O事件绑定,线程只在"真正有数据处理"时被占用。
多线程+轮询非阻塞式I/O
那么基于上述关键点,我们写出了第1版代码。首先让连接和线程解耦,通过将连接的文件描述符设置为非阻塞式I/O,可以让进程/线程不阻塞在某个连接上
c
int set_nonblocking(int sockfd)
{
int flags = fcntl(sockfd, F_GETFL);
if (flags == -1)
{
perror("fcntl");
exit(EXIT_FAILURE);
}
flags |= O_NONBLOCK;
if (fcntl(sockfd, F_SETFL, flags) == -1)
{
perror("fcntl");
exit(EXIT_FAILURE);
}
printf("socket is nonblocking I/O now\n");
return 0;
}在非阻塞式I/O模式下,如果当前连接没有I/O事件,read方法不会阻塞而是会直接返回
只有当主进程检测到某个连接有I/O事件了,再把此连接交给线程池,线程池只专注于处理I/O事件以及后面的逻辑,不和连接绑定
主进程是怎么检测某个连接上有I/O事件呢?还是通过read方法,如果read方法返回的是错误码是EAGAIN,那么代表此时该连接上没有I/O事件,如果read方法返回了大于0的数字,说明此连接上有I/O事件,并且主进程已经把I/O部分数据读取到了buffer中,那么此时再交给多线程处理。
伪代码如下
c
// 所有已建立的连接列表
int connections[MAX_CONNECTIONS];
int conn_count = 0;
void main_process() {
int server_fd = create_server_socket();
set_nonblocking(server_fd);
while (1) {
/* ── 1. 建立新连接 ── */
int client_fd = accept(server_fd, NULL, NULL);
if (client_fd > 0) {
set_nonblocking(client_fd);
connections[conn_count++] = client_fd;
}
/* ── 2. 轮询已建立的连接,检测 I/O 事件 ── */
for (int i = 0; i < conn_count; i++) {
int fd = connections[i];
char buffer[BUFFER_SIZE];
ssize_t n = read(fd, buffer, sizeof(buffer));
if (n == -1 && errno == EAGAIN) {
// 该连接上暂无数据,跳过
continue;
}
if (n > 0) {
// 该连接上有 I/O 事件,且主进程已将数据读入 buffer
// 交给线程池异步处理,避免阻塞主进程
task_t *task = create_task(fd, buffer, n);
thread_pool_submit(task);
}
if (n == 0) {
// 对端关闭连接
close(fd);
remove_connection(connections, &conn_count, i);
}
}
}
}到这里就发现问题了,主进程既要负责建立连接,又要轮询已建立的连接以检测这些连接是否有I/O事件,还要读取连接中的I/O数据,这反而比1个连接1个线程模型还要糟糕,因为代码基本回到了串行状态。假如此时如果大量连接请求建立,由于代码是串行,主进程忙着轮询或读取数据(因为检查状态就是通过read来实现的),迟迟无法回到程序的最开端去accept连接
进一步的优化,可以让主进程只负责建立连接;对于轮询,可以使用1个单独的线程,这就防止了主进程不会迟迟不能accept新连接的问题。但是还是无法解决,这个单独的线程轮询过程中可能出现的read读取数据导致连接被串行处理的问题。
更进1步优化,既然1个单独的线程存在瓶颈,我多开几个不就可以了。这的确是个思路。因为我们的背景是数千条连接中,只有少数连接在同一时刻有I/O事件。
到此时服务器端架构就变成了:主进程只负责accept新连接+建立连接后直接通过算法,负载均衡送给4个子线程,这4个子线程分别负责1组已建立连接的轮询+如果检测到I/O就绪,则把任务丢到线程池中,假设为100个,让这100个线程真正处理业务
伪代码如下
c
/* ================================================================
* 架构总览:
* 主进程(1) ──accept──▶ 负载均衡 ──▶ I/O轮询线程(4)
* │
* 检测到I/O就绪
* │
* ▼
* 线程池(100) ── 处理业务
* ================================================================ */
#define IO_THREAD_COUNT 4
#define WORKER_COUNT 100
#define MAX_CONN_PER_IO (MAX_CONNECTIONS / IO_THREAD_COUNT)
/* ── 每个 I/O 轮询线程持有的连接组 ── */
typedef struct {
int fds[MAX_CONN_PER_IO];
int count;
mutex_t lock;
} io_group_t;
io_group_t io_groups[IO_THREAD_COUNT]; // 4 个连接组
thread_pool_t *worker_pool; // 100 个业务线程
/* ================================================================
* 负载均衡:把新连接分配给连接数最少的 I/O 线程(最小连接数算法)
* ================================================================ */
int pick_io_thread() {
int target = 0;
for (int i = 1; i < IO_THREAD_COUNT; i++) {
if (io_groups[i].count < io_groups[target].count)
target = i;
}
return target;
}
/* ================================================================
* I/O 轮询线程(×4):轮询本组连接,检测 I/O 事件,就绪则投递任务
* ================================================================ */
void *io_thread(void *arg) {
io_group_t *group = (io_group_t *)arg;
while (1) {
int io_ready_count = 0; // 记录本轮有多少连接就绪
mutex_lock(&group->lock);
for (int i = 0; i < group->count; i++) {
int fd = group->fds[i];
char buffer[BUFFER_SIZE];
ssize_t n = read(fd, buffer, sizeof(buffer));
if (n == -1 && errno == EAGAIN) {
// 该连接暂无数据,继续轮询下一个
continue;
}
if (n > 0) {
// I/O 就绪:数据已读入 buffer,投递给业务线程池
task_t *task = create_task(fd, buffer, n);
thread_pool_submit(worker_pool, task);
}
if (n == 0) {
// 对端断开,清理连接
close(fd);
remove_fd(group, i);
i--; // 修正下标
}
}
mutex_unlock(&group->lock);
/* ── 关键:本轮没有任何连接就绪,主动休眠,让出 CPU ── */
if (io_ready_count == 0) {
usleep(POLL_INTERVAL_US); // 例如休眠 100~500 微秒
}
}
}
/* ================================================================
* 业务线程池(×100):真正处理业务逻辑
* ================================================================ */
void *worker_thread(void *arg) {
while (1) {
task_t *task = thread_pool_fetch(worker_pool); // 阻塞等待任务
handle_business_logic(task->fd, task->buffer, task->len);
free_task(task);
}
}
/* ================================================================
* 主进程:只负责 accept + 负载均衡分发,不做任何 I/O 轮询
* ================================================================ */
int main() {
int server_fd = create_server_socket();
set_nonblocking(server_fd);
/* 初始化 4 个 I/O 轮询线程 */
for (int i = 0; i < IO_THREAD_COUNT; i++) {
io_groups[i].count = 0;
mutex_init(&io_groups[i].lock);
thread_create(io_thread, &io_groups[i]);
}
/* 初始化 100 个业务线程池 */
worker_pool = thread_pool_init(WORKER_COUNT);
/* 主循环:只管 accept,其余全部甩给子线程 */
while (1) {
int client_fd = accept(server_fd, NULL, NULL);
if (client_fd < 0) continue;
set_nonblocking(client_fd);
// 负载均衡:挑选连接数最少的 I/O 线程
int idx = pick_io_thread();
mutex_lock(&io_groups[idx].lock);
io_groups[idx].fds[io_groups[idx].count++] = client_fd;
mutex_unlock(&io_groups[idx].lock);
}
}整体架构如下
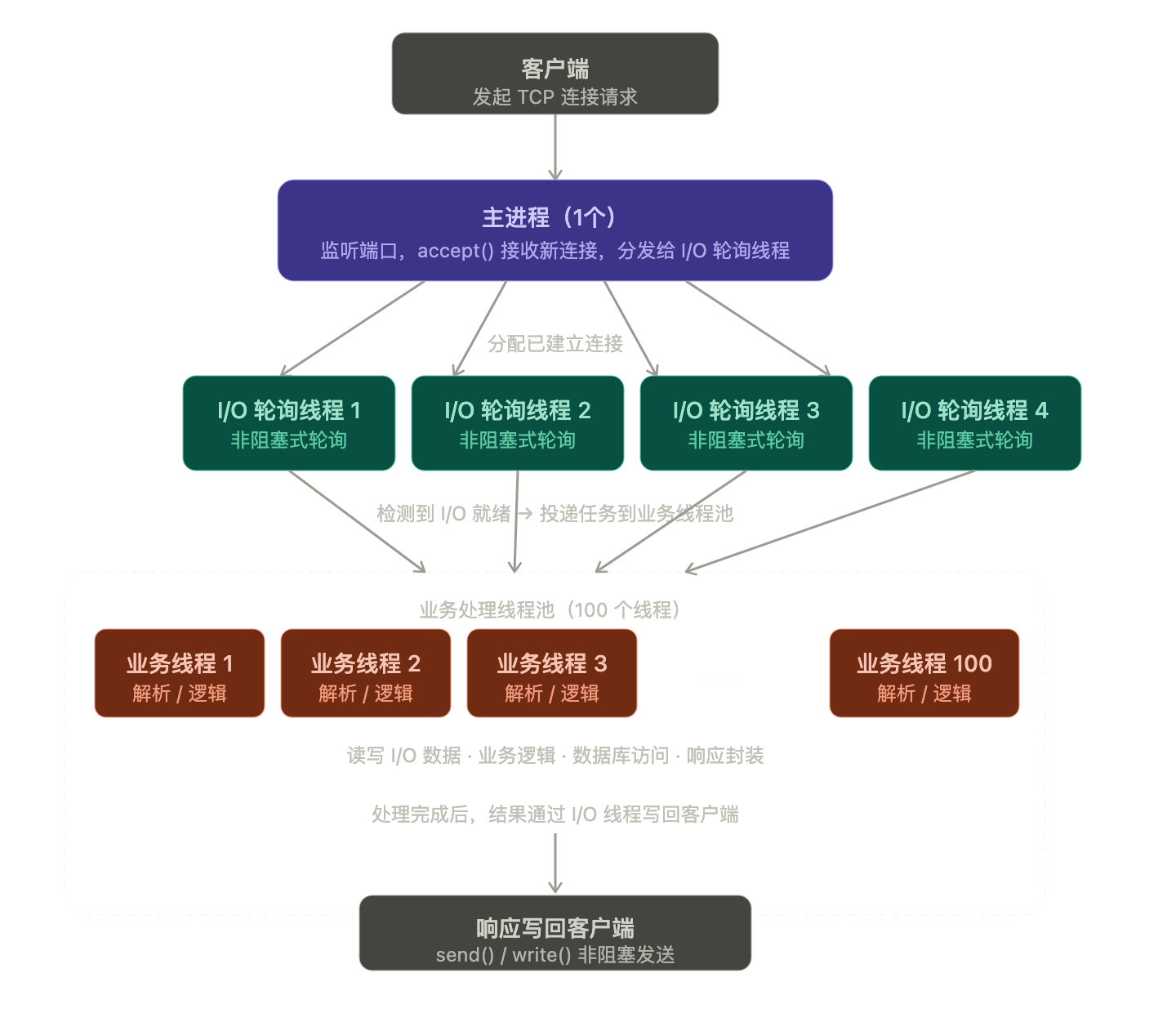
┌─────────────────┬──────────────────────────────────────────────┐
│ 角色 │ 职责 │
├─────────────────┼──────────────────────────────────────────────┤
│ 主进程 (×1) │ accept 新连接,按最小连接数负载均衡分发 │
├─────────────────┼──────────────────────────────────────────────┤
│ I/O轮询线程(×4) │ 轮询本组连接,read 检测就绪,读数据→投递任务 │
├─────────────────┼──────────────────────────────────────────────┤
│ 业务线程池(×100)│ 阻塞等待任务,取到后执行真正的业务逻辑 │
└─────────────────┴──────────────────────────────────────────────┘I/O 多路复用
上述架构中,4个子线程,每个子线程负责检测1批连接。这其实就是I/O多路复用的意思。
官方定义:I/O 多路复用允许我们同时检查多个文件描述符,看其中任意一个是否可执行 I/O 操作
Master-Worker 模式
上述设计将 连接管理、I/O 多路复用、业务处理 三件事完全解耦,I/O 线程少而精(避免大量线程上下文切换),业务线程多(充分利用 CPU 并行处理能力)。这种架构模式叫做Master-Worker 模式。其核心思想是将任务的调度与执行分离,由 Master 负责接收和分发任务,多个 Worker 负责并行处理子任务,从而大幅提升系统吞吐量
轮询的弊端
如果轮询休眠时间过长,则I/O事件不能及时被处理,增加了延迟;如果轮询时间过短,则会一直在无意义循环中,白白浪费CPU
既然用户无法实时知道哪些连接有I/O事件了,那就让内核帮忙做这件事。当连接有I/O事件了,让内核推送给用户程序
select I/O多路复用
select()会一直阻塞,直到一个或多个文件描述符集合成为就绪态
Q : 在轮询非阻塞式I/O时,只能通read方法判断某个文件描述符是否可以进行I/O操作了,那么select是如何知道一个文件描述符已经可以进行I/O操作呢?
A: select() 的就绪判断发生在内核态,它直接检查每个 fd 对应的内核数据结构状态,而不是真的去调用 I/O 函数试探。每种类型的 fd,内核都维护着对应的数据结构,就绪判断就是直接读这些结构的字段。如tcp_poll,pipe_poll
例如:
- socket 可读? → 检查 接收缓冲区 sk_receive_queue 是否非空
- socket 可写? → 检查 发送缓冲区 剩余空间是否足够
- 监听socket? → 检查 accept队列 是否非空
- 管道可读? → 检查 管道缓冲区 是否有数据,或写端是否已关闭
这里以单进程为例简单演示select系统调用的用法
c
/*
FD_ZERO()将fdset所指向的集合初始化为空。
FD_SET()将文件描述符fd添加到由fdset所指向的集合中。
FD_CLR()将文件描述符fd从fdset所指向的集合中移除。
*/
int server_that_can_process_requests_concurrently_using_io_multiplexing_by_select()
{
int server_socket = bind_server_socket_to_port_and_listen();
set_nonblocking(server_socket);
fd_set active_fd_set, read_fd_set;
FD_ZERO(&active_fd_set);
FD_SET(server_socket, &active_fd_set);
int max_fd = 0;
if (server_socket >= max_fd)
{
max_fd = server_socket + 1;
}
while (1)
{
read_fd_set = active_fd_set;
/*
参数nfds必须设为比3个文件描述符集合中所包含的最大文件描述符号还要大1。
该参数让select()变得更有效率,因为此时内核就不用去检查大于这个值的文件描述符号是否属于这些文件描述符集合
readfds是用来检测输入是否就绪的文件描述符集合
writefds是用来检测输出是否就绪的文件描述符集合
exceptfds是用来检测异常情况是否发生的文件描述符集合
参数 readfds、writefds 和 exceptfds 所指向的结构体都是保存结果值的地方。
在调用select()之前,这些参数指向的结构体必须初始化(通过FD_ZERO()和FD_SET()),
以包含我们感兴趣的文件描述符集合。
之后select()调用会修改这些结构体,当select()返回时,它们包含的就是已处于就绪态的文件描述符集合了
返回一个正整数表示有1个或多个文件描述符已达到就绪态。
返回值表示处于就绪态的文件描述符个数。
*/
int active_fd_num = select(max_fd, &read_fd_set, NULL, NULL, NULL);
if (active_fd_num < 0)
{
perror("select error");
exit(EXIT_FAILURE);
}
/*
只知道个数还不行,要找到具体来自于哪个连接。
所以每个返回的文件描述符集合都需要检查(通过 FD_ISSET()),
以此找出发生的 I/O 事件是什么
*/
for (int i = 0; i < max_fd; i++)
{
if (FD_ISSET(i, &read_fd_set))
{
if (i == server_socket)
{
int new_client_socket = accept(server_socket, NULL, NULL);
if (new_client_socket < 0)
{
perror("accept");
exit(EXIT_FAILURE);
}
printf("new client connected\n");
set_nonblocking(new_client_socket);
FD_SET(new_client_socket, &active_fd_set);
if (new_client_socket >= max_fd)
{
max_fd = new_client_socket + 1;
}
}
else
{
int result = read_from_client(i);
if (result <= 0)
{
close(i);
FD_CLR(i, &active_fd_set);
}
else if (result == READ_AGAIN)
{
print_time();
printf("no connection now, please connect after 3 seconds\n");
continue;
}
}
}
}
}
}理解fd_set位图
fd_set位图实际上是1个含有16个元素的数组,元素类型为unsigned long,该类型在Linux系统+64位机器上 占8字节,64位,所以每个元素为64位,这样每1位都可以按照下列条件来判断文件描述符是否在这个位图中
shell
fd_set = unsigned long fds_bits[16]
└── 16个元素 × 64位 = 1024位 总容量
第一步:fd / 64 → 确定在哪个数组元素(哪个槽)
第二步:fd % 64 → 确定在该元素的哪一位(槽内偏移)
fd = 0: 0/64=0 → fds_bits[0], 0%64=0 → 第0位
fd = 5: 5/64=0 → fds_bits[0], 5%64=5 → 第5位
fd = 64: 64/64=1 → fds_bits[1], 64%64=0 → 第0位
fd = 100: 100/64=1→ fds_bits[1], 100%64=36→第36位
fd = 200: 200/64=3→ fds_bits[3], 200%64=8 → 第8位fd_set这个数组的大小是写死的,如果要改变,必须得自己手动修改源码然后重新编译。同时可以发现,尽管其大小为1024位,但实际很可能无法支撑很大的并发。
实际可用大小 = 1024 - 保留的3个fd(0,1,2) - 1 (服务器本身的fd) = 1020
假设:每个客户端连接后需要打开3个文件,且这3个文件在系统级打开文件表中都不是同一项;同时打开的这几个文件短时间内不会关闭,这也就意味着fd无法被释放以重用。那么不考虑其他因素,该服务器实际可支撑的并发最大也就是1020/5=255个
而且任何一个 fd 的值 ≥ 1024,位图就直接无法处理它
select的缺点
- fd_set位图的缺点导致它还是没办法承受太高的并发
- 内核层面效率低:由于select系统调用的第一个参数是要检查的文件描述符的最大值,如果从0-max_fd 这个范围里只有少数几个连接有I/O事件,那么内核要遍历整个集合
- 用户层面效率低:内核并不会直接告诉用户哪些文件描述符有I/O事件了,用户还是需要遍历整个集合比较才能知道,复杂度为O(n)
后续poll()系统调用虽然优化了一些select()的fd数量上限,但是性能问题还是存在,我就没仔细研究它了,直接用终极解决方案
epoll
epoll系统调用是内核直接返回有I/O事件的文件描述符列表,不再需要用户逐一确认,直接拿来用即可
这里以单进程为例简单演示epoll系统调用的用法
c
#include <sys/epoll.h>
#define MAX_EVENTS 10
/*
EPOLL_CTL_ADD将描述符fd添加到epoll实例epfd中的兴趣列表中去。对于fd上我们感兴趣的事件,都指定在ev所指向的结构体中
*/
int server_that_can_process_requests_concurrently_using_io_multiplexing_by_event_poll()
{
int epfd = epoll_create1(0);
if (epfd == -1)
{
perror("epoll_create error");
exit(1);
}
int server_socket = bind_server_socket_to_port_and_listen();
set_nonblocking(server_socket);
struct epoll_event ev;
ev.events = EPOLLIN;
ev.data.fd = server_socket;
if (epoll_ctl(epfd, EPOLL_CTL_ADD, server_socket, &ev) == -1)
{
perror("epoll_ctl error");
exit(1);
}
struct epoll_event evlist[MAX_EVENTS];
while (1)
{
/*
参数evlist所指向的结构体数组中返回的是有关就绪态文件描述符的信息
*/
int nready = epoll_wait(epfd, evlist, MAX_EVENTS, -1);
if (nready == -1)
{
perror("epoll_wait error");
exit(1);
}
for (int i = 0; i < nready; i++)
{
int fd = evlist[i].data.fd;
if (fd == server_socket)
{
int new_client_socket = accept(server_socket, NULL, NULL);
if (new_client_socket < 0)
{
perror("accept error");
exit(EXIT_FAILURE);
}
printf("new epoll client connected\n");
set_nonblocking(new_client_socket);
struct epoll_event client_ev;
client_ev.events = EPOLLIN;
client_ev.data.fd = new_client_socket;
if (epoll_ctl(epfd, EPOLL_CTL_ADD, new_client_socket, &client_ev) == -1)
{
perror("epoll_ctl error");
exit(1);
}
}
else if (evlist[i].events & (EPOLLIN | EPOLLHUP | EPOLLERR | EPOLLRDHUP))
{
int result = read_from_client(fd);
if (result <= 0)
{
// epoll_ctl(epfd, EPOLL_CTL_DEL, fd, NULL);
// 调用close后内核会自动把fd从epoll中删除,无需显示调用epoll_ctl
close(fd);
}
else if (result == READ_AGAIN)
{
print_time();
printf("no connection now, please connect after 3 seconds\n");
continue;
}
}
}
}
close(server_socket);
close(epfd);
return 0;
}文件描述符关闭和epoll的行为
上一篇博文提到,只有当系统级打开文件表里的某一项的文件描述符引用降为0后,内核才会进行真正释放底层资源。这里也一样。一旦所有指向打开的文件描述的文件描述符都被关闭后,这个打开的文件描述将从epoll的兴趣列表中移除。这表示如果我们通过 dup()(或类似的函数)或者fork()为打开的文件创建了描述符副本,那么这个打开的文件只会在原始的描述符以及所有其他的副本都被关闭时才会移除。
上述代码主动调用了close()方法,保证了文件引用降为0,所以注释掉了EPOLL_CTL_DEL这一操作
借助docker环境在MacOS上调用epoll
由于epoll是Linux独有的,MacOS上如果想使用类似的机制,得使用kqueue。也考虑过使用屏蔽各平台之间差异的libuv,但还是决定当前把主要精力放在epoll上,其他2个可以作为拓展后续学习一下
所以最终得借助docker linux镜像来编译代码,容器安装build-base工具包,这个包里包括了gcc、make等工具
yaml
services:
hello-c:
image: alpine:latest
container_name: hello-c
ports:
- 18080:18080
command: >
sh -c "
apk add --no-cache build-base &&
echo 'build-base installed successfully' &&
gcc --version &&
make --version &&
tail -f /dev/null
"
working_dir: /app
volumes:
- type: bind
source: ./
target: /app
read_only: false
shell
docker compose up -d
docker exec -it hello-c sh
make
./hello水平触发和边缘触发
当文件描述符是非阻塞式I/O模式下,它有I/O事件时,如果用户读取了部分数据而不是全部读完所有数据
-
水平触发:只要用户没把文件描述符中的数据读完,那么每次epoll_wait每次返回的evlist中都有该文件描述符。直到读完所有数据,返回的evlist才不包含该文件描述符。这就看出来水平触发的弊端了,水平触发如果一次读不完所有数据,会一直触发epoll_wait系统调用,增加了开销
epoll_wait() ← 系统调用 1,fd 就绪返回 read(fd, buf, 40) ← 系统调用 2,读了 40 字节 epoll_wait() ← 系统调用 3,缓冲区非空,fd 再次返回 read(fd, buf, 40) ← 系统调用 4,读了 40 字节 epoll_wait() ← 系统调用 5,缓冲区非空,fd 再次返回 read(fd, buf, 20) ← 系统调用 6,读完剩余 20 字节 共 6 次系统调用 -
边缘触发:只要读过1次,就不再出现在evlist中。直到这个文件描述符下一次有新的I/O活动
epoll_wait() ← 系统调用 1,fd 就绪返回 // 必须循环读完,否则不再通知 read(fd, buf, 40) ← 系统调用 2 read(fd, buf, 40) ← 系统调用 3 read(fd, buf, 20) ← 系统调用 4,返回 EAGAIN,退出循环 共 4 次系统调用要使用边缘触发,得在注册events时,声明EPOLLET标志位
cstruct epoll_event client_ev; client_ev.events = EPOLLIN | EPOLLET;使用边缘触发要注意,由于它是要把某个连接的数据全都读完,才算处理完毕。可能存在着某个连接一直有数据,导致同一批次的其他连接迟迟无法得到处理。这里不再过多展开,有兴趣的同学可以自行了解 解决方式
Multi-Reactor 模式
基于上述所有优化,那么回到最初的背景+要解决的问题上:
需要同时处理许多客户端的服务器:需要监视大量的文件描述符,但大部分处于空闲状态,只有少数文件描述符处于就绪态
整体架构
最终的服务端架构为在Master-Worker模式基础上,使用epoll+边缘触发模式 来高效的处理。这就是Multi-Reactor 模式,整体架构如下
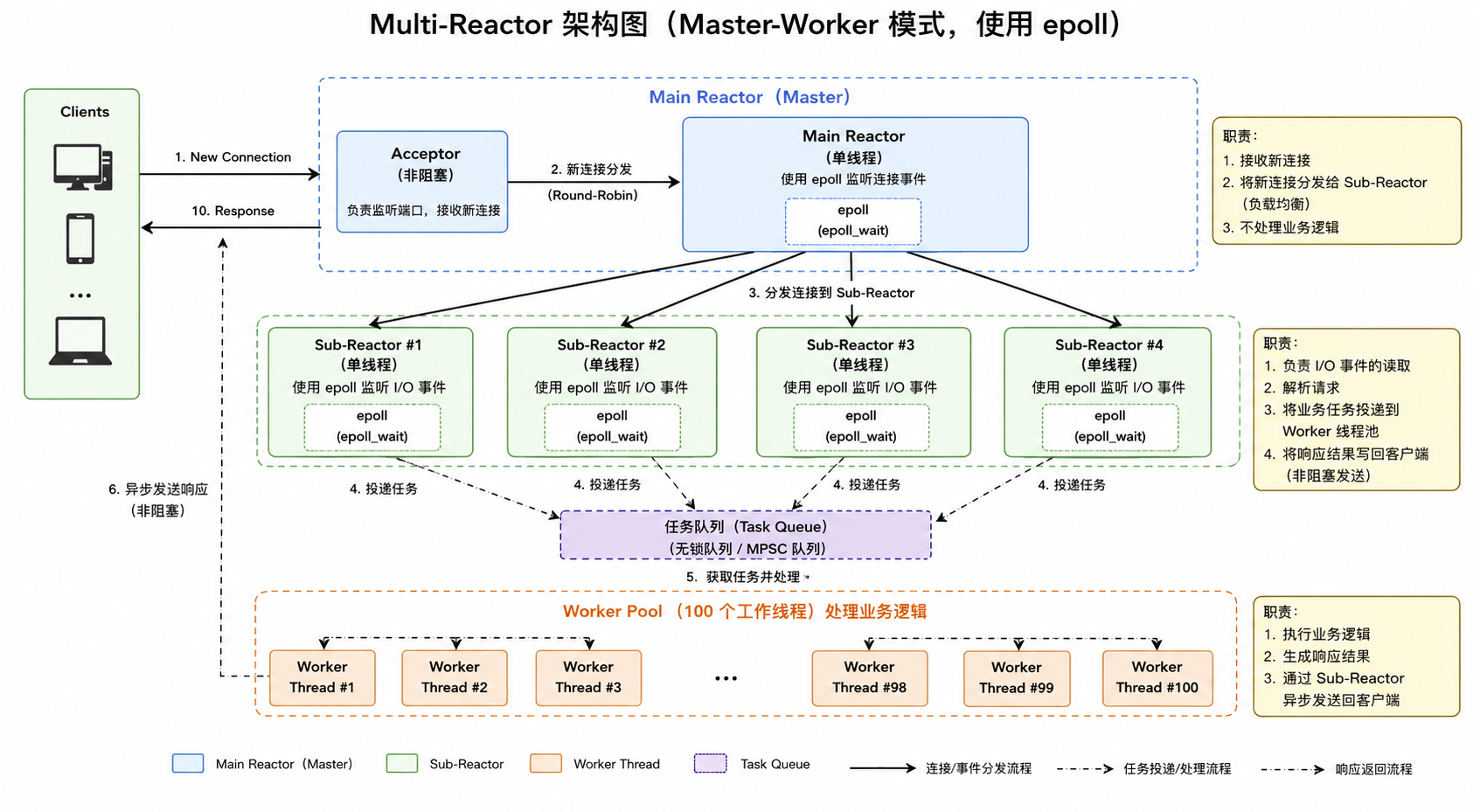
架构实现
c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <errno.h>
#include <fcntl.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <sys/epoll.h>
#include <sys/eventfd.h>
#include <pthread.h>
#include "nio_master_slave.h"
#define PORT 8080
#define MAX_EVENTS 100
#define SUB_REACTOR_COUNT 2 // IO 搬运工数量
#define WORKER_THREAD_COUNT 4 // 业务算力工人数量
#define MAX_CLIENTS 10000
// --- 1. 连接上下文 ---
typedef struct
{
int fd;
int sub_reactor_id;
char out_buffer[8192]; // 发送缓冲区
int out_len;
pthread_mutex_t lock; // 保护 out_buffer
} Connection;
Connection *connections[MAX_CLIENTS];
// --- 2. 核心组件结构 ---
typedef struct
{
int id;
int epoll_fd;
int wakeup_fd;
int fd_queue[1024];
int queue_count;
pthread_mutex_t lock;
pthread_t thread_id;
} SubReactor;
SubReactor sub_reactors[SUB_REACTOR_COUNT];
typedef struct
{
int client_fd;
char *data;
} Task;
Task worker_queue[2048];
int worker_task_count = 0;
pthread_mutex_t worker_queue_lock = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t worker_queue_cond = PTHREAD_COND_INITIALIZER;
// --- 辅助函数 ---
static void set_nonblocking(int sockfd)
{
int flags = fcntl(sockfd, F_GETFL, 0);
fcntl(sockfd, F_SETFL, flags | O_NONBLOCK);
}
void update_epoll(int epoll_fd, int fd, int events)
{
struct epoll_event ev;
ev.events = events;
ev.data.fd = fd;
epoll_ctl(epoll_fd, EPOLL_CTL_MOD, fd, &ev);
}
// 清理连接资源
void close_connection(int fd)
{
Connection *conn = connections[fd];
if (conn)
{
close(fd); // 自动从 epoll 移除
pthread_mutex_destroy(&conn->lock);
free(conn);
connections[fd] = NULL;
printf("客户端 FD %d 断开连接,资源已清理\n", fd);
}
}
// --- 3. 业务线程池 (专职算力) ---
void *worker_thread_loop(void *arg)
{
while (1)
{
Task task;
pthread_mutex_lock(&worker_queue_lock);
while (worker_task_count == 0)
{
pthread_cond_wait(&worker_queue_cond, &worker_queue_lock);
}
task = worker_queue[--worker_task_count];
pthread_mutex_unlock(&worker_queue_lock);
// 模拟业务处理耗时 (0.1秒)
usleep(100000);
Connection *conn = connections[task.client_fd];
if (conn)
{
char response[2048];
int len = snprintf(response, sizeof(response), "[Worker Processed] %s", task.data);
pthread_mutex_lock(&conn->lock);
// 将结果安全地拼接到发送缓冲区
if (conn->out_len + len < sizeof(conn->out_buffer))
{
memcpy(conn->out_buffer + conn->out_len, response, len);
conn->out_len += len;
// 唤醒对应的 Sub-Reactor 去发数据
int sub_epoll = sub_reactors[conn->sub_reactor_id].epoll_fd;
update_epoll(sub_epoll, task.client_fd, EPOLLIN | EPOLLOUT | EPOLLET);
}
else
{
printf("警告:FD %d 的发送缓冲区已满,丢弃数据\n", task.client_fd);
}
pthread_mutex_unlock(&conn->lock);
}
free(task.data); // 释放通过 strdup 申请的内存
}
return NULL;
}
// --- 4. 子 Reactor (专职 IO,严格执行 ET 模式) ---
void *sub_reactor_loop(void *arg)
{
SubReactor *reactor = (SubReactor *)arg;
struct epoll_event events[MAX_EVENTS];
char buffer[1024];
while (1)
{
int n = epoll_wait(reactor->epoll_fd, events, MAX_EVENTS, -1);
for (int i = 0; i < n; i++)
{
int fd = events[i].data.fd;
// --- 任务 1:处理主线程扔过来的新连接 ---
if (fd == reactor->wakeup_fd)
{
uint64_t val;
read(reactor->wakeup_fd, &val, sizeof(val));
pthread_mutex_lock(&reactor->lock);
for (int j = 0; j < reactor->queue_count; j++)
{
int new_client = reactor->fd_queue[j];
set_nonblocking(new_client);
connections[new_client]->sub_reactor_id = reactor->id;
struct epoll_event client_ev;
client_ev.events = EPOLLIN | EPOLLET; // 注册边缘触发
client_ev.data.fd = new_client;
epoll_ctl(reactor->epoll_fd, EPOLL_CTL_ADD, new_client, &client_ev);
}
reactor->queue_count = 0;
pthread_mutex_unlock(&reactor->lock);
}
// --- 任务 2:处理客户端 IO ---
else
{
Connection *conn = connections[fd];
if (!conn)
continue;
// [ET 修复] 可读事件:必须用 while 循环榨干内核缓冲区!
if (events[i].events & EPOLLIN)
{
while (1)
{
ssize_t count = read(fd, buffer, sizeof(buffer) - 1);
if (count > 0)
{
buffer[count] = '\0';
// 读到一块数据,就扔给业务线程池
pthread_mutex_lock(&worker_queue_lock);
worker_queue[worker_task_count].client_fd = fd;
worker_queue[worker_task_count].data = strdup(buffer);
worker_task_count++;
pthread_cond_signal(&worker_queue_cond);
pthread_mutex_unlock(&worker_queue_lock);
}
else if (count == -1)
{
if (errno == EAGAIN || errno == EWOULDBLOCK)
{
// 数据终于读干了,可以安心退出了
break;
}
else
{
// 真正发生错误
close_connection(fd);
break;
}
}
else if (count == 0)
{
// 客户端主动断开
close_connection(fd);
break;
}
}
}
// [ET 修复] 可写事件:尽量发,直到发完或者遇到 EAGAIN
if (conn && (events[i].events & EPOLLOUT))
{
pthread_mutex_lock(&conn->lock);
while (conn->out_len > 0)
{
ssize_t sent = send(fd, conn->out_buffer, conn->out_len, 0);
if (sent > 0)
{
conn->out_len -= sent;
if (conn->out_len > 0)
{
// 将没发完的数据往前挪
memmove(conn->out_buffer, conn->out_buffer + sent, conn->out_len);
}
}
else if (sent == -1)
{
if (errno == EAGAIN || errno == EWOULDBLOCK)
{
// 内核发送缓冲区满了,立刻停手,等下次 EPOLLOUT
break;
}
else
{
perror("send error");
close_connection(fd);
break;
}
}
}
// 发完了,取消关注 EPOLLOUT,只保留 EPOLLIN
if (conn && conn->out_len == 0)
{
update_epoll(reactor->epoll_fd, fd, EPOLLIN | EPOLLET);
}
pthread_mutex_unlock(&conn->lock);
}
}
}
}
return NULL;
}
// --- 5. 主线程 (专职 Accept) ---
int multiple_level_reactor()
{
// 1. 初始化资源
for (int i = 0; i < MAX_CLIENTS; i++)
connections[i] = NULL;
for (int i = 0; i < WORKER_THREAD_COUNT; i++)
{
pthread_t tid;
pthread_create(&tid, NULL, worker_thread_loop, NULL);
}
for (int i = 0; i < SUB_REACTOR_COUNT; i++)
{
sub_reactors[i].id = i;
sub_reactors[i].queue_count = 0;
pthread_mutex_init(&sub_reactors[i].lock, NULL);
sub_reactors[i].epoll_fd = epoll_create1(0);
sub_reactors[i].wakeup_fd = eventfd(0, EFD_NONBLOCK);
struct epoll_event ev;
// Linux系统编程 63.4.6 边缘触发通知
// 要使用边缘触发通知,我们在调用epoll_ctl()时在ev.events字段中指定EPOLLET标志
ev.events = EPOLLIN | EPOLLET;
ev.data.fd = sub_reactors[i].wakeup_fd;
epoll_ctl(sub_reactors[i].epoll_fd, EPOLL_CTL_ADD, sub_reactors[i].wakeup_fd, &ev);
pthread_create(&sub_reactors[i].thread_id, NULL, sub_reactor_loop, &sub_reactors[i]);
}
// 2. 创建 Server Socket
int server_fd = socket(AF_INET, SOCK_STREAM, 0);
int opt = 1;
setsockopt(server_fd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt));
struct sockaddr_in address;
address.sin_family = AF_INET;
address.sin_addr.s_addr = INADDR_ANY;
address.sin_port = htons(PORT);
bind(server_fd, (struct sockaddr *)&address, sizeof(address));
listen(server_fd, SOMAXCONN);
set_nonblocking(server_fd); // 必须非阻塞
// 3. 主 Reactor
int main_epoll_fd = epoll_create1(0);
struct epoll_event event;
event.events = EPOLLIN | EPOLLET; // 主 Reactor 也要用 ET
event.data.fd = server_fd;
epoll_ctl(main_epoll_fd, EPOLL_CTL_ADD, server_fd, &event);
printf(">>> NIO 终极架构启动 (严格 ET 模式) <<<\n");
printf("PORT: %d | Main(1) + Sub(%d) + Worker(%d)\n", PORT, SUB_REACTOR_COUNT, WORKER_THREAD_COUNT);
int next_reactor = 0;
struct epoll_event events[MAX_EVENTS];
while (1)
{
int n = epoll_wait(main_epoll_fd, events, MAX_EVENTS, -1);
for (int i = 0; i < n; i++)
{
if (events[i].data.fd == server_fd)
{
int client_fd;
// [ET 修复] Accept 必须榨干队列!
while ((client_fd = accept(server_fd, NULL, NULL)) > 0)
{
if (client_fd >= MAX_CLIENTS)
{
printf("达到最大连接数,拒绝连接\n");
close(client_fd);
continue;
}
Connection *conn = malloc(sizeof(Connection));
conn->fd = client_fd;
conn->out_len = 0;
pthread_mutex_init(&conn->lock, NULL);
connections[client_fd] = conn;
int target = next_reactor % SUB_REACTOR_COUNT;
next_reactor++;
SubReactor *reactor = &sub_reactors[target];
pthread_mutex_lock(&reactor->lock);
reactor->fd_queue[reactor->queue_count++] = client_fd;
uint64_t one = 1;
write(reactor->wakeup_fd, &one, sizeof(one));
pthread_mutex_unlock(&reactor->lock);
}
// 处理 accept 的错误
if (client_fd == -1)
{
if (errno != EAGAIN && errno != EWOULDBLOCK)
{
perror("accept error");
}
}
}
}
}
return 0;
}备注
有了这些基础,下一篇博文将介绍如何在 Java 中使用 java.nio.channels.Selector 来实现高效的多路复用以及其他使用了Reactor模式的框架的部分源码解读