测试学习记录,仅供参考!
添加其他方法
获取当前系统时间方法
1、 修改项目根目录 unit_tools 软件包debugtalk.py的 Python 文件内容,添加获取当前时间方法;
# 导包
import random # random -- 随机数
import re # re -- 正则表达式
from unit_tools.handle_data.yaml_handler import get_extract_yaml
import time
# 定义一个类 DebugTalk
class DebugTalk:
# 定义一个方法 get_extract_data提取全局配置文件extract.yaml变量--第一个参数 node_name;第二个参数这里默认为空,可以传也可以不传
def get_extract_data(self, node_name, out_format=None):
"""
获取全局yaml文件extract.yaml数据,首先判断out_format是否为数字类型,如果不是就获取下一个节点的value
:param node_name: 全局文件extract.yaml文件中的key--例如:Cookie、access_token_cookie、token
:param out_format: str类型,0:随机去读取;-1:读取全部数据,返回字符串格式;-2:读取全部,返回列表格式;其他值的就按顺序读取
:return:
"""
# 导包引入模块之后--直接调用方法get_extract_yaml()--需要传两个参数,暂时先传一个参数 node_name--返回值赋值给变量data
data = get_extract_yaml(node_name)
# 若是数值类型的--判断第二个参数不等于空 并且 --加一个布尔值--正则表达式,判断传入的第二个参数是数值的形式还是一个字母参数的形式
if out_format is not None and bool(re.compile(r'^[+-]?\d+$').match(str(out_format))):
# 转换格式成int类型--返回赋值给变量out_format
out_format = int(out_format)
# 定义一个字典--或者使用if else
data_value = {
# 若传的这个参数out_format存在--通过self.seq_read(data, out_format)调用
out_format: self.seq_read(data, out_format),
# 若第二参数传入的是 0 -- 通过随机函数-- 随机去读取
0: random.choice(data),
# 传入的是 -1 -- 去读取全部,返回字符串格式--列表怎么转字符串--通过 ','.join(data) 逗号分隔.join() 组成新的字符串
-1: ','.join(data),
# 若传入的是 -2 --读取全部,返回列表格式
-2: ','.join(data).split(',')
}
# 通过data_value取值--取第二个值--返回出去赋值给变量data
data = data_value[out_format]
else:
# 若第二个参数传入的不是数字--调用get_extract_yaml方法--把这两个node_name, out_format参数给它传进来
data = get_extract_yaml(node_name, out_format)
# return--把data值返回出去
return data
# 定义一个方法 seq_read--参入两个参数,第一个data,第二个随机数randoms
def seq_read(self, data, randoms):
""" 获取extract.yaml,第二个参数不为 0、-1、-2的情况下 """
# 直接判断这个参数randoms不是0、-1、-2
if randoms not in [0, -1, -2]:
# 直接返回一个 data--通过这个 randoms去减1--为什么要减1呢?--
return data[randoms - 1]
else:
return None
# 获取当前时间
@classmethod
def get_now_time(cls):
return time.time()
# 测试调试查看
if __name__ == '__main__':
# 实例化类 DebugTalk()
debug = DebugTalk()
# 通过对象取调用方法--第一个参数是goodsId
# 第二个参数(0:随机读取,1~4:按顺序依次读取,-1:读取全部,-2:读取全部,返回列表格式,-3是第一个)
# 根据实际情况其他超出范围会报"索引错误:列表索引超出范围 " IndexError: list index out of range
res = debug.get_extract_data('goodsId','0')
print(res)2、修改项目根目录 datas 目录文件路径下adduser.yaml文件内容,通过"${}"这种格式去调用对应的函数方法,可以动态的去实现某一个功能,这就是要做热加载的一个原因;
- baseInfo:
api_name: 用户新增
url: /dar/user/addUser
method: post
header:
Content-Type: application/x-www-formurlencoded;charset=UTF-8
testCase:
- case_name: 用户新增正常校验
data:
username: testadduser
password: tset6789890
role_id: 123456789
dates: ${get_now_time()}
phone: 13800000000
token: ${get_extract_data(goodsId,1)}
3、在项目根目录 unit_tools 软件包下新建名称为apiutils.py的 Python 文件,输入以下内容;
# 导包
import json
from unit_tools.handle_data.yaml_handler import read_yaml
# 创建一个类 RequestsBase
class RequestsBase:
# 创建一个方法 parse_and_replace_variables(解析并且替换变量)--传一个参数 yml_data--要解析的yaml文件的数组
def parse_and_replace_variables(self, yml_data):
"""
解析并替换YAML文件数据中的变量引用,如:${get_extract_data(goodsId,1)}
:param yml_data: 解析的YAML数据
:return:
"""
# if isinstance(yml_data, str)--判断传进来的数据是什么类型?--后续需要字符串才能做操作的,所以这里先判断是不是字符串格式
# yml_data若是字符串则执行 if 语句左边的代码 直接返回yml_data
# yml_data不是字符串--调用json.dumps(yml_data)模块转成字符串--ensure_ascii=False 参数是可以处理中文
# if else 语句写在一行是 三元运算--通过这一系列之后最终返回一个 新的变量yaml_data_str --它是一个字符串
yaml_data_str = yml_data if isinstance(yml_data, str) else json.dumps(yml_data, ensure_ascii=False)
# 打印查看 yaml_data_str
print(f'解析前的类型:{type(yaml_data_str)},解析前:{yaml_data_str}')
# 测试调试查看
if __name__ == '__main__':
# 先引进读取方法 read_yaml--传如一个它的相对路径--赋值给新变量data--[0]通过索引去列表值第一个
data = read_yaml('.././datas/adduser.yaml')[0]
# 打印
print(data)
# 实例化类 RequestsBase()--并赋值给一个变量对象 req
req = RequestsBase()
# 通过类对象去调用parse_and_replace_variables(data) 这个解析的方法--把读取到的 data 这个yaml数据传给它
req.parse_and_replace_variables(data)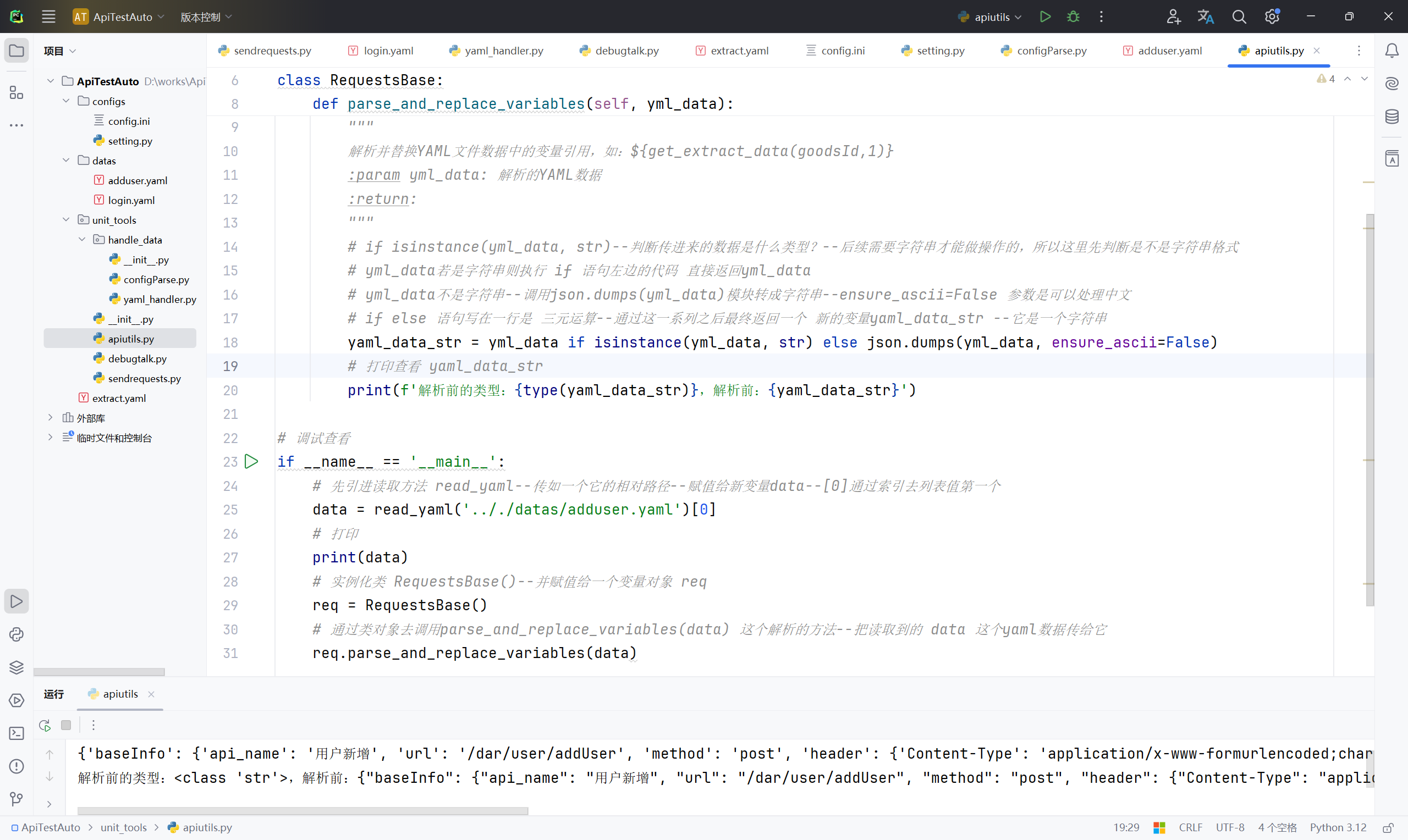
4、运行查看,从打印结果中可以看出,解析前是一个字符串格式类型,而所需要的数据("{get_now_time}"、"${get_extract_data(goodsId,1)}")解析后类型是一个字典格式;
# 打印结果--可以看到 解析前是一个字符串,解析后是一个字典格式
{'baseInfo': {'api_name': '用户新增', 'url': '/dar/user/addUser', 'method': 'post', 'header': {'Content-Type': 'application/x-www-formurlencoded;charset=UTF-8'}}, 'testCase': [{'case_name': '用户新增正常校验', 'data': {'username': 'testadduser', 'password': 'tset6789890', 'role_id': 123456789, 'dates': '${get_now_time()}', 'phone': 13800000000, 'token': '${get_extract_data(goodsId,1)}'}}]}
解析前的类型:<class 'str'>,解析前:{"baseInfo": {"api_name": "用户新增", "url": "/dar/user/addUser", "method": "post", "header": {"Content-Type": "application/x-www-formurlencoded;charset=UTF-8"}}, "testCase": [{"case_name": "用户新增正常校验", "data": {"username": "testadduser", "password": "tset6789890", "role_id": 123456789, "dates": "${get_now_time()}", "phone": 13800000000, "token": "${get_extract_data(goodsId,1)}"}}]}5、修改apiutils.py文件,使用 for 循环去判断字符串 yaml_data_str 里面的标识符,从而获取到所需要的数据(详情烦请自行查看每行代码注释);
# 导包
import json
from unit_tools.handle_data.yaml_handler import read_yaml
# 创建一个类 RequestsBase
class RequestsBase:
# 创建一个方法 parse_and_replace_variables(解析并且替换变量)--传一个参数 yml_data--要解析的yaml文件的数组
def parse_and_replace_variables(self, yml_data):
"""
解析并替换YAML文件数据中的变量引用,如:${get_extract_data(goodsId,1)}
:param yml_data: 解析的YAML数据
:return:
"""
# if isinstance(yml_data, str)--判断传进来的数据是什么类型?--后续需要字符串才能做操作的,所以这里先判断是不是字符串格式
# yml_data若是字符串则执行 if 语句左边的代码 直接返回yml_data
# yml_data不是字符串--调用json.dumps(yml_data)模块转成字符串--ensure_ascii=False 参数是可以处理中文
# if else 语句写在一行是 三元运算--通过这一系列之后最终返回一个 新的变量yaml_data_str --它是一个字符串
yaml_data_str = yml_data if isinstance(yml_data, str) else json.dumps(yml_data, ensure_ascii=False)
# 打印查看 yaml_data_str
print(f'解析前的类型:{type(yaml_data_str)},解析前:{yaml_data_str}')
# 用for循环去判断 字符串yaml_data_str里面这种标识 "${" 格式出现的次数--加一个'_'下划线表示不需要用到这个变量,是一个占位符的意思
for _ in range(yaml_data_str.count("${")):
# if判断这个标识'${' 它包含在字符串yaml_data_str里面--并且另一半它 '}' 也包含在字符串yaml_data_str里面
if '${' in yaml_data_str and '}' in yaml_data_str:
# 通过获取到 "${" 标识的起始位置--通过字符串 yaml_data_str 的索引 index--获取它的索引的起始位置
strat_index = yaml_data_str.index("${")
# 获取结束位置 标识 "}"--再加一个参数 它的开头 strat_index
end_index = yaml_data_str.index("}", strat_index)
# 拿到开始、结束位置后--通过字符串切片--起始位置、结束位置+1--为什么+1?--因为python中索引切片是左闭右开的一个规则
# 什么是左闭右开?--开始位置是包含在切片里面的,但是结束元素不包含在切片中,所以得+1
variable_data = yaml_data_str[strat_index:end_index + 1]
# 打印查看 variable_data
print(variable_data)
# 调试查看
if __name__ == '__main__':
# 先引进读取方法 read_yaml--传如一个它的相对路径--赋值给新变量data--[0]通过索引去列表值第一个
data = read_yaml('.././datas/adduser.yaml')[0]
# 打印
print(data)
# 实例化类 RequestsBase()--并赋值给一个变量对象 req
req = RequestsBase()
# 通过类对象去调用parse_and_replace_variables(data) 这个解析的方法--把读取到的 data 这个yaml数据传给它
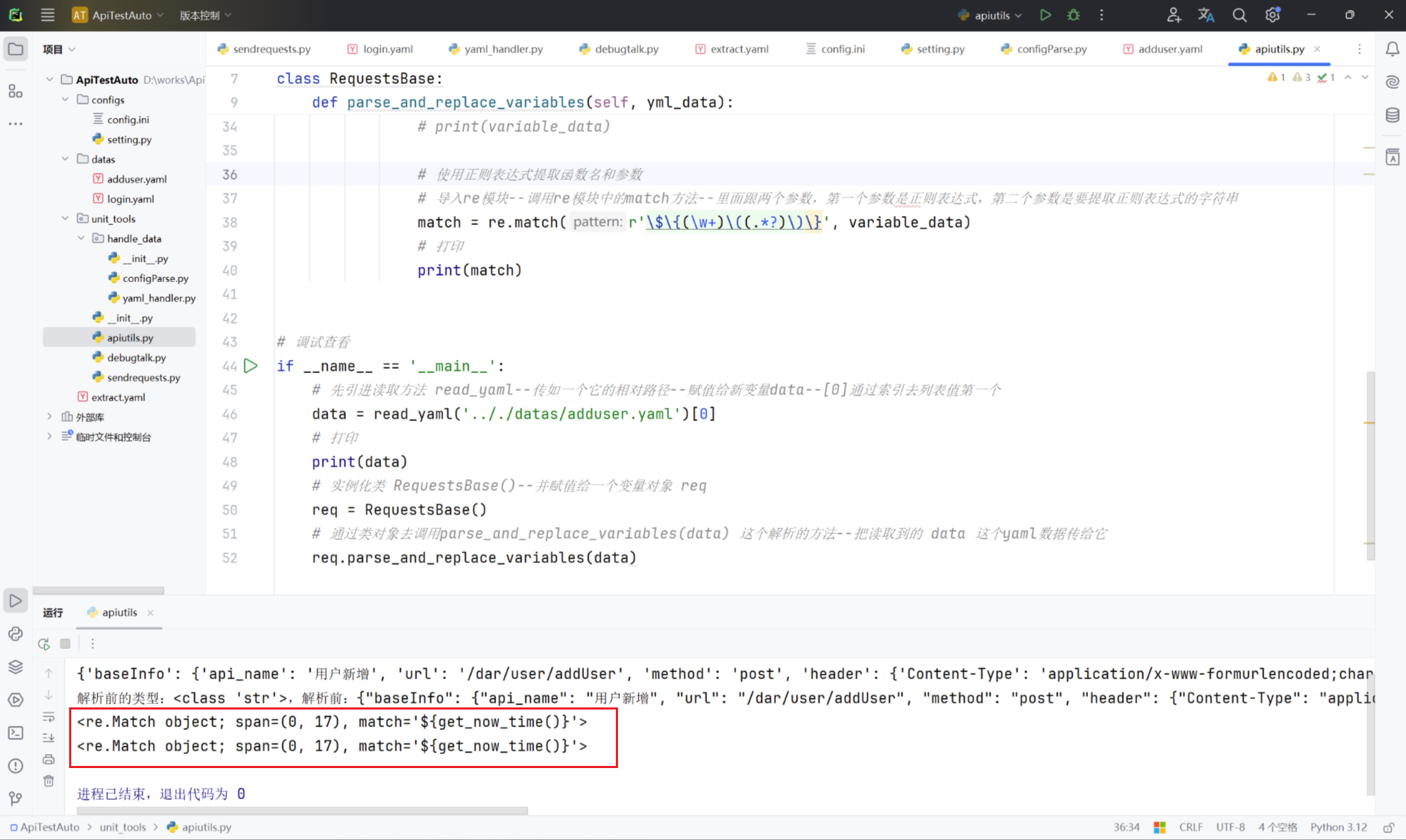
req.parse_and_replace_variables(data)6、再次执行查看,可以看到会打印两个一模一样的数据,跟配置文件中的两个数据("{get_now_time}"、"{get_extract_data(goodsId,1)}")是不一样的?这是因为代码在循环中每次都是从原始的字符串中去查找这个标识(起始、结束位置),所以会重复查找相同的变量;
{'baseInfo': {'api_name': '用户新增', 'url': '/dar/user/addUser', 'method': 'post', 'header': {'Content-Type': 'application/x-www-formurlencoded;charset=UTF-8'}}, 'testCase': [{'case_name': '用户新增正常校验', 'data': {'username': 'testadduser', 'password': 'tset6789890', 'role_id': 123456789, 'dates': '${get_now_time()}', 'phone': 13800000000, 'token': '${get_extract_data(goodsId,1)}'}}]}
解析前的类型:<class 'str'>,解析前:{"baseInfo": {"api_name": "用户新增", "url": "/dar/user/addUser", "method": "post", "header": {"Content-Type": "application/x-www-formurlencoded;charset=UTF-8"}}, "testCase": [{"case_name": "用户新增正常校验", "data": {"username": "testadduser", "password": "tset6789890", "role_id": 123456789, "dates": "${get_now_time()}", "phone": 13800000000, "token": "${get_extract_data(goodsId,1)}"}}]}
${get_now_time()}
${get_now_time()}使用正则表达式提取函数名和参数
正则表达式烦请自行学习了解,可参考教程:Python3 正则表达式
|--------|---|---|
| 正则表达式:  |||
|||
| \ | 第一步,先拿到 这一部分,怎么写呢?--斜杠 美元符号 \$ ||
| \{ | 花括号或者大括号的左边位置 { -- 再来一个 斜杠 花括号 \{ ||
| (\w+) | 处理函数名,这里使用一个组给它括起来 () -- \w 匹配 字母、数字、下划线 组成 -- 再加一个 加号 + 可以匹配一个或者多个 字母、数字、下划线-- (\w+) ||
| \( | 函数名后面的括号 () --先左边位置 斜杠 小括号 \( ||
| (.*?) | 参数名,有的有参数,有的没有,同样需要处理,怎么处理呢?--需要用一个贪婪匹配,就是 .*? --点 星号 问号--就是第二个捕获组,匹配任意字符--尽量去匹配一个最短的长度,用于匹配参数--(.*?) ||
| \) | 小括号 右边的括号 \) ||
| \} | 最外层右边的花括号 \} ||
7、修改apiutils.py文件内容,使用正则表达式来提取所需要的函数名和参数;
# 导包
import json
from unit_tools.handle_data.yaml_handler import read_yaml
import re
# 创建一个类 RequestsBase
class RequestsBase:
# 创建一个方法 parse_and_replace_variables(解析并且替换变量)--传一个参数 yml_data--要解析的yaml文件的数组
def parse_and_replace_variables(self, yml_data):
"""
解析并替换YAML文件数据中的变量引用,如:${get_extract_data(goodsId,1)}
:param yml_data: 解析的YAML数据
:return:
"""
# if isinstance(yml_data, str)--判断传进来的数据是什么类型?--后续需要字符串才能做操作的,所以这里先判断是不是字符串格式
# yml_data若是字符串则执行 if 语句左边的代码 直接返回yml_data
# yml_data不是字符串--调用json.dumps(yml_data)模块转成字符串--ensure_ascii=False 参数是可以处理中文
# if else 语句写在一行是 三元运算--通过这一系列之后最终返回一个 新的变量yaml_data_str --它是一个字符串
yaml_data_str = yml_data if isinstance(yml_data, str) else json.dumps(yml_data, ensure_ascii=False)
# 打印查看 yaml_data_str
print(f'解析前的类型:{type(yaml_data_str)},解析前:{yaml_data_str}')
# 用for循环去判断 字符串yaml_data_str里面这种标识 "${" 格式出现的次数--加一个'_'下划线表示不需要用到这个变量,是一个占位符的意思
for _ in range(yaml_data_str.count("${")):
# if判断这个标识'${' 它包含在字符串yaml_data_str里面--并且另一半它 '}' 也包含在字符串yaml_data_str里面
if '${' in yaml_data_str and '}' in yaml_data_str:
# 通过获取到 "${" 标识的起始位置--通过字符串 yaml_data_str 的索引 index--获取它的索引的起始位置
strat_index = yaml_data_str.index("${")
# 获取结束位置 标识 "}"--再加一个参数 它的开头 strat_index
end_index = yaml_data_str.index("}", strat_index)
# 拿到开始、结束位置后--通过字符串切片--起始位置、结束位置+1--为什么+1?--因为python中索引切片是左闭右开的一个规则
# 什么是左闭右开?--开始位置是包含在切片里面的,但是结束元素不包含在切片中,所以得+1
variable_data = yaml_data_str[strat_index:end_index + 1]
# 打印查看 variable_data
# print(variable_data)
# 使用正则表达式提取函数名和参数
# 导入re模块--调用re模块中的match方法--里面跟两个参数,第一个参数是正则表达式,第二个参数是要提取正则表达式的字符串
match = re.match(r'\$\{(\w+)\((.*?)\)\}', variable_data)
# 打印
print(match)
# 调试查看
if __name__ == '__main__':
# 先引进读取方法 read_yaml--传如一个它的相对路径--赋值给新变量data--[0]通过索引去列表值第一个
data = read_yaml('.././datas/adduser.yaml')[0]
# 打印
print(data)
# 实例化类 RequestsBase()--并赋值给一个变量对象 req
req = RequestsBase()
# 通过类对象去调用parse_and_replace_variables(data) 这个解析的方法--把读取到的 data 这个yaml数据传给它
req.parse_and_replace_variables(data)8、运行成功后发现它们俩个还是一样的,继续下一步;
9、修改apiutils.py文件内容,添加判断;
# 导包
import json
from unit_tools.handle_data.yaml_handler import read_yaml
import re
# 创建一个类 RequestsBase
class RequestsBase:
# 创建一个方法 parse_and_replace_variables(解析并且替换变量)--传一个参数 yml_data--要解析的yaml文件的数组
def parse_and_replace_variables(self, yml_data):
"""
解析并替换YAML文件数据中的变量引用,如:${get_extract_data(goodsId,1)}
:param yml_data: 解析的YAML数据
:return:
"""
# if isinstance(yml_data, str)--判断传进来的数据是什么类型?--后续需要字符串才能做操作的,所以这里先判断是不是字符串格式
# yml_data若是字符串则执行 if 语句左边的代码 直接返回yml_data
# yml_data不是字符串--调用json.dumps(yml_data)模块转成字符串--ensure_ascii=False 参数是可以处理中文
# if else 语句写在一行是 三元运算--通过这一系列之后最终返回一个 新的变量yaml_data_str --它是一个字符串
yaml_data_str = yml_data if isinstance(yml_data, str) else json.dumps(yml_data, ensure_ascii=False)
# 打印查看 yaml_data_str
print(f'解析前的类型:{type(yaml_data_str)},解析前:{yaml_data_str}')
# 用for循环去判断 字符串yaml_data_str里面这种标识 "${" 格式出现的次数--加一个'_'下划线表示不需要用到这个变量,是一个占位符的意思
for _ in range(yaml_data_str.count("${")):
# if判断这个标识'${' 它包含在字符串yaml_data_str里面--并且另一半它 '}' 也包含在字符串yaml_data_str里面
if '${' in yaml_data_str and '}' in yaml_data_str:
# 通过获取到 "${" 标识的起始位置--通过字符串 yaml_data_str 的索引 index--获取它的索引的起始位置
strat_index = yaml_data_str.index("${")
# 获取结束位置 标识 "}"--再加一个参数 它的开头 strat_index
end_index = yaml_data_str.index("}", strat_index)
# 拿到开始、结束位置后--通过字符串切片--起始位置、结束位置+1--为什么+1?--因为python中索引切片是左闭右开的一个规则
# 什么是左闭右开?--开始位置是包含在切片里面的,但是结束元素不包含在切片中,所以得+1
variable_data = yaml_data_str[strat_index:end_index + 1]
# 打印查看 variable_data
# print(variable_data)
# 使用正则表达式提取函数名和参数
# 导入re模块--调用re模块中的match方法--里面跟两个参数,第一个参数是正则表达式,第二个参数是要提取正则表达式的字符串
match = re.match(r'\$\{(\w+)\((.*?)\)\}', variable_data)
# 判断一下有没有匹配到--匹配的对象是不是成功了--成功
if match:
# 通过match.groups()去拿到函数名还有参数--定义两个变量去接收,第一个函数名func_name、第二个函数值func_params
func_name, func_params = match.groups()
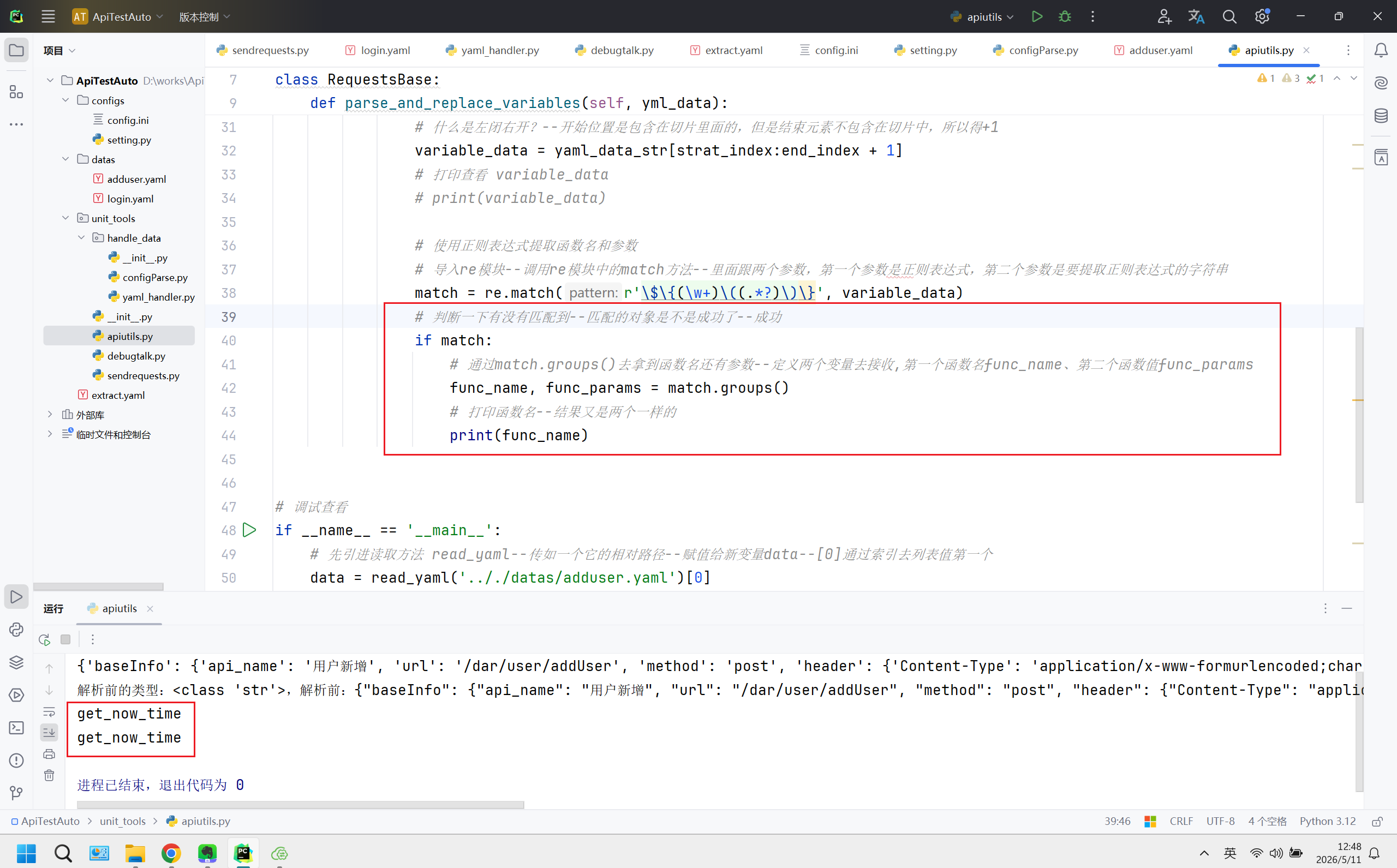
# 打印函数名--结果又是两个一样的
print(func_name)
# 调试查看
if __name__ == '__main__':
# 先引进读取方法 read_yaml--传如一个它的相对路径--赋值给新变量data--[0]通过索引去列表值第一个
data = read_yaml('.././datas/adduser.yaml')[0]
# 打印
print(data)
# 实例化类 RequestsBase()--并赋值给一个变量对象 req
req = RequestsBase()
# 通过类对象去调用parse_and_replace_variables(data) 这个解析的方法--把读取到的 data 这个yaml数据传给它
req.parse_and_replace_variables(data)10、运行查看结果仍是一样的,接着下一步;
11、修改apiutils.py文件内容;
# 导包
import json
from unit_tools.handle_data.yaml_handler import read_yaml
import re
# 创建一个类 RequestsBase
class RequestsBase:
# 创建一个方法 parse_and_replace_variables(解析并且替换变量)--传一个参数 yml_data--要解析的yaml文件的数组
def parse_and_replace_variables(self, yml_data):
"""
解析并替换YAML文件数据中的变量引用,如:${get_extract_data(goodsId,1)}
:param yml_data: 解析的YAML数据
:return:
"""
# if isinstance(yml_data, str)--判断传进来的数据是什么类型?--后续需要字符串才能做操作的,所以这里先判断是不是字符串格式
# yml_data若是字符串则执行 if 语句左边的代码 直接返回yml_data
# yml_data不是字符串--调用json.dumps(yml_data)模块转成字符串--ensure_ascii=False 参数是可以处理中文
# if else 语句写在一行是 三元运算--通过这一系列之后最终返回一个 新的变量yaml_data_str --它是一个字符串
yaml_data_str = yml_data if isinstance(yml_data, str) else json.dumps(yml_data, ensure_ascii=False)
# 打印查看 yaml_data_str
print(f'解析前的类型:{type(yaml_data_str)},解析前:{yaml_data_str}')
# 用for循环去判断 字符串yaml_data_str里面这种标识 "${" 格式出现的次数--加一个'_'下划线表示不需要用到这个变量,是一个占位符的意思
for _ in range(yaml_data_str.count("${")):
# if判断这个标识'${' 它包含在字符串yaml_data_str里面--并且另一半它 '}' 也包含在字符串yaml_data_str里面
if '${' in yaml_data_str and '}' in yaml_data_str:
# 通过获取到 "${" 标识的起始位置--通过字符串 yaml_data_str 的索引 index--获取它的索引的起始位置
strat_index = yaml_data_str.index("${")
# 获取结束位置 标识 "}"--再加一个参数 它的开头 strat_index
end_index = yaml_data_str.index("}", strat_index)
# 拿到开始、结束位置后--通过字符串切片--起始位置、结束位置+1--为什么+1?--因为python中索引切片是左闭右开的一个规则
# 什么是左闭右开?--开始位置是包含在切片里面的,但是结束元素不包含在切片中,所以得+1
variable_data = yaml_data_str[strat_index:end_index + 1]
# 打印查看 variable_data
# print(variable_data)
# 使用正则表达式提取函数名和参数
# 导入re模块--调用re模块中的match方法--里面跟两个参数,第一个参数是正则表达式,第二个参数是要提取正则表达式的字符串
match = re.match(r'\$\{(\w+)\((.*?)\)\}', variable_data)
# 判断一下有没有匹配到--匹配的对象是不是成功了--成功
if match:
# 通过match.groups()去拿到函数名还有参数--定义两个变量去接收,第一个函数名func_name、第二个函数值func_params
func_name, func_params = match.groups()
# 先判断它存在--走if左边的代码--给它做一个切片;若参数值不存在,则返回一个空列表即可
# 参数值有一个或多个--所以需要做一个处理--参数值func_params通过逗号去做一个切片
# 最后再把值重新赋值给它自己
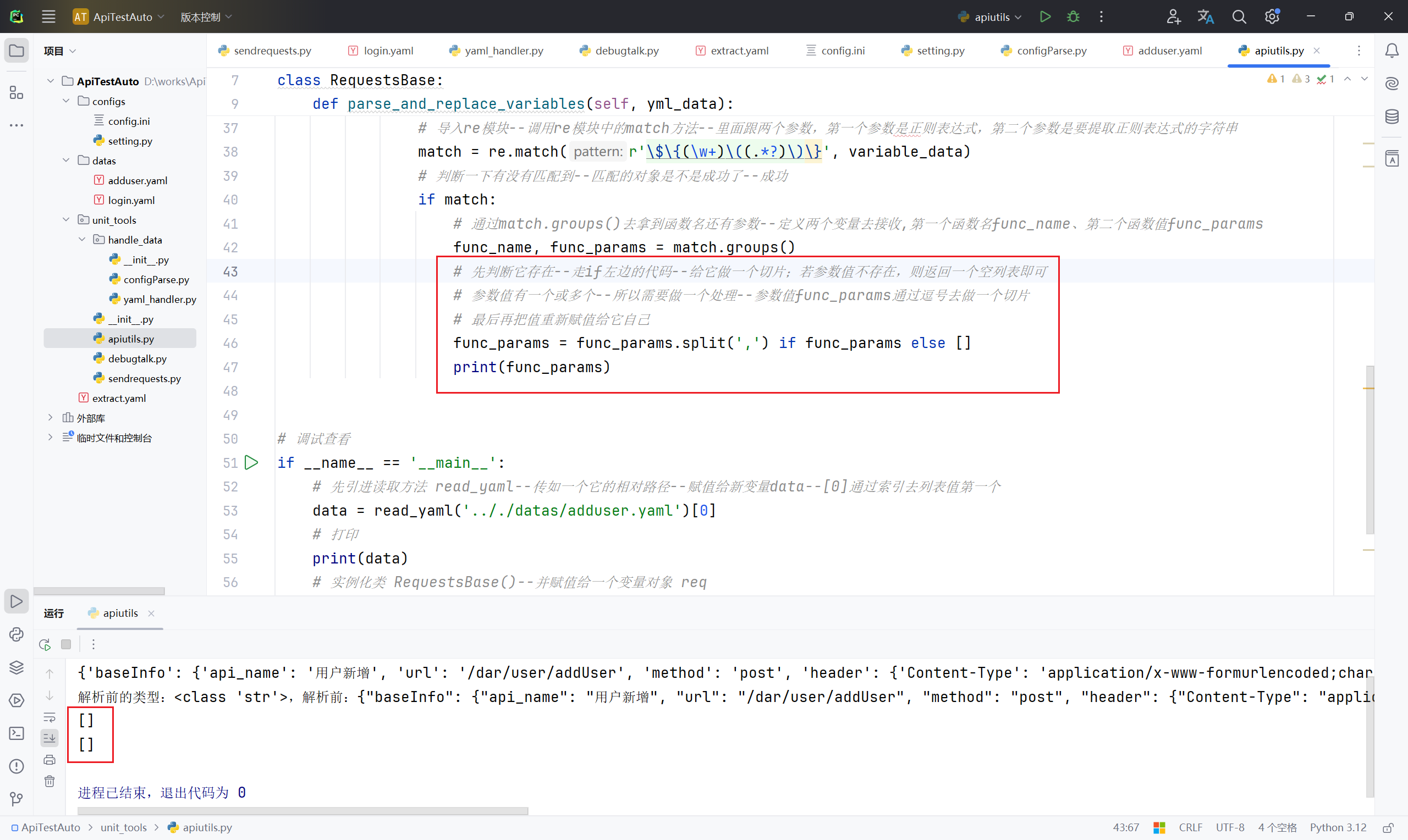
func_params = func_params.split(',') if func_params else []
print(func_params)
# 调试查看
if __name__ == '__main__':
# 先引进读取方法 read_yaml--传如一个它的相对路径--赋值给新变量data--[0]通过索引去列表值第一个
data = read_yaml('.././datas/adduser.yaml')[0]
# 打印
print(data)
# 实例化类 RequestsBase()--并赋值给一个变量对象 req
req = RequestsBase()
# 通过类对象去调用parse_and_replace_variables(data) 这个解析的方法--把读取到的 data 这个yaml数据传给它
req.parse_and_replace_variables(data)12、运行查看打印结果是空列表,这是因为始终读取的都是第一个 "${get_now_time()}" ,它里面没有参数值;
13、修改apiutils.py文件内容;
# 导包
import json
from unit_tools.handle_data.yaml_handler import read_yaml
import re
from unit_tools.debugtalk import DebugTalk
# 创建一个类 RequestsBase
class RequestsBase:
# 创建一个方法 parse_and_replace_variables(解析并且替换变量)--传一个参数 yml_data--要解析的yaml文件的数组
def parse_and_replace_variables(self, yml_data):
"""
解析并替换YAML文件数据中的变量引用,如:${get_extract_data(goodsId,1)}
:param yml_data: 解析的YAML数据
:return: 最终要返回的是dict类型--才能给后续的一些方法调用时使用
"""
# if isinstance(yml_data, str)--判断传进来的数据是什么类型?--后续需要字符串才能做操作的,所以这里先判断是不是字符串格式
# yml_data若是字符串则执行 if 语句左边的代码 直接返回yml_data
# yml_data不是字符串--调用json.dumps(yml_data)模块转成字符串--ensure_ascii=False 参数是可以处理中文
# if else 语句写在一行是 三元运算--通过这一系列之后最终返回一个 新的变量yaml_data_str --它是一个字符串
yml_data_str = yml_data if isinstance(yml_data, str) else json.dumps(yml_data, ensure_ascii=False)
# 打印查看 yaml_data_str
print(f'解析前:{yml_data_str}')
# 用for循环去判断 字符串yml_data_str里面这种标识 "${" 格式出现的次数--加一个'_'下划线表示不需要用到这个变量,是一个占位符的意思
for _ in range(yml_data_str.count("${")):
# if判断这个标识'${' 它包含在字符串yml_data_str里面--并且另一半它 '}' 也包含在字符串yml_data_str里面
if '${' in yml_data_str and '}' in yml_data_str:
# 通过获取到 "${" 标识的起始位置--通过字符串 yml_data_str 的索引 index--获取它的索引的起始位置
strat_index = yml_data_str.index("${")
# 获取结束位置 标识 "}"--再加一个参数 它的开头 strat_index
end_index = yml_data_str.index("}", strat_index)
# 拿到开始、结束位置后--通过字符串切片--起始位置、结束位置+1--为什么+1?--因为python中索引切片是左闭右开的一个规则
# 什么是左闭右开?--开始位置是包含在切片里面的,但是结束元素不包含在切片中,所以得+1
variable_data = yml_data_str[strat_index:end_index + 1]
print(f'函数名:{variable_data}')
# 使用正则表达式提取函数名和参数
# 导入re模块--调用re模块中的match方法--里面跟两个参数,第一个参数是正则表达式,第二个参数是要提取正则表达式的字符串
match = re.match(r'\$\{(\w+)\((.*?)\)\}', variable_data)
# 判断一下有没有匹配到--匹配的对象是不是成功了--成功
if match:
# 通过match.groups()去拿到函数名还有参数--定义两个变量去接收,第一个函数名func_name、第二个函数值func_params
func_name, func_params = match.groups()
# 先判断它存在--走if左边的代码--给它做一个切片;若参数值不存在,则返回一个空列表即可
# 参数值有一个或多个--所以需要做一个处理--参数值func_params通过逗号去做一个切片
# 最后再把值重新赋值给它自己
func_params = func_params.split(',') if func_params else []
print(f'函数值:{func_name}')
# 使用面向对象反射getattr调用函数
# 引如类后直接 实例化类--第二个参数传的是一个函数名 func_name--函数调用 (*func_params)--通过星号把参数值func_params去解包传递给参数func_name
extract_data = getattr(DebugTalk(), func_name)(*func_params)
# 使用正则表达式替换原始字符串中的变量引用为调用后的结果
# 使用正则表达式替换函数re.sub--第一个参数就是需要替换的哪个参数值,第二个参数是解析后得到的数据extract_data,第三个参数是原始解析前的yml_data_str
yml_data_str = re.sub(re.escape(variable_data), str(extract_data), yml_data_str)
# 还原数据,将其转换为字典类型
# 添加异常处理--像这种转换的最好是加一个异常处理
try:
# 直接调用 son.loads(yml_data_str)--把字符串转换成字典
data = json.loads(yml_data_str)
# json转码异常
except json.JSONDecodeError:
# 返回原始数据yml_data_str--赋值给新变量 data
data = yml_data_str
return data
# 调试查看
if __name__ == '__main__':
# 先引进读取方法 read_yaml--传如一个它的相对路径--赋值给新变量data--[0]通过索引去列表值第一个
data = read_yaml('.././datas/adduser.yaml')[0]
# 实例化类 RequestsBase()--并赋值给一个变量对象 req
req = RequestsBase()
# 通过类对象去调用parse_and_replace_variables(data) 这个解析的方法--把读取到的 data 这个yaml数据传给它
res = req.parse_and_replace_variables(data)
print(f'解析后:{res}')14、运行查看打印结果,可以看到"解析前、解析后"的数据信息,函数名、函数值它们两个不在是同样的了;
解析前:{"baseInfo": {"api_name": "用户新增", "url": "/dar/user/addUser", "method": "post", "header": {"Content-Type": "application/x-www-formurlencoded;charset=UTF-8"}}, "testCase": [{"case_name": "用户新增正常校验", "data": {"username": "testadduser", "password": "tset6789890", "role_id": 123456789, "dates": "${get_now_time()}", "phone": 13800000000, "token": "${get_extract_data(goodsId,1)}"}}]}
函数名:${get_now_time()}
函数值:get_now_time
函数名:${get_extract_data(goodsId,1)}
函数值:get_extract_data
解析后:{'baseInfo': {'api_name': '用户新增', 'url': '/dar/user/addUser', 'method': 'post', 'header': {'Content-Type': 'application/x-www-formurlencoded;charset=UTF-8'}}, 'testCase': [{'case_name': '用户新增正常校验', 'data': {'username': 'testadduser', 'password': 'tset6789890', 'role_id': 123456789, 'dates': '1684646092.8515406', 'phone': 13800000000, 'token': '11111111111'}}]}总结详细操作步骤
首先,定义了一个方法 def parse_and_replace_variables(self, yml_data):
然后,传入了一个变量 yml_data --这个变量就是需要解析的一个yaml文件的数据;
第一行代码 yml_data_str = yml_data if isinstance(yml_data, str) else json.dumps(yml_data, ensure_ascii=False)
先去判断一下 if isinstance(yml_data, str) 传进来的数据 它是不是一个字符串
如果是字符串,直接返回回去 yml_data
若不是字符串,调用json序列化 json.dumps(yml_data, ensure_ascii=False) 序列化之后把它转成字符串
最终存到一个新的变量 yml_data_str 里面去
再然后通过下一步使用for循环 for _ in range(yml_data_str.count("${")):
去循环字符串有没有自定义的标识出现的一个次数--这个次数取决于字符串中它出现多少次;这个循环还用于处理所有变量的引用;
通过if判断 if '${' in yml_data_str and '}' in yml_data_str: 这个标识是否包含在字符串里面
如果包含的话,它就找到起始位置,找到起始位置之后再找到结束位置--通过开始、结束位置就可以获取到需要引用的字符串,通过起止位置可以对字符串进行切片,通过切片可以拿到引用的数据,切片引用需要注意"左闭右开"的规则;
使用正则表达式去提取 需要的这个字符串--这个字符串里面的函数名,还有它的参数,有参数提取它的参数
通过这种方式去拿到要匹配的对象
当匹配成功的话
从匹配的对象中去获取函数名还有它的参数--对参数值做一个切片,分割为一个列表
然后使用 *func_params 给它传递就行了
到这一步就是 extract_data = getattr(DebugTalk(), func_name)(*func_params) 使用python里面类的一个反射把结果给返回出去
最后需要做一个替换,就是把原始的字符串里面这种格式替换成 调用后一个结果 extract_data ,再把最后得到的结果给还原一下,转换成一个字典类型--整个过程就是这样的。优化请求头传输格式
15、优化修改debugtalk.py文件内容,添加请求头处理方法;
# 导包
import random # random -- 随机数
import re # re -- 正则表达式
from unit_tools.handle_data.yaml_handler import get_extract_yaml
import time
# 定义一个类 DebugTalk
class DebugTalk:
# 定义一个方法 get_extract_data提取全局配置文件extract.yaml变量--第一个参数 node_name;第二个参数这里默认为空,可以传也可以不传
def get_extract_data(self, node_name, out_format=None):
"""
获取全局yaml文件extract.yaml数据,首先判断out_format是否为数字类型,如果不是就获取下一个节点的value
:param node_name: 全局文件extract.yaml文件中的key--例如:Cookie、access_token_cookie、token
:param out_format: str类型,0:随机去读取;-1:读取全部数据,返回字符串格式;-2:读取全部,返回列表格式;其他值的就按顺序读取
:return:
"""
# 导包引入模块之后--直接调用方法get_extract_yaml()--需要传两个参数,暂时先传一个参数 node_name--返回值赋值给变量data
data = get_extract_yaml(node_name)
# 若是数值类型的--判断第二个参数不等于空 并且 --加一个布尔值--正则表达式,判断传入的第二个参数是数值的形式还是一个字母参数的形式
if out_format is not None and bool(re.compile(r'^[+-]?\d+$').match(str(out_format))):
# 转换格式成int类型--返回赋值给变量out_format
out_format = int(out_format)
# 定义一个字典--或者使用if else
data_value = {
# 若传的这个参数out_format存在--通过self.seq_read(data, out_format)调用
out_format: self.seq_read(data, out_format),
# 若第二参数传入的是 0 -- 通过随机函数-- 随机去读取
0: random.choice(data),
# 传入的是 -1 -- 去读取全部,返回字符串格式--列表怎么转字符串--通过 ','.join(data) 逗号分隔.join() 组成新的字符串
-1: ','.join(data),
# 若传入的是 -2 --读取全部,返回列表格式
-2: ','.join(data).split(',')
}
# 通过data_value取值--取第二个值--返回出去赋值给变量data
data = data_value[out_format]
else:
# 若第二个参数传入的不是数字--调用get_extract_yaml方法--把这两个node_name, out_format参数给它传进来
data = get_extract_yaml(node_name, out_format)
# return--把data值返回出去
return data
# 定义一个方法 seq_read--参入两个参数,第一个data,第二个随机数randoms
def seq_read(self, data, randoms):
""" 获取extract.yaml,第二个参数不为 0、-1、-2的情况下 """
# 直接判断这个参数randoms不是0、-1、-2
if randoms not in [0, -1, -2]:
# 直接返回一个 data--通过这个 randoms去减1--为什么要减1呢?--
return data[randoms - 1]
else:
return None
# 获取当前时间
@classmethod
def get_now_time(cls):
return time.time()
# 定义方法 get_headers--获取请求头--传入一个参数类型params_type
def get_headers(self, params_type):
"""
获取请求头
:param params_type: 参数类型:例如'data'或者'json'
:return:
"""
# 先约定请求头--定义一个字典 headers_mapping
headers_mapping = {
# 如果是data类型--请求头 需要一个字典类型
'data': {'Content-Type': 'application/x-www-formurlencoded;charset=UTF-8'},
# 若是json类型--请求头 这里参数名一样的,参数值不一样
'json': {'Content-Type': 'application/json;charset=UTF-8'}
}
# 通过这个字典取值去获取 headers_mapping.get(params_type)--传入参数 params_type
header = headers_mapping.get(params_type)
# 判断 header 是否为空
if header is None:
# 若是空的话,手动抛出异常
raise ValueError('不支持其他类型的请求头设置!')
# 最后要把结果返回出去
return header
# 测试调试查看
if __name__ == '__main__':
# 实例化类 DebugTalk()
debug = DebugTalk()
# 通过对象取调用方法--第一个参数是goodsId
# 第二个参数(0:随机读取,1~4:按顺序依次读取,-1:读取全部,-2:读取全部,返回列表格式,-3是第一个)
# 根据实际情况其他超出范围会报"索引错误:列表索引超出范围 " IndexError: list index out of range
res = debug.get_extract_data('goodsId', '0')
print(res)16、修改项目根目录 datas 目录文件路径下adduser.yaml文件请求头相关内容,把刚刚定义的请求头get_headers方法添加到对应请求头header的位置下(${get_headers(data)});
- baseInfo:
api_name: 用户新增
url: /dar/user/addUser
method: post
header:
${get_headers(data)}
testCase:
- case_name: 用户新增正常校验
data:
username: testadduser
password: tset6789890
role_id: 123456789
dates: ${get_now_time()}
phone: 13800000000
token: ${get_extract_data(goodsId,1)}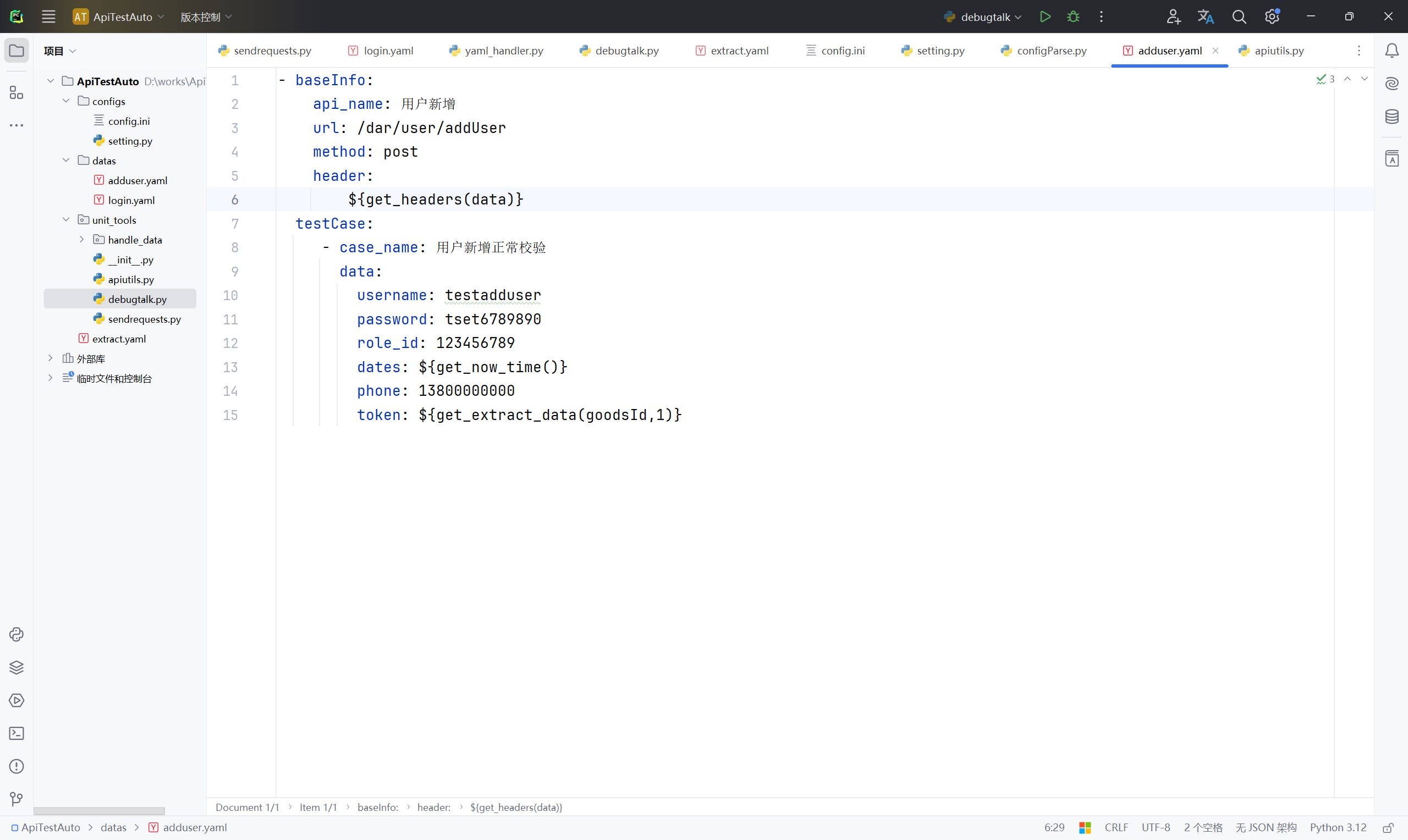
17、优化apiutils.py文件内容,验证新定义封装的请求头处理方法;
# 导包
import json
from unit_tools.handle_data.yaml_handler import read_yaml
import re
from unit_tools.debugtalk import DebugTalk
# 创建一个类 RequestsBase
class RequestsBase:
# 创建一个方法 parse_and_replace_variables(解析并且替换变量)--传一个参数 yml_data--要解析的yaml文件的数组
def parse_and_replace_variables(self, yml_data):
"""
解析并替换YAML文件数据中的变量引用,如:${get_extract_data(goodsId,1)}
:param yml_data: 解析的YAML数据
:return: 最终要返回的是dict类型--才能给后续的一些方法调用时使用
"""
# if isinstance(yml_data, str)--判断传进来的数据是什么类型?--后续需要字符串才能做操作的,所以这里先判断是不是字符串格式
# yml_data若是字符串则执行 if 语句左边的代码 直接返回yml_data
# yml_data不是字符串--调用json.dumps(yml_data)模块转成字符串--ensure_ascii=False 参数是可以处理中文
# if else 语句写在一行是 三元运算--通过这一系列之后最终返回一个 新的变量yaml_data_str --它是一个字符串
yml_data_str = yml_data if isinstance(yml_data, str) else json.dumps(yml_data, ensure_ascii=False)
# 打印查看 yaml_data_str
print(f'解析前:{yml_data_str}')
# 用for循环去判断 字符串yml_data_str里面这种标识 "${" 格式出现的次数--加一个'_'下划线表示不需要用到这个变量,是一个占位符的意思
for _ in range(yml_data_str.count("${")):
# if判断这个标识'${' 它包含在字符串yml_data_str里面--并且另一半它 '}' 也包含在字符串yml_data_str里面
if '${' in yml_data_str and '}' in yml_data_str:
# 通过获取到 "${" 标识的起始位置--通过字符串 yml_data_str 的索引 index--获取它的索引的起始位置
strat_index = yml_data_str.index("${")
# 获取结束位置 标识 "}"--再加一个参数 它的开头 strat_index
end_index = yml_data_str.index("}", strat_index)
# 拿到开始、结束位置后--通过字符串切片--起始位置、结束位置+1--为什么+1?--因为python中索引切片是左闭右开的一个规则
# 什么是左闭右开?--开始位置是包含在切片里面的,但是结束元素不包含在切片中,所以得+1
variable_data = yml_data_str[strat_index:end_index + 1]
# print(f'函数名:{variable_data}')
# 使用正则表达式提取函数名和参数
# 导入re模块--调用re模块中的match方法--里面跟两个参数,第一个参数是正则表达式,第二个参数是要提取正则表达式的字符串
match = re.match(r'\$\{(\w+)\((.*?)\)\}', variable_data)
# 判断一下有没有匹配到--匹配的对象是不是成功了--成功
if match:
# 通过match.groups()去拿到函数名还有参数--定义两个变量去接收,第一个函数名func_name、第二个函数值func_params
func_name, func_params = match.groups()
# 先判断它存在--走if左边的代码--给它做一个切片;若参数值不存在,则返回一个空列表即可
# 参数值有一个或多个--所以需要做一个处理--参数值func_params通过逗号去做一个切片
# 最后再把值重新赋值给它自己
func_params = func_params.split(',') if func_params else []
# print(f'函数值:{func_name}')
# 使用面向对象反射getattr调用函数
# 引如类后直接 实例化类--第二个参数传的是一个函数名 func_name--函数调用 (*func_params)--通过星号把参数值func_params去解包传递给参数func_name
extract_data = getattr(DebugTalk(), func_name)(*func_params)
print(f'提取到的结果:{extract_data}')
# 使用正则表达式替换原始字符串中的变量引用为调用后的结果
# 使用正则表达式替换函数re.sub--第一个参数就是需要替换的哪个参数值,第二个参数是解析后得到的数据extract_data,第三个参数是原始解析前的yml_data_str
yml_data_str = re.sub(re.escape(variable_data), str(extract_data), yml_data_str)
# 还原数据,将其转换为字典类型
# 添加异常处理--像这种转换的最好是加一个异常处理
try:
# 直接调用 son.loads(yml_data_str)--把字符串转换成字典
data = json.loads(yml_data_str)
# json转码异常
except json.JSONDecodeError:
# 返回原始数据yml_data_str--赋值给新变量 data
data = yml_data_str
return data
# 调试查看
if __name__ == '__main__':
# 先引进读取方法 read_yaml--传如一个它的相对路径--赋值给新变量data--[0]通过索引去列表值第一个
data = read_yaml('.././datas/adduser.yaml')[0]
# 实例化类 RequestsBase()--并赋值给一个变量对象 req
req = RequestsBase()
# 通过类对象去调用parse_and_replace_variables(data) 这个解析的方法--把读取到的 data 这个yaml数据传给它
res = req.parse_and_replace_variables(data)
print(f'解析后:{res}')
解析前:{"baseInfo": {"api_name": "用户新增", "url": "/dar/user/addUser", "method": "post", "header": "${get_headers(data)}"}, "testCase": [{"case_name": "用户新增正常校验", "data": {"username": "testadduser", "password": "tset6789890", "role_id": 123456789, "dates": "${get_now_time()}", "phone": 13800000000, "token": "${get_extract_data(goodsId,1)}"}}]}
提取到的结果:{'Content-Type': 'application/x-www-formurlencoded;charset=UTF-8'}
提取到的结果:1684646092.8515406
提取到的结果:11111111111
解析后:{'baseInfo': {'api_name': '用户新增', 'url': '/dar/user/addUser', 'method': 'post', 'header': "{'Content-Type': 'application/x-www-formurlencoded;charset=UTF-8'}"}, 'testCase': [{'case_name': '用户新增正常校验', 'data': {'username': 'testadduser', 'password': 'tset6789890', 'role_id': 123456789, 'dates': '1684646092.8515406', 'phone': 13800000000, 'token': '11111111111'}}]}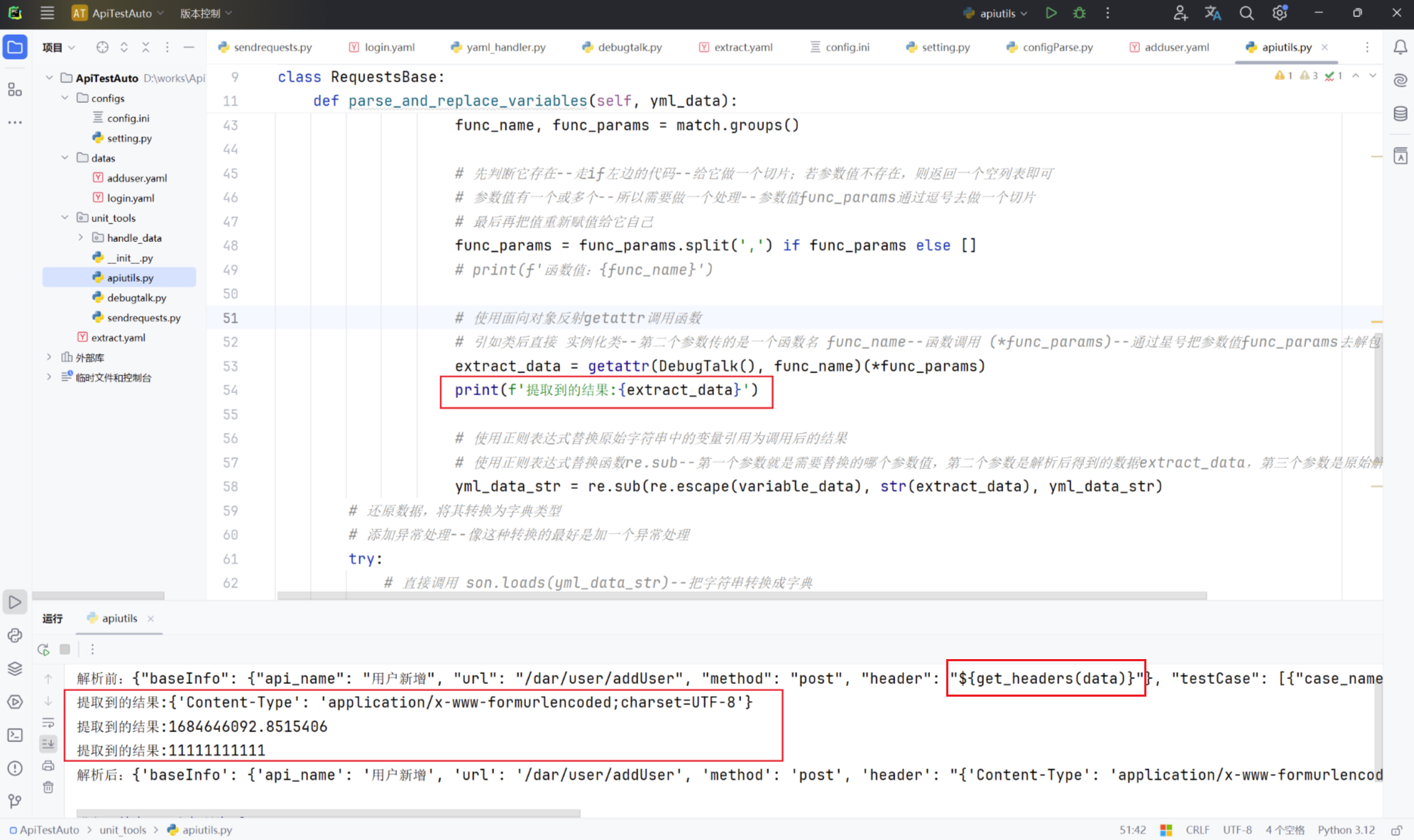
未完待续。。。