这篇文章我不展开讲服务路由、链路透传、MQ 灰度、分布式任务灰度这些后续动作,只聚焦最前面的识别层:如何在网关入口把一条原始请求加工成可计算的灰度对象,再用一套通用规则模型做匹配,最终产出唯一、稳定的灰度结果。
一、规则匹配之前,必须先有特征补全层
如果直接拿原始请求去做灰度规则匹配,很多规则其实根本没法算。
比如你想配这样的规则:
- 指定用户进入灰度
- 指定地区进入灰度
- 指定入口网关进入灰度
- 指定时间窗口内进入灰度
这些信息并不一定天然就在原始请求里。最常见的几个例子就是:
- 用户 ID 往往要先通过
token -> uid解析出来 - 地区往往要先通过
IP -> 地区转换出来 - 请求域名要从代理头或者
Host头里拿 - 入口应用名要由网关自己补进去
- 请求时间也最好统一补成标准元数据
所以在规则匹配层 之前,还需要一层特征补全层。这层的职责不是做业务判断,而是把原始请求加工成一份"规则引擎可以直接消费的标准特征集合"。
在这套方案里,这件事放在 Spring Cloud Gateway 的入口链路上做。补全完成后,会把这些特征重新放回请求上下文里,本质上还是写入 ServerWebExchange 对应的请求对象中。后面的规则匹配层不再关心 token 怎么转 uid、IP 怎么转地区,而是统一从 ServerWebExchange 里拿它需要的元数据值。
可以把这个过程理解成下面这样:
java
ServerHttpRequest newRequest = exchange.getRequest().mutate()
.header("X-UID", uid)
.header("X-REQUEST-IP", ip)
.header("X-REGION", region)
.header("X-HOST", host)
.header("X-REQ-APPLICATION", appName)
.header("X-REQUEST-TIME", requestTime)
.build();
ServerWebExchange newExchange = exchange.mutate().request(newRequest).build();这样做有两个非常直接的好处。
第一,规则匹配层只负责一件事:拿标准特征,执行匹配逻辑 。
第二,整条网关过滤链路都围绕同一个 ServerWebExchange 工作,后面的匹配、打标、路由都可以共享同一份元数据,不需要每一层再各自重新解析。
特征补全层 规则匹配层 在网关层面的落地实现都是单独的Filter 特征补全层负责加工ServerWebExchange 的Header, 规则匹配层 负责产出匹配当前请求的泳道编码(灰度环境编码),最终回写回ServerWebExchange 的一个固定Header X-LANE-CODE .
二、RuleExpression 怎么设计,为什么它能支持复杂多维规则
灰度规则最怕两件事:
- 匹配维度越来越多
- 规则组合越来越复杂
如果规则模型只支持一组平铺条件,比如"字段 A 等于 xx,字段 B 等于 yy",那很快就不够用了。真实业务里更常见的是下面这种表达方式:
- 指定用户白名单
或者指定地区 - 指定入口网关
并且指定路径 - 某个时间窗口内
并且某个查询参数命中 - 一层
AND里面再嵌一层OR
所以规则模型不能是平铺结构,而要设计成表达式树 。这也是 RuleExpression 的核心价值 (这也是常见的营销风控相关的复杂规则设计的基础数据模型)。
2.1 RuleExpression 的整体结构
简化以后,它的设计思路大概是这样:
java
class RuleExpression {
NodeType type;
LogicRelation relation;
List<RuleExpression> children;
Condition condition;
}这里最关键的是四个字段。
type
用来说明当前节点是什么类型。
- 如果是逻辑节点,那它负责组织子表达式
- 如果是条件节点,那它负责描述一个可直接执行的叶子条件
也就是说,type 决定了当前节点是"继续往下组合",还是"已经到了最终判断条件"。
relation
这个字段只有逻辑节点才会用到,表示子节点之间是什么关系。
ANDOR
有了它,规则就不再是固定的一条条件链,而是可以自由拼装。
children
这个字段是表达式树真正能"长起来"的关键。
- 逻辑节点通过
children挂子节点 - 子节点既可以还是逻辑节点,也可以是叶子条件节点
这意味着规则可以无限扩展成多层结构,而不是只能停留在一层平铺判断。
condition
这个字段只在叶子节点上有意义,描述的就是一个真正要执行的匹配条件。
它本身通常又会拆成四个部分:
java
class Condition {
ParamType paramType;
Operator operator;
String paramName;
String paramValue;
}分别解决四个问题:
paramType:值从哪里拿operator:怎么比较paramName:拿哪个字段paramValue:拿到以后要和什么目标值比较
2.2 它为什么适合复杂多维规则
这套设计最重要的一点,不是"字段多",而是复杂度不靠加表字段,而靠表达式树组合出来。
也就是说:
- 匹配维度变多,不需要推翻模型
- 条件组合变复杂,不需要改代码结构
- 业务只是在"配规则",不是在"改逻辑"
这其实就是灰度规则体系能不能长期演进的分水岭。
2.3 例子一:白名单用户或者指定地区,并且命中订单路径
这个规则翻译成人话是:
用户在白名单或者用户地区是上海,并且请求路径命中 /order/**
如果用表达式树表示,大概可以写成这样:
json
{
"type": "LOGIC",
"relation": "AND",
"children": [
{
"type": "LOGIC",
"relation": "OR",
"children": [
{
"type": "EXPRESSION",
"condition": {
"paramType": "header",
"paramName": "X-UID",
"operator": "regex",
"paramValue": "^(1001|1002|1003)$"
}
},
{
"type": "EXPRESSION",
"condition": {
"paramType": "header",
"paramName": "X-REGION",
"operator": "=",
"paramValue": "shanghai"
}
}
]
},
{
"type": "EXPRESSION",
"condition": {
"paramType": "uri",
"operator": "match",
"paramValue": "/order/**"
}
}
]
}这个例子很能说明问题:规则不是靠"为白名单单独写一套逻辑,为地区单独写一套逻辑,为路径再写一套逻辑",而是都统一落在表达式树里。
2.4 例子二:指定入口网关、指定域名、指定时间窗
这个规则翻译成人话是:
请求必须来自指定入口网关,请求域名必须是目标域名,并且当前请求时间处在规定时间窗内
它也可以很自然地落到表达式树中:
json
{
"type": "LOGIC",
"relation": "AND",
"children": [
{
"type": "EXPRESSION",
"condition": {
"paramType": "gateway_app_name",
"operator": "=",
"paramValue": "app-gateway"
}
},
{
"type": "EXPRESSION",
"condition": {
"paramType": "host",
"operator": "=",
"paramValue": "api.xxx.com"
}
},
{
"type": "EXPRESSION",
"condition": {
"paramType": "header",
"paramName": "X-REQUEST-TIME",
"operator": "TimeAfter",
"paramValue": "2026-05-18 00:00:00"
}
},
{
"type": "EXPRESSION",
"condition": {
"paramType": "header",
"paramName": "X-REQUEST-TIME",
"operator": "TimeBefore",
"paramValue": "2026-05-18 23:59:59"
}
}
]
}这个例子说明了另一件事:复杂规则只是配置复杂,不是代码复杂。
只要规则模型抽象对了,后面业务加维度、改维度、组合维度,基本都只是配表达式树,而不是不断改匹配引擎本身。
三、规则匹配是怎么跑起来的:取值、求值、裁决、放量
有了特征补全层,也有了 RuleExpression 这套规则模型,接下来就是运行时到底怎么算出结果。
整个过程可以拆成四步。
3.1 先从 ServerWebExchange 里把真实值取出来
规则引擎执行某个条件时,第一步不是比较,而是取值。
它会先看 paramType:
- 如果是
header,就从请求头里取 - 如果是
query,就从查询参数里取 - 如果是
cookie,就从 cookie 里取 - 如果是
uri,就拿请求路径 - 如果是
ip,就拿补全后的请求 IP - 如果是
host,就拿补全后的域名 - 如果是
gateway_app_name,就拿入口应用名 - 如果是
req_method,就拿请求方法
也就是说,规则层本身不负责生产特征,它只负责消费特征。
所以前面的特征补全层不是可选项,而是规则匹配能否成立的基础。
3.2 再按操作符执行叶子条件判断
取到真实值以后,才轮到真正的条件判断。
常见的操作符一般包括:
=:精确匹配regex:正则匹配contains:包含匹配startsWith/endsWith:前后缀匹配match/pathPattern:路径模式匹配exclude:排除匹配TimeBefore/TimeAfter:时间窗匹配
这一层只解决一件事:单条件到底是真还是假。
3.3 在 RuleMatchEngine 里递归执行整棵表达式树
真正把复杂规则跑起来的地方,是规则执行引擎,也就是这里要重点提到的 RuleMatchEngine。
它的逻辑其实很清晰:
- 如果当前节点是叶子条件节点,就直接判断这个条件是否成立
- 如果当前节点是逻辑节点,就递归判断所有子节点,然后用
AND或OR合并结果
简化后的思路大概就是这样:
java
boolean match(node, exchange) {
if (node.type == EXPRESSION) {
return evaluate(node.condition, exchange);
}
if (node.relation == AND) {
for (child in node.children) {
if (!match(child, exchange)) {
return false;
}
}
return true;
}
if (node.relation == OR) {
for (child in node.children) {
if (match(child, exchange)) {
return true;
}
}
return false;
}
return false;
}这里其实有一个非常关键的点,就是短路逻辑 这个非常关键,在QPS很大的情况下会大大减缓匹配带来的性能损耗 。 其次也需要注意 常规来讲一个泳道环境的 匹配规则不要设计的层级过深
AND 的短路
对于 A AND B AND C 来说,只要 A 不成立,后面的 B、C 就没必要继续算了。
因为整个表达式已经不可能为真。
OR 的短路
对于 A OR B OR C 来说,只要 A 已经成立,后面的 B、C 也没必要再算了。
因为整个表达式已经确定为真。
这个逻辑看起来普通,但在灰度规则里非常重要。因为规则一旦多起来、层级一旦深起来,如果每次都把整棵树完全遍历一遍,网关这条热路径的计算成本会越来越高。
而短路逻辑的意义就在这里:
- 少做无意义计算
- 降低热路径开销
- 让表达式执行更符合直觉
所以像 A OR B 这种规则,匹配到 A 以后就没必要继续匹配 B 了,这不是"漏执行",而是明确的优化策略,也是规则引擎应该具备的基本能力。
3.4 命中规则以后,还要做优先级裁决和权重放量
规则命中以后,其实还没有结束。
因为一条请求理论上可能同时满足多个泳道的条件,所以还要有一层裁决逻辑。
这里的核心原则一般是:
- 先按泳道优先级从高到低遍历
- 泳道内部再按规则组优先级从高到低匹配
- 只要某个泳道命中了,就以它为准,不再继续往后匹配别的泳道
也就是说,运行时关心的不是"命中了多少条规则",而是"最终应该进入哪个唯一泳道"。
但即便某个泳道命中了规则,也不代表一定放进去。后面通常还会有一层权重放量。
这套思路我比较认同的一点是,它不是用随机数放量,而是用稳定分桶。
大概做法就是:
- 先拿用户 ID 作为稳定标识
- 对用户 ID 做哈希
- 对
100取模 - 如果结果小于当前泳道权重,就进入灰度,否则不进入
伪代码大概是这样:
java
int hash = Math.abs(uid.hashCode()) % 100;
if (hash < weight) {
return laneCode;
}
return null;这样做最大的价值不是"实现简单",而是同一个用户的命中结果稳定。
不会出现这次进了灰度、下一次又回到正常流量的情况。对于用户体验、数据观测、问题排查来说,这个稳定性都非常重要。
所以整个运行时匹配链路,其实可以概括成一句话:
规则先判断"有没有资格进这个泳道",权重再判断"有资格的人里放多少进去"。
四、管理端怎么把规则配置真正变成运行时能力
如果只有运行时规则引擎,没有管理端,这套东西很快就会走向手工维护、难以回溯、容易出错。
所以完整的灰度流量识别方案,一定要有管理端来承接配置能力。
这块我更倾向于拆成三件事来看。
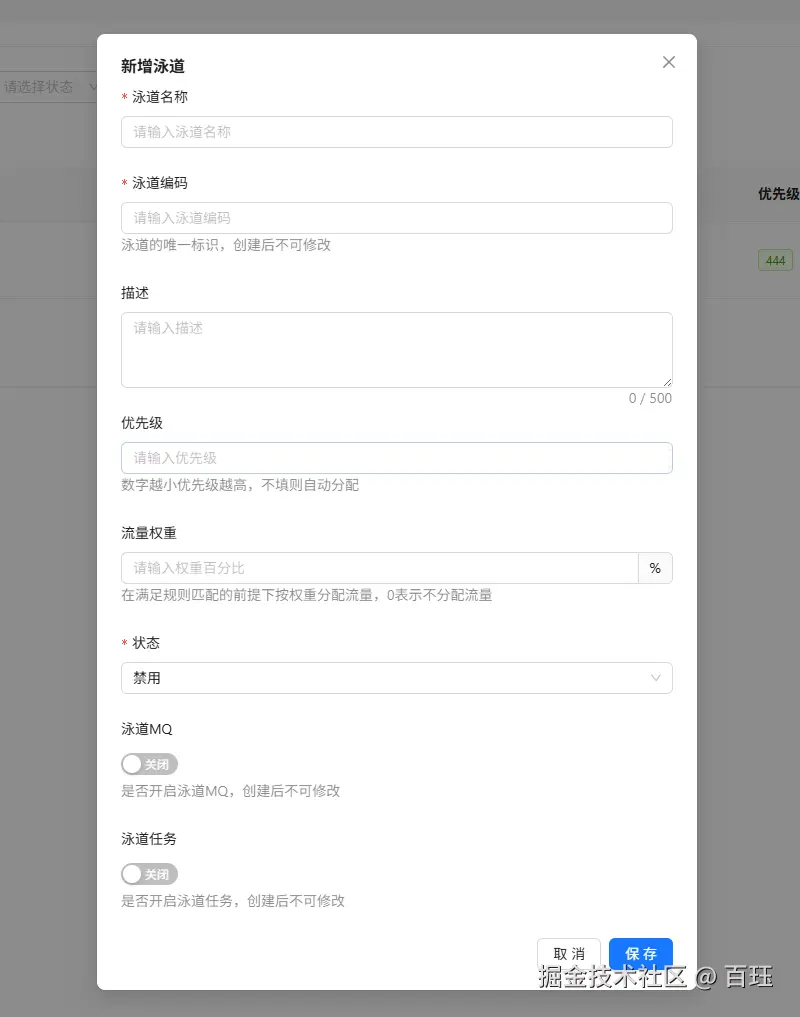
4.1 泳道管理
泳道本身描述的是一个灰度目标,通常至少会包含这些信息:
- 泳道编码
- 是否启用
- 优先级
- 权重
- 是否开启任务灰度
- 是否开启 MQ 灰度
这里最关键的还是优先级和权重:
- 优先级解决"多个泳道同时命中怎么办"
- 权重解决"命中以后放多少流量进去"
4.2 规则组管理
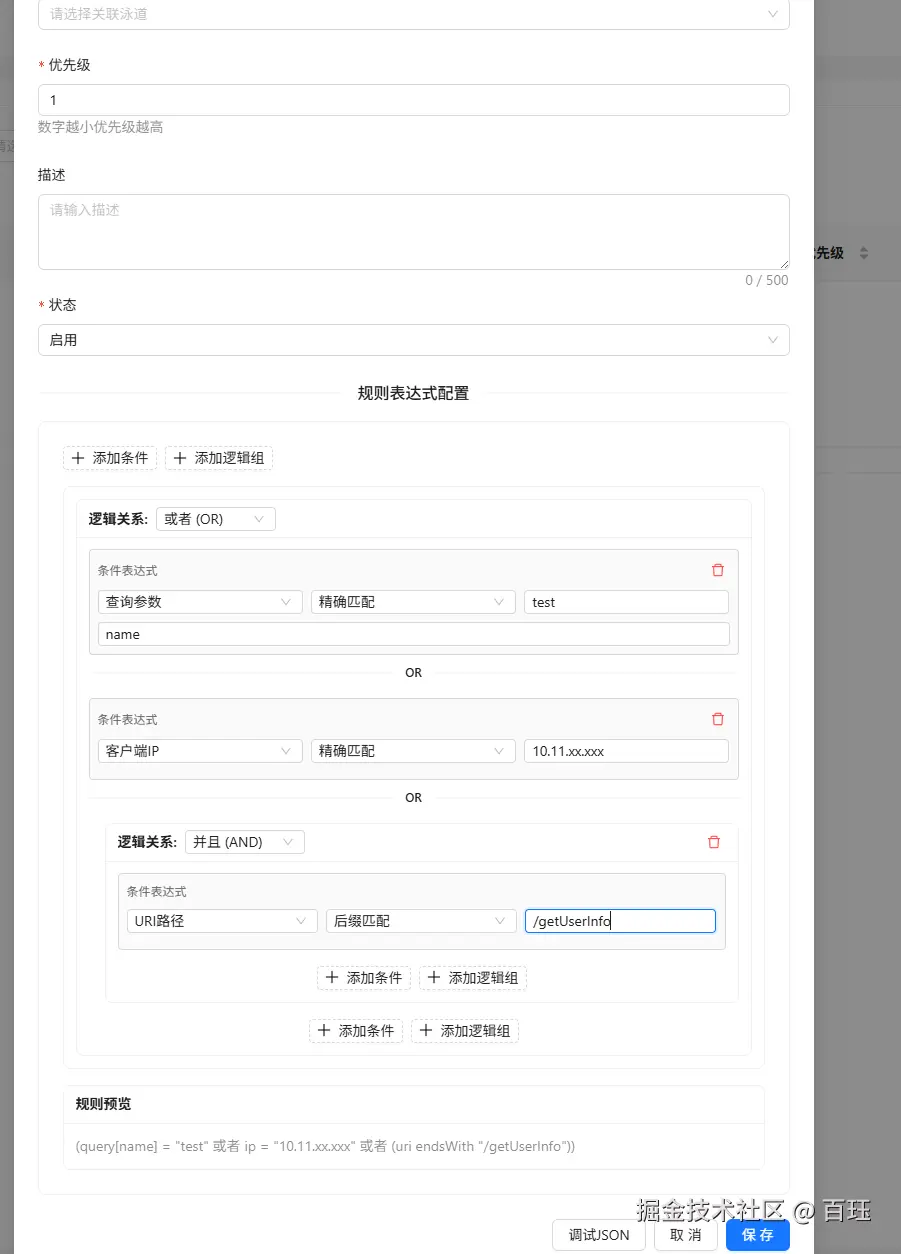
规则组是挂在泳道下面的。
一个泳道可以有多条规则组,规则组之间也有优先级。这样做有几个实际好处:
- 便于把同一个泳道下不同来源的规则拆开管理
- 便于做规则级别的启停,而不是整条泳道一起开关
- 便于做诊断,知道到底是哪一组规则命中了
规则组里最关键的字段其实就两个:
- 优先级
- 规则表达式 JSON
这里把 RuleExpression 序列化成 JSON 存下来,是非常关键的一步。因为这意味着管理端和运行时交换的不是某个临时对象,而是一份统一的规则语言。
4.3 配置推送、热更新、预处理
管理端配完规则后,运行时当然不能每次请求都回数据库查一遍,这样太重了。
更合理的方式一般是:
- 管理端把启用中的泳道和规则组组装成统一配置
- 推送到配置中心
- 网关节点监听配置变化
- 配置变更后在内存里热更新
4.4 规则验证能力一定要有
这一点在实际落地里特别实用。
因为灰度规则一旦复杂起来,只靠人眼看配置,其实很难判断一条请求会不会命中。尤其当规则开始出现多层 AND、OR 嵌套时,单靠脑子推演很容易出错。
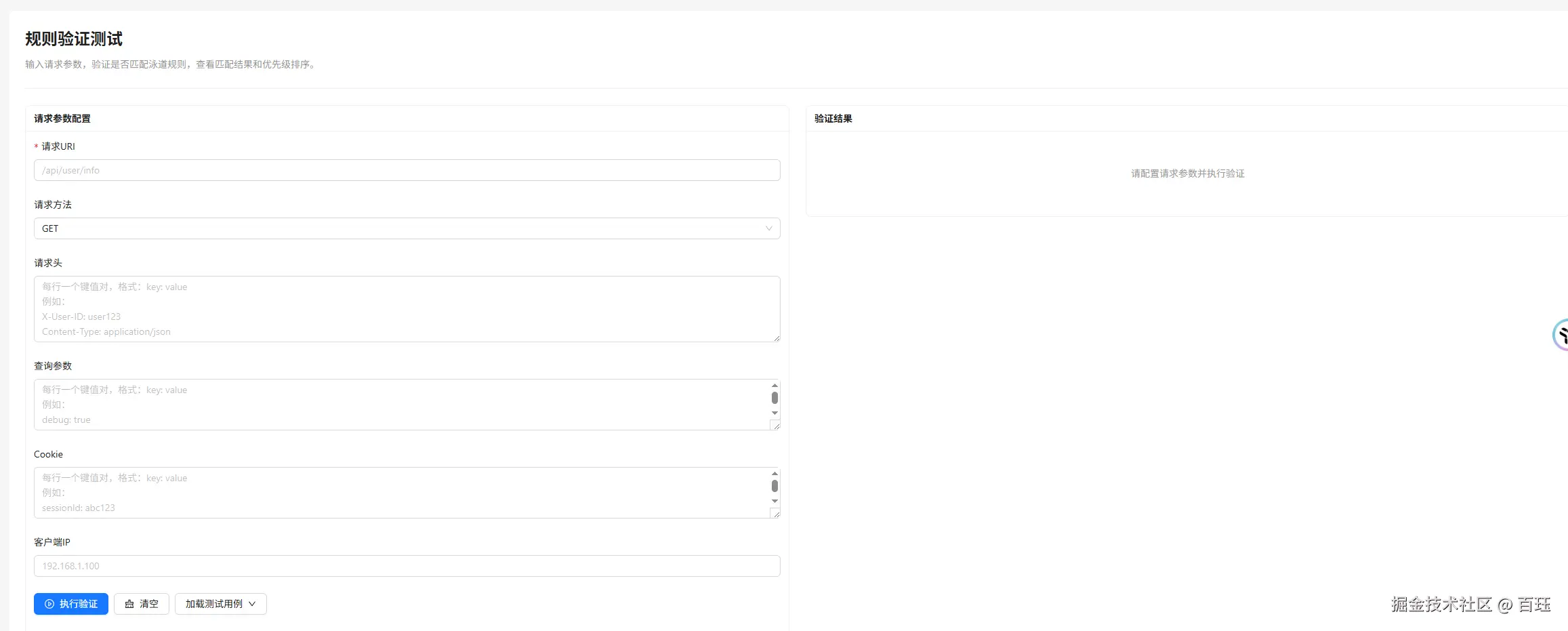
所以管理端最好能提供一个"模拟请求验证"能力,让你输入:
- URI
- Method
- Header
- Query
- Cookie
- Client IP
然后直接告诉你:
- 命中了哪些泳道
- 命中了哪些规则组
- 命中的条件是什么
这个能力不是为了替代运行时,而是为了提升配置可解释性和排障效率。
不过这里有一个边界要说清楚:
管理端的规则验证结果,更偏向"诊断视角";而运行时最终结果,还会继续叠加优先级裁决和权重放量。
所以管理端说"这条请求理论上命中了多个泳道",不代表线上最终会在多个泳道之间做选择。真正运行时只会按优先级走到唯一结果。
总结
灰度流量匹配这件事,真正落地下来绝对不是"写几条规则"这么简单。
它至少要拆成一整条完整链路:
- 前面先做特征补全
- 中间用
RuleExpression做复杂多维规则表达 - 运行时在
RuleMatchEngine里做递归匹配和短路求值 - 再通过优先级裁决 和稳定分桶得到最终唯一结果
- 最后由管理端和配置中心把这套能力真正跑起来