目录
[重大坑位一:Windows 下缺少 triton 包](#重大坑位一:Windows 下缺少 triton 包)
一定要切到sam3环境,conda activate sam3,Y:
cd Y:\miniconda_\sam3
pip install -e .
pip install -e ".notebooks"
git clone https://gitclone.com/github.com/facebookresearch/sam3.git
安装
前提条件
- Python 3.12 或更高版本
- PyTorch 2.7 或更高版本
- 支持CUDA 12.6及以上的CUDA兼容显卡
- 创建新的Conda环境:
conda create -n sam3 python=3.12
conda deactivate
conda activate sam3- 安装支持 CUDA 的 PyTorch:
pip install torch==2.10.0 torchvision --index-url https://download.pytorch.org/whl/cu128- 克隆仓库并安装包:
git clone https://github.com/facebookresearch/sam3.git
cd sam3
pip install -e .- 安装额外的依赖,比如笔记本或开发:
# For running example notebooks
pip install -e ".[notebooks]"
# For development
pip install -e ".[train,dev]"- 可选择的依赖以加快推理
pip install einops ninja && pip install flash-attn-3 --no-deps --index-url https://download.pytorch.org/whl/cu128
pip install git+https://github.com/ronghanghu/cc_torch.git下载sam3模型:
直接访问 SAM3 在 ModelScope 上的模型页面进行下载
- 访问地址 :
https://modelscope.cn/models/facebook/sam3
一堆报错:
(1)No module named 'pkg_resources'
pip install setuptools==70.0.0
(2)
重大坑位一:Windows 下缺少 triton 包
直接运行会报 No module named 'triton' 官方 triton 不支持 Windows,但社区大佬已编译好替代版:
pip install triton-windows==3.3.0.post19装完这步基本解决 90% 人的卡死问题
(3)
(sam3) Y:\miniconda_\sam3>python -c "import torch; print('CUDA可用:', torch.cuda.is_available()); print('显卡:', torch.cuda.get_device_name(0) if torch.cuda.is_available() else '无')"
CUDA可用: True
显卡: NVIDIA GeForce RTX 2060
(sam3) Y:\miniconda_\sam3>python -c "from sam3.model_builder import build_sam3_image_model; model = build_sam3_image_model(); print('文本编码器存在:', hasattr(model, 'text_encoder'))"
文本编码器存在: False
明确问题:文本编辑器不存在,模型从modelscope下载
图片识别代码:
python
import torch
import matplotlib.pyplot as plt
from PIL import Image
from sam3.model_builder import build_sam3_image_model
from sam3.model.sam3_image_processor import Sam3Processor
from sam3.visualization_utils import plot_results
# 加载模型(会自动读取本地 sam3.pt)
model = build_sam3_image_model()
print(" 模型加载成功!模型类型:", type(model))
processor = Sam3Processor(model,
confidence_threshold=0.1)
# 加载测试图片
image = Image.open("assets/images/test_image.jpg")
# 设置图像(这一步会做全图编码)
inference_state = processor.set_image(image)
print("设置图片成功")
# 文本提示分割(换成你想要的词)
inference_state = processor.set_text_prompt(state=inference_state, prompt="person")
# 或者分割鞋子:prompt="shoe"
# 或者试试:prompt="foot" / "sock" / "person" / "hat" 都好使
print("Text prompt set successfully.")
masks = inference_state["masks"]
print("\n===== 结果 =====")
print(f"检测到目标数量:{len(masks)}")
if len(masks) > 0:
plot_results(image, inference_state)
plt.show()
else:
print(" 未检测到目标")
# 自动重试其他词问题2:识别不出目标
processor = Sam3Processor(model,
confidence_threshold=0.1)这里手动把置信度门槛挑到0.1问题3:胡乱识别,识别结果200个
原因:checkpoint 根本没有正确加载,不知道什么时候被注释了
STEP 1:修 model_builder.py(必须)
找到:
if checkpoint_path is not None:
with open(checkpoint_path, "rb") as f:
checkpoint = torch.load(f, map_location="cpu")
#_load_checkpoint(model, checkpoint_path)改成👇:
if checkpoint_path is not None:
_load_checkpoint(model, checkpoint_path)取消注释
prompt="person":
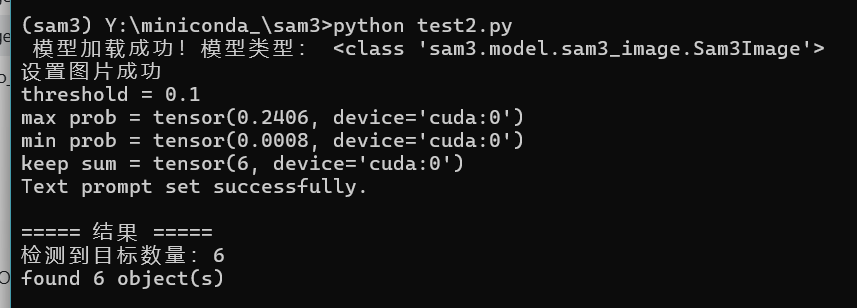
prompt="shoe":
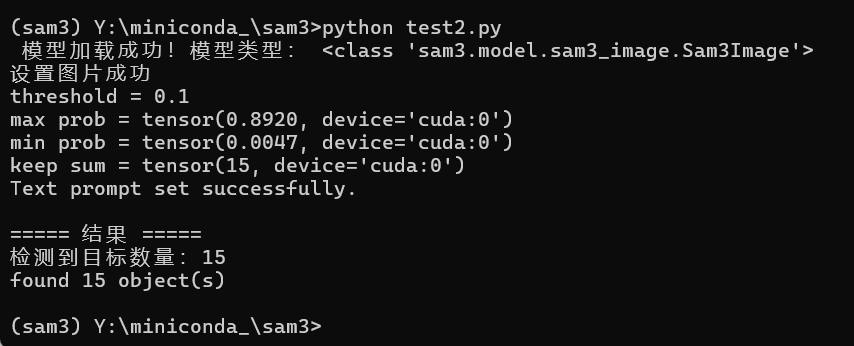

问题4:如何在pycharm中使用conda环境,
直接在终端:Y:\miniconda\Scripts\activate sam3
视频识别代码:
get_mask_hash,calculate_iou,fuse_match,filter_invalid_target这几个函数是为了防止掩码颜色乱跳,当然还有待优化
python
import os
os.environ['ULTRALYTICS_AUTOUPDATE'] = '0'
import torch
import cv2
import numpy as np
from pathlib import Path
from ultralytics.models.sam import SAM3SemanticPredictor
import hashlib
# 【字典】存储 目标ID → 固定颜色,全程只赋值一次,永不修改
id2color = {}
# 【字典】存储上一帧的所有目标:{目标ID: 目标边框坐标}
prev_boxes = {}
# 【字典】存储上一帧所有目标的中心点:{目标ID: (中心x, 中心y)}
prev_centers = {}
# 【最大允许匹配距离】单位:像素
# 两个目标中心点超过200像素,直接判定不是同一个物体
MAX_DIST = 200
# ========== 配置参数 ==========
VIDEO_PATH = r"Y:/miniconda_/sam3/assets/videos/bedroom.mp4"
TEXT_PROMPT = "person" # 分割目标
CONF_THRESHOLD = 0.25
OUTPUT_PATH = "Y:/miniconda_/sam3/assets/out/bedroom_person_segmented2.mp4"
MODEL_PATH = "Y:/miniconda_/sam3/weights/sam3.pt" # 请确保sam3.pt文件在当前目录或指定路径
# [剔除错误id]掩码最小面积阈值(根据视频分辨率调整,720P设500,1080P设1000)
MIN_MASK_AREA = 500
#------------------------------------------------新增颜色跟踪的三个函数
def get_mask_hash(mask):#(1)给每个分割目标生成唯一 ID
# 1. 将掩码转为布尔值:>0.5 = 属于目标,否则=背景
mask_bool = mask > 0.5
# 2. 取出所有属于目标的像素坐标 (y坐标, x坐标)
coords = np.where(mask_bool)
# 3. 如果掩码为空(没有目标),直接返回None
if len(coords[0]) == 0:
return None
# 4. 找到目标的上下左右边界(最小/最大坐标)
y_min, y_max = np.min(coords[0]), np.max(coords[0])
x_min, x_max = np.min(coords[1]), np.max(coords[1])
# 5. 计算目标中心点坐标 (cx, cy)
cx, cy = (x_min + x_max) / 2, (y_min + y_max) / 2
# 6. 计算目标宽度 w 和高度 h
w, h = x_max - x_min, y_max - y_min
# 7. 把中心点、宽高拼成唯一字符串(作为目标特征)
feat = f"{cx:.1f}_{cy:.1f}_{w:.1f}_{h:.1f}"
# 8. 用MD5哈希把特征转为8位唯一ID(相当于身份证号)
return hashlib.md5(feat.encode()).hexdigest()[:8]
def calculate_iou(box1, box2):#(2)计算重叠度,两帧的重叠面积占总面积占比
# 1. 拆解box1:左上角(x1_1,y1_1),右下角(x2_1,y2_1)
x1_1, y1_1, x2_1, y2_1 = box1
# 2. 拆解box2:左上角(x1_2,y1_2),右下角(x2_2,y2_2)
x1_2, y1_2, x2_2, y2_2 = box2
# 3. 计算两个框重叠区域的左上角坐标(取最靠右、最靠下)
inter_x1 = max(x1_1, x1_2)
inter_y1 = max(y1_1, y1_2)
# 4. 计算两个框重叠区域的右下角坐标(取最靠左、最靠上)
inter_x2 = min(x2_1, x2_2)
inter_y2 = min(y2_1, y2_2)
# 5. 计算重叠区域面积(max(0,...)防止负数,不重叠=0)
inter_area = max(0, inter_x2 - inter_x1) * max(0, inter_y2 - inter_y1)
# 6. 计算box1自身面积
area1 = (x2_1 - x1_1) * (y2_1 - y1_1)
# 7. 计算box2自身面积
area2 = (x2_2 - x1_2) * (y2_2 - y1_2)
# 8. 计算并集面积(两个框合起来的面积,避免重复计算重叠区)
union = area1 + area2 - inter_area
# 9. 返回 IoU = 重叠面积 / 并集面积(范围0~1,越大越重合)
return inter_area / union if union > 0 else 0
def fuse_match(box):#(3)IoU + 距离 综合匹配,
# 1. 计算当前目标框的中心点坐标 (cx, cy)
cx = (box[0] + box[2]) / 2
cy = (box[1] + box[3]) / 2
# 2. 初始化:最佳匹配ID、最高得分
best_id = None
best_score = -1.0
# 3. 遍历上一帧所有目标,找最可能匹配的同一个物体
for pid, pbox in prev_boxes.items():
# 3.1 计算当前框 与 上一帧某个框 的 IoU
iou = calculate_iou(box, pbox)
# 3.2 获取上一帧目标的中心点
pcx, pcy = prev_centers.get(pid, ((pbox[0]+pbox[2])/2, (pbox[1]+pbox[3])/2))
# 3.3 计算两个中心点的欧几里得距离(像素距离)
dist = ((cx - pcx)**2 + (cy - pcy)**2)**0.5
print(f"中心距离={dist}")
# 3.4 距离超过最大允许值,直接跳过(不可能是同一个物体)
if dist > MAX_DIST:
continue
# 3.5 归一化距离:0=很近,1=最远
norm_dist = dist / MAX_DIST
# 3.6 综合打分:IoU占70%,距离占30%(兼顾重叠+移动)
score = 0.7 * iou + 0.3 * (1 - norm_dist)
# 3.7 保留得分最高的目标ID(最可能是同一个)
if score > best_score:
best_score = score
best_id = pid
# 4. 返回最匹配的目标ID,没找到则返回None
return best_id
# [剔除错误id]过滤误分割的无效目标(置信度+掩码面积双重校验)
def filter_invalid_target(mask, conf):
# 条件1:置信度低于阈值,直接判定为无效目标
if conf < CONF_THRESHOLD:
return False
# 条件2:掩码二值化后计算面积,像素数过少判定为无效
mask_bool = mask > 0.5
mask_area = np.sum(mask_bool)
if mask_area < MIN_MASK_AREA:
print(f"【过滤】掩码面积{mask_area} < {MIN_MASK_AREA},判定为误分割")
return False
# 双重校验通过,判定为有效目标
return True
#------------------------------------------------------------------------------------------------------------------------------------------------
# ========== 初始化SAM 3预测器 ==========
print("正在加载SAM 3模型...")
overrides = dict(
conf=CONF_THRESHOLD,
task="segment",
mode="predict",
model=MODEL_PATH,
half=True, # 使用FP16加速推理
save=False,
)
predictor = SAM3SemanticPredictor(overrides=overrides)
print("模型加载成功!")
# ========== 打开视频 ==========创建视频捕获对象
cap = cv2.VideoCapture(VIDEO_PATH)
if not cap.isOpened():
print(f"无法打开视频文件: {VIDEO_PATH}")
exit()
# 获取视频信息
fps = int(cap.get(cv2.CAP_PROP_FPS))
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
print(f"视频信息:")
print(f" 帧率: {fps} fps")
print(f" 分辨率: {width} x {height}")
print(f" 总帧数: {total_frames}")
# ========== 创建输出视频写入器 ==========
fourcc = cv2.VideoWriter_fourcc(*'mp4v')#视频编码格式,*将字符串 'mp4v' 拆解为四个独立的字符
#函数返回一个整数fourcc,该整数代表指定的编码格式
out = cv2.VideoWriter(OUTPUT_PATH, fourcc, fps, (width, height))
#创建输出视频对象
# ========== 逐帧处理视频 ==========
frame_idx = 0 #初始化计数器,提示开始处理。
print("开始处理视频...")
while True: #逐帧读取视频
# frame:三维NumPy数组,表示读取到的这一帧图像。形状为(height, width, 3),其中3代表BGR三个颜色通道
ret, frame = cap.read() #ret(return的缩写):布尔值,表示是否成功读取到一帧。
print(f"ret={ret}")
if not ret :
break
print(f"处理进度!!: {frame_idx}/{total_frames} 帧 ({frame_idx / total_frames * 100:.1f}%)")
# 设置当前帧进行分割
#①将输入的帧调整到模型期望的尺寸(SAM3期望输入尺寸为1024×1024),并进行归一化等操作
#②将预处理后的图像送入SAM3的image_encoder神经网络(Vision Transformer架构),提取出高维特征向量
#③将生成的图像嵌入存储在预测器内部的features属性中,供后续的掩码解码器使用
#(这里的predictor.set_image=SAM3SemanticPredictor.set_image
# 与图像分割中的Sam3Processor.set_image()都是编码图像,区别是:前者属于ultralytics库,后者属于原生sam3库)
predictor.set_image(frame)
# 使用文本提示进行分割,返回的results包含单帧检测到的目标掩码、边界框、置信度等信息
results = predictor(text=[TEXT_PROMPT])
print("11111111111111111")
# 绘制分割结果(len(results) > 0确保有检测结果;results[0].masks确保有掩码生成)
if len(results) > 0 and results[0].masks is not None:
# 获取掩码(data获得掩码张量,再将数据从GPU内存移动到CPU内存,转成numpy数组)
#masks形状是(目标数量,图像高度,图像宽度)(N, H, W),表示每个像素属于目标的概率,就是目标的轮廓图
masks = results[0].masks.data.cpu().numpy()
boxes = results[0].boxes.data.cpu().numpy() if results[0].boxes is not None else []
# 创建空白掩码叠加层,用于绘制掩码的彩色区域。
overlay = np.zeros((height, width, 3), dtype=np.uint8)
current_boxes = {}
current_centers = {}
# 为每个检测到的对象绘制不同颜色的掩码
for i, mask in enumerate(masks):
print(f"正在处理第{frame_idx}帧的第{i}张掩码")
#print(f"处理----: {frame_idx}/{total_frames} 帧 ({frame_idx / total_frames * 100:.1f}%)")
# [剔除错误id]1. 获取当前目标的置信度(用于过滤)
current_conf = 0.0
if results[0].boxes is not None and len(results[0].boxes) > i:
current_conf = results[0].boxes[i].conf.cpu().numpy()[0]
#[剔除错误id]2. 过滤无效目标(误分割),直接跳过不处理
if not filter_invalid_target(mask, current_conf):
continue
mask_bool = mask > 0.5 # 二值化掩码(mask是每个像素属于目标的概率)
# 随机生成颜色
# 绘制边界框(如果有)
if results[0].boxes is not None and len(results[0].boxes) > i:
#results[0]获取第一张图像的检测结果;boxes[i]获取第 i 个边界框的完整信息;xyxy获取该框的坐标属性,
# 它返回一个形状为 [1, 4] 的张量,包含边界框的左上角和右下角坐标 [x1, y1, x2, y2]
#将GPU张量转为CPU上的NumPy数组,将浮点数坐标转为整数像素坐标
box = results[0].boxes[i].xyxy[0].cpu().numpy().astype(int)
# 1. 用融合匹配函数,找当前目标对应上一帧的ID(同一个物体)
target_id = fuse_match(box)
# 2. 如果没找到匹配 → 判定为新目标 → 生成唯一ID
if target_id is None:
print("target_id=None")
target_id = get_mask_hash(mask)
# 3. 如果这个ID还没有颜色 → 分配一次随机颜色(终身不变)
# 生成3个0~255之间的随机整数,分别代表R、G、B值。.tolist():将NumPy数组转换为Python列表,格式为[R, G, B]
if target_id not in id2color:
print("新目标给新颜色")
id2color[target_id] = np.random.randint(0, 255, 3).tolist()
# 4. 取出该目标固定颜色
color = id2color[target_id]
overlay[mask_bool] = color
#绘制边框rectangle参数:图像 + 左上角坐标 + 右下角坐标 + 颜色 + 粗细
cv2.rectangle(frame, (box[0], box[1]), (box[2], box[3]), color, 2)
# 记录当前帧信息
cx = (box[0] + box[2]) / 2
cy = (box[1] + box[3]) / 2
current_boxes[target_id] = box
current_centers[target_id] = (cx, cy)
# 半透明叠加,第一张图(原始帧)70%透明度,overlay:第二张图(绘制内容),权重0.3(30%透明度
frame = cv2.addWeighted(frame, 0.7, overlay, 0.3, 0)
# 显示检测数量,参数(目标图像,要显示的文本内容,文本左下角坐标,字体类型,字体大小,字体颜色BGR格式,字体线条粗细)
cv2.putText(frame, f"Person count: {len(masks)}", (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
# 更新上一帧数据
prev_boxes = current_boxes
prev_centers = current_centers
# 写入输出视频
out.write(frame)
frame_idx += 1
print(f"frame_idx={frame_idx}")
print(f"total_frames={total_frames}")
if frame_idx > total_frames:
break
# ========== 释放资源 ==========
cap.release()
out.release()
cv2.destroyAllWindows()
print(f"\n视频处理完成!")
print(f"输出文件: {OUTPUT_PATH}")
print(f"处理帧数: {frame_idx}")分割效果:
