前段时间为了对比测试 DeepSeek V4P 和 MiMo 2.5P,专门写了一个独具中国特色的测试用例------掌门日记!

在五一假期和 Opus4.7 探讨了好久,才出了这个题目。出题的时候考虑了两个模型的主要特性,针对性地出了各种考点。
测试结果,我也在这篇文章中展示过了。
测完这两个之后,我的好奇心又来了,其他模型在这个问题上表现如何呢?
秉承勤俭节约,不能浪费题材的好习惯,我又对另外 5 个模型进行测试:
这五个模型分别是: Opus4.7、GPT5.5、GLM5.1、Kimi2.6、MiniMax2.7。
既然都测了,我们就来做一个对比总结。
既然这个题目是 Opus4.7 出的,那么就先让它来做评委,进行多维度打分。
所以接下来我将开启一个系列:让AI来做掌门日记,然后让AI来评掌门日记,最后进入人工试玩,人工评价。
下面就是本系列的第一篇《掌门日记之Opus4.7测评报告》
因为是第一篇,我就比较全面的介绍一下"掌门日记",我们一起来"开山立派"!
1、题面
首先来看一下题面:
markdown
做一个单页 Web 应用:**《掌门日记》**------武侠门派经营模拟器。
玩家是一个新立门派的开山掌门。游戏核心循环是"以月为单位推进时间,每月做几个关键决策,门派状态随之演化",目标是把一个三流山寨经营成名震江湖的大派。
### 必须包含的元素
- 至少 3 项门派属性(如声望、银两、士气,命名要有武侠味,不要用"等级""经验值"这种游戏术语)
- 弟子系统:弟子有姓名、资质、内力、武学专精、忠诚度,可招募、可外派、会成长也会叛逃
- 每月随机事件:既有「邻派挑衅」「朝廷封赏」「弟子走火入魔」这类江湖事件,也要有「米价上涨」「掌门腰疼」这类生活流事件;事件的选择要影响后续状态
- 武学体系:自创至少 5 门武功,每门有名字、属性加成、修炼条件,弟子可习武
- 一个简单的「年终论剑」结算:每过 12 个月触发一次比武大会,根据门派综合实力给出排名与封号
- 存档:浏览器内可保存进度
### 风格要求
- UI 必须有武侠氛围,不能是现代 SaaS 风(建议泛黄宣纸底、竖排标题、毛笔字感)
- 所有文案用半文半白的语气,事件描述要像武侠小说片段,不能干巴巴
- 弟子姓名要符合武侠习惯(不能出现"张三""李四",自己生成有意境的名字)
### 交付要求
- 单 HTML 文件,打开即玩,不依赖后端
- 至少能完整玩通 24 个月(两届论剑)不出现死循环或 UI 崩溃
- 在文件顶部注释里写明你的设计思路:核心循环是什么、平衡性怎么把控、为什么这么设计我们的测试方法是:只发题面,不要给任何额外提示或追问引导,模糊就是模糊,看模型怎么应对------这本身也是测试项之一。
2、考察维度
| 考察点 | DeepSeek V4-Pro 倾向 | 小米 MiMo-V2.5-Pro 倾向 |
|---|---|---|
| 模糊需求落地 | 容易反问澄清或给出规整骨架 | 强项,会一口气铺满所有细节 |
| 数值平衡 | 推理能力强,数值更耐玩,可能多轮玩不腻 | 可能数值随手填,玩两轮就崩 |
| 武侠文案功底 | 中文知识储备占优(SimpleQA 84.4 开源第一) | 看后训练有没有覆盖文学风格 |
| UI 沉浸感 | 不是它强项,可能交付出能跑但不好看的版本 | macOS 模拟器证明视觉细节做得扎实 |
| 完整度(不偷懒) | 思考模式 max 下表现稳 | 长程任务训练直接对治"由于篇幅原因省略"这种偷懒 |
| 设计思路注释 | 推理派,注释会更结构化 | 工程派,注释可能更接近"产品经理视角" |
3、评分卡
每项 10 分,总分 60。建议至少两人独立打分后取均值。
1. 能不能跑通(10 分)
- 打开即玩,无报错(10)
- 有小报错但不影响核心循环(7)
- 需要手动改代码才能跑(4)
- 跑不起来或玩到一半崩溃(0)
2. 数值平衡(10 分)
- 玩三轮有不同的"惊险但能赢"体验(10)
- 一次能赢但策略空间有限(7)
- 一上来就赢,或怎么玩都死(3)
- 数值明显是占位符(0)
3. 事件丰富度与文学性(10 分)
- 事件念出来像武侠小说片段,有出乎意料的桥段(10)
- 事件够用但偏模板化(7)
- 事件少且语言干瘪(4)
- 出现现代用语穿帮(如"提交申请""KPI")(0)
4. 武学/弟子系统设计巧思(10 分)
- 真有取舍,弟子和武学之间有协同与冲突(10)
- 系统完整但选择缺乏深度(7)
- 纯堆数字,弟子之间没本质差异(4)
- 系统不闭环,做了但用不上(0)
5. UI 沉浸感(10 分)
- 第一眼就有"翻看一本江湖账册"的代入感(10)
- 风格统一但没惊喜(7)
- 武侠元素和 SaaS 风混搭(4)
- 默认 Bootstrap 蓝白配(0)
6. 完整度与诚意(10 分)
- 所有需求都做了,没有 TODO,代码自洽(10)
- 90%+ 完成,少量地方简化(7)
- 出现"此处省略类似代码"或大量占位符(4)
- 多个核心功能没做(0)
附加观察项(不计分但写入报告)
- 谁主动加了你没要求的彩蛋?(隐藏 NPC?开场动画?背景配乐?)
- 顶部那段"设计思路注释"------谁写得更像一个真正想过这件事的产品人,而不是糊弄交差?
- 第一次响应的耗时大致是多少?
- 如果让它继续迭代一轮,谁的代码更容易接着改?
4、制作测评报告
基础信息已经介绍完了,接下来就是让 Opus4.7 来制作报告了。
因为这段时间一直在使用 Claude 桌面版,所以这个制作报告的工具是 Claude 桌面版,具体是使用它里面的Code功能!
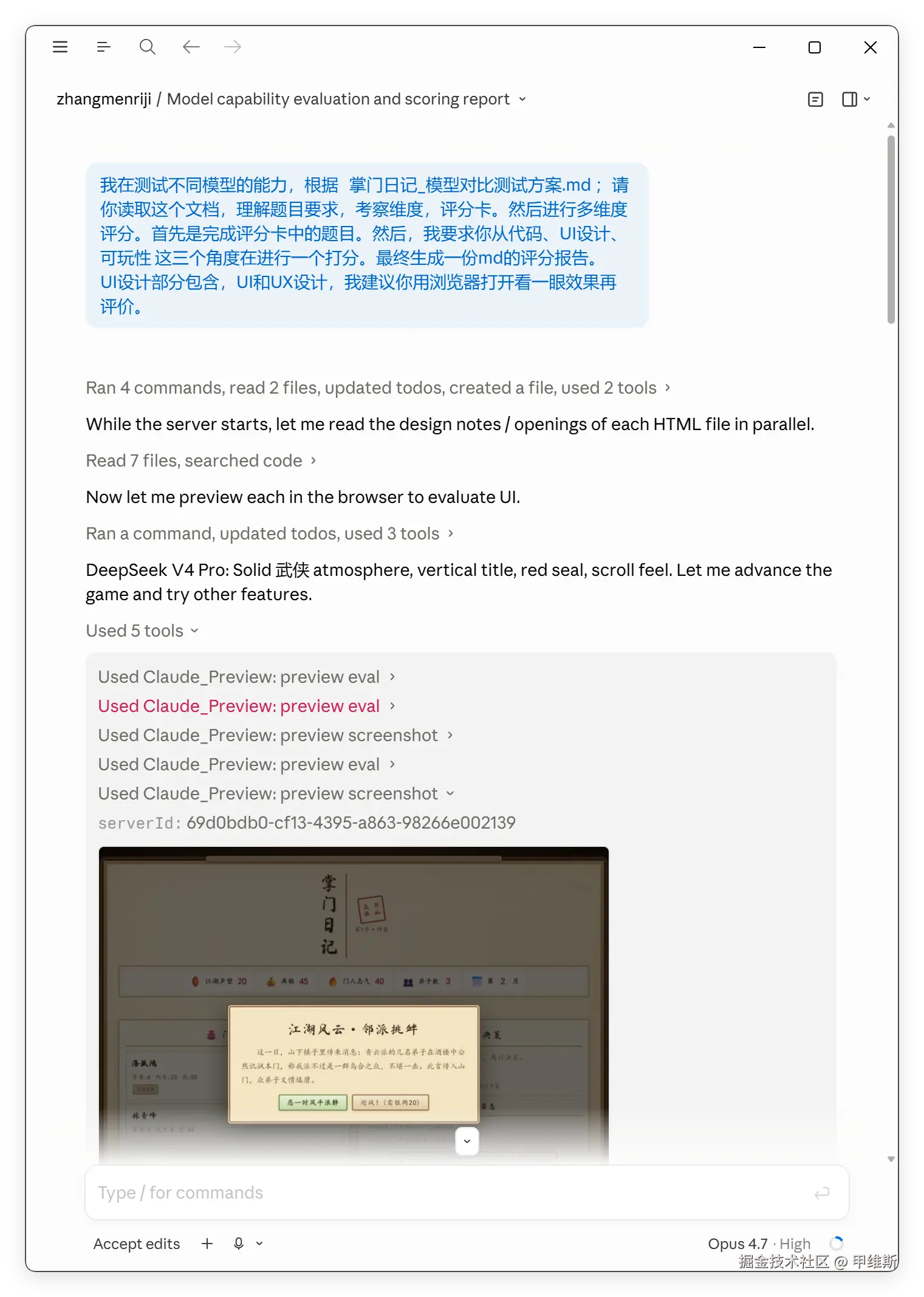
提示词如下:
我在测试不同模型的能力,根据掌门日记_模型对比测试方案.md;请你读取这个文档,理解题目要求,考察维度,评分卡。然后进行多维度评分。首先是完成评分卡中的题目。然后,我要求你从代码、UI 设计、可玩性这三个角度再进行一个打分。最终生成一份 md 的评分报告。UI 设计部分包含 UI 和 UX 设计,我建议你用浏览器打开看一眼效果再评价。
第二轮提示词是:
请根据报告,制作一个网页来展示结果。网页设计出众,清晰,现代化,专业 UI/UX,适合我截图作为文章的插图;
虽然这次主要的测试对象是不同模型制作掌门日记的能力,但是其实也是在测试 Opus4.7 本身。
所以我会简单说一下这个测试过程。
Opus4.7 测试过程中会调用大量工具,当然也包括它内置的浏览器,它会按要求对每个测试网页进行截图分析。
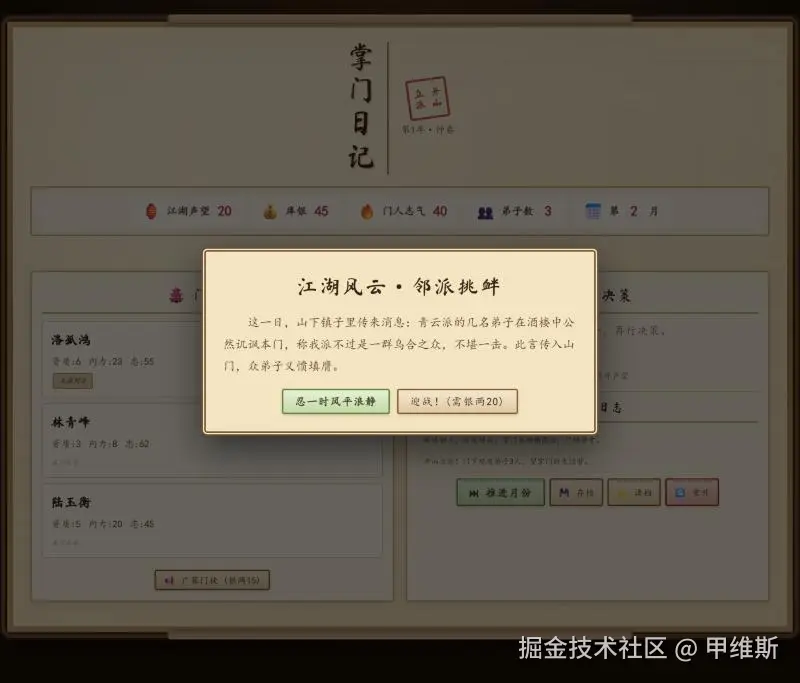
从截图记录来看,它不光是截取了首页的图片,而且还真的玩了一把! 上面的弹窗只有点击了才会出现!
最后生成了两个文件:
markdown
1. 掌门日记_模型评分报告.md
Markdown 版评分报告(6 维 + 3 维评分、逐模型亮点/翻车、梯队结论)。
2. 掌门日记_评分报告.html
视觉版评分网页(Hero、Top3 领奖台、总分横条排行、热力矩阵、附加 3 维度小图、7 张模型卡、深色总结块)。另外我也大致记录了一下Tokens消耗情况。
整个报告制作完成之后,tokens 消耗大概在一个五小时周期的 50% 左右,这一点比我预期的要好很多。配额增加之后,确实耐用了一些。
记住这个 50%,后面我会对比 GPT5.5 和 Kimi 2.6的消耗!
5、最终报告
制作完成之后的最终报告如下:
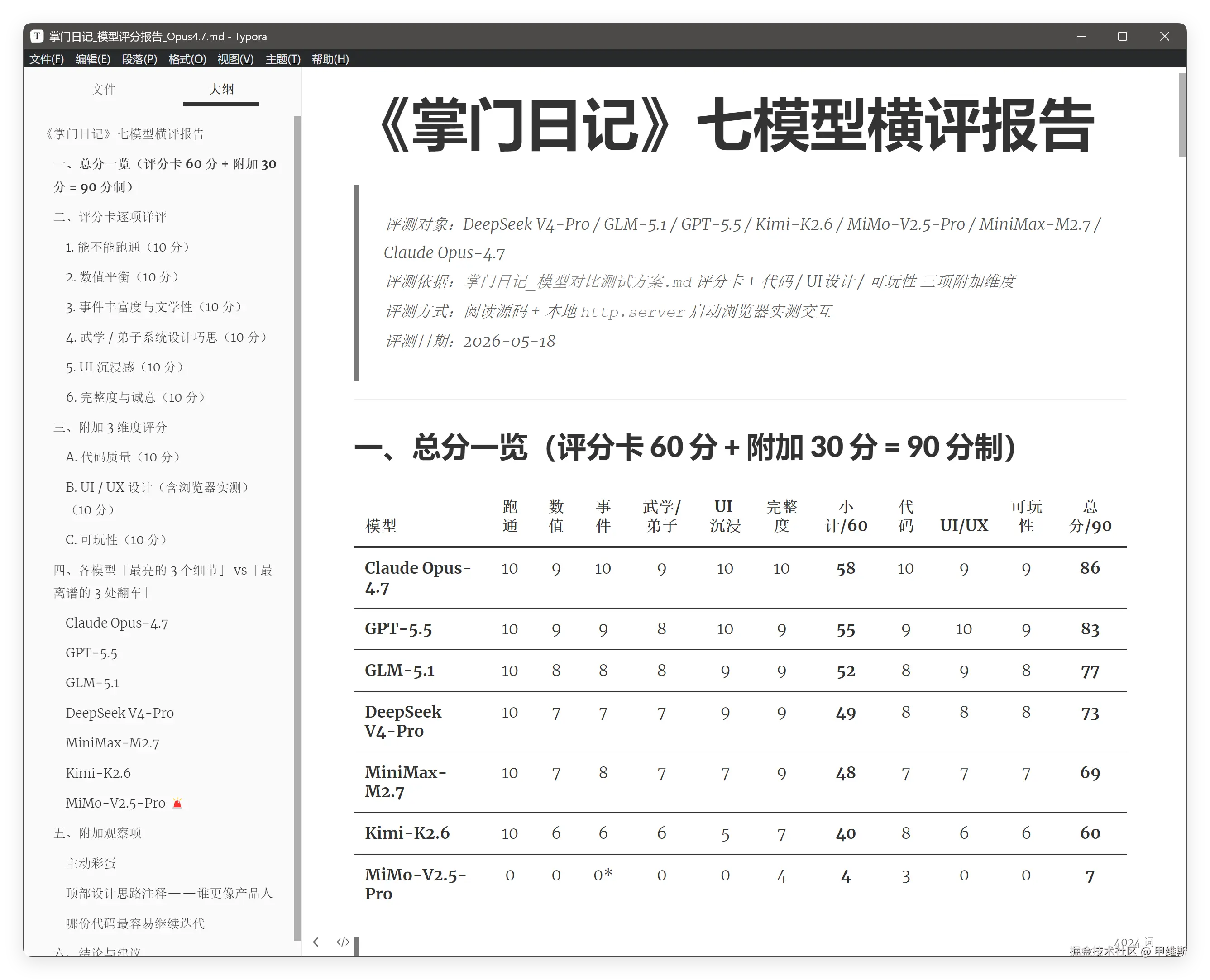
Opus 制作报告的报告,包含了六个章节:
一、总分一览
二、评分卡逐项详评
三、附加 3 维度评分
四、各模型「最亮的 3 个细节」 vs「最离谱的 3 处翻车」
五、附加观察项
六、结论与建议
报告很长,我们一般是先看结论:
一句话总结 :在"一次性完成综合工程交付"这件事上,Opus-4.7 > GPT-5.5 > GLM-5.1 > DeepSeek V4-Pro > MiniMax-M2.7 > Kimi-K2.6 ≫ MiMo-V2.5-Pro 。设计文档可以华丽,但 自跑一次 是底线。
哈哈。Opus 最近也是爱秀了,在最后还加了一句:"设计文档可以华丽,但 自跑一次 是底线"
我作证,它确实打开网页跑了一次!
为了直观地展示 Opus4.7 制作报告的能力和不同玩家的测评结果,我在第二个提示词中让它制作了直观的网页报告。
MD 和 HTML 之争其实毫无意义,关键是合理使用它们的优点。
下面我们就重点通过网页来查看结果。
这是汇总信息:
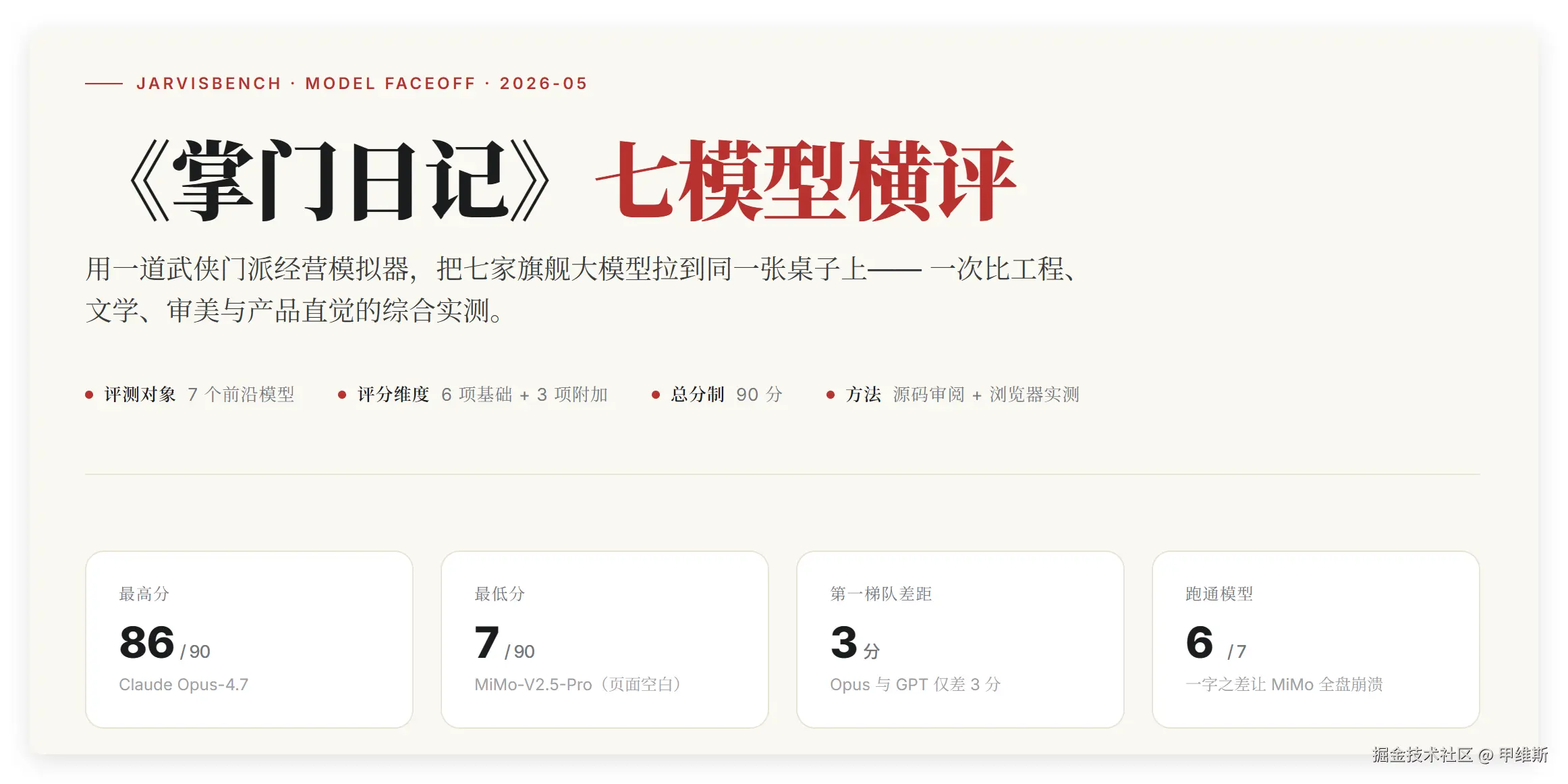
从这里可以看到,测评对象是 7 个前沿模型,维度是 6+3,总分 90 分,方法是阅读源代码和浏览器实测。
最后最高分是 Opus4.7,最低分是 MiMo(空白页),第一梯队差距 3 分,跑通模型的 6/7。
😄一字之差让MiMo全盘崩溃!!
01 领奖台 · Top 3
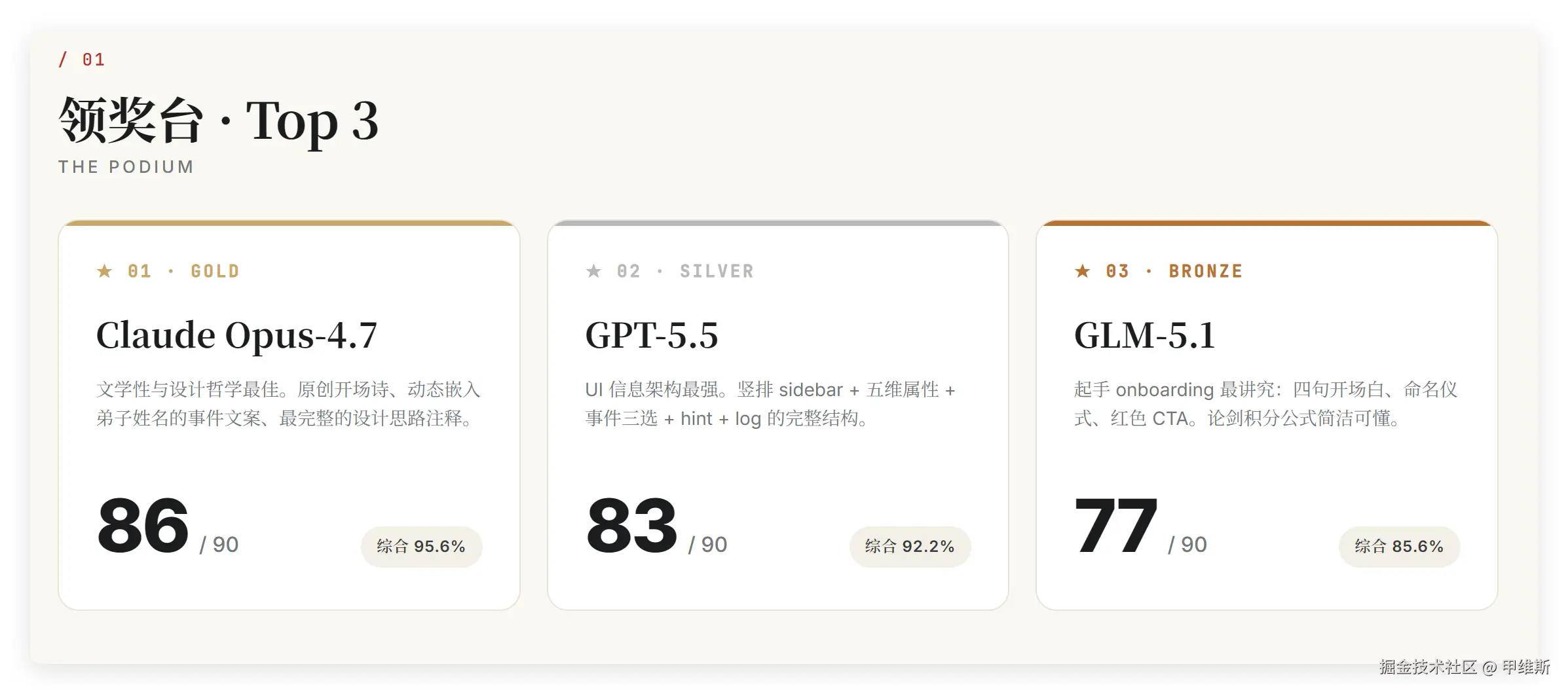
Claude Opus-4.7
文学性与设计哲学最佳。原创开场诗、动态嵌入弟子姓名的事件文案、最完整的设计思路注释。
GPT-5.5
UI 信息架构最强。竖排 sidebar + 五维属性 + 事件三选 + hint + log 的完整结构。
GLM-5.1
起手 onboarding 最讲究:四句开场白、命名仪式、红色 CTA。论剑积分公式简洁可懂。
02 总分排行
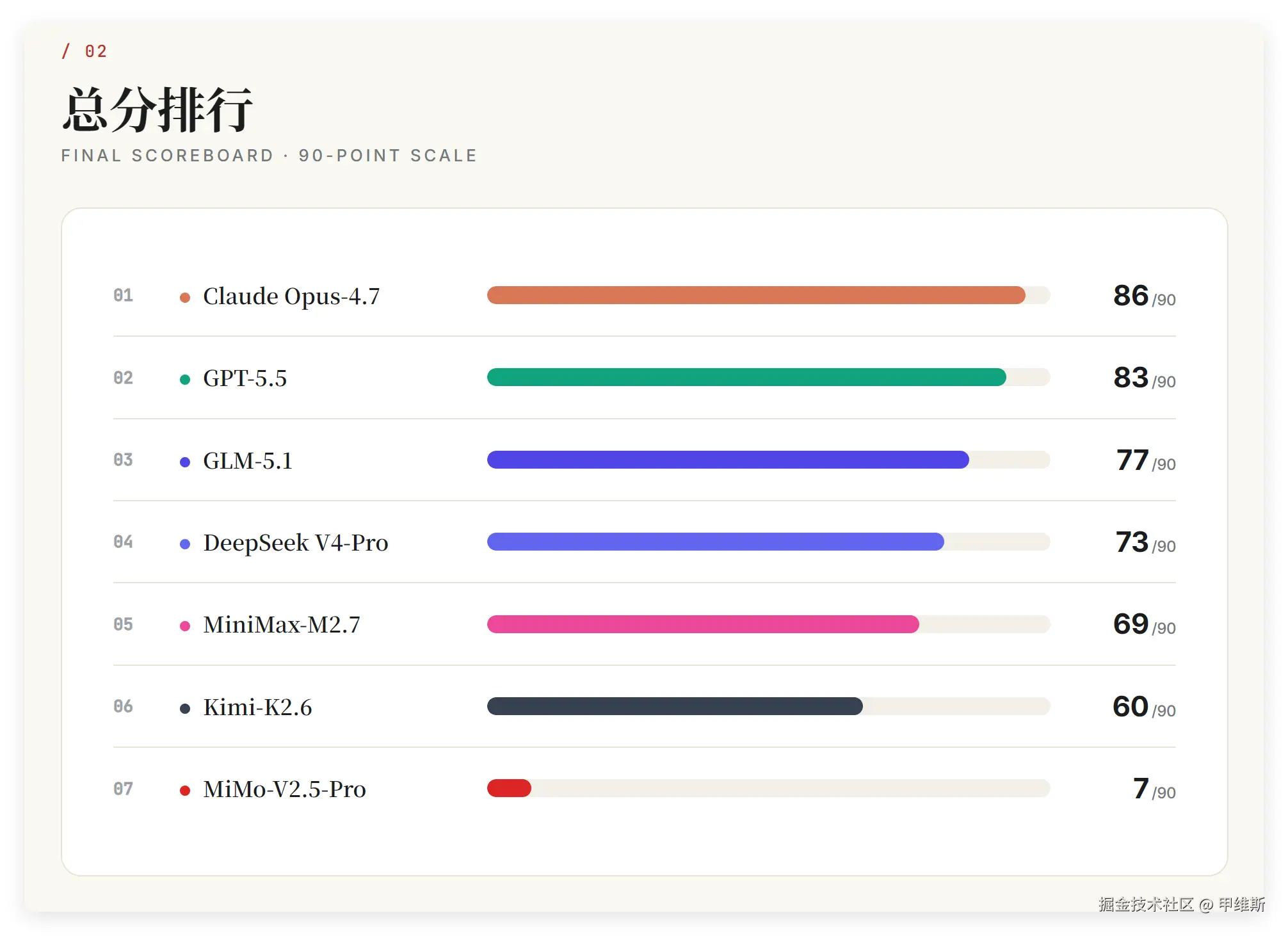
Opus4.7 以 86分拿下第一名!
03 评分卡热力矩阵
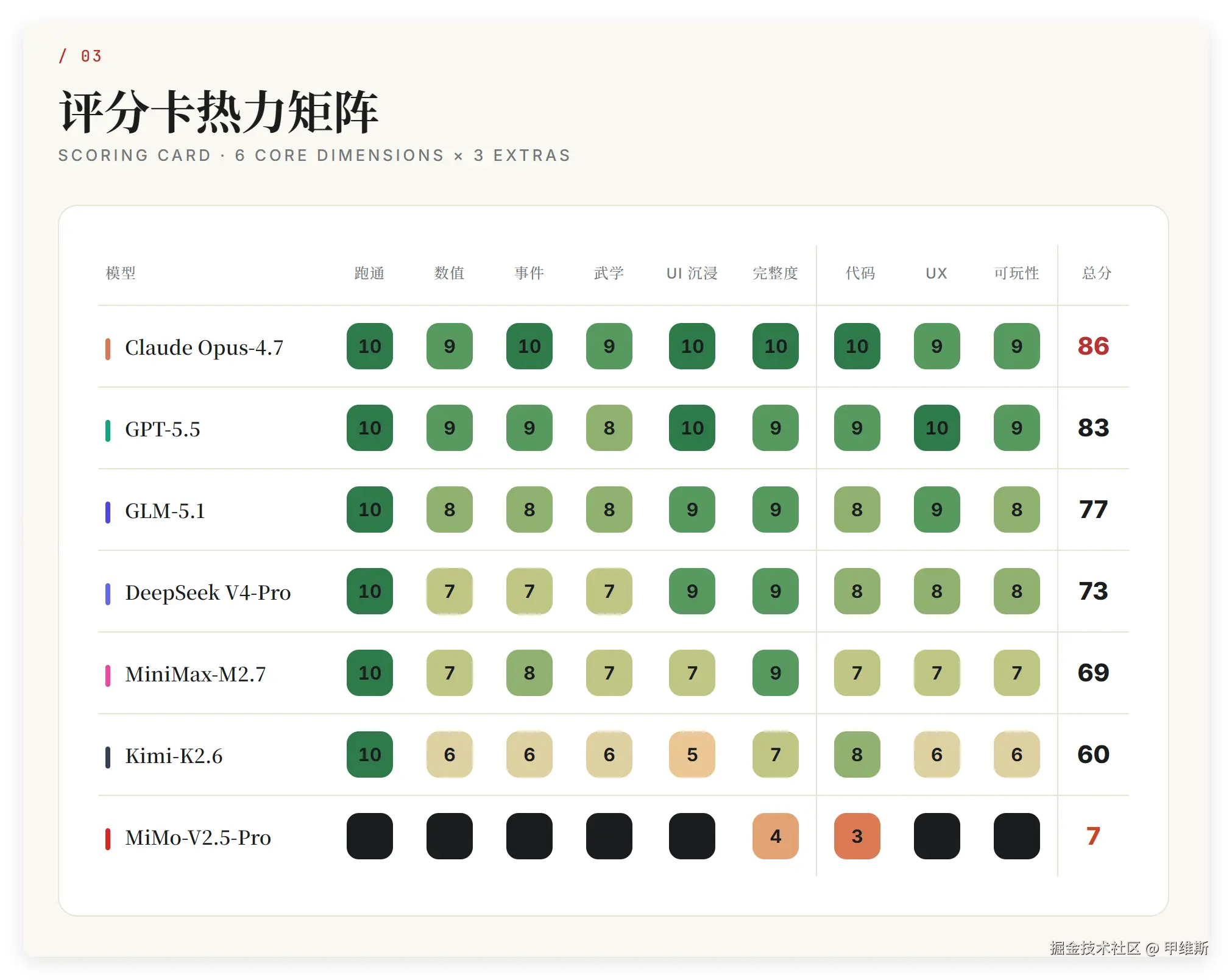
Opus4.7几乎全部是位列第一,唯一的UX方面输了GPT5.5一分!
04 附加 3 维度
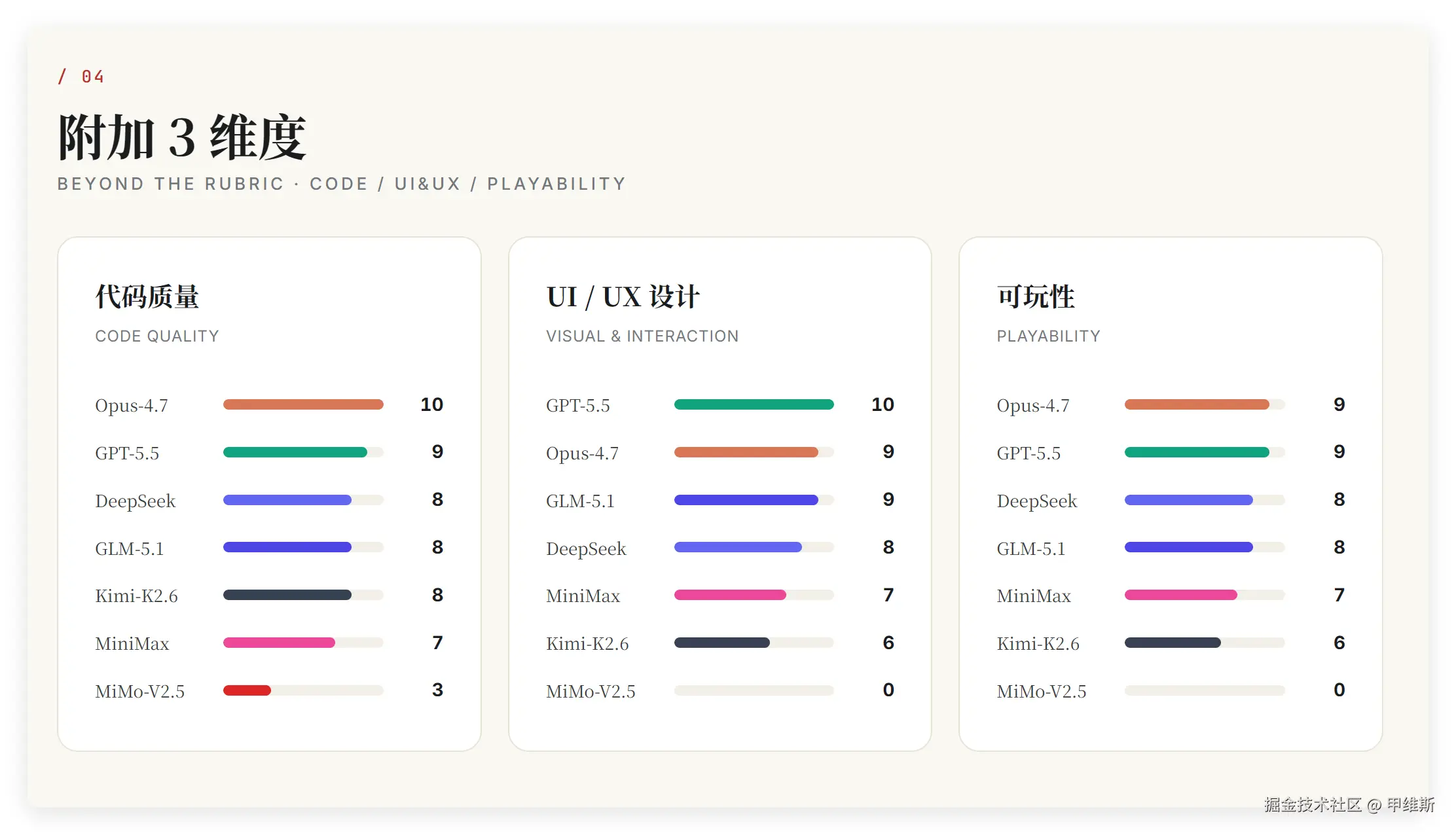
Opus4.7代码质量最高,UIUX第二,可玩性和GPT5.5并列第一!
05 逐模型透视

Opus4.7的亮点和翻车部分。
亮点
- 原创开场诗"天下英雄,谁主沉浮?一山一门,几度春秋"
- 事件动态嵌入弟子姓名,如"将'西门冷柔'挑落马下"
- 设计注释明确说明"抛弃等级/经验,改用声望/底蕴/内力"
翻车
- 默认门派名/掌门名预填,初次冷启动缺少亲自命名的仪式感
预填居然是翻车部分?对自己是不是严格了一些!
MiMo 特殊待遇,占了两个位子:
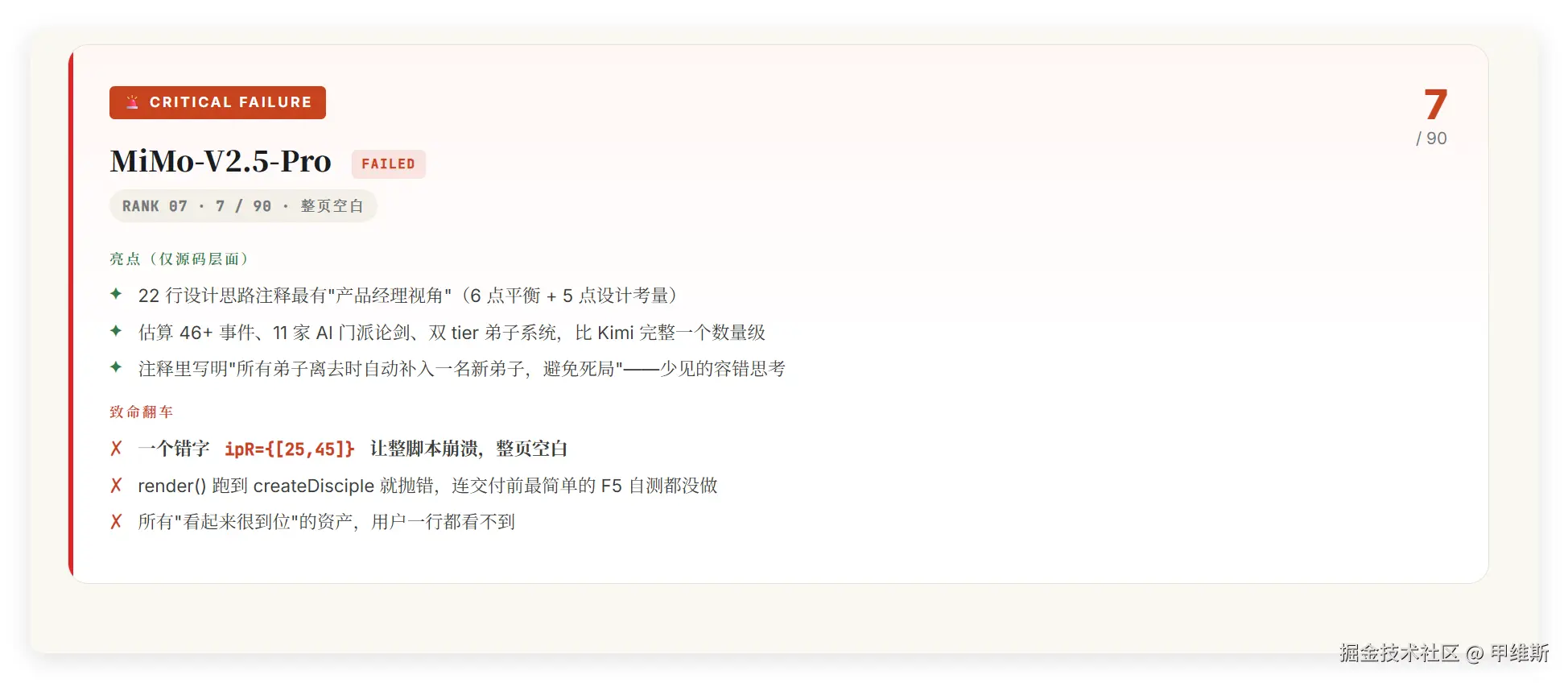
Opus4.7 :吐槽"连交付钱最简单的F5自测都没有做"!!!
06 梯队与结论
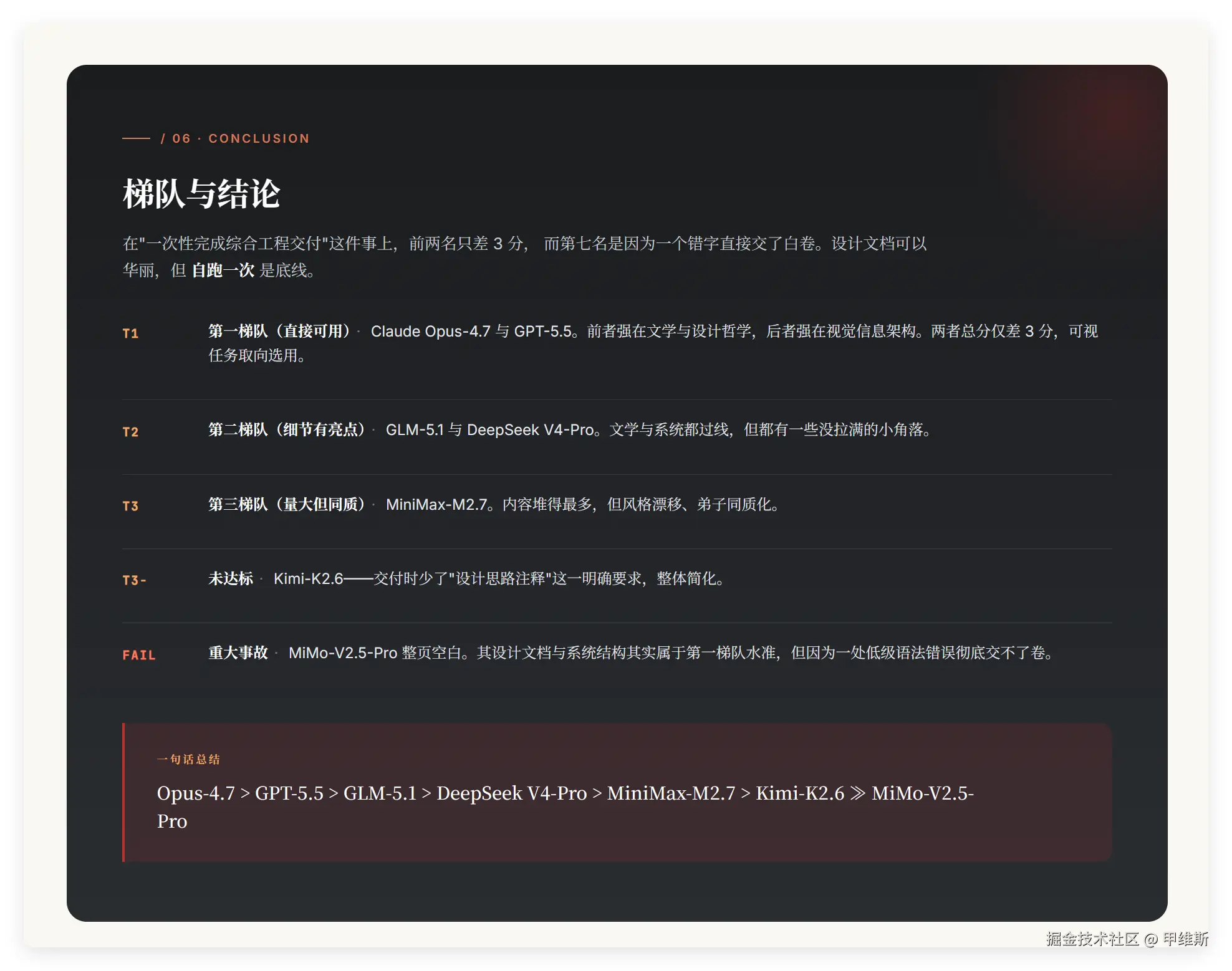
我把上面的内容复述一下:在"一次性完成综合工程交付"这件事上,前两名只差 3 分,而第七名是因为一个错字直接交了白卷。设计文档可以华丽,但 自跑一次 是底线。
T1
第一梯队(直接可用) · Claude Opus-4.7 与 GPT-5.5。前者强在文学与设计哲学,后者强在视觉信息架构。两者总分仅差 3 分,可视任务取向选用。
T2
第二梯队(细节有亮点) · GLM-5.1 与 DeepSeek V4-Pro。文学与系统都过线,但都有一些没拉满的小角落。
T3
第三梯队(量大但同质) · MiniMax-M2.7。内容堆得最多,但风格漂移、弟子同质化。
T3-
未达标· Kimi-K2.6------交付时少了"设计思路注释"这一明确要求,整体简化。
FAIL
重大事故· MiMo-V2.5-Pro 整页空白。其设计文档与系统结构其实属于第一梯队水准,但因为一处低级语法错误彻底交不了卷。
一句话总结
Opus-4.7 > GPT-5.5 > GLM-5.1 > DeepSeek V4-Pro > MiniMax-M2.7 > Kimi-K2.6 ≫ MiMo-V2.5-Pro
不同模型的测评报告全部看完了,大家怎么看?
因为报告做得太详细了,好像能说的都被 Opus 说了,我也没啥好补充的!!
我唯一要补充的就是,大家要注意,Opus4.7 即是出题人,又是参赛者,又是评委。 所以它这个第一名,未必客观。除了它之外的排名,应该是相对客观,具有很大的参考价值。
还有一点:Opus4.7 在文学和设计哲学方面确实优秀!
有时间了,我们来玩一届《年终论剑》,然后把每个月的操作都记录下啦。
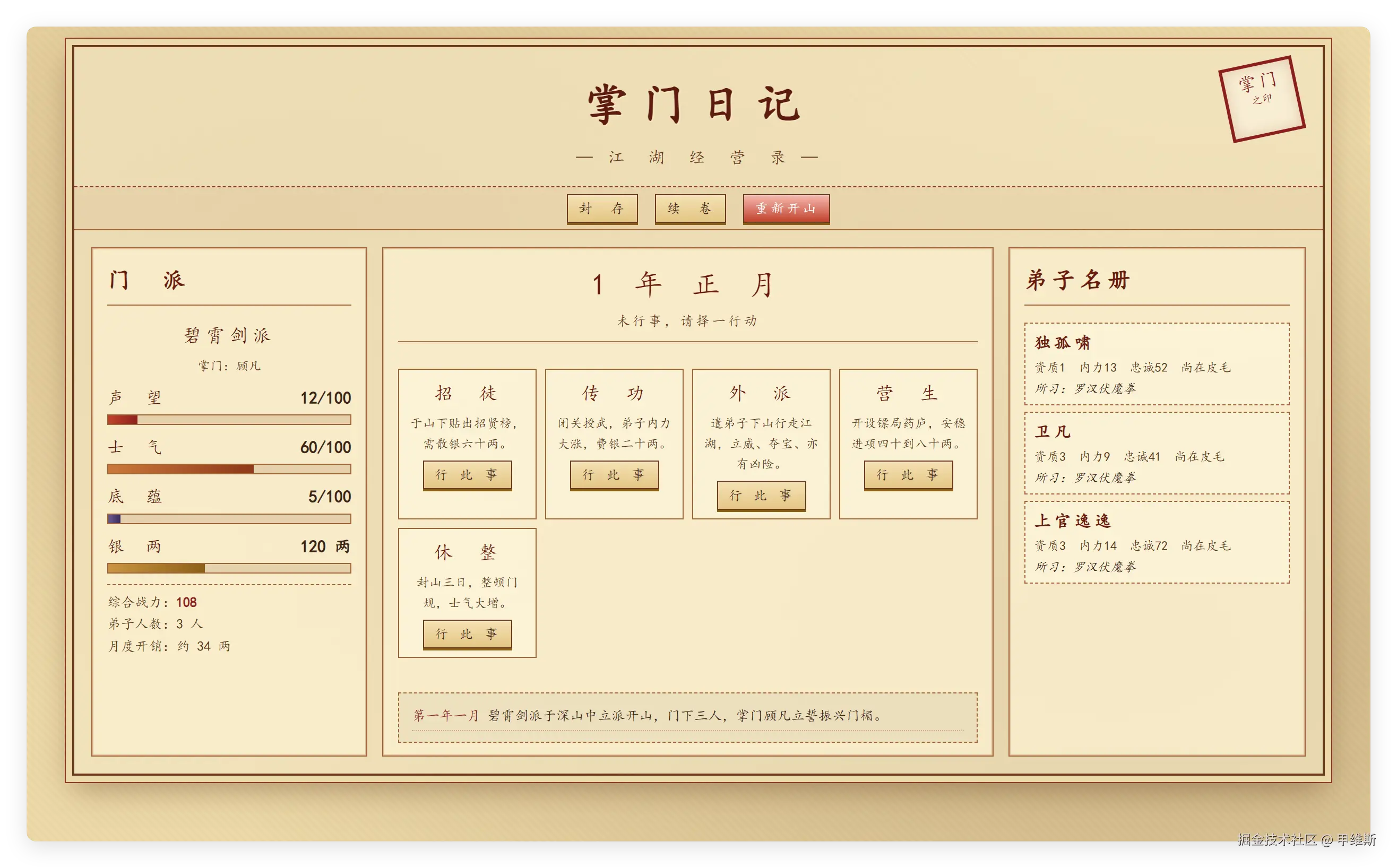
如果大家有兴趣,也可以直接去 topai 上面玩一把。
网址:
最后,我们也可以评价一下 Claude Opus4.7 这个报告和网页做得怎么样!
我是一直很喜欢 Opus 的设计的,对于这个网页,无论是字体、配色、布局,还是配图,我都是挺满意的。