嗨,我是辉哥,一个致力于使用 AI 技术搞副业的超级个体
OpenSpec:规格驱动开发的完整指南
OpenSpec 是一个专为 AI 编程助手设计的"规格驱动开发(SDD)"框架,48.8K+ GitHub Stars 。它的核心定位一句话:让 AI 和人在写代码之前,先在规格层面达成共识。
本文将从源码层面拆解 OpenSpec 的四个 SKILL.md 文件,回答:
- OpenSpec 是什么------它解决了什么问题?
- 源码长什么样------一个 Markdown 文件如何控制 AI 行为?
- 四步闭环怎么运转------每个 Skill 的执行流程?
- 底层机制是什么------三层行为控制架构?
- 什么场景适合------何时该用、何时不该用?
- 从源码中能学到什么------可复用的设计经验?
目录
- [一、OpenSpec 一句话介绍](#一、OpenSpec 一句话介绍 "#%E4%B8%80openspec-%E4%B8%80%E5%8F%A5%E8%AF%9D%E4%BB%8B%E7%BB%8D")
- 二、快速上手:四个核心Skill的使用
- [三、从源码看 SKILL.md 文件结构](#三、从源码看 SKILL.md 文件结构 "#%E4%B8%89%E4%BB%8E%E6%BA%90%E7%A0%81%E7%9C%8B-skillmd-%E6%96%87%E4%BB%B6%E7%BB%93%E6%9E%84")
- [四、四步闭环:每个 Skill 的执行流程](#四、四步闭环:每个 Skill 的执行流程 "#%E5%9B%9B%E5%9B%9B%E6%AD%A5%E9%97%AD%E7%8E%AF%E6%AF%8F%E4%B8%AA-skill-%E7%9A%84%E6%89%A7%E8%A1%8C%E6%B5%81%E7%A8%8B")
- 五、底层机制:三层行为控制架构
- 六、适用场景
- 七、可汲取的六条设计经验
一、OpenSpec 一句话介绍
这个问题几乎每个做 AI 辅助开发的开发者都遇到过:我们用 AI 写代码,但聊完就忘了,需求只存在于聊天历史中。这带来三个痛点:
| 痛点 | 表现 |
|---|---|
| 需求漂移 | 聊着聊着最初需求被不断修改,没人记录"最终版本到底是什么" |
| 上下文丢失 | 会话清理或压缩后,之前的讨论消失,AI 对项目的理解出现断层 |
| 不可回溯 | 出问题时找不到"当时是怎么决定的",无法追溯决策路径 |
共同根源:没有持久化的规格文档作为"契约"。
OpenSpec 的解决思路不是"加一个文档模板",而是构造了一个轻量级但结构化的规格生命周期:
所谓"结构化",指的不是"格式严格",而是每个制品有明确的角色、有固定的依赖关系、有可追踪的状态。它不像 Word 文档那样写完就放那里不管了------OpenSpec 的 CLI 会主动读取这些文件,判断谁完成了、谁还缺着、下一步该做什么。
术语解释:制品(Artifact)
规格文档的正式称呼,每个制品是一个独立的 Markdown 文件,记录变更的某个特定维度(为什么做、做什么、怎么做、分几步做)。制品由 AI 自动生成,人和 AI 都可以读取和修改。
理解了这一点,来看整个生命周期的运转方式:
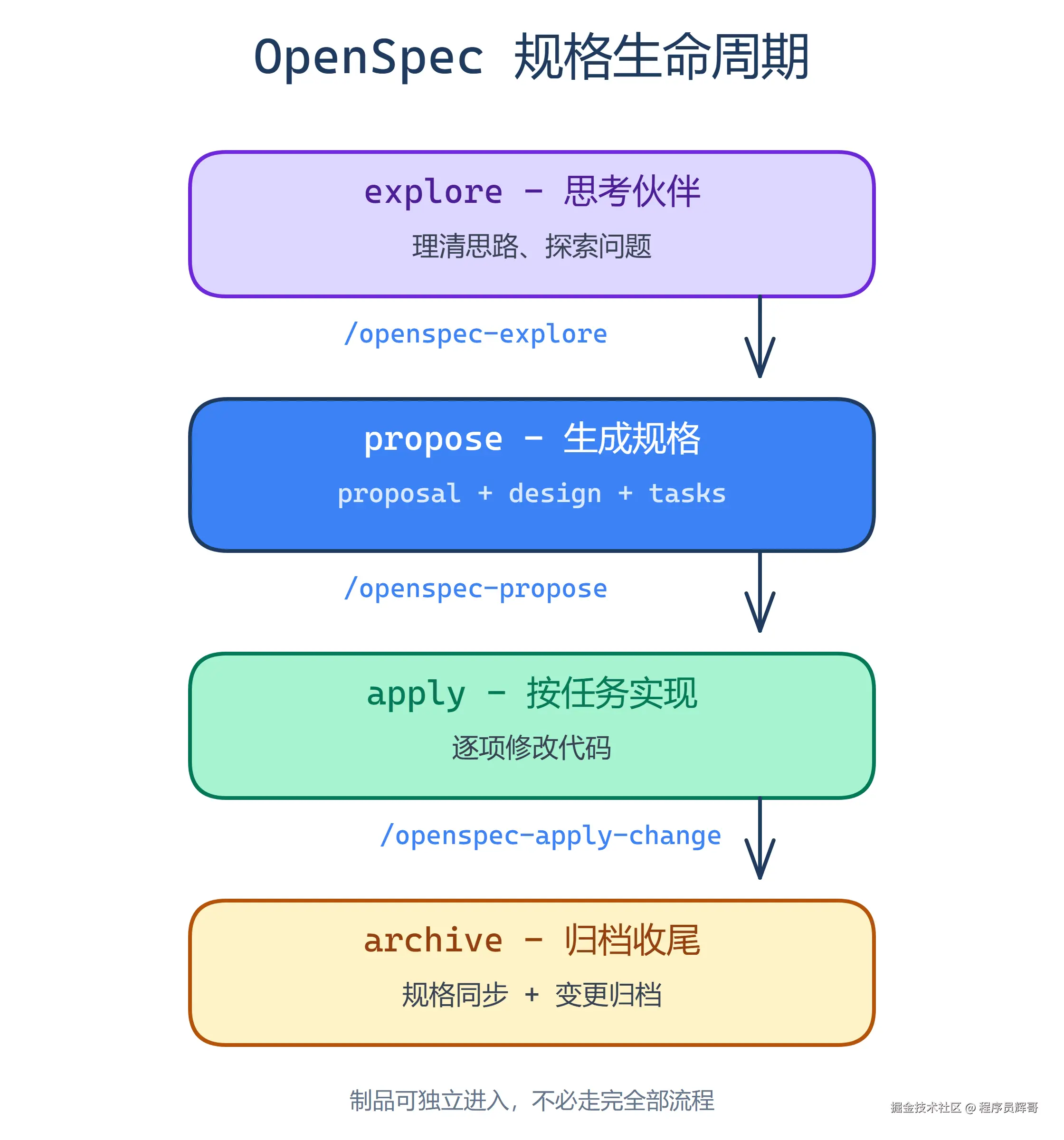
每个阶段对应一个 SKILL.md 文件引导 AI 行为,同时有 CLI 工具管理制品状态和依赖------两者缺一不可。
二、快速上手:四个核心Skill的使用
OpenSpec 的四个 Skill 覆盖了从想法到归档的完整开发流程,每个 Skill 都有明确的适用场景和触发方式。
2.1 什么时候用哪个Skill
| Skill | 适用场景 | 触发方式 | 核心输出 |
|---|---|---|---|
| explore | 想法模糊、需要理清思路、探索问题 | /openspec-explore 或自然语言"帮我探索一下这个想法" |
结构化的思考过程、决策建议 |
| propose | 想法清晰、需要生成完整规格 | /openspec-propose 或自然语言"创建一个变更提案" |
proposal.md、design.md、tasks.md、delta spec |
| apply | 规格已确认、需要开始实现 | /openspec-apply-change 或自然语言"实现这个变更" |
代码修改、已完成的任务标记 |
| archive | 实现已完成、需要收尾归档 | /openspec-archive-change 或自然语言"归档这个变更" |
归档的变更目录、更新后的主规格 |
2.2 典型工作流示例
-
探索阶段 :当你有一个模糊的想法"我想给系统加个实时通知功能",先调用
/openspec-explore,AI 会作为思考伙伴帮你理清需求、分析技术方案、识别潜在问题。 -
提案阶段 :当想法足够清晰后,调用
/openspec-propose,AI 会自动创建变更目录并生成所有必要的规格制品。 -
实现阶段 :审核并修改规格后,调用
/openspec-apply-change,AI 会按照 tasks.md 中的任务列表逐项实现代码。 -
归档阶段 :实现完成并测试通过后,调用
/openspec-archive-change,AI 会将变更归档并将 delta spec 同步到主规格中。
重要提示:四个 Skill 可以独立进入,不必从头走完整个流程。如果你已经有了规格文档,可以直接进入实现阶段;如果变更已经实现完成,也可以直接归档。
三、从源码看 SKILL.md 文件结构
OpenSpec 的四个 skill 以 SKILL.md 文件形式存在,位于 ~/.claude/skills/openspec-*/SKILL.md。AI 通过 Skill 工具加载这些文件,读取其中的行为指令来执行任务。
3.1 frontmatter:元数据定义
以 openspec-explore/SKILL.md 为例:
yaml
---
name: openspec-explore
description: Enter explore mode - a thinking partner for exploring ideas,
investigating problems, and clarifying requirements. Use when the user
wants to think through something before or during a change.
# 中文:进入探索模式------一个用于探索想法、调查问题、澄清需求的思考伙伴。
# 当用户想要在变更前或变更中仔细思考某件事时使用。
license: MIT
compatibility: Requires openspec CLI.
metadata:
author: openspec
version: "1.0"
generatedBy: "1.2.0"
---| 字段 | 作用 |
|---|---|
name |
skill 标识符,skill 选择系统通过此名称匹配 |
description |
决定何时加载------AI 的 skill 选择系统读取此字段判断是否应该激活 |
compatibility |
声明此 skill 需要 openspec CLI 配合 |
metadata.generatedBy |
生成此 skill 的 CLI 版本,建立 skill 和 CLI 的版本绑定关系 |
3.2 正文:行为指令的三种形态
打开任何一个 SKILL.md 文件,正文内容都围绕三种指令展开:
| 指令类型 | 对应源码章节 | 作用 |
|---|---|---|
| Workflow | ## Steps |
固定步骤序列:1→2→3→...,适合确定性操作 |
| Stance | ## The Stance |
行为原则集合:没有固定步骤,只有若干条行为原则,适合不确定的探索场景 |
| Guardrails | ## Guardrails |
定义"绝不能做什么"------硬性行为边界 |
| Output | ## Output |
定义"输出长什么样"------统一的输出格式 |
但不同 skill 的侧重点截然不同------explore 只有 Stance + Guardrails,没有固定 Steps;而 propose/apply/archive 都有明确的 Steps 序列。这是 OpenSpec 有意为之的设计,我们后面会拆解它背后的原因。
四、四步闭环:每个 Skill 的执行流程
4.1 explore:思考伙伴
核心声明:
进入探索模式。深入思考。自由可视化。跟随对话走向任何方向。 这是一个姿态,不是一个工作流。没有固定步骤,没有必选序列,没有强制输出。你是一个思考伙伴,帮助用户探索。
这是 explore 最独特的地方------它没有固定步骤。
Stance 定义
markdown
## The Stance
- **Curious, not prescriptive** → 好奇,而非规定------问自然涌现的问题,不按脚本走
- **Open threads, not interrogations** → 开放线索,而非审问------一次抛出多个方向,不让用户走单一路径
- **Visual** → 可视化------大量使用 ASCII 图来澄清思路
- **Adaptive** → 自适应------随新信息调整方向,该转向就转向
- **Patient** → 耐心------不急于下结论,让问题的形状自然浮现
- **Grounded** → 接地------探索实际代码库,不只停留在理论层面OpenSpec 上下文感知机制
explore 并非"纯聊天",它会主动感知当前项目的 OpenSpec 上下文:
markdown
### Check for context
At the start, quickly check what exists:
# 开始时,快速检查当前有什么变更
### When no change exists
Think freely. When insights crystallize, you might offer:
# 自由思考。当洞察变得清晰时,你可以提议:
"This feels solid enough to start a change. Want me to create a proposal?"
# "这个想法够成熟了,要不要开始创建一个变更提案?"
### When a change exists
1. Read existing artifacts for context
# 1. 读取已有制品获取上下文
2. Reference them naturally in conversation
# 2. 在对话中自然引用这些内容
3. Offer to capture when decisions are made
# 3. 当做出决策时,提议记录下来其中"洞察捕获"有一个结构化表格:
| 洞察类型 | 捕获到哪里 |
|---|---|
| 新需求被发现 | specs/<capability>/spec.md |
| 设计决策被做出 | design.md |
| 范围变更 | proposal.md |
| 新工作被识别 | tasks.md |
关键约束:
"用户来决定------提议然后继续。不要施压。不要自动捕获。"
AI 只"提议"捕获,绝不"自动"捕获。自动捕获会让 AI 从"思考伙伴"变成"文档管理员"。
Guardrails
markdown
## Guardrails
- **Don't implement** → 不实现------绝不写代码或实现功能
- **Don't fake understanding** → 不假装理解------不清楚就深挖
- **Don't rush** → 不催促------探索是思考时间,不是任务时间
- **Don't force structure** → 不强加结构------让模式自然浮现
- **Don't auto-capture** → 不自动捕获------提议保存,不主动去做
- **Do visualize** → 要可视化------一个好图胜过千言万语
- **Do explore the codebase** → 要探索代码库------基于实际代码讨论
- **Do question assumptions** → 要质疑假设------包括用户和你自己的行为模板机制
源码中直接写入了四个对话场景的完整示例。这些示例不是给人读的教程,而是给 AI 模仿的"行为模板"------研究表明 AI 在处理新场景时会强烈倾向于模仿最近看到的示例格式。
举个例子,当用户说"我想加实时协作"这种模糊想法时,源码中给出的示例回应是:
AI 看到这个示例后学到的不是"协作有哪些技术",而是回应模式:
4.2 propose:生成规格
核心声明:
创建一个新变更------生成变更目录和所有制品,一步完成。
markdown
Propose a new change - create the change and generate all artifacts in one step.
I'll create a change with artifacts:
- proposal.md (what & why) # 做什么、为什么
- design.md (how) # 怎么做
- tasks.md (implementation steps) # 实现步骤清单与 explore 的"无固定步骤"完全不同,propose 有明确的步骤序列。
propose 的流程信息量比较大,先抓住核心思路------"让 CLI 告诉 AI 该做什么,AI 只管按 CLI 的指引生成内容"。
Steps
markdown
1. **If no clear input provided, ask what they want to build**
如果用户没提供明确输入,询问想构建什么
使用 AskUserQuestion 工具(开放式提问,不设预设选项)
**IMPORTANT**: 不理解用户意图前,不能继续
2. **Create the change directory**
创建变更目录:openspec new change "<name>"
3. **Get the artifact build order**
获取制品构建顺序:openspec status --change "<name>" --json
从返回的 JSON 中解析:
- applyRequires: 实现前需要完成的制品 ID 数组(如 ["tasks"])
- artifacts: 所有制品及其状态和依赖关系
4. **Create artifacts in sequence until apply-ready**
按依赖顺序逐个创建制品,直到满足实现条件
使用 TodoWrite 工具跟踪进度
循环处理制品(依赖已满足的优先):
a. 获取指令:openspec instructions <artifact-id> --change "<name>" --json
b. 指令 JSON 包含:
- context: 项目背景信息(对你的约束------不要写入输出文件)
- rules: 制品特定规则(对你的约束------不要写入输出文件)
- template: 输出文件的结构模板
- instruction: 该制品类型的 schema 特定指导
- outputPath: 制品写入路径
- dependencies: 需要读取作为上下文的已完成制品
c. 读取已完成的依赖制品获取上下文
d. 使用 template 结构创建制品文件
e. 将 context 和 rules 作为约束应用------但不复制到文件中
5. **Show final status**
显示最终状态:openspec status --change "<name>"这个流程的精妙之处在于:skill 文件不包含任何制品依赖逻辑。具体谁是 ready、谁的依赖满足,全部由 CLI 的 JSON 输出决定。把依赖计算委托给 CLI,skill 就对制品结构变化"免疫"------换 schema、新增制品、修改依赖关系,skill 文件都不需要改。
术语解释:Schema可替换性
OpenSpec 支持不同的规格模板(schema),Skill 不需要硬编码文件路径和依赖关系,而是通过 CLI 动态获取当前使用的 schema 对应的文件列表和构建顺序。这使得 OpenSpec 可以灵活适应不同项目的需求。
隐性约束机制
markdown
**IMPORTANT**: `context` and `rules` are constraints for YOU, not content for the file
重要:context 和 rules 是给你的约束,不是文件内容
- Do NOT copy <context>, <rules>, <project_context> blocks into the artifact
- 不要把这些约束块复制到制品文件中
These guide what you write, but should never appear in the output
它们指导你写什么,但绝不出现在输出中这是隐性约束:AI 在生成制品内容时必须内化这些约束,但不把约束本身写出来。类比:建筑设计师收到"预算不超过 100 万"的约束,最终设计体现了这个约束,但图纸上不会写这句话。
Guardrails
markdown
## Guardrails
- Create ALL artifacts needed for implementation → 创建实现所需的所有制品
- Always read dependency artifacts before creating a new one → 创建新制品前,先读依赖制品
- If context is critically unclear, ask the user → 如果上下文严重不清晰,询问用户
- But prefer making reasonable decisions to keep momentum → 但优先做出合理决策以保持推进
- Verify each artifact file exists after writing before proceeding → 写入后验证文件存在再继续4.3 apply:实现任务
核心声明:
从 OpenSpec 变更中实现任务。
Steps
markdown
1. **Select the change**
选择变更------从对话上下文中推断,或只有一个活动时自动选择,有歧义时让用户选择
2. **Check status to understand the schema**
检查状态以了解使用的 schema:openspec status --change "<name>" --json
解析 schema 名称和哪个制品包含任务
3. **Get apply instructions**
获取实现指令:openspec instructions apply --change "<name>" --json
返回内容:
- 上下文文件路径(随 schema 变化)
- 进度(总数、已完成、剩余)
- 任务列表及状态
- 基于当前状态的动态指令
处理三种状态:
- "blocked"(制品未完成):建议先用 continue skill 完成制品
- "all_done"(全部完成):恭喜,建议归档
- 其他:继续实现
4. **Read context files**
读取上下文文件(proposal、specs、design、tasks 等)
文件列表随 schema 变化------spec-driven schema 读取 proposal/specs/design/tasks
其他 schema 跟随 CLI 返回的 contextFiles
5. **Show current progress**
显示当前进度
6. **Implement tasks (loop until done or blocked)**
逐项实现任务(循环直到完成或阻塞):
- 显示正在处理的任务
- 执行所需的代码修改
- 保持修改最小化、聚焦
- 标记任务完成:- [ ] → - [x]
- 继续下一个任务
暂停条件:
- 任务不清晰 → 请求澄清
- 实现暴露设计问题 → 建议更新制品
- 遇到错误或阻塞 → 报告并等待指导
- 用户中断
7. **On completion or pause, show status**
完成或暂停时显示状态输出模板
源码定义了三种输出格式:
markdown
**实现中**:
## Implementing: <change-name> (schema: <schema-name>)
Working on task 3/7: <task description>
✓ Task complete
**完成时**:
## Implementation Complete
**Progress:** 7/7 tasks complete ✓
**暂停时**:
## Implementation Paused
**Progress:** 4/7 tasks complete
**Issue Encountered**: <description>
**Options**: 1... 2... 3...这些模板确保 AI 在任何状态下都有一致的输出格式。
Guardrails
markdown
## Guardrails
- Keep going through tasks until done or blocked → 持续推进任务直到完成或阻塞
- Always read context files before starting → 开始前始终读取上下文文件
- If task is ambiguous, pause and ask before implementing → 任务模糊时,先问再做
- If implementation reveals issues, pause and suggest artifact updates → 发现问题时暂停并建议更新制品
- Keep code changes minimal and scoped to each task → 代码修改最小化,聚焦当前任务
- Update task checkbox immediately after completing → 完成一个任务立即标记
- Pause on errors, blockers, or unclear requirements - don't guess → 遇错、遇阻塞、需求不清时暂停------不要猜测
- Use contextFiles from CLI output, don't assume specific file names → 使用 CLI 返回的文件列表,不要假设具体文件名流体工作流声明
markdown
**Fluid Workflow Integration**
This skill supports the "actions on a change" model:
- **Can be invoked anytime**: 可在任何时机调用------制品未全部完成时、部分实现后、与其他操作交错进行
- **Allows artifact updates**: 允许更新制品------实现中发现设计问题,建议更新制品,不是阶段锁定的apply 不是"阶段锁定"的------它可以在任何时候被调用,也可以建议更新制品。这是 OpenSpec "fluid not rigid" 原则在 skill 层面的直接体现。
4.4 archive:归档收尾
核心声明:
归档一个已完成的变更。
Steps
markdown
1. **If no change name provided, prompt for selection**
未提供变更名时,让用户选择
**IMPORTANT**: 不要猜测或自动选择,始终让用户选择
2. **Check artifact completion status**
检查制品完成状态:openspec status --change "<name>" --json
如果有制品未完成 → 显示警告,列出未完成的制品,确认用户是否继续
3. **Check task completion status**
检查任务完成状态:读取 tasks 文件统计未完成项
如果有未完成任务 → 显示警告,确认用户是否继续
4. **Assess delta spec sync state**
评估 delta spec 同步状态:检查 openspec/changes/<name>/specs/ 是否存在
如果存在 delta spec → 与主规格对比,显示变更摘要,让用户选择是否同步
5. **Perform the archive**
执行归档:mv openspec/changes/<name> openspec/changes/archive/YYYY-MM-DD-<name>
6. **Display summary**
显示归档完成摘要Delta Spec 同步机制
术语解释:Delta Spec 增量规格,即本次变更相对于主规格的修改内容,采用 ADDED/MODIFIED/REMOVED 的补丁格式。每个变更的规格修改都被记录在变更目录中,归档时才同步到主库------比直接修改主规格更安全,因为变更可能在实现过程中被取消或修改。

Guardrails
markdown
## Guardrails
- Always prompt for change selection if not provided → 未提供变更名时必须提示选择
- Use artifact graph for completion checking → 使用制品图(CLI JSON 输出)检查完成状态
- Don't block archive on warnings - just inform and confirm → 不要在警告上阻塞------只提示和确认
- Preserve .openspec.yaml when moving to archive → 归档时保留 .openspec.yaml
- If delta specs exist, always run sync assessment → 有 delta spec 时,始终运行同步评估五、底层机制:三层行为控制架构
从源码层面看,每个 SKILL.md 文件都使用三种控制手段,形成清晰的三层架构:
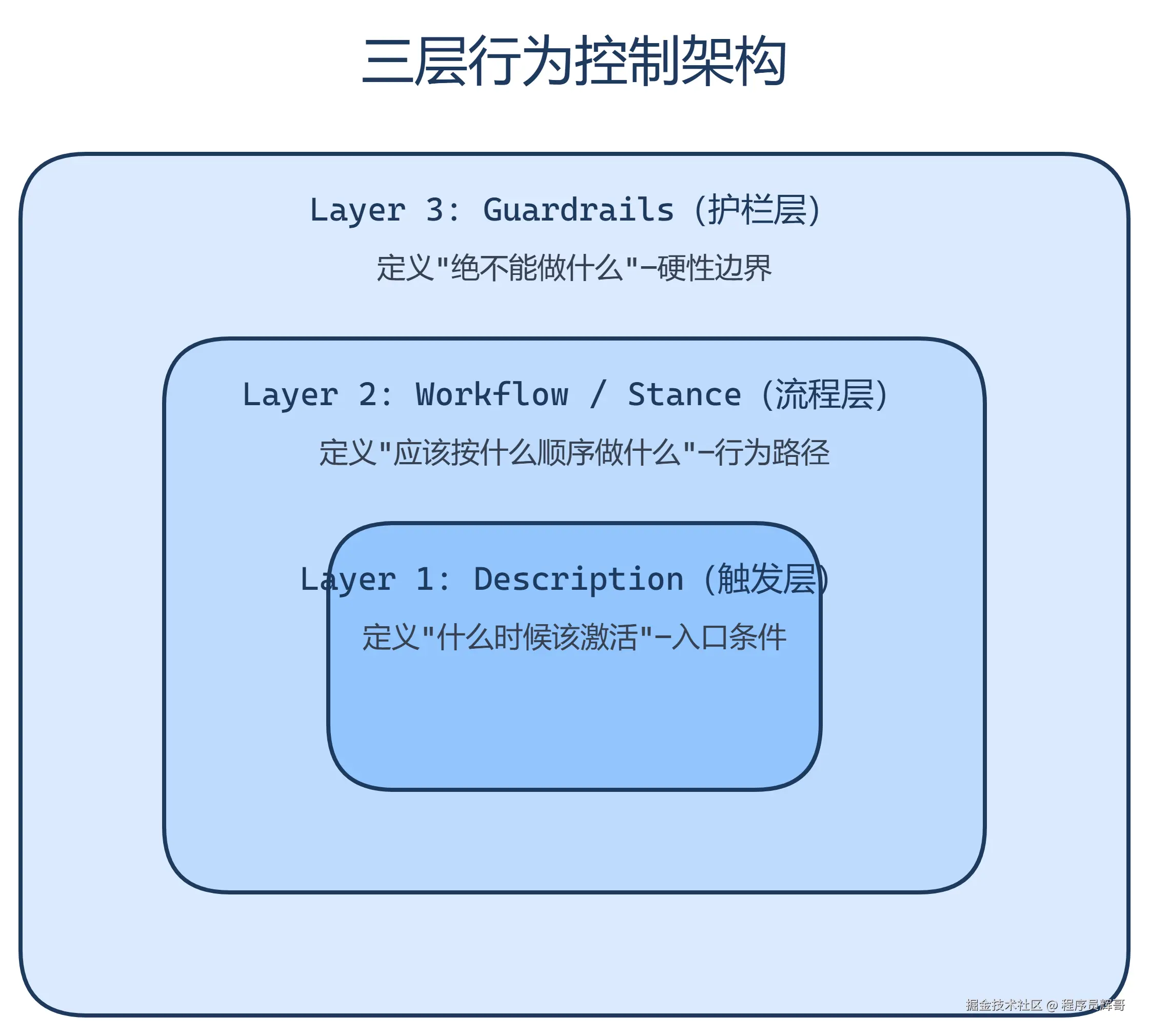
5.1 Layer 1: Description 触发层
frontmatter 中的 description 字段,只做一件事:告诉 AI 的 skill 选择系统"什么时候应该加载这个 skill"。
看 OpenSpec 四个 skill 的 description(直接来自源码,附中文翻译):
yaml
# explore
description: Enter explore mode - a thinking partner for exploring ideas,
investigating problems, and clarifying requirements.
Use when the user wants to think through something before or during a change.
# 中文:进入探索模式------用于探索想法、调查问题、澄清需求的思考伙伴。
# 当用户想要在变更前或变更中仔细思考时使用。
# propose
description: Propose a new change with all artifacts generated in one step.
Use when the user wants to quickly describe what they want to build
and get a complete proposal with design, specs, and tasks ready
for implementation.
# 中文:一步创建新变更及其所有制品。
# 当用户想快速描述要构建什么,并获取包含设计、规格和任务清单的完整提案时使用。
# apply-change
description: Implement tasks from an OpenSpec change.
Use when the user wants to start implementing, continue implementation,
or work through tasks.
# 中文:实现 OpenSpec 变更中的任务。
# 当用户想开始实现、继续实现、或逐项处理任务时使用。
# archive-change
description: Archive a completed change in the experimental workflow.
Use when the user wants to finalize and archive a change after
implementation is complete.
# 中文:归档实验工作流中已完成的变更。
# 当用户想在实现完成后收尾并归档一个变更时使用。四个 description 有三个共同特征:
- 都以 "Use when..." 开头------专注触发条件而非功能描述
- 都描述场景而非流程------不说"有 5 个步骤",只说"什么场景下该用"
- 都包含具体的症状信号------"想要思考"、"想要开始实现"、"想要归档"
5.2 Layer 2: Workflow / Stance 流程层
流程层是 OpenSpec 设计最精妙的地方之一。
两种控制哲学,分别对应不同的场景:
| 类型 | 适用 Skill | 源码特征 | 适用场景 |
|---|---|---|---|
| Workflow | propose, apply, archive | 有 ## Steps 章节,步骤编号 1→2→3→... |
确定性操作 |
| Stance | explore | 无 ## Steps,只有 ## The Stance |
不确定性探索 |
为什么 explore 用 stance 而其他三个用 workflow
回到第一性原理:
- explore 的场景是"不确定的探索"。如果给 AI 固定流程,它会在不相关的问题上仍然按流程走(浪费 token),或在真正有趣的线索上过早收束(因为"流程要求下一步做 X")
- propose/apply/archive 的场景是"确定性操作"。制品依赖顺序是 CLI 计算出来的,给 AI 固定流程能减少决策犹豫、确保制品完整性、保证状态一致性
核心洞察:不确定性场景用 stance 控制认知模式,确定性场景用 workflow 控制操作路径。混用会导致两种问题------要么探索被流程束缚,要么操作被自由发挥搞乱。
5.3 Layer 3: Guardrails 护栏层
每个 skill 底部都有一个 ## Guardrails 章节,定义了"绝不能做的事情"。
从源码中提取的关键护栏:
| Skill | 源码护栏 | 护栏类型 | 针对的 AI 失败模式 |
|---|---|---|---|
| explore | Don't implement - Never write code | 行为边界 | AI 天然倾向于"帮助用户实现需求" |
| explore | Don't auto-capture - Offer, don't do it | 主动性边界 | AI 天然倾向于"主动保存信息" |
| propose | Do NOT copy context/rules into file | 内容边界 | AI 天然倾向于"把所有信息写进文件" |
| propose | Create ALL artifacts needed | 完整性约束 | AI 可能跳过某些制品 |
| apply | Pause on errors, don't guess | 安全性约束 | AI 天然倾向于"尽可能完成任务" |
| apply | Keep code changes minimal | 范围约束 | AI 可能过度修改代码 |
| archive | Do NOT guess or auto-select | 自主性边界 | AI 天然倾向于"选择最合理选项并继续" |
| archive | Don't block on warnings | 流畅性约束 | AI 可能过度保守地阻塞操作 |
护栏的硬度分层
从源码措辞来看,护栏有三种硬度:
| 硬度级别 | 源码措辞 | 适用场景 |
|---|---|---|
| 绝对禁止型 | NEVER write code、Do NOT guess |
关键边界,绝不突破 |
| 建议暂停型 | Pause if: task is unclear |
需要判断的条件场景 |
| 偏好引导型 | Prefer making reasonable decisions |
非关键场景,允许灵活处理 |
这种分层硬度让 AI 在不同场景下有不同级别的约束------关键边界绝不突破,非关键场景可以灵活处理。
六、适用场景
适合的场景
- 中等以上复杂度的变更:涉及多个模块、需要设计决策的功能开发
- 团队协作开发:需要规格文档作为团队契约的场景
- AI 辅助开发的长期项目:需要规格持久化以防止上下文丢失
- 需要追溯决策路径的场景:合规、审计或事后复盘
不适合的场景
- 简单改动:改个配置项、修个 typo,完整的规格流程显得过度
- 一次性脚本:不需要规格追溯的一次性代码
- 快速原型验证:需要快速试错,规格反而会成为负担
OpenSpec 自己的哲学是 "fluid not rigid"、"easy not complex"------在实战中,它最适合中等以上复杂度的变更。
七、可汲取的六条设计经验
经验一:行为与状态解耦
Skill 管理行为姿态("不要写代码"、"按任务逐项实现"),CLI 管理制品状态(依赖图、状态追踪),两者独立迭代。explore skill 的 Guardrails 只定义行为边界,不碰制品状态;CLI 的 openspec status --json 只返回状态数据,不指导 AI 行为。改 skill 不影响制品,改制品也不影响 skill。
启示:将行为指令与状态管理解耦,让两个系统可以各自演进。
经验二:动态依赖图替代硬编码规则
制品依赖关系不是 skill 硬编码的,而是由 CLI 在运行时动态计算返回。propose skill 的步骤只说"按依赖顺序处理制品"------具体谁依赖谁,完全由 CLI JSON 输出决定。换 schema、新增制品、修改依赖关系,skill 文件都不需要改。
启示:将结构与行为指令解耦,避免配置文件变成"死规则"。
经验三:Stance 与 Workflow 匹配场景不确定性
同一个体系内,探索阶段用 stance(6 条行为原则,无固定步骤),执行阶段用 workflow(明确的步骤 1→2→3→...)。explore 用 stance 是因为场景信息不完整,需要"边看边想";规格和实现阶段目标明确,用 workflow 能避免混乱。
启示:为不同场景匹配不同控制强度。不确定性高的场景用原则引导,确定性高的场景用流程约束。
经验四:自由环入口设计
四个 skill 每个都可以独立进入,不必从头走完整个流程。已有规格文档可以直接进入实现;变更已实现完成但没有走流程也可以直接归档。
启示:降低用户进入门槛,已有制品直接复用。这比强制线性流程更容易被团队接受。
经验五:隐性约束保持制品纯净
context 和 rules 是 CLI 返回给 AI 的约束,AI 必须内化这些约束但绝不把它们写入制品文件。制品文件只包含规格内容,不包含 AI 的思考过程和生成限制,后续阶段读取不会困惑。
启示:区分"生成时的约束"和"生成的内容"。约束指导 AI 如何产出,但不应泄漏到产出物中。
经验六:软安全优于硬阻塞
archive 的四层确认都是"警告但不阻塞"------检查制品完成状态、任务完成状态、delta spec 同步状态,有未完成项时只警告并让用户确认,不阻止操作。不中断用户工作流,同时确保用户了解风险。
启示:在不可逆操作中,告知风险让用户决策,比直接阻止更友好也更实用。
经验七:可发现性与精确性的权衡
Description 只写触发条件而不写功能细节,是为了避免 AI 只读 description 就"以为"自己知道了该怎么做,然后跳过完整的 SKILL.md 内容。这是 discoverability(可发现性)和 precision(精确性)之间的权衡------description 只负责告诉 AI"什么时候该用我",具体"怎么用"必须读取完整的 skill 内容。
启示:在设计 AI 指令系统时,要明确区分"触发信息"和"执行信息",避免信息过载导致的执行偏差。
总结
OpenSpec 不是一个简单的文档模板,而是一个完整的 AI 辅助开发方法论。它通过四个精心设计的 Skill,将模糊的聊天对话转化为结构化、可追溯、可执行的规格文档,从根本上解决了 AI 辅助开发中的需求漂移、上下文丢失和不可回溯问题。
本文从源码层面深入拆解了 OpenSpec 的四个 Skill,分析了它们的执行流程和底层机制,并提炼出了可复用的设计经验。希望这篇文章能帮助你不仅学会使用 OpenSpec,更能理解它背后的设计思想,从而更好地利用 AI 提升开发效率。