如果说 encoder 更像一个"读者",decoder 就更像一个"写作者"。它的工作不是把整句编码成一个稳定表示,而是在每一个时刻回答一个更尖锐的问题:在已经看到前文、也许还看到外部条件的前提下,下一个 token 最应该是什么?
这个目标听起来只比 encoder 多了一个"预测下一个 token",但结构后果非常大。为了保证训练目标和推理过程一致,decoder 必须同时满足三件事:
- 能利用已经生成的历史;
- 不能偷看未来;
- 如果有外部输入,还要能读取 encoder 提供的 memory。
这三件事恰好对应 decoder 里那三块子层:masked self-attention、cross-attention、FFN。把这三块真正理解之后,GPT、T5、BART、翻译模型、对话模型之间的关系就都会清楚很多。
一、decoder layer 的骨架比 encoder 多一块
encoder 一层有两块:self-attention + FFN。decoder 一层比它多了一个中间层:cross-attention。
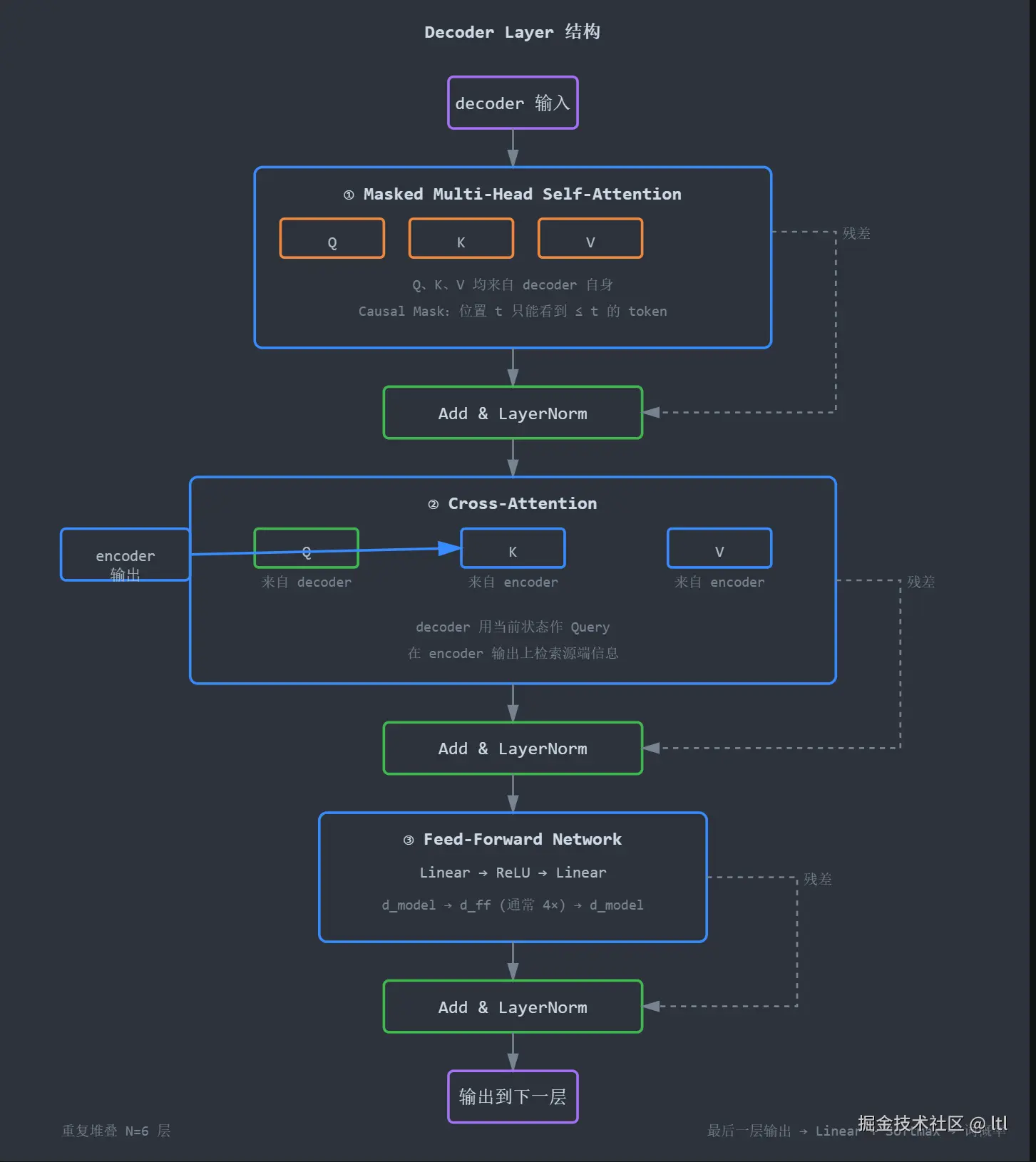 把一层展开,原论文的 post-LN 形式可以写成:
把一层展开,原论文的 post-LN 形式可以写成:
h1h2y=LayerNorm(x+MaskedMHA(x))=LayerNorm(h1+CrossAttn(h1,M))=LayerNorm(h2+FFN(h2))
这里的 M 是 encoder 最后一层输出的 memory。
如果换成现代更常见的 pre-LN,归一化会被挪到每个子层前面,但结构关系不变:
- 先做 masked self-attention;
- 再做 cross-attention;
- 最后做 FFN。
1.1 为什么必须是这个顺序
这个顺序不是随便排的。
- 先 masked self-attention:先把当前目标序列内部的历史整理出来,构造"我已经说到哪儿了"的状态。
- 再 cross-attention:拿着这个状态去 encoder memory 里查外部信息,决定接下来该对齐输入里的什么内容。
- 最后 FFN:对已经融合了历史和外部信息的表示做非线性重写。
如果把顺序倒过来,比如先 cross-attention 再 masked self-attention,会让"我要查什么外部信息"这件事缺少明确的目标历史状态,语义上很别扭。
二、第一块:masked self-attention 让 decoder 只看过去
decoder 的核心约束在这里。
如果不加 mask,训练时位置 t 在预测第 t 个 token 时,能直接看见真实答案 yt 甚至更后面的 yt+1,yt+2。这样 loss 会很好看,但模型学到的是作弊,不是生成。
所以 decoder 的 self-attention 必须加一个下三角 mask:

对应的打分矩阵可以写成:
S=dk QK⊤+Mask
其中:
Maskij={0,−∞,j≤ij>i
softmax 之后,所有未来位置的概率都变成 0。
2.1 这和 encoder 的 self-attention 只差一个 mask
公式上确实只差一个 mask,但行为差别极大。
- encoder:每个位置从第一层起就能看左右文,适合理解;
- decoder:每个位置只能看历史,适合生成。
从这个意义上说,causal mask 不是小补丁,而是 decoder 这条路线的结构分水岭。没有它,就没有 GPT 式自回归语言模型。
2.2 训练时可以并行,推理时必须串行
很多人一开始会被这里绕住:既然 decoder 只能看过去,那训练是不是也必须一个 token 一个 token 跑?
不是。训练时我们知道整条目标序列,只需要用 mask 保证第 t 个位置在计算时"看不见未来",就可以把所有位置一次性算出来。这叫 teacher forcing。
举个例子,目标序列是:
text
[BOS, 我, 喜欢, 机器, 学习]训练时:
- 位置 0 预测
我 - 位置 1 预测
喜欢 - 位置 2 预测
机器 - 位置 3 预测
学习
这四个位置可以在同一次前向里并行计算,因为 mask 已经保证每个位置只看自己的左侧历史。
但推理时不同。模型真正生成时并不知道未来 token,只能:
- 先输入
[BOS],预测出我; - 再输入
[BOS, 我],预测出喜欢; - 再输入
[BOS, 我, 喜欢],预测出机器; - 继续往后。
所以训练并行、推理串行,不是矛盾,而是同一套自回归约束在两种信息条件下的自然结果。
三、第二块:cross-attention 是 decoder 读取输入的唯一通道
如果有 encoder,decoder 还需要再读一遍源序列。这个动作就是 cross-attention。

它和 self-attention 最大的区别不是公式,而是 Q/K/V 的来源:
- Query:来自 decoder 当前层的隐藏状态;
- Key、Value:来自 encoder 最后一层输出。
写成公式是:
CrossAttn(Qdec,Kenc,Venc)=softmax(dk QdecKenc⊤)Venc
3.1 这一步是"条件生成"真正发生的地方
翻译任务里,decoder 并不是无条件地续写目标语言,而是在"已经生成的目标前缀"和"源句内容"这两个条件下继续写。
例如英语翻法语:
text
source: I love machine learning.
target prefix: J'当 decoder 需要决定下一个 token 是 aime 还是别的词时:
- masked self-attention 提供的是"我前面已经写了
J'"; - cross-attention 提供的是"源句里还有
love machine learning这些内容等着我对齐"。
只有两者结合,模型才知道"下一步既要符合目标语言历史,也要忠实于输入条件"。
3.2 没有 encoder 时,这一块可以整块删掉
这就是 GPT 系列为什么能把原始 decoder 改成 decoder-only。
如果任务是纯语言建模,条件就只剩左侧历史,不再有外部 memory。那 cross-attention 整块都可以去掉,decoder layer 就退化成:
- masked self-attention
- FFN
这也是现代大模型最常见的 block 形式。
所以从原论文到 GPT 的演化,不是发明了全新结构,而是把"带 cross-attention 的 decoder"裁成了"没有 cross-attention 的 decoder-only"。
四、第三块:FFN 负责把"历史 + 条件"重写成可预测状态
decoder 里的 FFN 和 encoder 里的 FFN 在公式上没有区别,但它吃到的输入语义完全不同。
encoder 的 FFN 看到的是"已经融合了全句上下文的表示";decoder 的 FFN 看到的是"已经融合了历史前缀,甚至还融合了 encoder memory 的表示"。
因此 decoder 里的 FFN 更像是在做下面这件事:
把当前生成位置的综合状态压成一个足够适合下一个 token 分类的隐藏向量。
这也是为什么很多语言模型的"事实回忆""风格偏好""模板填充"之类能力,最后都落到 decoder block 里的 FFN 和 residual stream 上,而不只是注意力本身。
五、训练和推理的数据流,要分开看才不会混
很多关于 decoder 的误解,都是把训练图和推理图混在一起导致的。下面把两者彻底分开。
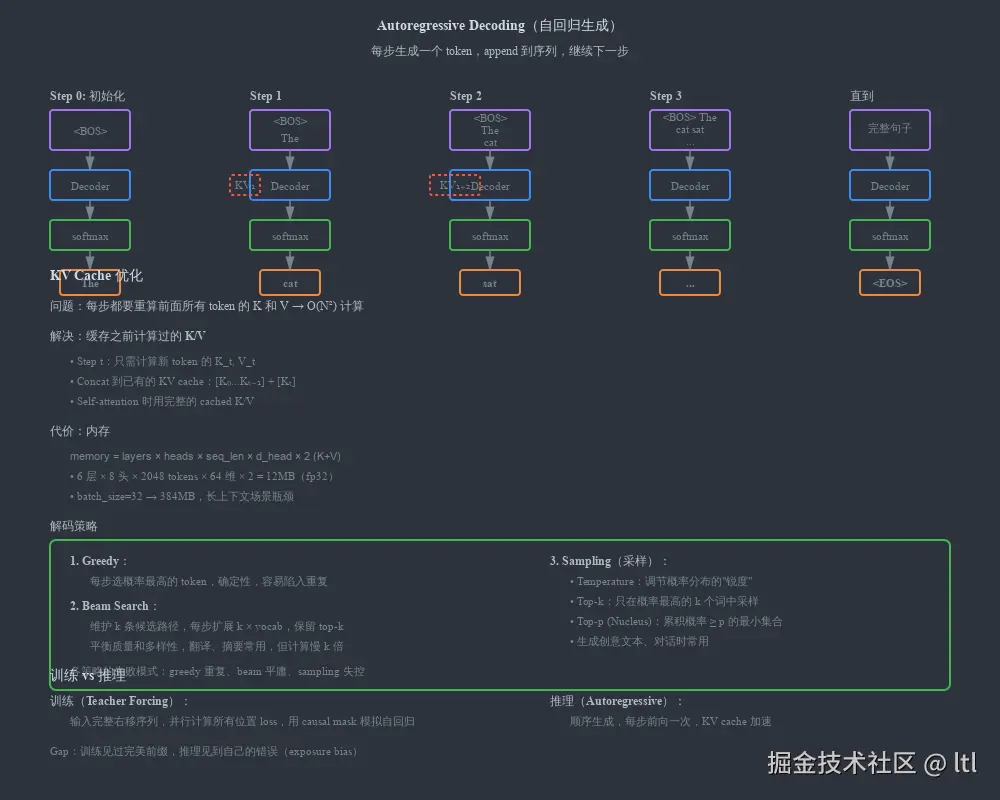
5.1 训练:一次性吃完整个目标前缀
训练时我们已经知道 ground-truth target,所以可以把目标序列右移一位,整体喂进 decoder:
text
decoder input : [BOS, y1, y2, ..., y_{T-1}]
training label: [y1, y2, y3, ..., y_T]然后用 causal mask 保证每个位置只利用左侧历史。
这带来两个直接好处:
- 训练可以并行,吞吐高;
- 每个 batch 提供了所有位置的监督信号。
5.2 推理:每一步只新增一个 token
推理时没有标签,模型必须自己生成。于是 decoder 的状态会随着前缀增长不断扩展。每一步只多一个 token,但必须基于之前全部历史。
这就是为什么:
- 推理天然串行;
- KV cache 会成为关键工程优化;
- 长上下文时 decoder-only LLM 的 latency 问题比训练更尖锐。
5.3 teacher forcing 也带来了 exposure bias
训练时 decoder 总是看到真实前缀;推理时看到的是自己刚生成出来、可能带误差的前缀。两者分布不完全一致,这就是 exposure bias。
机器翻译和文本生成里很多后续工作------scheduled sampling、sequence-level training、RLHF 某种意义上的 rollout 反馈------都在绕这个问题打补丁。
六、为什么 decoder 天生适合生成
现在可以把结论说得更硬一点:decoder 适合生成,不是因为"论文里刚好拿它做生成",而是因为它的结构从一开始就是围着生成目标设计的。
6.1 每个位置的训练目标和推理动作一致
decoder 每个位置学的是:
p(yt∣y<t,x)
如果没有外部条件 x,就是:
p(yt∣y<t)
这和真实生成时做的事情完全一致:给历史前缀,预测下一个 token。结构、目标、推理过程三者是对齐的。
6.2 历史状态天然累积在 residual stream 里
随着 token 一个一个生成,decoder 每一层的 residual stream 都在累积"到目前为止我已经说了什么"。这种状态不是 RNN 那种显式 hidden state,但效果上非常类似,只是它通过 attention 读取整段历史,而不是只传一个压缩向量。
6.3 对外部条件也很友好
如果任务是翻译、摘要、问答、多模态生成,decoder 只要加回 cross-attention,就能在保留自回归生成能力的同时,读取外部输入。这种"既能无条件生成、又能条件生成"的弹性很强。
这也是为什么从 2017 年到今天,decoder 这条路线一直没有消失,只是从"完整 encoder-decoder 里的右半边"演化成了"GPT 式 decoder-only 主干"。
七、为什么今天大模型大多是 decoder-only
这个问题本篇先给结构层面的答案,后面讲训练范式时会再补数据与目标层面的原因。
7.1 互联网文本天然适合 next-token 目标
大规模预训练数据多数是普通文本。对这种数据来说,最自然、最统一、几乎不用额外标注的训练目标就是 next-token prediction。decoder-only 和这个目标天生匹配。
7.2 统一接口特别简单
无论是对话、写作、代码补全、摘要、翻译、工具调用,最后都能转成:
text
给定一段前缀,继续生成后面的 token这让 decoder-only 在产品接口上极其统一。
7.3 少掉 cross-attention,结构和工程都更干净
没有 encoder,就没有两套 tower、没有 cross-attention、没有 source/target 两张图。模型主干、推理缓存、并行切分、部署系统都会简单不少。
当然,简单不等于无代价。decoder-only 在纯理解任务上未必是最省样本或最优雅的结构,但在"一个模型覆盖尽量多任务"的大模型时代,它的统一性优势太大了。
八、几个常见误解
8.1 "decoder 就是 encoder 多了个 mask"
不够准确。它不只多了 mask,还多了"自回归目标"这整个训练-推理闭环。没有这个闭环,mask 只是一个矩阵操作;有了这个闭环,decoder 才成为生成模型。
8.2 "cross-attention 是可有可无的附加模块"
对 decoder-only LLM 来说可以没有;但对翻译、摘要、条件生成来说,它就是读取输入条件的唯一主通道。删掉它,模型就失去"对齐输入"的核心能力。
8.3 "训练时 decoder 不能并行,所以慢"
错。训练时有 teacher forcing 和 causal mask,所有位置可以一次性并行算出来。真正串行的是推理。
8.4 "decoder-only 一定比 encoder-decoder 更先进"
不是。它只是更适合大规模统一预训练与通用生成。翻译、摘要、语音识别、某些多模态生成任务里,encoder-decoder 仍然很有竞争力,因为输入输出天然是两段不同序列。
8.5 "decoder 只能做文本生成"
也不对。代码、音频 token、图像 token、动作序列都可以做自回归生成。关键不是"文本",而是"序列化的下一步预测"。
九、结语
decoder 真正特别的地方,不在于公式比 encoder 复杂一点,而在于它把"只能看过去"这条约束写进了结构里,再把"预测下一个 token"这件事写进了训练目标里。masked self-attention 负责守住时间方向,cross-attention 负责读取外部条件,FFN 负责把这些信息重写成当前时刻的可预测状态。
理解了这一点,你再看 GPT、T5、BART、翻译模型、对话模型,就会发现它们并不是五花八门的不同东西,而是在同一个 decoder 思想上做裁剪和扩展。下一篇我们先不继续讲生成,而是退回到每一层里那条经常被画成一根细线、却真正决定深层网络能不能训起来的东西:残差连接。
十、参考文献
- Vaswani, A. et al. "Attention Is All You Need." NeurIPS 2017. 原始 decoder 结构与 masked self-attention、cross-attention 定义。
- Bahdanau, D., Cho, K., Bengio, Y. "Neural Machine Translation by Jointly Learning to Align and Translate." ICLR 2015. cross-attention 思想的直接前身。
- Radford, A. et al. "Improving Language Understanding by Generative Pre-Training." OpenAI Technical Report, 2018. decoder-only 路线在大规模预训练中的早期代表。
- Radford, A. et al. "Language Models are Unsupervised Multitask Learners." OpenAI Technical Report, 2019. GPT-2 把 decoder-only 统一生成接口推向主流。
- Brown, T. et al. "Language Models are Few-Shot Learners." NeurIPS 2020. decoder-only 规模化后的能力展示。
- Raffel, C. et al. "Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer." JMLR 2020. encoder-decoder 在统一文本生成任务上的代表工作。
← 上一篇:22|Encoder 详解 | 下一篇:24|残差连接 →