周末的时候,微信读书官方发布了一个 weread skills。
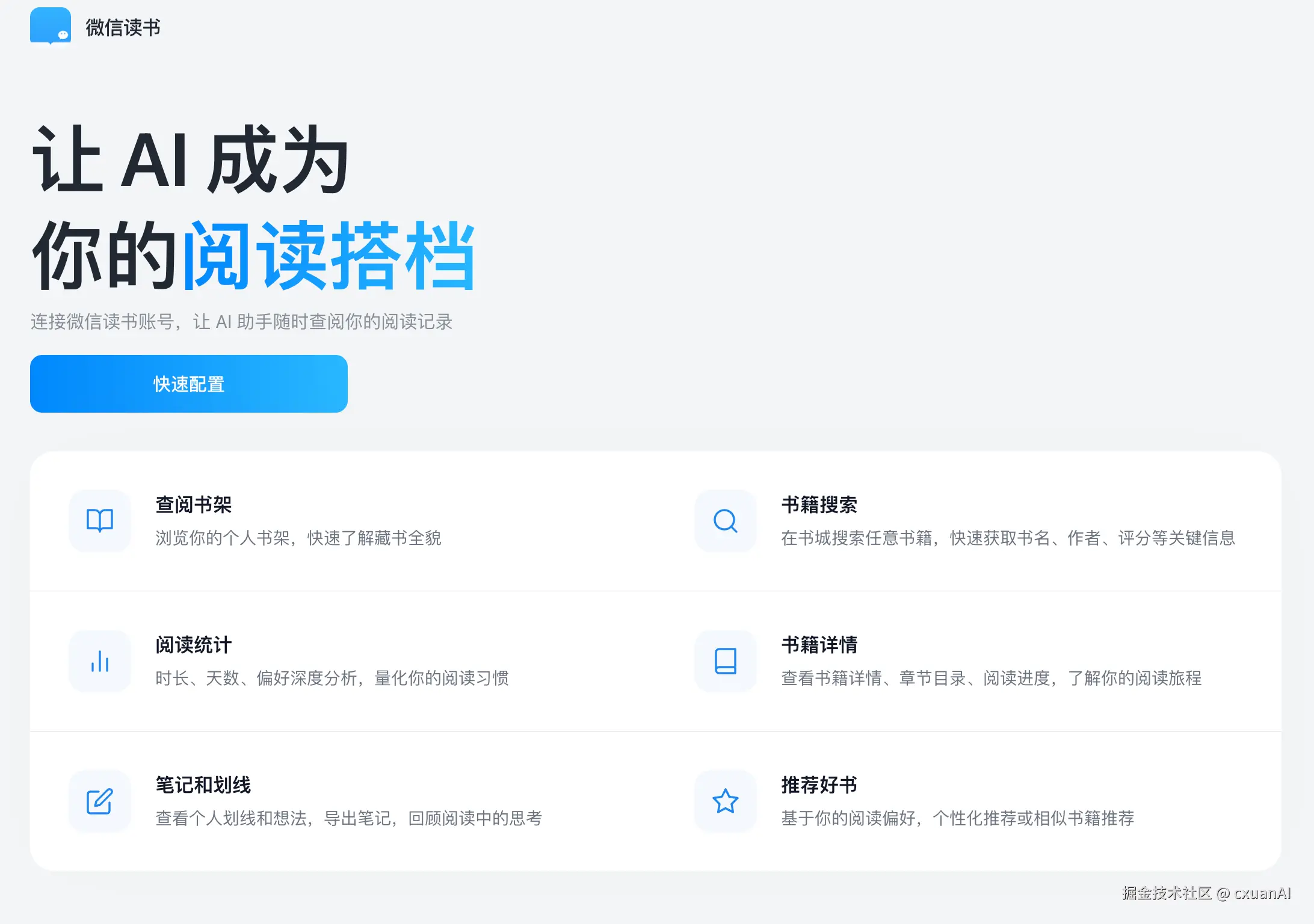
不得不说微信读书这波是走在前列的。
这篇就跟大家聊聊如何配置微信读书的 --- weread skills。
首先你需要登录 weread.qq.com/r/weread-sk...
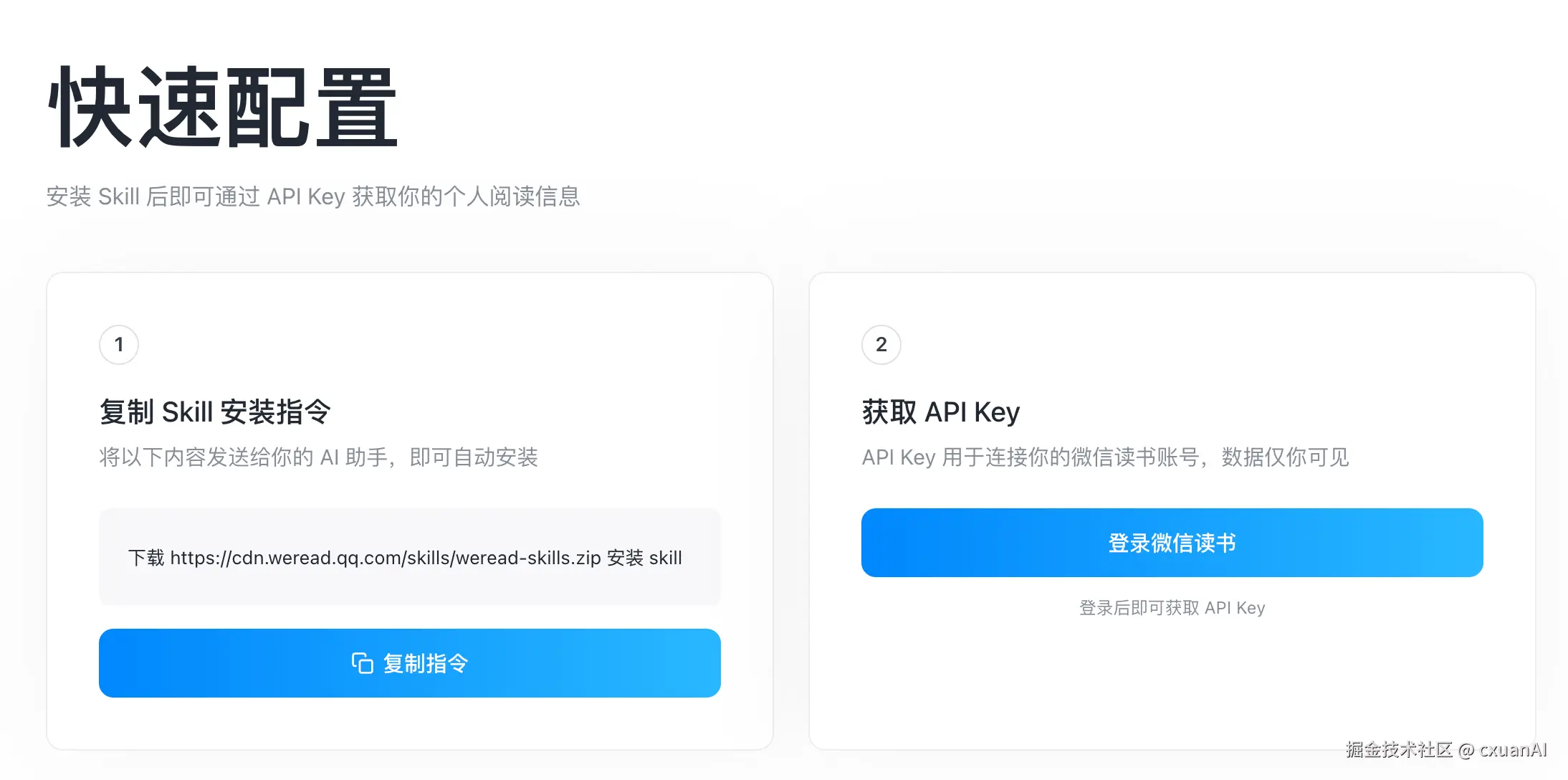
然后把 "下载 cdn.weread.qq.com/skills/were... 安装 skill" 这条指令直接扔给你的 AI 。
我这里是直接让 Codex 帮我装完了。
下载完成后其实是个 skills 包,里面包括了这些 skill 。

简单来说,这些 skill 相当于能帮助你做下面这些事情:
-
搜书 / 搜内容 支持搜电子书、网文、有声书/专辑、作者、全文、书单、公众号、文章等。
-
看书籍信息 查书籍详情、目录章节、阅读进度、累计阅读时长。
-
看书架 拉取你的书架列表,统计电子书、有声书/专辑、文章收藏、公开/私密阅读数量。
-
看阅读统计 查本周、本月、今年、总计阅读时长、阅读天数、读得最多的书、偏好分类、偏好时段、偏好作者等。
-
导出/查看笔记划线 可以看所有有笔记的书、单本书划线、个人想法/点评、热门划线、划线下的想法等。
-
看公开书评 查某本书的全部、推荐、最新、差评、一般点评。
-
推荐书 获取个性化推荐,或者基于某本书找相似书。
-
生成微信读书 App 跳转链接 能拼 weread://reading?... 这类深度链接,跳到书籍、章节、划线位置。
这里限制也很明确:它目前主要是读取/查询类能力 ,没看到添加书架、删除书、写笔记、修改书评这类写操作;而且不能导出书签内容,只能统计书签数量,划线和想法可以导出。
也就是说,基本上你在微信读书上的关于读取和查询的功能,这个 skills 都给你内置好了。
下载完成后,你需要登录一下微信读书,拿到 api-key。
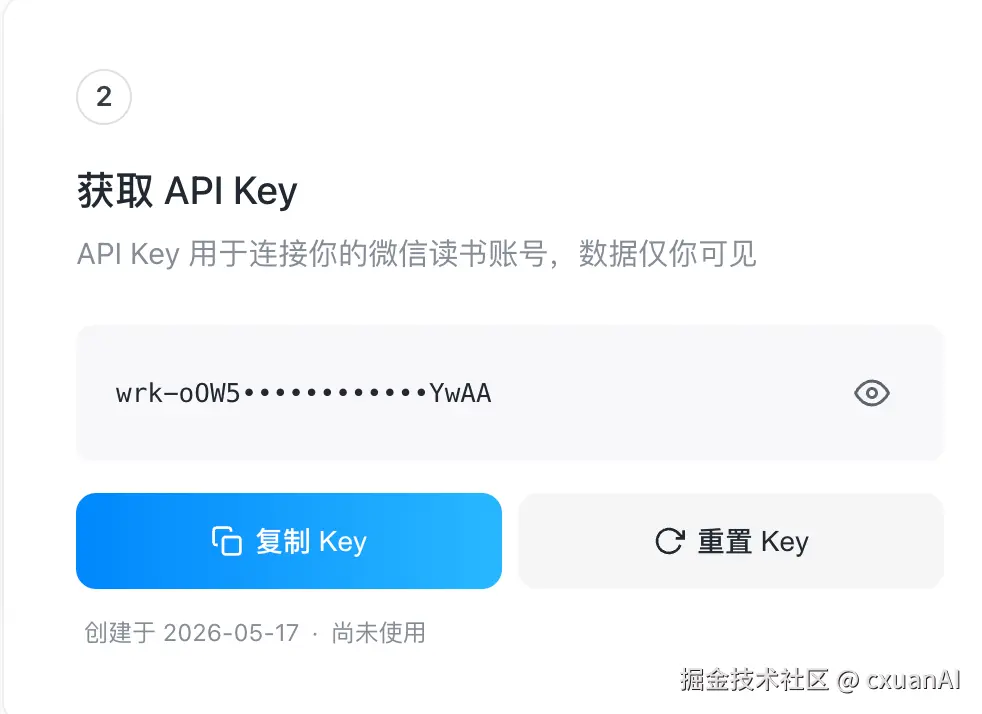
出于安全因素的考虑,最好不要把 api-key 直接扔给 AI ,所以这一步最好自己配置一下 api-key。
ini
export WEREAD_API_KEY="你的微信读书 api-key"直接在 ~/.zhsrc 里面加一条,然后 source ~/.zshrc 就可以了。
配置完成后,你就可以直接让 AI 帮你统计,或者你自己直接在 cli 中统计了。
比如我可以直接问 AI :
搜一些大模型的书籍,10 本就好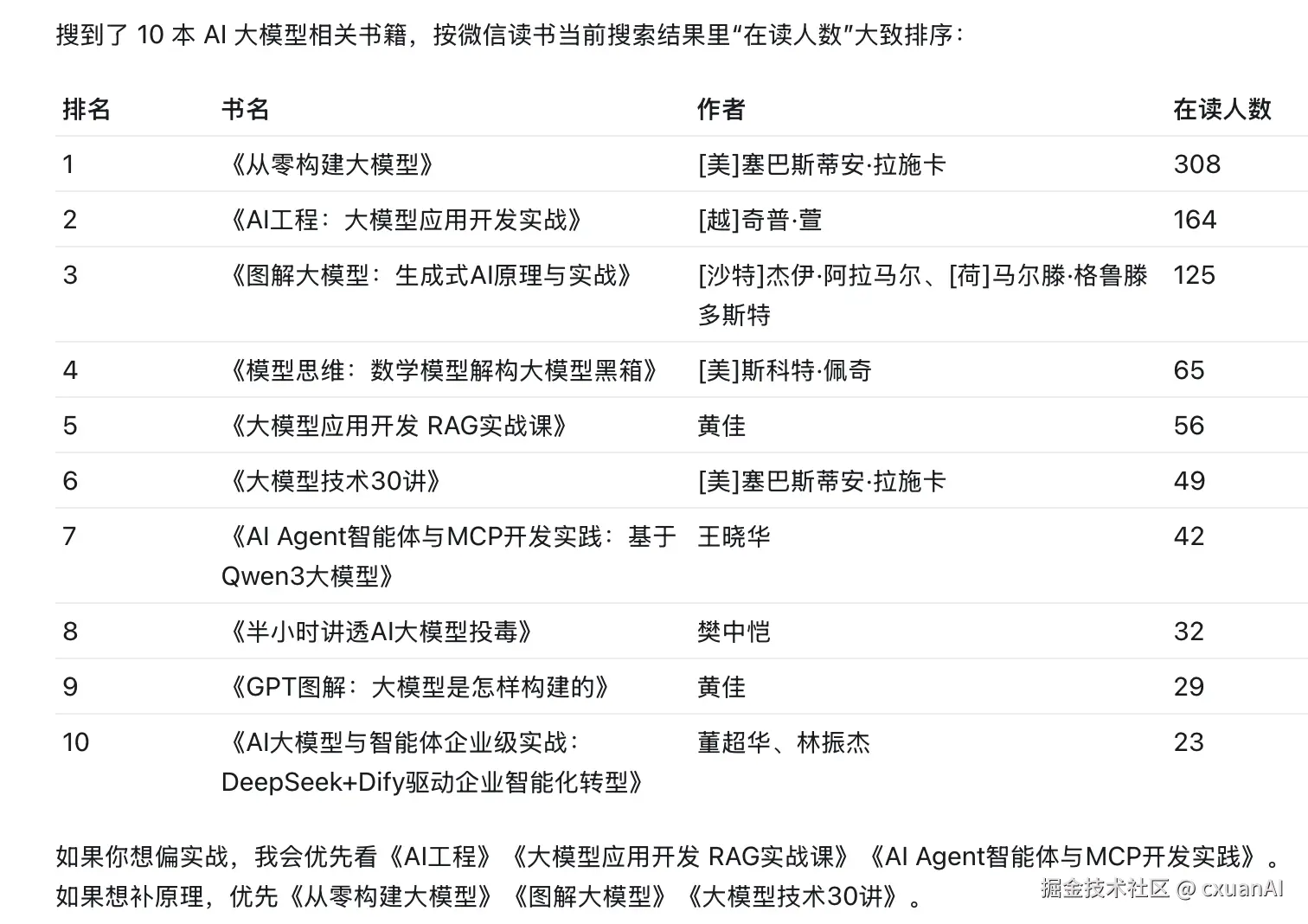
比如我可以让他看一下我阅读《凡人修仙传》的进度情况:
看一下我读凡人修仙传的进度
括号里面的备注好突兀。。。。。。
他还可以看你的书架信息。
还可以看我今年的阅读情况
统计一下我今年的阅读情况
呃呃呃,看到这个结果有些羞愧。
今年确实没怎么好好看书,一直都在折腾 AI 了,然后还在带娃。。。。。。
不找这些外部理由了,没看就是没看,规划一下,后面要捡起来。不能只有输出,没有输入。
我还可以让他看一下书评情况
查看所有书籍的笔记划线情况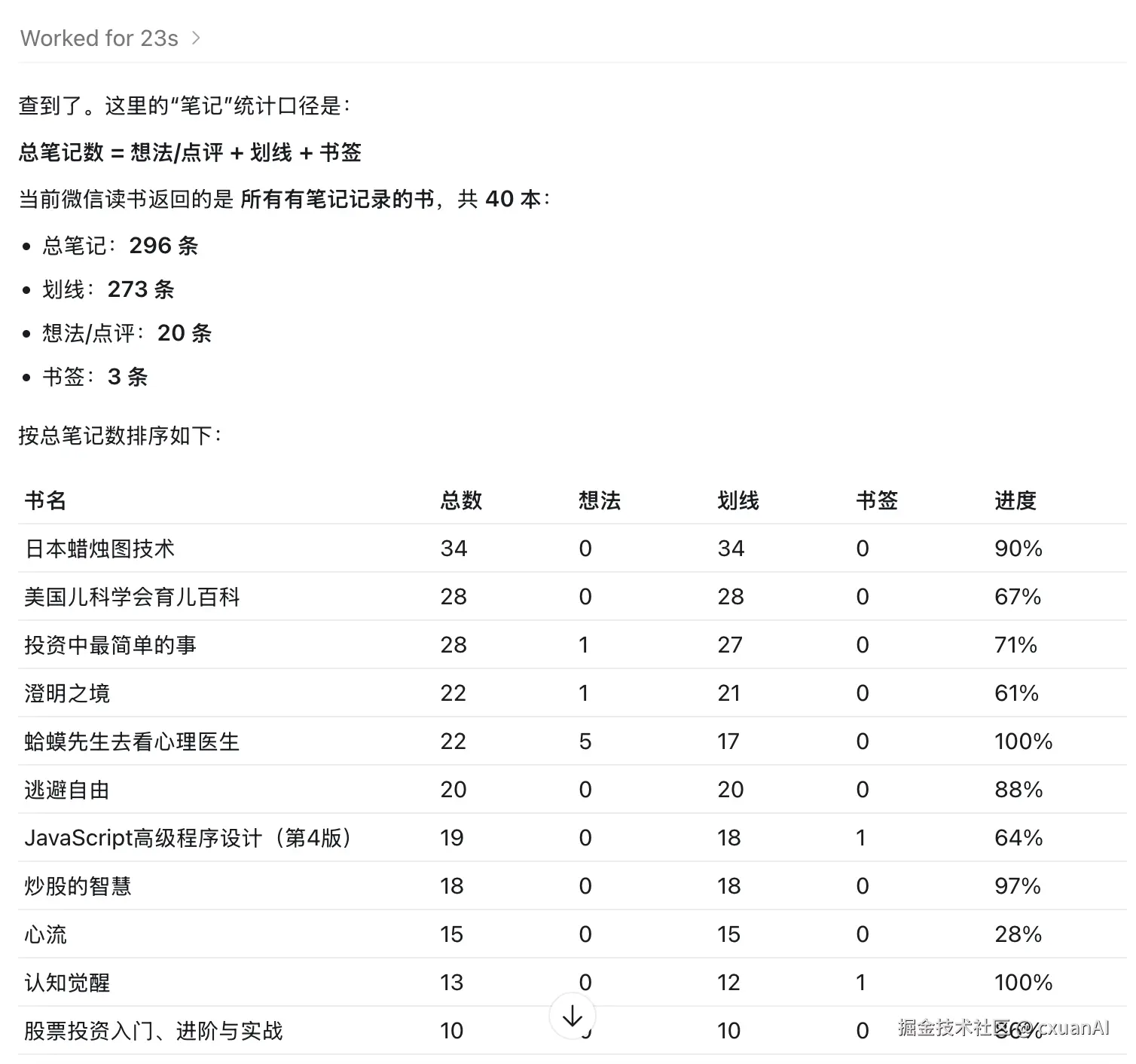
甚至我可以让他查看某些书籍的公开书评
看一下《鲁迅全集》的公开书评
你还可以让他推荐一些不同方向的好书,比如我这里让他推荐了一下科技领域的好书有哪些
推荐一下 科技领域内的好书,不局限于 AI LLM
这个推荐书单确实挺不错,我对这些书确实还挺有兴趣的。
最后一个 skill 技能有点意思。
这个功能本质上是:把微信读书里的某个位置,拼成一个 weread://... 开头的 App 深度链接。
你点这个链接,系统会尝试直接打开微信读书 App,并跳到对应的书、章节,甚至某条划线位置。
我说实话,这个功能是有点说法的,就这个功能,它可以实现 URL 级别的裂变效应,把流量都导入到微信读书中。
比如我可以针对书评做成 URL 分享。

确实,这个 url 可以直接打开。
以上是针对普通大众玩家的用自然语言来描述的玩法。
如果你想玩的更 Geek 一些,下面还有进阶操作
CLI 是进阶玩法,不是必选项
当然,如果你是程序员,也可以直接在命令行里调。
官方这个 skill 底层其实就是一个统一网关:
ruby
https://i.weread.qq.com/api/agent/gateway请求的时候带上:
bash
Authorization: Bearer $WEREAD_API_KEY然后 body 里传:
json
{
"api_name": "/shelf/sync",
"skill_version": "1.0.3"
}就可以查书架。
比如查书架,可以这样:
json
curl -sS -X POST "https://i.weread.qq.com/api/agent/gateway" \
-H "Authorization: Bearer $WEREAD_API_KEY" \
-H "Content-Type: application/json" \
-d '{"api_name":"/shelf/sync","skill_version":"1.0.3"}'查阅读统计:
json
curl -sS -X POST "https://i.weread.qq.com/api/agent/gateway" \
-H "Authorization: Bearer $WEREAD_API_KEY" \
-H "Content-Type: application/json" \
-d '{"api_name":"/readdata/detail","mode":"overall","skill_version":"1.0.3"}'搜书:
json
curl -sS -X POST "https://i.weread.qq.com/api/agent/gateway" \
-H "Authorization: Bearer $WEREAD_API_KEY" \
-H "Content-Type: application/json" \
-d '{"api_name":"/store/search","keyword":"三体","scope":10,"count":5,"skill_version":"1.0.3"}'但说实话,这种方式我不建议普通用户日常用。
因为它比较繁琐。
它更适合两类人:
第一类,你想把微信读书数据接到自己的脚本里。
第二类,你想做一个自己的阅读看板,比如统计每个月读了多少、读完哪些书、哪类书读得最多。
如果只是临时查一下,直接让 AI 调 skill 就够了。
我觉得这个东西非常有意义。说到底,它不是一个多复杂的东西。
它没有帮你写文章。
没有帮你自动读书。
也没有神奇到可以替你理解一本书。
但它做了一件很关键的事情:
它把你的阅读数据开放给了 AI。
这件事儿就不一样了。
因为以前微信读书里的数据是被锁在 App 里的。
你能看,但很难二次加工。
你能翻,但很难批量统计。
你能划线,但很难把划线变成结构化笔记。
现在有了 skills,AI 就可以围绕你的阅读数据做很多事情。
它可以帮你复盘。
可以帮你整理。
可以帮你发现自己的阅读偏好。
可以帮你把碎片化的划线变成文章。
可以帮你把一本书里的想法重新串起来。
这才是我觉得它真正有价值的地方。
现在你的阅读记录也接入 AI 工作流了。
如果这篇文章对你有启发,欢迎三连,也可以转发给同样关注 AI / 科技 / 开发效率的朋友。 我是 cxuanAI,会持续记录 AI 工具、技术趋势和科技圈里值得关注的变化。