YOLOv10 轮毂缺陷检测(下)------模型推理与 PyQt5 可视化应用
系列导读 :本文是"YOLOv10 轮毂缺陷检测"系列的第二篇。上一篇介绍了环境搭建、数据集准备与模型训练。本篇将聚焦模型推理测试 与完整 PyQt5 可视化检测应用的开发,带你从训练权重到一个可交付的桌面端检测工具。
一、回顾:训练结果获取
经过上篇的训练流程,runs/train/my_first_exp/weights/best.pt 就是我们获得的最优检测模型权重。将其复制到应用目录:
bash
# 将最优权重复制到应用目录
copy runs\train\my_first_exp\weights\best.pt ..\project\best.pt接下来我们先用命令行快速验证模型效果,再开发图形界面。
二、命令行推理测试(pre.py)
在开发 GUI 前,建议先通过脚本方式验证模型推理结果,快速排查问题。
2.1 完整推理脚本
python
import os
import cv2
from ultralytics import YOLOv10
import glob
# 加载训练好的权重(best.pt)
model = YOLOv10(r'D:\YOLOv10_project\project\best.pt')
# ──────────────────────────────────────────────
# 功能1:单张图片推理
# ──────────────────────────────────────────────
def image_load(image_path):
frame = cv2.imread(image_path)
res = model(frame)
# plot() 方法:在原图上绘制检测框、类别标签和置信度
# 返回带标注的 BGR numpy 数组
ann = res[0].plot()
cv2.imshow("yolov10_image", ann)
cv2.waitKey(0) # 按任意键关闭窗口
# 解析检测框数据
boxes = res[0].boxes
if boxes is not None:
xyxy = boxes.xyxy.cpu().numpy() # 左上右下坐标 [x1,y1,x2,y2]
conf = boxes.conf.cpu().numpy() # 置信度 [0~1]
cls = boxes.cls.cpu().numpy() # 类别 ID [0,1,2]
print(f"边界框坐标:\n{xyxy}")
print(f"置信度: {conf}")
print(f"类别ID: {cls}")
# 保存标注后的图像
res[0].save(r"D:\YOLOv10_project\project\output.jpg")
# ──────────────────────────────────────────────
# 功能2:批量图片推理
# ──────────────────────────────────────────────
def images_load(images_path):
imgs = glob.glob(os.path.join(images_path, '*.jpg'))
for img in imgs:
# predict() 方法支持 save=True 自动保存结果
model.predict(img, save=True)
# ──────────────────────────────────────────────
# 功能3:视频/摄像头实时推理
# ──────────────────────────────────────────────
def video_load(video_path):
cap = cv2.VideoCapture(video_path) # 传入0则打开摄像头
while cap.isOpened():
ret, frame = cap.read()
if ret:
res = model(frame)
ann = res[0].plot()
cv2.imshow("yolov10_video", ann)
if cv2.waitKey(1) == 27: # 按 ESC 退出
break
cv2.destroyAllWindows()
cap.release()
if __name__ == '__main__':
# 测试单张图片
image_load(r'D:\YOLOv10_project\yolov10\dataset_part\dataset_part\images\train\c41.bmp')
# 测试文件夹
# images_load(r'D:\code\lingjianjiance\tu')
# 测试视频或摄像头
# video_load(0)
# video_load(r'D:\code\lingjianjiance\test_video.mp4')2.2 推理 API 核心解析
model(frame) 与 model.predict() 的区别:
| 调用方式 | 特点 | 适用场景 |
|---|---|---|
model(frame) |
直接调用,返回 Results 对象 | 自定义结果处理(手动解析 boxes) |
model.predict(img, save=True) |
封装更高级,支持批量+自动保存 | 快速批量推理,无需手动处理 |
results[0].boxes 属性详解:
python
boxes = results[0].boxes
boxes.xyxy # 绝对像素坐标 [x1,y1,x2,y2],Tensor 格式
boxes.xywh # 中心点+宽高 [cx,cy,w,h],Tensor 格式
boxes.conf # 置信度分数 [0.0~1.0]
boxes.cls # 类别 ID(整数)
boxes.data # 完整数据 [x1,y1,x2,y2,conf,cls]三、PyQt5 检测应用架构设计
3.1 整体架构
项目的 GUI 应用采用经典的分层架构:
┌─────────────────────────────────────────────────┐
│ 汽车零件缺陷检测系统.py │
│ (业务逻辑层 + 信号槽连接层) │
│ │
│ ┌────────────────┐ ┌──────────────────────┐ │
│ │ MainWindow │ │ DetectionThread │ │
│ │ (主窗口控制器)│◄──►│ (YOLOv10 检测线程) │ │
│ └────────────────┘ └──────────────────────┘ │
│ │ │ │
│ │ setupUi() │ pyqtSignal │
│ ▼ │ │
│ ┌────────────────┐ │ │
│ │ UiMain.py │◄──────────────┘ │
│ │ (UI 布局定义)│ │
│ └────────────────┘ │
└─────────────────────────────────────────────────┘三层职责分离:
| 文件 | 职责 |
|---|---|
UiMain.py |
纯 UI 布局定义,不包含业务逻辑(类似前端的 HTML) |
DetectionThread |
YOLOv10 推理逻辑,继承 QThread 异步执行 |
MainWindow |
事件处理与状态管理,连接 UI 和检测线程 |
3.2 多线程设计的必要性
YOLOv10 推理是 CPU/GPU 密集型任务,单帧推理耗时约 10~100ms。若在主线程(UI 线程)中直接调用推理,将导致:
- 界面冻结卡顿(无法响应用户操作)
- 视频/摄像头检测丢帧严重
- 用户体验极差
解决方案:将推理任务放入 QThread 工作线程 ,通过 pyqtSignal 信号机制将结果安全地传回主线程更新 UI。
主线程(UI 线程) 工作线程(DetectionThread)
│ │
│── 创建线程,start() ──────────────► │
│ │── 执行推理
│ │── emit(frame_received)
│◄── 信号跨线程安全传递 ──────────────│
│── on_frame_received() 更新UI │
│ │四、UI 布局(UiMain.py)详解
4.1 界面结构
┌──────────────────────────────────────────────────────┐
│ [选择模型] [模型路径] 置信度:[0.80] IoU:[0.50] │ ← 配置栏
├──────────────────────────────────────────────────────┤
│ [图片检测] [视频检测] [摄像头检测] [停止检测] [保存] │ ← 功能按钮
├────────────────────┬─────────────────────────────────┤
│ │ │
│ 原始图像 │ 检测结果图像 │ ← 图像显示区
│ │ │
├────────────────────┴─────────────────────────────────┤
│ 检测类别 置信度 中心X 中心Y │ ← 结果表格
├──────────────────────────────────────────────────────┤
│ 状态栏:正在检测图片: c41.bmp │ ← 状态栏
└──────────────────────────────────────────────────────┘
4.2 核心 UI 组件代码解析
python
class UiMainWindow(object):
def setupUi(self, MainWindow):
# 窗口基本设置
MainWindow.resize(1200, 800) # 默认尺寸
MainWindow.setMinimumSize(1000, 700) # 最小尺寸限制
# ── 配置栏 ──────────────────────────────
# 置信度调节(步长0.05,默认0.8)
self.confidence_spinbox = QDoubleSpinBox()
self.confidence_spinbox.setRange(0.1, 0.99)
self.confidence_spinbox.setSingleStep(0.05)
self.confidence_spinbox.setValue(0.8) # 默认置信度阈值
# IoU阈值调节(步长0.05,默认0.5)
self.iou_spinbox = QDoubleSpinBox()
self.iou_spinbox.setRange(0.1, 0.99)
self.iou_spinbox.setSingleStep(0.05)
self.iou_spinbox.setValue(0.5) # 默认IoU阈值
# ── 图像显示区 ────────────────────────────
# 原始图像(左侧)
self.original_image_label = QLabel()
self.original_image_label.setMinimumSize(400, 300)
self.original_image_label.setStyleSheet("border: 1px solid #cccccc;")
self.original_image_label.setAlignment(Qt.AlignCenter)
# 检测结果图像(右侧)
self.result_image_label = QLabel()
# ...(同上)
# ── 结果表格 ──────────────────────────────
self.table_widget = QTableWidget()
self.table_widget.setColumnCount(4)
self.table_widget.setHorizontalHeaderLabels(
["检测类别", "置信度", "中心X", "中心Y"]
)
# 列自适应拉伸
self.table_widget.horizontalHeader().setSectionResizeMode(
QHeaderView.Stretch
)4.3 图像显示方法
UI 中最核心的图像处理方法------将 numpy BGR 数组转为 Qt 可显示的 Pixmap:
python
def display_image(self, label, image):
"""
将 numpy RGB 数组显示到 QLabel
:param label: 目标 QLabel 组件
:param image: numpy 数组(RGB格式,注意不是BGR)
"""
h, w, ch = image.shape
bytes_per_line = ch * w
# numpy → QImage(必须是 RGB888 格式)
qt_image = QImage(image.data, w, h, bytes_per_line,
QImage.Format_RGB888)
# QImage → QPixmap,并按 label 尺寸缩放(保持宽高比)
pixmap = QPixmap.fromImage(qt_image).scaled(
label.size(),
Qt.KeepAspectRatio, # 保持宽高比
Qt.SmoothTransformation # 平滑缩放(抗锯齿)
)
label.setPixmap(pixmap)注意 :OpenCV 读取图像默认为 BGR 格式,Qt 需要 RGB 格式,因此在传给
display_image()前必须使用cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)转换。
五、检测线程(DetectionThread)详解
5.1 线程设计
python
class DetectionThread(QThread):
# 信号定义(在类级别声明,非实例变量)
frame_received = pyqtSignal(np.ndarray, np.ndarray, list)
# 参数含义:(原始帧 RGB, 检测结果帧 RGB, 检测结果列表)
finished_signal = pyqtSignal() # 线程完成通知
def __init__(self, model, source, conf, iou, parent=None):
super().__init__(parent)
self.model = model # YOLOv10 模型实例
self.source = source # 图片路径 / 视频路径 / 摄像头编号(int)
self.conf = conf # 置信度阈值
self.iou = iou # IoU 阈值
self.running = True # 控制线程停止的标志位5.2 run() 方法:自适应多源处理
python
def run(self):
try:
# ── 视频 / 摄像头模式 ────────────────────
if isinstance(self.source, int) or \
self.source.endswith(('.mp4', '.avi', '.mov')):
cap = cv2.VideoCapture(self.source)
while self.running and cap.isOpened():
ret, frame = cap.read()
if not ret:
break
original_frame = frame.copy() # 保存原始帧副本
# YOLOv10 推理
results = self.model(frame, conf=self.conf, iou=self.iou)
annotated_frame = results[0].plot() # 绘制检测框
# 解析检测结果
detections = []
for result in results:
for box in result.boxes:
class_id = int(box.cls)
class_name = self.model.names[class_id]
confidence = float(box.conf)
x, y, w, h = box.xywh[0].tolist() # 中心坐标+宽高
detections.append((class_name, confidence, x, y))
# 跨线程信号发送(BGR→RGB 转换)
self.frame_received.emit(
cv2.cvtColor(original_frame, cv2.COLOR_BGR2RGB),
cv2.cvtColor(annotated_frame, cv2.COLOR_BGR2RGB),
detections
)
time.sleep(0.03) # 控制约30fps帧率
cap.release()
# ── 图片模式 ─────────────────────────────
else:
frame = cv2.imread(self.source)
if frame is not None:
original_frame = frame.copy()
results = self.model(frame, conf=self.conf, iou=self.iou)
annotated_frame = results[0].plot()
detections = []
for result in results:
for box in result.boxes:
class_id = int(box.cls)
class_name = self.model.names[class_id]
confidence = float(box.conf)
x, y, w, h = box.xywh[0].tolist()
detections.append((class_name, confidence, x, y))
self.frame_received.emit(
cv2.cvtColor(original_frame, cv2.COLOR_BGR2RGB),
cv2.cvtColor(annotated_frame, cv2.COLOR_BGR2RGB),
detections
)
except Exception as e:
import traceback
tb = traceback.format_exc()
QMessageBox.critical(None, "检测错误",
f"检测过程中出现错误:{str(e)}\n\nTraceback:\n{tb}")
finally:
self.finished_signal.emit() # 无论成功/失败都发送完成信号
def stop(self):
"""外部调用此方法可安全停止线程"""
self.running = FalsepyqtSignal 跨线程通信原理:
工作线程 主线程(UI)
─────────────────────────────────────────
emit(orig, result, list) → Qt事件队列
↓
on_frame_received(orig, result, list)
↓
display_image() 更新图像
add_detection_result() 更新表格Qt 的信号槽机制保证了跨线程调用的线程安全性,无需手动加锁。
六、主窗口逻辑(MainWindow)详解
6.1 信号槽绑定
python
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.ui = UiMainWindow()
self.ui.setupUi(self)
# 绑定按钮事件
self.ui.model_btn.clicked.connect(self.select_model_file)
self.ui.image_btn.clicked.connect(self.detect_image)
self.ui.video_btn.clicked.connect(self.detect_video)
self.ui.camera_btn.clicked.connect(self.detect_camera)
self.ui.stop_btn.clicked.connect(self.stop_detection)
self.ui.save_btn.clicked.connect(self.save_result)
# 状态变量
self.model = None # YOLO 模型实例
self.detection_thread = None # 检测线程
self.last_detection_result = None # 最后一帧检测结果
self.selected_model_path = None # 当前选中的模型路径6.2 模型加载
python
def select_model_file(self):
"""打开文件对话框选择 .pt 模型文件"""
file_path, _ = QFileDialog.getOpenFileName(
self, "选择YOLO模型文件", "",
"PyTorch模型文件 (*.pt);;所有文件 (*.*)"
)
if file_path:
self.selected_model_path = file_path
# 界面只显示文件名,不显示完整路径(更简洁)
self.ui.model_path_label.setText(os.path.basename(file_path))
self.load_model(file_path)
def load_model(self, model_path):
"""加载 YOLO 模型,异常时弹窗提示"""
try:
self.model = YOLO(model_path)
self.ui.update_status(
f"模型加载成功:{os.path.basename(model_path)}"
)
except Exception as e:
QMessageBox.critical(self, "错误", f"模型加载失败: {str(e)}")6.3 图片检测流程
python
def detect_image(self):
# 1. 前置检查
if self.model is None:
QMessageBox.warning(self, "警告", "请先选择并加载模型!")
return
if self.detection_thread and self.detection_thread.isRunning():
QMessageBox.warning(self, "警告", "请先停止当前检测任务")
return
# 2. 打开文件选择对话框
file_path, _ = QFileDialog.getOpenFileName(
self, "选择图片", "",
"图片文件 (*.jpg *.jpeg *.png *.bmp)"
)
if file_path:
# 3. 显示原始图片
self.ui.clear_results()
img = cv2.imread(file_path)
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
self.ui.display_image(self.ui.original_image_label, img_rgb)
# 4. 获取阈值参数
conf = self.ui.confidence_spinbox.value()
iou = self.ui.iou_spinbox.value()
# 5. 创建并启动检测线程
self.detection_thread = DetectionThread(
self.model, file_path, conf, iou
)
self.detection_thread.frame_received.connect(self.on_frame_received)
self.detection_thread.finished_signal.connect(self.on_detection_finished)
self.detection_thread.start()
self.ui.update_status(f"正在检测图片: {os.path.basename(file_path)}")6.4 检测结果回调
python
def on_frame_received(self, original_frame, result_frame, detections):
"""
检测线程通过信号回调此方法(在主线程中执行)
"""
# 更新图像显示(双图对比)
self.ui.display_image(self.ui.original_image_label, original_frame)
self.ui.display_image(self.ui.result_image_label, result_frame)
# 保存最后一帧(用于保存功能)
self.last_detection_result = result_frame
# 更新结果表格
self.ui.clear_results()
for class_name, confidence, x, y in detections:
self.ui.add_detection_result(class_name, confidence, x, y)
# 视频模式:写入结果帧到输出视频
if self.video_writer:
# Qt RGB → OpenCV BGR
bgr_frame = cv2.cvtColor(result_frame, cv2.COLOR_RGB2BGR)
self.video_writer.write(bgr_frame)6.5 视频结果保存
视频检测时,自动将检测结果保存为带时间戳的 mp4 文件:
python
def detect_video(self):
# ...(省略前置检查)
# 获取视频属性(用于初始化写入器)
cap = cv2.VideoCapture(file_path)
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = cap.get(cv2.CAP_PROP_FPS)
cap.release()
# 初始化视频写入器
os.makedirs("results", exist_ok=True)
timestamp = time.strftime("%Y%m%d_%H%M%S")
save_path = os.path.join("results", f"result_{timestamp}.mp4")
fourcc = cv2.VideoWriter_fourcc(*'mp4v') # MP4 编码
self.video_writer = cv2.VideoWriter(
save_path, fourcc, fps, (frame_width, frame_height)
)
# ...(后续启动线程同图片检测)6.6 保存与资源释放
python
def save_result(self):
"""保存当前检测结果图片"""
if self.last_detection_result is None:
QMessageBox.warning(self, "警告", "没有可保存的检测结果")
return
os.makedirs("results", exist_ok=True)
timestamp = time.strftime("%Y%m%d_%H%M%S")
save_path = os.path.join("results", f"result_{timestamp}.jpg")
# RGB → BGR 再保存(OpenCV 格式要求)
cv2.imwrite(save_path, cv2.cvtColor(
self.last_detection_result, cv2.COLOR_RGB2BGR
))
self.ui.update_status(f"检测结果已保存: {save_path}")
def closeEvent(self, event):
"""窗口关闭时自动清理所有资源"""
self.stop_detection() # 停止线程 + 释放视频写入器
event.accept()七、完整使用流程
7.1 启动应用
bash
# 切换到应用目录
cd D:\YOLOv10_project\project
# 运行主程序(Fusion 样式,跨平台一致性)
python 汽车零件缺陷检测系统.py7.2 操作步骤
① 点击 [选择模型文件] → 选择 best.pt
↓ 状态栏显示 "模型加载成功:best.pt"
② 调整置信度阈值(默认0.80)和IoU阈值(默认0.50)
* 置信度越高 → 误检越少,但漏检可能增多
* IoU越低 → 重叠框过滤更宽松
③ 选择检测模式:
[图片检测] → 选择 .jpg/.png/.bmp 文件,立即显示检测结果
[视频检测] → 选择 .mp4/.avi 文件,逐帧检测并保存结果视频
[摄像头检测] → 打开摄像头0实时检测
④ 查看结果:
* 左侧:原始图像
* 右侧:带检测框的结果图像
* 下方表格:每个检测框的类别、置信度、位置
⑤ [保存结果] → 图片保存到 results/ 目录
⑥ [停止检测] → 停止视频/摄像头检测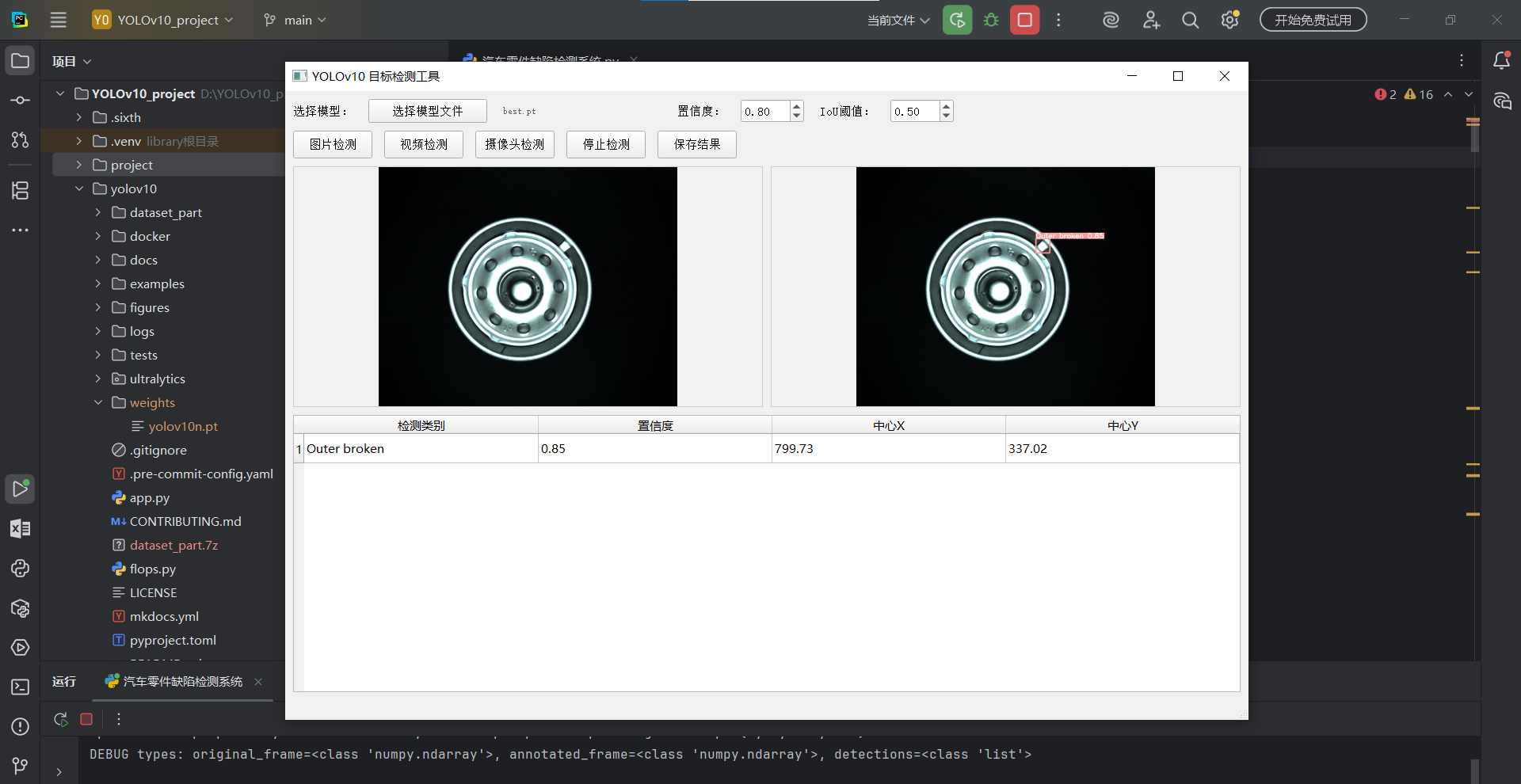
八、常见问题与解决方案
| 问题 | 原因 | 解决方案 |
|---|---|---|
ModuleNotFoundError: ultralytics |
未安装依赖 | uv pip install ultralytics |
CUDA out of memory |
显存不足 | 减小 batch 值或改用 device='cpu' |
| 界面显示但图像为空白 | BGR/RGB 格式混淆 | 确认传入 display_image 的是 RGB 格式 |
| 摄像头无法打开 | 摄像头被占用或编号错误 | 尝试 cv2.VideoCapture(1) |
| 训练时字体下载失败 | 网络问题 | 设置 os.environ['YOLO_FONT'] = r'C:\Windows\Fonts\Arial.ttf' |
.bmp 图片无法识别 |
文件格式过滤 | 在文件对话框过滤器中添加 *.bmp |
九、项目扩展建议
9.1 提升检测精度
python
# 训练时增加数据增强(在 train.py 中添加)
model.train(
data="mydata.yaml",
epochs=100, # 增加训练轮数
batch=16, # 增大批次(需更大显存)
imgsz=640,
augment=True, # 开启数据增强
hsv_h=0.015, # 色调变化
hsv_s=0.7, # 饱和度变化
flipud=0.1, # 垂直翻转
fliplr=0.5, # 水平翻转
mosaic=1.0, # Mosaic 增强
)9.2 模型量化与加速
python
# 导出为 ONNX 格式(推理速度更快)
model = YOLOv10("best.pt")
model.export(format="onnx", half=True, simplify=True)
# 导出为 TensorRT(NVIDIA GPU 最高性能)
model.export(format="engine", half=True)9.3 生产部署方案
| 部署方案 | 适用场景 | 特点 |
|---|---|---|
| ONNX Runtime | 通用 CPU/GPU | 无需 GPU 驱动,兼容性强 |
| TensorRT | NVIDIA GPU | 推理速度最快(3~5倍提升) |
| OpenVINO | Intel CPU/GPU | Intel 硬件专项优化 |
| CoreML | Apple 设备 | iOS/macOS 原生支持 |
十、总结
通过两篇文章,我们完整实现了一套基于 YOLOv10 的轮毂缺陷检测系统:
第一篇(上):
- ✅ YOLOv10 架构原理与模型选型
- ✅ uv 包管理器环境搭建
- ✅ 数据集标注格式与目录结构
- ✅ mydata.yaml + yolov10n_my.yaml 配置解析
- ✅ 迁移学习训练流程
第二篇(下):
- ✅ pre.py 命令行推理验证
- ✅ PyQt5 三层架构设计
- ✅ QThread 多线程异步推理
- ✅ pyqtSignal 跨线程信号通信
- ✅ 图片/视频/摄像头三种检测模式
- ✅ 检测结果保存与资源管理
整个项目代码量适中、结构清晰,非常适合作为工业视觉检测入门 或PyQt5 + YOLO 集成的参考项目。
📌 系列文章 :[← 上一篇:YOLOv10 轮毂缺陷检测(上)------环境搭建与模型训练](#← 上一篇:YOLOv10 轮毂缺陷检测(上)——环境搭建与模型训练)
📌 YOLOv10 官方仓库 :https://github.com/THU-MIG/yolov10
📌 uv 包管理器 :https://github.com/astral-sh/uv