一、什么是BeautifulSoup
BeautifulSoup,它是一个用于解析 HTML 和 XML 文档的 Python 库,能够从网页中提取数据,常用于网页抓取和数据挖掘。
- 非Python标准模块,需要手动安装
- 安装方式 pip/pip3 install beautifulsoup4
安装 pip3 install lxml # 推荐使用 lxml 作为解析器(速度更快)如果你没有 lxml,可以使用 Python 内置的 html.parser 作为解析器。
1.1 文档树结构
文档树结构。将字符串结构转换为文档树结构。
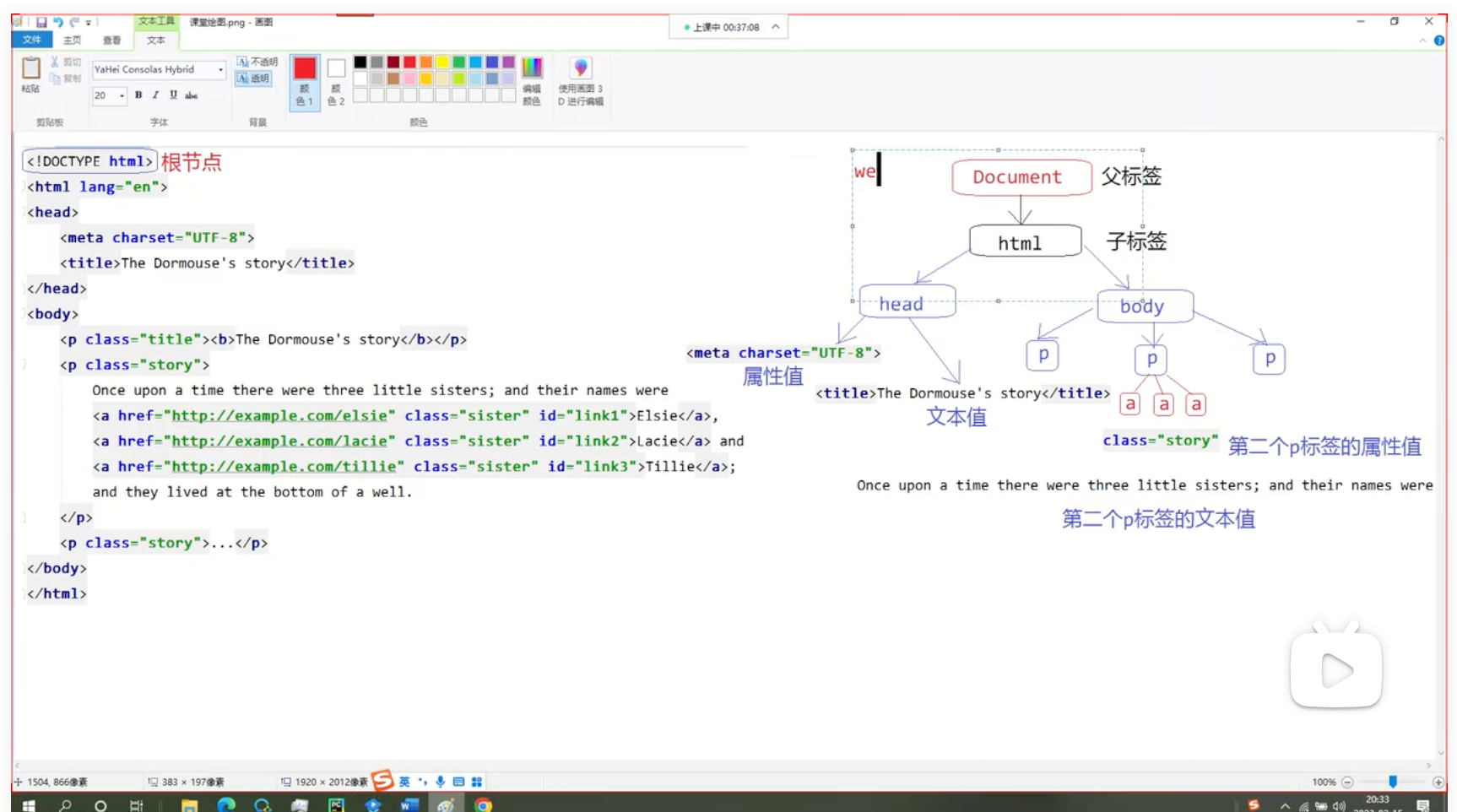
BeautifulSoup可以将字符串转换为文档树结构,方便解析。
1.2 BeautifulSoup装载HTML
BeautifulSoup容错:BeautifulSoup功能非常强大,它在装载过程中,如果发现HTML文档中的元素有缺失的情况下,它会尽可能的对文档进行修复,是的最后的文档树是一棵完整的文档树。
这一点十分重要。因为我们面临的大多数网页,或多或少有元素是缺失的,BeautifulSoup都能够正确装载它们。

小结:BeautifulSoup虽然功能强大能够修复一些缺失的HTML元素,但是它还没有智能到完全修复所有HTML文档错误的程度。
python
from bs4 import BeautifulSoup
import requests
# 使用 requests 获取网页内容
url = 'https://cn.bing.com/' # 抓取bing搜索引擎的网页内容
response = requests.get(url)
# 使用 BeautifulSoup 解析网页
soup = BeautifulSoup(response.text, 'lxml') # 使用 lxml 解析器
# 解析网页内容 html.parser 解析器
# soup = BeautifulSoup(response.text, 'html.parser')