2型糖尿病早期预警系统:当多参数集成模型学会"会诊"
想象一下:我们面前摆着一份体检报告------58岁,空腹血糖 6.8 mmol/L,BMI 27.3,γ-谷氨酰转肽酶轻度升高,低密度脂蛋白胆固醇偏高。单独看,没有一个指标越过确诊红线;但组合在一起,它们像几缕轻烟,隐约指向同一个方向:未来五年内发展为2型糖尿病的风险,可能远比我们以为的高。问题是,如何让算法像一位经验丰富的内分泌科主任一样,把这些散落的线索串成一条完整的证据链?别急,今天我们就来拆开一座真实运行的"数字会诊室",看看多参数集成分类模型到底在做什么。
目录
[第二站:从一张体检单到"特征向量"------渐进披露的 Toy Example](#第二站:从一张体检单到"特征向量"——渐进披露的 Toy Example)
第三站:基学习器集群------为什么需要一群"专科医生"?
第四站:元学习器融合------从"举手表决"到"加权会诊"
[第一步:硬投票(Hard Voting)](#第一步:硬投票(Hard Voting))
[第二步:软投票(Soft Voting)](#第二步:软投票(Soft Voting))
[算法 1:Stacking Ensemble 训练阶段](#算法 1:Stacking Ensemble 训练阶段)
[算法 2:单实例预测阶段(部署时)](#算法 2:单实例预测阶段(部署时))
[第六站:打开黑箱------SHAP 解释引擎如何工作?](#第六站:打开黑箱——SHAP 解释引擎如何工作?)
[直觉:从 Toy Example 开始](#直觉:从 Toy Example 开始)
[算法 3:特征归因(简化版)](#算法 3:特征归因(简化版))
第一站:整座"医院"的鸟瞰图
在继续之前,我们先退一步。如果把这个早期预警系统画成一座小型专科医院,它会长成什么样?
它不会只有一个诊室。真实系统中,数据从入口涌进来,要经过清洗对齐 、特征工程 、多专家并行诊断 、主任综合研判 、出具解释报告五个大区。我们可以把它想象成一条单向流水线,但每个工位上都站着不止一位"医生"。
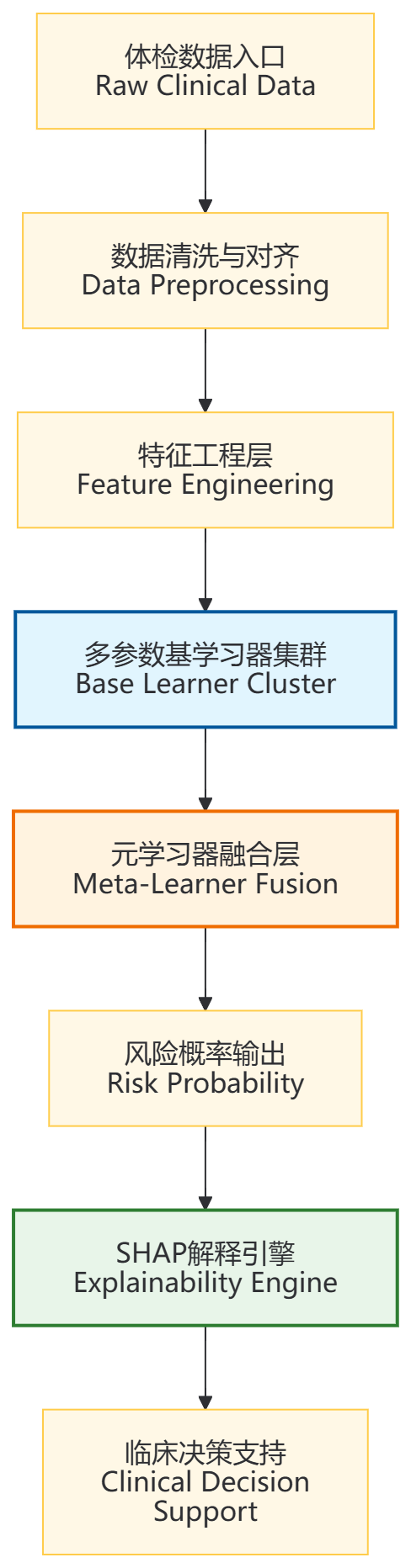
我们此刻站在医院大厅。 左边是急诊入口,各种格式的体检单、检验科报告、生活方式问卷从这里流入;右边是五个并行的专家诊室(基学习器集群),分别擅长不同的数据模式;最深处是主任医师办公室(元学习器),负责把各位专家的意见加权汇总;最后还有一间透明的玻璃房(SHAP解释引擎),把"为什么给出这个风险分"写成一份人人能读的报告。
听起来抽象对吧?没关系,我们现在已经了解了系统的"行政区划",接下来看看数据本身是如何从一张杂乱的体检单,变成模型能读懂的"病历摘要"的。
第二站:从一张体检单到"特征向量"------渐进披露的 Toy Example
让我们先玩一个极简的 toy example,再推广到真实规模。
假设世界上只有三个与糖尿病相关的指标:年龄、空腹血糖(FPG)、BMI。如果画成图,一份体检单就是一个小方框,里面躺着三个数字:
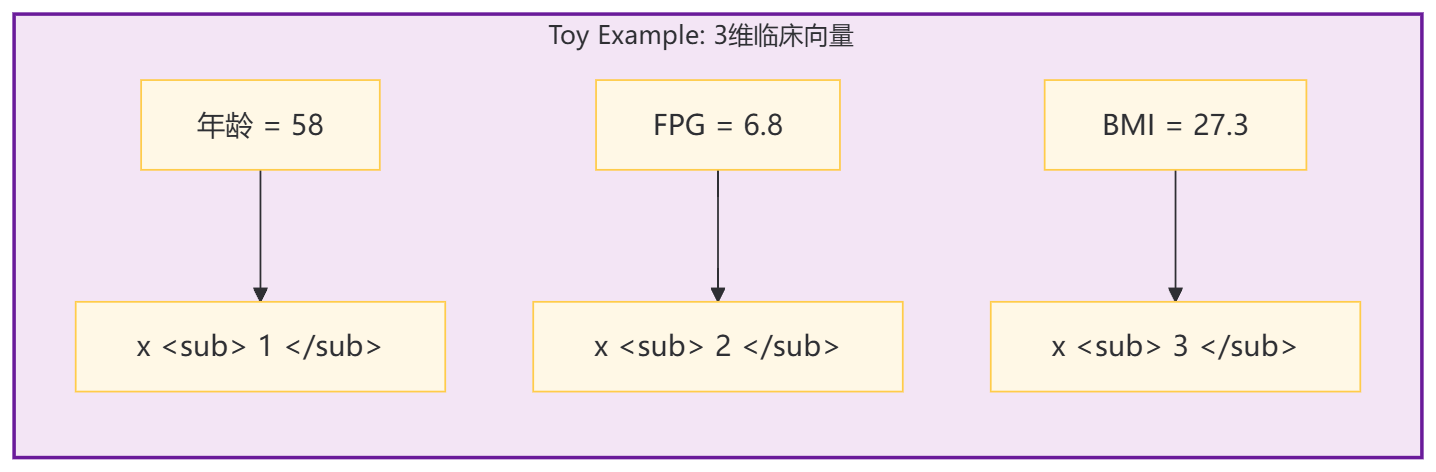
如果我们把这三个数字排成一列,就得到了一个 3 维向量 x\
但真实世界远比这复杂。根据 The Lancet eClinicalMedicine 一项覆盖韩国、日本、英国三国队列的研究,真正用于五年期 T2DM 预测的变量多达二十余项,涵盖人口学、人体测量、血糖特征、血脂谱、肝酶等维度。 如果把 toy example 扩展为真实规模,我们的小方框会突然长高、变宽,变成一张密密麻麻的表格:

关键洞察 :在模型眼里,每一位患者不再是一张体检单,而是高维空间中的一个点 。早期预警的本质,就是在这个高维空间里划出一道边界------边界一侧是"未来五年安全",另一侧是"未来五年高风险"。单一模型(比如单一的全连接层)可以试着划这道线,但高维临床数据往往呈现出非线性、异质、特征间交互复杂的分布。这就好比用一把直尺去量波浪线的长度,难免捉襟见肘。
所以,我们请来了多位"专家"一起划边界。现在我们已经了解了数据是如何从 3 维玩具变成 26+ 维真实的,接下来看看为什么需要一群模型,而不是一个模型。
第三站:基学习器集群------为什么需要一群"专科医生"?
我们先锚定一个已知概念:在序列任务里,我们不会只用一个 RNN 细胞处理长文本,而是堆叠多层、甚至引入双向结构,因为不同层捕捉不同时间尺度的模式。同样的道理,在静态的临床预测任务里,不同的基学习器就是不同专科的医生,各自擅长从数据的不同"视角"提取规律。
让我们用 toy example 来建立直觉。假设有三位医生面对同一份病历:
-
内科医生(Logistic Regression):习惯画一条直线分界。他只看"年龄 + FPG"的线性组合,简单、可解释,但遇到复杂的非线性交互就力不从心。
-
影像科医生(Random Forest) :喜欢做大量局部切片。他构建几百棵决策树,每棵树只看随机子集的特征,像做多次局部活检,擅长捕捉"如果 FPG > 6.5 且 BMI > 25 且 GGT 升高"这样的非线性规则。
-
生化科医生(AdaBoost):特别在意"难分病例"。他 sequentially 地训练一系列弱分类器,每一轮都更关注上一轮误诊的病人,像一位不断复盘疑难病例的专家。
如果把这三位医生(以及更多)并排摆放,就构成了基学习器层:
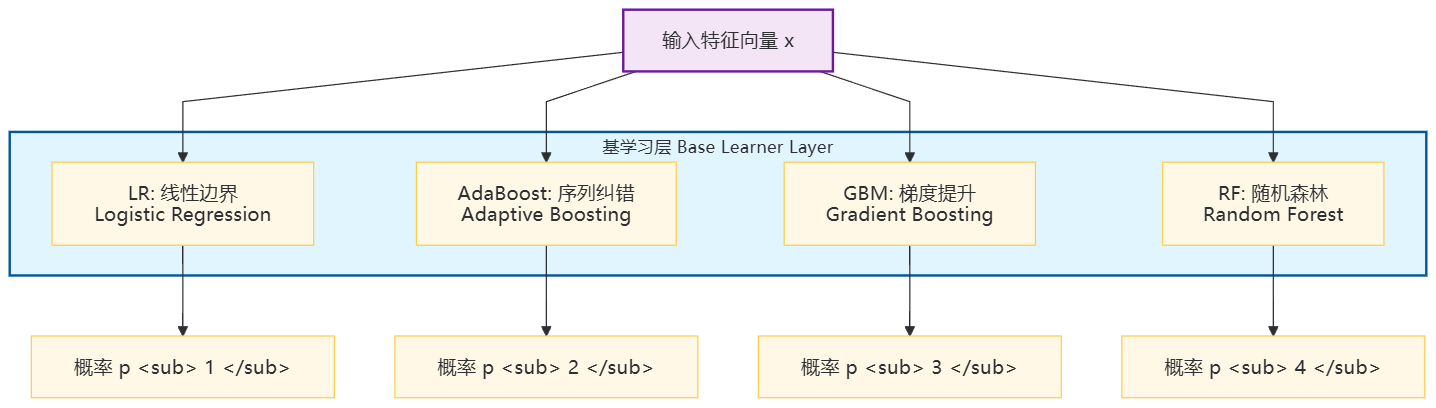
注意,这里的输出不是"是/否"的硬标签,而是概率值 p<sub>...p<sub>。为什么用概率?因为我们要给下一层------"主任医师"------留下足够的信息量,让他知道每位"专科医生"对自己判断的置信度。
在继续之前,你可能会问:如果四位专家意见一致,问题就简单了;但如果他们分歧严重呢?比如 LR 说"风险 30%",而 AdaBoost 说"风险 85%",我们该听谁的?这就引出了元学习器的核心问题。
第四站:元学习器融合------从"举手表决"到"加权会诊"
别急,我们先从最简单的融合方式讲起,像搭积木一样往上垒。
第一步:硬投票(Hard Voting)
想象四位专家同时举牌子,牌子背面写着"高风险"或"低风险"。我们数牌子,多数决。这叫做硬投票。它的优点是极度简单,缺点是浪费了概率信息------一位专家 51% 置信度的高风险,和另一位 99% 置信度的高风险,在硬投票里权重相同。
第二步:软投票(Soft Voting)
现在我们让专家举的牌子变成连续值:LR 说 0.30,AdaBoost 说 0.85,RF 说 0.60,GBM 说 0.55。我们直接取平均:(0.30 + 0.85 + 0.60 + 0.55) / 4 = 0.575。如果阈值设为 0.5,最终输出"高风险"。
软投票已经比硬投票聪明多了,但它有个隐含的假设:所有专家的平均水平一样可靠。现实中,AdaBoost 可能对血糖波动更敏感,而 RF 对肝酶组合更敏锐。我们能不能让数据自己告诉我们------在什么样的特征组合下,该更信任谁?
第三步:Stacking(堆叠泛化)
这就是 Stacking 的顿悟时刻。我们不再手工设定权重,而是把基学习器的概率输出当作新的特征(称为 meta-features),喂给另一个模型------通常是 Logistic Regression------让它学习如何最优地组合这些专家意见。
如果画成图,它就像一位主任医师,面前摆着四位专科医生写的初步诊断报告(p<sub>...p<sub>),他根据历史经验(训练数据)学会了:当 LR 和 AdaBoost 分歧大时,更信任 AdaBoost;当所有模型都给出中等概率时,倾向于保守估计。
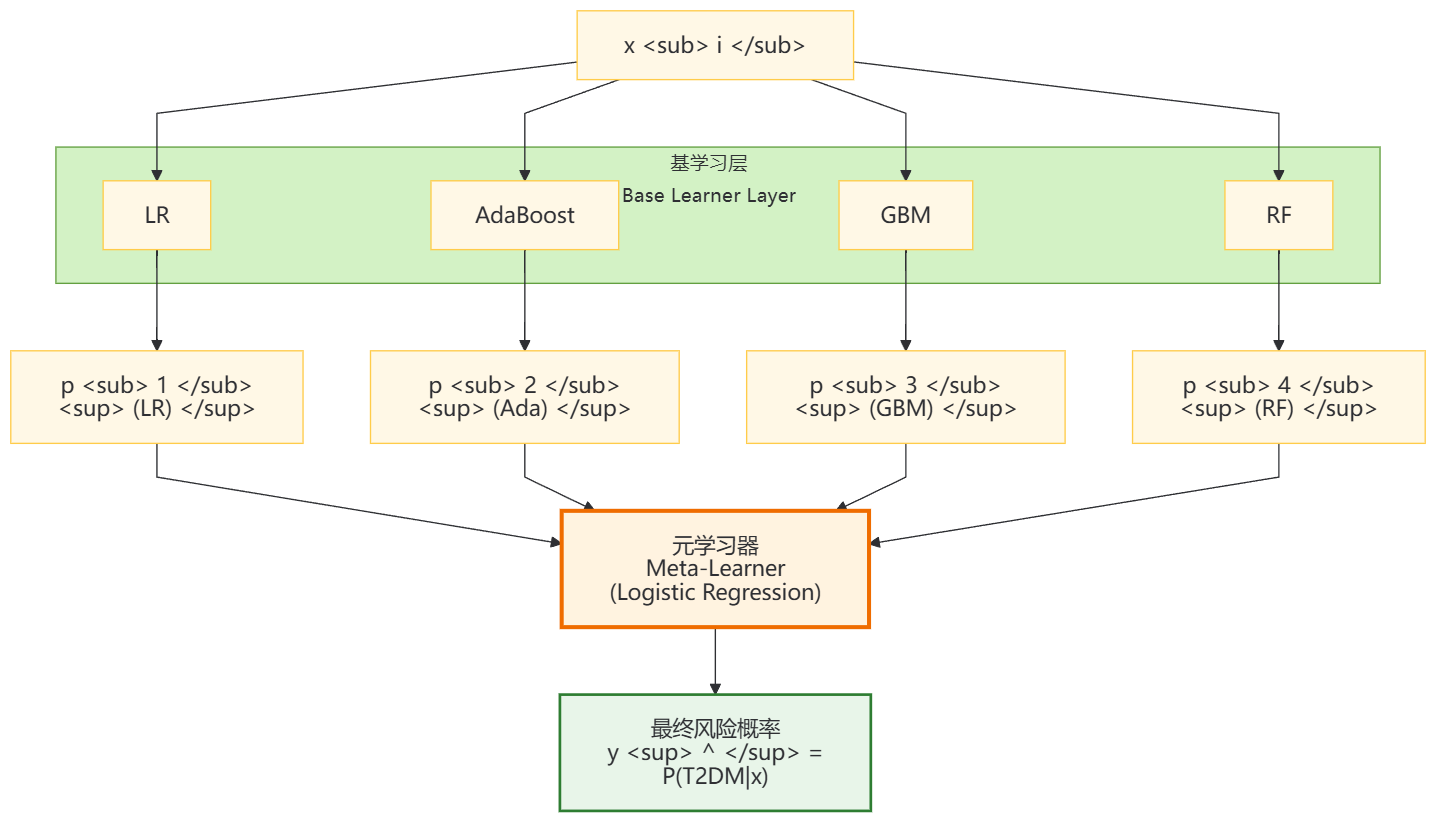
现在我们已经了解了"为什么要集成"以及"如何融合",接下来看看这整套机制在数学上是怎么跑起来的。别担心,我们先从向量级计算开始,再推广到矩阵实现。
第五站:算法心脏------结构化伪代码与计算流
让我们把刚才的会诊流程翻译成严谨的算法步骤。下面的伪代码采用类 Pascal/Algol 结构化风格,强调数学运算而非具体编程实现。
算法 1:Stacking Ensemble 训练阶段
plain
复制
Algorithm: TrainStackingEnsemble
Input: Feature matrix X ∈ R^{n×p}, labels y ∈ {0,1}<sup>n</sup>
Base learner pool B = {b<sub>1</sub>, b<sub>2</sub>, ..., b<sub>m</sub>}
Number of folds K = 5
Output: Trained ensemble E = (B<sup>*</sup>, M)
// 第一步:生成元特征(Out-of-Fold 预测)
Initialize Z ∈ R<sup>n×m</sup> // 元特征矩阵,每列对应一个基学习器
for k = 1 to K do
D<sub>train</sub><sup>(k)</sup> ← indices of training fold k
D<sub>val</sub><sup>(k)</sup> ← indices of validation fold k
for j = 1 to m do
fit b<sub>j</sub> on X[D<sub>train</sub><sup>(k)</sup>], y[D<sub>train</sub><sup>(k)</sup>]
p<sub>j</sub><sup>(k)</sup> ← predict_proba(b<sub>j</sub>, X[D<sub>val</sub><sup>(k)</sup>])
Z[D<sub>val</sub><sup>(k)</sup>, j] ← p<sub>j</sub><sup>(k)</sup>
end
end
// 第二步:训练元学习器
M ← LogisticRegression(solver = lbfgs, max_iter = 1000)
fit M on (Z, y) // 学习如何将基学习器概率映射到最终风险
// 第三步:在完整数据上重训练基学习器(用于最终部署)
for j = 1 to m do
fit b<sub>j</sub> on (X, y)
b<sub>j</sub><sup>*</sup> ← trained b<sub>j</sub>
end
return E = (B<sup>*</sup>, M)关键细节 :为什么第二步要用 Out-of-Fold(OOF)预测来构建 Z,而不是直接在训练集上预测?因为如果我们用同一份数据既训练基学习器又生成它们的预测,元学习器会学到一种虚假的自信 ------就像让医生提前看到标准答案再写诊断,主任医师会被这种过拟合的乐观欺骗。K-Fold OOF 策略确保每位基学习器的预测都来自它没见过的验证子集,从而保证元学习器看到的是真实的、带噪声的专家意见。
算法 2:单实例预测阶段(部署时)
plain
复制
Algorithm: PredictRisk
Input: Trained ensemble E = (B<sup>*</sup>, M), new instance x<sub>new</sub> ∈ R<sup>p</sup>
Output: Risk probability y<sup>^</sup> ∈ [0,1]
// 并行调用所有基学习器
for j = 1 to m do
z<sub>j</sub> ← predict_proba(b<sub>j</sub><sup>*</sup>, x<sub>new</sub>)
end
// 组装元特征向量
z ← [z<sub>1</sub>, z<sub>2</sub>, ..., z<sub>m</sub>]<<sup>T</sup>
// 元学习器最终决策
y<sup>^</sup> ← predict_proba(M, z)
return y<sup>^</sup>注意,在真实部署中,x<sub> 可能来自医院的实时检验科接口。基学习器的推断可以并行执行(四位专家同时看片),元学习器的加权只需毫秒级矩阵乘法,整个流程能在体检报告生成后的秒级完成。
第六站:打开黑箱------SHAP 解释引擎如何工作?
模型输出了 y<sup> = 0.78,意思是"未来五年 T2DM 风险 78%"。但医生盯着这个数字会问:是年龄贡献了大头,还是空腹血糖?是 BMI 在拖后腿,还是肝酶在报警? 如果给不出解释,再准的模型也难进临床。
这里我们引入 SHAP(Shapley Additive Explanations)。它的数学根源来自合作博弈论:把每个特征想象成一位"贡献者",模型的预测收益(相对于基准期望)要按贡献公平分配。
直觉:从 Toy Example 开始
假设我们只有三个特征:年龄、FPG、BMI。我们要算"年龄"这一特征的 SHAP 值 φ<sub>。思路是:我们让年龄这位"玩家"轮流加入不同的"联盟"(特征子集),看看每次加入后,模型的预测发生了多少变化。
比如:
-
联盟只有 FPG 时,模型预测风险 0.40;
-
联盟加入年龄后,模型预测风险 0.55;
-
那么年龄在这个联盟下的边际贡献就是 +0.15。
我们遍历所有可能的联盟(∅, {FPG}, {BMI}, {FPG,BMI}),把年龄的边际贡献按联盟规模加权平均,就得到 φ<sub>。

算法 3:特征归因(简化版)
plain
复制
Algorithm: ComputeSHAP
Input: Trained model f, instance x, feature set F = {1,2,...,p}
Output: Attribution vector φ ∈ R<sup>p</sup>
for j = 1 to p do
φ<sub>j</sub> ← 0
Let P(F \ {j}) be power set of features excluding j
for each S in P(F \ {j}) do
|S| ← cardinality of S
weight ← |S|! × (p - |S| - 1)! / p!
// 在特征子集 S 上的条件期望预测
f<sub>S</sub> ← E[ f(x) | x<sub>S</sub> ] // 不包含 j
f<sub>S∪{j}</sub> ← E[ f(x) | x<sub>S∪{j}</sub> ] // 包含 j
φ<sub>j</sub> ← φ<sub>j</sub> + weight × (f<sub>S∪{j}</sub> - f<sub>S</sub>)
end
end
return φ在实际系统中,我们不会暴力枚举所有子集(2<sup> 种组合),而是使用 TreeSHAP 或 KernelSHAP 等近似算法。 最终呈现给医生的,是一张瀑布图(waterfall plot):基准期望(比如训练集平均风险 0.35)在左侧,每个特征像一块积木,正向贡献(红色,推高风险)向右堆叠,负向贡献(蓝色,拉低风险)向左堆叠,最后汇总到当前患者的总风险 0.78。
根据 The Lancet eClinicalMedicine 的研究,在跨国队列中,年龄和空腹血糖通常占据 SHAP 值的前两位,其次是血红蛋白、GGT 和 BMI------这与临床共识完美吻合,也反向验证了模型的生物学合理性。
第七站:闭环------训练、验证与真实世界部署
现在我们已经了解了 X(系统架构、数据流、基学习器、元学习器、SHAP 解释),接下来看看 Y(这在训练和实际使用中意味着什么)。
训练意味着什么?
-
分层 K-Fold 交叉验证 :T2DM 预测是严重的类别不平衡问题(健康人远多于发病人)。如果随机切分,某一折可能全是健康人,模型会学会"永远猜健康"就能高准确率。因此我们必须分层(stratified),确保每一折都保持原始数据中的患病比例。
-
外部验证(External Validation):在韩国训练好的模型,必须在日本和英国的独立队列上测试。如果 AUROC 从 0.79 暴跌到 0.55,说明模型只是记住了韩国人群的特异规律,而非学到了普适的生物学机制。跨种族、跨医疗体系的泛化能力,是临床落地的前提。
-
超参数网格搜索:每个基学习器都有自己的旋钮(如 AdaBoost 的迭代次数、RF 的树深度)。我们用网格搜索(GridSearch)在验证集上寻找最优组合,防止过拟合。
实际使用意味着什么?
想象这样的临床工作流:

整个过程从数据入库到医生看到解释,耗时秒级。医生不需要懂集成学习,但他能看到:模型把这位患者判为高风险,最大的"推手"是年龄和空腹血糖,而较高的 HDL 胆固醇在一定程度上抵消了风险。这让干预有了明确靶点------也许这位患者最需要的是生活方式干预降低 FPG,而非立即用药。
延伸阅读与文献地图
如果你希望深入某个模块,以下是一份按层级整理的阅读路线:
-
整体架构与跨国验证:The Lancet eClinicalMedicine 2025 年的模型开发与验证研究,详细比较了 Voting、Stacking 在韩日英三国队列中的表现,并给出了 SHAP 全局解释。
-
堆叠集成与神经网络结合:PMC 2023 年的工作展示了如何用三层神经网络作为基学习器进行堆叠,在糖尿病分类中达到 95.5% 的准确率。
-
血糖时序预测的集成深度框架:Glu-Ensemble 工作将 RNN、LSTM、BiLSTM、GRU 并行堆叠,用线性回归和软投票做元学习器,对于需要连续血糖监测(CGM)的场景极具参考价值。
-
可解释性两阶段方法:Frontiers in Digital Health 2026 年的研究提出了先筛选高风险人群、再解释个体归因的两阶段框架,适合对 SHAP 和 LIME 的临床部署感兴趣的朋友。
-
特征选择与类别不平衡处理:MDPI 2024 年的综述系统讨论了 SMOTE、PCA、相关性过滤在糖尿病预测预处理中的角色。
我们今天的旅程就到这里。 从一张体检单的三个数字,到二十多维向量在高维空间中的边界划分;从三位专科医生的 toy example,到跨国队列上经过外部验证的 Stacking 集成;从黑箱概率输出,到 SHAP 归因的透明解释------这座"数字会诊室"的核心逻辑,其实就藏在分层协作 与可解释融合这两个关键词里。
下次当你看到体检报告上那几个偏高的箭头时,不妨想象:它们正沿着一条流水线,穿过并行运转的专家诊室,最终在一位元学习器"主任医师"的办公桌上,汇聚成一个有温度、有解释的风险分数。而算法能做的,就是在疾病真正敲门之前,替我们多看一眼。