

🔥个人主页:北极的代码(欢迎来访)
🎬作者简介:java后端学习者
✨命运的结局尽可永在,不屈的挑战却不可须臾或缺!
前言:
大家好,我是代码不加冰,今天是我们的每日刷题时间,前几周我们一直在学习二叉树相关的算法题,感觉有点枯燥,想学一点新的知识,总感觉长时间写一个种类的算法题很无聊,所以我想加快下速度,或者同时进行后面的章节,回溯算法,或者贪心算法。
摘要:
本文介绍了如何根据二叉树的中序和后序遍历序列重构二叉树。通过分析示例,文章指出仅靠后序遍历无法确定节点间的父子关系,必须结合中序遍历来精确定位。核心解法是:1)取后序最后一个元素作为根节点;2)在中序中找到根节点位置并分割左右子树;3)根据中序分割结果对应分割后序数组;4)递归处理左右子树。文章详细讲解了边界切割方法(推荐左闭右开),并提供了Java实现代码,强调要注意递归终止条件和边界值的正确处理。该方法利用哈希表优化查找效率,时间复杂度为O(n)。
题目背景:
给定两个整数数组
inorder和postorder,其中inorder是二叉树的中序遍历,postorder是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。示例 1:
输入:inorder = [9,3,15,20,7], postorder = [9,15,7,20,3] 输出:[3,9,20,null,null,15,7]示例 2:
输入:inorder = [-1], postorder = [-1] 输出:[-1]提示:
1 <= inorder.length <= 3000postorder.length == inorder.length-3000 <= inorder[i], postorder[i] <= 3000inorder和postorder都由 不同 的值组成postorder中每一个值都在inorder中inorder保证是树的中序遍历postorder保证是树的后序遍历
题目解析:
拿到这个题目,我们要先搞清楚题目的意思,这个题目说是从中序与后序遍历序列构造二叉树,意思就是没给我们实际的二叉树,让我们自己跟据这个二叉树的中序遍历结果和后序遍历结果来反推出二叉树,那为什么要两种遍历方式呢:
两种不同的树,后序遍历结果却一样
情况一:
B / \ A C后序遍历(左→右→根):A → C → B →
[A, C, B]情况二:
B / C / A这棵树只有左孩子(一路向左)。
后序遍历(左→右→根):
访问 A
访问 C
访问 B
结果也是
[A, C, B]!发现
情况一:
[A, C, B]中,A 是左子树(B的左孩子),C 是右子树(B的右孩子)情况二:
[A, C, B]中,A 是左子树的左子树,C 是 B 的左孩子只给后序
[A, C, B],我们无法区分:
到底 C 是 B 的左孩子还是右孩子?
到底 A 和 C 是兄弟关系还是父子关系?
这时候必须用中序遍历来澄清:
如果中序是
[A, B, C]→ B 在中间,A 在左,C 在右 → 情况一(左右都有)如果中序是
[A, C, B]→ B 在最后,A 和 C 都在 B 左边 → 情况二(一路向左)光靠后序,只能知道"A 在整体的左边",但无法知道"A 是紧挨着根的左孩子,还是隔了好几层的左孙子"。中序遍历提供了"位置关系"的精确信息。
那么整体的题目要求我们就了解了,那具体该怎么实现呢
后序数组的最后一个元素为切割点,先切中序数组,根据中序数组,反过来再切后序数组。一层一层切下去,每次后序数组最后一个元素就是节点元素。
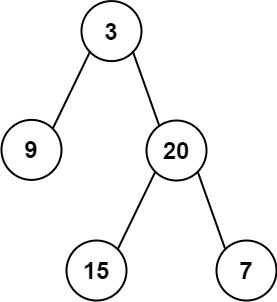
输入:
中序
[9, 3, 15, 20, 7]后序
[9, 15, 7, 20, 3]我们画个图走一遍:
看后序最后一个 :是
3。 → 根节点是 3。去中序找 3:
3 在中间。
左边
[9]是左子树。右边
[15, 20, 7]是右子树。处理左子树 (中序
[9],后序[9]):
- 只有一个 9。所以 3 的左孩子是 9。
处理右子树 (中序
[15, 20, 7],后序[15, 7, 20]):
看右子树的后序(15, 7, 20),最后一个
20是右子树的根。去中序(15, 20, 7)找 20:
左边
[15]是左孩子。右边
[7]是右孩子。总结结构:
根:3
3 的左:9
3 的右:20
20 的左:15
20 的右:7
所以还原出来的树长这样:
3 / \ 9 20 / \ 15 7
第一步:如果数组大小为零的话,说明是空节点了。
第二步:如果不为空,那么取后序数组最后一个元素作为节点元素。
第三步:找到后序数组最后一个元素在中序数组的位置,作为切割点
第四步:切割中序数组,切成中序左数组和中序右数组 (顺序别搞反了,一定是先切中序数组)
第五步:切割后序数组,切成后序左数组和后序右数组
第六步:递归处理左区间和右区间
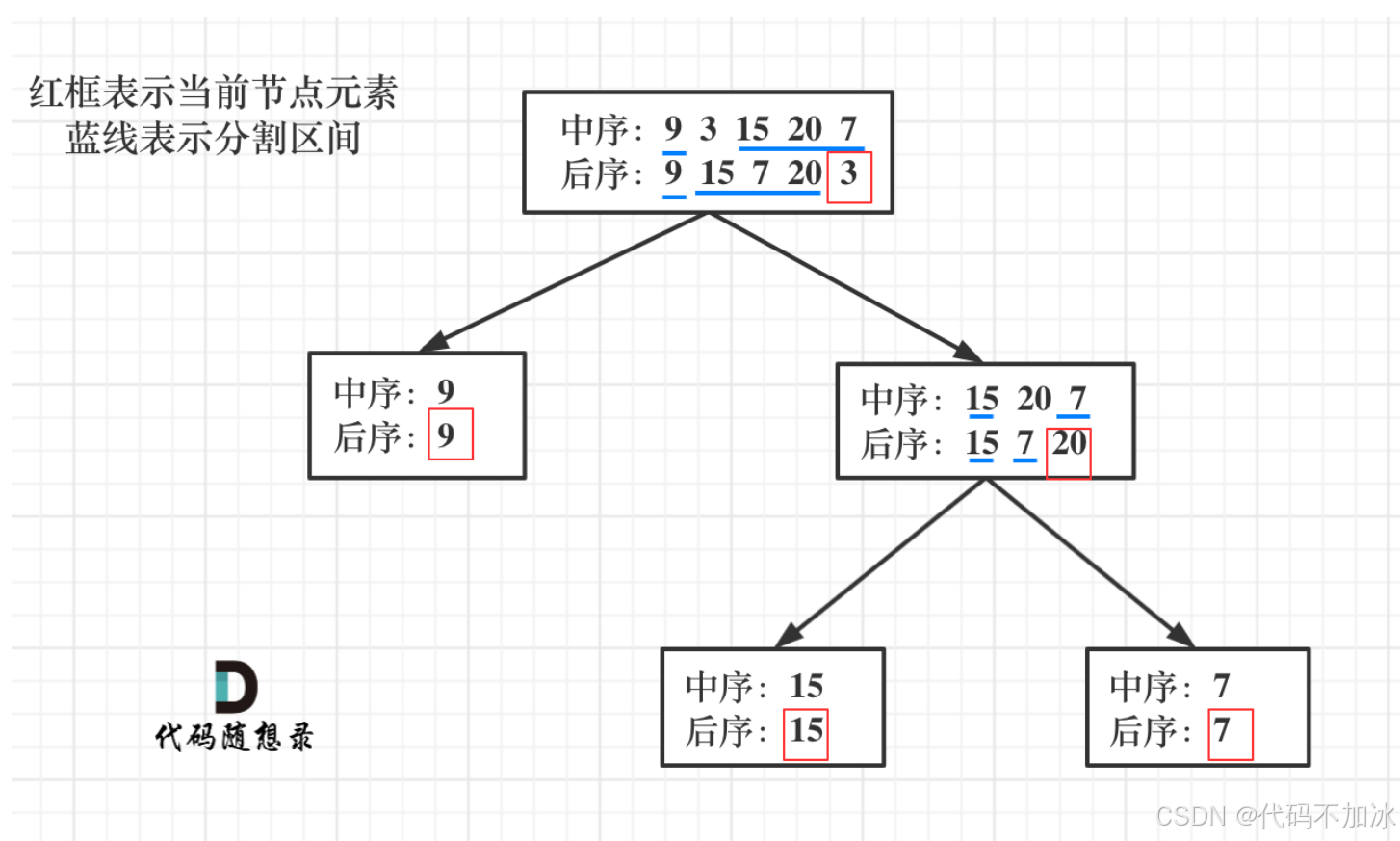
难点大家应该发现了,就是如何切割,以及边界值找不好很容易乱套。
边界切割
此时应该注意确定切割的标准,是左闭右开,还有左开右闭,还是左闭右闭,这个就是不变量,要在递归中保持这个不变量。
在切割的过程中会产生四个区间,把握不好不变量的话,一会左闭右开,一会左闭右闭,必然乱套
在二分法中强调过循环不变量的重要性,在二分查找以及螺旋矩阵的求解中,坚持循环不变量非常重要,本题也是。
首先要切割中序数组,为什么先切割中序数组呢
切割点在后序数组的最后一个元素,就是用这个元素来切割中序数组的,所以必要先切割中序数组。
中序数组相对比较好切,找到切割点(后序数组的最后一个元素)在中序数组的位置,然后切割
接下来就要切割后序数组了
首先后序数组的最后一个元素指定不能要了,这是切割点 也是 当前二叉树中间节点的元素,已经用了。
后序数组的切割点怎么找
后序数组没有明确的切割元素来进行左右切割,不像中序数组有明确的切割点,切割点左右分开就可以了。
此时,中序数组切成了左中序数组和右中序数组,后序数组切割成左后序数组和右后序数组。
接下来可以递归了
图解切割(四个边界)
我们把要递归传给左右子树的范围画出来。
第一层:根节点
3完整数组:
中序:
[ (9) , 3 , (15,20,7) ]后序:
[ (9) , (15,7,20) , 3 ]切割结果:
子树 中序范围 (inorder) 后序范围 (postorder) 左子树 [0 , 0](只有9)[0 , 0](只有9)右子树 [2 , 4](15,20,7)[1 , 3](15,7,20)右子树的内部(验证边界)
此时递归进入右子树,参数更新为:
inStart = 2,inEnd = 4
postStart = 1,postEnd = 3右子树数组看起来像这样:
中序子数组:
[15, 20, 7](新索引 0~2,对应原索引 2~4)后序子数组:
[15, 7, 20](新索引 0~2,对应原索引 1~3)在这一层:
根节点:后序最后一个
20(原索引 3)在中序找
20:原索引是3。新左子树长度 =
rootIndex - inStart=3 - 2 = 1(只有15)4. 四个边界的计算公式(重点)
假设当前递归函数参数如下:
中序:
inStart到inEnd后序:
postStart到postEnd计算得:
rootIndex(中序里根的位置),leftSize(左子树节点数)此时有一个很重的点,就是中序数组大小一定是和后序数组的大小相同的(这是必然)。
中序数组我们都切成了左中序数组和右中序数组了,那么后序数组就可以按照左中序数组的大小来切割,切成左后序数组和右后序数组。
后序左右边界:
左子树 :
[postStart , postStart + leftSize - 1]右子树 :
[postStart + leftSize , postEnd - 1](这里-1是因为要把当前的根postEnd去掉)中序左右边界:
左子树 :
[inStart , rootIndex - 1]右子树 :
[rootIndex + 1 , inEnd]6. 易错点提示
postEnd - 1:千万不要忘了-1,因为postEnd是当前树的根,传给子树必须去掉。
leftSize用中序算 :千万不要试图用后序的指针减来减去算长度,必须用中序 (rootIndex - inStart)。空区间判断 :递归开头一定要判断
if (inStart > inEnd) return null;总结一句:
先拿
rootIndex减inStart算出 左子树有几个节点 ,然后把leftSize加到postStart上,就能精准切出后序的左子树区间。这就是解决边界问题的唯一标准方法。
代码实现
这里用左闭右闭演示一下代码:
java
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public TreeNode buildTree(int[] inorder, int[] postorder) {
// 存储中序遍历中每个值的索引,方便快速查找根节点位置
Map<Integer, Integer> indexMap = new HashMap<>();
for (int i = 0; i < inorder.length; i++) {
indexMap.put(inorder[i], i);
}
return build(inorder, 0, inorder.length - 1,
postorder, 0, postorder.length - 1,
indexMap);
}
private TreeNode build(int[] inorder, int inStart, int inEnd,
int[] postorder, int postStart, int postEnd,
Map<Integer, Integer> indexMap) {
// 递归终止条件:区间为空
if (inStart > inEnd || postStart > postEnd) {
return null;
}
// 后序遍历的最后一个节点就是根节点
int rootVal = postorder[postEnd];
TreeNode root = new TreeNode(rootVal);
// 在中序遍历中找到根节点的位置
int rootIndex = indexMap.get(rootVal);
// 左子树的节点个数
int leftSize = rootIndex - inStart;
// 递归构建左子树
// 左子树的中序遍历区间:[inStart, rootIndex - 1]
// 左子树的后序遍历区间:[postStart, postStart + leftSize - 1]
root.left = build(inorder, inStart, rootIndex - 1,
postorder, postStart, postStart + leftSize - 1,
indexMap);
// 递归构建右子树
// 右子树的中序遍历区间:[rootIndex + 1, inEnd]
// 右子树的后序遍历区间:[postStart + leftSize, postEnd - 1]
root.right = build(inorder, rootIndex + 1, inEnd,
postorder, postStart + leftSize, postEnd - 1,
indexMap);
return root;
}
}| 参数 | 值 | 含义 |
|---|---|---|
inorder |
中序遍历数组 | 不变,全程使用 |
inStart |
0 |
中序数组的起始索引(第一个元素) |
inEnd |
inorder.length - 1 |
中序数组的结束索引(最后一个元素) |
postorder |
后序遍历数组 | 不变,全程使用 |
postStart |
0 |
后序数组的起始索引(第一个元素) |
postEnd |
postorder.length - 1 |
后序数组的结束索引(最后一个元素) |
indexMap |
值→索引的映射 | 方便快速查找根在中序的位置 |
为什么要传这些参数
因为递归函数需要知道当前处理的是哪一段区间:
-
第一次调用:处理整棵树 → 区间是
[0, 长度-1] -
递归左子树:处理左子树部分 → 区间会缩小,比如
[0, 2] -
递归右子树:处理右子树部分 → 区间会缩小,比如
[4, 6]
这四个索引(inStart, inEnd, postStart, postEnd)定义了当前递归层要处理的子树范围。
举例说明
用之前的例子:
inorder = [9, 3, 15, 20, 7],长度 = 5
postorder = [9, 15, 7, 20, 3],长度 = 5第一次调用:
text
inStart = 0 inEnd = 4 (因为 5-1=4) postStart = 0 postEnd = 4 (因为 5-1=4)这表示:整个中序数组的
[0, 4]和整个后序数组的[0, 4]构成了当前要处理的树。
左闭右开版本的对比
如果你用左闭右开,第一次调用就是:
java
return build(inorder, 0, inorder.length, // 注意:是 length,不是 length-1 postorder, 0, postorder.length, indexMap);区别:
左闭右闭 :终点是
length - 1左闭右开 :终点是
length(不包含)
左闭右开的核心公式(简洁版)
| 区间类型 | 左子树后序 | 右子树后序 |
|---|---|---|
| 左闭右闭 | [postStart, postStart + leftSize - 1] |
[postStart + leftSize, postEnd - 1] |
| 左闭右开 | [postStart, postStart + leftSize) |
[postStart + leftSize, postEnd - 1) |
注意右子树的后序终点是 postEnd - 1 而不是 postEnd ,因为 postEnd - 1 是当前根节点,右子树不能包含它。
为什么左闭右开更好
-
长度直接算 :区间
[l, r)的长度就是r - l,不需要+1 -
空区间判断简单 :
l >= r就是空,不用纠结>还是>= -
leftSize直接用 :postStart + leftSize天然就是右子树起点,不用+1
一个小坑提醒
左闭右开版本中,右子树的后序终点是 postEnd - 1 ,不是 postEnd。
因为 postEnd - 1 才是当前树的根节点,传给右子树时必须排除它。这是左闭右开唯一需要小心的地方。
总结: 如果觉得边界总搞错,个人建议改成左闭右开,逻辑更顺,代码更短。
结语:如果对你有帮助,请**点赞,关注,收藏,**你的支持就是我最大的鼓励!