一、前言:从一道算法题认识并查集
今天我们来看一道经典的图论入门题:1971. 寻找图中是否存在路径。
题目要求:给定一个无向双向图,判断从起点 source 到终点 destination 是否存在有效路径。数据范围极大,顶点和边数最高可达 2 × 10 5 2\times10^5 2×105。
对于这类判断两点是否连通、集合分组的问题,有两种主流解法:
-
搜索算法:DFS/ BFS,构建邻接表遍历图;
-
并查集:极简代码,专门处理连通性问题,效率更高。
本文结合这道题,从零讲解并查集,附带通俗易懂原理+Python代码,新手也能轻松看懂。
二、什么是并查集?
2.1 核心定义
并查集全称 Disjoint Set Union(DSU,不相交集合) ,是一种专门用于管理元素分组的数据结构。
它专注解决两个核心问题:
-
合并(Union):将两个元素划分到同一个集合;
-
查找(Find):查询某个元素的根节点,判断两个元素是否属于同一集合。
2.2 通俗比喻
把每个集合看作一个家族,每个元素是家族成员:
-
初始化:每个人自成一家,自己是自己的族长;
-
合并:两个家族联姻,合并为一个家族,共用同一个族长;
-
查找:找到某人的族长,判断两个人是否同族(连通)。
2.3 适用场景
并查集不擅长复杂图遍历,只专注连通性判断,常见场景:
-
无向图判断两点是否连通;
-
统计图中连通分量的个数;
-
社交网络好友圈层划分;
-
最小生成树(Kruskal 算法)。
三、并查集三大基础操作
并查集底层依托数组实现,用 fa[] 数组存储每个元素的父节点,fa[x] 表示元素 x 的父节点。
3.1 初始化 Init
初始状态下,每个元素独立成集合,父节点指向自身。
python
fa = list(range(n)) # n个顶点,0~n-1各自为父3.2 查找 Find(核心:路径压缩)
查找元素的根节点 ,并做路径压缩优化 :递归过程中,把沿途所有节点直接挂载到根节点下,减少后续查询耗时,让查询复杂度近乎 O ( 1 ) O(1) O(1)。
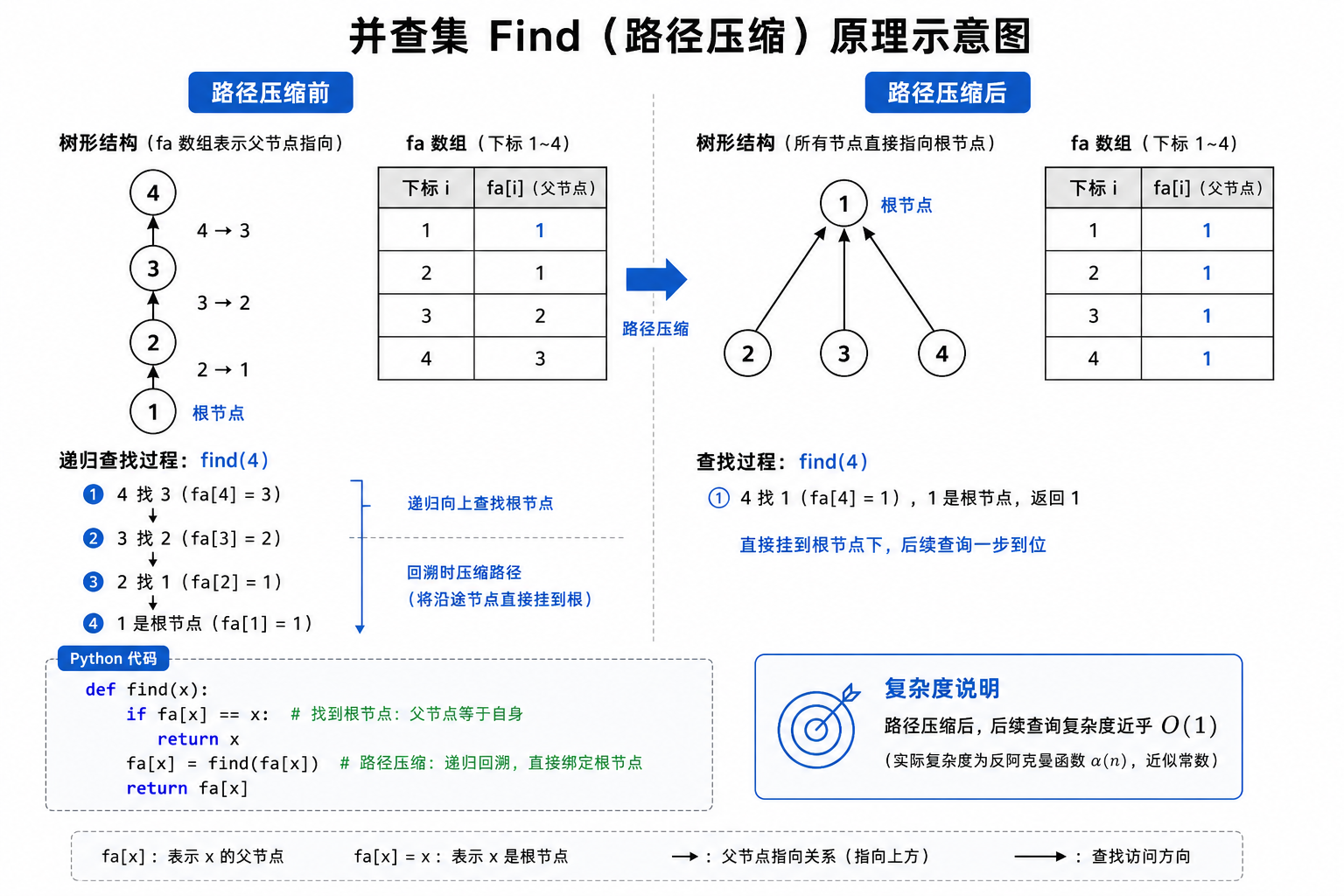
python
def find(x):
if fa[x] == x: # 找到根节点:父节点等于自身
return x
fa[x] = find(fa[x]) # 路径压缩:递归回溯,直接绑定根节点
return fa[x]3.3 合并 Union
合并两个元素所在的集合:先分别找到两个元素的根节点,若根节点不同,则将一个根节点挂载到另一个根节点下,完成合并。
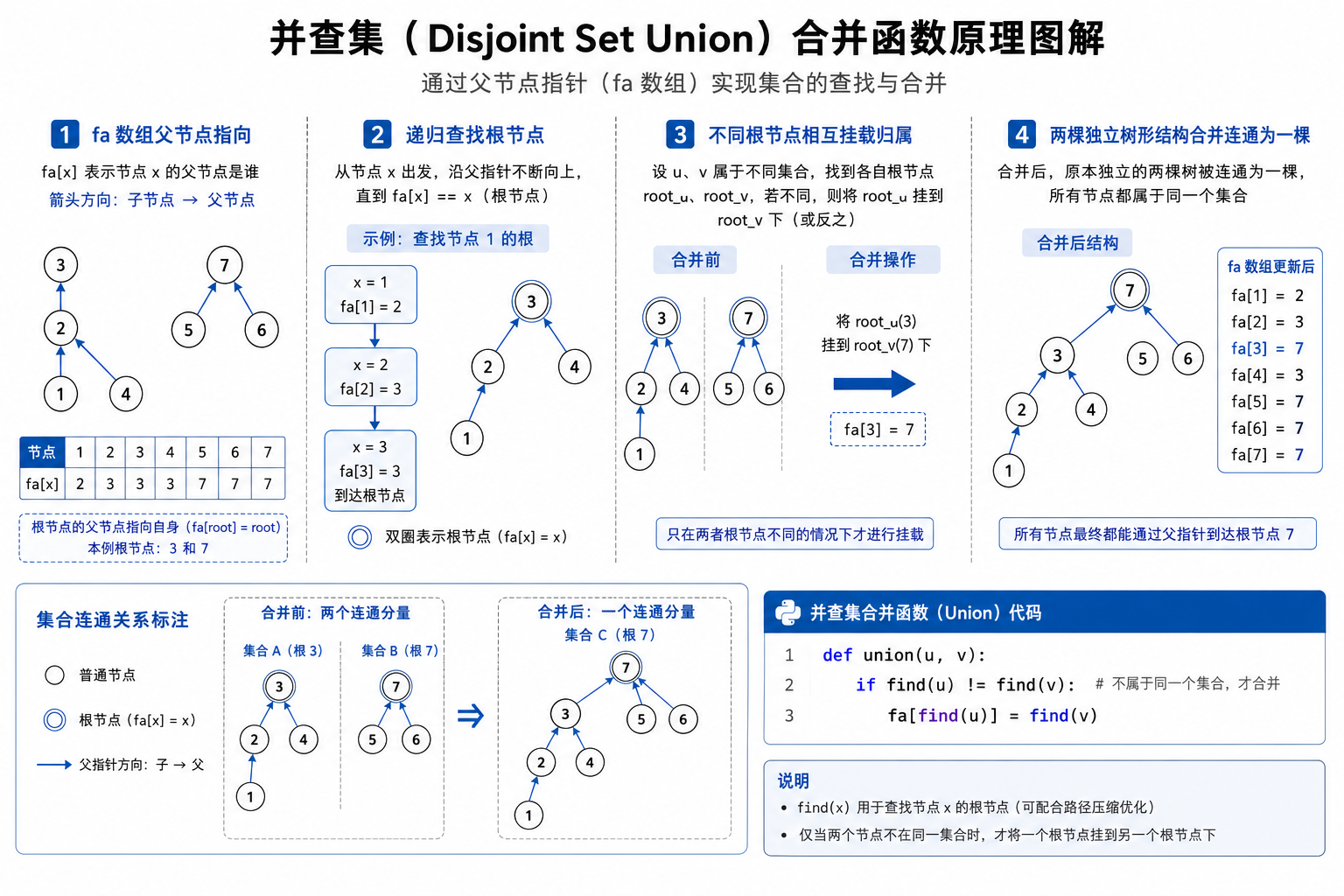
python
def union(u, v):
if find(u) != find(v): # 不属于同一个集合,才合并
fa[find(u)] = find(v)四、LeetCode 1971 并查集题解拆解
4.1 完整AC代码
python
class Solution:
def validPath(self, n: int, edges: List[List[int]], source: int, destination: int) -> bool:
fa = list(range(n))
# 查找函数+路径压缩
def find(x):
if fa[x] == x:
return x
fa[x] = find(fa[x])
return fa[x]
# 合并函数
def union(u, v):
if find(u) != find(v):
fa[find(u)] = find(v)
# 遍历所有边,合并连通的顶点
for u, v in edges:
union(u, v)
# 起点和终点根节点相同 = 连通
return True if find(source) == find(destination) else False4.2 代码逐行解析
-
数组初始化 :
fa = list(range(n)),所有顶点初始独立; -
find函数:递归实现路径压缩,扁平化结构,提升查询速度;
-
union函数:判断两个顶点是否同族,不同族则合并;
-
遍历边:无向图双向边,遍历所有边完成顶点合并;
-
结果判断:对比起点和终点的根节点,一致则连通,返回True。
五、DFS解法对比 & 优劣分析
5.1 DFS原题代码
python
class Solution:
def validPath(self, n: int, edges: List[List[int]], source: int, destination: int) -> bool:
# 构建邻接表
e = [[] for _ in range(n)]
for u, v in edges:
e[u].append(v)
e[v].append(u)
s = set() # 记录已访问节点
def dfs(source, destination):
if source == destination:
return True
s.add(source)
for v in e[source]:
if v not in s:
if dfs(v, destination):
return True
return False
return dfs(source, destination)5.2 两种解法对比
| 对比维度 | 并查集 | DFS深度优先搜索 |
|---|---|---|
| 代码复杂度 | 极简,无需构建邻接表 | 需手动建邻接表、去重访问 |
| 时间复杂度 | 近乎 O(1)(路径压缩优化) | O(n+m) 遍历节点和边 |
| 大数据适配性 | 优秀,适配 2e5 级数据 | Python递归深度有限,大数据栈溢出 |
| 适用场景 | 仅判断连通性 | 需要遍历路径、搜索节点 |
重点坑点:Python默认递归深度约1000,本题数据量极大,DFS递归写法会直接栈溢出超时,而并查集无递归深度限制,稳定性更强。
六、通用并查集模板
这里给大家整理一份通用Python模板,包含路径压缩+按秩合并双重优化,适配绝大多数算法题:
ps:但其实不使用按秩合并(启发式合并)也行,对复杂度影响不大,一般情况下路径压缩就够了。
python
class UnionFind:
def __init__(self, size):
self.parent = list(range(size)) # 父节点数组
self.rank = [1] * size # 秩:树的高度,用于按秩合并
# 查找+路径压缩
def find(self, x):
if self.parent[x] != x:
self.parent[x] = self.find(self.parent[x])
return self.parent[x]
# 合并+按秩合并(防止树过高)
def union(self, x, y):
x_root = self.find(x)
y_root = self.find(y)
if x_root == y_root:
return False # 已连通,无需合并
# 矮树合并到高树下方
if self.rank[x_root] < self.rank[y_root]:
self.parent[x_root] = y_root
else:
self.parent[y_root] = x_root
if self.rank[x_root] == self.rank[y_root]:
self.rank[x_root] += 1
return True七、总结
-
核心本质 :并查集是处理连通性、集合分组的轻量化数据结构;
-
两大优化:路径压缩(扁平化树)、按秩合并(限制树高度),均摊复杂度近乎常数;
-
刷题取舍:只判断连通性优先用并查集,需要遍历路径、搜索节点再用DFS/BFS;
-
本题结论:1971题目最优解为并查集,代码简洁、不易超时、空间开销小。
后续遇到无向图连通、朋友圈、岛屿数量等题目,直接套用并查集模板即可快速AC。