1、死锁:
死锁的发生,必须同时满足 4 个必要条件,缺一不可。互斥条件、持有并等待、不可剥夺、循环等待
1.1、批量行锁、执行顺序不一样引发死锁问题
1.1.1、情况分析:
举一个SQL的例子:
sql
# 事务1
BEGIN;
UPDATE phone_order_available SET upstream_callback_status = 1
WHERE id = 11;
UPDATE phone_order_available SET upstream_callback_status = 1
WHERE id = 12;
UPDATE phone_order_available SET upstream_callback_status = 1
WHERE id = 13;
COMMIT;
ROLLBACK;
sql
# 事务2
BEGIN;
UPDATE phone_order_available SET shop_callback_status = 1
WHERE id = 12;
UPDATE phone_order_available SET shop_callback_status = 1
WHERE id = 13;
UPDATE phone_order_available SET shop_callback_status = 1
WHERE id = 11;
COMMIT;
ROLLBACK;在这个例子中我们需要知道一个问题,锁只有在开启事务的时候才会出现,在这个例子中我开启了事务1和事务2.当我的事务1开启时执行了:
sql
UPDATE phone_order_available SET upstream_callback_status = 1
WHERE id = 11;事务2开启时执行了:
sql
UPDATE phone_order_available SET shop_callback_status = 1
WHERE id = 12;事务1锁的是id = 11的这个行,是行锁(update这个关键字会自动加锁且是行锁)。
事务2锁的是id = 12的这个行,是行锁。
当事务1执行:
sql
UPDATE phone_order_available SET upstream_callback_status = 1
WHERE id = 12;想锁id = 12但是此时因为事务2已经拿了这把锁,所以就只能阻塞了。这时候事务2继续执行:
sql
UPDATE phone_order_available SET shop_callback_status = 1
WHERE id = 13;
UPDATE phone_order_available SET shop_callback_status = 1
WHERE id = 11;此时id = 11已经被事务1给锁住了,所以此时事务2也得阻塞但是由于已经互卡了就成死锁了。
当MySQL的死锁检测器立刻发现之后回滚其中一个事务,另一个事务继续执行。
1.1.2、解决方法:
sql
UPDATE phone_order_available SET upstream_callback_status = 1
WHERE id in (11,12,13);用in语句就能很好的解决这个问题,因为in()这个语句无论里面的顺序是怎么样的((11, 12, 13),(12, 11, 13))MySQL的编译器会按照自己的一个设定来固定一个顺序输出,这样就很好的解决了这个问题。
比如说:
sql
#事务1
BEGIN;
UPDATE phone_order_available SET upstream_callback_status = 1 WHERE id = 11;
UPDATE phone_order_available SET upstream_callback_status = 1 WHERE id = 12;
UPDATE phone_order_available SET upstream_callback_status = 1 WHERE id = 13;
COMMIT;
sql
事务2
BEGIN;
UPDATE phone_order_available SET shop_callback_status = 1 WHERE id = 11;
UPDATE phone_order_available SET shop_callback_status = 1 WHERE id = 12;
UPDATE phone_order_available SET shop_callback_status = 1 WHERE id = 13;
COMMIT;用一样的顺序去执行,事务1先锁11,事务2也想锁11但因为11已经被锁了所以只能阻塞等待了。事务1继续锁12、锁13,事务1 提交→释放所有锁,事务2拿到锁,继续执行。
1.2、间隙锁引发死锁问题
1.2.1、情况分析:
sql
# 事务1 间隙锁之间不互斥、间隙锁和排他锁(行锁)互斥的
BEGIN;
# (7,18)
SELECT * from `user` WHERE id = 10 FOR UPDATE;
INSERT INTO `user`(id,username,pwd,age,pic,sex) VALUES (10,"派大星","123456",3,"paidaxing.png",2);
COMMIT;
ROLLBACK;
sql
# 事务2
BEGIN;
# (7,18)
SELECT * from `user` WHERE id = 11 FOR UPDATE;
INSERT INTO `user`(id,username,pwd,age,pic,sex) VALUES (11,"oo","pp",25,"www.yyy.com/pic",1);
COMMIT;
ROLLBACK;这个问题最核心的一句话:间隙锁之间不互斥、间隙锁和排他锁(行锁)互斥的。为什么?
间隙锁的设计目的,是为了防止幻读,它只阻止其他事务在这个间隙里插入新数据,但多个事务可以同时持有同一个间隙的间隙锁。
间隙锁和行锁(排他锁)之间是互斥的 为什么?
这个很好理解就是排他锁会排除其他的锁。
sql
SELECT * from `user` WHERE id = 10 FOR UPDATE;
INSERT INTO `user`(id,username,pwd,age,pic,sex) VALUES (10,"派大星","123456",3,"paidaxing.png",2);这里加的是间隙锁,首先id = 10在这个表中的数据是找不到的,如果找到了就加行锁,找不到就加临键锁,但因为找不到10这个数据就进行锁降级加间隙锁,锁的是(7, 18)这个区间,也就是这个表中10的上一个数据和下一个数据之间的这个区间,此处有个insert插入操作(因为这里插入的是id这个主键)所以这里会自动给他加一个插入意向锁(因为要排斥其他要修改id=10的操作不然可能会引起其他错误(主键重复插入(重复提交)、脏读、幻读))这里也就引出了间隙锁和插入意向锁不互斥从而引发死锁。
再明白的讲:id=10锁的是(7, 18)这个区间,id=11也是锁的(7, 18)这个区间互相卡住了对方的锁资源都在等待对方释放锁,直接就引发了死锁。
1.2.2、解决问题
事务1和事务2中其中一个不加锁或者直接加分布式锁。
方案一:去掉SELECT ... FOR UPDATE,不加锁。
原代码:
sql
BEGIN;
SELECT * FROM user WHERE id = 10 FOR UPDATE; -- 间隙锁的根源
-- 判断是否存在...
INSERT ...;
COMMIT;改成:
sql
BEGIN;
SELECT * FROM user WHERE id = 10; -- 普通SELECT,不加任何锁(快照读)
-- 判断是否存在...
INSERT ...;
COMMIT;普通SELECT不会加间隙锁,也不会加任何行锁,因此两个事务可以并发执行,不会互相阻塞,自然也就不存在间隙锁与插入意向锁的死锁。
(1)潜在问题及处理:
①并发插入导致主键冲突
如果两个事务都通过普通SELECT发现id=10不存在,然后都执行INSERT,那么第二个INSERT会因为主键重复而失败(或阻塞,取决于唯一索引检测)。
解决方案:
在应用层捕获Duplicate entry错误,然后重试整个事务(或直接返回成功,因为记录已经存在)。
改用INSERT IGNORE或INSERT ... ON DUPLICATE KEY UPDATE,彻底不需要先SELECT。
①幻读影响
如果业务逻辑要求"在事务内多次查询结果一致",普通SELECT在RR隔离级别下确实不会看到其他事务新插入的数据(快照读),但如果你在INSERT之前需要基于查询结果做复杂判断(例如统计数量),可能因为快照读读不到最新数据而做出错误决策。不过对于"不存在则插入"这种逻辑,快照读其实已经足够(如果读到不存在,但实际别的事务已经插入了,你的INSERT会因主键冲突失败,重试即可)。
方案二:直接加分布式锁:
(1)为什么分布式锁能解决这个问题?
分布式锁的核心思想:
在分布式环境中,多个进程通过一个外部共享的、互斥的协调者,来确保对同一共享资源的操作在同一时刻只能被一个进程执行。
原来的死锁是因为两个事务同时持有了间隙锁。使用分布式锁后,对于同一个user_id的操作会被串行化:只有一个客户端能拿到锁,其他客户端必须等待。没有两个并发事务同时进入临界区,就不会出现"你持有间隙锁,我需要插入意向锁"的互斥等待,从而彻底避免死锁。注意:如果两个事务操作的是不同的 user_id(例如 10 和 11),分布式锁可以使用不同的key,因此它们仍然可以并行执行,不会互相阻塞。这正是分布式锁粒度精细的优势。
(2)具体实现方案
以下以Redis分布式锁为例:
①改造后的业务逻辑(伪代码):
java
String lockKey = "user_lock:" + userId; // 例如 "user_lock:10"
// 尝试获取分布式锁,超时 5 秒,锁自动过期 10 秒
if (redisLock.tryLock(lockKey, 5, 10, TimeUnit.SECONDS)) {
try {
// 1. 查询用户是否存在(普通 SELECT,不加 FOR UPDATE)
User user = userMapper.selectById(userId);
if (user == null) {
// 2. 不存在则插入
userMapper.insert(new User(userId, ...));
}
// 3. 提交事务(如果使用了数据库事务,可以自动提交)
} finally {
redisLock.unlock(lockKey);
}
} else {
// 获取锁失败,重试或返回失败
throw new LockAcquisitionException("操作过于频繁,请稍后重试");
}(3)为什么这样就不会出现间隙锁死锁?
①锁的粒度是user_id,两个不同id的操作可以并行,不影响性能。
②对于同一个id,同一时刻只有一个客户端能进入临界区,因此不会有多个事务同时去SELECT ... FOR UPDATE,也不会有多个事务同时持有间隙锁。
③临界区内的SELECT使用普通查询(快照读),不需要加任何行锁或间隙锁;INSERT正常进行。
④由于没有并发事务,数据库隔离级别即便还是REPEATABLE READ,也不会产生幻读(因为只有一个写入者)。
(4)处理锁超时与续期:
①锁过期时间:应大于业务最大执行时间,例如业务通常耗时100ms,设置5s即可。如果业务可能很长(比如批量处理),需要启动看门狗线程自动续期。
②Redis建议使用Redisson:它内置了看门狗机制,默认每10秒续期一次,避免业务未完成锁被自动释放。
③如果锁意外过期,而业务还在执行,其他客户端可能获得锁并产生并发问题。因此也可以采用安全模式:在业务代码中定期检查锁是否仍被自己持有,若丢失则主动回滚或抛出异常。
(5)使用Redisson完整的java代码示例:
java
public void insertUserWithLock(int userId, String username, ...) {
RLock lock = redisson.getLock("user_lock:" + userId);
try {
// 尝试加锁,最多等待 3 秒,锁自动释放时间 30 秒(看门狗会自动续期)
if (lock.tryLock(3, 30, TimeUnit.SECONDS)) {
try {
// 开启数据库事务(可选)
// 查询用户是否存在(不加 FOR UPDATE)
User existUser = userDao.selectById(userId);
if (existUser == null) {
userDao.insert(new User(userId, username, ...));
log.info("插入用户 {} 成功", userId);
} else {
log.info("用户 {} 已存在,无需插入", userId);
}
// 提交事务
} finally {
lock.unlock();
}
} else {
throw new RuntimeException("获取锁失败,请稍后重试");
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException("锁等待被中断");
}
}1.3、普通索引回表引发的死锁
1.3.1、情况分析:
sql
set session transaction isolation level read committed;
show variables like 'transaction%';
BEGIN;
update `user` SET `age` = 12 where `name` = 'zhangsan' AND `date1` <= '2023-08-10' AND phone = '214231';
update `user` SET `age` = 12 where `name` = 'zhangsan' AND `date1` > '2023-08-10';
COMMIT;
ROLLBACK;
SELECT * FROM performance_schema.data_locks;
SHOW PROCESSLIST;
kill 1797;
sql
set session transaction isolation level read committed;
show variables like 'transaction%';
BEGIN;
update `user` SET `age` = 11 where `name` = 'zhangsan' AND `date1` <= '2023-08-10' AND phone = '124342523';
ROLLBACK;
COMMIT;这两张数据库的数据如下:
|----|----------|------------|------------|------------|-----|
| id | name | phone | date | date1 | age |
| 1 | lisi | 12345 | Null | Null | 18 |
| 4 | wangwu | 1278612991 | Null | Null | 20 |
| 9 | zhangsan | 1729200191 | 2023-08-10 | 2023-08-11 | 1 |
| 10 | zhangsan | 124342523 | 2023-08-10 | 2023-08-10 | 1 |
| 11 | zhangsan | 214231 | 2023-08-11 | 2023-08-10 | 1 |
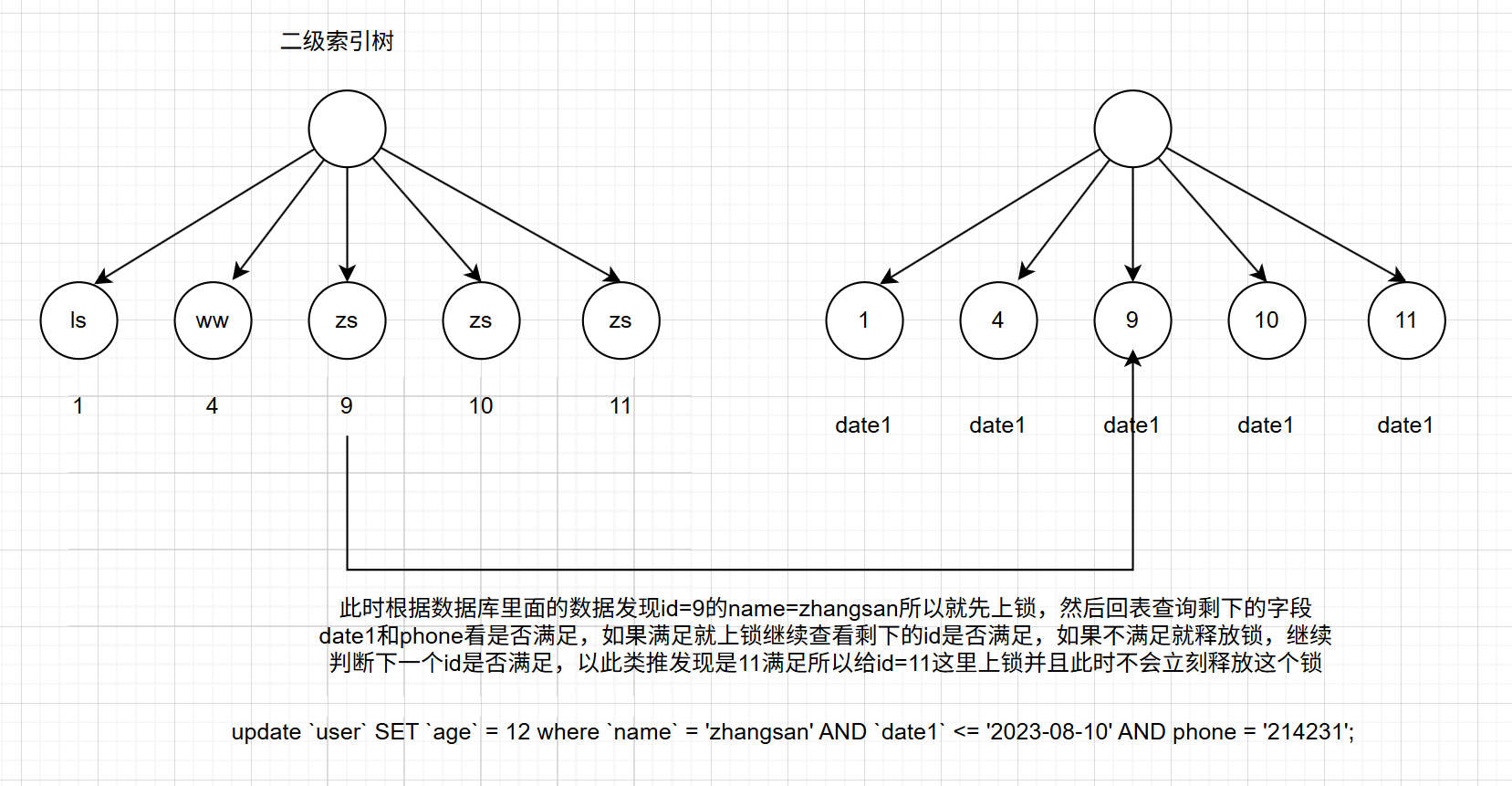
sql
update `user` SET `age` = 12 where `name` = 'zhangsan' AND `date1` <= '2023-08-10' AND phone = '214231';在第一个事务中,运行这行SQL代码,进行一个判断,需要满足name = zhangsan、date1 <= 2023-08-10且phone = 214231。这时当一个索引查找到9的时候发现满足name = zhangsan此时需要回表,回到主键索引里面拿到完整的数据,再进行具体的比较。
此时来到了第二个事务,运行这行SQL代码:
sql
update `user` SET `age` = 11 where `name` = 'zhangsan' AND `date1` <= '2023-08-10' AND phone = '124342523';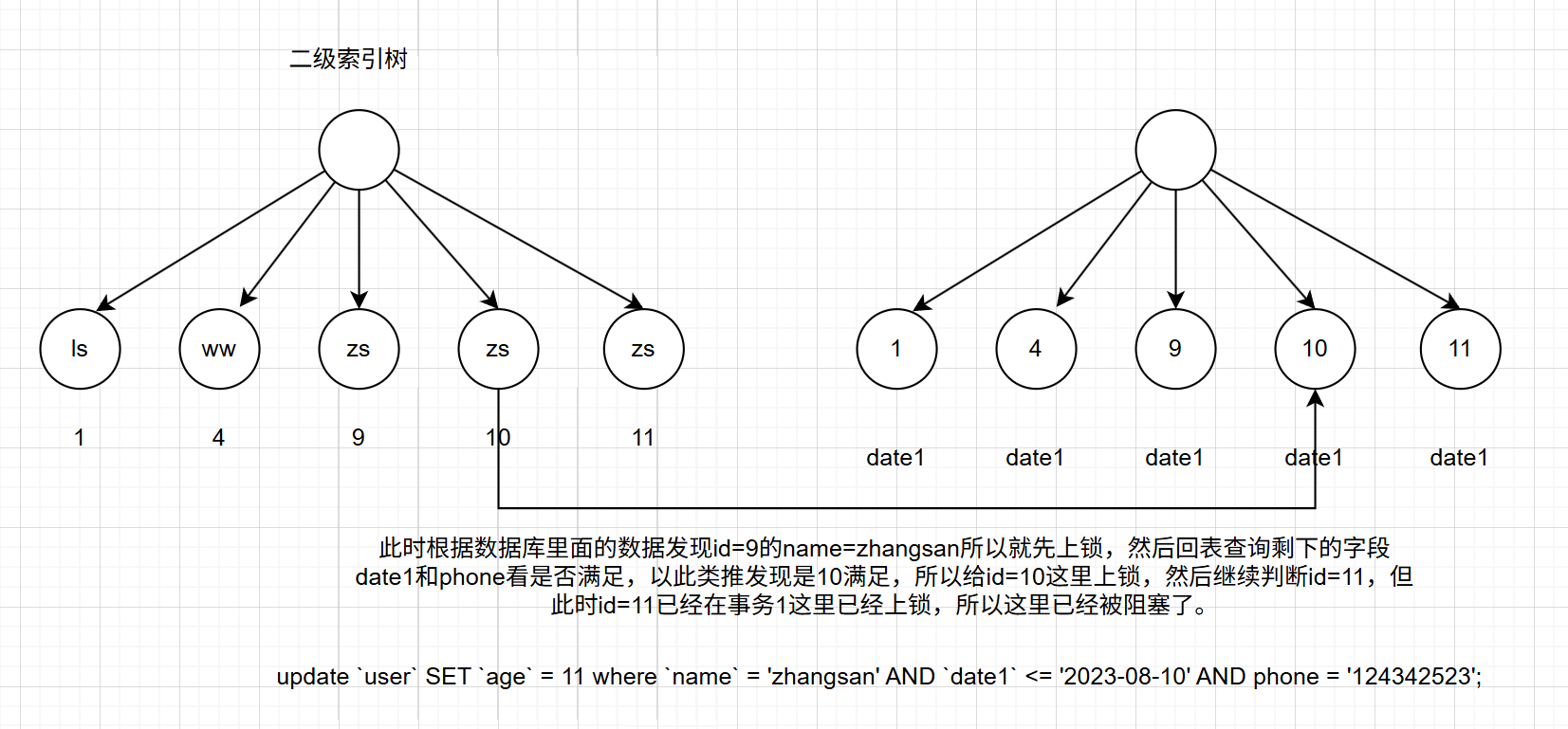
此刻继续运行事务1的SQL代码:
sql
update `user` SET `age` = 12 where `name` = 'zhangsan' AND `date1` > '2023-08-10';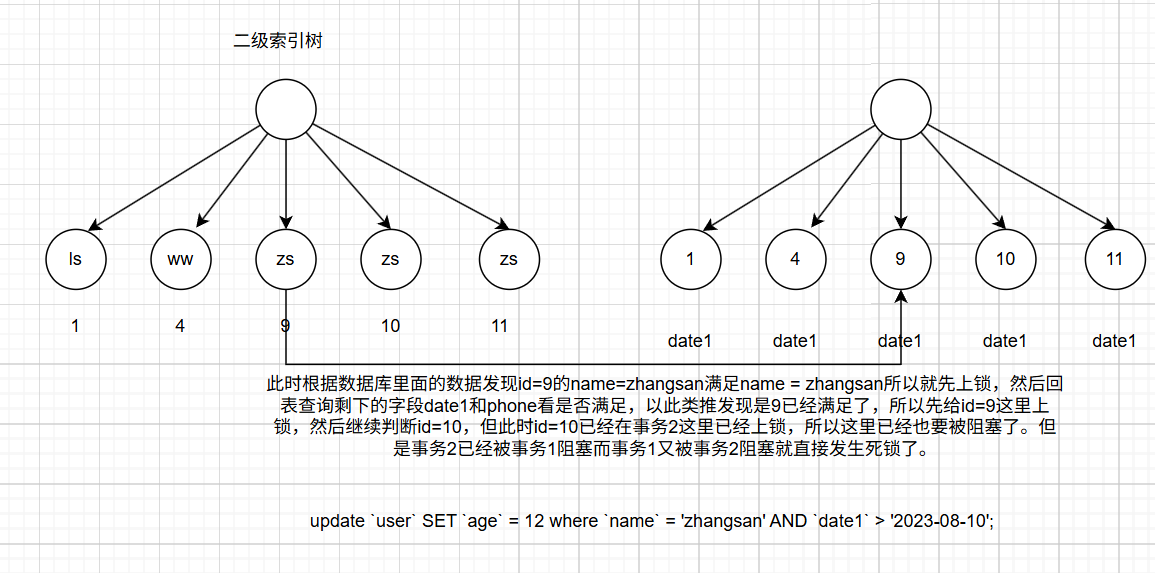
这里就已经发生死锁了。
1.3.2、解决方案:
(1)事务隔离级别如果是RR就不会在这种情况下发生死锁现象。
(2)用联合索引也不会出现这种死锁问题。
1.4、索引合并引发的死锁(merge index)
1.4.1、索引优化:
MySQL5.0之前,一个表一次只能使用一个索引,无法同时使用多个索引分别进行条件扫描。但是从5.1开始,引入了index merge优化技术,对同一个表可以使用多个索引(一般是2个)分别进行条件扫描。简单的说,index merge技术其实就是:对多个索引分别进行条件扫描,然后将它们各自的结果进行合并,合并方式分为三种:union, intersection, 以及它们的组合sort_union (先内部intersect然后在外部union);
查看数据库是否开启了index_merge: show variables like '% optimizer_switch%' ;
关闭index_merge(重启才能生效): set @@global.optimizer_switch = 'index_merge=off' ;
开启index_merge(重启才能生效): set @@global.optimizer_switch = 'index_merge=on' ;
默认index_merge 索引优化是开启的;
举个例子:
执行语句: EXPLAIN update users set phone = '10086' where name = 'tom' and age = 25;
|----|-------------|-------|-------------|------------------|------------------|---------|------|------|-------------------------|
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
| 1 | SIMPLE | users | index_merge | idx_age,idx_name | idx_age,idx_name | 2,257 | NULL | 1 | Using intersect(idx_... |
这种情况用到了索引index_merge 优化。对index_age, idx_name索引分别进行条件扫描;然后扫描结果出来的 id 列值进行交集;然后再二次查找(也叫回表);最终通过聚簇索引primary索引返回行数据;
(1)index_merge 索引优化的作用:
我们可以对比索引合并与普通利用单个索引的效率:
还是以EXPLAIN update users set phone = '10086' where name = 'tom' and age = 25为例子。
(2)单个索引:
①根据name = 'tom'查询条件,利用idx_name索引找到叶子节点中保存的id值;
②通过找到的id值,利用PRIMARY索引找到叶子节点中保存的行数据;
③再通过age = 25条件对找到的行数据进行过滤。
(3)索引合并:
①根据name = 'tom'查询条件,利用idx_name索引找到叶子节点中保存的id值;
②根据age = 25查询条件,利用idx_age索引找到叶子节点中保存的id值;
③将1、2步中找到的id值取交集,然后利用PRIMARY索引找到叶子节点中保存的行数据
上边两种情况的主要区别在于,第一种是先通过一个索引把数据找到后,再用其它查询条件进行过滤;第二种是先通过两个索引查出的id值取交集,如果取交集后还存在id值,则再去回表将数据取出来。开启索引index_merge之后,不一定都会用到索引优化;只有当优化器认为索引合并比单个索引优势大的时候就会触发索引合并。
1.4.2、情况分析:
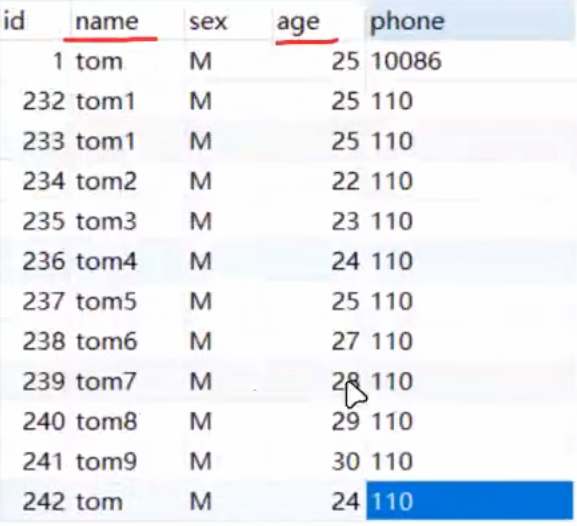
用这个数据库里面的数据来举例子(其中name、age为索引):
sql
update users set phone = '10086' where name = 'tom4' and age = 24 #事务1
update users set phone = '10086' where name = 'tom' and age = 24 #事务2|-------------------------------------------------------|---------------------------------------------------------|
| 事务1 | 事务2 |
| 锁住idx_name索引中的name为tom4的索引项 | |
| | 锁住idx_name索引中的name为tom 的索引项 |
| 回表锁住Primary索引中的id为236的索引项 | |
| | 回表锁住Primary索引中的id为242的索引项 |
| 锁住idx_age索引中的age为24的索引项 | |
| | 试图锁住 idx_age索引中的age为24的索引项,发现该索引项目锁住了,等待事务1释放age为24的索引项 |
| 试图回表锁住Primary索引中的id为 242,236的索引项。发现242索引被事务2锁住了,等待释放。 | |
| 导致死锁了。 ||
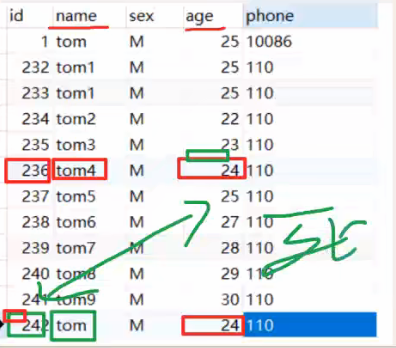
用一段话来解释一遍这个过程:首先事务1先锁tom4,这时需要进行回表将id=236这个字段也给锁住,事务2锁tom,需要进行回表将id=242这个字段锁住。这时,事务1将age=24这个相关的字段锁住也就是会去锁age = 24的所有字段,再进行一个回表就会锁id = 236和id = 242但id = 242已经被事务2给锁住了,所以就只能进行阻塞了。事务2继续将age=24进行查询,然后再来锁age=24的所有行,但id = 236已经被事务1锁了,所以此时就直接死锁了。
1.4.3、解决方案:
(1)将index_merge (互斥优化):set @@global.optimizer_switch = 'index_merge=off';这个给关闭了就行(有设置按钮,可以直接进行关闭,可以通过show variables like '%optimizer_switch%';这行代码进行一个查看)。
(2)将age和name建立成联合索引也可以解决这个死锁问题。
(3)减去其中一个索引,避免索引合并;在业务代码里面过滤。
(4)使用复合索引替代。