一、问题:3套监控各发各的告警,值班快疯了
有一个客户的运维体系优化项目,情况是这样:
- Zabbix:管着200台物理服务器+50台网络设备,告警发到企业微信群A
- Prometheus+Alertmanager:管着K8s集群+中间件,告警发到企业微信群B
- 阿里云云监控CMS:管着30台ECS+RDS+SLB,告警发到钉钉群
值班人的日常:每天早上打开3个群,逐条看告警;同一台机器在Zabbix和云监控里各报了一遍(一个报CPU高、一个报ECS异常),但没人知道是同一件事;核心交换机Down了之后Zabbix报了交换机告警,Prometheus报了依赖这台交换机的服务超时,云监控报了SLB健康检查失败------3条告警分散在3个群里,值班人花了20分钟才意识到"这是一件事"。
核心观点:多监控工具并存不是问题------没有统一的事件入口才是问题。不管用几套监控工具,告警必须汇入同一个事件中心做归一化处理。
二、整体架构
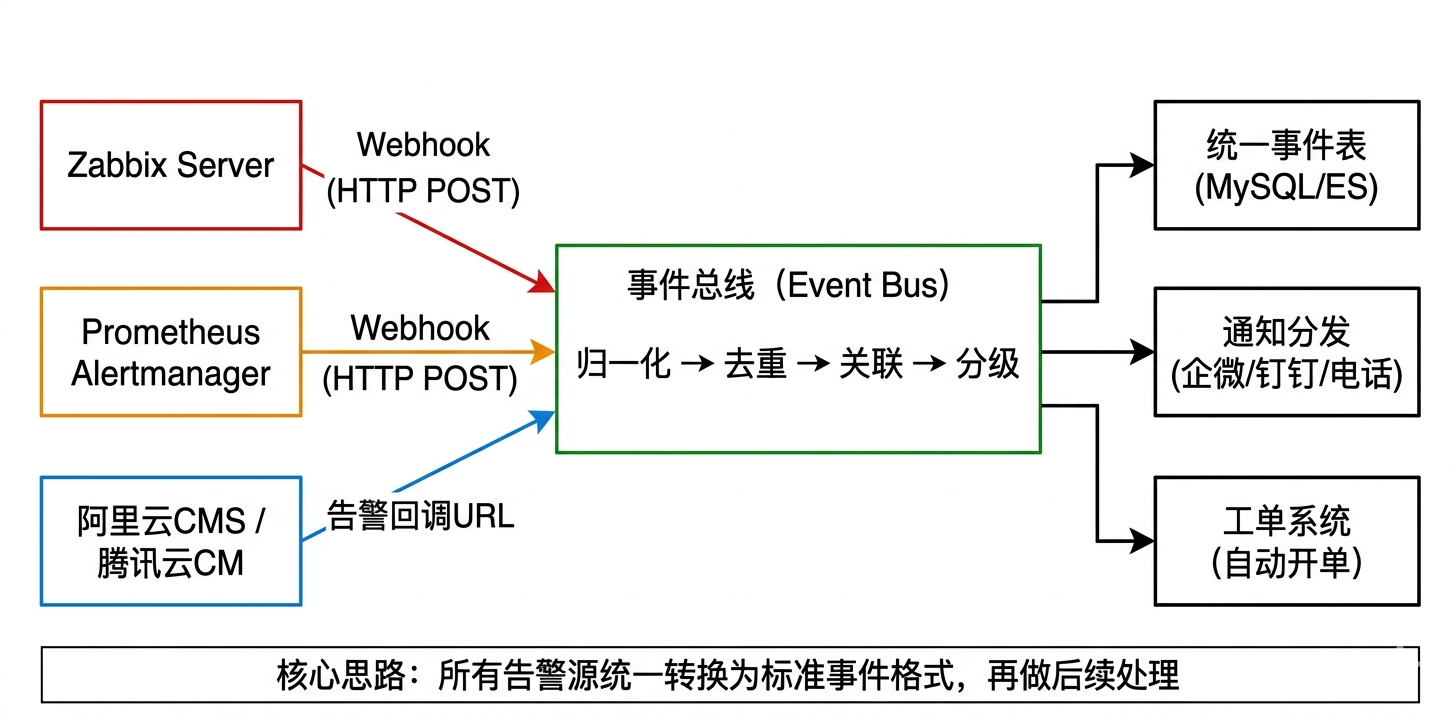
关键设计原则:
- 每个告警源只负责"发Webhook到事件总线"
- 事件总线负责"归一化→去重→关联→分级→分发"
- 下游只对接事件总线,不直接对接告警源
三、各告警源Webhook对接配置
3.1 Zabbix Webhook配置
Zabbix 5.0+支持Webhook类型的告警媒介:
步骤1:管理 → 报警媒介类型 → 创建
javascript
// Zabbix Webhook脚本(JavaScript)
// 管理 → 报警媒介类型 → 新建 → 类型选Webhook
var params = JSON.parse(value);
var req = new HttpRequest();
req.addHeader('Content-Type: application/json');
var payload = {
source: "zabbix",
alert_id: params.event_id,
status: params.event_status, // "PROBLEM" or "RESOLVED"
severity: params.trigger_severity, // "Disaster"/"High"/"Average"...
host: params.host_name,
host_ip: params.host_ip,
alert_name: params.trigger_name,
description: params.trigger_description,
timestamp: params.event_time,
tags: params.event_tags, // "app:mysql,env:prod" 格式
event_url: params.zabbix_url + "/tr_events.php?triggerid=" + params.trigger_id
};
var resp = req.post(
"http://event-bus:8080/api/v1/alerts/ingest",
JSON.stringify(payload)
);
if (req.getStatus() !== 200) {
throw "Event bus responded with: " + resp;
}
return "OK";步骤2:配置参数映射(在Webhook参数里配置)
| 参数名 | 值(Zabbix宏) |
|---|---|
| event_id | {EVENT.ID} |
| event_status | {EVENT.VALUE} |
| trigger_severity | {TRIGGER.SEVERITY} |
| host_name | {HOST.NAME} |
| host_ip | {HOST.IP} |
| trigger_name | {TRIGGER.NAME} |
| trigger_description | {TRIGGER.DESCRIPTION} |
| event_time | {EVENT.DATE} {EVENT.TIME} |
| event_tags | {EVENT.TAGS} |
| trigger_id | {TRIGGER.ID} |
| zabbix_url | http://zabbix.internal |
步骤3:创建动作绑定
管理 → 动作 → 触发器动作 → 新建:
- 条件:触发器严重性 >= "警告"
- 操作:发送消息 → 媒介类型选上面的Webhook → 发给"Event Bus"用户组
3.2 Prometheus Alertmanager Webhook配置
Alertmanager原生支持webhook_configs:
yaml
# alertmanager.yml
route:
receiver: 'event-bus'
group_by: ['alertname', 'instance']
group_wait: 30s
group_interval: 5m
repeat_interval: 4h
routes:
# 所有告警都转发到事件总线
- match_re:
alertname: '.+'
receiver: 'event-bus'
continue: true # continue=true: 转发后还可以走其他receiver(如直接发企微作为备份)
receivers:
- name: 'event-bus'
webhook_configs:
- url: 'http://event-bus:8080/api/v1/alerts/ingest'
send_resolved: true
http_config:
bearer_token: 'your-api-token'Alertmanager发出的Webhook数据结构(固定格式,不可自定义):
json
{
"version": "4",
"groupKey": "{}:{alertname=\"NodeHighCPU\"}",
"status": "firing",
"receiver": "event-bus",
"alerts": [
{
"status": "firing",
"labels": {
"alertname": "NodeHighCPU",
"instance": "192.168.1.10:9100",
"severity": "warning",
"job": "node"
},
"annotations": {
"summary": "CPU使用率超85%: 192.168.1.10",
"description": "CPU使用率 87.3%,持续超过10分钟"
},
"startsAt": "2026-05-19T08:30:00.000Z",
"endsAt": "0001-01-01T00:00:00Z",
"generatorURL": "http://prometheus:9090/graph?g0.expr=..."
}
]
}3.3 阿里云云监控告警回调
在阿里云云监控控制台配置告警联系人组时,可以设置"告警回调URL":
路径:云监控 → 报警服务 → 报警联系人 → 创建报警联系人组 → 填写Webhook地址
回调URL: http://event-bus.yourcompany.com:8080/api/v1/alerts/ingest阿里云CMS回调的数据格式:
json
{
"alertName": "ECS_CPU_utilization",
"alertState": "ALERT",
"curValue": "92.5",
"dimensions": "{\"instanceId\":\"i-bp1234567890\",\"userId\":\"1234567890\"}",
"expression": "Average(CPUUtilization)>85",
"instanceName": "prod-web-01",
"metricName": "CPUUtilization",
"metricProject": "acs_ecs_dashboard",
"namespace": "acs_ecs_dashboard",
"preName": "ECS实例CPU使用率过高",
"regionId": "cn-hangzhou",
"ruleId": "rule_12345",
"timestamp": 1716091800000,
"triggerLevel": "WARN",
"userId": "1234567890"
}3.4 腾讯云云监控告警回调
腾讯云CM的配置路径:云监控 → 告警配置 → 通知模板 → 接口回调
回调URL填写事件总线地址,腾讯云的回调格式:
json
{
"sessionId": "xxxxxxxx",
"alarmStatus": "1",
"alarmType": "metric",
"alarmObjInfo": {
"region": "gz",
"namespace": "qce/cvm",
"dimensions": "{\"unInstanceId\":\"ins-xxxxx\"}"
},
"alarmPolicyInfo": {
"policyName": "CPU使用率告警",
"conditions": {
"metricName": "cpu_usage",
"metricShowName": "CPU使用率",
"calcType": ">",
"calcValue": "85",
"currentValue": "91.2",
"calcUnit": "%"
}
},
"firstOccurTime": "2026-05-19 08:30:00",
"durationTime": 300
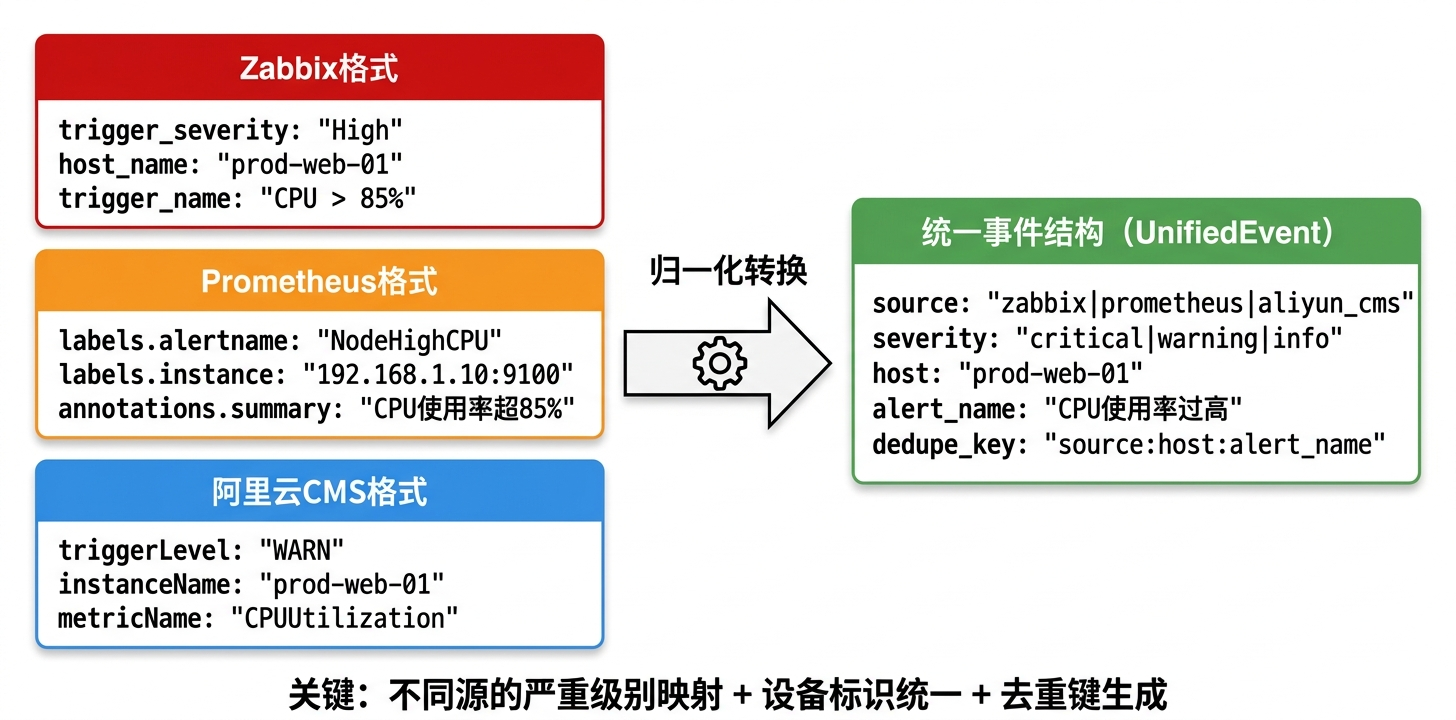
}四、事件归一化:把4种格式转成1种
这是整个方案最关键的一步。4个告警源的数据格式完全不同,必须转成统一的事件结构才能做后续处理。
统一事件数据结构(Event Schema)
python
# event_schema.py
from dataclasses import dataclass, field
from typing import Optional, Dict, List
from datetime import datetime
from enum import Enum
class Severity(Enum):
CRITICAL = "critical" # P1
WARNING = "warning" # P2
INFO = "info" # P3
class EventStatus(Enum):
FIRING = "firing"
RESOLVED = "resolved"
@dataclass
class UnifiedEvent:
"""统一事件结构 - 所有告警源归一化后的标准格式"""
# === 必填字段 ===
event_id: str # 全局唯一ID(UUID)
source: str # 来源:zabbix / prometheus / aliyun_cms / tencent_cm
source_alert_id: str # 原始告警ID(用于去重和关联恢复)
status: EventStatus # firing / resolved
severity: Severity # critical / warning / info
# === 对象标识 ===
host: str # 主机名或实例名
host_ip: Optional[str] = None # IP地址(如果有)
resource_id: Optional[str] = None # 云实例ID等
# === 事件内容 ===
alert_name: str = "" # 告警规则名
summary: str = "" # 一句话摘要
description: str = "" # 详细描述
metric_name: Optional[str] = None # 触发指标
current_value: Optional[str] = None # 当前值
# === 时间 ===
fired_at: datetime = field(default_factory=datetime.now)
resolved_at: Optional[datetime] = None
received_at: datetime = field(default_factory=datetime.now)
# === 扩展 ===
tags: Dict[str, str] = field(default_factory=dict)
labels: Dict[str, str] = field(default_factory=dict)
raw_payload: Dict = field(default_factory=dict) # 保留原始数据
# === 处理状态 ===
dedupe_key: str = "" # 去重键(source + host + alert_name)
is_duplicate: bool = False
correlated_events: List[str] = field(default_factory=list)各源归一化转换器
python
# normalizers.py
import uuid
import json
from datetime import datetime
from event_schema import UnifiedEvent, Severity, EventStatus
class ZabbixNormalizer:
"""Zabbix告警 → 统一事件格式"""
SEVERITY_MAP = {
"Disaster": Severity.CRITICAL,
"High": Severity.CRITICAL,
"Average": Severity.WARNING,
"Warning": Severity.WARNING,
"Information": Severity.INFO,
"Not classified": Severity.INFO,
}
def normalize(self, payload: dict) -> UnifiedEvent:
severity = self.SEVERITY_MAP.get(
payload.get("severity", ""), Severity.WARNING
)
status = (
EventStatus.RESOLVED
if payload.get("status") == "RESOLVED"
else EventStatus.FIRING
)
# 解析tags字符串 "app:mysql,env:prod" → dict
tags = {}
for tag_str in payload.get("tags", "").split(","):
if ":" in tag_str:
k, v = tag_str.split(":", 1)
tags[k.strip()] = v.strip()
return UnifiedEvent(
event_id=str(uuid.uuid4()),
source="zabbix",
source_alert_id=payload.get("alert_id", ""),
status=status,
severity=severity,
host=payload.get("host", ""),
host_ip=payload.get("host_ip"),
alert_name=payload.get("alert_name", ""),
summary=payload.get("alert_name", ""),
description=payload.get("description", ""),
fired_at=self._parse_time(payload.get("timestamp", "")),
tags=tags,
raw_payload=payload,
dedupe_key=f"zabbix:{payload.get('host', '')}:{payload.get('alert_name', '')}",
)
def _parse_time(self, time_str: str) -> datetime:
try:
return datetime.strptime(time_str, "%Y.%m.%d %H:%M:%S")
except (ValueError, TypeError):
return datetime.now()
class PrometheusNormalizer:
"""Prometheus Alertmanager告警 → 统一事件格式"""
SEVERITY_MAP = {
"critical": Severity.CRITICAL,
"warning": Severity.WARNING,
"info": Severity.INFO,
}
def normalize(self, payload: dict) -> list[UnifiedEvent]:
"""Alertmanager一次可能推送多条告警,返回列表"""
events = []
group_status = payload.get("status", "firing")
for alert in payload.get("alerts", []):
labels = alert.get("labels", {})
annotations = alert.get("annotations", {})
severity = self.SEVERITY_MAP.get(
labels.get("severity", "warning"), Severity.WARNING
)
status = (
EventStatus.RESOLVED
if alert.get("status") == "resolved"
else EventStatus.FIRING
)
# 从instance label提取host和IP
instance = labels.get("instance", "")
host_ip = instance.split(":")[0] if ":" in instance else instance
event = UnifiedEvent(
event_id=str(uuid.uuid4()),
source="prometheus",
source_alert_id=f"{labels.get('alertname', '')}_{instance}",
status=status,
severity=severity,
host=labels.get("instance", ""),
host_ip=host_ip,
alert_name=labels.get("alertname", ""),
summary=annotations.get("summary", ""),
description=annotations.get("description", ""),
fired_at=self._parse_time(alert.get("startsAt", "")),
resolved_at=self._parse_time(alert.get("endsAt", "")) if status == EventStatus.RESOLVED else None,
labels=labels,
tags={k: v for k, v in labels.items() if k not in ("alertname", "severity")},
raw_payload=alert,
dedupe_key=f"prometheus:{instance}:{labels.get('alertname', '')}",
)
events.append(event)
return events
def _parse_time(self, time_str: str) -> datetime:
try:
return datetime.fromisoformat(time_str.replace("Z", "+00:00"))
except (ValueError, TypeError):
return datetime.now()
class AliyunCMSNormalizer:
"""阿里云CMS告警 → 统一事件格式"""
LEVEL_MAP = {
"CRITICAL": Severity.CRITICAL,
"WARN": Severity.WARNING,
"INFO": Severity.INFO,
}
def normalize(self, payload: dict) -> UnifiedEvent:
severity = self.LEVEL_MAP.get(
payload.get("triggerLevel", "WARN"), Severity.WARNING
)
status = (
EventStatus.RESOLVED
if payload.get("alertState") == "OK"
else EventStatus.FIRING
)
# 解析dimensions JSON字符串
dimensions = {}
try:
dimensions = json.loads(payload.get("dimensions", "{}"))
except json.JSONDecodeError:
pass
instance_id = dimensions.get("instanceId", "")
return UnifiedEvent(
event_id=str(uuid.uuid4()),
source="aliyun_cms",
source_alert_id=payload.get("ruleId", ""),
status=status,
severity=severity,
host=payload.get("instanceName", ""),
resource_id=instance_id,
alert_name=payload.get("preName", ""),
summary=payload.get("preName", ""),
description=f"{payload.get('expression', '')},当前值: {payload.get('curValue', '')}",
metric_name=payload.get("metricName"),
current_value=payload.get("curValue"),
fired_at=datetime.fromtimestamp(payload.get("timestamp", 0) / 1000),
tags={"region": payload.get("regionId", ""), "namespace": payload.get("namespace", "")},
raw_payload=payload,
dedupe_key=f"aliyun_cms:{instance_id}:{payload.get('metricName', '')}",
)
五、事件去重:同一告警5分钟内不重复生成事件
python
# deduplication.py
from datetime import datetime, timedelta
from typing import Optional
import redis
# 用Redis做去重窗口(简单高效)
redis_client = redis.Redis(host='localhost', port=6379, db=0)
DEDUPE_WINDOW = 300 # 5分钟窗口
def check_and_mark_duplicate(event) -> bool:
"""
检查事件是否是重复的。
去重键 = source + host + alert_name
5分钟窗口内同一去重键只保留第一条。
"""
dedupe_key = event.dedupe_key
# 尝试设置key,如果已存在则说明是重复
is_new = redis_client.set(
f"dedupe:{dedupe_key}",
event.event_id,
nx=True, # 只在key不存在时设置
ex=DEDUPE_WINDOW
)
if not is_new:
# 已存在,是重复事件
event.is_duplicate = True
# 获取原始事件ID用于关联
original_event_id = redis_client.get(f"dedupe:{dedupe_key}")
if original_event_id:
event.correlated_events.append(original_event_id.decode())
return True
return False六、事件关联:同一设备/服务的告警串起来
python
# correlation.py
from datetime import datetime, timedelta
from typing import List
# 关联窗口:10分钟内同一host的告警视为相关
CORRELATION_WINDOW = timedelta(minutes=10)
def correlate_events(new_event, recent_events: List) -> List[str]:
"""
关联逻辑:
1. 同一host,10分钟内的其他事件 → 互相关联
2. 同一IP,10分钟内的其他事件 → 互相关联(跨监控源)
"""
correlated = []
for existing in recent_events:
if existing.event_id == new_event.event_id:
continue
# 时间窗口检查
time_diff = abs((new_event.fired_at - existing.fired_at).total_seconds())
if time_diff > CORRELATION_WINDOW.total_seconds():
continue
# 关联条件1:同host
if new_event.host and new_event.host == existing.host:
correlated.append(existing.event_id)
continue
# 关联条件2:同IP(跨监控源关联的关键)
if new_event.host_ip and new_event.host_ip == existing.host_ip:
correlated.append(existing.event_id)
continue
# 关联条件3:同resource_id
if new_event.resource_id and new_event.resource_id == existing.resource_id:
correlated.append(existing.event_id)
continue
return correlated跨源关联的关键 :Zabbix用hostname、Prometheus用instance(IP:port)、云监控用instanceId。要实现跨源关联,必须有一个资产映射表,把这三者对应起来:
sql
-- 资产映射表:打通不同监控源的设备标识
CREATE TABLE asset_mapping (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
hostname VARCHAR(128), -- Zabbix里的Host Name
ip_address VARCHAR(45), -- Prometheus instance的IP
cloud_instance_id VARCHAR(128), -- 阿里云/腾讯云实例ID
cmdb_device_id VARCHAR(64), -- CMDB设备ID(如果有)
service_name VARCHAR(128), -- 所属业务服务
UNIQUE INDEX idx_hostname (hostname),
INDEX idx_ip (ip_address),
INDEX idx_cloud_id (cloud_instance_id)
);
-- 示例数据
INSERT INTO asset_mapping VALUES
(1, 'prod-web-01', '192.168.1.10', 'i-bp1234567890', 'DEV-001', 'order-service'),
(2, 'prod-db-01', '192.168.1.20', 'i-bp0987654321', 'DEV-002', 'mysql-master');有了这张表,不管告警从哪个源来,都能通过hostname/IP/cloud_id找到同一台设备,实现跨源关联。
七、事件总线完整API实现
python
# event_bus.py - Flask实现的事件总线入口
from flask import Flask, request, jsonify
from normalizers import ZabbixNormalizer, PrometheusNormalizer, AliyunCMSNormalizer
from deduplication import check_and_mark_duplicate
from correlation import correlate_events
from notification import dispatch_notification
import logging
app = Flask(__name__)
logger = logging.getLogger(__name__)
# 初始化归一化器
normalizers = {
"zabbix": ZabbixNormalizer(),
"prometheus": PrometheusNormalizer(),
"aliyun_cms": AliyunCMSNormalizer(),
}
@app.route("/api/v1/alerts/ingest", methods=["POST"])
def ingest_alert():
"""统一告警接入入口"""
payload = request.get_json(force=True)
# 1. 判断来源并归一化
source = detect_source(payload)
normalizer = normalizers.get(source)
if not normalizer:
return jsonify({"error": f"unknown source: {source}"}), 400
# Prometheus可能一次推送多条
if source == "prometheus":
events = normalizer.normalize(payload)
else:
events = [normalizer.normalize(payload)]
results = []
for event in events:
# 2. 去重
is_dup = check_and_mark_duplicate(event)
if is_dup:
logger.info(f"Duplicate event suppressed: {event.dedupe_key}")
results.append({"event_id": event.event_id, "status": "deduplicated"})
continue
# 3. 关联
recent = get_recent_events(minutes=10)
correlated_ids = correlate_events(event, recent)
event.correlated_events = correlated_ids
# 4. 持久化
save_event(event)
# 5. 分发通知
if event.status.value == "firing":
dispatch_notification(event)
results.append({"event_id": event.event_id, "status": "processed"})
logger.info(
f"Event processed: {event.source}/{event.alert_name} "
f"severity={event.severity.value} correlated={len(correlated_ids)}"
)
return jsonify({"results": results}), 200
def detect_source(payload: dict) -> str:
"""根据payload特征自动判断来源"""
if "alerts" in payload and "groupKey" in payload:
return "prometheus"
if payload.get("source") == "zabbix":
return "zabbix"
if "metricProject" in payload or "namespace" in payload:
if "acs_" in payload.get("namespace", ""):
return "aliyun_cms"
if "alarmObjInfo" in payload:
return "tencent_cm"
# 默认根据显式声明
return payload.get("source", "unknown")
if __name__ == "__main__":
app.run(host="0.0.0.0", port=8080)八、效果数据
上线3周后的统计:
| 指标 | 接入前 | 接入后 | 变化 |
|---|---|---|---|
| 值班需要盯的群/渠道数 | 3个 | 1个 | -67% |
| 日均告警条数(原始) | 340条 | 340条(不变) | - |
| 日均事件数(去重后) | - | 78条 | 去重率77% |
| 跨源关联成功率 | 0%(无法关联) | 65% | - |
| 重复问题平均定位时间 | 20分钟 | 3分钟 | -85% |
| 告警遗漏(无人响应) | 周均4次 | 周均0次 | 100%消除 |
最明显的改善:核心交换机Down之后,Zabbix/Prometheus/云监控同时报警,事件总线5秒内把3条告警关联成1个事件,值班人看到的是"交换机故障(3条关联告警)"而不是3条分散的消息。
九、3个踩坑记录
坑1:Zabbix Webhook调用超时
Zabbix的Webhook有10秒超时限制(不可配置)。如果事件总线处理慢导致响应超10秒,Zabbix会判定为失败并重试------导致重复告警。
解决:事件总线接收到Webhook后立即返回200(异步处理),不要同步做去重/关联/通知。
python
# 改为异步处理
from concurrent.futures import ThreadPoolExecutor
executor = ThreadPoolExecutor(max_workers=10)
@app.route("/api/v1/alerts/ingest", methods=["POST"])
def ingest_alert():
payload = request.get_json(force=True)
# 立即返回,异步处理
executor.submit(process_event, payload)
return jsonify({"status": "accepted"}), 200坑2:Prometheus恢复通知和Zabbix恢复通知时间差
同一故障恢复时,Prometheus和Zabbix的恢复检测时间可能差1-2分钟(评估周期不同)。导致事件总线先收到Prometheus的resolved,但Zabbix的还在firing------事件状态反复横跳。
解决:恢复判定规则改为"所有关联告警源都发送了resolved才标记事件恢复",或者设置2分钟恢复延迟窗口。
坑3:资产映射表数据不全导致关联失败
上线第一周跨源关联率只有30%------因为asset_mapping表只录了核心服务器,大量开发/测试环境没录入。
解决:写了一个定时脚本,从Zabbix API拉主机列表、从Prometheus targets拉实例列表、从云控制台API拉实例信息,自动填充asset_mapping表。
十、小结
多监控工具并存是现实,"全部换成一套"不现实。关键是在告警出口统一收口:
- 每个告警源只负责发Webhook------保持各工具原有能力不动
- 事件总线负责归一化------4种格式转1种,后续逻辑只面对一种数据结构
- 去重+关联是核心价值------340条→78条,3条分散告警→1个关联事件
- 资产映射表是跨源关联的前提------hostname/IP/cloud_id必须能对应起来
我们在冠服云EMS平台里做的事件中心就是这个架构------Zabbix/Prometheus/N9e/云监控都可以通过Webhook接入,平台内部做归一化、去重、关联、分级,然后统一派单和通知。如果你不想自己搭这套事件总线(上面的代码看着简单但生产化还有很多细节:高可用、消息队列缓冲、告警风暴限流等),直接用一个成熟的事件中心平台会省很多事。
不管用什么方案,核心逻辑就一条:告警从多个源头出来,必须进同一个入口做处理,不能让值班人肉当"人形事件总线"。