基于 Transformer 架构的翻译模型实践 - 主流分词器(Tokenizer)的对比
flyfish
参考
bash
https://github.com/shaoshengsong/ pytorch -transformer-en-zh-translation-demo对hello不同的分词方案
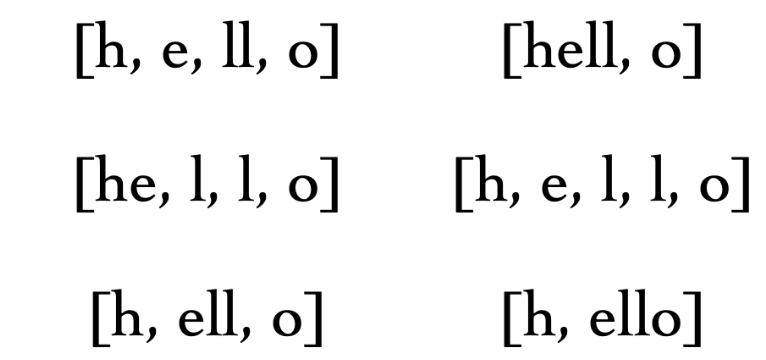
可以分为单个字符【h,e,l,l,o】, 也可以类似【hell,o】
分词算法比较
上图来源是ByteByteGo
| 颜色 | 类型 | 说明 |
|---|---|---|
| 青色 | 完整单词(Complete Words) | 保留原词,不拆分 |
| 橙色 | 子词(Subwords) | 拆分后的词片段(非词缀) |
| 绿色 | 前缀(Prefixes) | 词的开头部分(如un-、pre-) |
| 紫色 | 字符(Characters) | 单个字符/数字(如1、e) |
| 粉色 | 特殊Token(Special Tokens) | 词首标记(如SentencePiece的▁)、特殊符号 |
| 米黄色 | 空格(Spaces) | 文本中的空格(如BPE会单独处理) |
| 蓝色 | 表情符号(Emojis) | 单个emoji作为独立token |
| 黄色 | 标点符号(Punctuation) | 标点(如-) |
1. BPE(Byte Pair Encoding,字节对编码)
从单个字符开始,不断合并语料中出现频率最高的相邻符号,生成子词。
不区分词首/词中,直接合并高频序列;空格可单独作为token处理。
示例:
unhappy → un(前缀) + happy(子词) → 2个token
Hello world → Hello(完整词) + (空格) + world(完整词) → 3个token
learning123 → learn + ing + 1 + 2 + 3 → 5个token
2. WordPiece(Google的方法,BERT等模型使用)
与BPE类似,但优先保留词首,用##标记非词首的子词 (表示"前面还有内容",避免歧义)。
通过##明确区分词首和词中;空格通常不单独作为token(会被隐式合并到词中)。
示例:
unhappy → un(词首前缀) + ##happy(词中子词) → 2个token
Hello world → Hello + world(空格被隐式处理,不单独分词) → 2个token
pre-trained → pre + ##- + ##train + ##ed → 4个token(##-表示标点是前面内容的延续)
3. SentencePiece(语言无关,LLaMA、T5等模型使用)
直接对**整个文本(包括空格)**进行分词,用▁(下划线)表示词首的空格,实现"语言无关"(无需提前做空格/分词预处理,适配中文、日文等无空格语言)。
把空格作为token的一部分(用▁标记),无需依赖空格分词;子词拆分更灵活。
示例:
unhappy → ▁(词首空格标记) + un + happy → 3个token
Hello world → ▁Hello + ▁world(每个词前加▁,空格被替换为▁) → 2个token
Emojis
🧠🤖 → ▁ + 🧠 + 🤖 → 3个token(开头的空格被标记为▁)
4. Unigram(概率方法,XLNet、ALBERT等模型使用)
基于概率模型,保留语料中概率最高的子词组合 (从大词表开始删减,保留最优token)。
倾向于保留更"合理"的长片段(高频词可能直接作为完整token);同样用▁处理空格(和SentencePiece类似)。
示例:
unhappy → 直接作为完整词(概率最高) → 1个token
learning123 → ▁ + learning(完整词) + 123(合并的数字片段) → 3个token
pre-trained → ▁ + pre + - + trained(trained作为完整词) → 4个token