一、消息
1.1 消息结构
LLM 消息结构
在大模型使用过程中,我们通常会提到一个词------提示词。提示词又分为系统提示、用户提示词等,这些都会以消息的形式发送给大模型。在 OpenAI 等主流大模型中,常见的消息结构如下:
python
{
"role": "user",
"content": "Hello, how are you?",
},
{
"role": "assistant",
"content": "I'm doing well, thank you for asking.",
},
{
"role": "user",
"content": "Can you tell me a joke?",
}role:消息身份(角色)content:消息内容
以 OpenAI Chat API 为例,常见角色如下:
system:系统角色,用于控制模型行为user:用户角色,表示用户输入assistant:AI 助手角色,表示模型回复tool:工具角色,表示工具调用结果
不同模型可能有不同的消息角色与消息组织形式,但相同点是:这些消息最终都会被打包传递给大模型。
在 LangChain 中,为实现跨模型兼容,将这些模型消息进行了封装统一,极大地方便了模型切换与消息组织。
LangChain 中的消息类型:
| 消息类型 | 对应角色 | 描述 |
|---|---|---|
| SystemMessage | system | 用于设定模型行为、规则、人设与上下文 |
| HumanMessage | user | 用户输入内容 |
| AIMessage | assistant | 模型返回的普通响应 |
| AIMessageChunk | assistant(流式) | 用于流式输出,每次返回一个文本片段 |
| ToolMessage | tool | 工具调用结果 |
LangChain 抽象 Message 的核心目的,是屏蔽不同模型 API 之间的差异。开发者只需面向统一接口编程,无需关心底层模型协议的细节。
例如:
python
from langchain_core.messages import HumanMessage, SystemMessage
messages = [
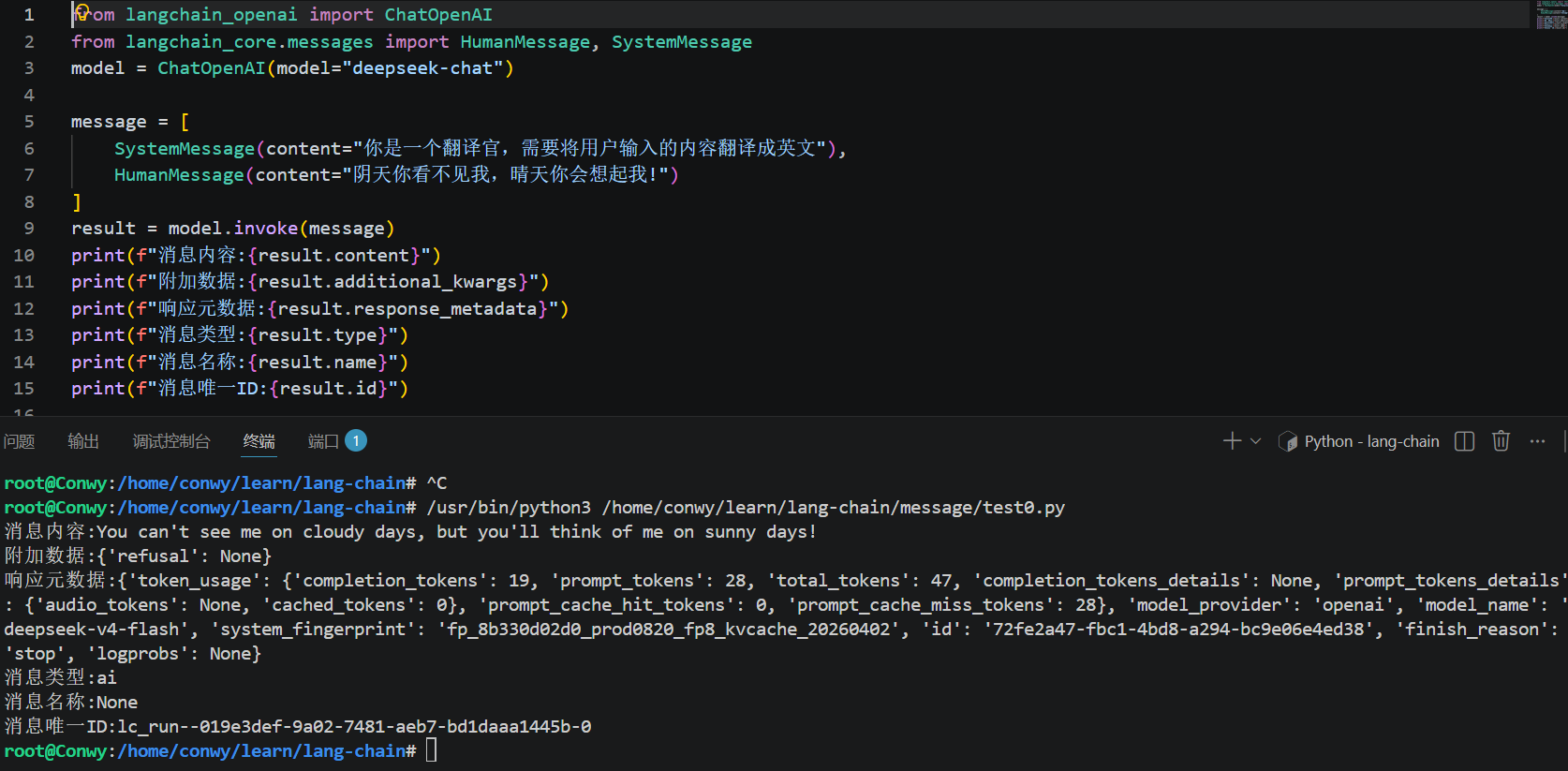
SystemMessage(content="你是一个翻译官,把用户输入的信息翻译成地道的英语"),
HumanMessage(content="阴天你看不见我,天晴你会想起我!"),
]这样就能实现:跨模型切换、Prompt 标准化、Agent 统一通信、Tool Calling 兼容。
在 LangChain 中,所有 Message 类型最终都继承自 BaseMessage 抽象消息类:
python
langchain_core.messages.base.BaseMessage它是 LangChain 聊天模型输入与输出的统一抽象,参数如下:
| 参数 | 说明 |
|---|---|
content |
消息内容 |
additional_kwargs |
附加数据,例如工具调用信息 |
response_metadata |
响应元数据(token 用量、模型信息等) |
type |
消息类型 |
name |
消息名称(可选) |
id |
消息唯一 ID |
这些数据通常用于成本统计、日志分析、性能监控与 Debug 调试。
验证:
内置方法:
格式化打印 Message:
python
msg.pretty_print()返回格式化字符串:
python
msg.pretty_repr()支持 HTML 输出:
python
msg.pretty_repr(html=True)获取纯文本内容:
python
msg.text()Message 类型的本质
Message 的本质是 LLM 的上下文载体,不同 Message 负责不同功能:
system:控制模型行为与人设human:提供用户输入assistant:保存历史回复tool:保存工具调用结果
在现代 Agent 系统中,Message 已经不只是聊天记录,而是 AI 系统的数据总线。并且 Message 不一定只有文本,现代模型已逐渐支持图片、音频、视频等多模态内容。
例如:
python
HumanMessage(
content=[
{"type": "text", "text": "这张图是什么?"},
{"type": "image_url", "image_url": "..."}
]
)因此:Message 本质上是一种多模态上下文协议。
1.2 消息缓存
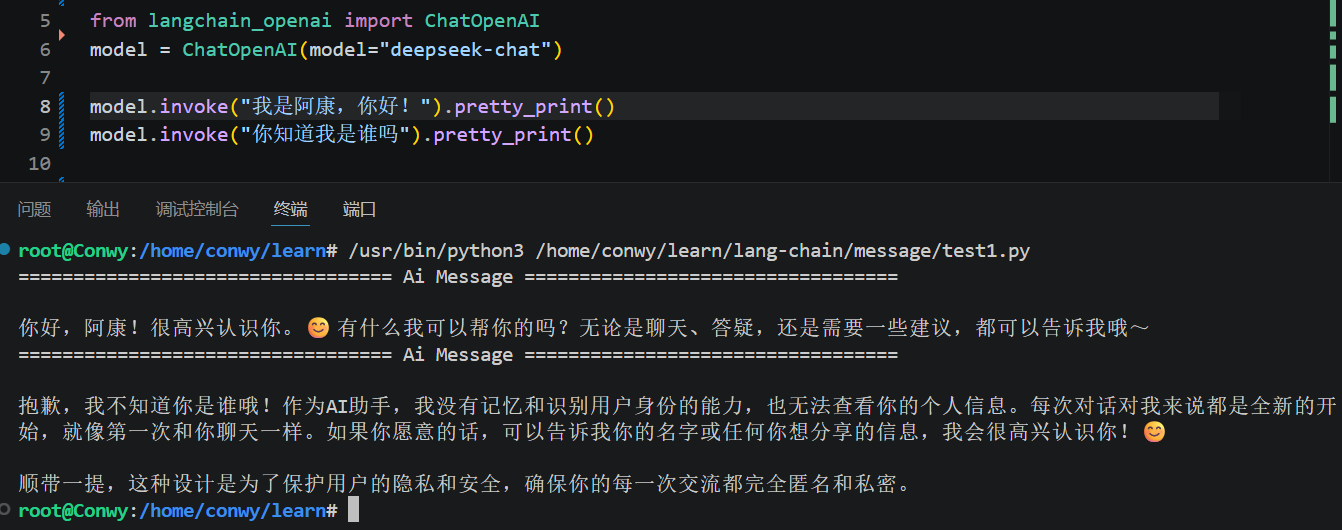
原生大模型本身是无状态的,不支持多轮对话,也就是说它没有记忆功能------上一秒的对话,转头就忘。
演示:
内存缓存
解决方案其实也很简单粗暴:把历史聊天记录一并传给大模型,这些历史消息就是"上下文"。在 LangChain 中,推荐使用 InMemoryChatMessageHistory 管理对话历史,配合 RunnableWithMessageHistory 将其与链绑定,实现自动维护上下文的多轮对话。
python
from langchain_core.chat_history import InMemoryChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
# 用字典按 session_id 管理多个会话
store = {}
def get_session_history(session_id: str):
if session_id not in store:
store[session_id] = InMemoryChatMessageHistory()
return store[session_id]
# 将历史管理绑定到链
with_history = RunnableWithMessageHistory(
model,
get_session_history,
input_messages_key="input",
history_messages_key="history",
)
# 使用 session_id 区分不同对话
config = {"configurable": {"session_id": "user_001"}}
with_history.invoke({"input": "我叫小明"}, config=config)
with_history.invoke({"input": "你还记得我叫什么吗?"}, config=config) InMemoryChatMessageHistory 将历史记录存储在内存中,程序重启后数据即丢失,适用于短期会话场景。若需要持久化存储,可将其替换为基于 Redis、数据库等后端实现的历史存储类。
注意:在 LangChain 新版本中,
RunnableWithMessageHistory已被更轻量的langgraph状态管理方案逐渐替代,但两者思路一致,理解核心原理即可切换。
1.3 消息管理
相关概念
大模型能处理的内容是有限的,每个模型的上下文窗口大小是固定的。有些历史消息至关重要,而有些则是无关紧要的废话。因此,对历史消息进行有效管理显得尤为重要。
上下文窗口的大小以 token 度量。一个 token 约等于 4 个英文字母,或 1 到 2 个汉字。可以用一个形象的比喻理解:
把上下文窗口想象成一个固定大小的工作台,Token 是积木零件,大模型是工匠。工匠要拼出模型,必须把所需零件(输入 Token)放在工作台上,一边拼装(生成回复),一边把拼好的部分(输出 Token)也放在台上。整个过程(输入 + 输出)的所有 Token 总数,都不能超过工作台的最大容量(上下文窗口大小)。

如果输入的零件太多,占满了工作台,工匠就没有空间进行拼装了,这时就需要精简输入(裁剪消息)。
近期主流模型的上下文窗口参考:
- Claude Opus 4.7: 标准上下文 200K,1M 处于 Beta 阶段
- GPT-5.5: API 支持 1M token,标准窗口 256K,超出后按 2 倍价格计费
- DeepSeek V4: V4 Pro(1.6T 参数,49B 激活)和 V4 Flash(284B 参数)均原生支持 1M token
消息裁剪
在 LangChain 中,可以通过 trim_messages 对历史消息进行裁剪,剔除不重要的对话,优先保留关键上下文。
示例:
python
from langchain_core.messages import trim_messages
# 历史消息记录
messages = [
SystemMessage(content="你是一个万能的小助手"),
HumanMessage(content="我是阿康"),
AIMessage(content="你好,我是你的小助手"),
HumanMessage(content="I like vanilla ice cream"),
AIMessage(content="nice"),
HumanMessage(content="whats 2 + 2"),
AIMessage(content="4"),
HumanMessage(content="thanks"),
AIMessage(content="no problem!"),
HumanMessage(content="having fun?"),
AIMessage(content="yes!"),
HumanMessage(content="What's my name?"),
]
trimmer = trim_messages(
max_tokens=11, # 裁剪后保留的最大 token 数(此处等价于消息数)
strategy="last", # 裁剪策略:"last" 保留最新消息,"first" 保留最早消息
token_counter=len, # 传入 len 函数时,max_tokens 代表最大消息条数
include_system=True, # 始终保留系统消息
allow_partial=False, # 不允许拆分单条消息
start_on="human", # 确保裁剪后第一条非系统消息是 human 类型
)
chain = trimmer | model
print(chain.invoke(messages))参数说明:
| 参数 | 说明 |
|---|---|
max_tokens |
保留消息的最大 token 数(或消息条数,取决于 token_counter) |
strategy |
"last":保留最新消息;"first":保留最早消息 |
token_counter |
传入模型:按模型规则计算 token;传入 len:按消息条数计算 |
include_system |
是否始终保留初始系统消息 |
allow_partial |
是否允许拆分单条消息内容 |
start_on |
裁剪后第一条非系统消息的类型(如 "human") |
裁剪流程:
messages
↓
token_counter 计算当前 token 数
↓
是否超过 max_tokens?
├── 是 → 按裁剪策略删减消息
└── 否 → 原样返回将
token_counter=len时,max_tokens代表的是最大消息条数 而非 token 数。例如max_tokens=11表示最多保留 11 条消息。
消息过滤
在更复杂的场景下,我们可能只想将完整消息列表中的某个子集传递给模型,而非全部历史记录。filter_messages 方法支持按类型、ID 或名称灵活过滤消息。
示例:
python
from langchain_core.messages import filter_messages
messages = [
SystemMessage("你是一个聊天助手", id="1"),
HumanMessage("示例输入", id="2"),
AIMessage("示例输出", id="3"),
HumanMessage("真实输入", id="4"),
AIMessage("真实输出", id="5"),
]
# 按类型筛选:只保留 HumanMessage
print(filter_messages(messages, include_types="human"))
# 按 ID 排除:排除 id="3" 的消息
print(filter_messages(messages, exclude_ids=["3"]))
# 组合筛选:排除 id="3",同时只保留 HumanMessage 和 AIMessage
print(filter_messages(messages, exclude_ids=["3"], include_types=[HumanMessage, AIMessage]))消息合并
某些模型不支持传递连续同类型 的消息(例如连续两条 HumanMessage)。merge_message_runs 方法可以自动将相邻的同类型消息合并为一条,避免触发模型报错。
示例:
python
from langchain_core.messages import merge_message_runs
messages = [
SystemMessage("你是一个聊天助手。"),
SystemMessage("你总是以笑话回应。"), # 与上一条同为 SystemMessage
HumanMessage("为什么要使用 LangChain?"),
HumanMessage("为什么要使用 LangGraph?"), # 与上一条同为 HumanMessage
AIMessage("因为当你试图让代码更有条理时,LangGraph 会让你感到"节点"是个好主意!"),
AIMessage("不过别担心,它不会"分散"你的注意力!"),
HumanMessage("选择 LangChain 还是 LangGraph?"),
]
# 方式一:直接合并后调用
merged_messages = merge_message_runs(messages)
model.invoke(merged_messages).pretty_print()
# 方式二:组成链,自动合并后传入模型
chain = merge_message_runs() | model
chain.invoke(messages).pretty_print()合并后,两条连续的 SystemMessage 会被拼接为一条,HumanMessage 同理,保证消息结构合法。
二、提示词模版
2.1 概念
当提示词很长、重复度很高、处理同一类任务时,手动拼接字符串既繁琐又容易出错。提示词模板正是为解决这一问题而生的。
提示词模板的核心价值:
- 可复用性:定义一次模板,可用于无数个同类查询,无需重复编写。
- 关注点分离:将提示词的结构与具体数据分离开------提示工程师专注优化模板,应用程序只负责填充变量值。
- 一致性:确保发送给 LLM 的提示词结构统一,有助于获得更稳定、可预期的输出结果。
- 可维护性:需要修改提示词风格时,只需改一个模板文件,而无需在代码中的无数处进行修改。
LangChain 提供了 PromptTemplate 类实现上述功能。PromptTemplate 实现了标准的 Runnable 接口,可以无缝接入链式调用。
示例:
python
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate
model = ChatOpenAI(model="deepseek-chat")
# 方式一:显式声明变量
prompt_template = PromptTemplate(
template="介绍一下{film_name}这部电影",
input_variables=["film_name"],
)
# 方式二:从模板字符串自动推断变量
prompt_template2 = PromptTemplate.from_template("将文本从{language_from}翻译为{language_to}")
# 链式调用:模板填充 → 模型推理
model.invoke(prompt_template.invoke({"film_name": "霸王别姬"})).pretty_print()
# 仅实例化,不调用模型
print(prompt_template2.invoke({"language_from": "英文", "language_to": "中文"}))聊天消息中的模板
在多轮对话场景中,使用 ChatPromptTemplate 可以同时为 system、user、assistant 等多个角色定义模板:
python
chat_prompt_template = ChatPromptTemplate(
[
("system", "将文本从{language_from}翻译为{language_to}"),
("user", "{text}"),
]
)
# 实例化模板(生成消息列表,不调用模型)
messages = chat_prompt_template.invoke(
{
"language_from": "英文",
"language_to": "中文",
"text": "hi, what is your name?",
}
)
# 组成链后调用
chain = chat_prompt_template | model
chain.invoke(
{
"language_from": "英文",
"language_to": "中文",
"text": "hi, what is your age?",
}
).pretty_print()消息占位符
当需要在模板中动态插入一段历史消息列表 时(例如多轮对话的上下文),可以使用 MessagesPlaceholder:
python
from langchain_core.prompts import MessagesPlaceholder
chat_prompt_template = ChatPromptTemplate(
[
("system", "将文本从{language_from}翻译为{language_to}"),
MessagesPlaceholder("msgs"), # 在此处插入历史消息列表
("user", "{text}"),
]
)
messages_placeholder = [
HumanMessage(content="hi, what is your name?"),
AIMessage(content="你好,你叫什么名字?"),
]
chain = chat_prompt_template | model
chain.invoke(
{
"language_from": "英文",
"language_to": "中文",
"text": "hi, what is your age?",
"msgs": messages_placeholder,
}
).pretty_print()LangChain Hub
LangChain Hub 是 LangChain 提供的提示词社区共享平台,开发者可以在上面发布、复用和版本管理提示词模板。通过 Hub,你可以直接拉取社区中经过验证的高质量 Prompt,无需从零编写。
python
from langchain import hub
# 从 Hub 拉取公开 Prompt(格式为 owner/prompt-name)
prompt = hub.pull("rlm/rag-prompt")
print(prompt)使用场景:
- 快速复用 RAG、Agent、Chain-of-Thought 等成熟 Prompt 模板
- 团队内部版本化管理 Prompt,避免散落在代码各处
- 发布自己的模板供社区使用
三、少样本提示与示例选择
3.1 概念
少样本提示(Few-Shot Prompting),是指在提示词中提供少量输入-输出示例,让大模型通过"找规律"的方式理解你的意图,从而输出符合预期格式或风格的结果。
例如,给大模型如下示例:
input:1🕊5,output:6
input:3🕊6,output:9
input:8🕊7,output:15大模型会推断出 🕊 等价于加法,若输入 4🕊6,则输出 10。
少样本提示能解决什么问题?
LLM 虽然知识渊博,但有时我们需要它以非常特定的格式、风格或逻辑回答问题。提供合适的示例可以:
- 格式约束:强制模型以特定格式(如 JSON、XML、特定列表样式)输出结果,示例充当格式样板。
- 风格引导:有些任务很难用文字描述清楚(例如"用莎士比亚风格写作"),几个示例胜过千言万语。
- 推理路径引导:对于复杂的多步推理任务,示例可以展示思考链,引导模型遵循类似的推理路径。
当示例库很大时,不应将所有示例全部传给模型(会消耗大量 token),而是应该根据当前输入,动态选择最合适的若干条示例。LangChain 提供了以下几种示例选择器。
3.2 按长度选择
LengthBasedExampleSelector 根据已格式化示例的总字数来控制选择数量,确保生成的提示词不超过长度限制。
python
from langchain_core.example_selectors import LengthBasedExampleSelector
from langchain_core.prompts import PromptTemplate
# 反义词示例集合
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic","output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
# 单条示例的格式模板
example_prompt = PromptTemplate.from_template("Input: {input}\nOutput: {output}")
# 按长度选择示例
example_selector = LengthBasedExampleSelector(
examples=examples,
example_prompt=example_prompt,
max_length=25, # 格式化示例的最大"词数"(以空格或换行分隔计算)
)适用场景:对 token 消耗敏感,需要动态控制 Prompt 总长度时。
3.3 按语义选择
语义相似性衡量的是文本在含义上的近似程度,而非字面匹配。例如:
- "我喜欢猫"
- "他讨厌狗"
从字面看毫无关联,但语义上都是表达对动物的态度,因此语义相似度较高。
SemanticSimilarityExampleSelector 通过向量嵌入(Embedding)计算输入与示例之间的语义距离,选出最相关的 k 条示例:
python
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples, # 示例集
OpenAIEmbeddings(model="text-embedding-3-large"), # 嵌入模型,用于度量语义距离
Chroma, # 向量数据库,存储示例向量
k=2, # 选取最相似的 k 条示例
)注意:语义选择依赖嵌入模型,需要配置对应的 Embedding API。
3.4 按最大边际相关性选择(MMR)
最大边际相关性(Max Marginal Relevance, MMR)是一种重排序算法,在语义相似性的基础上,进一步保证所选示例之间的多样性,避免所有示例都"长得一样"。
用一个比喻理解两者的区别:
- 语义相似性:像面试官给每位候选人单独打分,只考虑"与职位的匹配度"。
- MMR:像团队经理组建团队,既要选出与需求相关的成员,又要确保团队成员技能互补、各有特色。
| 方法 | 核心目标 | 适用场景 |
|---|---|---|
| 语义相似性 | 找最相关的 k 条示例 | 语义搜索、重复检测、聚类 |
| MMR | 找既相关又多样的 k 条示例 | 推荐系统、文档摘要、RAG 去重 |
MMR 在 RAG 场景中尤为有用:从知识库检索出大量相关文档后,通过 MMR 去重与多样化筛选,能有效提升最终答案质量、减少幻觉。
python
from langchain_core.example_selectors import MaxMarginalRelevanceExampleSelector
example_selector = MaxMarginalRelevanceExampleSelector.from_examples(
examples, # 示例集
OpenAIEmbeddings(model="text-embedding-3-large"), # 嵌入模型
Chroma, # 向量数据库
k=5, # 选取 k 条多样化示例
)3.5 按 N-Gram 重叠选择
什么是 N-Gram?
N-Gram 是文本序列中连续 n 个词或字符的组合。例如对于句子"苹果手机很好用",其 2-gram 为:"苹果手机", "手机很", "很好用"。
什么是 N-Gram 重叠?
通过统计两段文本之间共同拥有的 N-Gram 数量来衡量相似度。例如:
text1 = "苹果手机很好用" → 分词后:[苹果, 手机, 很, 好用]
text2 = "这款手机很好用" → 分词后:[这款, 手机, 很, 好用]两者共享了"手机、很、好用",N-Gram 重叠度较高。但再看:
text1 = "苹果手机很好用"
text2 = "iPhone 非常不错"两者含义相近,但 N-Gram 重叠度为 0。这正是传统 N-Gram 的局限------只能做字面匹配,无法处理同义词。
语义 N-Gram 重叠
在此基础上引入语义向量(Embedding),不再比较词的字面是否相同,而是比较词在语义空间中的向量是否相近。只要相似度超过设定阈值,即认为发生了"重叠"。这在剽窃检测等场景中特别有效,能识别出"改头换面但保留核心思想"的内容。
python
from langchain_community.example_selectors import NGramOverlapExampleSelector
examples = [
{"input": "See Spot run.", "output": "看见 Spot 跑。"},
{"input": "My dog barks.", "output": "我的狗叫。"},
{"input": "Spot can run.", "output": "Spot 可以跑。"},
]
example_selector = NGramOverlapExampleSelector(
examples=examples,
example_prompt=example_prompt,
threshold=0.0, # 阈值控制:
# < 0:连不相关示例也会被选中
# = 0:只选与输入有重叠的示例
# ≥ 1:排除全部示例,返回空列表
)四、输出解析器
4.1 概念
大模型的原始输出是纯文本字符串。在实际应用中,我们往往需要将其解析为特定格式(JSON 对象、Python 数据类、列表等)才能进一步使用。**输出解析器(Output Parser)**负责完成这一转换工作。
与 with_structured_output 的区别
这两者经常被混淆,本质区别在于作用层面不同:
| 维度 | 输出解析器(Output Parser) | with_structured_output |
|---|---|---|
| 作用层面 | 链(Chain)层面,对模型输出的文本进行后处理 | 模型(Model)层面,通过 Function Calling 或 JSON Mode 强制结构化 |
| 依赖 | 不依赖模型特性,任何模型均可使用 | 依赖模型对结构化输出的原生支持 |
| 稳定性 | 模型输出格式不稳定时可能解析失败 | 由模型保证格式,稳定性更高 |
| 适用场景 | 模型不支持结构化输出,或需要自定义解析逻辑 | 模型支持 Function Calling(推荐优先使用) |
经验之谈 :如果你使用的模型支持 Function Calling(如 GPT-4、DeepSeek),优先使用
with_structured_output;若模型能力有限,则退而求其次使用输出解析器。
4.2 解析文本输出
StrOutputParser 是最简单的解析器,将模型输出的 AIMessage 对象转换为纯字符串,方便后续处理或直接展示。
python
from langchain_core.output_parsers import StrOutputParser
chain = prompt_template | model | StrOutputParser()
result = chain.invoke({"film_name": "霸王别姬"})
print(result) # 直接得到字符串,无需 .content
print(type(result)) # <class 'str'> 除此之外,CommaSeparatedListOutputParser 可将模型输出的逗号分隔文本直接解析为 Python 列表:
python
from langchain.output_parsers import CommaSeparatedListOutputParser
parser = CommaSeparatedListOutputParser()
# 自动生成格式指令,告诉模型该如何输出
format_instructions = parser.get_format_instructions()
# "Your response should be a list of comma separated values, eg: `foo, bar, baz`"
prompt = PromptTemplate(
template="列出五种{subject}。\n{format_instructions}",
input_variables=["subject"],
partial_variables={"format_instructions": format_instructions},
)
chain = prompt | model | parser
result = chain.invoke({"subject": "冰淇淋口味"})
print(result) # ['草莓', '巧克力', '抹茶', '香草', '芒果']4.3 解析结构化对象输出
在需要从模型输出中提取结构化数据时,LangChain 提供了两种主要方式:JsonOutputParser 和 PydanticOutputParser。
JsonOutputParser
JsonOutputParser 将模型输出的 JSON 字符串解析为 Python 字典,并支持通过 Pydantic 模型定义期望的 JSON Schema,自动生成格式指令:
python
from langchain_core.output_parsers import JsonOutputParser
from pydantic import BaseModel, Field
# 定义期望的数据结构
class Movie(BaseModel):
name: str = Field(description="电影名称")
director: str = Field(description="导演姓名")
year: int = Field(description="上映年份")
rating: float = Field(description="豆瓣评分")
parser = JsonOutputParser(pydantic_object=Movie)
prompt = PromptTemplate(
template="介绍一下电影《{film_name}》。\n{format_instructions}",
input_variables=["film_name"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
chain = prompt | model | parser
result = chain.invoke({"film_name": "霸王别姬"})
print(result)
# {'name': '霸王别姬', 'director': '陈凯歌', 'year': 1993, 'rating': 9.6}PydanticOutputParser
PydanticOutputParser 在 JsonOutputParser 的基础上更进一步,直接将输出解析为 Pydantic 模型实例,提供字段类型验证和自动纠错能力:
python
from langchain.output_parsers import PydanticOutputParser
parser = PydanticOutputParser(pydantic_object=Movie)
prompt = PromptTemplate(
template="介绍一下电影《{film_name}》。\n{format_instructions}",
input_variables=["film_name"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
chain = prompt | model | parser
result = chain.invoke({"film_name": "霸王别姬"})
print(result) # Movie(name='霸王别姬', director='陈凯歌', year=1993, rating=9.6)
print(result.director) # '陈凯歌'
print(type(result)) # <class '__main__.Movie'>两者对比:
| 解析器 | 输出类型 | 类型校验 | 适用场景 |
|---|---|---|---|
JsonOutputParser |
dict |
否 | 需要灵活操作字典时 |
PydanticOutputParser |
Pydantic 模型实例 | 是(自动校验) | 需要类型安全、字段约束时 |
建议 :当输出结构明确、字段类型重要时,优先使用
PydanticOutputParser,它能在解析阶段就捕获格式错误,而不是让问题流入下游逻辑。
非常感谢您能耐心读完这篇文章。倘若您从中有所收获,还望多多支持呀!🎉