混淆矩阵(也称误差矩阵)是机器学习和深度学习中表示精度评价的一种标准格式,常用n行n列的矩阵形式来表示。其列代表的是预测的类别,行代表的是实际的类标,以一个常见的二分类的混淆矩阵为例。我们会发现二分类的混淆矩阵包括TP, FP, FN, TN,其中TP为True Positive,True代表实际和预测相同,Positive代表预测为正样本。同理可得,False Positive (FP)代表的是实际类别和预测类标不同,并且预测类别为正样本,实际类别为负样本;False Negative (FN)代表的是实际类别和预测类标不同,并且预测类别为负样本,实际类别为正样本;True Negative (TP)代表的是实际类别和预测类标相同,预测类别和实际类别均为负样本。
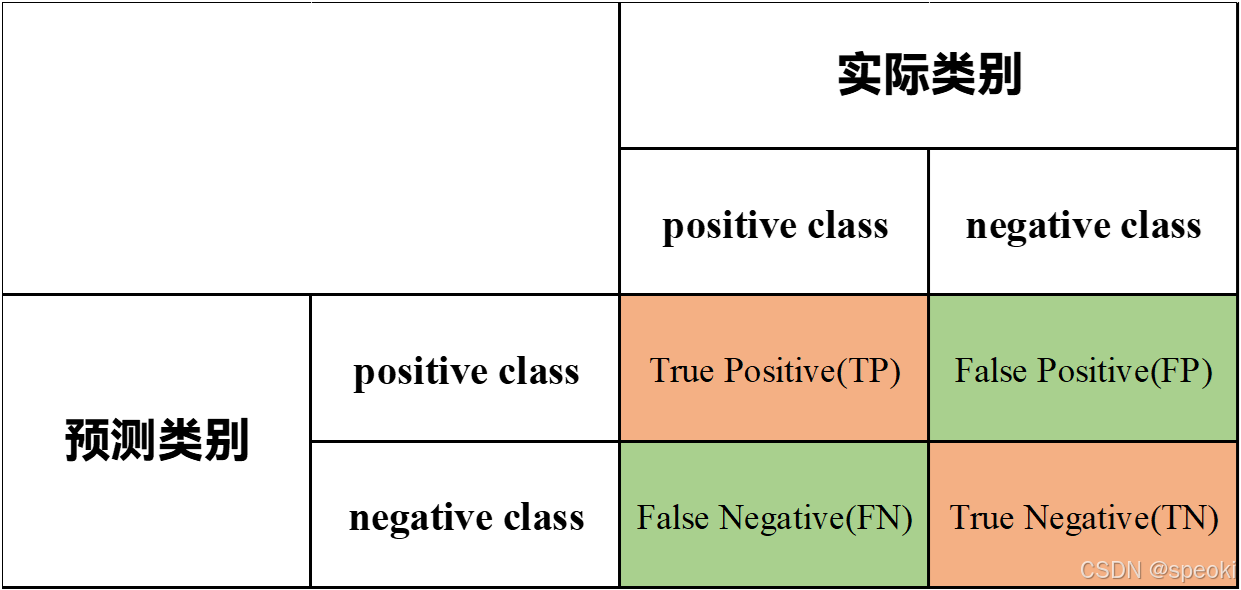
在这里我们以一个二分类的例子来帮助大家理解。假设我们是某核酸检测机构,将对100个人进行核酸检测,实际结果为98个阴性,2个阳性,但是我们的模型对核酸检测结果进行预测,预测结果为94个阴性,6个阳性结果,在这里我们定义核酸结果阴性为正样本,核酸结果阳性为负样本。在这个例子中,TP代表实际为阴性且被预测为阴性的数量,共有94人;FP代表实际为阳性,模型预测为阴性的数量,共有0人;FN代表实际为阴性被模型判断为阳性的数量,共有4人;TN代表实际为阳性,被模型识别为阳性的数量,共有2人。 于是我们就可以得到下面的这个混淆矩阵。
我们在拥有混淆矩阵后,可以计算Accuracy,Precision,Recall,F1 Score等衡量模型的评价指标。关于混淆矩阵的代码实现,我们可以使用sklearn.metrics.confusion_matrix()函数进行计算
python
from sklearn.metrics import confusion_matrix
def compute_confusion_matrix(labels,pred_labels_list,gt_labels_list):
pred_labels_list = np.asarray(pred_labels_list)
gt_labels_list = np.assarray(gt_labels_list)
matrix = confusion_matrix(test_label_list,
pred_label_list,
labels=labels)
return matrixPytorch基础知识
张量

张量是现代机器学习的基础。它的核心是一个数据容器,多数情况下,它包含数字,有时候它也包含字符串,但这种情况比较少。因此可以把它想象成一个数字的水桶。
这里有一些存储在各种类型张量的公用数据集类型:
- 3维 = 时间序列
- 4维 = 图像
- 5维 = 视频
例子:一个图像可以用三个字段表示:
(width, height, channel) = 3D但是,在机器学习工作中,我们经常要处理不止一张图片或一篇文档------我们要处理一个集合。我们可能有10,000张郁金香的图片,这意味着,我们将用到4D张量:
(batch_size, width, height, channel) = 4D在PyTorch中, torch.Tensor 是存储和变换数据的主要工具。如果你之前用过NumPy,你会发现 Tensor 和NumPy的多维数组非常类似。然而,Tensor 提供GPU计算和自动求梯度等更多功能,这些使 Tensor 这一数据类型更加适合深度学习。
创建tensor
在接下来的内容中,我们将介绍几种常见的创建tensor的方法。
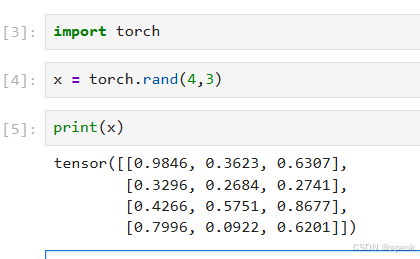
- 随机初始化矩阵 我们可以通过torch.rand()的方法,构造一个随机初始化的矩阵:
- 全0矩阵的构建 我们可以通过torch.zeros() 构造一个矩阵全为0,并且通过dtype 设置数据类型为long。除此之外,我们还可以通过torch.zero_()和torch.zeros_like()将现有矩阵转换为全0矩阵。
张量的构建 我们可以通过torch.tensor()直接使用数据,构造一个张量:
python
import torch
x = torch.tensor([5.5,3])
print(x)基于已经存在的 tensor,创建一个 tensor :

张量的操作
python
import torch
# 方式1
y = torch.rand(4, 3)
print(x + y)
# 方式2
print(torch.add(x, y))
# 方式3 in-place,原值修改
y.add_(x)
print(y)需要注意的是:索引出来的结果与原数据共享内存,修改一个,另一个会跟着修改。如果不想修改,可以考虑使用copy()等方法
autograd
torch.Tensor 是这个包的核心类。如果设置它的属性 .requires_grad 为 True,那么它将会追踪对于该张量的所有操作。当完成计算后可以通过调用 .backward(),来自动计算所有的梯度。这个张量的所有梯度将会自动累加到.grad属性。
注意:在 y.backward() 时,如果 y 是标量,则不需要为 backward() 传入任何参数;否则,需要传入一个与 y 同形的Tensor。
要阻止一个张量被跟踪历史,可以调用.detach()方法将其与计算历史分离,并阻止它未来的计算记录被跟踪。为了防止跟踪历史记录(和使用内存),可以将代码块包装在 with torch.no_grad(): 中。在评估模型时特别有用,因为模型可能具有 requires_grad = True 的可训练的参数,但是我们不需要在此过程中对他们进行梯度计算。
还有一个类对于autograd的实现非常重要:Function 。
Tensor 和 Function 互相连接生成了一个无环图 (acyclic graph),它编码了完整的计算历史。
每个张量都有一个**.grad_fn属性,该属性引用了创建 Tensor 自身的Function(除非这个张量是用户手动创建的,即这个张量的grad_fn是 None )。下面给出的例子中,张量由用户手动创建,因此grad_fn返回结果是None**。
python
a = torch.randn(2, 2) # 缺失情况下默认 requires_grad = False
a = ((a * 3) / (a - 1))
print(a.requires_grad)
a.requires_grad_(True)
print(a.requires_grad)
b = (a * a).sum()
print(b.grad_fn)梯度
现在开始进行反向传播,因为 out 是一个标量,因此out.backward()和 out.backward(torch.tensor(1.)) 等价。
python
out.backward()
# 输出导数 d(out)/dx
python
print(x.grad)