引言:
在第一篇中,我们掌握了 Linux 文件 IO 的系统调用------
open、read、write、close、dup2,也理解了文件描述符fd背后的数据结构struct file和files_struct。现在我们要追问一个更根本的问题:为什么 Linux 要把键盘、显示器、磁盘、管道、套接字这些完全不同的东西,全部抽象成"文件"?这个设计背后的机制是什么?本章将给出答案
4. 理解"一切皆文件"
一、"一切皆文件"的两层含义
第一层:Windows 中是文件的东西,Linux 中也是文件。
普通文本文件、图片、可执行程序、目录------这些在 Windows 中就是"文件"的东西,在 Linux 中同样是文件。
第二层:Windows 中不是文件的东西,Linux 中也抽象成了文件。
进程信息、磁盘分区、显示器、键盘、网卡、管道、套接字------这些在 Windows 中各有各的操作接口,在 Linux 中全部被抽象成了"文件",可以用访问文件的方法来访问它们。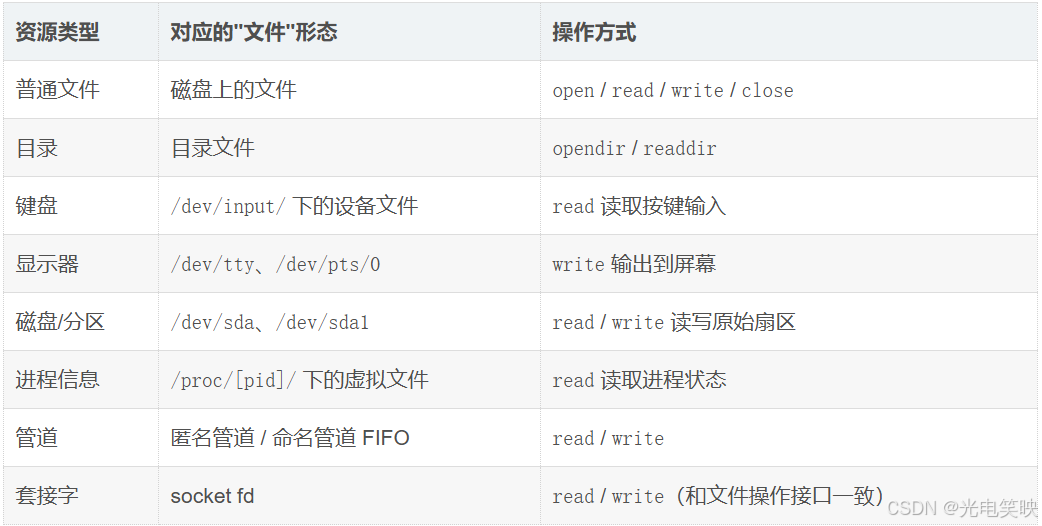
二、这样做的好处:一套 API,操作一切资源
开发者仅需要掌握一套 API,即可调取 Linux 系统中绝大部分的资源。
-
读操作 :无论是读普通文件、读系统状态(
/proc)、读管道、读 socket,都可以用read函数 -
写操作 :无论是写普通文件、修改系统参数、写管道、写 socket,都可以用
write函数 -
打开/关闭 :
open和close适用于所有可被打开的资源
这就是"统一接口"的巨大优势------学习成本极低,代码复用性极高。
三、底层实现机制:struct file + file_operations
"一切皆文件"不是靠嘴实现的,而是靠内核中的两个核心数据结构:
3.1 struct file
之前学过,每当打开一个文件时,内核都会创建一个 struct file 对象来描述这次打开操作的状态(偏移量、打开模式、引用计数等)。这个结构体定义在 <linux/fs.h> 中。
3.2 file_operations ------ 多态的函数指针表
struct file 中有一个关键成员:f_op 指针,它指向一个 file_operations 结构体:
cpp
struct file {
...
struct inode *f_inode; /* cached value */
const struct file_operations *f_op;
...
atomic_long_t f_count; // 表⽰打开⽂件的引⽤计数,如果有多个⽂件指针指向它,就会增加f_count的值。
unsigned int f_flags; // 表⽰打开⽂件的权限
fmode_t f_mode; // 设置对⽂件的访问模式,例如:只读,只写等。所有的标志在头⽂件<fcntl.h> 中定义
loff_t f_pos; // 表⽰当前读写⽂件的位置
...
} __attribute__((aligned(4))); /* lest something weird decides that 2 is OK */struct file {
// ... 其他成员 ...
const struct file_operations *f_op; // ← 指向操作函数集
// ...
};
struct file_operations {
struct module *owner;
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
int (*open) (struct inode *, struct file *);
int (*release) (struct inode *, struct file *);
loff_t (*llseek) (struct file *, loff_t, int);
// ... 还有很多函数指针 ...
};moduleIX/kernel_3.10.0_fs.h · 光电笑映/Linux - 码云 - 开源中国这里是更详细说明的链接
file_operations 中除了 owner 之外,其余成员全部是函数指针。每个函数指针对应一个系统调用:read 系统调用最终会调用 f_op->read,write 系统调用最终会调用 f_op->write。
3.3 不同设备,不同的实现
关键在于:不同的文件类型,其 file_operations 中这些函数指针指向的函数是不同的。

但对用户程序来说,调用接口始终只有 read(fd, buf, size) 和 write(fd, buf, size)。内核会根据 fd 找到 struct file,再通过 f_op 调用对应的函数------这就是面向对象中的"多态"在 C 语言中的经典实现。
四、完整调用链
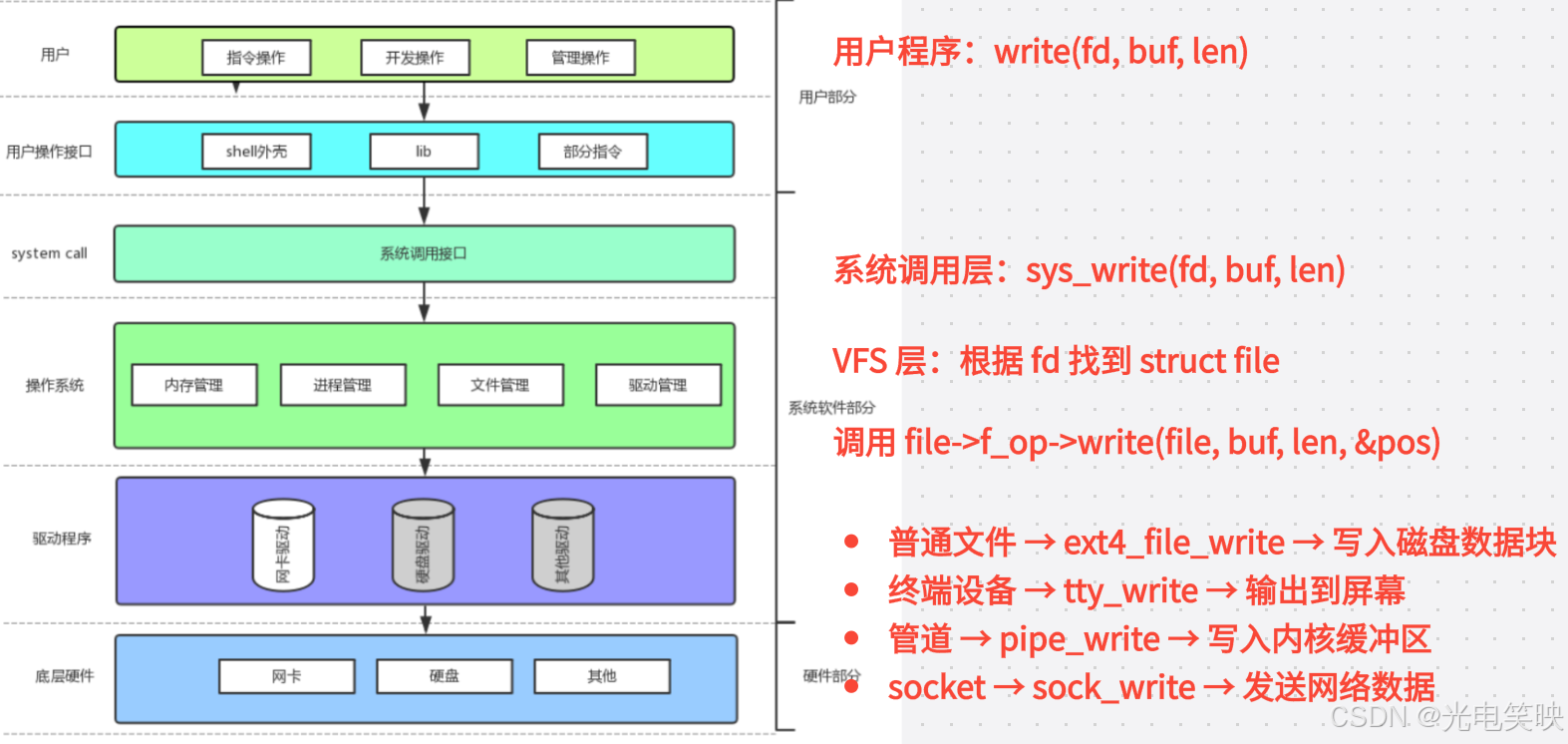
用户只调了一个 write,内核根据文件类型自动分派到不同的底层实现。这就是"一切皆文件"的核心机制。
五、"先描述,再组织"在"一切皆文件"中的体现
六、总结
"一切皆文件"的本质不是把所有东西都存进磁盘,而是用统一的"文件"接口(
open/read/write/close)来操作一切资源。内核通过struct file中的file_operations函数指针表,实现了"同一个接口,不同底层实现"的多态机制------对上提供统一的系统调用,对下分派到不同的设备驱动函数。这就是 Linux 用一套 API 管理所有资源的底层秘密。
5.缓冲区
上一篇 3.6 节提到的 page cache 是内核级缓冲区 ,由 Linux 内核管理。本章重点讨论的是用户级缓冲区,由 C 标准库管理。两层缓冲各司其职:用户级缓冲减少系统调用次数,内核级缓冲减少磁盘 IO 次数。
5.1 什么是缓冲区
缓冲区是内存空间中预留出来的一段存储空间,用来临时存放输入或输出的数据。
它不是磁盘上的区域,而是内存的一部分。数据在从源头到目的地的路上,先在缓冲区里"歇个脚",等时机合适再一次性搬走。
5.2 为什么需要缓冲区
一、没有缓冲区:每次读写都触发系统调用
如果读写文件时不使用缓冲区,每次对文件进行一次读写操作,都需要直接调用系统调用(read/write)来操作磁盘。
一次系统调用的代价:
-
CPU 状态切换:从用户空间切换到内核空间
-
进程上下文切换:保存当前进程状态,加载内核执行环境
-
磁盘 IO 等待:磁盘的寻道和读写是毫秒级的,CPU 只能空等
如果每读写一个字节都走一遍这个流程,程序的大量 CPU 时间将消耗在"切换"和"等待"上,而不是真正的数据处理上。
二、缓冲区的两大核心优势
缓冲区的解决思路:批量搬运
核心思想:一次多搬点,减少搬运次数。 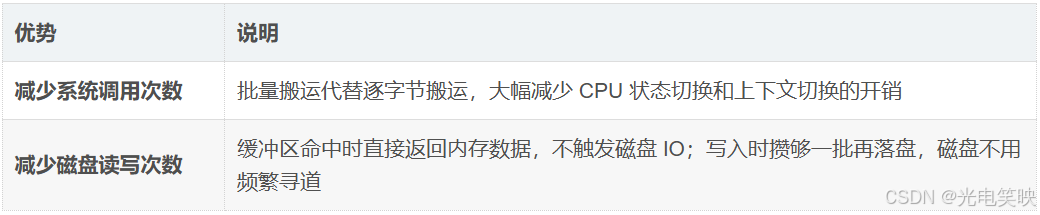
计算机对缓冲区的操作(内存读写)远快于对磁盘的操作,应用缓冲区可大幅提高计算机的运行速度。
C++ 的 allocator 和 C 库的缓冲区是同一个思想在不同领域的不同应用:缓冲区攒数据减少
write次数,allocator 攒内存减少brk/mmap次数。都是"先向 OS 拿一大块,自己管理,按需分发",目的都是减少用户态与内核态的频繁切换。
四、生活类比:打印机
打印机是低速设备,打印速度远慢于 CPU 的处理速度。
- **没有缓冲区:**CPU 把一页文档发给打印机,然后停下来等打印机一页页打完,才能继续处理其他任务。
- **有缓冲区:**CPU 把整份文档一次性发送到打印机的缓冲区中,然后立刻返回处理其他任务。打印机从缓冲区中自行逐步打印,不再占用 CPU。
缓冲区使得低速的输入输出设备和高速的 CPU 能够协调工作,避免低速设备拖累 CPU,解放出 CPU 去处理其他任务。
总结:对于用户级缓冲区通过减少系统调用以提高程序效率,对于内核缓冲区, 对于内核缓冲区,通过减少磁盘 IO 次数以提高系统整体性能。
5.3 缓冲类型
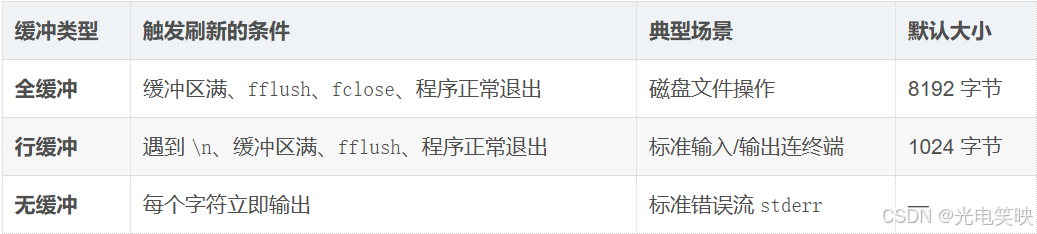
一、标准 I/O 提供的三种缓冲模式
标准 I/O(C 标准库)为 FILE * 流提供了三种缓冲类型,控制数据何时从用户态缓冲区通过系统调用交给内核。
- 全缓冲
填满整个缓冲区后才执行 I/O 系统调用。
-
典型场景:对磁盘文件的操作通常使用全缓冲
-
刷新时机 :缓冲区满、手动
fflush、文件关闭(fclose)、程序正常退出
- 行缓冲
遇到换行符 \n 时,执行 I/O 系统调用。
-
典型场景 :流涉及终端时(例如标准输入
stdin和标准输出stdout连接到终端) -
刷新时机 :遇到
\n、缓冲区满、手动fflush、程序正常退出 -
注意:即使没遇到换行符,只要缓冲区满了,也会触发刷新
- 无缓冲
不对字符进行缓存,直接调用系统调用。系统称为写透模式
-
典型场景 :标准错误流
stderr -
目的:错误信息需要立即显示,不能被缓冲延迟
-
每个字符都立即触发一次
write系统调用
刷新模式在5.4五有详细的例子讲解,这里先引出概念
二、缓冲模式总结表
三、特殊情况也会触发缓冲区的刷新
除了上述默认刷新方式外,以下情况也会引发缓冲区刷新:
-
缓冲区满时
-
执行
fflush语句时 -
调用
fclose关闭文件时 -
程序正常退出(
return或exit)时
四、验证实验:缓冲区刷新时机
cpp
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main()
{
close(1);
int fd = open("log.txt", O_CREAT | O_TRUNC | O_WRONLY, 0664);
// 库函数:写入 C 库缓冲区
printf("hello world\n");
printf("hello world\n");
printf("hello world\n");
// 系统调用:直接写入内核 page cache
const char *msg = "this is write\n";
write(fd, msg, strlen(msg));
// close(fd); // 先注释掉
return 0;
}运行结果(注释 close(fd)):
bash
log.txt 内容:
this is write
hello world
hello world
hello world运行结果(保留 close(fd)):
bash
log.txt 内容:
this is write五、现象分析
为什么保留 close(fd) 后,printf 的三行数据消失了?
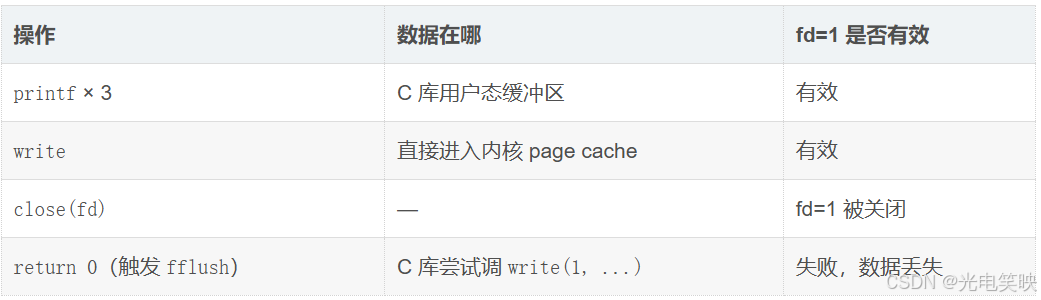
printf/fprintf/fputs 等库函数写入的是 C 库的用户态缓冲区,不是内核缓冲区。 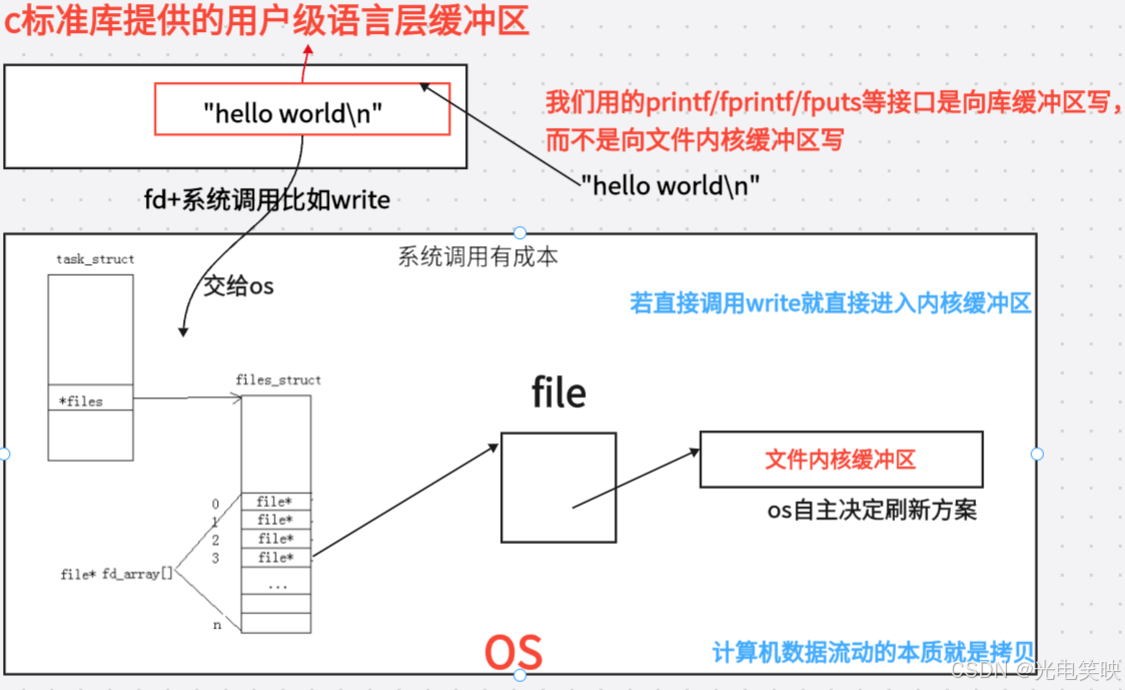
-
既没有手动
fflush -
也不满足行缓冲的刷新条件(stdout 已被重定向到普通文件,变成了全缓冲 ,
\n不再触发刷新) -
close(fd)在return 0之前执行,关闭了 fd=1 的通道 -
程序退出时 C 库尝试
fflush,调用write(1, ...),但 fd=1 已经无效,数据丢失
解决方法:在 close(fd) 之前强制刷新缓冲区。
cpp
fflush(stdout); // 强制将 C 库缓冲区的数据通过 write 交给内核
close(fd);六、缓冲区在哪里?------ FILE 结构体
为什么任何一个被打开的文件都有一个缓冲区?
因为 C 库为每个打开的 FILE * 流在堆上 malloc 了一个 FILE 结构体,这个结构体内部维护了缓冲区及其管理指针。
FILE 结构体中的缓冲区相关字段:
cpp
typedef struct _IO_FILE FILE;
struct _IO_FILE {
int _flags; // 标志位
char *_IO_read_ptr; // 当前读指针
char *_IO_read_end; // 读区域末尾
char *_IO_read_base; // 读区域起始
char *_IO_write_base; // 写区域起始
char *_IO_write_ptr; // 当前写指针
char *_IO_write_end; // 写区域末尾
char *_IO_buf_base; // 缓冲区起始地址 ← 这就是缓冲区!
char *_IO_buf_end; // 缓冲区末尾
int _fileno; // 封装的底层文件描述符 fd
// ... 更多字段
};缓冲区就是 _IO_buf_base 到 _IO_buf_end 之间的这段内存空间。读写指针在这段空间内移动,决定当前读写位置。
fopen 的完整流程:
-
调用
open系统调用,获取 fd -
在堆上
malloc一个FILE结构体 -
在堆上
malloc一块内存作为缓冲区(默认 8192 字节),_IO_buf_base指向它 -
将 fd 存入
_fileno -
根据文件类型设置缓冲模式
-
返回
FILE *指针给用户
5.4 FILE ------ C 库对 fd 的封装
一、核心结论
因为 I/O 相关函数与系统调用接口对应,并且库函数封装系统调用,所以本质上,访问文件都是通过 fd 访问的 。因此 C 库中的 FILE 结构体内部,必定封装了 fd。
_fileno 字段就是 open 返回的那个文件描述符。
二、printf/fwrite 和 write 的本质区别
printf/fwrite 的用户态缓冲区是 C 标准库在系统调用之上"二次加上"的,目的是减少系统调用次数,提高性能。
三、缓冲区不属于内核,属于 C 标准库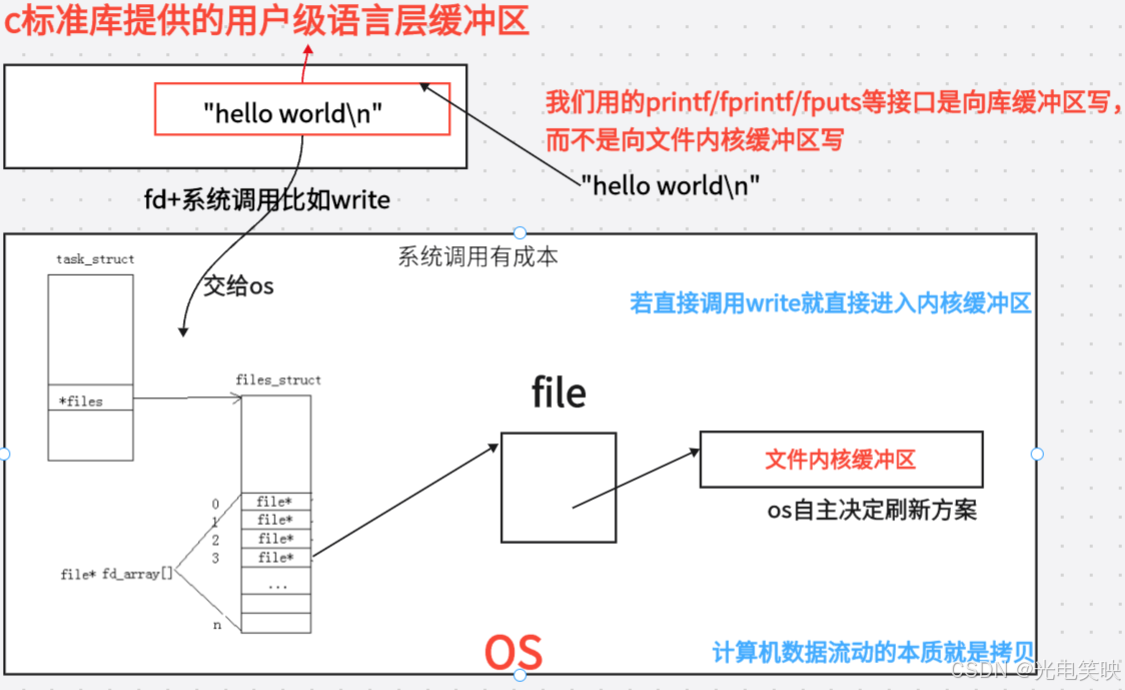
计算机数据流动本质就是拷贝,所以计算机运行效率发展,如更快的 CPU 主频 ,多级缓存(L1/L2/L3) 更快的内存,本质就是增加拷贝效率,所有性能优化,归根结底就两个方向:提高单次拷贝速度,减少不必要拷贝次数。

四、强制将内核缓冲区刷新到文件方法
核心系统调用 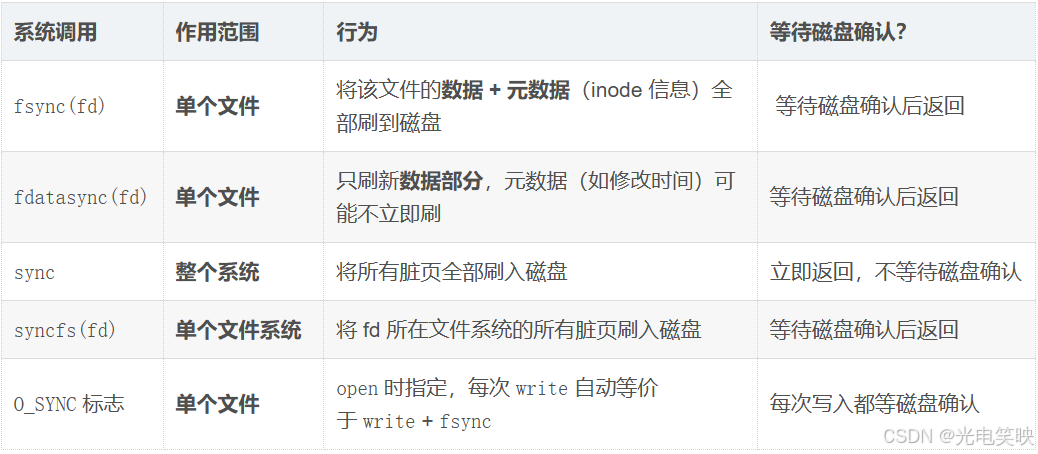
注意: fdatasync 比 fsync 少刷一些 inode 信息,适合只关心数据内容、不关心修改时间的场景。性能也比较高
函数原型
cpp
#include <unistd.h>
int fsync(int fd); // 刷数据 + 元数据
int fdatasync(int fd); // 只刷数据
void sync(void); // 全系统刷盘
int syncfs(int fd); // 刷 fd 所在的文件系统O_SYNC:打开文件时强制每次写入都同步
cpp
int fd = open("file.txt", O_WRONLY | O_CREAT | O_TRUNC | O_SYNC, 0644);
write(fd, buf, len); // 这次 write 等价于 write + fsync,自动等磁盘确认
一般只对数据库的 WAL 日志这类关键文件使用 O_SYNC
fsync(fd)和 fflush 的对比 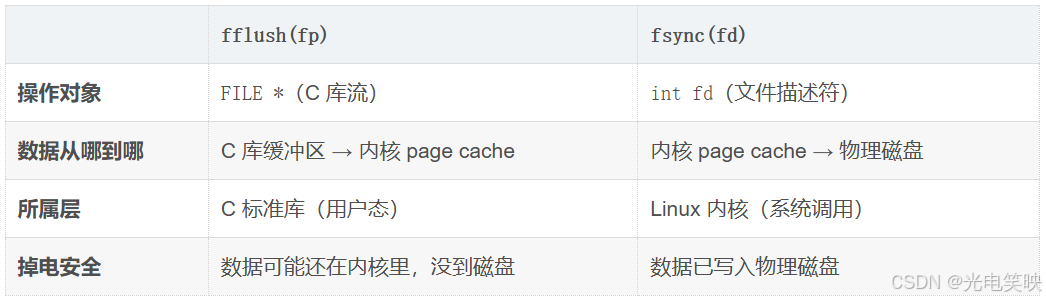
五、完整数据流

六、经典验证实验:fork 复制缓冲区
cpp
int main()
{
const char *msg0="hello printf\n";
const char *msg1="hello fprintf\n";
const char *msg2="hello fwrite\n";
const char *msg3="hello write\n";
//库函数
printf("%s", msg0);
fprintf(stdout,"%s",msg1);
fwrite(msg2,strlen(msg2),1,stdout);
//系统调用
write(1, msg3, strlen(msg3));
//fork();
return 0;
}运行结果:
cpp
#无fork
xqq@ubuntu-server:~/linux/moduleIX/testcache$ ./file
hello printf #涉及终端,行缓冲,立即刷新
hello fprintf
hello fwrite
hello write
xqq@ubuntu-server:~/linux/moduleIX/testcache$ ./file >log.txt #文件操作,全缓冲
xqq@ubuntu-server:~/linux/moduleIX/testcache$ cat log.txt
hello write
hello printf
hello fprintf
hello fwrite
#加入fork之后
xqq@ubuntu-server:~/linux/moduleIX/testcache$ ./file
hello printf
hello fprintf
hello fwrite
hello write
xqq@ubuntu-server:~/linux/moduleIX/testcache$ ./file >log.txt
xqq@ubuntu-server:~/linux/moduleIX/testcache$ cat log.txt
hello write#系统调用打印一次
hello printf#库函数打印两次
hello fprintf
hello fwrite
hello printf
hello fprintf
hello fwrite场景一:没有 fork
直接输出到终端(标准输出为终端)
-
此时
stdout是行缓冲 。printf、fprintf、fwrite输出的字符串都以\n结尾,所以每调用一个函数,缓冲区被换行符触发刷新,立即写入终端。 -
write是系统调用,直接写入文件描述符 1。由于四个函数依次调用并立即输出,顺序严格按照代码逻辑。
重定向到文件(> log.txt)
-
当
stdout被重定向到普通文件时,标准 IO 变为全缓冲。 -
printf、fprintf、fwrite的数据并没有立刻写入文件,而是暂存在stdout的缓冲区中。 -
write是系统调用,没有用户态缓冲,直接写入内核并最终落入文件。所以它第一个到达文件。 -
当
main结束(return 0)时,C 运行时调用exit,它会冲刷所有标准 IO 流,此时stdout缓冲区中的三条消息才被写入文件,顺序就是它们进入缓冲区的顺序。
场景二:加入 fork
直接输出到终端
输出与没有 fork 完全一样,四条消息各出现一次,顺序正确。
原因:行缓冲时,fork 执行前缓冲区已经被 \n 刷空,父子进程都没有残留的缓冲区数据,fork 不影响终端输出。
重定向到文件(> log.txt)
重定向到文件,即输出到文件里,对磁盘文件的操作通常使用全缓冲,所以缓冲模式从原本向stdout的行缓重变成了全缓冲
这里发生了关键变化:write(系统调用) 只出现一次,而库函数的三条消息全部重复了一次。
原因分析:
-
重定向后
stdout全缓冲。 -
printf、fprintf、fwrite三条消息进入缓冲区,尚未写入文件。 -
write是系统调用,无缓冲,此时直接写入文件,所以它最先出现在文件里,并且只出现一次。 -
随后执行
fork():-
fork会完整复制父进程的地址空间,包括stdout的用户态缓冲区。 -
此时父子进程各自拥有一份相同的缓冲区,里面都包含了那三条库函数消息。
-
-
父进程、子进程各自最终执行
return 0→exit→ 冲刷stdout。-
于是两份完全相同的缓冲区内容被先后写入同一个文件。
-
文件里就出现了两组
hello printf / hello fprintf / hello fwrite。
-
重定向的底层原理(dup2 替换 fd1 的指向)已在上一篇 3.7 节详细讲解,此处不再展开。
5.5 简单设计⼀下libc库
实现代码:
mystdio.c
cpp
#include"mystdio.h"
//C 语言只给用户头文件(.h,声明)和编译好的库文件(.so/.a,二进制实现)
//。源码(.c)不公开。用户拿着头文件编译自己的代码,链接器把库的机器码和用户的机器码合并成可执行文件
//static 让 BuyFile 成为 mystdio.c 的私有函数,
//用户只能通过 MyFopen 间接使用它,不能直接调用。
//这实现了封装,避免了符号冲突,和面向对象的 private 是一个道理
static MYFILE* BuyFile(int fd,int mode)
{
MYFILE*file=(MYFILE*)malloc(sizeof(MYFILE));
if(file==NULL)
{
perror("malloc fail!");
return NULL;
}
memset(file->out,0,sizeof(file->out));
file->bufflen=0;
file->fileno=fd;
file->flag=mode;
// 如果是终端设备,用行缓冲;否则用全缓冲
if (isatty(fd))
file->flush_method = LINE_FLUSH;
else
file->flush_method = FULL_FLUSH;
return file;
}
MYFILE* MyFopen(const char *pathname, const char *mode)
{
int fd=-1;
int _mode=0;
if(strcmp(mode,"w")==0)
{
_mode=O_WRONLY|O_CREAT|O_TRUNC;
fd=open(pathname,_mode,0666);
}
else if(strcmp(mode,"r")==0)
{
_mode=O_RDONLY;
fd=open(pathname,_mode);
}
else if(strcmp(mode,"a")==0)
{
_mode=O_WRONLY|O_CREAT|O_APPEND;
fd=open(pathname,_mode,0666);
}
else if(strcmp(mode,"w+")==0)
{
_mode=O_RDWR|O_CREAT|O_TRUNC;
fd=open(pathname,_mode,0666);
}
else if(strcmp(mode,"r+")==0)
{
_mode=O_RDWR;
fd=open(pathname,_mode);
}
else if(strcmp(mode,"a+")==0)
{
_mode=O_RDWR|O_CREAT|O_APPEND;
fd=open(pathname,_mode,0666);
}
else
{
//...
}
if(fd<0)
return NULL;
return BuyFile(fd,_mode);
}
void MyFclose(MYFILE *stream)
{
if(stream==NULL||stream->fileno<0) return;
MyFFlush(stream);
close(stream->fileno);
free(stream);
}
//传入 onst char * 类型的字符串,不需要强制类型转换
int MyFwrite(MYFILE*file,const void* src,int len)
{//写入就是拷贝
memcpy(file->out+file->bufflen,src,len);
file->bufflen+=len;
//写入尝试刷新
if((file->flush_method & LINE_FLUSH)&&file->out[file->bufflen-1]=='\n')
{
MyFFlush(file);
}
return 0;
}
void MyFFlush(MYFILE*file)
{
if(file==NULL||file->bufflen<=0) return;
//将缓冲区里的数据写到内核缓冲区里
int n=write(file->fileno,file->out,file->bufflen);
if(n<0)
perror("write");
file->bufflen=0;
memset(file->out,0,MAX);
}mystdio.h
cpp
#pragma once
#include<stdio.h>
#include<unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include<string.h>
#include<stdlib.h>
#define MAX 1024
//定义刷新模式
#define NONE_FLUSH (1<<0)
#define LINE_FLUSH (1<<1)
#define FULL_FLUSH (1<<2)
typedef struct IO_FIILE
{
int fileno;//文件描述符
int flag;//打开方式
char out[MAX];//缓冲区
int bufflen;//有效元素
int flush_method;
}MYFILE;
MYFILE* MyFopen(const char *pathname, const char *mode);
void MyFclose(MYFILE *stream);
int MyFwrite(MYFILE*,const void* str,int len);
void MyFFlush(MYFILE*);usercode.c
cpp
#include"mystdio.h"
int main()
{
const char* msg="hello world\n";
MYFILE* fp=MyFopen("test.txt","a");
if(!fp)
{
perror("MyFopen fail");
return 1;
}
int cnt=10;
while(cnt--)
{
MyFwrite(fp,msg,strlen(msg));
printf("缓冲区:%s\n",fp->out);
//MyFFlush(fp);//下面进行讲解
sleep(1);
}
MyFclose(fp);
return 0;
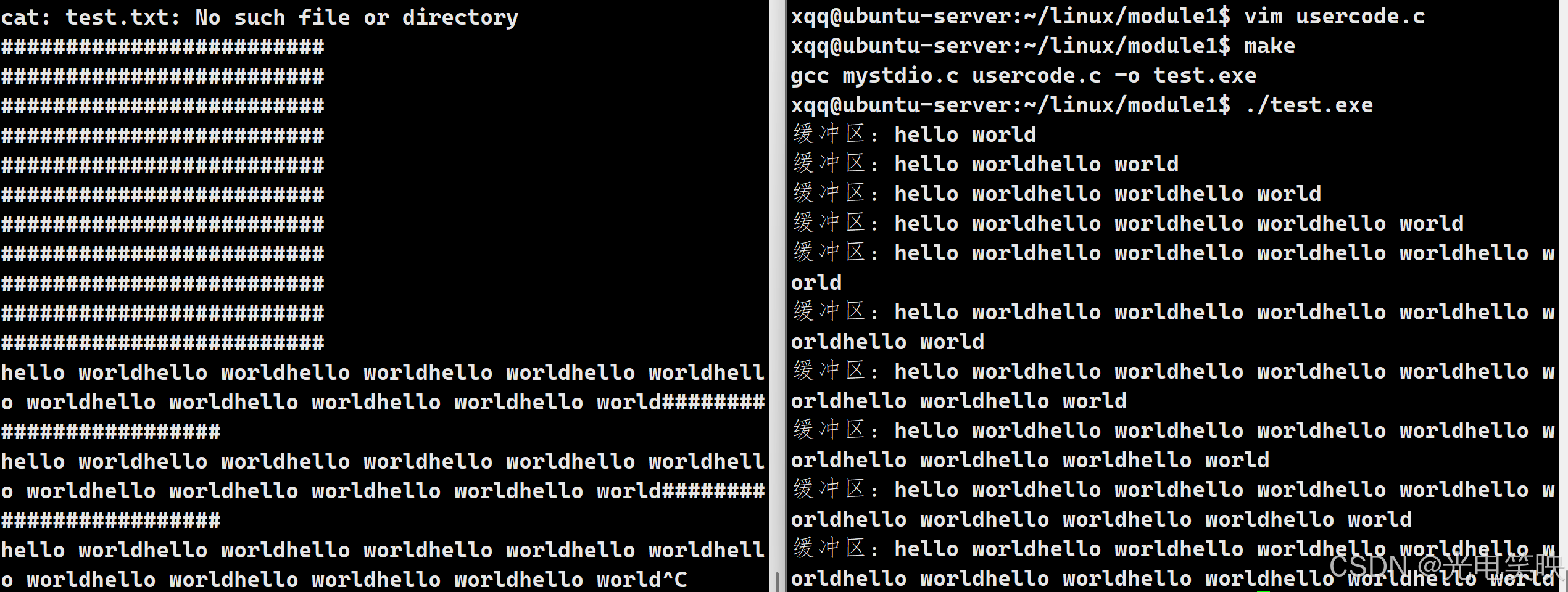
} 验证缓冲区:
监测脚本:
bashwhile :; do cat test.txt;sleep 1;echo "#########################";done可以看到,缓冲区越来越满,此时文件是空的,直到循环结束调用MyFclose(fp),强制刷新缓冲区,这样一次性全部刷到了系统内核缓冲区,写入磁盘文件
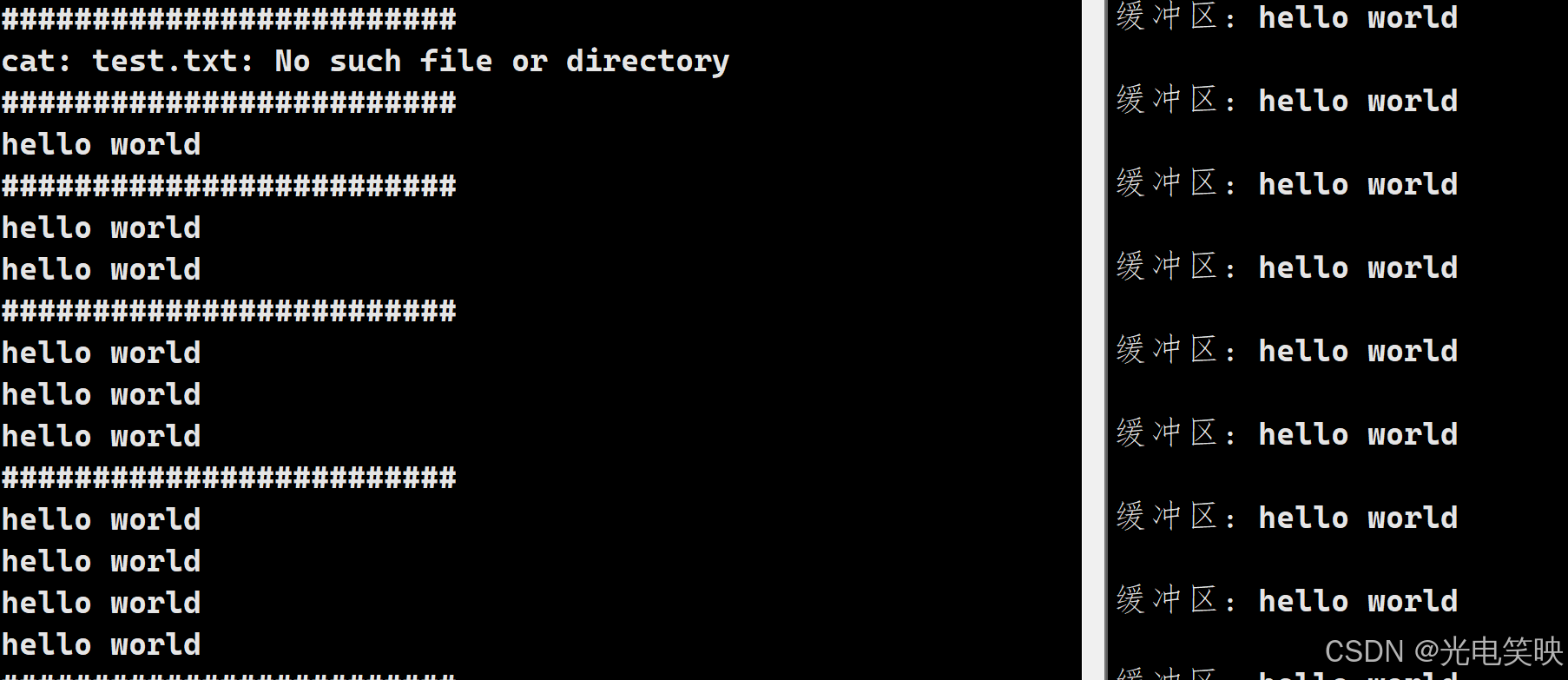
加上MyFFlush(fp);后: