文章目录
-
- 前言
- 一、核心定义
- 二、标准体系结构图
- 三、场景推演
- 四、实战案例
-
- [4.1 需求分析](#4.1 需求分析)
- [4.2 架构图](#4.2 架构图)
-
- [4.2.1 普通方式架构图](#4.2.1 普通方式架构图)
- [4.2.2 享元模式架构图](#4.2.2 享元模式架构图)
- [4.3 时序图](#4.3 时序图)
-
- [4.3.1 普通代码时序图](#4.3.1 普通代码时序图)
- [4.3.2 享元模式时序图](#4.3.2 享元模式时序图)
- [4.4 代码分析](#4.4 代码分析)
-
- [4.4.1 普通代码](#4.4.1 普通代码)
- [4.4.2 享元模式代码](#4.4.2 享元模式代码)
- 总结
前言
在实际开发中,我们经常会遇到一种情况:系统里有大量对象,但这些对象中很多数据是重复的。
比如:
游戏地图中有 10 万棵树:
每棵树都有坐标、颜色、纹理、树种。
秒杀系统中有很多活动查询:
每次查询都有活动名称、活动描述、开始时间、结束时间、库存信息。随着业务规模的扩张,这些海量的对象会像无底洞一样吞噬系统的内存,导致频繁的垃圾回收(GC),甚至引发系统崩溃(OOM)。
对于这种情况,如何用最少的资源办最多的事?
如果每次都创建一个完整的对象,就像每个学生都要一本完全一样的教材,但学校却给每个人重新打印一遍,这显然会浪费大量资源。
共享元模式就是为了解决这种"重复对象过多,内存浪费严重"的问题。
其核心思想是:
相同的内容共享,不同的外部内容形成。
本文代码:https://github.com/likerhood/CodeDesignWork/tree/main/codedesign10.0-0 和 10.0-1
一、核心定义
享元模式的核心思想非常纯粹:运用共享技术,有效地支持大量细粒度对象的复用。
它的定义可以这样理解:
通过共享已经存在的对象,减少大量相似对象的创建,从而降低内存消耗,提高系统访问效率。
更直白地说:
- 不要每次都 new 一个完整对象;
- 能共享的部分就共享;
- 不能共享的部分再单独传入;
这里的思想和原型模式比较接近。
在共享元模式中,最重要的是区分两个状态:
| 状态 | 意义 | 是否共享 | 举例说明 |
|---|---|---|---|
| 内在状态 | 对象中稳定、不变、可复用的数据 | 可以分享 | 活动名称、活动描述、树的纹理、树的颜色 |
| 外部在状态 | 每个对象突出、经常变化的数据 | 不分享 | 库存数量、树的坐标、当前用户状态 |
类比在购物节的秒似杀活动中:
-
活动ID、活动名称、活动描述、开始时间、结束时间,这些通常是不变的,可以共享。
-
库存数量、已售数量、用户下单状态,这些是变化的,不适合共享。
所以享元模式的本质是:完整对象 = 共享对象 + 外部状态
二、标准体系结构图
享元模式的标准体系通常包含以下核心角色:
- FlyweightFactory(享元工厂):负责创建和管理享元对象。当客户端请求时,工厂会检查池中是否已有符合要求的对象,如果有则直接返回,没有则创建新对象并放入池中。
- Flyweight(抽象享元接口):规定了具体享元类必须实现的方法,通常会接收外部状态作为参数。
- ConcreteFlyweight(具体享元类):实现了接口,并为内部状态提供存储空间。
这里的重点在于:
- 客户端不直接创建共享对象;
- 客户端通过享元工厂获取共享对象;
- 享元工厂内部维护一个对象池;
- 如果对象已经存在,直接复用;
- 如果对象不存在,再创建并放入对象池。
获取享元对象
管理对象池
Client
+operation()
FlyweightFactory
-Map<String, Flyweight> pool
+getFlyweight(key) : Flyweight
<<interface>>
Flyweight
+operation(extrinsicState)
ConcreteFlyweight
-intrinsicState
+operation(extrinsicState)
三、场景推演
在游戏开发中,通常需要渲染成千上万的树木来构成一片广袤的森林。如果每一棵树都包含完整的品种信息、高分辨率的树皮贴图模型(几十MB大小)以及具体的坐标位置,一百万棵树就会直接撑爆显存。
但仔细推演我们会发现:森林里的树虽然多,但"品种"其实只有寥寥几种(比如橡树、松树、白桦树)。树的品种和贴图模型是永远不变的(内部状态) ,而树在地图上的 X、Y 坐标是每棵树独有的(外部状态)。
JAVA
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
// 享元对象:树的类型,保存可共享的内部状态
class TreeType {
// 内部状态:树的品种
private final String name;
// 内部状态:树皮贴图
private final String barkTexture;
// 内部状态:树的模型数据
private final String modelData;
public TreeType(String name, String barkTexture, String modelData) {
this.name = name;
this.barkTexture = barkTexture;
this.modelData = modelData;
}
// 外部状态通过参数传入
public void render(int x, int y) {
System.out.println(
"渲染树木:" + name +
",坐标:(" + x + ", " + y + ")" +
",贴图:" + barkTexture +
",模型:" + modelData
);
}
}
// 享元工厂:负责创建和复用 TreeType
class TreeFactory {
private static final Map<String, TreeType> TREE_TYPE_POOL = new HashMap<>();
public static TreeType getTreeType(String name, String barkTexture, String modelData) {
String key = name + "_" + barkTexture + "_" + modelData;
if (!TREE_TYPE_POOL.containsKey(key)) {
System.out.println("创建新的树类型:" + name);
TREE_TYPE_POOL.put(key, new TreeType(name, barkTexture, modelData));
}
return TREE_TYPE_POOL.get(key);
}
public static int getTreeTypeCount() {
return TREE_TYPE_POOL.size();
}
}
// 具体树对象:保存每棵树独有的外部状态
class Tree {
// 外部状态:每棵树的位置不同
private final int x;
private final int y;
// 引用共享的树类型对象
private final TreeType treeType;
public Tree(int x, int y, TreeType treeType) {
this.x = x;
this.y = y;
this.treeType = treeType;
}
public void render() {
treeType.render(x, y);
}
}
// 森林类:管理大量树木
class Forest {
private final List<Tree> trees = new ArrayList<>();
public void plantTree(int x, int y, String name, String barkTexture, String modelData) {
TreeType treeType = TreeFactory.getTreeType(name, barkTexture, modelData);
Tree tree = new Tree(x, y, treeType);
trees.add(tree);
}
public void render() {
for (Tree tree : trees) {
tree.render();
}
}
public int getTreeCount() {
return trees.size();
}
}
// 测试类
public class FlyweightTreeDemo {
public static void main(String[] args) {
Forest forest = new Forest();
// 种植很多棵橡树
forest.plantTree(10, 20, "橡树", "oak_bark_texture.png", "oak_model.obj");
forest.plantTree(30, 50, "橡树", "oak_bark_texture.png", "oak_model.obj");
forest.plantTree(80, 120, "橡树", "oak_bark_texture.png", "oak_model.obj");
// 种植很多棵松树
forest.plantTree(200, 300, "松树", "pine_bark_texture.png", "pine_model.obj");
forest.plantTree(250, 360, "松树", "pine_bark_texture.png", "pine_model.obj");
// 种植白桦树
forest.plantTree(400, 500, "白桦树", "birch_bark_texture.png", "birch_model.obj");
forest.render();
System.out.println("----------------------");
System.out.println("森林中的树木总数:" + forest.getTreeCount());
System.out.println("实际创建的树类型数量:" + TreeFactory.getTreeTypeCount());
}
}最核心的地方是这句:
java
TreeType treeType = TreeFactory.getTreeType(name, barkTexture, modelData);它表示:
种树时不要每次都创建完整树模型,而是先去享元池里找有没有相同类型的树。如果有,就直接复用。
这些数据不再每棵树都复制一份,而是相同类型的树共享一份。
Tree 对象还是创建了 6 个,但 TreeType 这种重量级、可共享的对象只创建了 3 个。
四、实战案例
4.1 需求分析
秒杀活动查询接口通常会返回活动 ID、活动名称、活动描述、开始时间、结束时间、库存等信息。
普通实现中,每次请求都会重新创建完整的活动对象,活动基础信息和库存信息一起被反复构建。
但在真实秒杀场景中,活动名称、描述、开始/结束时间等属于相对稳定的内部状态,而库存已用数量属于频繁变化的外部状态。
享元模式的核心思路就是:复用稳定对象,只把变化数据放在外部动态补充,从而减少对象创建和内存占用。
4.2 架构图
4.2.1 普通方式架构图
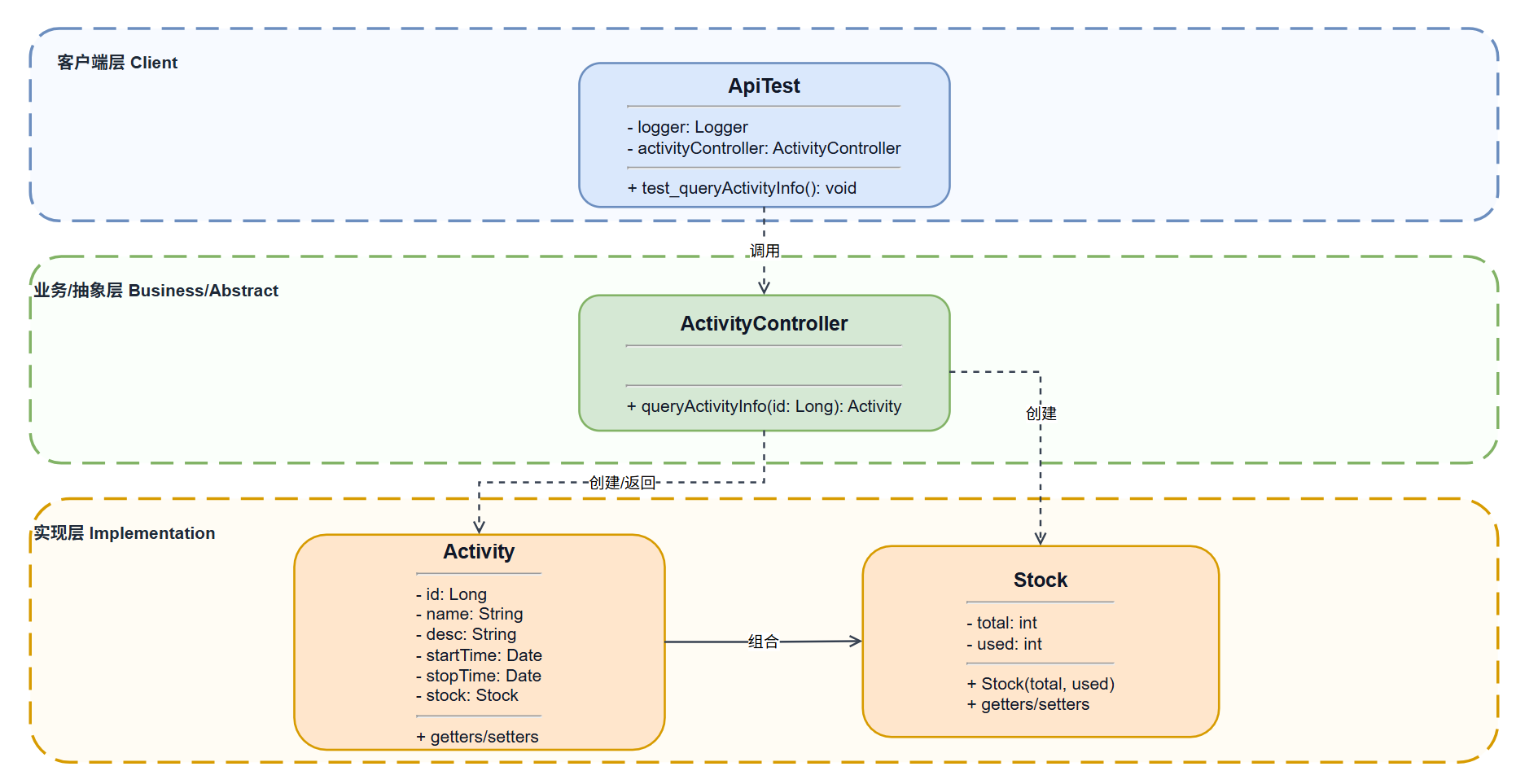
4.2.2 享元模式架构图
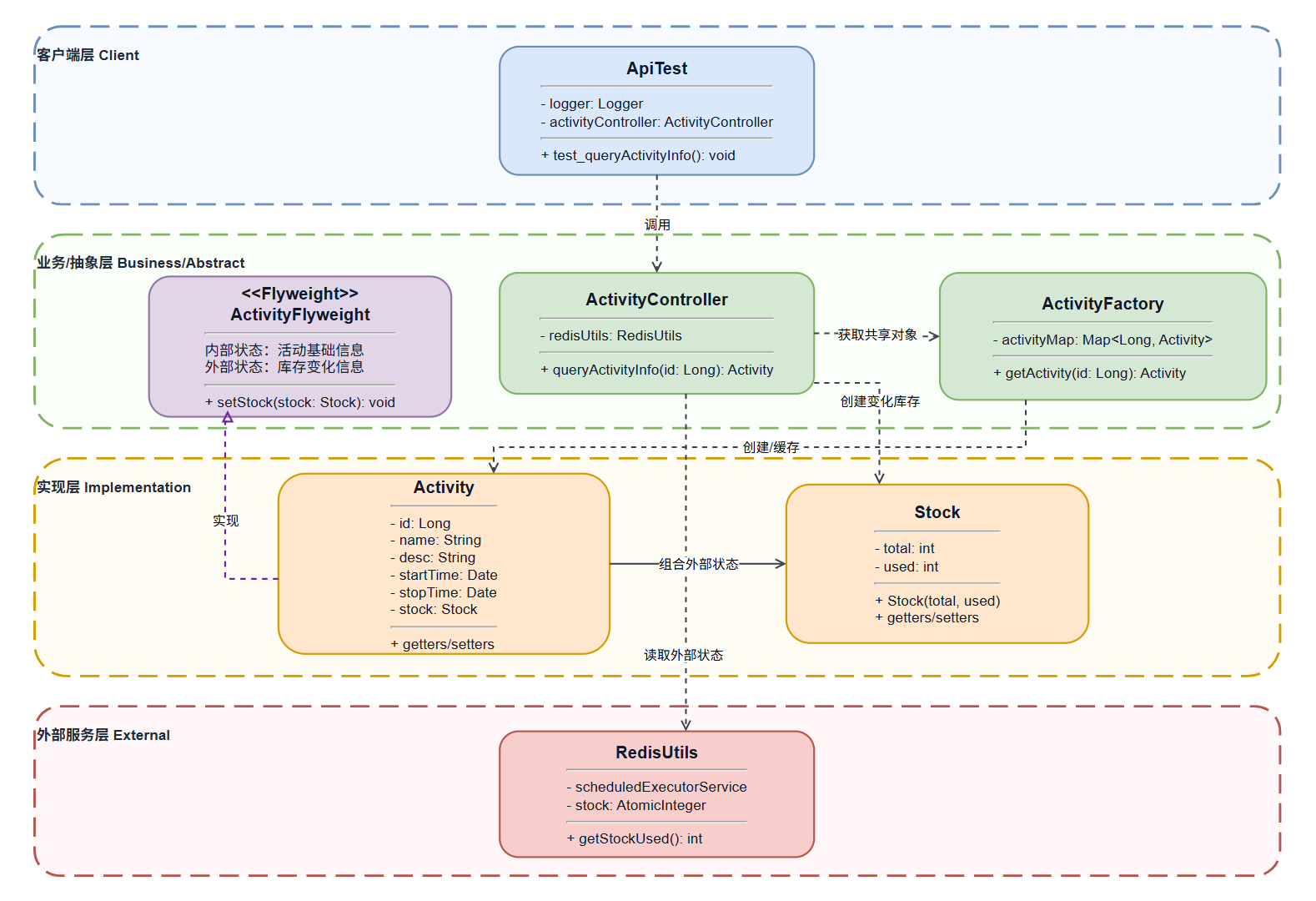
4.3 时序图
4.3.1 普通代码时序图
Stock Activity ActivityController ApiTest Stock Activity ActivityController ApiTest queryActivityInfo(10001L) new Activity() setId/setName/setDesc/setTime new Stock(1000, 1) setStock(stock) return Activity
4.3.2 享元模式时序图
Stock RedisUtils Shared Activity ActivityFactory ActivityController ApiTest Stock RedisUtils Shared Activity ActivityFactory ActivityController ApiTest alt 缓存不存在 缓存存在 queryActivityInfo(10001L) getActivity(10001L) new Activity() activityMap.put(id, activity) return cached Activity getStockUsed() used new Stock(1000, used) setStock(stock) return Activity
4.4 代码分析
4.4.1 普通代码
普通实现的核心问题在于每次请求都会重新创建 Activity,并把活动基础信息、活动时间、库存信息全部硬编码到接口逻辑里。
java
public Activity queryActivityInfo(Long id) {
Activity activity = new Activity();
activity.setId(10001L);
activity.setName("图书嗨乐");
activity.setDesc("图书优惠券分享激励分享活动第二期");
activity.setStartTime(new Date());
activity.setStopTime(new Date());
activity.setStock(new Stock(1000, 1));
return activity;
}这种方式简单直接,但当请求量变大时,大量重复对象会被创建。
活动基础信息本身并不会频繁变化,却在每一次查询中重新构造,造成不必要的内存和对象创建成本。
4.4.2 享元模式代码
享元模式版本引入 ActivityFactory,通过 Map<Long, Activity> 缓存活动对象。
活动 ID、名称、描述、时间等稳定信息作为内部状态被共享;库存已用数量作为外部状态,从 RedisUtils 中动态读取后重新设置。
java
public class ActivityFactory {
static Map<Long, Activity> activityMap = new HashMap<>();
public static Activity getActivity(Long id) {
Activity activity = activityMap.get(id);
if (null == activity) {
activity = new Activity();
activity.setId(10001L);
activity.setName("图书嗨乐");
activity.setDesc("图书优惠券分享激励分享活动第二期");
activity.setStartTime(new Date());
activity.setStopTime(new Date());
activityMap.put(id, activity);
}
return activity;
}
}
public Activity queryActivityInfo(Long id) {
Activity activity = ActivityFactory.getActivity(id);
Stock stock = new Stock(1000, redisUtils.getStockUsed());
activity.setStock(stock);
return activity;
}整体来看,享元模式把"不变的活动信息"和"变化的库存信息"拆开处理:前者缓存复用,后者按请求动态补充。这样可以减少重复对象创建,也让业务结构更贴合高并发秒杀查询场景。
总结
享元模式是空间换时间(或共享换空间)的经典体现。通过构建缓存池和状态拆分,它能在高并发、大数据量的场景下,将内存占用成千上万倍地压缩。
虽然它极大提升了性能,但也引入了状态分离的系统复杂度。
在实际应用中(如 Java 的 String 常量池、数据库连接池、线程池),我们需要时刻警惕多线程环境下的线程安全问题,确保享元对象的"内部状态"绝对不可被篡改。