目录
[1.0 简介](#1.0 简介)
[2.0 项目搭建](#2.0 项目搭建)
[(1) 项目初始化](#(1) 项目初始化)
[3.0 成果展示](#3.0 成果展示)
综合案例
一、项目
1.0 简介
(1)项目介绍
构建一套面向"嘟嘟就业课"课程咨询场景的智能聊天系统
支持 对话记忆、RAG 知识库问答、敏感词安全引导、⼯具调⽤ (MCP ⼯单系统) , 并提供简单易⽤的 Web 聊天界⾯
组成:`chat-bot-service`:对外 Web 服务 (端⼝默认 8081) , 提供聊天流式接⼝、会话管理、RAG 检索、敏感词引导、MCP 客⼾端调⽤. `ticket-service`:MCP Server (⽆ Web, STDIO 启动) , 暴露"创建⼯单/查询⼯单"的⼯具能⼒, 持久化在 MySQL.
2.0 项目搭建
(1) 项目初始化
在一期案例的基础上 进行改动 创建项目:bit-chat-bot 和 模块chat - bot - service
(2)代码整理
升级SpringAI版本 切换框架为SpringAI Alibaba
java
<properties>
<spring-ai.version>1.0.1</spring-ai.version>
</properties>
<!-- 父工程依赖 -->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.5.3</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<!-- 依赖版本管理 -->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>chat-bot-service项目pom.xml修改如下
java
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- spring ai alibaba -->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-bom</artifactId>
<version>1.0.0.2</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>修改配置文件:
java
server:
port: 8081
spring:
application:
name: spring-chat-bot
ai:
dashscope:
api-key: ${DASHSCOPE_API_KEY}
logging:
level:
org.springframework.ai.chat.client.advisor: debug
pattern:
console: "%d{HH:mm:ss.SSS} %5p ${PID:- } --- [%15.15t] %-40.40logger{39} : %m%n%wEx"修改代码:
由于切换了SpringAI版本以及更改了LLM的配置,所以导致先前出现的代码出现一些问题,需要进行修改
修改CommonConfiguration.java
java
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.MessageChatMemoryAdvisor;
import org.springframework.ai.chat.client.advisor.SimpleLoggerAdvisor;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.memory.MessageWindowChatMemory;
import org.springframework.ai.dashscope.DashScopeChatModel;
@Configuration
public class CommonConfiguration {
@Bean
public ChatMemory chatMemory() {
MessageWindowChatMemory memory = MessageWindowChatMemory.builder()
.maxMessages(10)
.build();
return memory;
}
@Bean
public ChatClient dashscopeChatClient(DashScopeChatModel chatModel, ChatMemory chatMemory) {
return ChatClient.builder(chatModel)
.defaultSystem("你叫小特,是比特教育研发的一款智能AI助手,擅长Java和C++,主要工作是解决学生在学习过程中遇到的一些问题")
.defaultAdvisors(
new SimpleLoggerAdvisor(),
MessageChatMemoryAdvisor.builder(chatMemory).build()
)
.build();
}
}修改ChatController

修改之后进行测试:
启动服务 测试http://127.0.0.1:8081/index.html
(2)构建RAG知识库
1 文件加载
由于就业课的网络公开资源较为有限,为提升就业课智能咨询系统的回答质量,解决其网络资源不足的问题,我们需要引入知识库作为大语言模型的上下文
添加文件:把提供的文件放在resource/bit目录下,为知识库的搭建做准备
resource的file下面
有了相关文档,首先加载上述提供的文件,转换为Document,方便后续处理
添加相关依赖:
java
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-markdown-document-reader</artifactId>
</dependency>创建rag包下DocumentLoader
把这些mardown文件变成resource 接下来使用markdown reader把resource变成document List
//简单来说就是 把本地的Markdown文件,通过Spring的Resource加载机制和Spring AI的Markdown读取器,转成程序可以处理的文档对象列表,为构建知识库做准备
写代码的时候ctrl加左键 看构造方法参数 这些都是编译器提前提供好了的
java
@Slf4j
@Component
public class DocumentLoader {
@Autowired
private ResourceLoader resourceLoader;
public Resource[] getResources(String location) throws IOException {
ResourcePatternResolver resolver = new PathMatchingResourcePatternResolver(resourceLoader);
return resolver.getResources(location);
}
public List<Document> loadMarkdowns() {
List<Document> allDocuments = new ArrayList<>();
try {
Resource[] resources = getResources("classpath:bit/*.md");
for (Resource resource : resources) {
String fileName = resource.getFilename();
log.info("load file:"+ fileName);
MarkdownDocumentReaderConfig config = MarkdownDocumentReaderConfig.builder()
.withHorizontalRuleCreateDocument(true)
.withIncludeCodeBlock(false)
.withIncludeBlockquote(false)
.withAdditionalMetadata("filename", fileName)
.build();
MarkdownDocumentReader reader = new MarkdownDocumentReader(resource, config);
allDocuments.addAll(reader.get());
}
}catch (IOException e){
log.error("加载文件失败", e);
}
log.info("文档加载完成");
return allDocuments;
}
}2 文本分割
文档加载后,为适应模型的上下文窗口限制,需要对原始文档进行切分
也就是将冗长文档拆解为符合令牌数量限制的语义片段,这是确保后续向量化处理与精准检索能够顺利进行的先决条件
//模仿TokenTextSplitter 对源文档按中文标点符号进行切分 因为源码默认是英文的 不方便
我们拿来修改一下
最主要的部分是:
java
// Find the last period or punctuation mark in the chunk
int lastPunctuation = Math.max(chunkText.lastIndexOf('.'),
Math.max(chunkText.lastIndexOf('?'),
Math.max(chunkText.lastIndexOf('!'),
Math.max(chunkText.lastIndexOf('。'),
Math.max(chunkText.lastIndexOf('?'),
Math.max(chunkText.lastIndexOf('!'),
chunkText.lastIndexOf('\n'))))));在文本里面找到一个最合适的断句点,避免把一句话切的稀碎,它在最后一个可以干净利落断句的标点符合位置,让切割更符合语言习惯
3 补充关键词元信息
为了实现更精准的智能检索,完成文本分割后,系统将对分割后的文本块进行"元信息增强"处理,为每个文本块提取并附加关键词元信息,当进行语义检索时,这些关键词与文本块的嵌入向量系统工作,提升问答系统的响应质量与用户体验。
java
@Component
public class KeywordEnricher {
@Autowired
private DashScopeChatModel chatModel;
/**
* 补充关键词元信息
* @param documents
* @return
*/
public List<Document> enrich(List<Document> documents) {
// 关键词提取
KeywordMetadataEnricher enricher = KeywordMetadataEnricher.builder(chatModel)
.keywordCount(5)
.build();
return enricher.apply(documents);
}
}4 定义向量数据库
完成这些预处理后 关键的一步就是把这些文本框存入向量数据库
完成知识库构建的最后一步 此后 系统便可根据用户问题,实时从库中召回最相关的知识片段
java
@Configuration
public class VectorConfig {
@Bean
public VectorStore vectorStore(EmbeddingModel embeddingModel){
return SimpleVectorStore.builder(embeddingModel).build();
}
}5 流程串联
通过这个DataInit方法把整个流程串联起来
代码不进行展示了 比较多 需要解决一下bug,可能会有乱码的问题
解决方式是在配置文件里面加入
java
charset:
console: UTF-8
file: UTF-8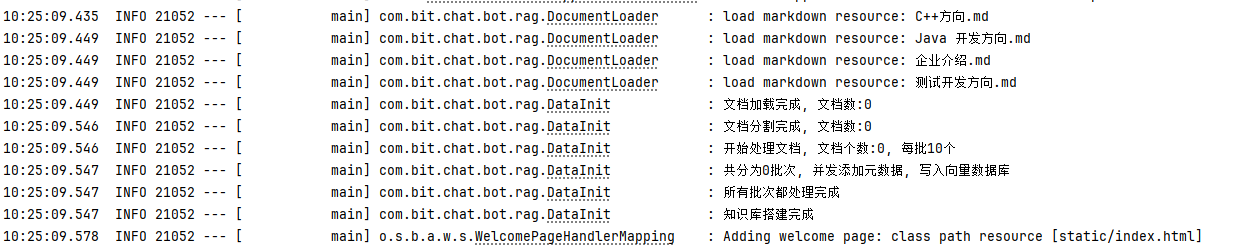
6 应用RAG知识库问答
知识库构建完成后,即可基于向量库实施检索了
修改提示词:
在之前的CommonConfiguration里面把提示词修改一下
你是⼀名专业的企业培训课程咨询 助⼿, 代表【就业课】为客⼾提供课程咨询服务. 你的职责是准确、礼貌、⾼效地解答客⼾关于⽐特就业课培训课程的各类问题
定义QuestionAnswerAdvisor,绑定到ChatClient:
添加依赖
java
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>加入代码:
java
QuestionAnswerAdvisor questionAnswerAdvisor = QuestionAnswerAdvisor.builder(vectorStore).build();
-----------------
.defaultAdvisors(questionAnswerAdvisor)提示词也修改一下 //这部分需要修改很多的bug
封装一个 Advisor类
7 测试:
启动项目 观察日志 知识库是否搭建完成

(3)多线程处理文档
问题:启动服务的时候 关键词提取耗时非常长(6--10min)

优化:使用多线程处理文档
CountDownLatch
同时等待N个任务执行结束:同时出发,都结束,才是结束
• 构造 CountDownLatch 实例, 初始化 10 表⽰有 10 个任务需要完成.
• 每个任务执⾏完毕, 都调⽤ latch.countDown() . 在 CountDownLatch 内部的计数器同时⾃减
• 主线程中使⽤ latch.await(); 阻塞等待所有任务执⾏完毕. 相当于计数器为 0 了.
看看代码吧:
java
public class Demo {
public static void main(String[] args) throws Exception {
CountDownLatch latch = new CountDownLatch(10);
Runnable r = new Runnable() {
@Override
public void run() {
try {
Thread.sleep((int) (Math.random() * 10000));
latch.countDown();
} catch (Exception e) {
e.printStackTrace();
}
}
};
for (int i = 0; i < 10; i++) {
new Thread(r).start();
}
// 必须等到 10 人全部回来
latch.await();
System.out.println("比赛结束");
}
}latch.countDown 就像是在一个计数器门上按下减一 ,就是个倒计数信号,每完成一个任务减一下,减到0就放行等待的人。
使用CountDownLatch和线程池进行批量处理
测试:服务重启后,通过启动日志,可以观察到本次优化的效果:关键流程的耗时从原来的6--10 大幅降至2分钟以内
java
private final ExecutorService executorService = Executors.newFixedThreadPool(8);代码讲解:简单来说就是把document分批次搬进向量数据库 线程池里面的现成同时搬
batchSize是分批 每批几个 enricher.enrich是贴标签,比如给文档补充一些关键词之类的元信息 vectorStore.add是把处理好的文档写入向量数据库,后面检索用 countDownLatch.await(10, TimeUnit.MINUTES); 就是主线程等所有人干完
(4)切换向量数据库
基于测试,,我们发现当前设计存在的两个问题:
数据易失性:向量数据存储在内存,服务重启后会造成数据丢失
初始化效率:因为数据丢失,所以每次重启都需要重新写入全量向量,效率低下
为了解决上述问题,进行以下两点优化:
数据持久化:将向量存储从内存迁移至Redis向量数据库,确保数据持久可用
流程可配置优化:引入用户配置项,允许按需控制是否执行向量初始化流程,避免无效开销
java
data:
is-load: true使用配置:
java
@Value("${data.is-load}")
private boolean isLoad;
@PostConstruct
public void initData(){
if (!isLoad){
log.info("知识库文档无需加载....");
return;
}
//.... 执行文档加载流程
}切换向量数据库:
添加redis相关依赖、添加Redis配置 、 删除SimpleVectorStore定义
java
<!-- 接入Redis -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-redis</artifactId>
</dependency>
-----------------------------------------------------------------
spring:
ai:
vectorstore:
redis:
initialize-schema: true # 是否自动创建索引结构
index-name: bit-chat-bot # 向量索引名称
prefix: "rag:" # Redis Key 前缀
data:
redis:
url: redis://XX.XX.XX.XX:XX//添加依赖 配置之后,注入VectroStore会自动切换为RedisVectorStore 删除之前定义的SimpleVecctorStore 注释掉就可以
重新测试
(5)重排序
在初步检索之后,我们可以引入一个更擅长判断相关性的精排模型,对候选文档进行重新打分
从而更精准的筛选出最匹配的内容,再交大模型生成回答,这一流程能够有效提升最终答案的准确度
定义重排序Advisor
利用SpringAI提供的 RestrievalRerankAdvisor 我们在初步检索的基础上进行精细相关性排序,显著提升检索精度
也可以对重排序模型进行配置
(6)MCP
1 添加MCP应用
尽管接入了向量数据库和知识库后,大模型的回答能力有了明显的提升,但在实际使用中,还是会遇到一些超出它处理范围的用户请求
比如,当用户明确说 转人工客服 找专属顾问咨询 或是提到涉及敏感操作、复杂流程等需求时,仅靠预训练模型和静态的知识库往往难以应对
为了提升系统的灵活性和服务能力,我们计划引入外部工具调用机制(MCP),让模型在遇到特定场景时,能够触发外部服务或流程进行衔接
开发工单MCP服务
就是把工单系统做成一个标准插头,让AI助手能直接插上,自动帮你查任务 派任务 改状态
用这个来模拟人工客服
我们这个mcp服务要实现的功能是什么:
• 接收需求:使⽤"创建⼯单"⼯具, 将⽤⼾请求转化为待处理⼯单.
• 跟进进度:使⽤"查询⼯单"⼯具, 通过ID随时查看最新状态.
例如:我要退款 当我收到这个请求的时候 系统可以直接创建一个工单 这样后台的客服人员就可以看着这个工单列表来联系用户了

java
-- 创建数据库
DROP DATABASE IF EXISTS bit_chat_bot;
CREATE DATABASE IF NOT EXISTS bit_chat_bot DEFAULT CHARACTER SET utf8mb4;
-- 使用数据库
USE bit_chat_bot;
-- 创建表
DROP TABLE IF EXISTS `ticket_info`;
CREATE TABLE `ticket_info` (
`id` int NOT NULL AUTO_INCREMENT,
`ticket_id` varchar(128) NOT NULL COMMENT '工单ID',
`title` varchar(128) NOT NULL COMMENT '工单标题',
`description` varchar(255) NOT NULL COMMENT '工单详细描述',
`related_chat_id` varchar(128) DEFAULT NULL COMMENT '关联会话ID',
`status` tinyint DEFAULT '1' COMMENT '工单状态 1-新建 2-处理中 3-已解决 4-已关闭',
`creator` varchar(128) DEFAULT 'system' COMMENT '创建人',
`assignee` varchar(128) DEFAULT NULL COMMENT '分配给',
`created_time` datetime DEFAULT CURRENT_TIMESTAMP,
`updated_time` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`closed_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='工单信息表';接下来进行mcp服务开发:
创建模块ticket-service//方便管理
完善pom文件
java
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-server</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>3.5.3</version>
</plugin>
</plugins>
</build>添加配置文件 : 别忘记数据库相关的信息
java
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/bit_chat_bot?characterEncoding=utf8&useSSL=false&allowPublicKeyRetrieval=true
username: root
password: root
driver-class-name: com.mysql.cj.jdbc.Driver
ai:
mcp:
server:
name: ticket-service
version: 0.0.1
main:
web-application-type: none
banner-mode: off
mybatis:
configuration:
map-underscore-to-camel-case: true #配置驼峰自动转换
logging:
pattern:
console: "%d{HH:mm:ss.SSS} %5p ${PID:- } --- [%15.15t] %-40.40logger{39} : %m%n%wEx"添加启动类
3 定义工具和暴漏工具
java
@Configuration
public class TicketTool {
@Bean
public ToolCallbackProvider toolCallbackProvider(TicketService ticketService){
return MethodToolCallbackProvider.builder()
.toolObjects(ticketService)
.build();
}
}maven里面进行打包 //中文路径可能会有乱码的情况

更改路径:
接入MCP
添加依赖
java
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-client</artifactId>
</dependency>添加mcp配置 并创建mcp-servers-config.json文件
java
spring:
ai:
mcp:
client:
request-timeout: 60000
stdio:
servers-configuration: classpath:/mcp/mcp-servers-config.json文件内容为:
java
{
"mcpServers": {
"ticket-service": {
"command": "java",
"args": [
"-Dspring.ai.mcp.server.stdio=true",
"-Dlogging.pattern.console=",
"-Dfile.encoding=UTF-8",
"-jar",
"D:/Git/spring-ai-2/spring-chat-bot2/ticket-service/target/ticket-service-1.0-SNAPSHOT.jar"
]
}
}
}添加工具
将会话ID传递给MCP
java
.defaultToolCallbacks(toolCallbackProvider)修改QuestionAnswerAdvisor模板提示词
java
1.若上下文信息中包含与用户问题直接相关的内容,即使表述方式略有不同,也应通过语义理解判断其相关性,并据此进行回复。
2.如果答案不在上下文中,请帮忙创建工单,并让用户等待专业课程顾问回答。
3.如果用户要求 "人工客服"," 人工顾问 ' 来回答,请帮忙创建工单,并让用户等待专业课程顾问回答。
4.回复时直接给出答案或解决方案,避免使用 "根据您提供的信息"、"根据上下文" 等冗余表达。
确保系统具备基本的语义匹配能力,不能仅依赖字面完全匹配来判断信息相关性测试MCP

(7)敏感词处理
我们可以基于用户的输入内容进行智能判断与分类处理
例如:当检测到脏话或违规内容时,系统将不予响应
Spring AI 提供的 SafeGuardAdvisor 组件可⽤于对⽤⼾输⼊内容进⾏安全检测与过滤, ⽀持敏感信息识别、不当⾔论拦截, 从⽽保障对话系统的安全性与合规性
java
.defaultAdvisors(new SafeGuardAdvisor(List.of("正副")))自定义处理
SafeGuardAdvisor 的内置敏感词过滤是比较"死板"的,如果你觉得它不够用,可以自己动手写一个更聪明的 Advisor 来代替它。
自定义Advisor:CustomSafeGuardAdvisor
修改对应的返回模板
java
private static final String DEFAULT_FAILURE_RESPONSE = "这个问题我暂时解答不了, 我们聊点别的吧";(8)聊天记忆持久化
存在问题:服务重启后所有历史会话和上下文全部丢失 无法支持生产环境长期运行需求
当前系统的会话管理由两部分组成:
会话记忆 会话列表 //都是在内存中实现的 不持久
目标:将上述两个模块的数据存储方式改为持久化存储,提升系统可用性与数据可靠性
SpringAI提供了多种内置的聊天记忆存储实现,包括:
• InMemoryChatMemoryRepository (默认)
• JdbcChatMemoryRepository (关系型数据库)
• CassandraChatMemoryRepository
• Neo4jChatMemoryRepository
我们选择JDBC方案,适配现有MySQL环境,实现轻量级持久化
引入依赖:
java
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-chat-memory-repository-jdbc</artifactId>
</dependency>
<!-- MySQL驱动 -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>添加配置:
java
spring:
ai:
chat:
memory:
repository:
jdbc:
initialize-schema: always
schema: classpath:/sql/schema-mysql.sql
datasource:
username: root
password: root
url: jdbc:mysql://localhost:3306/bit_chat_bot?characterEncoding=utf8&useSSL=false&serverTimezone=UTC
driver-class-name: com.mysql.cj.jdbc.Driver在resources/sql/schema-mysql.sql文件中定义表结构
java
CREATE TABLE chat_sessions (
id INT NOT NULL AUTO_INCREMENT,
chat_id VARCHAR(36) NOT NULL,
title VARCHAR(127) NOT NULL DEFAULT '新会话',
created_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
updated_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
);配置JdbcChatMemoryRepository 通过注入JdbcChatMemoryRepository 构建持久化的MessageWindowChatMemory
java
@Bean
ChatMemory chatMemory(JdbcChatMemoryRepository chatMemoryRepository) {
return MessageWindowChatMemory
.builder()
.maxMessages(10) // 控制每个会话最多保留10条消息
.chatMemoryRepository(chatMemoryRepository)
.build();
}扩展:实现会话列表的持久化
⽬前"会话列表"是通过内存Map存储( MemoryChatHistoryRepository )的, 可以将其改造为"数
据库持久化版本".
参考步骤: 设计数据库表结构 编写实体类ChatSession 实现JdbcChatHistroyRepository类
替换原内存实现为数据库实现 测试:重启服务后确认数据不丢失
//这部分代码可以用AI实现
3.0 成果展示
(1)界面展示
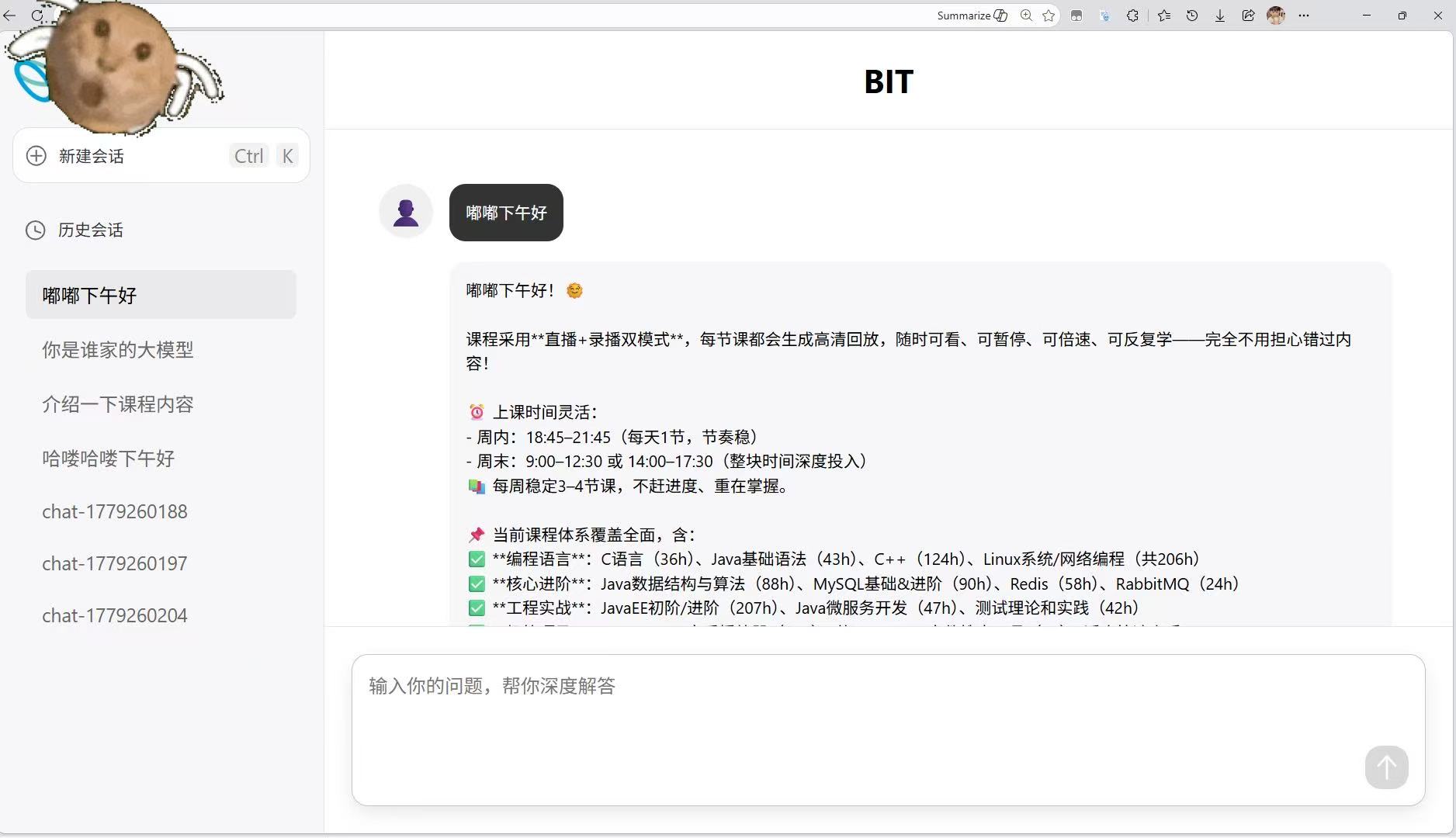
(2)会话内容记忆
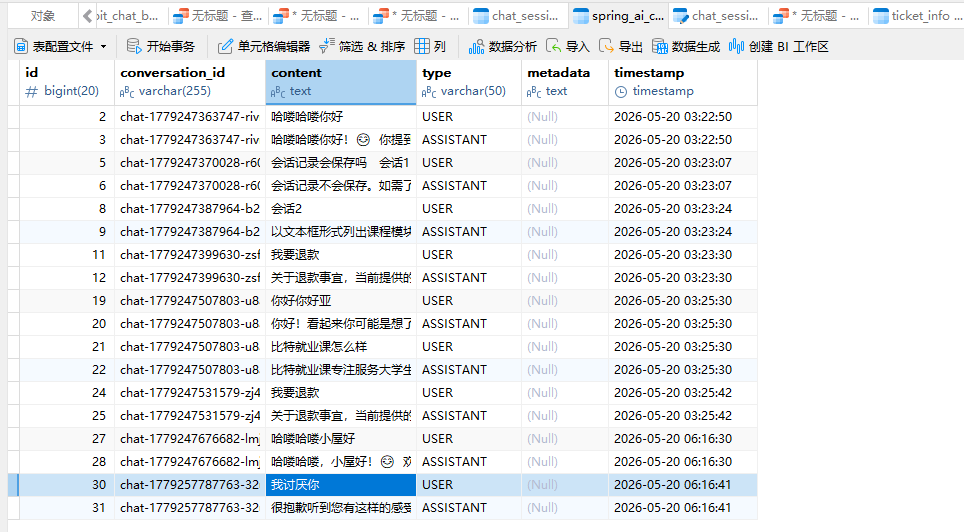
(3)会话列表记忆
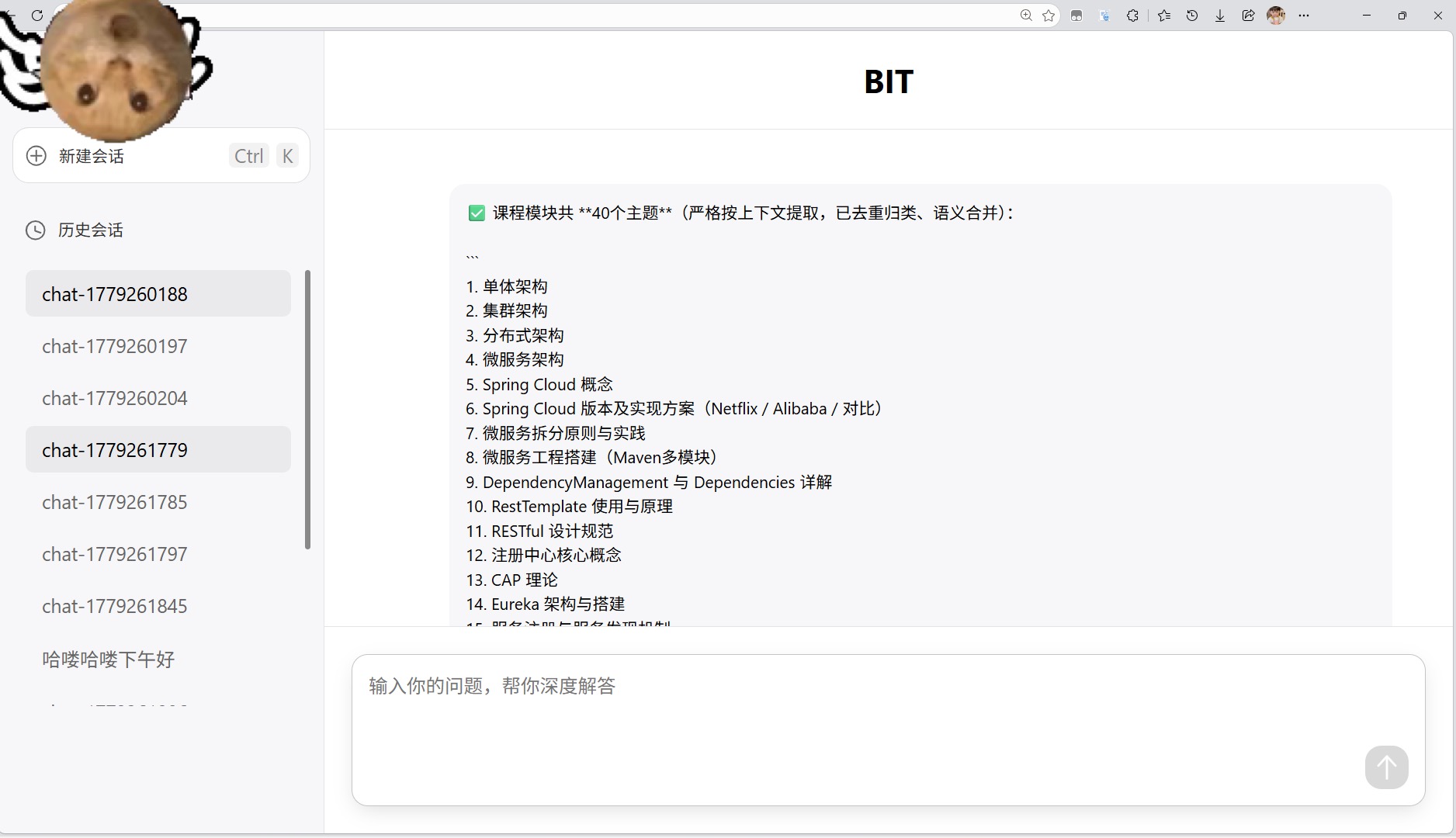
(4)接入的mcp

(5)后台