上周,我盯着电脑屏幕上一个两小时的行业研讨会视频,感到前所未有的无力。
这是我需要消化的第三份资料------此前还有一期50分钟的播客和一段40分钟的企业内部录音。如果按传统方式处理,我需要耗费至少5小时进行逐字听写与截图。而deadline就在明天。
我尝试过用NotebookLM,但外国的产品在某些方面与国内的内容有部分不太适应;也试过腾讯的ima,却被"请先将视频转换为文档格式"这个要求彻底击败------我要是有时间转文档,还需要你干什么?
那一刻我意识到,当前知识工作者面临的核心矛盾,其实是海量非结构化音视频数据与有限个人处理带宽之间的冲突。而市面上那些工具,都在用"文档思维"解决"流媒体时代"的问题。
直到我发现了一款名为Ai好记的工具。
在讨论新工具之前,我想先拆解一下为什么那些看起来很美的产品,在实际工作流中会让人抓狂。NotebookLM的问题不在于功能不强大,而在于它根本没考虑过中国用户的真实使用场景;IMA则更多是格式壁垒。
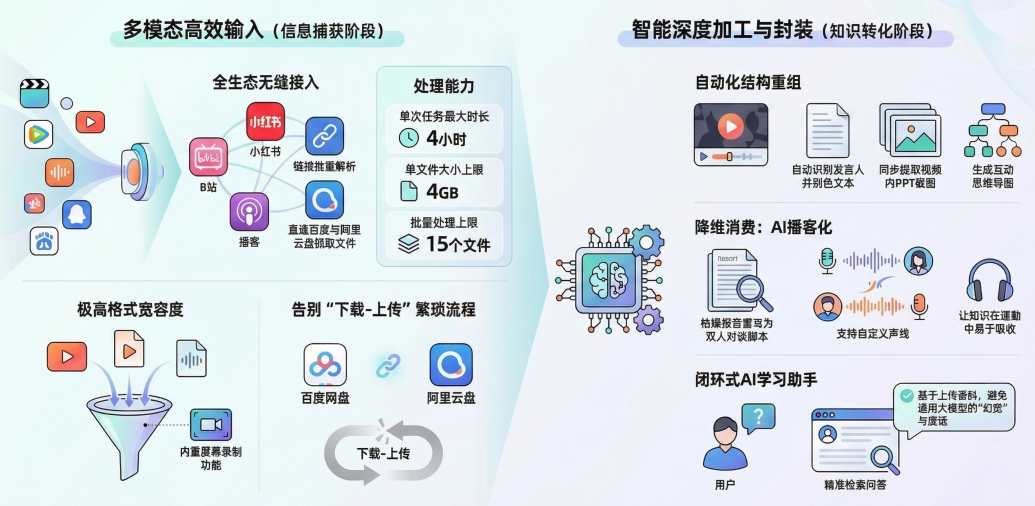
真实工作场景中,我们要处理的是散落在B站、小红书、网盘里的各种格式资料。
基于这个认知,我开始重新定义评估标准:一个真正有用的知识库工具,必须能够无缝接入国内主流内容生态,并提供高度自由的二次编辑与重组能力。
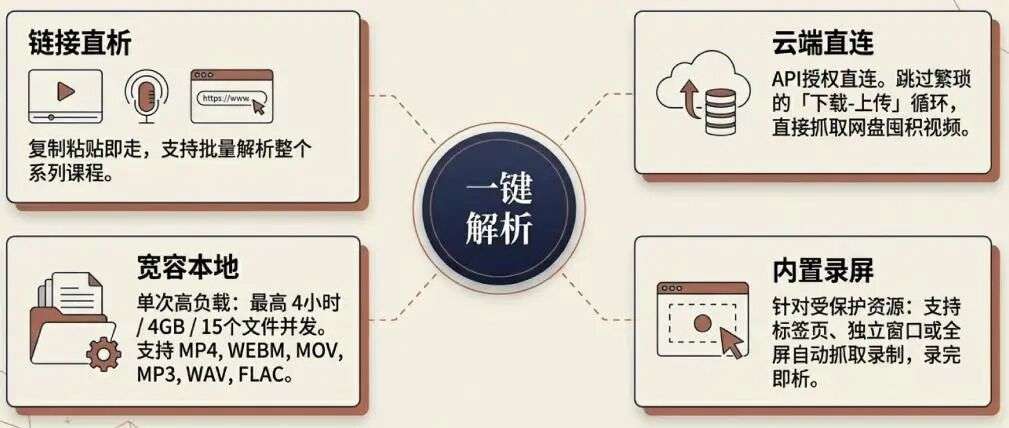
Ai好记支持直接复制粘贴链接进行解析。B站的长视频、小红书和抖音的短视频、知乎的图文问答、小宇宙的播客------所有这些平台的内容,只需要复制链接,粘贴,点击解析。
更重要的是,它支持批量解析,这意味着当你需要处理一整套课程或系列内容时,不需要一个一个手动导入。

但真正让我眼前一亮的,是它对云端数据的处理方式。
我有一个不好的习惯------喜欢把各种课程视频囤在网盘里,然后永远不看。
Ai好记直接打通了阿里云盘和百度网盘的授权接口。登录账号后,系统可以直接抓取网盘内的音视频文件进行解析,完全跳过了"下载到本地-上传到工具"这个繁琐的中间环节。
当然,这里有个前提条件需要说明:受限于网盘自身的服务端限速,如果你要高效使用这个功能,最好有对应网盘的会员。但即使如此,相比传统方式,这已经是降维打击了。
至于本地文件,它的宽容度也让人安心。支持mp4、webm、mov、mp3、wav、flac等数十种格式,单次任务最大承载时长7小时、文件大小4GB、最多15个文件。
对于那些无法通过链接解析或下载的受保护资源,系统还内置了屏幕录制功能------你可以录制浏览器标签页、独立窗口或全屏内容,录制完成后自动进入解析流程。
这套输入机制的设计逻辑很清晰:不是让用户适应工具,而是让工具适应用户真实的内容获取方式。
1、深度加工,当信息变成可操作的知识
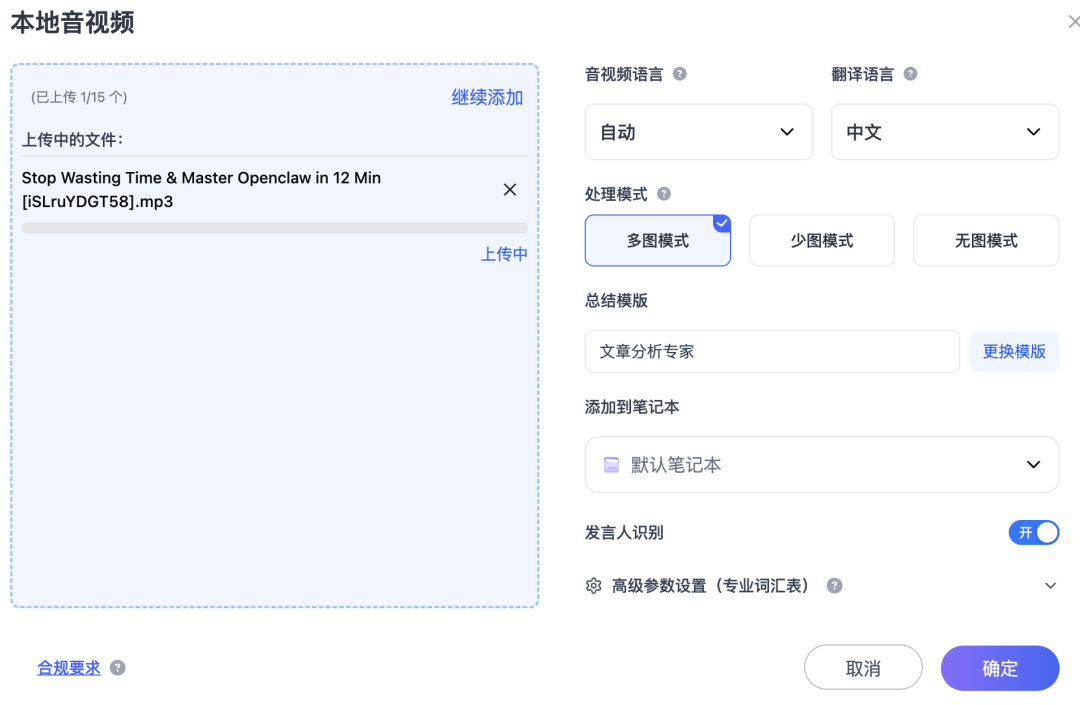
第一步:高信噪比的文本转录与角色分离
将素材导入后,可以选择处理模式和总结模板,并自动添加时间戳。
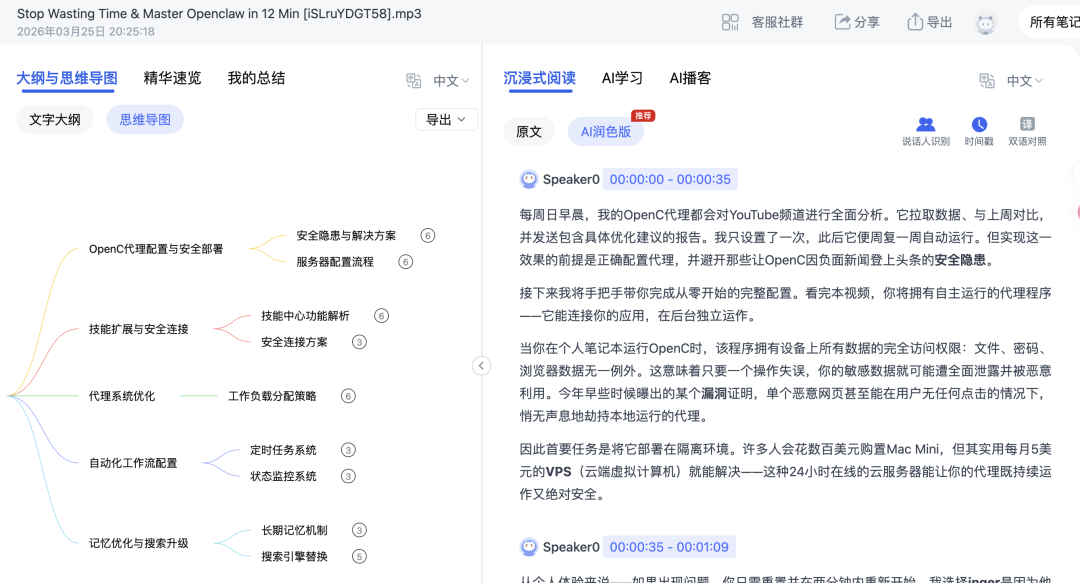
更关键的是,系统提供了"原文"与"AI润色版"双轨对照。润色版会自动过滤掉"嗯、啊、这个"等口语冗余,修正语病,并根据语义进行逻辑分段。
这意味着你不需要再对着充满语气词和重复表达的逐字稿抓狂,可以直接获得一份可读性极高的文本。
如果素材包含英文讲座等海外调研数据,系统支持将其自动翻译为中文(覆盖22种语言),并在界面中呈现中外文双语对照的沉浸式阅读体验。
第二步:视觉资产的自动剥离
在那段2小时研讨会视频中,专家展示了大量关于"小龙虾价格周期曲线"的PPT。传统做法是边看边截图,然后手动整理。
Ai好记的算法能够自动捕捉视频中的PPT等关键画面。在生成的图文笔记中,系统会将这些截图直接穿插在对应的文本段落旁,实现了音、形、意的同步。对于网课和报告分析而言,这彻底免除了手动截图归档的繁琐。
第三步:信息的结构化重组
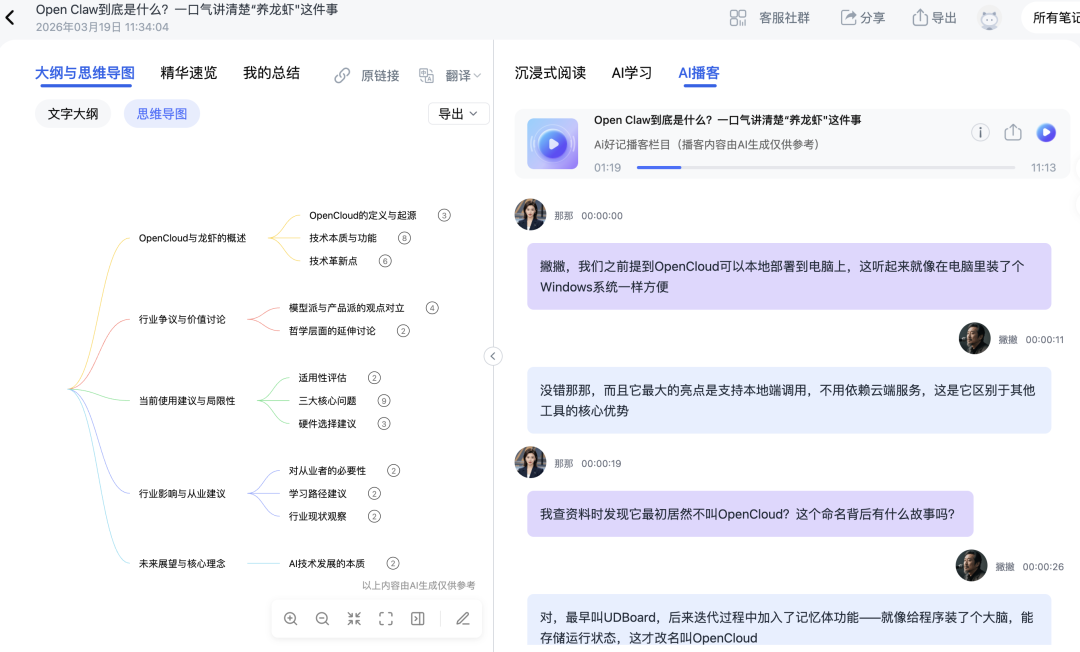
这是整个流程中最核心的环节。系统会在解析完成后,同步生成"文字大纲"与"思维导图"。
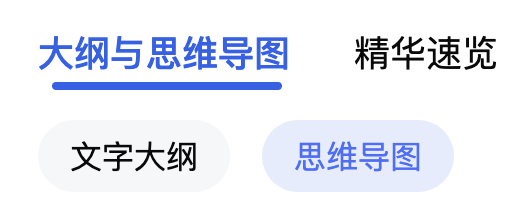
针对小龙虾产业视频,AI会自动提炼出"概述""讨论价值""建议与局限性"等核心节点,并按照时间或逻辑顺序构建树状图。
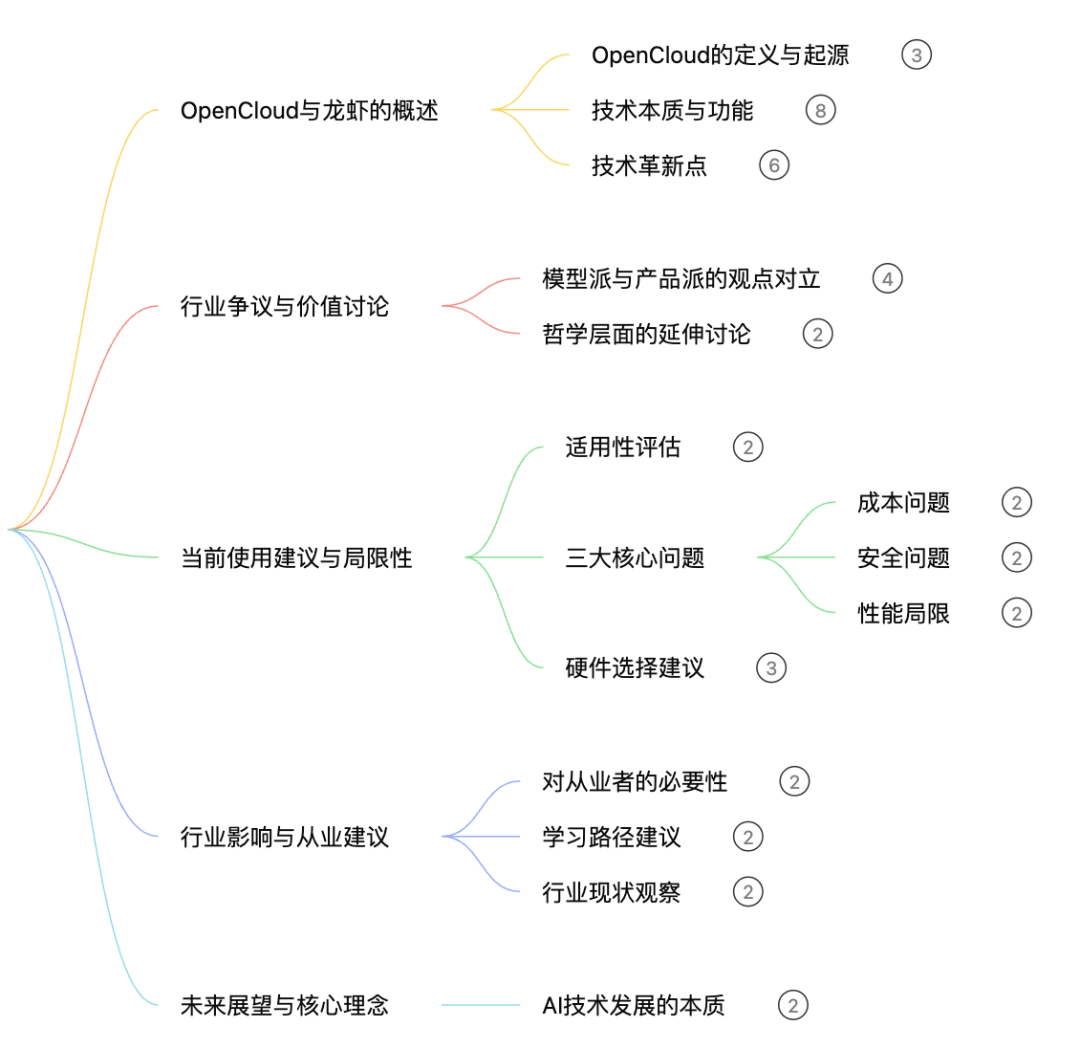
但这个思维导图不是静态图片,而是具备交互能力的导航枢纽。
当你点击导图上的"安全问题"节点,右侧的图文笔记和浮窗播放的视频会自动跳转至该知识点对应的进度。这种联动机制让复盘和定位变得极其高效。
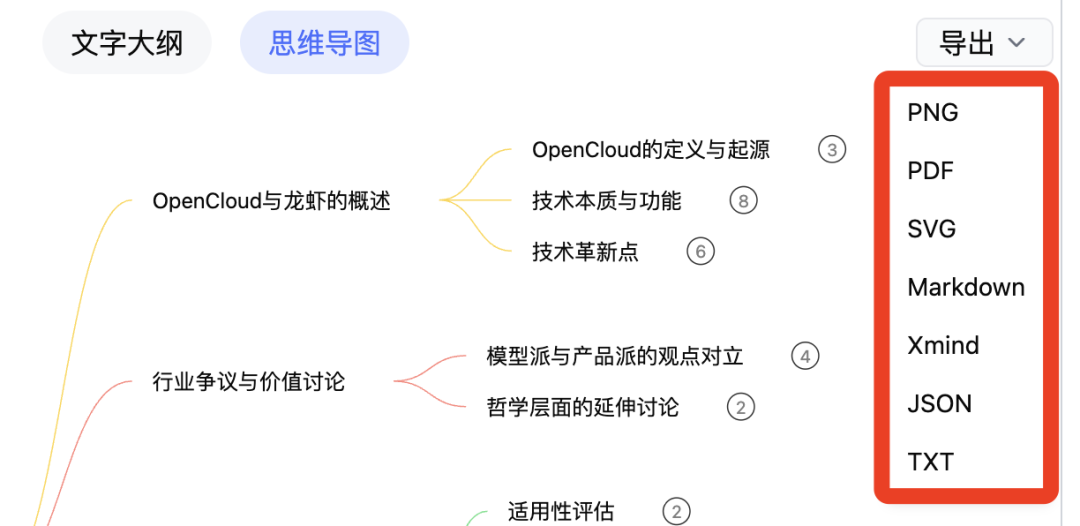
梳理完毕后,该思维导图支持一键导出为PNG、PDF、SVG图片格式,或者Markdown、TXT文本格式,更可直接导出为JSON和Xmind源文件,完美嵌入你现有的汇报PPT或Obsidian知识库中。
2、知识的二次封装,从单向输出到双向对话
完成结构化拆解只是第一步。真正让我觉得这个工具有价值的,是它提供了多种将知识转化为"易消费产品"的方式。
降维消费:AI播客生成
如果你在通勤、跑步等非屏幕时间需要复习资料,AI播客功能提供了极佳的解决方案。
系统利用大模型,将冗长、枯燥的行业报告,重写为一份类似《锵锵三人行》的双人对谈脚本。你不仅可以选择播客的生成语言(支持多种语言转中文播客收听),还可以自定义主持人的声线和名称。
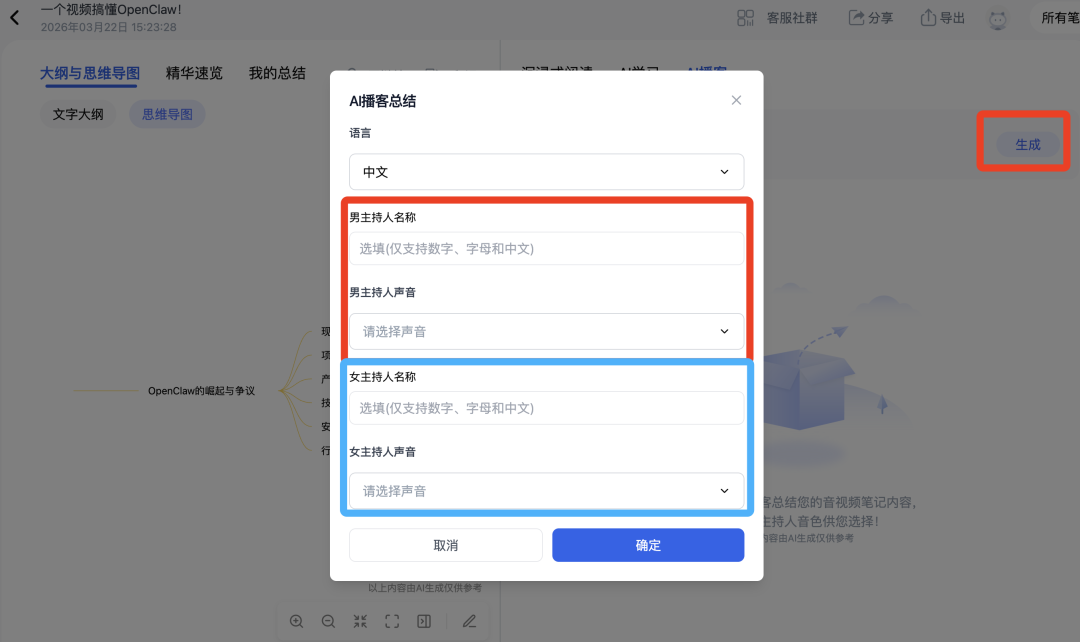
通过这种方式,原本枯燥的知识,变成了一段5分钟的相声式对谈。这种降维消费的方式,极大降低了知识接收的阻力。
闭环式AI学习助手
当你面对深度内容产生疑问时,传统做法是去询问通用大模型,但这容易面临"模型幻觉"或"通用废话"的风险。
Ai好记的AI学习助手,其所有的推理和回答严格基于你当前上传的音视频语料进行检索和推演。系统内置了阅读扩展建议、批判性思考、学习计划、会议总结、自问自答、快速复习等六种学习模式。
你可以直接对助手提问:"自问自答"。AI会根据视频提及的数据和观点进行提炼回答,避免了答非所问。它相当于一个只精读过该份资料的私人导师,随时为你提供"哪里不会点哪里"的划线解释服务。

3、长期管理的基础设施
知识的价值在于沉淀与复用。作为知识库,其基础设施的完善度至关重要。
多端同步机制
Ai好记实现了Web网站端、Android端和iOS端的全平台数据互通。我的使用习惯是:在移动端APP进行碎片的链接收集、上传以及播客复听;在桌面网页端进行沉浸式的大屏阅读、导图精修和深度总结输出。
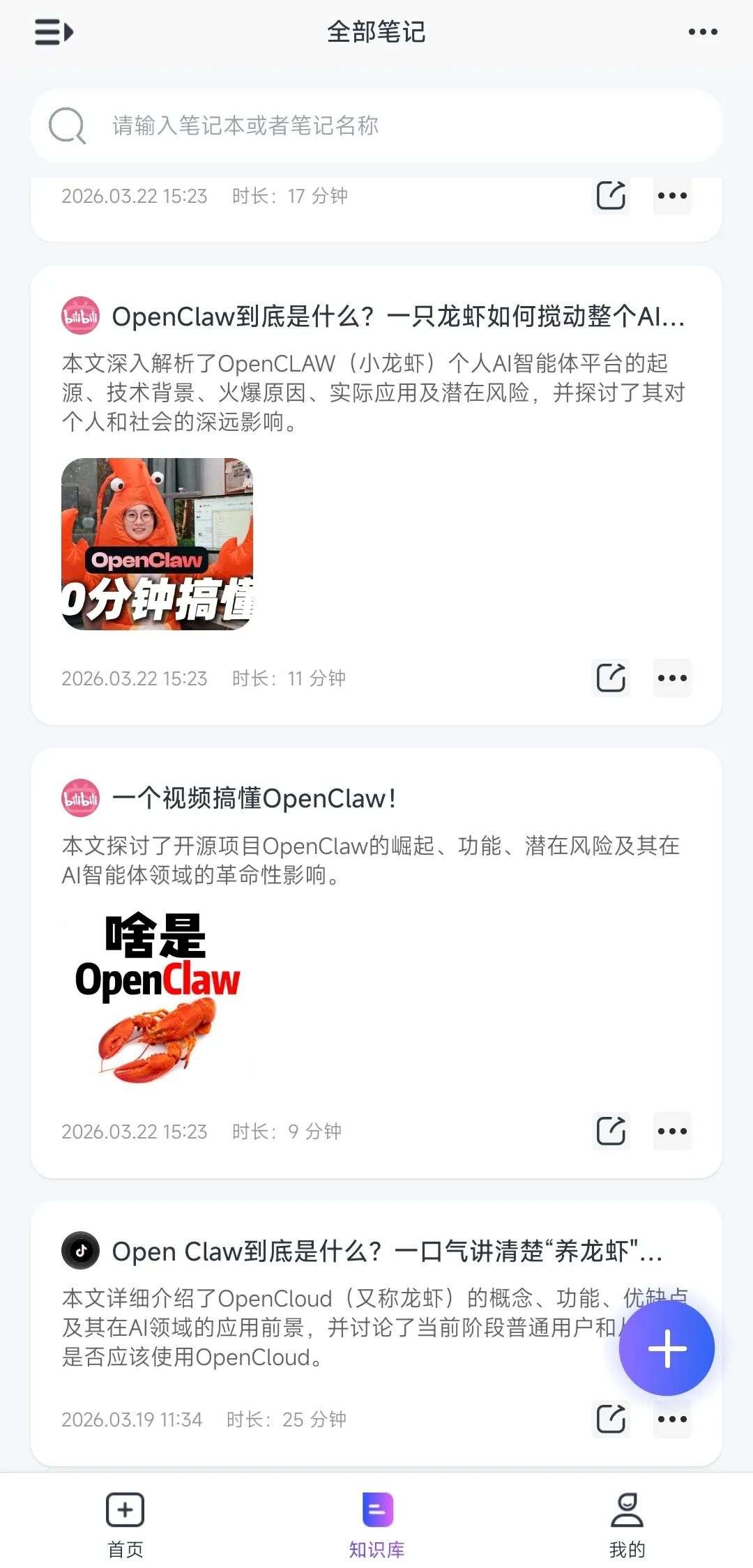
知识库分类检索
所有解析生成的笔记、导图、音频,都会被自动沉淀至个人的"默认笔记本"中。系统支持创建多级目录分类、自定义笔记名称、批量移动与删除,并具备全局搜索功能,确保海量资料的有序排列与快速调取。
零摩擦分享
生成的结构化成果支持一键分享。不仅可以导出本地文件,还能生成带有封面的知识卡片海报,或直接生成网页链接分享至微信群或朋友圈。

4、这个工具适合谁
通过这段时间的使用,我逐渐明确了它的适用边界。
Ai好记并非一个简单的"语音转文字"工具,而是一个集成信息捕获、降噪转录、结构重组、交互学习与多模态输出的"工作流引擎"。
相比于其他软件,它在本土生态接入(全网链接/网盘直连)、文本编辑自由度(Markdown开放编辑)、以及学习模式创新(自定义双人播客/私有数据问答)上,展现出了明显的场景适配优势。
如果你是需要拆解专业网课的备考学生,或是需要提炼会议纪要、竞品分析的职场人士,亦或是寻找选题素材的内容创作者,这个工具能显著提升你单位时间内的信息转化率。
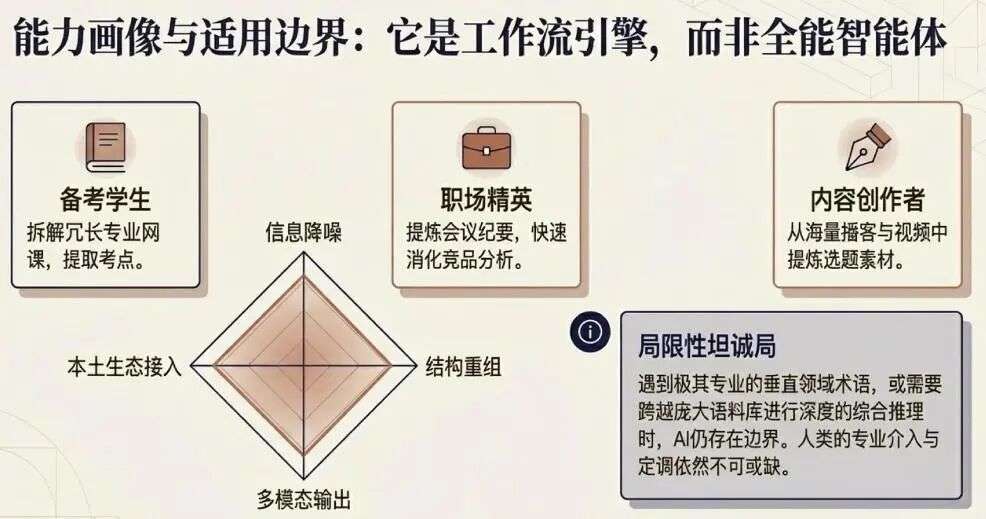
但我也必须说明它的局限:对于那些需要处理极其专业的垂直领域术语、或者需要进行跨语料的综合推理的场景,目前的AI能力仍然存在边界。它更像是一个高效的信息处理助手,而非全知全能的智能体。
这个学习过程中里,我做的不是机械的听写和截图,而是在思考如何将这些信息重组为有价值的洞察。
工具的意义从来不是替代思考,而是释放思考的空间。
你在信息处理中遇到的最大痛点是什么?是找不到合适的工具,还是不知道如何将海量信息转化为可操作的知识?欢迎在评论区分享你的经历。