把一件复杂的事做简单,有两种方式:降低门槛,或者让别人替你做。
团队选择了后者。那个"别人",是我们自己的 AI。
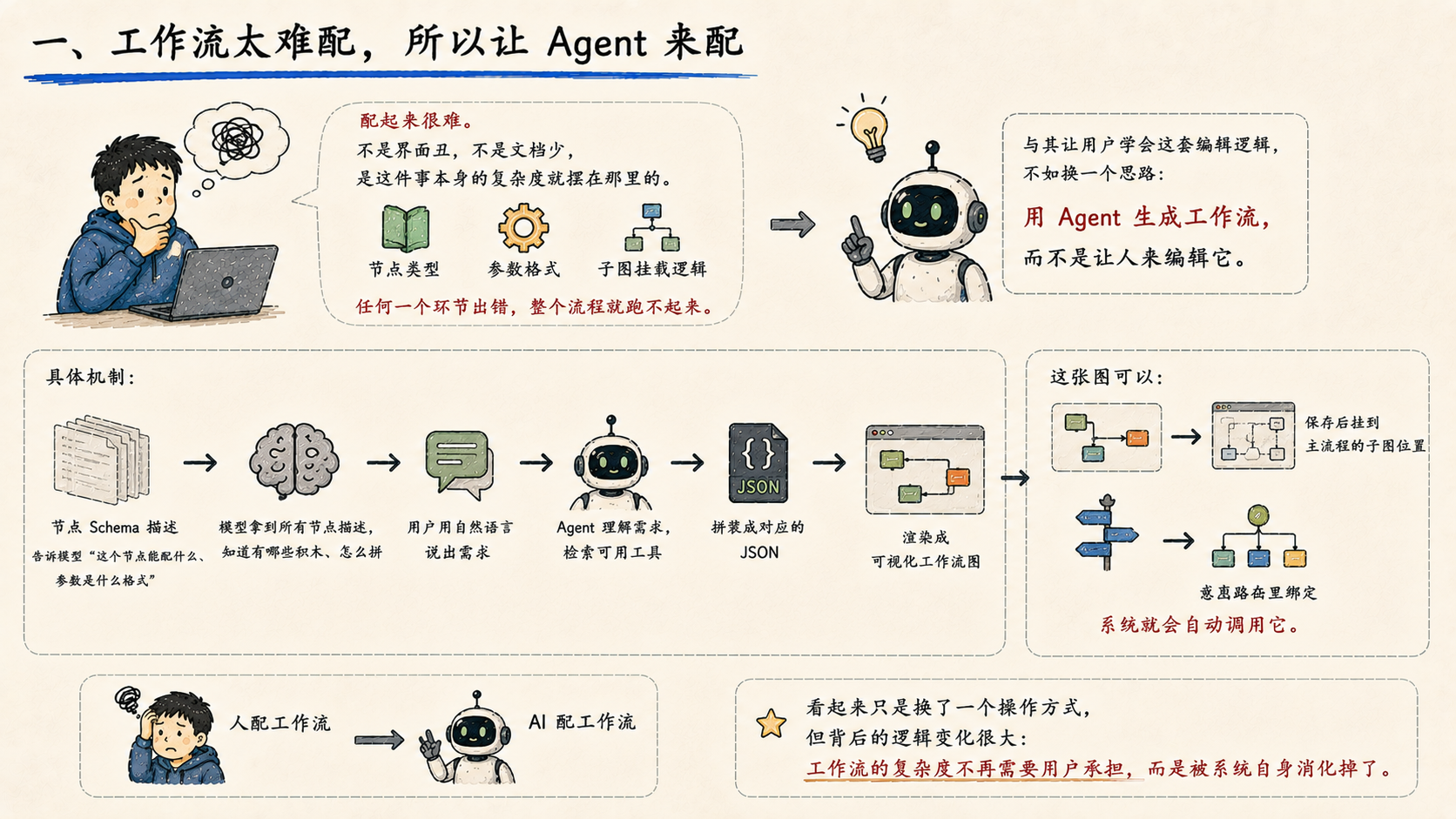
一、工作流太难配,所以让 Agent 来配
昨天上线了工作流初版,可视化节点编排,支持拖拽连线、配置参数。看起来很完整。
但有一个问题从一开始就存在:配起来很难。 不是界面丑,不是文档少,是这件事本身的复杂度就摆在那里------节点类型、参数格式、子图挂载逻辑,任何一个环节出错,整个流程就跑不起来。
与其让用户学会这套编辑逻辑,不如换一个思路:
用 Agent 生成工作流,而不是让人来编辑它。
具体的机制是这样的:
每个工作流节点上都有一份 Schema 描述,告诉模型"这个节点能配什么、参数是什么格式"。模型拿到所有节点的描述之后,就知道它可以用哪些积木、怎么拼。用户只需要用自然语言说出需求,Agent 自动把对应的工具组装成一段 JSON,再把 JSON 渲染成可视化的工作流图。
整条路径是:自然语言 → Agent 理解需求 → 检索可用工具 → 拼装 JSON → 渲染成图。
这张图是可以保存的,保存完之后挂到主流程的子图位置,或者直接在意图路由里绑定这个工作流,系统就会自动调用它。
从"人配工作流"变成"AI 配工作流",看起来只是换了一个操作方式,但背后的逻辑变化很大:工作流的复杂度不再需要用户承担,而是被系统自身消化掉了。
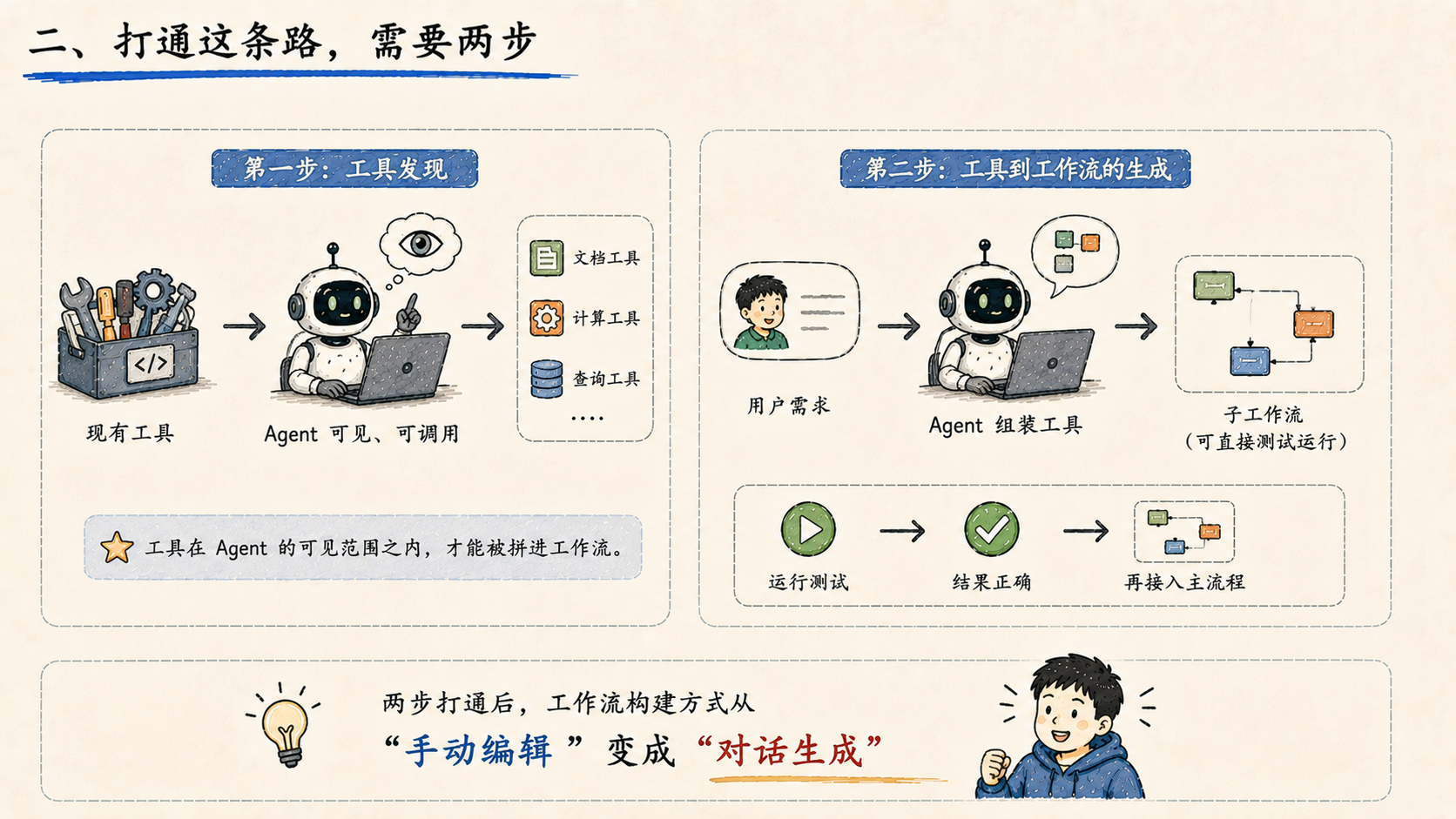
二、打通这条路,需要两步
目前这个方向的实现分两步走。
第一步是工具发现: 把现有的工具暴露给 Agent,让它能看到、能调用。工具在 Agent 的可见范围之内,才能被拼进工作流。这一步是基础,没有它后面的一切都无从谈起。
第二步是工具到工作流的生成: Agent 拿到工具之后,能够根据用户需求,把工具组装成一段结构化的子工作流,生成的结果可以直接测试运行,不需要先挂到主流程。这让调试变得轻量------先跑通子图,确认结果正确之后再接入主流程。
这两步打通之后,整个工作流的构建方式就从"手动编辑"变成了"对话生成"。
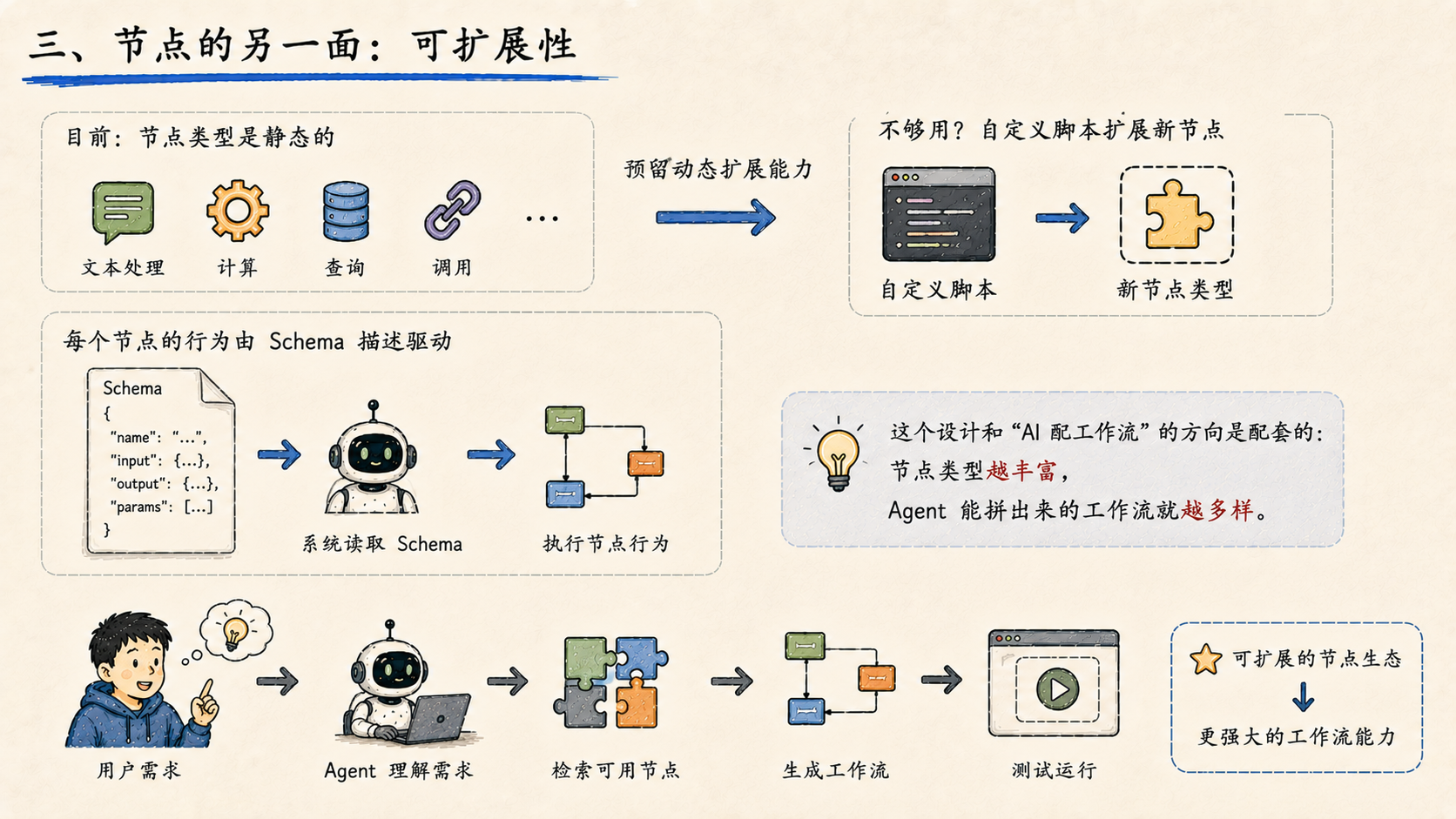
三、节点的另一面:可扩展性
今天还讨论了节点设计的一个细节。
目前的节点类型是静态的,但设计上预留了动态扩展的能力------如果内置节点不够用,可以通过自定义脚本扩展新的节点类型。每个节点的行为由 Schema 描述驱动,系统不需要硬编码节点逻辑,这为后续扩展留了空间。
这个设计和"AI 配工作流"的方向是配套的:节点类型越丰富,Agent 能拼出来的工作流就越多样。
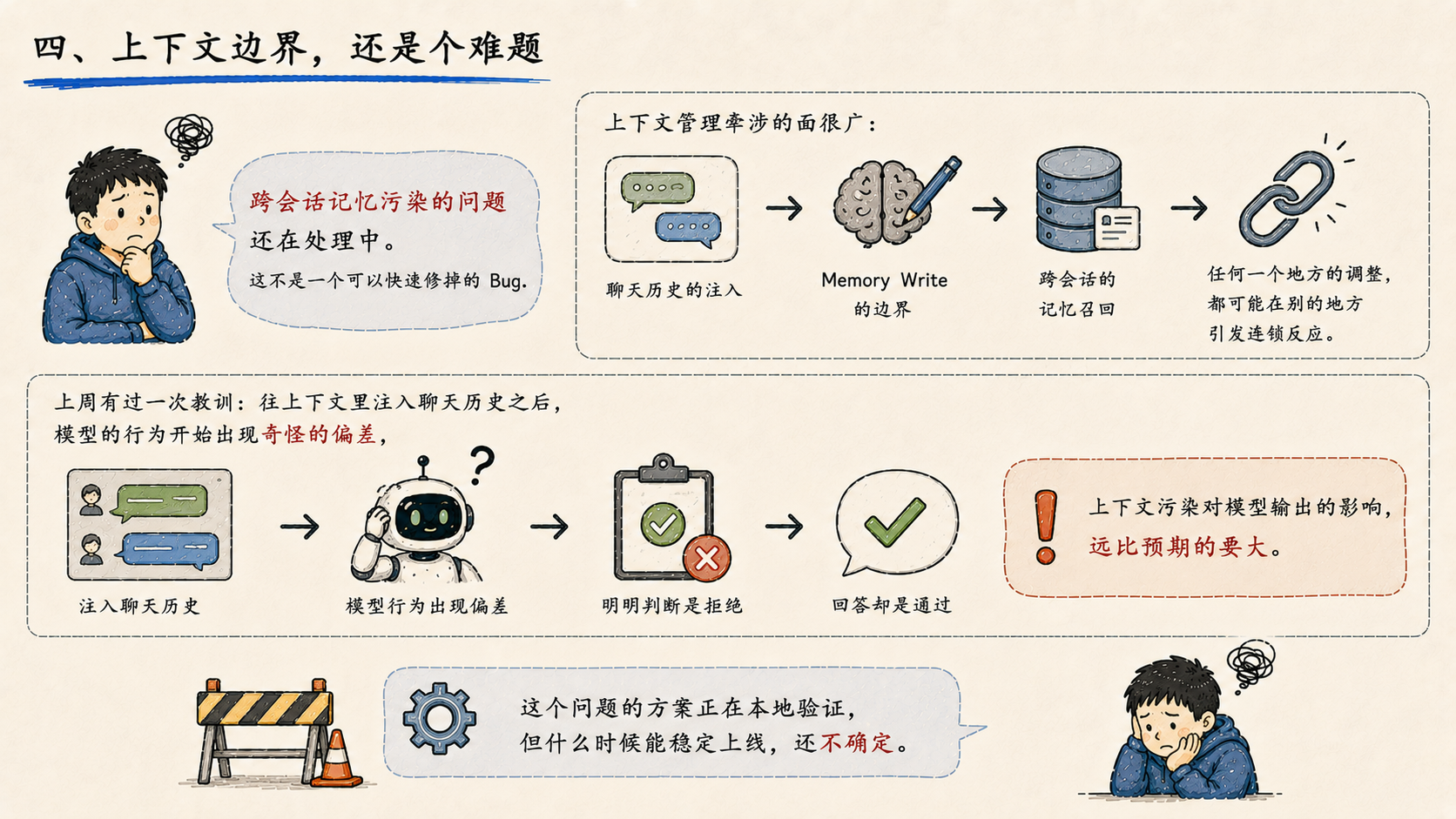
四、上下文边界,还是个难题
跨会话记忆污染的问题还在处理中。这不是一个可以快速修掉的 Bug。
上下文管理牵涉的面很广:聊天历史的注入、Memory Write 的边界、跨会话的记忆召回------任何一个地方的调整,都可能在别的地方引发连锁反应。上周有过一次教训:往上下文里注入聊天历史之后,模型的行为开始出现奇怪的偏差,明明判断是拒绝,回答却是通过。上下文污染对模型输出的影响,远比预期的要大。
这个问题的方案正在本地验证,但什么时候能稳定上线,还不确定。
今天有人问:让 AI 来配工作流,那生成出来的东西,我们自己看得懂吗?
团队的回应是:生成出来会渲染成图,看图不需要看 JSON。如果图也看不懂,那就直接跑一下,看结果对不对。
这可能就是 AI 工具的新交互范式:你不需要完全理解它是怎么做到的,你只需要知道结果对不对。
这,是第二十九天。
**《从0到1:企业级AI项目迭代日记》**记录一个企业级 AI 项目从创意、架构到落地的真实过程。不讲神话,只记录进化。
如果你也在做企业 AI 落地,欢迎留言来聊。或者,把这篇转发给一个正在踩同样坑的朋友。