自动化构建
vs帮助我们自动化构建了,Linux里需要我们自己维护,make是一条命令,makefile是一个文件,make/makefile是用来自动化项目的构建的,构建的意思就是源文件到可执行文件的过程。因为如果一个项目有几千个文件的话,不可能每一个文件都手动用gcc/g++去编译,所以肯定是需要一些自动化构建的工具的。
见见make/makefile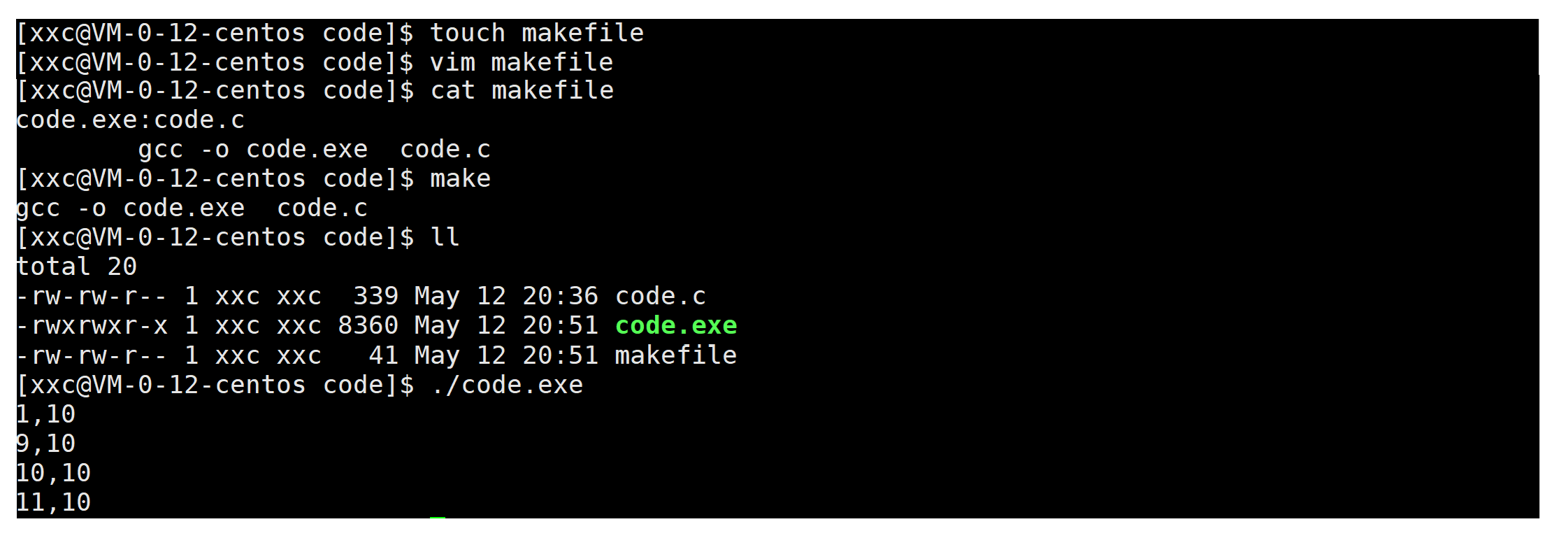
依赖关系和依赖方法
(截图里),makefile(也可以创建成Makefile)里包含了依赖关系和依赖方法,make可以解析makefile第一行的依赖关系,然后根据第二行的依赖方法形成对应的目标文件。
依赖关系就类似于现实中人和人之间的关系,比如父子,人和人沟通的时候,光有依赖关系,别人也不知道你的意图是什么,因此还得有依赖方法,告诉别人你想做什么,所以依赖关系和依赖方法就必须要同时具备才能达到目的。
依赖关系和依赖方法也得需要有合理性,比如你跟别家孩子得父亲没关系,你提的需求人家也不会去实现,反过来你在自己家里跟自己父亲提出一些不合理的需求,你父亲也不会去实现。
那为什么Linux里会出现这两个依赖呢?这个世界,要完成任何一件事,都得需要有依赖关系和依赖方法,就比如你想让腾讯给你发工资,那你得先拿到腾讯的offer,产生了这个依赖关系,人家才会给你发工资,Linux也是属于这个世界,它也需要这两个依赖。
makefile里各部分具体的名称如下。(注意目标文件和依赖文件列表以 : 隔开,如果有多个依赖文件,用空格隔开,每一行的依赖方法起始空一个Tab),依赖关系(目标文件,依赖文件列表),依赖方法会构建形成可执行目标文件的语义。
makefile的基本语法
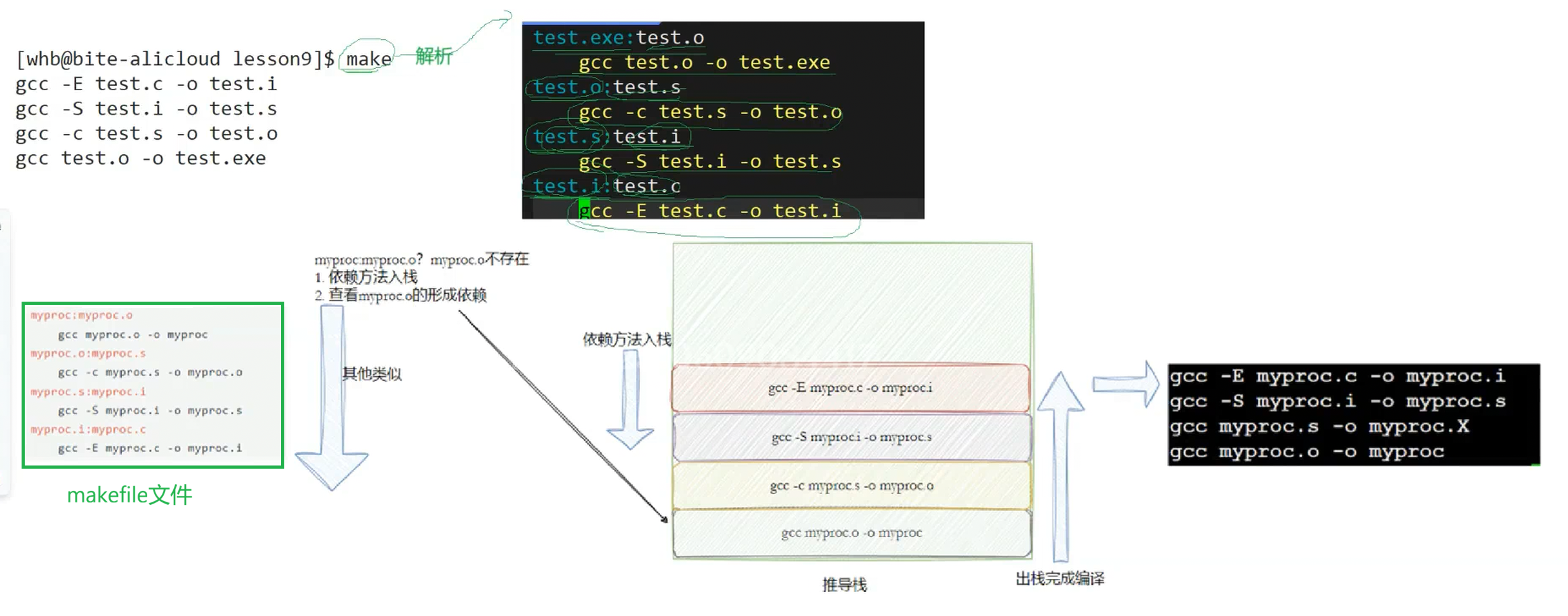
上文说过make会去解析makefile,那具体是怎么解析的呢?make会去扫描makefile,从第一行开始,判断目标文件myproc的依赖文件列表的文件myproc.o是否存在,如果不存在,将该依赖关系的依赖方法入栈,这个栈叫做推导栈,是make命令内部维护的一个语法栈结构,接下去就去看看myproc.o跟哪个文件发生依赖,去看看该依赖文件是否存在,不存在就将依赖方法继续入栈,以此类推。最后myproc.c存在于当前目录,接下来就进行出栈,一个个依赖方法进行执行。综上,make自动解析形成推导栈(依赖关系的集合)。(make的解析过程就像是一个函数递归的过程)。
最佳实践
细节1:依赖关系必须存在,依赖文件列表可以为空
细节2:依赖方法可以是任何shell命令
细节3:clean目标,只是利用make的自动推导能力,让它执行了rm命令,在构建工程的视角,看起来就是清理项目,清理项目,本质就是删除不需要的临时文件
细节4:make命令,后边可以跟"目标文件名",后边跟谁就解析谁的依赖关系和依赖方法,make默认只会推导一条完整的推导链路,make默认只会推导第一个依赖关系默认的推导链(推导链的意思就如上边解释makefile的基本语法下的那张图里的过程,那就是一个完整的推导链)
.PHONY的作用
.PHONY用来修饰目标文件是一个伪目标,本质上,被它修饰之后,该目标文件所属的一条完整的推导链总是被执行。拿code.exe举例:
加.PHONY前: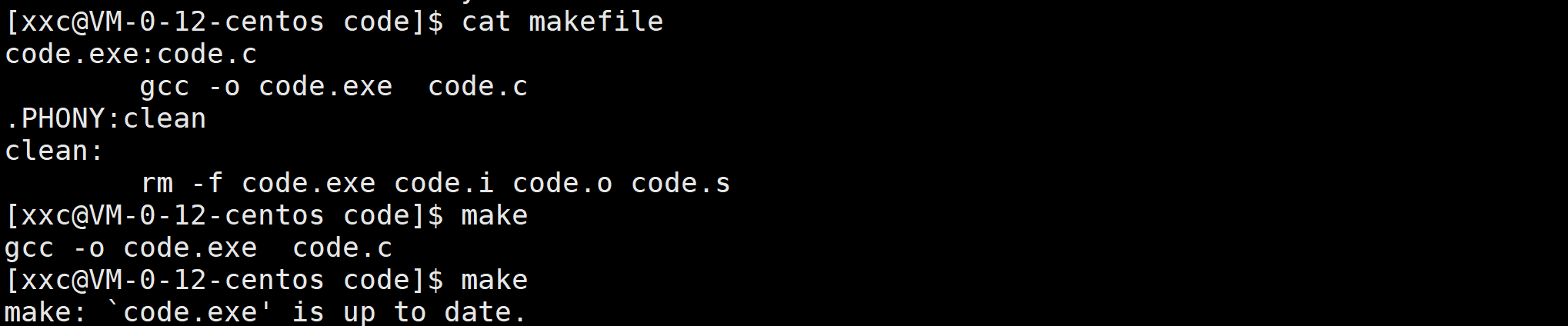
加.PHONY后: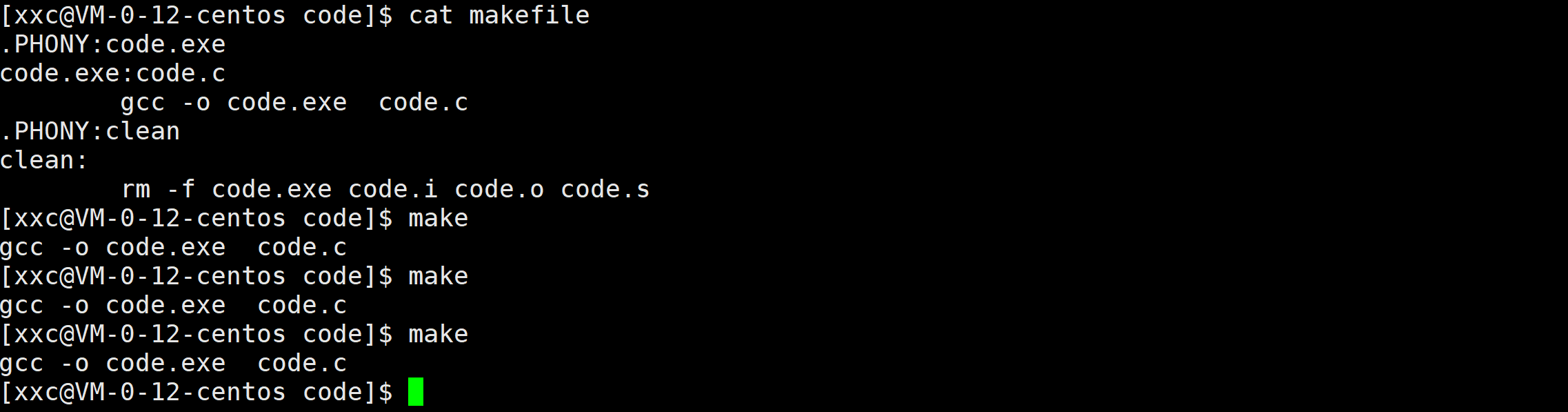
为什么形成可执行程序的时候默认不要加.PHONY?
对于一个没有编译过的源文件,默认只能编译一次,第二次编译就不让编译了,因为makefile和gcc会自动识别到源代码没有发生变化,如果再编译就是浪费资源了,因为如果当前项目里有1万个源文件,但是只有一个源文件编译之后被修改了一下,那重新编译的时候只需要编译这一个源文件就行了,而如果加上.PHONY,那这个1万个源文件不管有没有被修改都要重新编译,效率就低了,因此,.exe默认不用.PHONY修饰是为了加速编译的效率,源文件发生更改才会重新编译。
为什么.PHONY总是被执行,它是如何做到的?为什么之前gcc无法二次编译老代码?
文件是有时间的,stat可以查看文件的时间,文件总共有3个时间,现在先着重看Modify时间,这个时间表示文件新建或者内容被修改的最近时间。Linux下一切皆文件,因此code.c和code.exe都是文件,它们都有对应的Modify时间,如果code.c的时间比code.exe新,那么就可以二次编译,如果没修改过code.c,那code.c的时间肯定比code.exe旧,所以就无法编译。因此只要确保code.c的时间比code.exe新,code.c就一直可以被重新编译,而老代码的时间比其可执行程序的时间旧,自然gcc就无法二次编译老代码。除了修改文件的内容从而去更新文件的时间,touch 已存在的文件名 也可以更新文件的时间。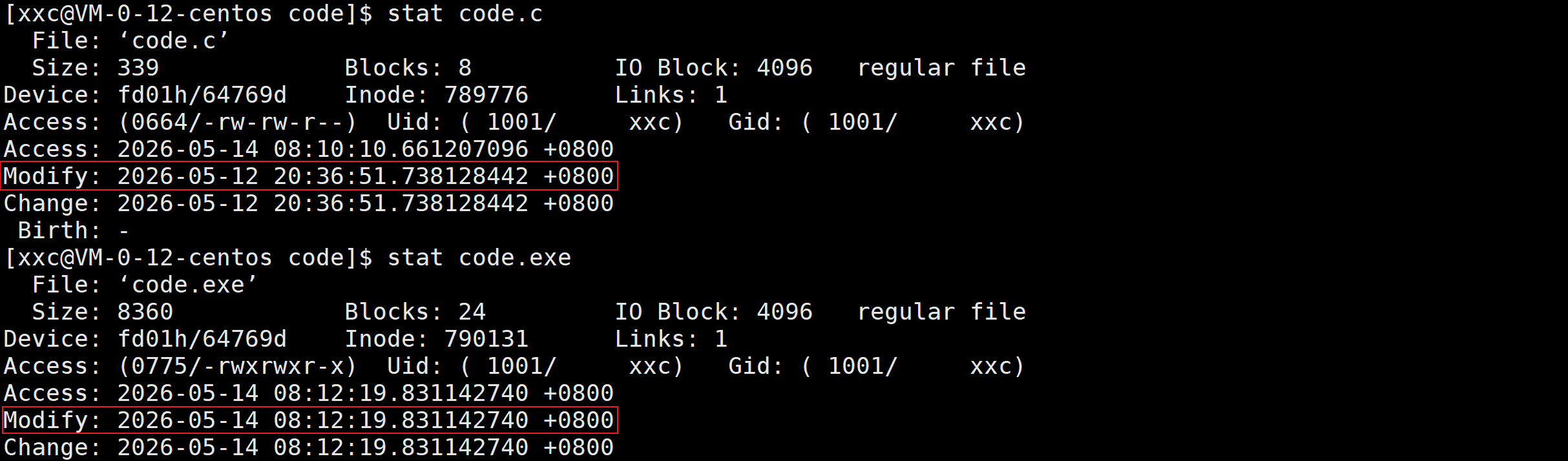
总结一下:源文件是否需要被重新编译看的是源文件和可执行谁更加新,判断文件新旧,根据文件的Modify时间判定。.PHONY总是被执行的原因就是让gcc或者对应的命令忽略对比Modify时间新旧。
谈谈ACM时间
文件 = 文件内容 + 文件属性
修改文件内容,更新的是Modify时间
修改文件属性,更新的是Change时间
Access,文件最近被访问的时间,访问文件分为访问文件内容(cat...),访问文件属性(stat...),Access偏重的是访问文件内容
更改文件属性:
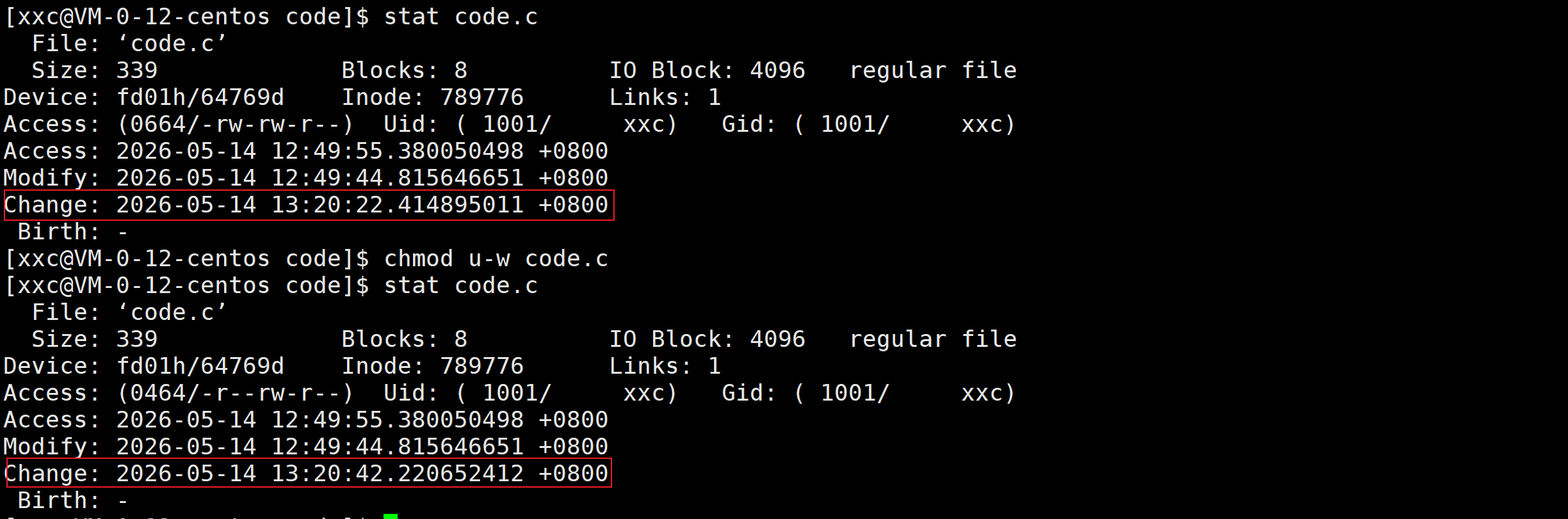
为什么更改文件内容后既会改变Modify时间也会改变Change时间?
因为更改文件内容会影响到文件大小,文件大小属于文件属性,并且Modify时间本身就属于文件属性,所以Change时间也会改变。
为什么访问文件之后,Access时间没有马上更新呢?
查看文件内容的比重远大于修改文件,如果每次查看文件都要更新Access时间,更新时间就是修改文件属性,系统会将修改的文件属性刷新到磁盘(只要修改文件内容就需要从内存刷新到磁盘),如果每次修改属性都刷新一下磁盘,那么这会导致访问磁盘的次数增加,又由于磁盘属于外设,效率本来就低,这就使得OS整体效率低下。因此,访问文件内容,在特定次数之后才会更新一次时间。
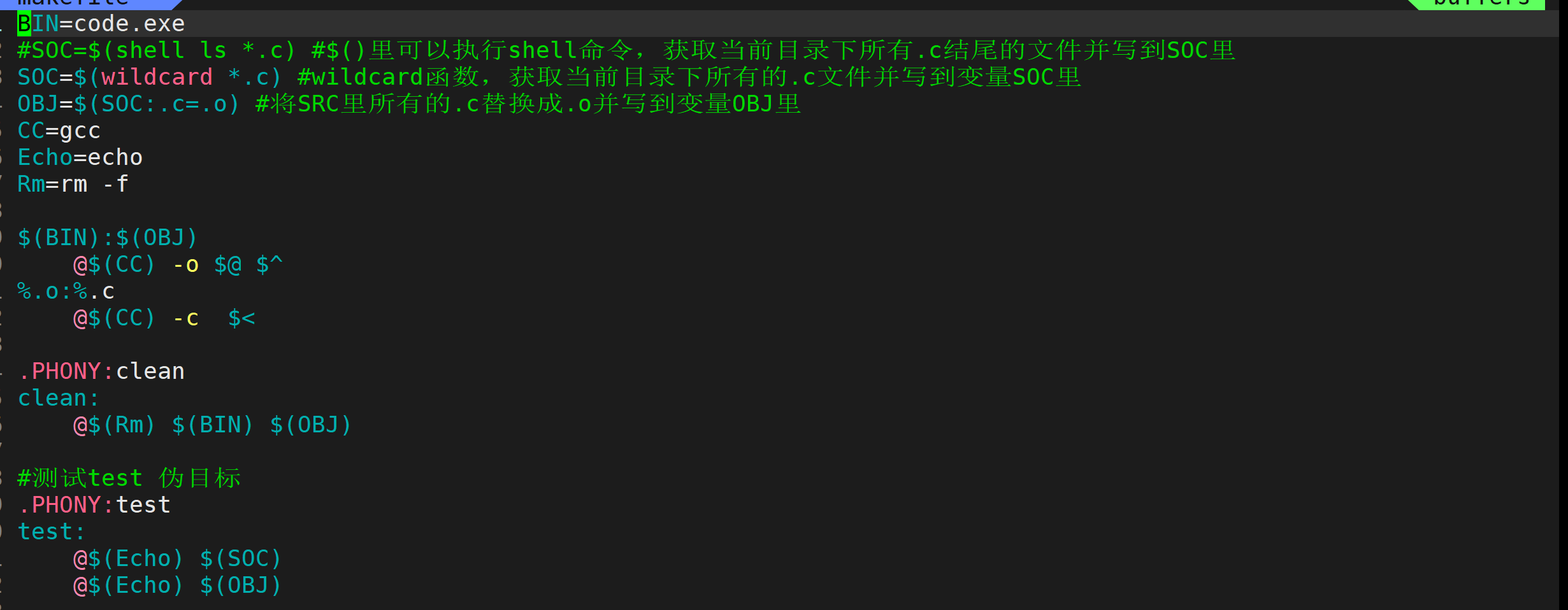
禁止命令回显与创建变量
使用make的时候,命令会回显到屏幕上,现在我不想让命令回显,就在命令前加上@。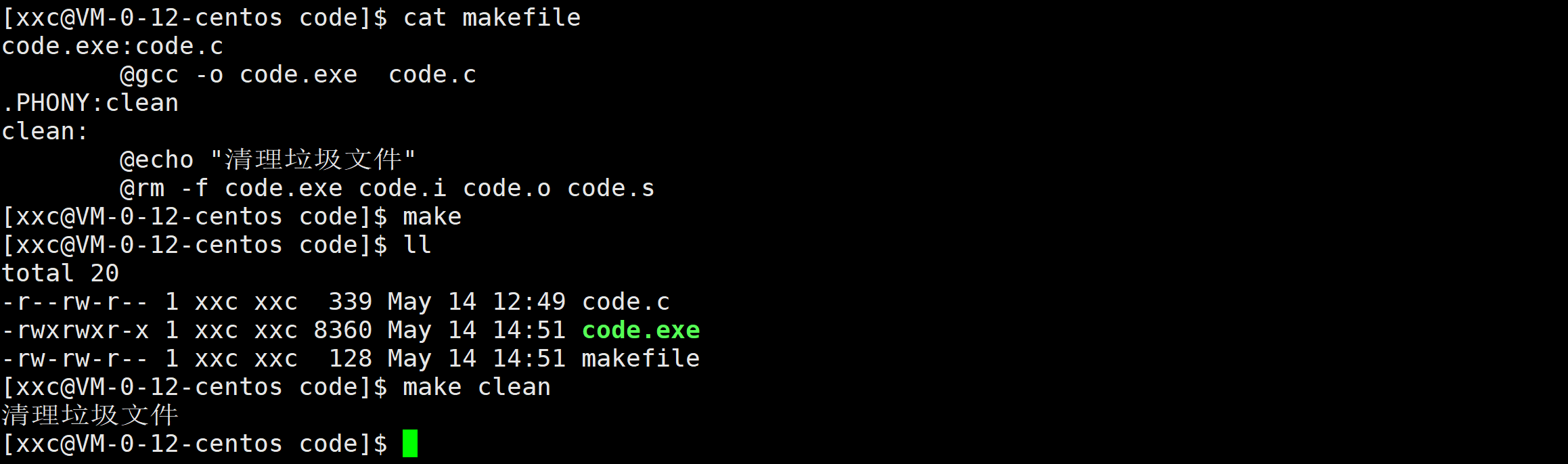
假设现在目标文件的名字变成了text.exe,那我就要打开makefile,将code.exe改成text.exe,如果有成百上千个名字不就太麻烦了吗?因此makefile语法给我们提供了创建变量的方式。在makefile里的一切都被认为是字符串,因此也不需要指定变量的类型,创建变量的时候中间不要带空格,()就是提取变量的内容,类似于宏替换,就比如下边的(BIN)在makefile解释时就直接被替换成text.exe,还有就是括号可以不带,但是带上不会有坑。还有一点要注意,gcc那句指令里如果还是code.exe和code.c,不管BIN和SOR这两个变量的内容改的天花乱坠,gcc编译出来的文件名字依旧是code.exe,因此gcc那句指令也要改。@和^是makefile里的自动变量,@指代的就是目标文件,^指代的就是该目标文件所对应的依赖文件列表。
编译多个文件
上边都是在针对code.c这一个源文件进行编译,现在我想针对多个源文件进行编译。首先得有多个源文件,touch code{1..100}.c的意思就是创建100个文件,分别叫code1.c到code100.c,类似于一个循环。删除的话也可以直接rm code{1..100}.c。
以上这些文件的编译方式就按照规范,先把这些文件编译成.o文件,最后所有.o文件一起链接起来形成一个可执行程序。(下边makefile里的指令就完全是按照以下张图去编译链接的)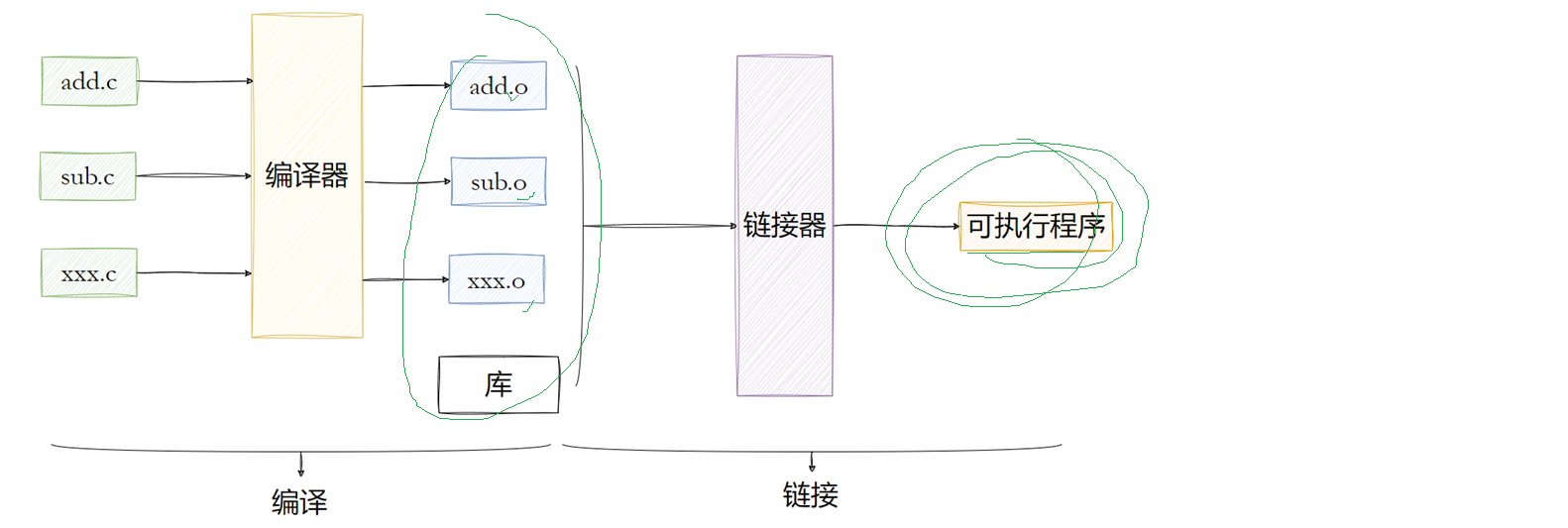
完整通用版本(下图):接下来将makefile里的内容依次解释,将gcc,echo,rm -f包装成变量是为了跨平台时候的通用性,比如要编译C++的话就仅需要将gcc改成g++,根据上文我们通用的编译思路,将所有的.c文件一一编译成对应的.o文件之后再一起链接成可执行程序,对应到下边的代码里就是(BIN)代表的就是最终的可执行文件code.exe,(OBJ)就是所有的.o文件,@代表的是目标文件,^代表的是所有的依赖文件(如果有重复的会自动去重),所以那行指令的意思就是将所有的.o文件链接形成最终的可执行程序code.exe。(注意这里写入OBJ的仅仅只是改变的文件名而已,并没有实际将.c编译成.o呢)。
进度条
两个背景知识
1.回车换行:回车是光标回到当前行的开头,换行是换到下一行,因此回车换行是两个动作。\r(回车)、\n(换行)。(C语言的语法会自动将\n解释成\r\n)。
2.\r\n或者\n是会刷新缓冲区的,以行为单位刷新。如果不带\r\n,则程序会在结束的时候自动刷新。
总结一下:显示器刷新数据按行刷新,要么就是遇到\r\n或者\n刷新,要么就是程序运行结束,缓冲区内部的数据会被自动刷新。(缓冲区在内存里,如果不刷新的话,数据就只会在内存里,不会显示到显示器上)。
如果不想带\r\n或者\n,有没有其他的方式可以刷新缓冲区?C语言里有个fflush函数可以刷新缓冲区,fflush返回值的意思就是刷新了多少字节,它有一个参数,表示的是流,程序默认会打开三个流,叫标准输入/输出/错误流,分别是stdin,stdout,stderr,其中stdin对应的是键盘,stdout对应的是显示器,它们都是文件(Linux下一切皆文件),缓冲区为什么只会刷新到显示器上?为什么不刷新到其他的地方?缓冲区是有归属的,它的归属就是显示器(文件),而显示器对应的文件是stdout,所以fflush的参数就是stdout。
倒计时:(验证上边的\r和fflush刷新缓冲区)
现在想实现一个倒计时功能,效果就是光标在同一个位置,数字依次由9变成0。
cpp
1 #include<stdio.h>
2 #include<unistd.h>
3
4 int main()
5 {
6 int cnt = 9;
7 while(cnt >= 0)
8 {
9 printf("%d\r", cnt); // \r(回车),让光标到这一行的开头
10 fflush(stdout);
11 sleep(2);
12 --cnt;
13 }
14
15 //系统终端命令行提示[xxc@VM-0-12-centos code]也是换行打印的,因此会把最后一个0覆盖掉
16 printf("\n");
17 return 0;
18 }如果现在我要从10开始倒计时呢?运行会发现,打印顺序依次为10,90,80...这是为什么呢?当你向显示器写入12345的时候,显示器会把它们当作一个个字符,包括输出的时候也是这样的。printf打印10的底层逻辑如下。
步骤 1:内存里存的是
10→ 二进制00001010这只是数字,显示器根本看不懂。步骤 2:printf 开始工作(格式化转换),看到
%d,知道要把整数转成字符:数字
1→ 查 ASCII 表 → 字符'1'→ 编码49数字
0→ 查 ASCII 表 → 字符'0'→ 编码48步骤 3:发给显示器,显示器收到 49、48,立刻显示:1和0
因此为什么打印的时候会有90,80....原因就是按照一个个字符打印到显示器上的时候10占两个位置,而打印9的时候,字符9只占一个位置,printf不是有\r光标回退,那原来1的位置覆盖成了9,但是原来0的位置没有被覆盖,所以就变成这种效果了。只需要将%d改成%-2d,左对齐按两个字符打印即可解决。
version1
明确目标:我要的进度条的样子大致为下边这样。
前期分析:进度条需要有3个部分
进度显示部分:类似于下边的效果,只不过实现的时候是要打印在一行的,用\r就可以了,注意细节,\[\]在最一开始的时候就为最终的长度,而不是跟进度 '=' 一起变长。
=
==
===
.........
百分比部分:这里就简单的格式化打印一下即可。
小风车旋转部分:这个部分的作用就类似于,假设程序加载停了,进度是不是要卡在那里,然后这个部分就是表示进度在顺利进行,利用一个字符串 "|/-\\" + 循环 就可以表现出一个顺时针旋转的效果。
processbuffer.c(main.c和processbuffer.h过于简单就不贴出来了)
cpp
1 #include"processbuffer.h"
2 #define SIZE 101
3 #define STYLE '='
4 #include<string.h>
5 #include<unistd.h>
6
7 void processbuff()
8 {
9 const char* mode = "|/-\\";//注意\会当成转移字符开始的标志,要多加个\
10 int len = strlen(mode);
11 char probuff[SIZE];//进度条数组字符串,开101大小,预留一个给'\0'
12 memset(probuff, '\0', sizeof(probuff));
13 int cnt = 0;
14 while(cnt <= 100)
15 {
16 //从空字符串开始,依次变长
16 printf("[%-100s] [%d%%] [%c]\r", probuff, cnt, mode[cnt % len]);
17 fflush(stdout);
18 probuff[cnt++] = STYLE;
19 usleep(30000);
20 }
21 printf("\n");
22 }**关于usleep:**man 3 usleep查出来表示它的单位是微秒,具体换算自行查看,sleep的单位是秒。循环一次30000微秒,循环100次,就是3s。
version2(实用版)
version1只是在描述进度条的原理,但是实际真正我们在下载的时候进度条的进度是跟程序下载的速度有关的,它不是一下子就到百分百的,因此version2诞生了。
main.c
cpp
1 #include"processbuffer.h"
2 #include<unistd.h>
3 double total = 1024.0;//下载总量
4 double speed = 1.0;//下载速度
5
6 void Download()
7 {
8 double curr = 0.0;//实际的下载量
9
10 while(curr <= total)
11 {
12 Flushprocess(total, curr);//更新进度,按照下载进度进行更新进度条
13 curr += speed;//更新下载量
14 usleep(3000);
15 }
16 }
17
18 int main()
19 {
20 //processbuff();
21 Download();
22 return 0;
23 }processbuffer.c
cpp
1 #include"processbuffer.h"
2 #define SIZE 101
3 #define STYLE '='
4 #include<string.h>
5 #include<unistd.h>
6
6 void Flushprocess(double total,double curr)
7 {
8 //实际下载量不能比总量还多
9 if(curr > total)
10 curr = total;
10
10 //total=1024.0, curr=512.0, rate=512.0/1024.0=0.5,但我要的是百分比
11 double rate = curr / total * 100;
12 int cnt = (int)rate;
13 char probuff[SIZE];
14 memset(probuff, '\0', sizeof(probuff));
15
15 /* 关于小风车:
16 * 预期的是只要程序在加载,就一直旋转,
17 * 有可能百分比不在变,可能是网速太慢,但是程序依旧在下载,小风车还得转
18 * 因此小风车跟total和curr无关,跟Flushprocess的调用次数有关
19 * 如果Flushprocess没有被调用,那就说明程序卡住了,小风车就不要转了
20 * */
21 static const char* label = "|/-\\";
22 static int index = 0;
23
23 //我现在要下载的百分比为整数的时候才更新进度条'=',否则只更新百分比
24 //下载多少就直接显示多少'='
25 for(int i = 0;i < cnt;i++)
26 probuff[i] = STYLE;
27
27 printf("[%-100s] [%.1lf%%] [%c]\r", probuff, rate, label[index++]);
28 index %= strlen(label);
29 fflush(stdout);//每打印一次就主动刷新,不要等函数调用结束让他自动刷新
30 if(curr == total)
31 printf("\n");//进度条加载完换个行,不然会被系统的指令提示给覆盖掉一部分
32 }测试
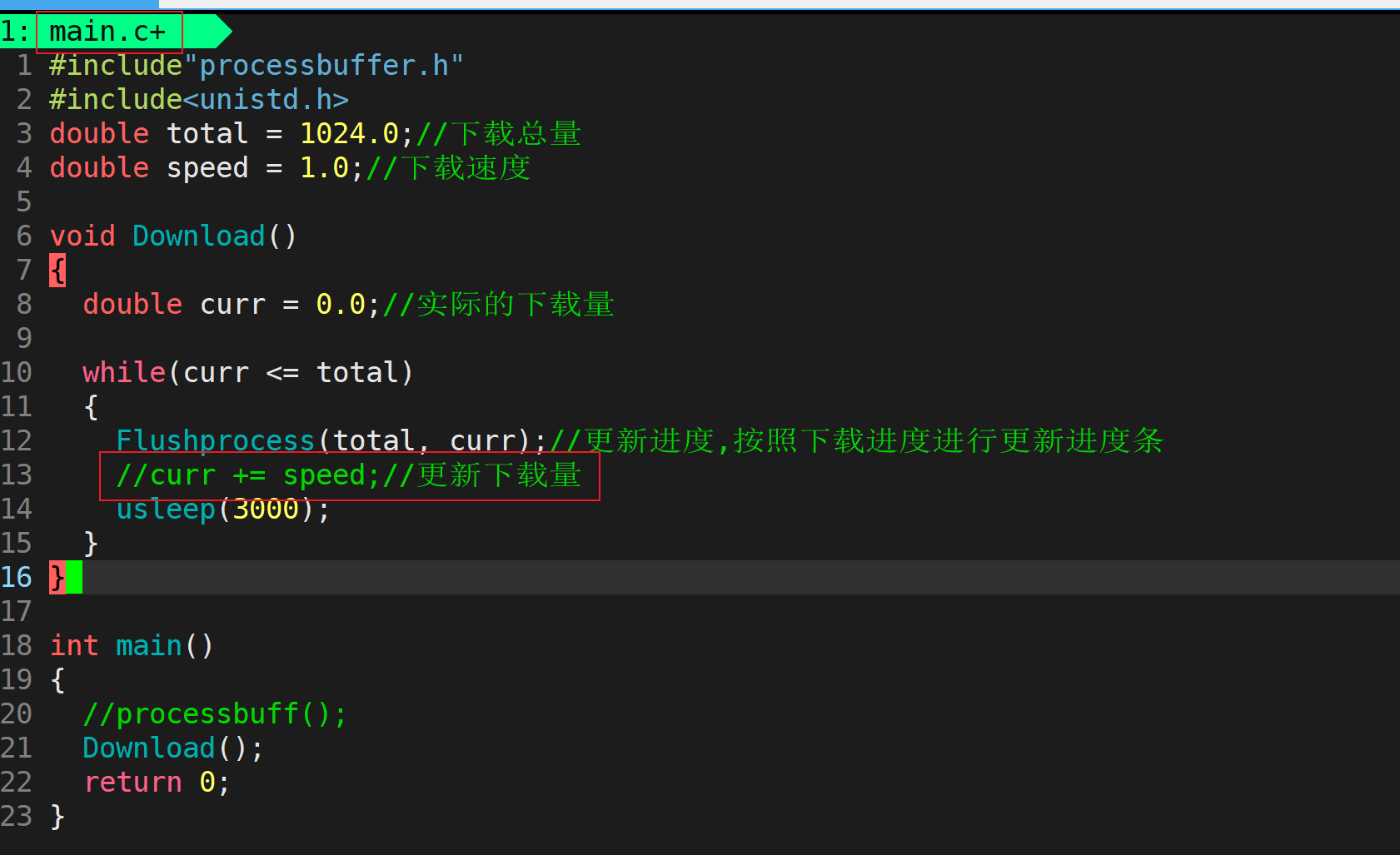
测试1
上边代码注释里说到那个小风车,它在进度条加载百分比不动得时候,如果程序依旧在下载,那么它还是会继续转动。注释掉main.c文件里的curr更新代码就意味着processbuffer.c里的rate不再更新,百分比不动了,看是否依旧能执行。
测试2:更改网速
之前的代码里的网速speed设置的是1.0固定不变的,现在我要将用随机数+变化浮动去代替它,看进度条是否还能正常执行。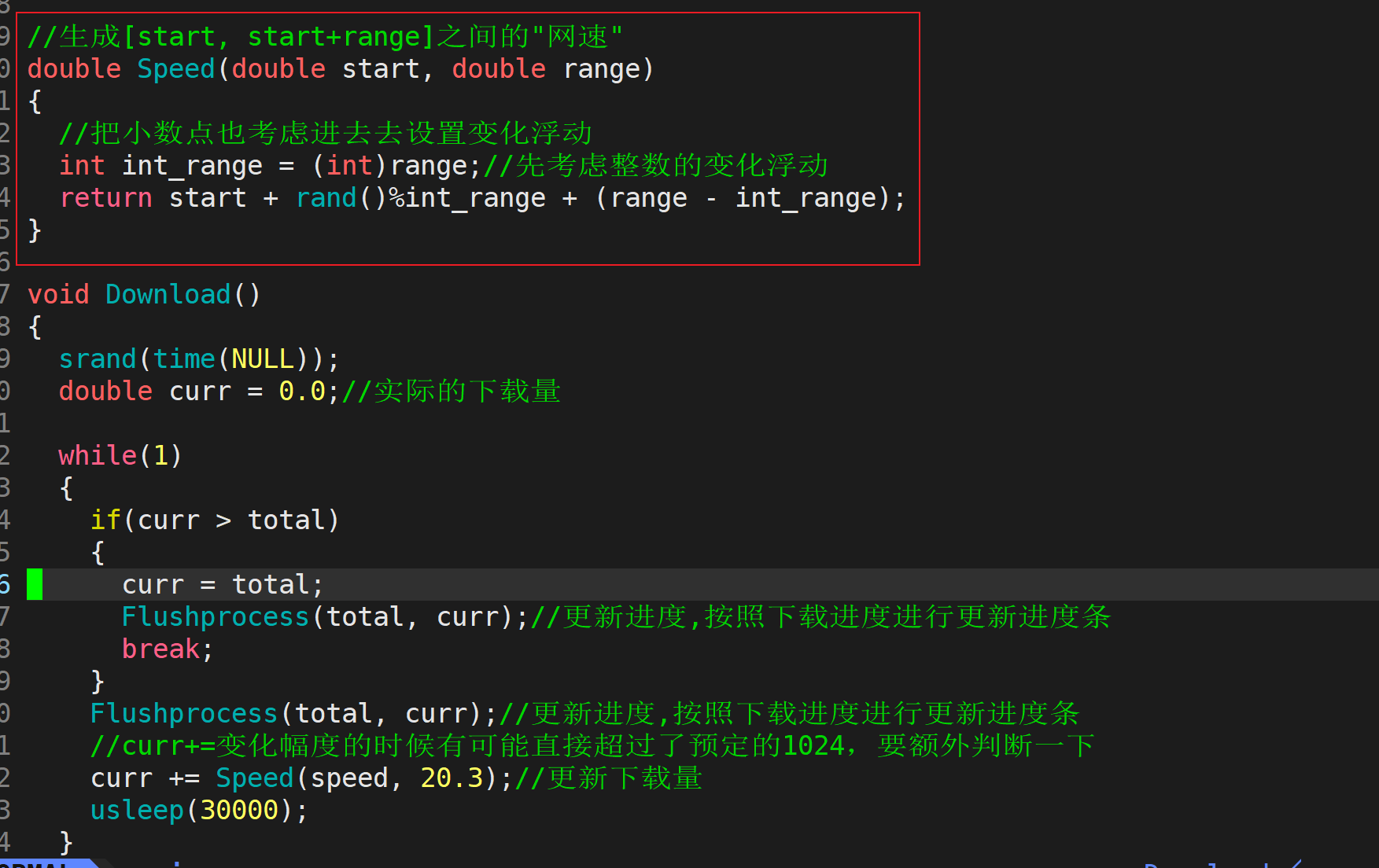
测试3:改变下载量
之前的代码里的下载量始终为1024,但是实际需求是会一直变化的。通过修改total,可以体验到下载不同大小的文件的真实的下载速度的区别。
修复代码的耦合度问题
main.c里的Download函数依赖Flushprocess函数,将来的程序里可能不止下载,还要安装以及各种乱起八糟的地方都要用到这个函数,万一Flushprocess函数的名字发生变化,全部的代码都要修改,如果利用函数指针回调的方式可以降低耦合度,不用去关心底层,只要修改main函数里的函数调用部分就可以了。
最终修复以及添加3条测试的完整main.c
cpp
1 #include"processbuffer.h"
2 #include<unistd.h>
3 #include<time.h>
4 #include<stdlib.h>
5
6 //重命名函数指针类型
7 typedef void (*flush)(double, double);
8
9 //double total = 1024.0;//下载总量
10 double speed = 1.0;//下载速度
11
12 //生成[start, start+range]之间的"网速"
13 double Speed(double start, double range)
14 {
15 //把小数点也考虑进去去设置变化浮动
16 int int_range = (int)range;//先考虑整数的变化浮动
17 return start + rand()%int_range + (range - int_range);
18 }
19
20 void Download(double total, flush cb)
21 {
22 srand(time(NULL));
23 double curr = 0.0;//实际的下载量
24
25 while(1)
26 {
27 if(curr > total)
28 {
29 curr = total;
30 cb(total, curr);//更新进度,按照下载进度进行更新进度条
31 break;
32 }
33 cb(total, curr);//更新进度,按照下载进度进行更新进度条
34 //curr+=变化幅度的时候有可能直接超过了预定的1024,要额外判断一下
35 curr += Speed(speed, 20.3);//更新下载量
36 usleep(30000);
37 }
38 }
39
40 int main()
41 {
42 //processbuff();
43 printf("下载100MB:\n");
44 Download(100, Flushprocess);
45 printf("下载50MB:\n");
46 Download(50, Flushprocess);
47 printf("下载2000MB:\n");
48 Download(2000, Flushprocess);
49 printf("下载89MB:\n");
50 Download(89, Flushprocess);
51 return 0;
52 }版本控制器git
版本控制
通俗理解一下版本控制,其意思就是假设现在你在修改一份实验报告,你修改了三次,你每次修改之前都把上一个版本备份了一下,然后之后要哪个版本就能回退去找的到那个版本,这叫版本控制。
git的版本控制:
结论1:git进行版本控制的时候,是同步记录"变化"来进行版本控制的。意思就是每次修改代码的时候,它会自动对比并记录两次提交的代码之间的区别,记录一下修改的地方而不是做备份,这样一来可以减少存储的工作量。要想回到之前的版本只需要把修改或者增加的部分逆向的做一遍就可以了。
补充:git是一个工具,帮助我们对代码进行版本控制的,而github和gitee是网站(也有客户端),分别是国外的和国内的,底层是git,只不过通过图形化界面的方式更便于操作,受众更广。
结论2:git是一个去中心化的,分布式的版本控制器。
简单操作
git clone 地址
将远端的仓库克隆到本地,其中这个地址就是你对应远端gitee仓库的地址。
linux_study_code(下文简称lsc)是我远端仓库的名字,查看里边的所有文件属性会看到一个.git文件夹,它就是本地git仓库,包含.git的文件夹就被视为是一个工作区,对于本文来讲就是lsc,反之就是一个普通目录。
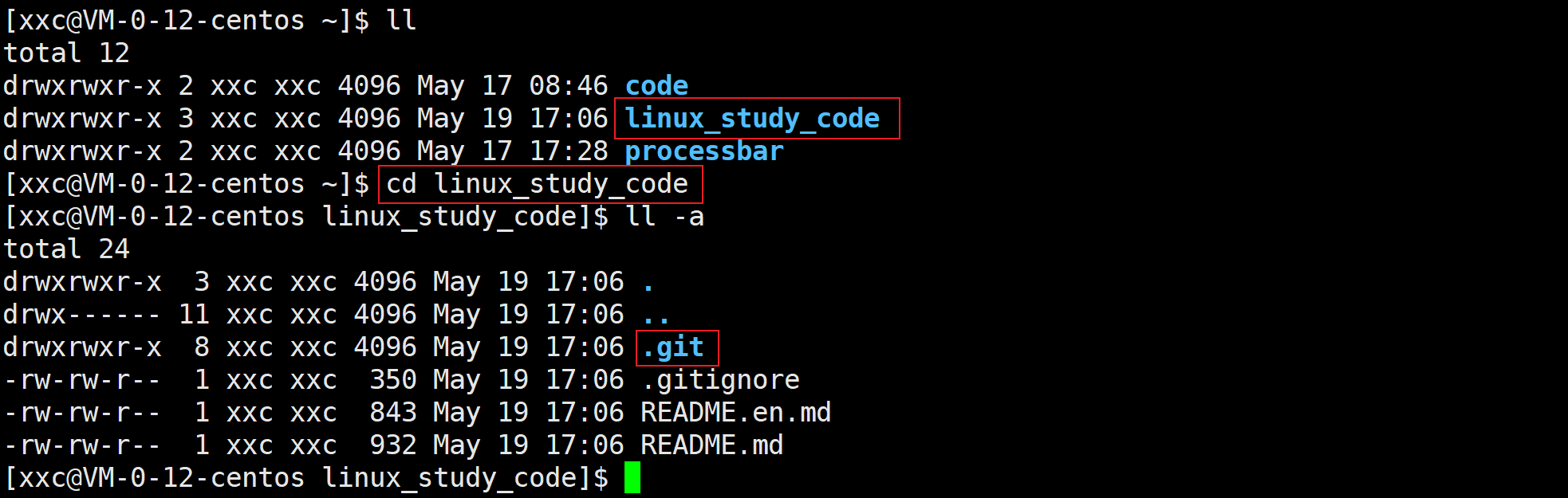
tree .git之后能看到一个objects目录,这里边记录的就是每次的修改记录(git的版本控制)。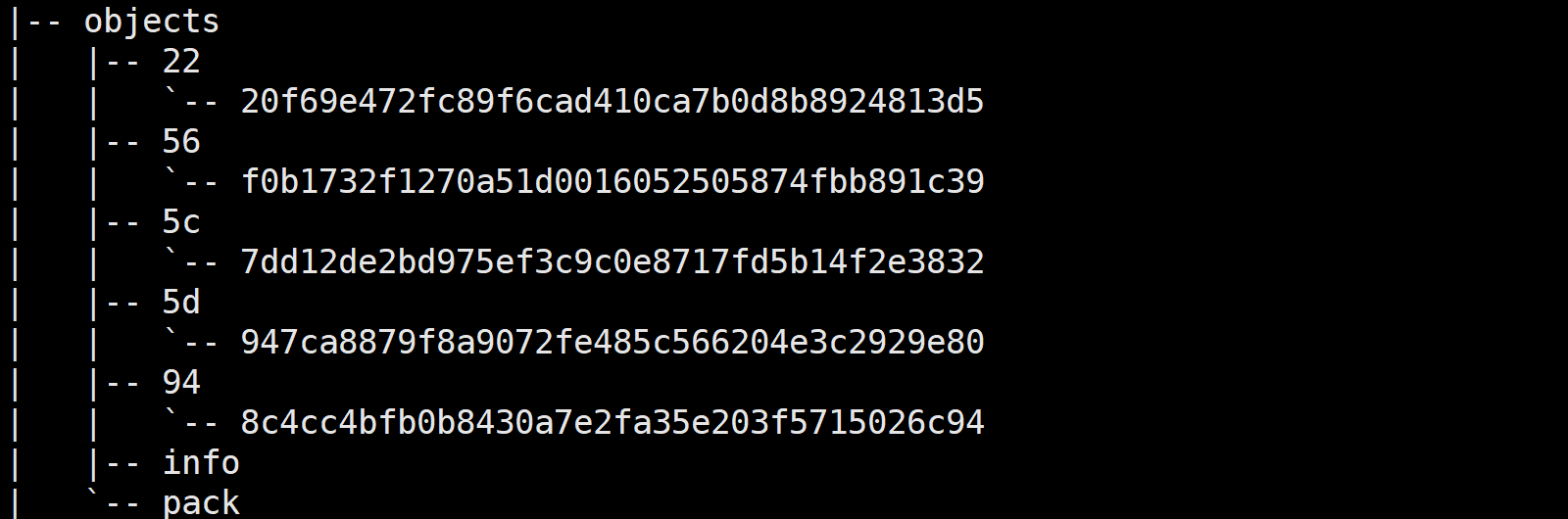
提交代码到远端
我现在手头有一个processbar文件夹,想把它提交到我远端的lsc仓库里,应该如何操作呢?
第一步:把processbar移动到工作区的目录底下 ,但是还没有在.git里。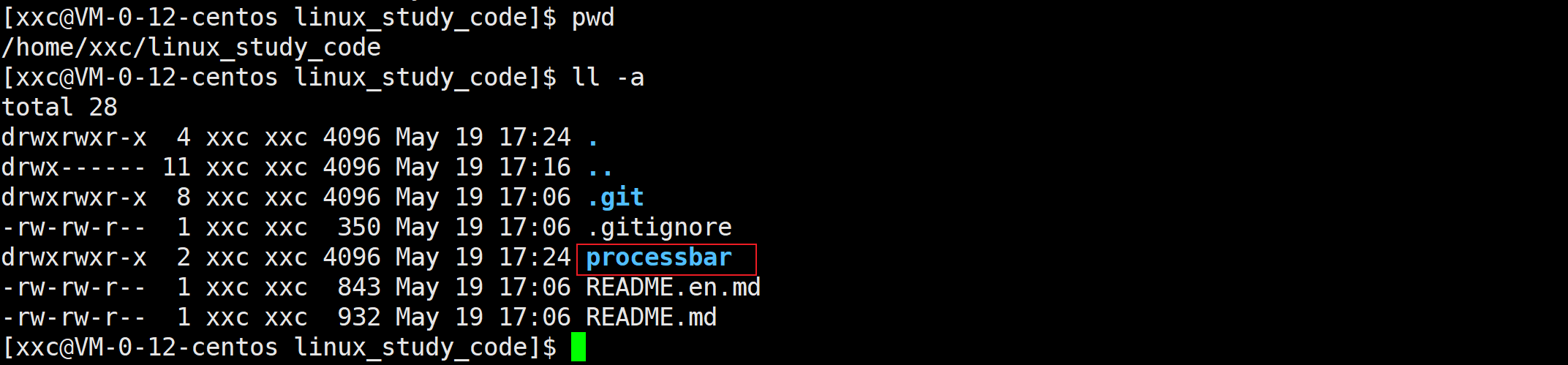
补充:git status查看一下当前工作区和git仓库的状态。通过这种方式也可以知道processbar还没有提交到本地git仓库.git里。
第二步:git add . + git commit -m "提交日志"(""里的内容是提交的代码的修改是什么,就是上文说的git的版本控制,每一个版本的变化记录下来),注意也可以直接写成git add processbar,只不过git add .能将当前目录下所有发生修改的内容全部提交。
上边两句指令的作用是将当前目录下所有发生修改的内容提交到本地git仓库里,也就是.git。那add和commit分别干了什么呢?.git仓库有好几个区域,其中add是将当前目录下指定的文件临时写到.git里的暂存区里,commit是将暂存区里的内容一下子全部提交到修改记录里(这个修改记录才是.git真正的仓库)。

上边说的暂存区就是.git里的index,就是一个普通文件。
第三步:git push
这条指令可以将.git里的内容拷贝、推送到远端,说白了就是将本地修改过后的内容再拷贝一份到远端gitee仓库里。
由上边三步就可以实现本地代码推送到远端了。
补充
git log:查看历史上与本地git仓库有关的提交日志
工作区(lsc)里还有一个.gitignore文件,这是当初在 Gitee 网页端创建仓库时勾选自动生成的 Git 忽略配置文件。在这个文件中配置好的文件、文件夹或文件后缀,都会被 Git 忽略,本地执行提交推送操作时,这些内容不会被追踪上传到远程仓库。
gdb/cgbd调试
程序发布有两种版本,一种是debug版,一种是release版,debug是程序员调试代码的时候用的版本,体积较大。release是测试人员调试用的版本,体积较小,用户使用的就是此版。gcc/g++编译代码时,默认是release版,而gdb是个调试工具,其需要的版本是debug版,因此在用gcc/g++编译的时候,要在后边带上-g,此时编译出来的就是debug版了。
Eg:gcc mycmd.c -o mycmd -g
将源文件编译成debug版的二进制文件之后,可以去验证一下这件事,可执行程序不仅只是一个二进制的集合,内部是有固定格式的,这个固定格式是ELF。readelf -S 二进制文件名 可以读取格式信息的细节,然后再用grep筛选debug就能知道是否该文件是debug版。
开始使用
注意:gdb和cgdb的用法是一模一样的,只不过cgdb更好用一些。以下拿code.exe举例子,cgdb code.exe进入调试,用i和Esc进行光标上下两个分屏之间切换。
l:查看code.exe里的内容,默认从上一次查看的位置开始,每次固定查看10行,也可以l linenum(行号),显示的是以n为中心,上下各5行
r:程序执行,相当于vs里的F5,要配合断点一起使用
b linenum:在指定行处设置断点
i b:查看所有断点信息
d linenum:删除序号为linenum的端点,注意这个序号不是端点所在的行号,而是i b的时候显示的该断点的序号
n:打了断点之后再r程序会直接到断点的位置,此时按n程序就执行下一行,相当于vs里的F10逐过程,如果想重新开始调试再按r就又到了第一个断点的位置
s:逐语句调试(进入函数内部),gdb会自动记录最近一次命令,接下来再想执行s按回车就可以了,其他指令也一样
p 变量/&变量/...:可以查看该变量的信息,就相当于是vs里的监视窗口
display 变量名:追踪变量名,也相当于vs里的监视窗口,上一个指令p是看的结果,display是追踪的变化
undisplay 编号(编号指的是下图圈出部分):取消追踪
until linenum:执行到指定行号(帮助我们运行一个函数内的指定区域的代码,就假设这个函数里有个循环,我不想一直按s,我就想看到循环结果或者看看有没有死循环,就可以用until直接执行到函数内return语句那一行就可以直接看到循环结果了)
finish:执行到当前函数返回然后停止
(注意until是只能在这个函数的范围里指定行号执行,而finish是直接可以执行完这个函数,就比如你现在在调试一个函数,突然不想调试了,就用finish就可以直接执行完这个函数。说白了就是until可以帮助我们直接跳过函数体内的一个代码块(循环),finish是直接可以跳过一整个函数)
c:从一个断点到下一个断点


调试的本质就是找到问题,辅助帮助我们分析问题,gdb作为一个调试工具,它有很多的指令,本质上都是在干一件事,就是帮助我们确定问题出现的范围,从而让我们更好的找到问题,然后去解决。一个工具而已,没什么复杂的。