虽然算法名字中有"回归"这两个字,但它其实是一个分类算法。本篇的任务一共有三个:
- 搞清楚逻辑回归的原理;
- 知道 sigmoid 函数的作用,清楚这个函数是干嘛的;
- 能进行逻辑回归的实现(代码怎么去写的)。
这个代码是很简单的,和前一篇的线性回归差不多,但是还有一些细节需要注意一下。因为它是分类算法,但是线性回归是回归算法,最常用的方式是做二分类,还可以去做多分类,另外这个算法和建模不仅是能做预测分析,还能对未来的一些现象去做预测。比如预测天气,预测薪资,预测房价等等。
核心思想(什么是逻辑回归以及 Sigmoid 公式讲解)
1、逻辑回归概念解析:用于分类问题的统计方法,将输入数据分为两个或多个类别,通过线性组合与非线性转换预测概率。(白话解释:通过分析特征,算出属于某个类别的可能性,帮我们把东西分成不同的组)
2、二元与多元分类:适用于二元分类问题,将输入分为两个类别,也可扩展到多类别分类,输出样本属于某一类别的概率。
3、基本思想:线性组合特征与权重,通过逻辑函数转换,得到0到1之间的概率值,表示数据属于某一类别的可能性。
既然是分类算法,为什么它叫回归呢?对比一下线性回归,在线性回归当中,y 是一个结果也就是输出,而在逻辑回归当中,y 是我们的输入。和线性回归相反,其实就是把输出作为了输入。这是线性回归和逻辑回归的区别以及关联性。第二个,y 是我们的目标列,目标列在线性回归算法里,是连续型的数值。逻辑回归,是分类算法,在逻辑回归当中,就会把 y 作为一个判断的依据条件。比如结果 > 1,就属于 A 类,结果 <=0 就属于 B 类。这是分类算法当中很重要的思想。其实就是把线性回归的结果作为逻辑回归的输入,也就是把线性回归的那个公式拿过去做判断,如果这个 y 大于 0,就是 1 这个类别的,小于 0 就是 0 这个类别的。通过这种方式来分类。
这个和 python 当中的思想是类似的,在 python 当中有用过 pandas,pandas 方法里面有一个 pd.cut() 方法。它的使用会把一个连续型的数据给离散化。比如处理年龄,年龄有 1, 2, 3, 4, ... , 99,从 1 岁一直到 99 岁。假如有一万个数据,并不想知道每个人的年龄到底多少岁,只想知道一个范围,比如年满 18 岁的有多少人?比如 1~18 岁有 300 个人,18~25 岁有 1000 个人,25~40 岁有 2500 人,40~65 岁有 3700 人,65~99 岁有 3500 人。只想统计出在哪个范围,不想统计出每个人的年龄是多少,这种数据其实就给它做了分段处理,类似于连续型数据给做了离散化的处理。这个地方的离散化指的就是分段,也就是做的分类这种效果。
上一篇有讲到鸢尾花数据集。取的是下标为 2 以及下标为 3 的这两列作为线性回归的特征列和目标列,也就是花瓣长度和花瓣宽度。当时选择的是这两列作为 X 和 y,当时为什么没有选择 Species 这列呢?这列是鸢尾花的类型,类型一共有 0,1,2 这三种类型,它是一个离散型数据,而逻辑上我们使用分类算法其实是更合理的,上一篇使用的是回归算法,所以当时就没有用这一列,如果用这一列就用分类算法来做。
本篇使用分类算法,通过鸢尾花四个特征去预测这个鸢尾花到底是哪个类型的花,看它是属于 0 还是 1 还是 2。这种分类算法就是本篇要完成的。
看一下逻辑回归的公式。对于逻辑回归,模型的前面与线性回归类似。
这个公式这里是 ,之前那个是
。这是变量名字,变量名字是随便起的。再看一下这个公式,首先要把它分段处理。如果是二分类,就把它切分成两段。就可以用轴来表示两段。一般来说,用 0 表示正中间,左边是负数,右边是正数。这样在做二分类时候更好区分一些。比如大于 0,就属于 1 这个类别,小于或等于 0 就属于 0 这个类别。这个是我们自己去设定的。它在程序里是没有这样表达的,是习惯上判断大于 0 属于 1 类别,小于或等于 0 就属于 0 这个类别。这就是二分类的主要思想。
假设真实的分类的值为1与0,则模型的预测结果为:
这里的 是模型给预测出来的值。上面有个尖尖的小帽子,表示是预测值。预测为 0 这个类别,为 1 这个类别是多少。也就是前面说的线性回归的输出作为了逻辑回归的输入。0 和 1 这两个类别是预测出来的,那么 0 这个概率有多大?1 的概率又有多大呢?这个概率我们怎么去进行计算呢?这个时候我们就要用到一个函数,Sigmoid 函数。
Sigmoid 函数(也称为 Logistic 函数)是一种常见的非线性激活函数,通常用于将实数值映射到介于 0 和 1 之间的范围。它的数学形式如下:
可以看到,当 时,
,代入到公式里面,
,整个结果就会趋近于 1。还有一种情况,就是当
时,
,代入到公式里面,
,整个结果就会趋近于 0。最终,一切实数,通过这个公式,最后的结果就是介于 0 到 1 之间的。但是这个值,只能无限接近 0 到 1,不可能取到 0 和 1 这两个值的。Sigmoid 函数是单调递增的,这意味着输入值增加时,输出值也增加。这里也可以把它看做是概率,看做是计算某个类别的概率。接下来我们从 jupyter 上用代码来实现一下。
临界值推导
中间临界值是 0.5。首先推导一下为什么 s(z) 的中间值是 0.5。像抛硬币一样,首先设定出来正面是属于 1 这个类别的,也就是先把 s(z) 看成是 1 这个类别,反面就用 1 - s(z) 来表示。1-s(z) 属于 0 这个类别,对应硬币就是抛到反面。现在把 s(z) 看做是 1 这个类别,也就是它预测出来的值一定是 1 这个类别,那么正面的概率一定比反面的概率大,它才能预测出来是为 1 这个类别的。所以根据这个来看,s(z) 一定大于 1-s(z),也就是 1 类别一定大于 0 类别,即 s(z) > 0.5。同样,如果设定 s(z) 属于 0 这个类别,最后结果就是相反的了,s(z) < 1 - s(z),会得出 s(z) < 0.5 的结果。通过这种方式能够判断出来,它的中间值是 0.5。
接下来画一下 Sigmoid 图形,看长什么样子。
Sigmoid 函数可视化
首先第一步导包,涉及到画图,所以要把 matplotlib导进来。然后科学计算库 numpy 也导进来。设置画布大小,设置图形对应的中文字体。Windows电脑设置黑体,Mac 电脑:plt.rcParams'font.sans-serif' = 'Songti SC' ,对应宋体。图形中会出现负号,这个负号也要单独设置一下,避免显示的时候变成方块。
python
# sigmoid函数图
import matplotlib.pyplot as plt
import numpy as np
plt.figure(figsize=(16, 8))
plt.rcParams['font.family'] = 'SimHei' # Windows的字体,如果是Mac电脑这里需要改一下
plt.rcParams['axes.unicode_minus'] = False # 设置负号
z 的范围是负无穷到正无穷,我们画这个图取个对称的范围即可。本篇取 -10 到 10。生成数据。使用 np.linspace 去进行数据生成。它的核心功能是生成指定区间内均匀分布(等间隔)的数值序列。np.linspace(start, stop, num=50) 的主要目的是在 start 和 stop 之间生成 num 个等间距的点。只要参数固定,每次生成的结果完全一样,不包含任何随机性。本次选取 -10 到 10 之间的 200 个数据。这里的点取的越多,线看上去就越平滑,不会是折折弯弯的那种,所以取了 200 个,这个就是 z。然后 y 是公式,定义一下。照着这个公式定义:
python
# 生成数据
z = np.linspace(-10, 10, 200)
y = 1 / (1 + np.exp(-z))
接下来绘制这个图形。线条的粗细,宽度,标题,调整一下。然后展示一下。
python
# 绘制图形
plt.plot(z, y, label='sigmoid函数', linewidth=2)
# 垂直线
plt.axvline(x=0, ls='--', c='black')
# 水平线
plt.axhline(y=1, ls=':', c='black')
plt.axhline(y=0, ls=':', c='black')
plt.axhline(y=0.5, ls=':', c='black')
plt.xlabel('z')
plt.ylabel('sigmoid(z)')
plt.title('sigmoid函数图像')
plt.legend()
plt.show()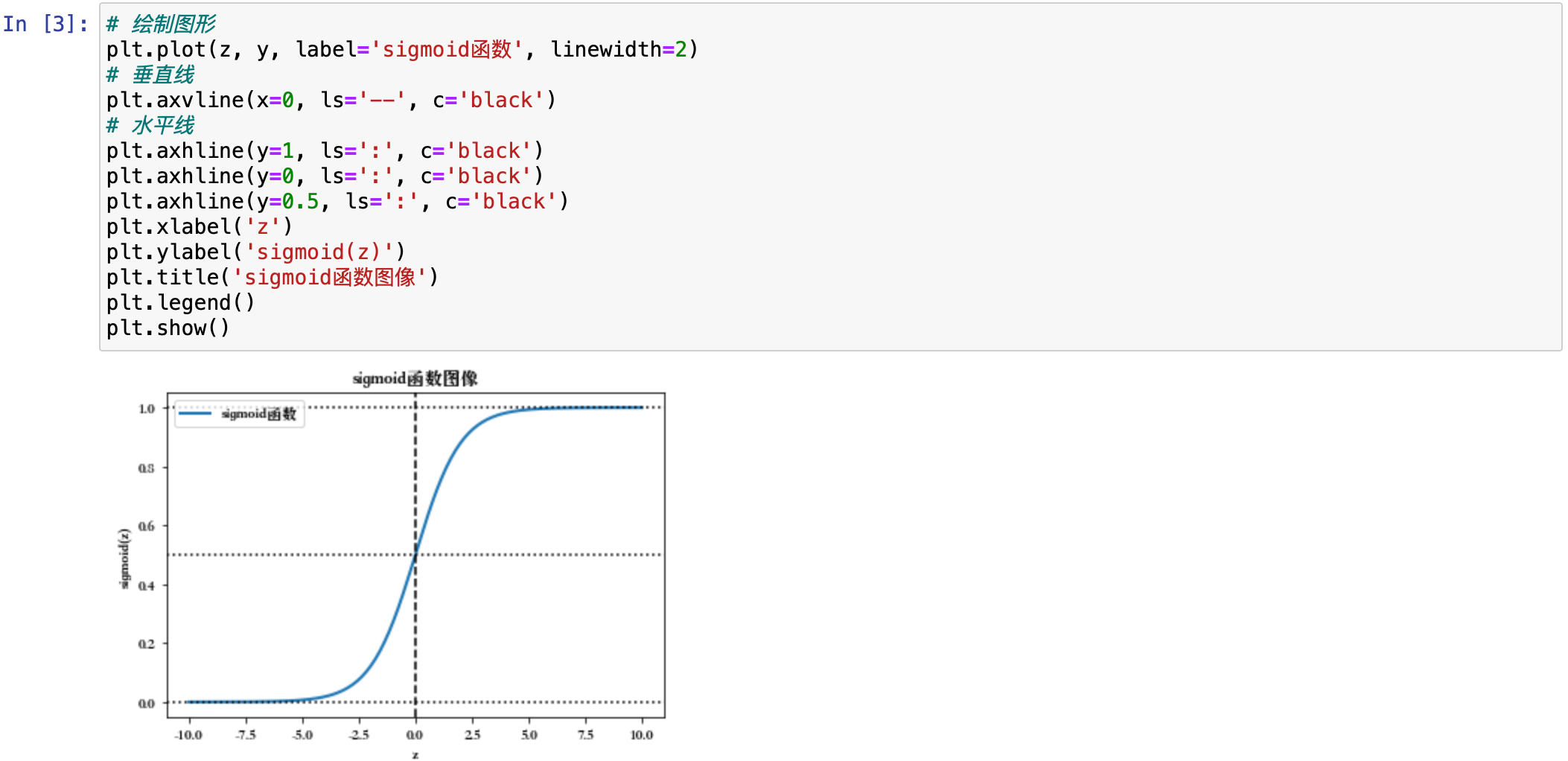
可以看到这个图像在 z 为 5.0 的时候是接近 1 这个值的,在为 -5.0 的时候接近 0 这个值。接下来我们看另外一个,就是损失函数。
损失函数
先介绍一下推导过程:
用 p 表示为 1 这个类别的概率,里面有两个参数,一个是 x(这个 x 是输入),一个是 w(线性回归涉及到的),根据线性回归这个公式来的,所以需要这两个参数。
第一步,计算概率,假如预测出来为 1 的概率,用 p(y=1) 来表示。还有两个参数拿进来,一个是 x,一个是 w,为 1 的时候这个概率等于s(z),也就是 p(y=1|x,w) = s(z) ------ 式子1。
第二步,当为 0 这个类别的时候,还是要传这两个参数,p(y=0|x,w) = 1 - s(z),0 这个类别的概率是 1 - s(z) ------ 式子2。最后要把式子1和式子2合并起来。
第三步,合并两个式子。y 这里不指定是 1 还是 0 了。p(y|x,w) = s(z)^y*(1-s(z))^(1-y)。x 和 w 的条件下 y 的概率就等于 s(z) 的 y 次方乘上 1-s(z) 的 1-y 次方。这是式子1和式子2合并起来的结果。最后可以验证一下,当 y=1:公式自动退化为 s(z)。当 y=0:公式自动退化为 1−s(z)。
该公式的数学背景:伯努利分布
从概率论的角度来看,逻辑回归处理的是二分类问题,其输出服从伯努利分布(Bernoulli Distribution)。伯努利分布描述了一次实验中只有两种可能结果(成功/失败,1/0)的概率分布。如果一个事件发生的概率是p,不发生的概率是 1−p,那么对于随机变量 Y(取值为 0 或 1),其概率质量函数(PMF)的标准定义就是:P(Y=y)=p^y * (1−p)*(1−y),y∈{0,1}。
损失,预测值和真实值之间的差异。损失函数就是求它的最大似然函数。在逻辑回归中,损失函数通常是对数损失函数(log loss),它根据模型的预测概率和真实标签来计算损失。
为了方便求解,我们取对数似然函数,让累积乘积变成累积求和:
我们可以将上式的相反数作为逻辑回归的损失函数(对数损失函数):
取反后其实就是将最大值变成了最小值,这个函数就是逻辑回归的损失函数。
损失函数与sigmoid
接下来看一下这个图形,这是基于损失函数画出来的图形。
python
import matplotlib.pyplot as plt
s =np.linspace(0.01,0.99,200)
for y in [0,1]:
loss = -(y*np.log(s)+(1-y)*np.log(1-s))
plt.plot(s,loss,label=f"y={y}")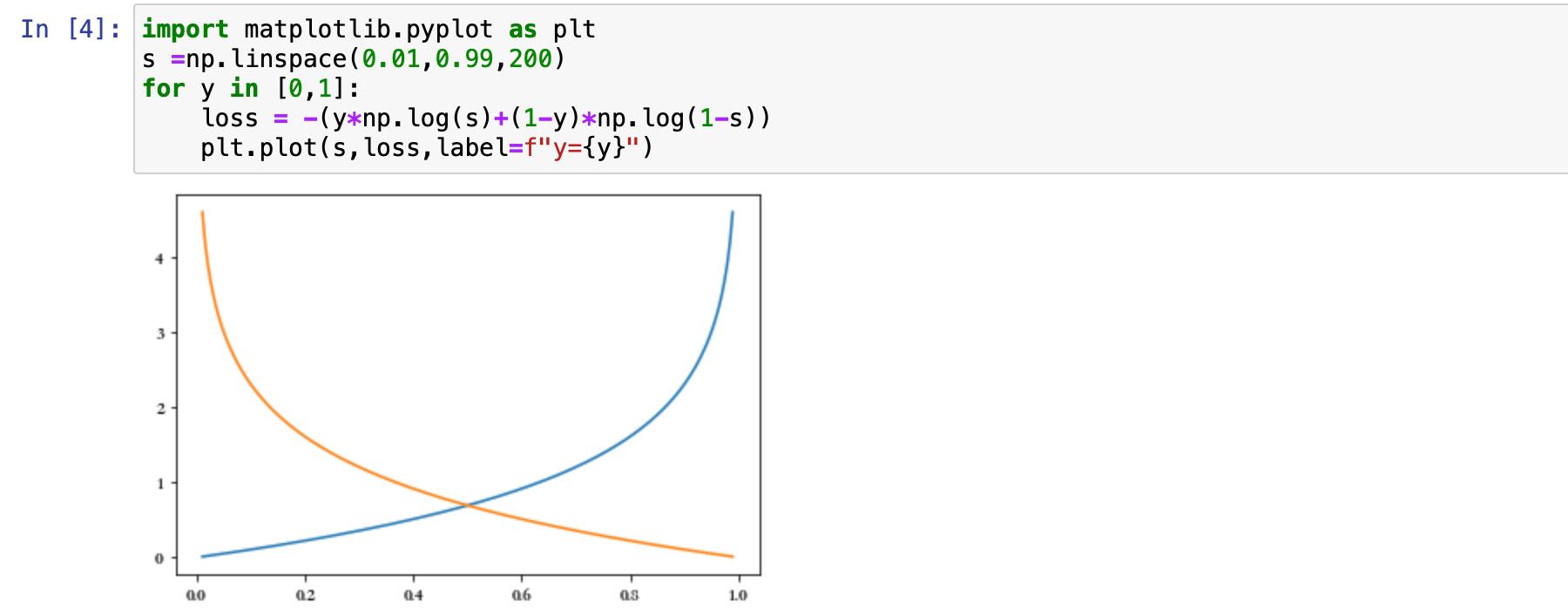
s 取 0.01 到 0.99 这两个数中间的,取 200 个数据点。然后 loss 那个地方是损失函数的公式,最终这个图给画出来了。代码中的 for 循环对 y 分别取值 0 和 1 进行了两次计算和绘图操作,每次计算得到的 loss 数组不同,所以会画出两条线。
当 y 取 0 这个类别时,将其代入损失函数 ,可得:
。对于函数
,其定义域为
,对其求导,根据复合函数求导法则,令
,则
,先对
关于
求导得
,再对
关于
求导得
,根据复合函数求导公式
,可得
。在定义域
内,
,所以
,这表明函数
在定义域内单调递增。也就是蓝色的那根曲线。
同理,当 y 取 0 这个类别时,函数在定义域内单调递减,是橙黄色的那条曲线。
这个图可以再稍微优化一下。图例加上,x 轴和 y 轴的标签表示出来。x 轴是损失,用 loss 表示,y 轴是 s(z)。运行一下看看。
python
import matplotlib.pyplot as plt
s =np.linspace(0.01,0.99,200)
for y in [0,1]:
loss = -(y*np.log(s)+(1-y)*np.log(1-s))
plt.plot(s,loss,label=f"y={y}")
plt.legend()
plt.xlabel('loss')
plt.ylabel('s(z)')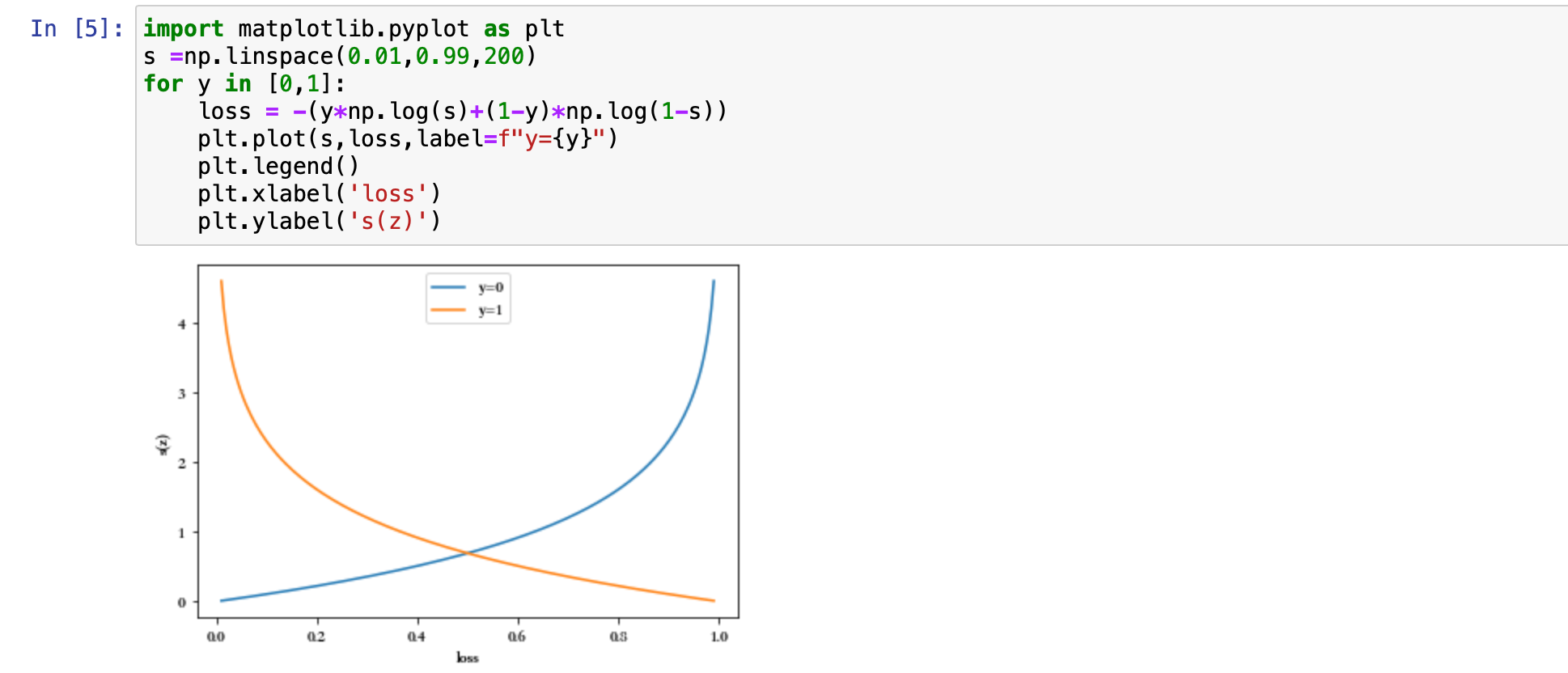
在使用的时候,我们希望损失函数是越小越好的。比如 y 属于 0 类别的时候, s(z) 越小越好,损失就越小。当 y 属于 1 这个类别的时候,s(z) 越大,损失就越小,也就是在这个时候 s(z) 越大越好。
模型训练与预测
一共有下面几个步骤:
- 导入数据与预处理:加载鸢尾花数据,处理标签为0和1,使用LogisticRegression进行训练。
- 模型训练:设置测试集大小为25%,使用LogisticRegression训练模型,获取训练好的分类器。
- 预测结果:使用训练好的模型对测试集进行预测,获取预测类别标签。
- 可视化预测结果:绘制真实类别与预测类别的对比图,直观展示模型分类效果。
我们可以看到它训练与预测的过程,和线性回归是一模一样的。回到 jupyter notebook 进行实操。如果上一篇的线性回归没有什么问题,那么这次的逻辑回归代码会比较轻松一些。
首先导入模型的包,逻辑回归的包。还涉及到测试集和训练集的划分,用于数据集拆分的工具导入进来。鸢尾花数据集导入进来。最后忽略警告。运行一下,后面要用。
python
from sklearn.linear_model import LogisticRegression #逻辑回归的包
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
import warnings
warnings.filterwarnings('ignore') # 忽略警告命令
之后,获取数据,然后打印出来看一看。
python
iris = load_iris()
iris
和上次一样的。在上一篇的第一步导包+获取数据集的部分有详细介绍过这个数据集。
这次涉及到的是二分类,所以这个地方只可以选择其中的两个类别。可以看一下数据集,鸢尾花有三个类别:0,1,2。这里选 1 和 2 这两个类别。并且特征取从索引 2 开始到末尾的所有元素。
确立特征和目标,X 和 y。特征直接用 iris.data,目标就用 iris.target。拿到特征列和目标列。先打印一下特征列看一看。
python
X,y=iris.data,iris.target
print(X)
这里补充一下 data 和 target 的关系:
1、对应关系
data 是鸢尾花的特征矩阵,形状为 (150, 4),每一行代表一个鸢尾花样本的 4 个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度);target 是一维标签数组,长度为 150,每一个元素对应 data 中对应行样本的品种类别(0、1、2 分别对应山鸢尾、变色鸢尾、维吉尼亚鸢尾)。也就是 data 里的第 i 行样本,对应的品种就是 target 里的第 i 个数字。
2、作用关系
data 是模型的输入数据,用来训练机器学习模型学习鸢尾花的特征规律;target 是模型的输出标签,是模型需要预测的目标,通过 data 和 target 的对应关系,模型可以学习到不同特征对应的鸢尾花品种,之后就能根据新的特征数据预测未知鸢尾花的品种了。
3、维度匹配
data 的行数和 target 的长度完全一致,都是 150,这种匹配的维度才能保证每个样本的特征和对应的标签能准确对应上,是机器学习分类任务中数据集的标准组织形式。
然后我们需要操作一下,筛选出所有非 0 类别的样本索引稍微的,每行从索引 2 开始到末尾的所有元素,也就是每行的第 3、4 个特征并且类别不属于 0 类别。打印出来看看。
python
X,y=iris.data,iris.target
print(X)
print("操作后")
X=X[y!=0,2:]
print(X)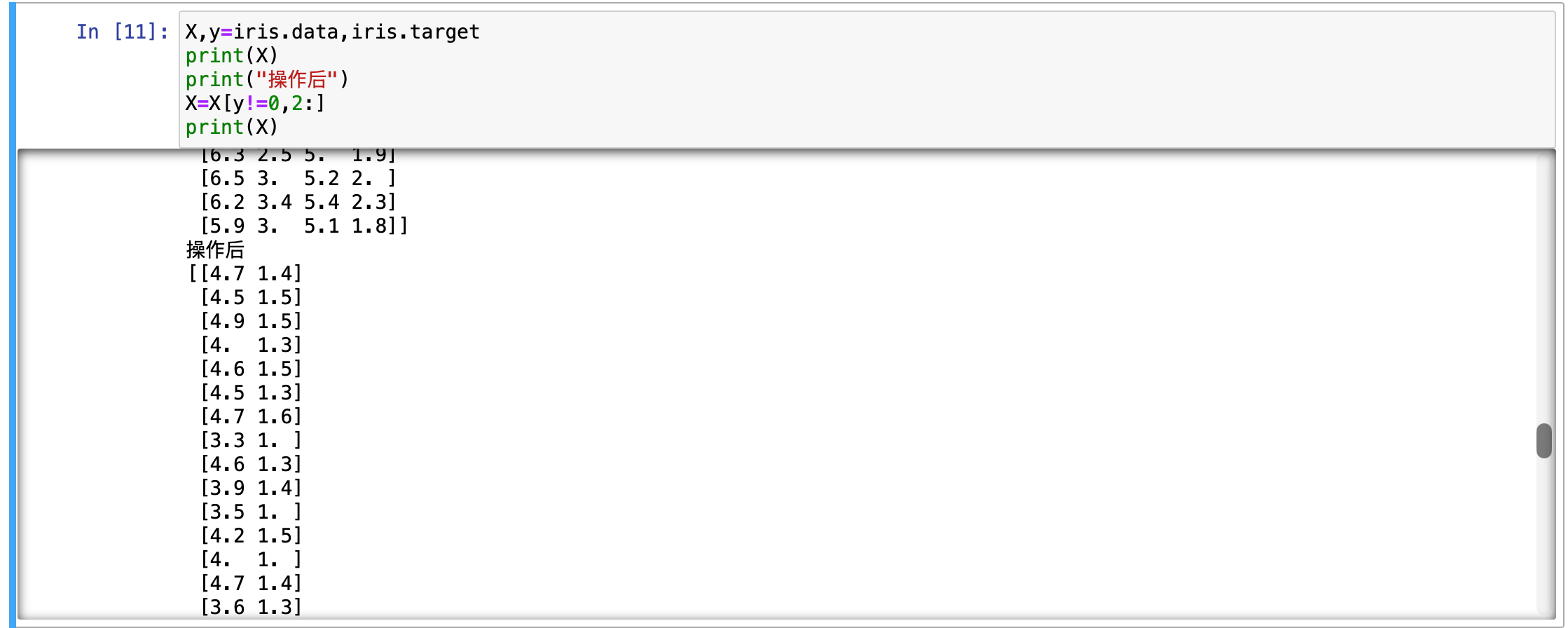
y 更好取了,y 直接不等于 0 就可以了。由于没有 0 类别,有 1 和 2 这两个类别,分别是变色鸢尾、维吉尼亚鸢尾,这个时候把 1 类别看做 0 类别,把 2 类别看做 1 类别。这个地方使用赋值的方法就可以了。这个就是通过赋值符号去改变它的类别属性。
python
y=y[y!=0]
print(y)
y[y==1]=0
y[y==2]=1
print(y)
这个地方操作结束之后,下一步,做训练集与测试集的划分。划分之后拿到模型,之后进行拟合。拟合的时候把训练集的数据放进去,最后再进行一下预测。
python
# 进行训练集和测试集划分
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=2)
lg=LogisticRegression()
# 进行拟合
lg.fit(X_train,y_train)
# 预测
Y=lg.predict(X_test)
最后对模型进行一下评估,还是用评分的方式来看。看一下这个模型性能怎么样。直接看它测试集上的数据,运行一下。发现是 0.9。
python
print(lg.score(X_test,y_test))
从评分可以看出来,这个模型的性能还是不错的。还可以通过可视化的方式来看一下效果。一般来说,分类算法就不像之前那样,用线的方式来查看了,分类算法用散点图的方式进行查看。真实值,用红色,菱形来表示。然后预测值,形状和颜色换一换,用圆圈和黄色来表示。
python
# 可视化
plt.scatter(X_test[:,0],y_test,label='真实值',color='red',marker='D')
plt.scatter(X_test[:,0],Y,label='预测值',color='yellow',marker='o')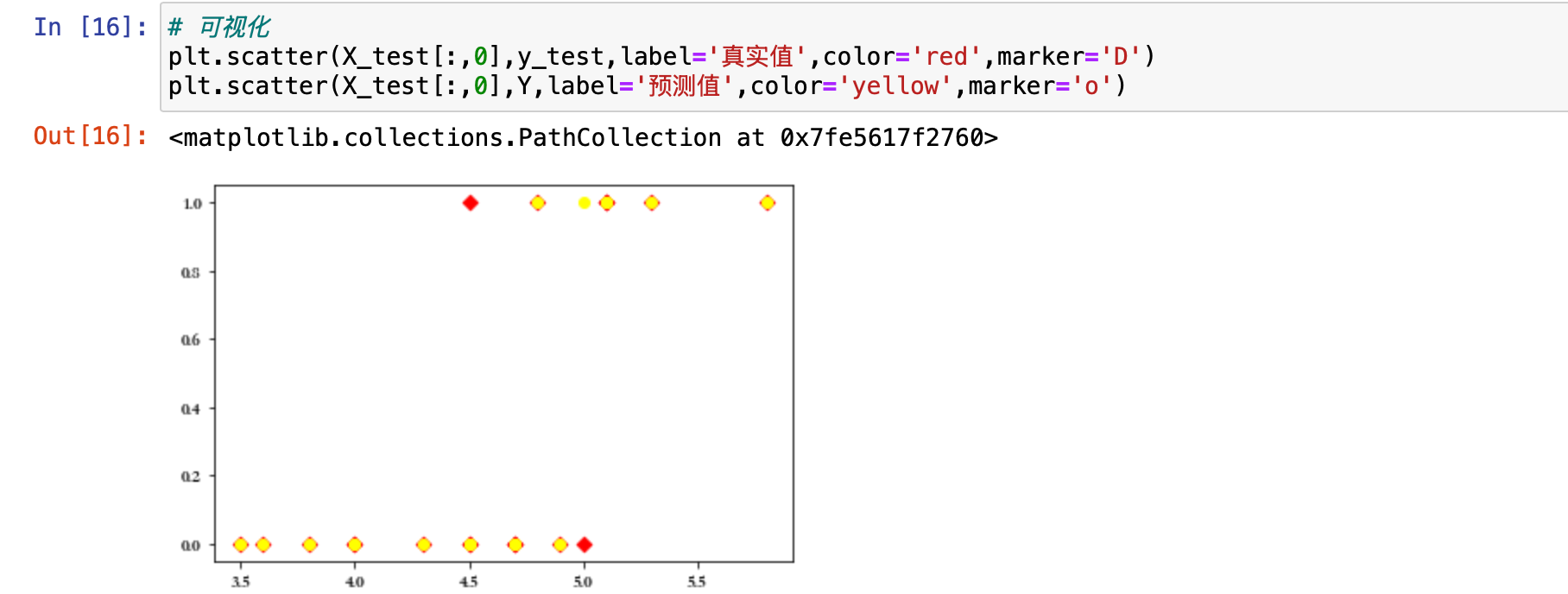
可以发现预测值和真实值的点都基本重合了。所以预测值基本上都预测对了。对于分类算法最好画点图。点图更加明显一些。
最后通过可视化看一下鸢尾花的类别 0 和类别 1。最终,这个效果还不错。
python
#可视化类别
import matplotlib.pyplot as plt
plt.rcParams['font.family']='SimHei'
c1=X[y==0]
c2=X[y==1]
plt.scatter(x=c1[:,0],y=c1[:,1],c='g',label='类别0')
plt.scatter(x=c2[:,0],y=c2[:,1],c='r',label='类别1')
plt.xlabel('花瓣长度')
plt.ylabel('花瓣宽度')
plt.title('鸢尾花样本分布')
plt.legend()
plt.show()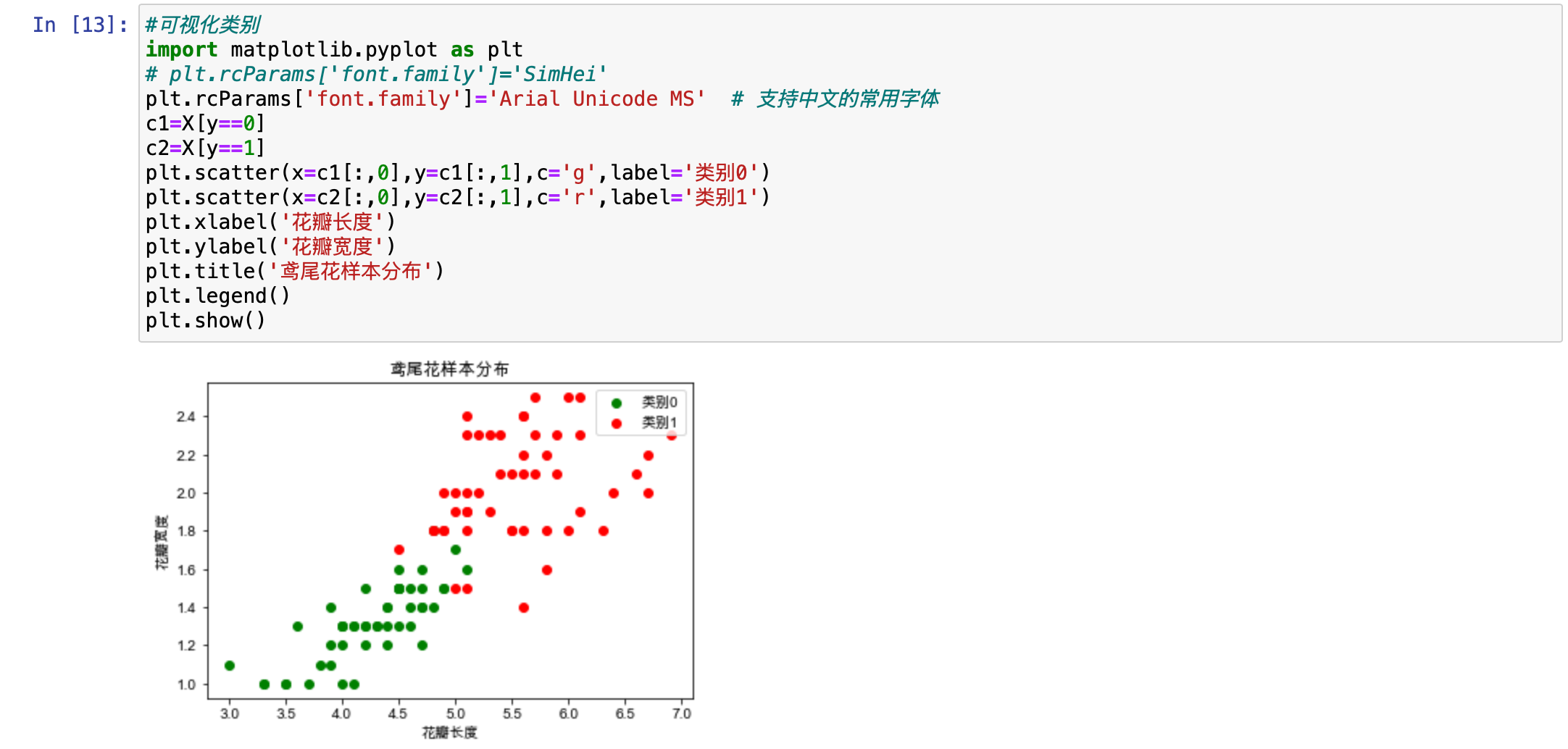
两类样本在图当中区分程度较高,没有出现大量重叠的情况。
计算概率值。一般在分类项目里面都会用到概率值。在这里有相应的函数来帮助对概率值直接进行计算。使用的是 predict_proba 函数。
python
#计算概率值
pro=lg.predict_proba(X_test)
print(pro)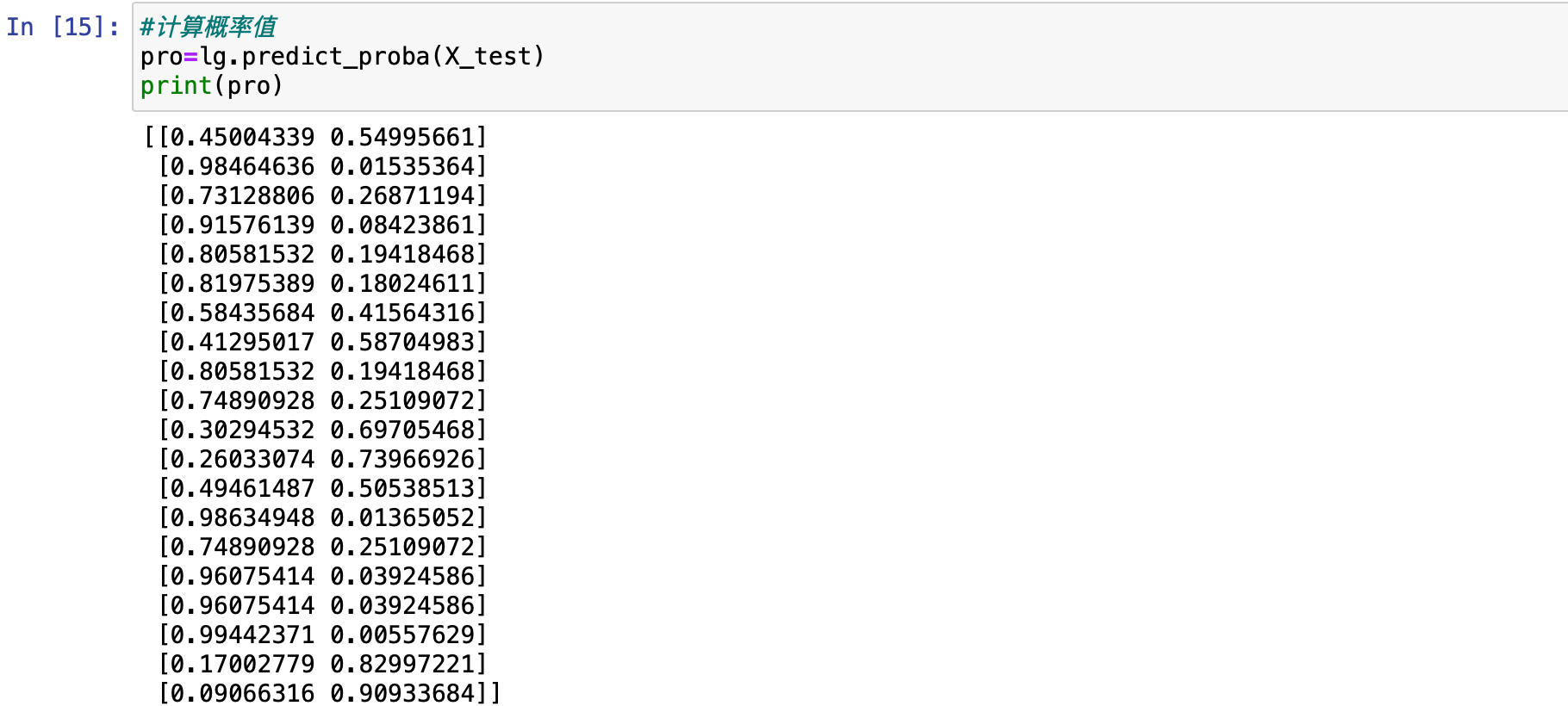
理解一下这个地方。predict_proba 是 sklearn 库中逻辑回归模型(LogisticRegression)等分类模型的一个方法,用于生成输入样本属于各个类别的概率。在二分类问题中,predict_proba 方法生成的概率是互补的,即属于正类和负类的概率之和为 1。从输出结果上看,每一行对应一个样本,第一列是样本属于第一个类别(类别 0)的概率,第二列是样本属于第二个类别(类别 1)的概率,这两个的和为 1。阈值是 0.5,在之前求过,哪一类大于这个阈值就属于哪一类。
还可以对预测的 Y 进行打印,回到上面预测的那个地方。
这里已经有预测出来了,在这里取它前十个,打印出来看一看。可以看到这个运行结果。

把这个结果拿过来和后面的比较一下看看。发现都对上了。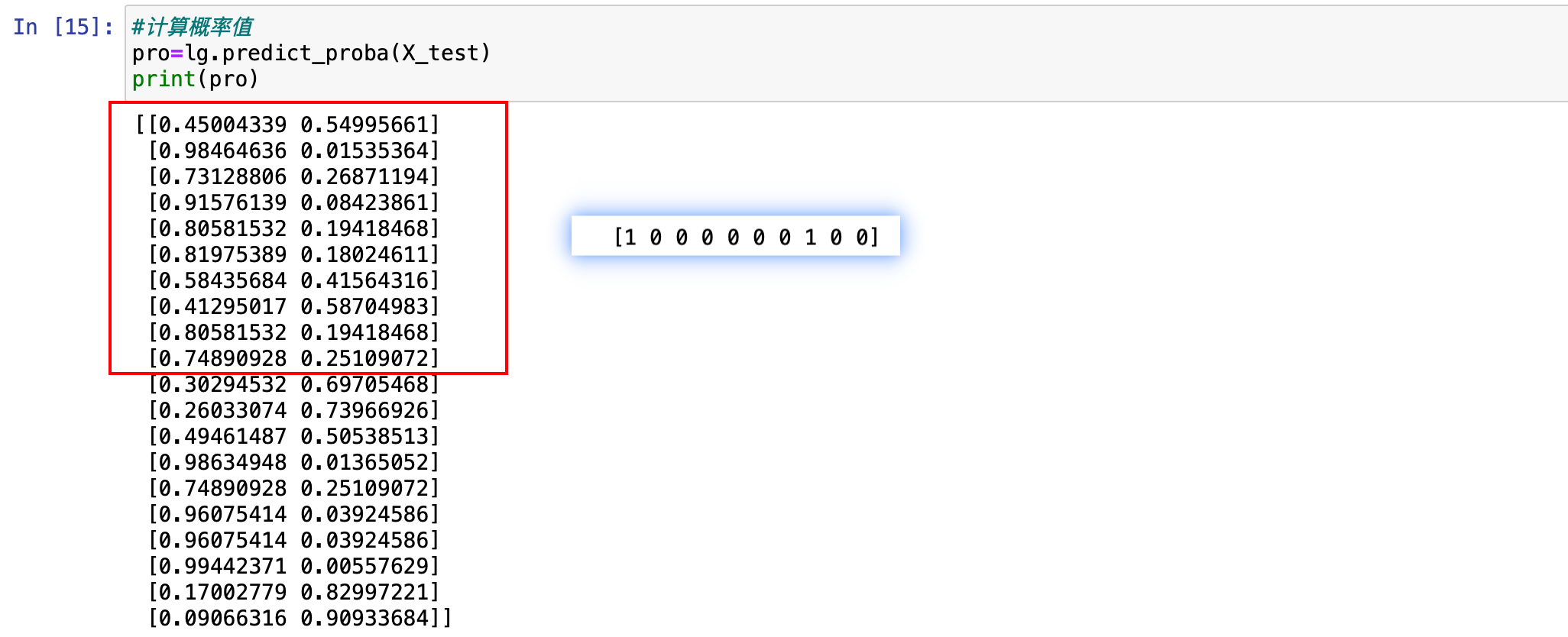
基于 0.5 这个阈值,它不是固定的,它是通用。针对业务的不同,这个阈值是可以调节的,在有些业务里面,这个阈值需要把它调高。
决策边界
这是一个固定的模版,后面遇到其他分类算法,可以直接往里套。这个难度较大,作为一个了解就可以了。这是分类算法模版,回归就不行了。先把代码弄过来放在这里,然后解释它的意思,以及以后使用的时候改哪几个地方就可以了。这是这个模版的代码。
python
# 决策边界
from matplotlib.colors import ListedColormap
def plot_decision_boundary(model,X,y):
color=['r','g','b'] # 设置颜色
marker=['o','v','x']
class_label=np.unique(y)
cmap=ListedColormap(color[:len(class_label)])
x1_min,x2_min=np.min(X,axis=0)
x1_max,x2_max=np.max(X,axis=0)
x1=np.arange(x1_min-1,x1_max+1,0.02)
x2=np.arange(x2_min-1,x2_max+1,0.02)
X1,X2=np.meshgrid(x1,x2)
Z=model.predict(np.array([X1.ravel(),X2.ravel()]).T).reshape(X1.shape)
plt.contourf(X1,X2,Z,cmap=cmap,alpha=0.5)
for i,class_ in enumerate(class_label):
plt.scatter(x=X[y==class_,0],y=X[y==class_,1],c=cmap.colors[i],label=class_,marker=marker[i])
plt.legend()这个运行之后没有任何结果,因为是定义了一个函数。所以后面还要调用一下函数。在调用的时候可以设置一下图形的画布大小。然后函数名字拿过来,传入逻辑回归模型,对应的是 X_train 和 y_train,最后 show 出来看看。
python
# 调用函数
plt.figure(figsize=(10,6))
plot_decision_boundary(lg,x_trian,y_train)
plt.show()运行之后会发现出来这样一个图形。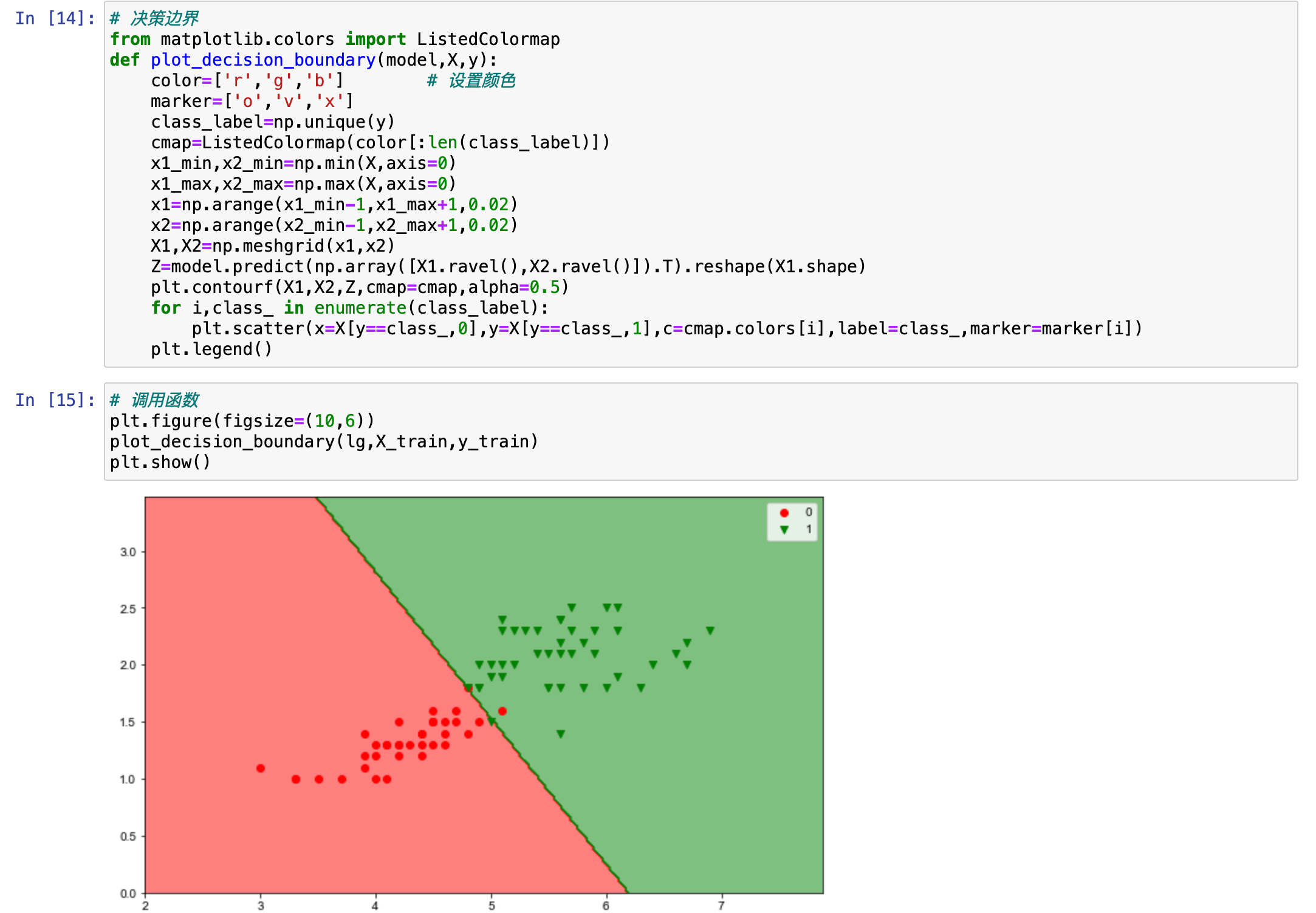
后面要画决策边界的话,直接这段代码复制粘贴过去,然后个别参数去调整,调整成想要的图形就可以了。这个图形难点在于把背景图给画出来。解释一下 min 和 max 这两句代码:
- x1_min,x2_min=np.min(X,axis=0) 找出特征矩阵 X 中每列(即每个特征)的最小值。
- x1_max,x2_max=np.max(X,axis=0) 找出特征矩阵 X 中每列的最大值。
这两句代码是为了得到一个范围,获取图像里面这样的空间。接下来是 arrange 的那两句,这两句是用来画出背景图用的。
- x1=np.arange(x1_min - 1,x1_max + 1,0.02) 和 x2=np.arange(x2_min - 1,x2_max + 1,0.02) 根据上述最值,分别生成在特征取值范围基础上向外扩展 1 个单位、步长为 0.02 的数组,用于后续生成网格点。生成这些数据点就是为了画背景图。
然后,np.meshgrid(x1, x2) 生成的网格点在数学本质上就是两个一维数组的笛卡尔积。这是为了获取到更多的数据点。补充知识:什么是笛卡尔积?在集合论中两个集合 A 和 B 的笛卡尔积(Cartesian Product),记为 A×B,是指所有可能的有序对 (a,b) 的集合,其中 a∈A 且 b∈B。例如:x1=1,2,x2=3,4,它们的笛卡尔积包含以下点:(1,3),(1,4),(2,3),(2,4)。
接下来,Z=model.predict(np.array(X1.ravel(),X2.ravel()).T).reshape(X1.shape),这句代码是模型预测与重塑。
- 扁平化输入:将网格矩阵 X1 和 X2 拉平(ravel),并组合成 (N, 2) 形状的输入数组,其中 N 是网格点的总数。
- 批量预测:调用 model.predict 对网格中每一个点进行类别预测。
- 恢复形状:将预测结果 Z 重塑(reshape)回与 X1 相同的二维形状,以便后续绘图。Z 中的每个值代表该网格点所属的预测类别。
这整个的函数定义中间的代码都是为了给它绘图绘色,所以后面要用的时候,这部分代码原封不动拿过来,复制粘贴,只需要改的地方是后面调用时候,传入的参数 model,改成对应的分类算法的模型。还有可以修改的参数是,传入的 X_train 和 y_train,这两个可以改变一下。其他的基本没有需要改变的。下面是总结的调用函数可以修改的地方以及修改例子。
在调用函数的时候可以修改的地方:
- 传入模型:在调用 plot_decision_boundary 函数时,将 model 参数替换为你训练好的不同分类算法模型,例如支持向量机模型 SVM、决策树模型 DecisionTreeClassifier 等。
- 数据:根据实际情况,将 X 和 y 替换为相应的特征数据和标签数据。如果是测试不同数据集,直接传入对应的数据集即可。
- 类别数量及颜色标记:如果数据集中的类别数量超过代码中预设的 3 类,需要修改 color 和 marker 列表,添加更多的颜色和标记符号,以确保每个类别都有不同的显示样式。
假设使用支持向量机(SVM)模型来绘制决策边界,代码修改如下:
python
from sklearn.svm import SVC
# 训练SVM模型
svm_model = SVC()
svm_model.fit(X_train, y_train)
plt.figure(figsize=(10,6))
# 调用函数,传入SVM模型、训练数据
plot_decision_boundary(svm_model,X_train,y_train)
plt.show()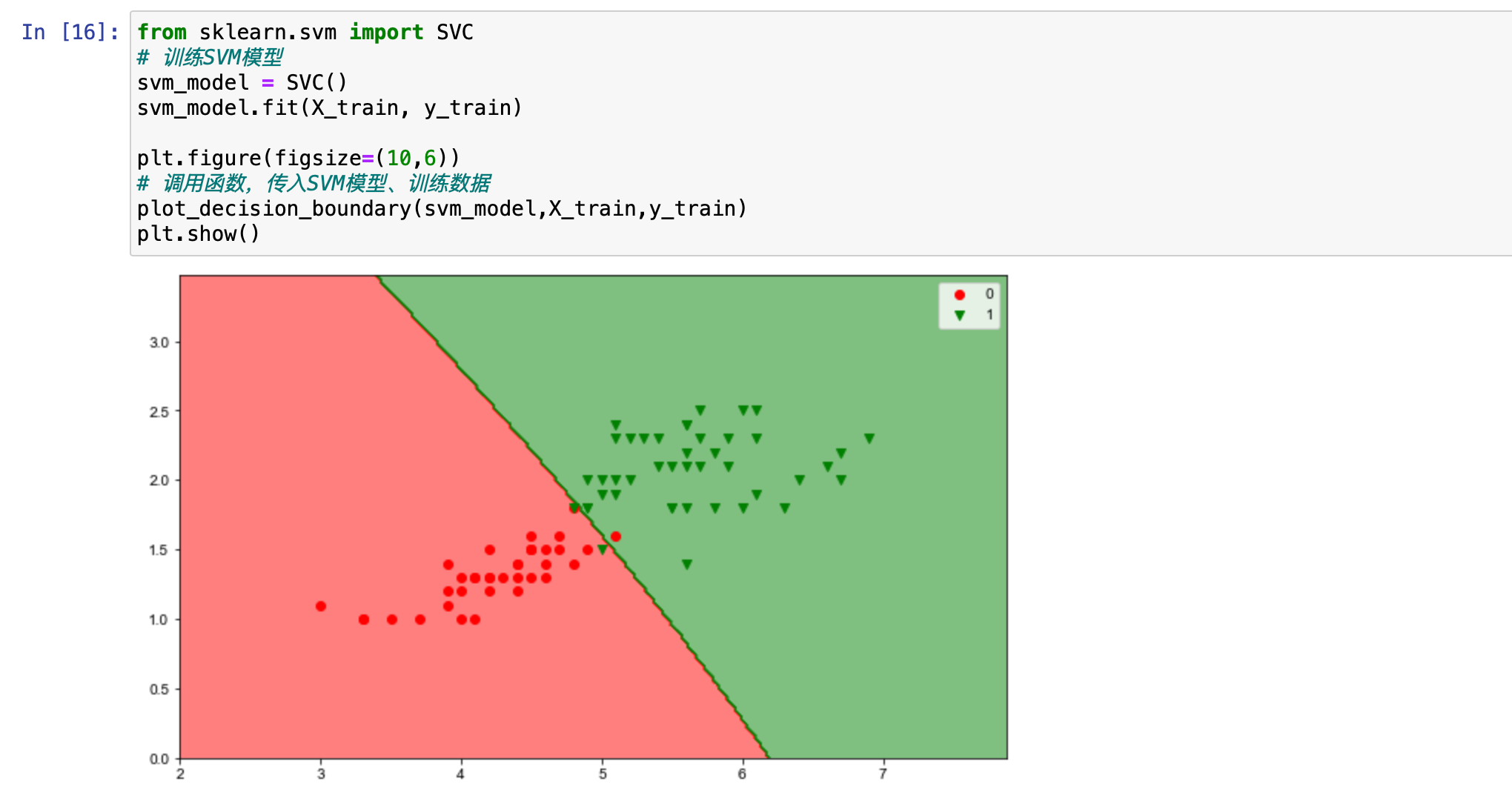
运行之后的图形和之前的图形十分相似。这是因为尽管使用了不同的模型,但由于数据相同、绘图设置一致以及模型在当前数据上的表现相似,最终生成的图形看起来一模一样。
本篇完整代码
由于字体显示在不同的系统下,效果不一样,所以这里总结了 Windows 和 Mac 这两个版本的完整代码。
Windows 版本
python
# sigmoid函数图
import matplotlib.pyplot as plt
import numpy as np
plt.figure(figsize=(16, 8))
plt.rcParams['font.family'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False # 设置负号
# 生成数据
z = np.linspace(-10, 10, 200)
y = 1 / (1 + np.exp(-z))
# 绘制图形
plt.plot(z, y, label='sigmoid函数', linewidth=2)
# 垂直线
plt.axvline(x=0, ls='--', c='black')
# 水平线
plt.axhline(y=1, ls=':', c='black')
plt.axhline(y=0, ls=':', c='black')
plt.axhline(y=0.5, ls=':', c='black')
plt.xlabel('z')
plt.ylabel('sigmoid(z)')
plt.title('sigmoid函数图像')
plt.legend()
plt.show()
# 损失函数与sigmoid
import matplotlib.pyplot as plt
s =np.linspace(0.01,0.99,200)
for y in [0,1]:
loss = -(y*np.log(s)+(1-y)*np.log(1-s))
plt.plot(s,loss,label=f"y={y}")
plt.legend()
plt.xlabel('loss')
plt.ylabel('s(z)')
# 模型训练与预测
from sklearn.linear_model import LogisticRegression #逻辑回归的包
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
import warnings
warnings.filterwarnings('ignore') # 忽略警告命令
# 模型训练与预测
from sklearn.linear_model import LogisticRegression #逻辑回归的包
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
import warnings
warnings.filterwarnings('ignore') # 忽略警告命令
iris = load_iris()
iris
X,y=iris.data,iris.target
print(X)
print("操作后")
X=X[y!=0,2:]
print(X)
y=y[y!=0]
print(y)
y[y==1]=0
y[y==2]=1
print(y)
# 进行训练集和测试集划分
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=2)
lg=LogisticRegression()
# 进行拟合
lg.fit(X_train,y_train)
# 预测
Y=lg.predict(X_test)
print(Y[:10])
print(lg.score(X_test,y_test))
# 可视化
plt.scatter(X_test[:,0],y_test,label='真实值',color='red',marker='D')
plt.scatter(X_test[:,0],Y,label='预测值',color='yellow',marker='o')
#可视化类别
import matplotlib.pyplot as plt
plt.rcParams['font.family']='SimHei'
c1=X[y==0]
c2=X[y==1]
plt.scatter(x=c1[:,0],y=c1[:,1],c='g',label='类别0')
plt.scatter(x=c2[:,0],y=c2[:,1],c='r',label='类别1')
plt.xlabel('花瓣长度')
plt.ylabel('花瓣宽度')
plt.title('鸢尾花样本分布')
plt.legend()
plt.show()
#计算概率值
pro=lg.predict_proba(X_test)
print(pro)
# 决策边界
from matplotlib.colors import ListedColormap
def plot_decision_boundary(model,X,y):
color=['r','g','b'] # 设置颜色
marker=['o','v','x']
class_label=np.unique(y)
cmap=ListedColormap(color[:len(class_label)])
x1_min,x2_min=np.min(X,axis=0)
x1_max,x2_max=np.max(X,axis=0)
x1=np.arange(x1_min-1,x1_max+1,0.02)
x2=np.arange(x2_min-1,x2_max+1,0.02)
X1,X2=np.meshgrid(x1,x2)
Z=model.predict(np.array([X1.ravel(),X2.ravel()]).T).reshape(X1.shape)
plt.contourf(X1,X2,Z,cmap=cmap,alpha=0.5)
for i,class_ in enumerate(class_label):
plt.scatter(x=X[y==class_,0],y=X[y==class_,1],c=cmap.colors[i],label=class_,marker=marker[i])
plt.legend()
# 调用函数
plt.figure(figsize=(10,6))
plot_decision_boundary(lg,X_train,y_train)
plt.show()
# 更改示例(换svm分类模型)
from sklearn.svm import SVC
# 训练SVM模型
svm_model = SVC()
svm_model.fit(X_train, y_train)
plt.figure(figsize=(10,6))
# 调用函数,传入SVM模型、训练数据
plot_decision_boundary(svm_model,X_train,y_train)
plt.show()Mac 版本
python
# sigmoid函数图
import matplotlib.pyplot as plt
import numpy as np
plt.figure(figsize=(16, 8))
# plt.rcParams['font.family'] = 'SimHei'
plt.rcParams['font.sans-serif'] = ['Songti SC']
plt.rcParams['axes.unicode_minus'] = False # 设置负号
# 生成数据
z = np.linspace(-10, 10, 200)
y = 1 / (1 + np.exp(-z))
# 绘制图形
plt.plot(z, y, label='sigmoid函数', linewidth=2)
# 垂直线
plt.axvline(x=0, ls='--', c='black')
# 水平线
plt.axhline(y=1, ls=':', c='black')
plt.axhline(y=0, ls=':', c='black')
plt.axhline(y=0.5, ls=':', c='black')
plt.xlabel('z')
plt.ylabel('sigmoid(z)')
plt.title('sigmoid函数图像')
plt.legend()
plt.show()
# 损失函数与sigmoid
import matplotlib.pyplot as plt
s =np.linspace(0.01,0.99,200)
for y in [0,1]:
loss = -(y*np.log(s)+(1-y)*np.log(1-s))
plt.plot(s,loss,label=f"y={y}")
plt.legend()
plt.xlabel('loss')
plt.ylabel('s(z)')
# 模型训练与预测
from sklearn.linear_model import LogisticRegression #逻辑回归的包
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
import warnings
warnings.filterwarnings('ignore') # 忽略警告命令
# 模型训练与预测
from sklearn.linear_model import LogisticRegression #逻辑回归的包
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
import warnings
warnings.filterwarnings('ignore') # 忽略警告命令
iris = load_iris()
iris
X,y=iris.data,iris.target
print(X)
print("操作后")
X=X[y!=0,2:]
print(X)
y=y[y!=0]
print(y)
y[y==1]=0
y[y==2]=1
print(y)
# 进行训练集和测试集划分
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=2)
lg=LogisticRegression()
# 进行拟合
lg.fit(X_train,y_train)
# 预测
Y=lg.predict(X_test)
print(Y[:10])
print(lg.score(X_test,y_test))
# 可视化
plt.scatter(X_test[:,0],y_test,label='真实值',color='red',marker='D')
plt.scatter(X_test[:,0],Y,label='预测值',color='yellow',marker='o')
#可视化类别
import matplotlib.pyplot as plt
# plt.rcParams['font.family']='SimHei'
plt.rcParams['font.family']='Arial Unicode MS' # 支持中文的常用字体
c1=X[y==0]
c2=X[y==1]
plt.scatter(x=c1[:,0],y=c1[:,1],c='g',label='类别0')
plt.scatter(x=c2[:,0],y=c2[:,1],c='r',label='类别1')
plt.xlabel('花瓣长度')
plt.ylabel('花瓣宽度')
plt.title('鸢尾花样本分布')
plt.legend()
plt.show()
#计算概率值
pro=lg.predict_proba(X_test)
print(pro)
# 决策边界
from matplotlib.colors import ListedColormap
def plot_decision_boundary(model,X,y):
color=['r','g','b'] # 设置颜色
marker=['o','v','x']
class_label=np.unique(y)
cmap=ListedColormap(color[:len(class_label)])
x1_min,x2_min=np.min(X,axis=0)
x1_max,x2_max=np.max(X,axis=0)
x1=np.arange(x1_min-1,x1_max+1,0.02)
x2=np.arange(x2_min-1,x2_max+1,0.02)
X1,X2=np.meshgrid(x1,x2)
Z=model.predict(np.array([X1.ravel(),X2.ravel()]).T).reshape(X1.shape)
plt.contourf(X1,X2,Z,cmap=cmap,alpha=0.5)
for i,class_ in enumerate(class_label):
plt.scatter(x=X[y==class_,0],y=X[y==class_,1],c=cmap.colors[i],label=class_,marker=marker[i])
plt.legend()
# 调用函数
plt.figure(figsize=(10,6))
plot_decision_boundary(lg,X_train,y_train)
plt.show()
# 更改示例(换svm分类模型)
from sklearn.svm import SVC
# 训练SVM模型
svm_model = SVC()
svm_model.fit(X_train, y_train)
plt.figure(figsize=(10,6))
# 调用函数,传入SVM模型、训练数据
plot_decision_boundary(svm_model,X_train,y_train)
plt.show()