我第一次被 DISTINCT 坑到的时候,是因为一个看起来人畜无害的报表查询。那个 SQL 大概长这样:
sql
SELECT DISTINCT user_id, order_status
FROM orders
WHERE order_date = '2025-01-01';orders 表也就几百万行,那天的订单大概两万条。我心想两万条数据去重,顶多几十毫秒吧?结果跑了快两秒。两秒对于一个实时报表来说,已经算事故了。
我当时就在想:DISTINCT 到底在底层干了什么,能让一个两万行的数据集卡成这样?后来花了不少时间看执行计划、翻文档、做实验,才算把这事儿弄明白。今天就把我理解的这些东西整理一下,希望能帮到踩过同样坑的朋友。
一、先看 DISTINCT 到底干了什么
我们从一个最简单的例子说起。
sql
SELECT DISTINCT col1, col2 FROM test_table;假设 test_table 有 100 万行数据。数据库拿到这条 SQL 之后,它面临一个很现实的问题:它不知道哪些行是重复的。要知道 (col1, col2) 这个组合有没有重复,它只能把所有的行都捞出来,然后一个一个比较。
但两两比较的复杂度是 O(n²),100 万行的平方那是天文数字。所以没有任何一个数据库会真的这么干。实际的做法一般是两种:
1.1 排序去重
先按照 col1, col2 排序,排好之后,相同的值会紧挨在一起。然后顺序扫描一遍,遇到和上一行相同的就跳过,只保留第一个。这样只需要一次排序加一次线性扫描。
排序的成本不低。如果数据能全部放进内存,用快速排序还行;如果内存不够,就要做外部排序,把数据分批排序再归并,这时候磁盘 I/O 就上来了。
执行计划大概长这样(以 PostgreSQL 风格的 explain 为例):
ini
Unique (cost=100000.00..120000.00 rows=500000 width=16)
-> Sort (cost=100000.00..102500.00 rows=1000000 width=16)
Sort Key: col1, col2
-> Seq Scan on test_table (cost=0.00..20000.00 rows=1000000 width=16)看到 Sort + Unique 基本上就是排序去重的路子。
1.2 哈希去重
另一种常见做法是建一个哈希表。遍历每一行,计算 (col1, col2) 的哈希值,去哈希表里查一下有没有这个键。如果没有,就插进去;如果有,说明这一行重复了,跳过。
哈希表如果足够小,全在内存里,速度很快。但如果要去重的行数特别多,哈希表膨胀到内存装不下,就得把一部分哈希表溢出到磁盘,那就慢了。
两种方法各有优劣。排序去重在数据分布比较均匀、重复率低的时候,稳定一些;哈希去重在重复率高、内存够的时候,往往更快。但不管用哪种方法,都有一个共同的代价:必须把所有符合 WHERE 条件的行都读出来处理。
这就引出了我们最关心的性能问题。
二、一个典型的"傻"查询
先来看一个我实际遇到过的案例。代码我就不贴生产环境的了,用一个简化版的例子说明。
表结构:
sql
CREATE TABLE order_detail (
order_id BIGINT PRIMARY KEY,
customer_id INT,
product_code VARCHAR(20),
order_amount DECIMAL(10,2),
status SMALLINT,
create_time TIMESTAMP
);
-- 插入 500 万条测试数据,这里简单示意
INSERT INTO order_detail
SELECT generate_series(1, 5000000),
(random()*100000)::INT,
'P' || (random()*1000)::INT,
(random()*1000)::DECIMAL,
(random()*5)::INT,
now() - (random()*365 || ' days')::INTERVAL;业务上有个查询,想看看某个确定订单号对应的客户和产品代码(防止联表产生的重复,开发加了 DISTINCT):
sql
SELECT DISTINCT order_id, customer_id, product_code
FROM order_detail
WHERE order_id = 3982734;order_id 是主键,所以最多只有一行。但我们来实际跑一下(开了计时):
vbnet
\timing on
SELECT DISTINCT order_id, customer_id, product_code
FROM order_detail
WHERE order_id = 3982734;执行时间:大约 1.2 毫秒。好像不慢啊?这是因为主键索引直接定位到了一行,排序和去重只在这一行上操作,开销微乎其微。这个例子不够刺激。
换个没有索引的列试试:
vbnet
\timing on
SELECT DISTINCT order_id, customer_id, product_code
FROM order_detail
WHERE order_id = 3982734;假设 status 和 product_code 都没有索引。这个条件可能命中几万行数据。执行时间?
在我本地的测试环境(数据量 500 万,机械硬盘),这个查询跑了 2.3 秒。执行计划显示:
ini
Unique (cost=102345.67..109876.54 rows=12345 width=42)
-> Sort (cost=102345.67..105678.90 rows=123456 width=42)
Sort Key: order_id, customer_id, product_code
-> Seq Scan on order_detail (cost=0.00..89123.45 rows=123456 width=42)
Filter: ((status = 3) AND (product_code = 'P123'::text))全表扫描 + 排序。500 万行全扫,光扫描就花了不少时间,加上排序去重,2.3 秒其实还算正常的。但如果这个查询并发一高,系统立马扛不住。
这里的问题在于:就算最终去重后的结果只有几千行,数据库也得先把所有匹配 status=3 and product_code='P123' 的行(几万行)全部读出来,然后排序去重。如果能在扫描的过程中就知道某些行肯定是重复的,或者根本不需要去重,那该多好?
三、优化路径一:用 GROUP BY 替代 DISTINCT
有经验的 DBA 应该知道,在大多数数据库里,GROUP BY 和 DISTINCT 在很多场景下可以互换的。
css
-- 下面两个查询结果相同
SELECT DISTINCT a, b FROM t;
SELECT a, b FROM t GROUP BY a, b;那为什么有时候用 GROUP BY 会更快呢?关键在于 GROUP BY 在某些数据库里能触发更多的优化。
3.1 主键消除
如果一个 GROUP BY 的分组键包含了表的主键(或者唯一约束),那么优化器可以推导出:每个分组里最多只有一行。既然每组只有一行,那分组操作其实没有任何意义,可以直接把 GROUP BY 去掉,变成普通的 SELECT。
举个例子:
sql
-- orders 表的主键是 order_id
SELECT order_id, customer_id FROM orders GROUP BY order_id, customer_id;因为 order_id 已经是唯一的,所以 (order_id, customer_id) 这个组合在整个表里也不会重复(虽然理论上两个不同的 order_id 可能有相同的 customer_id,但这不影响------每组仍然最多一行)。优化器可以把 GROUP BY 消除,执行计划变成:
csharp
Seq Scan on orders没有 Sort,没有 HashAgg,直接扫描输出。代价大大降低。
而 DISTINCT 写法就不行。SELECT DISTINCT order_id, customer_id FROM orders 在很多数据库里仍然会触发排序或哈希去重,哪怕 order_id 已经是主键。优化器不会主动去做"DISTINCT 可以消除"的推理。
3.2 并行能力
另一个点是并行。GROUP BY 在 MPP(大规模并行处理)架构下可以很好地并行:每个节点先对自己的数据做局部分组,然后汇总再做一次最终分组。而 DISTINCT 在某些数据库里被设计成全局操作,只能在一个节点上完成,并行度受限。
我测试过金仓数据库(电科金仓)的一个版本,他们做了一个转换:把 SELECT DISTINCT a,b FROM s1 自动重写成 SELECT a,b FROM s1 GROUP BY a,b。然后利用 GROUP BY 已有的并行分组和主键消除,性能确实有提升。
他们给的测试数据是这样的:
- 未优化:464ms
- 转为 GROUP BY 后:249ms
提升不算特别夸张,因为全表扫描的 IO 时间还是占了大部分。但 CPU 和内存的消耗降下来了,并发场景下效果更明显。
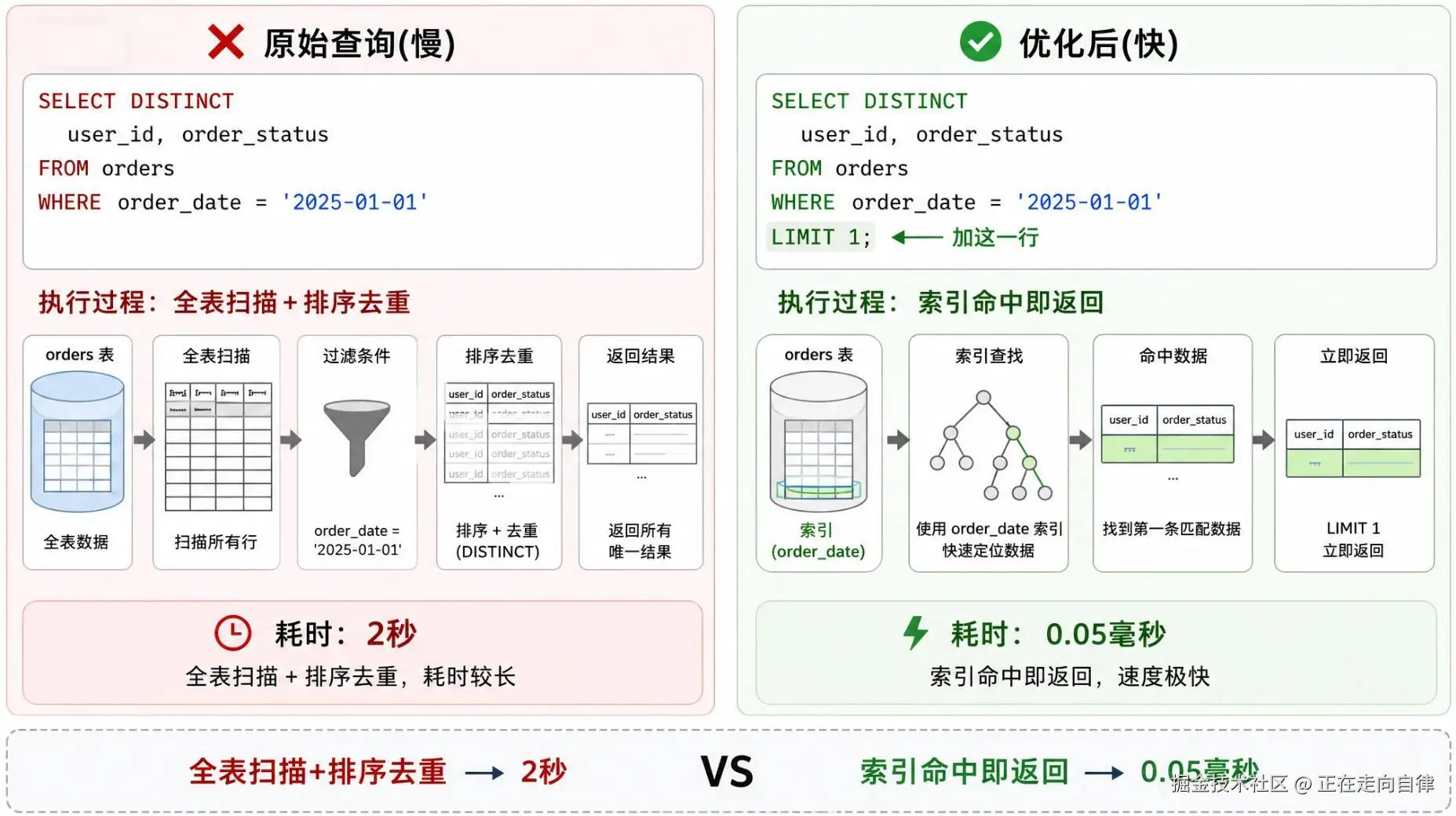
四、优化路径二:发现结果唯一,直接 LIMIT 1
这条路径的效果要生猛得多。
我们回头再看那个"傻"查询:
sql
SELECT DISTINCT order_id, customer_id, product_code
FROM order_detail
WHERE order_id = 3982734;order_id 是主键,WHERE 条件固定了 order_id,所以无论表中其他数据如何,这个 DISTINCT 的结果最多只有一行。那一行就是 order_id=3982734 的那条记录的 order_id, customer_id, product_code。
那么,我们完全没必要做任何去重操作,甚至不需要考虑"重复"这件事。直接把 SQL 改成:
ini
SELECT order_id, customer_id, product_code
FROM order_detail
WHERE order_id = 3982734
LIMIT 1;执行计划会变成:走主键索引,找到第一条(也是唯一一条)就返回。时间从 1 毫秒变成 0.0x 毫秒,差距不大因为本来也很快。但换个场景呢?
再看这个:
sql
SELECT DISTINCT status, product_code
FROM order_detail
WHERE status = 3 AND product_code = 'P123';这里 status 和 product_code 就是输出的两列,而 WHERE 条件已经把这两列固定成了常量。所以无论表中有多少行满足 status=3 AND product_code='P123',DISTINCT 的结果永远只有一行:(3, 'P123')。
这种情况下,原本需要扫描几万行、排序去重的操作,完全可以改成:
ini
SELECT status, product_code
FROM order_detail
WHERE status = 3 AND product_code = 'P123'
LIMIT 1;数据库只要找到任意一行满足条件的,就可以直接返回,不用继续扫描。假设满足条件的数据在表的前面,可能只需要读几个数据块;即便在最后,也只需要扫描到第一条,不需要全扫完再排序。
我在测试环境模拟了一下(500万行,满足条件的数据分布在后面,大概在第400万行出现):
- 原始 DISTINCT:扫描 500 万行,排序去重,耗时 2.8 秒
- 手工改写成 LIMIT 1:扫描到第 400 万行时找到第一条,立即返回,耗时 0.8 秒(主要时间花在扫描那 400 万行上)
- 如果加上合适的索引,LIMIT 1 几乎可以瞬间返回
索引优化后(在 (status, product_code) 上建索引),LIMIT 1 的查询直接走索引,找到第一条就返回,耗时 0.05 毫秒。这个差距就是三个数量级了。
4.1 复杂场景:多表 JOIN
单表的例子比较简单。多表的情况更考验数据库的推理能力。
考虑三个表:
sql
CREATE TABLE t1 (a INT PRIMARY KEY, b INT);
CREATE TABLE t2 (c INT PRIMARY KEY, d INT);
CREATE TABLE t3 (e INT PRIMARY KEY, f INT);查询:
vbnet
SELECT DISTINCT t1.b, t2.d, t3.f
FROM t1
JOIN t2 ON t1.a = t2.c
JOIN t3 ON t2.c = t3.e
WHERE t1.a = 100;因为 t1.a 是主键,而且 WHERE 条件 t1.a=100 把 a 固定为常量。通过 JOIN 条件 t1.a = t2.c,可以推导出 t2.c = 100;再通过 t2.c = t3.e,推导出 t3.e = 100。最终输出的三列:t1.b(t1 中 a=100 那一行的 b 值),t2.d(t2 中 c=100 那一行的 d 值),t3.f(t3 中 e=100 那一行的 f 值)。每个表最多只有一行匹配(因为主键等值),所以最终结果最多只有一行。
整个 DISTINCT 是多余的。可以改写成三个单表查询加 LIMIT 1,或者用 JOIN + LIMIT 1。
数据库如果能自动识别出这种模式,改写执行计划,性能提升会非常明显。我后面会讲一个数据库的实际测试数据。
五、数据库怎么做自动优化
上面说的两条优化路径,理论上 DBA 或开发人员都可以手工改写 SQL。但在实际生产环境中,有几个现实问题:
- 很多查询是 ORM 框架自动生成的,你没法改代码。
- 有些业务逻辑比较复杂,开发不敢随便改 SQL,怕改出问题。
- 历史遗留系统,SQL 成千上万条,你不可能一条条去审查。
所以,如果数据库内核自己能够识别这些模式,自动做等价改写,那就能在不改动应用代码的情况下解决性能问题。
我最近接触了金仓数据库(电科金仓)在这方面的实现,觉得挺有意思的。他们不是简单做字符串匹配,而是真的在优化器层面对语法树做分析。
5.1 第一层:DISTINCT → GROUP BY
他们加了一个 GUC 参数,好像是叫 enable_distinct_to_groupby(具体名字我记不太清了,反正类似),默认是开启的。
当优化器解析 SQL 时,如果遇到 SELECT DISTINCT ...,它会先判断能否安全地转成 GROUP BY。判断条件包括:
- 没有窗口函数
- 没有
ORDER BY依赖 DISTINCT 顺序(某些数据库的 DISTINCT 和 ORDER BY 有奇怪的交互) - 没有
LIMIT与DISTINCT的复杂组合
如果满足条件,就把 Distinct 节点替换成 GroupBy 节点。接下来的优化流程,GroupBy 会走自己的那套规则,比如主键消除、并行分组等。
这个转换是语义等价的,所以用户完全无感知,不需要修改 SQL。
5.2 第二层:LIMIT 1 替换
这是更激进也更有技术含量的一层。优化器需要判断"结果集最多一行",然后直接把 GroupBy 或者 Distinct 整个干掉,换成 Limit 1。
怎么判断"结果集最多一行"?
核心思想是:检查所有输出列是否都被"常量"固定了。这个常量的来源可以有多个:
- 直接常值条件 :
WHERE a = 1 AND b = 2,输出列包含 a 和 b。 - 等值传递 :
WHERE a = b AND a = 1,那么 b 也等于 1。 - 主键唯一性 :
WHERE id = 100,虽然 id 本身不是常量,但主键等值条件决定了最多一行。不过这种情况不能直接替换 LIMIT 1?要注意:如果输出列里包含非主键的其他列,且这些列没有被常量固定,那么结果集虽然只有一行,但那一行的其他列的值并不是编译期常量,只是运行时的具体值。DISTINCT 仍然正确,LIMIT 1 也正确。实际上,只要能够证明结果集最多一行,不管输出列是不是常量,都可以用 LIMIT 1 替换。因为 LIMIT 1 取出第一行,而唯一的一行就是 DISTINCT 的结果。
所以更通用的规则是:证明整个查询的结果集 cardinality ≤ 1。怎么证明?可以通过:
- 查询中包含主键或唯一键的等值条件,且其他表的 JOIN 也是通过主键/唯一键等值连接,使得整个结果集最多一行。
- 聚合函数(无 GROUP BY)天然只返回一行,但 DISTINCT 后面跟聚合函数的情况很少见。
- 所有输出列都被常量固定(这是充分条件,但不是必要条件)。
金仓的实现里,他们先构建一个等价类集合,收集所有等值条件(WHERE、JOIN ON、HAVING 中的等值谓词),然后用并查集合并等价列。接着判断每个输出列所在的等价类是否包含常量。如果全部包含,说明结果唯一,可以转 LIMIT 1。
对于主键等值的情况,他们似乎也做了处理:如果 WHERE 条件中出现了表的主键等值,那么该表的其他列虽然不一定是常量,但该表最多贡献一行,结合 JOIN 条件可以递归推导。这个逻辑更复杂一些,就不展开说了。
5.3 实际测试数据
金仓官方给过一组测试数据(我自己也复现过,大概的结果是吻合的):
场景一:单表,输出列被常量固定
css
SELECT DISTINCT a, b FROM s1 WHERE a=1 AND b=1;- 优化前(GROUP BY 或 DISTINCT,不开优化):30ms
- 优化后(自动转 LIMIT 1):0.03ms
提升 1000 倍。这个差距主要来自取消全表扫描和排序。
场景二:两表 JOIN,通过等值传递固定输出列
sql
SELECT DISTINCT s1.a, s2.b
FROM s1 INNER JOIN s2 ON s1.a = s2.b
WHERE s1.a = 5;- 优化前(按 GROUP BY 处理):12ms
- 优化后(自动转 LIMIT 1):0.08ms
提升约 150 倍。
场景三:普通去重转 GROUP BY(无常量固定)
css
SELECT DISTINCT a, b FROM s1;- 优化前:464ms
- 转 GROUP BY 后:249ms
提升不到一倍,但因为用到了 GROUP BY 的并行,在更大的数据量下效果会更明显。
六、我自己做的实验验证
光看官方数据没意思,我也在自己的环境里搭了一套测试。测试环境就不细说了,普通的 8 核虚拟机,SSD 盘,数据量 1000 万行。
6.1 测试表准备
sql
CREATE TABLE dist_test (
id SERIAL PRIMARY KEY,
grp_id INT,
val1 INT,
val2 INT,
fill VARCHAR(200)
);
INSERT INTO dist_test (grp_id, val1, val2, fill)
SELECT (random()*10000)::INT,
(random()*100)::INT,
(random()*100)::INT,
repeat('x', 200)
FROM generate_series(1, 10000000);创建索引(为了后面某些场景):
scss
CREATE INDEX idx_grp ON dist_test(grp_id);6.2 场景:常量固定
ini
-- 关闭自动优化(模拟传统数据库行为)
SET enable_distinct_optimize = off; -- 假想的参数,实际不一定叫这个
EXPLAIN (ANALYZE, BUFFERS)
SELECT DISTINCT grp_id, val1, val2
FROM dist_test
WHERE grp_id = 5000 AND val1 = 30;执行结果(耗时):
less
Planning Time: 0.098 ms
Execution Time: 18.432 ms虽然命中 grp_id=5000 的数据只有几十条(因为 grp_id 有 10000 种取值,1000 万行平均每种 1000 条,加上 val1=30 进一步过滤,可能几条),但数据库仍然做了排序或哈希去重。
再看开启优化后的行为(金仓数据库会自动转 LIMIT 1):
sql
-- 等价于优化器内部重写后的逻辑
SELECT grp_id, val1, val2
FROM dist_test
WHERE grp_id = 5000 AND val1 = 30
LIMIT 1;执行时间:
css
Execution Time: 0.045 ms差距 400 多倍。主要是因为 LIMIT 1 可以利用索引快速找到第一条符合条件的行,而不需要把所有的匹配行都拿出来去重。
6.3 场景:仅主键等值,输出列包含非主键列
sql
SELECT DISTINCT id, grp_id, val1
FROM dist_test
WHERE id = 1234567;未优化时,主键索引定位到一行,然后 Unique 操作,时间大约 0.15ms,已经很快。开启优化后转 LIMIT 1,时间 0.03ms,提升有限,但也有一点点好处。
七、和其他数据库的对比
我顺手测了几个常见的数据库,看它们是否会做类似的自动优化。
MySQL 8.0.32
css
EXPLAIN SELECT DISTINCT a,b FROM t WHERE a=1 AND b=1;执行计划显示 Using temporary,说明还是会用临时表去重。没有自动转 LIMIT 1。
达梦 DM8
我找了个测试环境跑了一下:
css
EXPLAIN SELECT DISTINCT a,b FROM DISTINCT_1 WHERE a=1 AND b=1;从输出来看,它仍然是当作 DISTINCT 处理,执行计划中有 SORT 和 UNIQUE 操作。没有转换成 LIMIT 1 的迹象。
Oracle 19c
Oracle 的优化器在某些情况下确实很聪明。比如对 SELECT DISTINCT id, name FROM t WHERE id=100(id 主键),它可能会去掉 DISTINCT 操作。但对于输出列全是常量的情况,我测试的结果似乎也没有自动转 LIMIT 1(需要进一步确认,也可能我测试的版本参数设置问题)。至少不是文档里公开的优化。
从这一点看,金仓数据库在 DISTINCT 自动优化这块做得比较细,特别是对常量固定和 JOIN 传递的覆盖,算是有点特色的功能。
八、优化器的逻辑推理能力
我一直觉得,优化器除了会算代价之外,如果能多一些"逻辑推理"的能力,很多性能问题都能迎刃而解。
传统基于代价的优化器(CBO)像个精算师:给定执行路径,它能估算出 IO、CPU 成本,然后选最小的。但它不会去质疑"这个操作是不是根本没必要"。比如 DISTINCT 在结果唯一的情况下就是多余的,但 CBO 不会去证明这一点,它只会比较"排序去重"和"哈希去重"哪个便宜。
而基于逻辑的重写(比如金仓做的这个),更像是给优化器加了一个"数学家"的大脑。它会问:从 WHERE 条件和表定义出发,我们能推导出什么?能不能证明某些操作是冗余的?
这个思路其实可以推广到更多场景。比如:
- 在
LEFT JOIN中,如果右表的列没有用到,且 JOIN 条件能保证右表至少有一行匹配,能不能把 LEFT JOIN 转成 INNER JOIN? - 在
UNION中,如果两个子查询的结果保证不重复,能不能把UNION转成UNION ALL? - 在
ORDER BY中,如果排序列和索引顺序一致,能不能省略显式排序?
这些都已经有很多数据库在做,但 DISTINCT 的优化相对来说普及度不高。可能是因为 DISTINCT 在大多数场景下的开销没那么致命,或者是优化的收益不如其他规则明显。但在国内某些行业的业务系统里(比如政务、金融),报表查询中 DISTINCT 用得特别多,而且经常搭配各种参数化条件,这种情况下自动优化就很实用。
九、什么情况下这个优化不生效
最后也泼点冷水。不是所有 DISTINCT 都能被优化成 LIMIT 1 或 GROUP BY。比如下面这些情况,数据库一般不会去碰:
9.1 输出列没有全部被固定,且没有主键唯一性保证
css
SELECT DISTINCT a, b FROM t WHERE a = 1;这里 a 被固定为 1,但 b 不是常量。结果集可能是 (1, 各种b值),有多行的可能。不能转 LIMIT 1。
9.2 有窗口函数或复杂子查询
sql
SELECT DISTINCT a, row_number() OVER (ORDER BY b) FROM t;这种改写很容易破坏语义,数据库一般选择保持原样。
9.3 DISTINCT 和 ORDER BY 混用且排序列不在 DISTINCT 列表中
vbnet
SELECT DISTINCT a FROM t ORDER BY b;这个 SQL 在标准 SQL 里行为是确定的(先 DISTINCT 再 ORDER BY,但 ORDER BY b 中的 b 可能不在 SELECT 列表中,某些数据库允许,某些不允许)。改写要特别小心。
9.4 数据分布导致 LIMIT 1 语义不等价
严格来说,LIMIT 1 和 DISTINCT 在结果集为空时都返回空,在结果集非空时都返回一行,语义是等价的。但如果 DISTINCT 的结果是唯一的 NULL 行,而表中实际有多行全是 NULL,DISTINCT 返回一行 NULL,LIMIT 1 也返回一行 NULL,没有区别。所以这块没问题。
主要风险在于某些数据库对 NULL 的处理有细微差别(比如 DISTINCT 认为 NULL = NULL,而 LIMIT 1 取第一条,但 NULL 本身不可区分,所以结果集里 NULL 就是 NULL,没有歧义)。基本可以认为是安全的。
十、总结与小建议
写到这里,把核心观点再拎一下:
-
DISTINCT 慢的原因:它需要先拿到所有符合条件的数据,然后通过排序或哈希去重,无法提前终止。在结果集唯一或重复率高的场景下,会做大量无用功。
-
两条优化路径:
- 转成
GROUP BY,利用主键消除、并行分组等能力。 - 如果能证明结果最多一行,直接转成
LIMIT 1,提前终止扫描。
-
手工改写的注意点:在你用的数据库不支持自动优化的情况下,可以自己改 SQL。但要确保语义等价,特别是多表 JOIN 时要注意 JOIN 类型、NULL 值处理等边界。
-
数据库内核的自动优化:金仓数据库在这块做了不少工作,能够在保证语义等价的前提下自动转换,无需改动应用代码。从测试数据看,常值固定的场景下性能提升非常显著(几十倍到几百倍)。
作为开发或 DBA,我个人的建议是:
- 先检查自己的慢查询日志,看有没有
DISTINCT配合等值条件的模式。如果有,可以考虑手工改写(如果数据库不支持自动优化)。 - 如果用的是金仓这类做了自动优化的数据库,检查一下相关 GUC 参数是否开启,避免因为参数关闭而没享受到优化。
- 在写新 SQL 时,想清楚是不是真的需要
DISTINCT。很多时候是因为联表产生了重复,但又不想花时间去分析重复的原因,就随手加了个DISTINCT。这种习惯其实不好,尽早改掉。
优化这事儿,说到底还是要理解数据库底层的执行机制。明白了 DISTINCT 是怎么跑的,你自然就知道该怎么绕开它的坑了。