灰度标如何全链路透传:APM、自研方案与 Java Agent 的实现取舍
1. 为什么灰度发布需要全链路透传组件
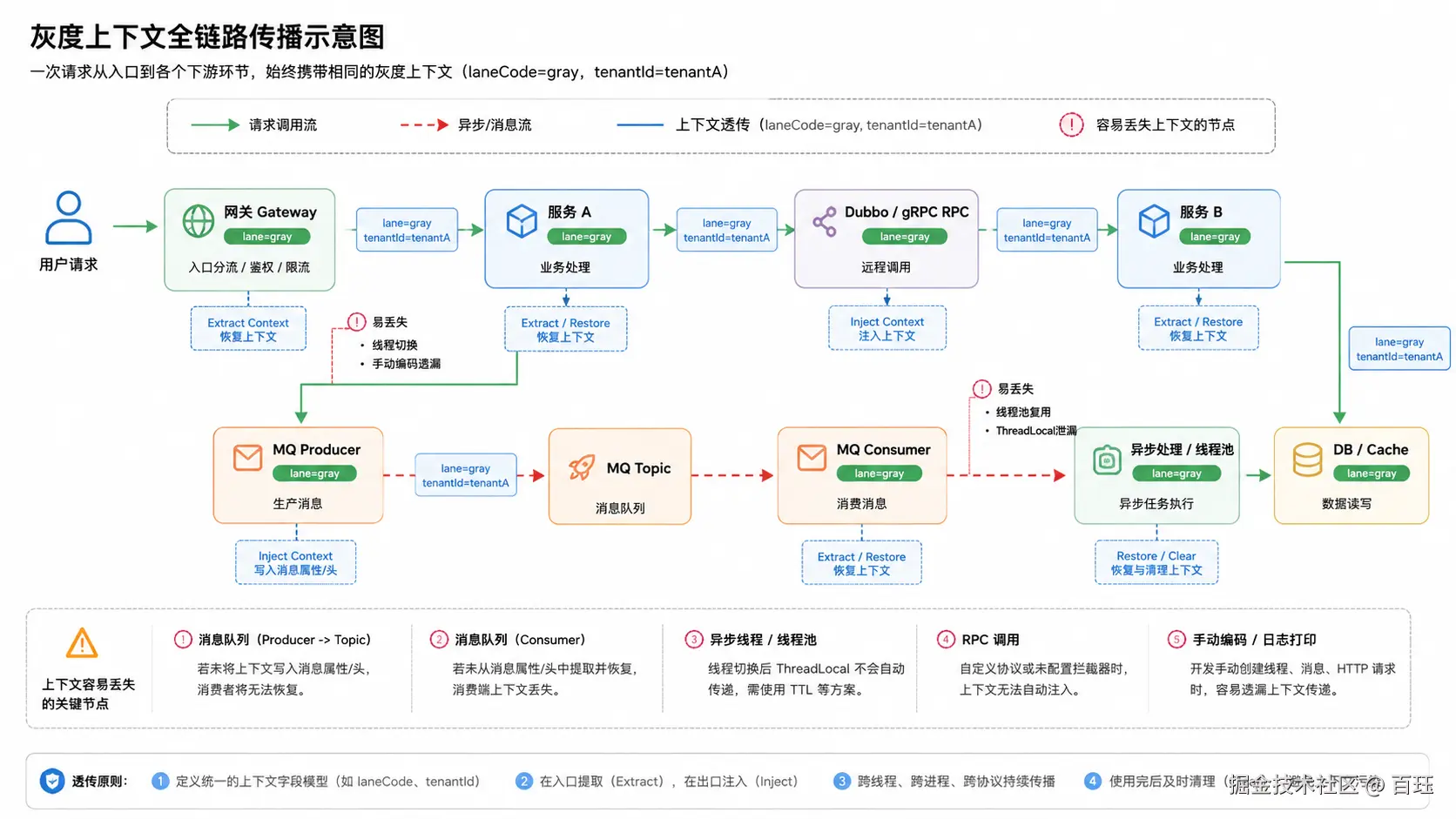
灰度发布不仅是将入口流量按比例分流,更重要的是保证一次请求在整个生命周期内,始终遵循同一套灰度规则。
入口流量一旦被判定为灰度流量,其后续经过的网关、HTTP 调用、RPC、MQ、定时任务、异步线程等所有环节,都必须持续携带该灰度上下文。否则,系统将面临以下典型问题:
- 灰度标丢失:入口命中灰度规则,但下游服务因丢失灰度标而回落到基线实例。
- 链路不一致:同一条调用链中,部分服务走灰度,部分走基线,导致数据读写不一致。
- 异步决策断链:消息异步化后灰度上下文丢失,消费端无法延续原始的路由决策。
- 线程切换失效:线程切换后上下文丢失,导致日志、TraceId 与灰度标彼此无法关联。
因此,灰度发布真正依赖的底层能力,往往是一层独立的业务上下文全链路透传组件。该组件需要切实解决以下三个核心问题:
- 定义模型 :定义一套稳定且通用的上下文字段模型,例如
laneCode(泳道标)、tenantId(租户标)。 - 边界处理 :在各类组件的入口和出口完成上下文的提取(Extract)、注入(Inject)、恢复(Restore)和清理(Clean)。
- 跨界传播:保证上下文在跨线程、跨进程、跨协议传输时的连续性。
2. 自研方案与复用 APM 扩展能力的取舍
提到全链路透传,很多开发者的第一反应是复用现有的 APM 组件。
从实现路径上看,通常有两种选择:
yaml
路径 A: 直接复用 APM 的上下文传播能力 (如 Sleuth/Micrometer Baggage, SkyWalking Correlation, OTel Baggage)
路径 B: 自建面向业务的透传 SDK (将 APM 退化为单纯的 TraceId 提供方与观测后端)路径 A 的吸引力在于前期开发成本低,因为 APM 框架通常已经内置了对 HTTP、消息队列、线程池、日志 MDC 的部分集成。
但这种方案的局限性也较为明显:APM 的核心定位是分布式观测,其背后承载着 Trace 模型、传播器(Propagator)、采样策略、指标聚合及版本兼容等一整套复杂的体系。如果强行将业务路由逻辑绑定在 APM 组件上,可能会遇到以下挑战:
- 扩展成本高:面对企业内部的非标协议或自研中间件时,仍需深入 APM 复杂的插件机制进行二次开发。
- 技术栈绑定:一旦未来面临 APM 产品的升级、替换(例如从 Sleuth 迁移到 Micrometer Tracing),原有的透传逻辑、插件和传播语义也需要同步重构。
因此,核心问题并不在于"能否复用 APM",而在于是否愿意将事关业务路由的灰度透传逻辑,深度耦合在特定 APM 产品的实现细节中。
3. 当前主流路线对比
目前行业中主流的透传路线主要分为以下两类:
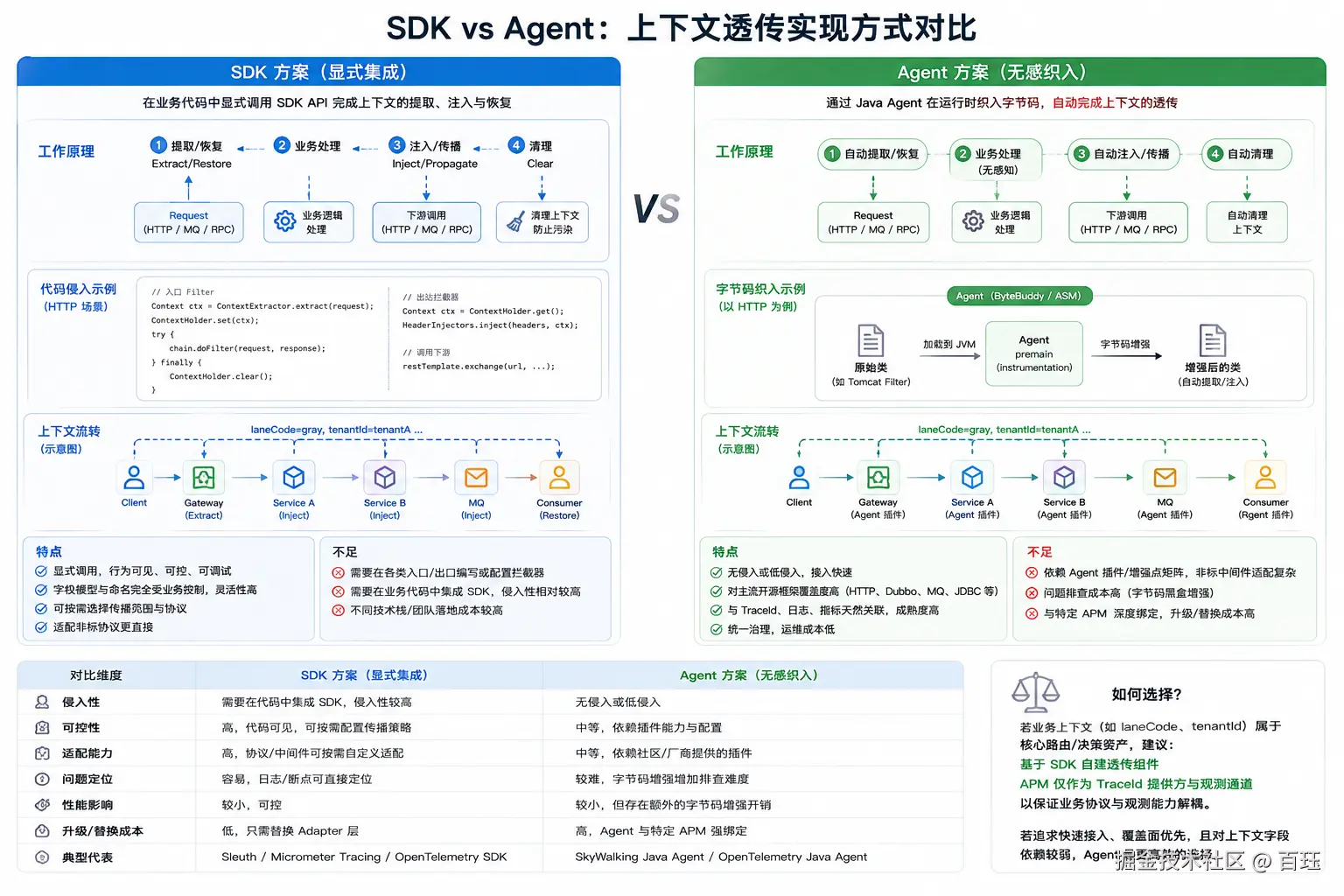
3.1 SDK 路线(显式集成)
业务代码或基础设施组件显式调用上下文 API 进行透传。
- 典型代表:Spring Cloud Sleuth、Micrometer Tracing、OpenTelemetry SDK。
- 特征:适配过程清晰可控,代码逻辑显式呈现,便于调试和定制。
3.2 Java Agent 路线(无感织入)
利用字节码增强技术,在应用无感知或低侵入的前提下,自动将传播逻辑织入目标框架。
- 典型代表:Apache SkyWalking Java Agent、OpenTelemetry Java Agent。
- 特征:开箱即用,对主流开源框架覆盖面广,但高度依赖中间件的插件支持矩阵。
4. 两类方案的具体实现思路
4.1 SDK 方案的实现方式
SDK 方案通常将灰度标等业务字段放入 Tracing Context 中,作为 Baggage 或 Extra Field 进行维护:
- 当前线程:创建或更新 Baggage。
- HTTP 出站:将 Baggage 注入(Inject)到请求头。
- HTTP 入站:从请求头提取(Extract)并恢复 Baggage。
- 日志关联:将指定字段同步至日志框架的 MDC(Mapped Diagnostic Context)。
4.2 Java Agent 方案的实现方式
Java Agent 方案主要通过增强开源框架的入口和出口来实现自动传播。
以 Apache SkyWalking 为例:
- Agent 在 HTTP、Dubbo、MQ 等组件的拦截点织入插件。
- 出口插件将业务字段编码进特定协议头(如
sw8-correlation)。 - 入口插件在接收端解析该协议头,并恢复至
Correlation Context。
示例文章: juejin.cn/post/728268...
SkyWalking 业务上下文传递示例:
java
package com.example.gateway;
import org.apache.skywalking.apm.toolkit.trace.TraceContext;
public final class GrayContext {
private GrayContext() {}
public static void mark(String laneCode) {
// 将灰度标写入 Correlation Context,由 Agent 自动跨进程透传
TraceContext.putCorrelation("laneCode", laneCode);
}
}5. 方案优缺点客观分析
| 维度 | SDK 方案 | Java Agent 方案 |
|---|---|---|
| 优点 | • 行为可预期,易于单体调试。 • 字段模型与命名完全受控,适合复杂的业务域上下文。 • 隔离性强,替换 APM 产品时无需重写业务透传协议。 | • 无需或极少修改业务代码,接入迅速。 • 开源社区对主流框架(如 WebFlux、JDBC)适配度高。 • 对 TraceId 生成与日志关联等基础功能支持非常成熟。 |
| 缺点 | • 需要对各种协议(HTTP、RPC、MQ)逐一编写或配置拦截器。 • 面对缺乏统一技术栈的团队,推广与落地成本较高。 | • 遇到非标中间件或自定义协议时,需编写复杂的 Agent 插件。 • 字节码黑盒增强增加了排查偶发性问题的难度。 |
6. 为什么建议基于 SDK 自建透传组件
为了保障核心路由逻辑的稳定性,更稳妥的工程实践通常是:基于 SDK 自建一层轻量级的业务透传组件,下层对接具体的 APM 实现。
lua
+------------------------------------------+
| 业务代码 / 路由网关 |
+------------------------------------------+
| 自建业务透传组件 (SDK) | <-- 统一管理 laneCode, tenantId 等
+------------------------------------------+
| 适配层 (Adapter / SPI) |
+------------------------------------------+
| [ OTel / Micrometer / SkyWalking ] (APM) | <-- 仅作为 TraceId 提供方与观测通道
+------------------------------------------+这种架构有三个直接好处:
- 业务协议与 APM 解耦:灰度标等业务属性属于业务资产,不应绑定在特定 APM 的私有传输协议上。
- 适配层可单独演进:未来若从 Micrometer 切换到 OpenTelemetry,只需重写适配层,业务方的 API 调用无需任何改动。
- 业务指标优先级更高:灰度发布的核心诉求是确保业务字段不丢失,自建组件能更精确地控制这些字段的生命周期。
7. 落地自建透传组件时需重点覆盖的场景
7.1 HTTP 场景
利用 Filter 在 Servlet 入口处提取并恢复上下文,并在请求结束时务必清理,防止线程复用导致上下文污染。
java
package com.example.http;
import com.example.context.ContextAttachment;
import com.example.context.TraceContext;
import jakarta.servlet.Filter;
import jakarta.servlet.FilterChain;
import jakarta.servlet.ServletRequest;
import jakarta.servlet.ServletResponse;
import jakarta.servlet.http.HttpServletRequest;
import java.util.ArrayList;
import java.util.Enumeration;
import java.util.List;
public class ContextServletFilter implements Filter {
private final Iterable<ContextAttachment> attachments;
public ContextServletFilter(Iterable<ContextAttachment> attachments) {
this.attachments = attachments;
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) {
HttpServletRequest httpRequest = (HttpServletRequest) request;
try {
TraceContext.setContext(name -> {
Enumeration<String> values = httpRequest.getHeaders(name);
List<String> result = new ArrayList<>();
while (values != null && values.hasMoreElements()) {
result.add(values.nextElement());
}
return result;
}, attachments);
chain.doFilter(request, response);
} catch (Exception ex) {
throw new RuntimeException(ex);
} finally {
// 必须在 finally 块中清理,防止 ThreadLocal 污染
TraceContext.clear();
}
}
}7.2 MQ 场景
MQ 场景需同时对生产端和消费端进行双向拦截。
- 生产端注入:
java
package com.example.mq;
import com.example.context.TraceContext;
public class MessageContextProducer {
public void beforeSend(Message message) {
TraceContext.propagate((key, values) ->
message.putProperty(key, String.join("|", values)));
}
public interface Message {
void putProperty(String key, String value);
}
}- 消费端提取(注意修正正则表达式转义问题):
java
package com.example.mq;
import com.example.context.ContextAttachment;
import com.example.context.TraceContext;
import java.util.Arrays;
import java.util.Collections;
public class MessageContextConsumer {
private final Iterable<ContextAttachment> attachments;
public MessageContextConsumer(Iterable<ContextAttachment> attachments) {
this.attachments = attachments;
}
public void onMessage(Message message, Runnable businessLogic) {
try {
TraceContext.setContext(name -> {
String raw = message.getProperty(name);
if (raw == null || raw.isBlank()) {
return Collections.emptyList();
}
// 使用 "\\|" 替代 "\|" 以保证正则转义正确
return Arrays.asList(raw.split("\\|"));
}, attachments);
businessLogic.run();
} finally {
TraceContext.clear();
}
}
public interface Message {
String getProperty(String name);
}
}- 注意:在批量消费场景下,需明确业务策略(如默认提取首条消息的上下文,或采取拆分单条处理的消费策略)。
7.3 Dubbo / RPC 场景
在 Provider 和 Consumer 侧分别配置 Filter,通过 Attachment 进行上下文的传递。
- Consumer 侧拦截:
java
package com.example.rpc;
import com.example.context.TraceContext;
import org.apache.dubbo.rpc.Filter;
import org.apache.dubbo.rpc.Invocation;
import org.apache.dubbo.rpc.Invoker;
import org.apache.dubbo.rpc.Result;
public class ConsumerContextFilter implements Filter {
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) {
TraceContext.propagate((key, values) ->
invocation.setAttachment(key, String.join("|", values)));
return invoker.invoke(invocation);
}
}- Provider 侧拦截:
java
package com.example.rpc;
import com.example.context.ContextAttachment;
import com.example.context.TraceContext;
import org.apache.dubbo.rpc.Filter;
import org.apache.dubbo.rpc.Invocation;
import org.apache.dubbo.rpc.Invoker;
import org.apache.dubbo.rpc.Result;
import java.util.Arrays;
import java.util.Collections;
public class ProviderContextFilter implements Filter {
private final Iterable<ContextAttachment> attachments;
public ProviderContextFilter(Iterable<ContextAttachment> attachments) {
this.attachments = attachments;
}
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) {
try {
TraceContext.setContext(name -> {
String raw = invocation.getAttachment(name);
if (raw == null || raw.isBlank()) {
return Collections.emptyList();
}
return Arrays.asList(raw.split("\\|"));
}, attachments);
return invoker.invoke(invocation);
} finally {
TraceContext.clear();
}
}
}7.4 定时任务
由于定时任务缺乏上游请求,因此在任务触发时,应当在其生命周期开始时初始化一个新的"根上下文"(如生成全新的 TraceId,并根据配置绑定特定的泳道或环境信息),任务结束时同样需要及时清理。
8. 异步线程与 TTL(TransmittableThreadLocal)的集成
异步线程通常是上下文丢失的高发地带。由于线程池中的线程是被预先创建并复用的,普通的 ThreadLocal 以及只在线程创建时复制一次的 InheritableThreadLocal 均无法解决"任务提交时刻"上下文向"执行线程"传递的问题。
阿里巴巴开源的 TransmittableThreadLocal (TTL) 专为此场景设计。
8.1 接入 TTL 的三种常见方式
- 手动包装 :使用
TtlRunnable.get(task)显式包装任务。 - 池级包装 :使用
TtlExecutors.getTtlExecutorService(executor)包装线程池。 - Agent 自动增强 :挂载
transmittable-thread-localJava Agent,实现字节码级别的线程池无感增强。
若要在项目中尽量减少对业务代码的侵入,通常会采用 Agent 挂载 的方式。 Agent挂载需要考虑注意一些风险点
8.2 TTL Agent 的加载顺序与避坑指南
在实际生产环境中,TTL Agent 与 APM Agent(如 SkyWalking、Prometheus)同时挂载时,极易因加载顺序问题导致线程池增强失效:
- 失效原因 :诸如 SkyWalking 等 APM Agent 在其初始化阶段(
premain)就会触发线程池或特定基础类的加载。如果此时 TTL Agent 尚未加载,那么这些被提前加载的线程池类将失去被 TTL 字节码增强的机会,导致异步透传失效。 - 解决方案 :在 JVM 启动参数中,必须将 TTL Agent 配置在最前位置。
- 风险 使用 agent 挂载需要考虑一些风险点# TTL Agent 踩雷实践
启动参数配置示例:
bash
java -javaagent:/path/to/transmittable-thread-local-2.x.y.jar \
-javaagent:/path/to/skywalking-agent.jar \
-jar app.jar9. 总结
灰度发布设计的精髓,在于业务上下文能否在复杂的微服务网格中稳定、不失真地完成全链路透传。
复用 APM 扩展能力能帮助团队在初期快速跑通流程;但从长远演进来看,基于 SDK 自建一层轻量级的业务透传组件,并将具体的 APM 抽象为底层实现,是构建健壮灰度发布体系的更优解。在此基础上,辅以 TTL Java Agent 解决异步线程池的透传瓶颈并注意挂载顺序,即可为全链路灰度路由打下坚实的基础。