系列定位说明
本文是 "领域驱动设计与业务架构"系列的第 1 篇,定位为 DDD(领域驱动设计)的战略设计层。在"微服务与云原生架构"系列的第 3 篇中,我们从技术架构视角探讨了微服务拆分策略,并指出限界上下文是其核心依据。总纲系列第 1 篇则建立了"四大能力域 × 五层架构"的统一模型,其中 DDD 的限界上下文正是业务能力在软件模型中的直接映射。
现在,我们将视角从技术架构拉回业务源头,回答一个根本性问题:服务的边界究竟从哪里来? DDD 的战略设计------统一语言、限界上下文、实体与值对象------正是这个问题的答案,它也是本系列后续战术设计、工程落地和架构演进的基石。
总结性引言
你接手了一个电商系统,业务文档厚达 200 页,需求涵盖了用户下单、库存扣减、支付确认、物流发货、通知推送、数据统计。如果直接按技术层面划分------分成 Controller 层、Service 层、DAO 层------你很快会发现任何一个小需求变更都要跨多个"技术模块"修改。如果按数据库表划分------订单表归订单服务,用户表归用户服务------你又会发现有些需求(如下单需要用户信息、库存信息、支付信息)会跨越多个服务,导致分布式事务和不可接受的耦合。
这些问题的根源在于:你没有一个从业务语义出发的"限界上下文"。DDD 的战略设计正是解决这个问题的。通过事件风暴,你和业务专家一起在白板上梳理出领域事件(订单已创建、库存已扣减、支付已确认),自然聚类出限界上下文(订单上下文、库存上下文、支付上下文);通过统一语言,你确保代码中的 Order.place() 和产品经理口中的"下单"精确对应;通过实体和值对象,你精确建模了哪些对象需要唯一标识(实体------如订单),哪些对象只需关心属性值(值对象------如收货地址)。
更进一步,事件风暴的输出可以直接按规则生成代码骨架------领域事件和命令映射为不可变 final class,聚合映射为 @Entity,值对象映射为 @Embeddable 不可变类。而 ArchUnit 规则则为这些边界提供了自动化验证------检测上下文内部的分层架构和跨上下文的非法依赖。
本文将以电商订单系统为贯穿案例,从业务需求文档出发,通过事件风暴一步步推导出限界上下文,并在 Spring Boot 工程中用 @Entity 和 @Embeddable 落地实体和值对象,同时展示如何用 AI 辅助提取领域事件和生成统一语言术语表。
核心要点
- 统一语言:团队与业务专家协同建立术语表,代码中类名/方法名/API 路径精确映射,同一词汇不同含义即上下文边界。
- 事件风暴 :领域事件(过去式)→ 命令 → 聚合 → 限界上下文的四步推导法,代码骨架生成规则(事件/命令→不可变
final class,聚合→@Entity,值对象→@Embeddable不可变类)。 - 限界上下文验证:四大启发式规则 + ArchUnit 检测包级分层与跨上下文依赖。
- 上下文映射:六种模式,每种关联具体通信协议示例(客户-供应商→OpenAPI 3.0,发布语言→Avro Schema Registry)。
- 实体与值对象 :实体用
@Entity + @Id唯一标识,值对象用@Embeddable+ 不可变类(private final字段,全参构造器,无 setter)。
文章组织架构图
图表主旨概括:本流程图展示了全文十大模块之间的逻辑递进关系,从战略设计全景出发,深入三大核心概念,最终汇聚到AI辅助和贯穿案例,并以面试专题(尤其包含系统设计题)收尾,形成学以致用的闭环。
逐层/逐元素分解:
- 根基层(模块1):建立DDD战略设计的三大核心概念------统一语言、限界上下文、实体与值对象的全局认知。
- 核心概念层(模块2、3、6):分别深入探讨统一语言、事件风暴、实体与值对象这三个独立又相互关联的核心领域。
- 工程验证与集成层(模块4、5):在核心概念基础上,引入限界上下文的工程验证方法和上下文间的集成模式。
- 聚合与实践层(模块7、8):将前述所有概念通过AI辅助探索和完整的电商案例进行串联和实践。
- 收尾层(模块9、10):缝合系列其他篇章,并通过深度面试题(包括一道完整系统设计题)巩固和检验学习成果。
设计原理映射:该结构严格遵循DDD战略设计的认知路径:先理解"是什么"(全景图),再学习"怎么做"(统一语言、事件风暴、实体建模),接着是"怎么验证和连接"(ArchUnit验证、上下文映射),最后是"如何综合应用"(AI辅助、贯穿案例、系统设计)。
工程联系与关键结论加粗 :DDD战略设计的核心不是"画图",而是"建立业务与代码的统一词汇表"。事件风暴的输出可以直接映射为代码骨架,ArchUnit为边界提供自动化验证。当业务专家说"订单已创建"时,你代码中Order.placed()方法被调用,领域事件OrderPlacedEvent被发布------这才是DDD落地的终极目标。
1. DDD 战略设计全景:统一语言、限界上下文、实体与值对象
领域驱动设计(DDD)并非一门具体的技术,而是一套处理软件核心复杂性的思想体系。它分为两个层次:战略设计 与战术设计。战略设计关注宏观层面的业务边界和模型划分,其三大核心概念构成了理解业务、建模业务的基础框架:
- 统一语言(Ubiquitous Language):是业务专家与开发团队共享的、严格定义的语言,是所有讨论、文档和代码的基础。
- 限界上下文(Bounded Context):是一个语义明确的模型边界。在一个限界上下文内,统一语言中的所有术语都有其特定且无歧义的含义。它是划分业务能力的基本单元。
- 实体(Entity)与值对象(Value Object):是限界上下文内用于表达领域模型的基础构造块。实体拥有唯一的、贯穿生命周期的标识,而值对象仅由其属性值定义。
这三者的关系可以用一个形象的比喻来理解:统一语言是"词汇",限界上下文是"词典",而实体与值对象是"单词"。一本词典(限界上下文)定义了一系列词汇(统一语言)的精确含义,而这些词汇由一个个单词(实体/值对象)构成。在不同的词典里,同一个单词可能有完全不同的释义,这正是限界上下文的边界所在。
在"微服务与云原生架构系列第 3 篇"中,我们已达成共识:限界上下文是微服务拆分最核心的理论依据。一个设计良好的限界上下文,其业务能力内聚、数据独立、团队自治,能够自然地映射为一个或一组微服务。本文后续所有讨论,都将围绕如何从业务需求出发,识别并落地限界上下文而展开。
2. 统一语言的建立与代码映射
2.1 统一语言的定义与建立流程
统一语言不是一个存放在Confluence里吃灰的术语表文档,而是团队每天在对话和编码中使用的、活的、代码中无处不在的语言。它的建立是DDD战略设计的起点。
建立流程:事件风暴工作坊 → 术语表
- 事件风暴工作坊 :业务专家、产品经理、架构师、开发人员聚集在白板前。我们用橙色便签纸写下领域事件(Domain Event),即业务上已经发生的事实。例如,"订单已提交"(Order Placed)、"库存已扣减"(Inventory Deducted)。
- 术语碰撞与对齐:当有人写下"订单已创建"时,可能有人会问:"它和'订单已提交'是同一个意思吗?"这种讨论本身就是建立统一语言的过程。最终,团队必须就每个术语的含义、使用场景达成唯一共识。
- 输出术语表(Glossary):将达成一致的术语整理为结构化的文档。每个术语包含中文名、英文类名、精确的定义、所属的限界上下文。下表为电商订单系统部分术语表示例:
| 中文名 | 英文类名 | 定义 | 所属上下文 |
|---|---|---|---|
| 订单 | Order |
用户一次购买行为的记录和状态跟踪 | 订单上下文 |
| 订单已提交 | OrderPlaced |
用户提交订单,订单进入待支付状态 | 订单上下文 |
| 库存 | Inventory |
某个SKU的可售数量、锁定数量等 | 库存上下文 |
| 支付 | Payment |
针对一笔订单的支付行为和结果记录 | 支付上下文 |
| 确认支付 | ConfirmPayment |
第三方支付网关返回支付成功后的内部确认动作 | 支付上下文 |
| 地址 | Address |
收货地址的值快照,包含省/市/区/详情 | 订单上下文、物流上下文 |
| 金额 | Money |
表示金额和货币类型的值对象 | 共享内核 |
2.2 代码中的映射规则
统一语言的终极目标是将其直接映射到代码中。这意味着你的代码读起来应该像一本关于业务领域的书。
| 代码元素 | 规则 | 正例 | 反例 |
|---|---|---|---|
| 类名 | 直接使用业务术语,避免技术后缀 | Order, Product, Customer |
OrderInfo, OrderEntity, OrderDTO |
| 方法名 | 表达业务意图,避免CRUD风格 | place(), confirmPayment() |
createOrder(), updatePaymentStatus() |
| 包名 | 反映限界上下文和模块边界 | com.company.order.domain |
com.company.model |
| API路径 | 资源命名使用业务术语,动词用HTTP方法表达 | POST /api/v1/orders |
POST /api/v1/createOrder |
| 数据库表名 | 与聚合根实体名保持一致 | t_order, t_order_item |
sys_order_info_tab |
2.3 词汇差异:限界上下文的边界指示灯
当一个词汇在不同上下文中具有不同含义时,这就是一个强烈的信号,表明这里存在着一个限界上下文的边界。强行将两个不同的含义塞进同一个模型会导致歧义和臃肿。
案例:"用户"这个词
-
在"订单上下文"中 ,"用户"被建模为"下单者"。我们只关心标识和名称。
java// 订单上下文 @Embeddable public class Placer { private final Long userId; private final String userName; // 构造器,getter, equals/hashCode... } -
在"用户画像上下文"中 ,"用户"是一个拥有复杂偏好和标签的分析对象。
java// 用户画像上下文 @Entity public class UserProfile { @Id private Long userId; private Integer age; private List<String> preferences; private Map<String, Double> tags; // ... }
在这个例子中,Placer 是一个值对象,它只是订单上下文中的一个快照。订单上下文不关心用户的年龄或偏好。而 UserProfile 是用户画像上下文中的一个实体,拥有自己独立的生命周期和复杂的分析模型。这两个"用户"在不同的上下文中,通过 userId 关联,但模型完全解耦。
2.4 统一语言的反模式
- 后缀泛滥 :在类名后加
Info、DTO、VO等后缀。应直接使用业务术语,例如Order。数据传输对象可以用OrderResponse等更精确的表述,或者明确放在dto包中。 - CRUD 思维命名 :方法名使用
create、update、delete等通用动词,这模糊了业务意图。业务行为如"下单"用place,"取消订单"用cancel,能更准确地表达领域知识。 - 一词多译 :在代码的不同地方,对同一个业务概念使用不同的英文表达,例如
purchase和order混用。
3. 事件风暴:从业务需求到限界上下文与代码骨架
事件风暴是Alberto Brandolini发明的一种工作坊方法,是快速探索复杂业务领域、建立统一语言和发现限界上下文的利器。它以"事件"为中心,通过四步法,将业务需求一步步推导为可落地的领域模型。
3.1 事件风暴四步法详解
我们以电商订单系统的一个核心流程为例:"用户下单后,系统扣减库存,用户完成支付,系统发送通知"。
第一步:识别领域事件(Domain Event)------ 过去式的业务事实
领域事件是事件风暴的起点,是领域专家关心的、已经发生的事实。它总是用过去式动词表达。
OrderPlaced:订单已提交。InventoryDeducted:库存已扣减。PaymentConfirmed:支付已确认。PaymentFailed:支付失败。NotificationSent:通知已发送。
第二步:识别命令(Command)------ 触发事件的动作
命令是用户意图的表达,它触发了领域事件。命令通常以"动词+名词"的形式出现。
PlaceOrder→ 触发OrderPlacedDeductInventory→ 触发InventoryDeducted或InventoryDeductionFailedConfirmPayment→ 触发PaymentConfirmed或PaymentFailedSendNotification→ 触发NotificationSent
第三步:识别聚合(Aggregate)------ 接收命令并产生事件的对象簇
聚合是领域模型的核心,它是一个由实体和值对象组成的、具有事务一致性的边界。聚合接收命令,执行业务规则,并产生领域事件。
Order聚合:接收PlaceOrder命令,执行验证,产生OrderPlaced事件。Inventory聚合:接收DeductInventory命令,检查库存并扣减,产生InventoryDeducted事件。Payment聚合:接收ConfirmPayment命令,处理支付,产生PaymentConfirmed事件。Notification聚合:接收SendNotification命令,发送消息,产生NotificationSent事件。
第四步:聚类为限界上下文(Bounded Context)------ 确定边界
将关联紧密的聚合、事件和命令归入同一个限界上下文。依据是这些元素围绕着一个共同的核心业务能力。
- 订单上下文 :包含
Order聚合,处理下单、修改收货地址等。 - 库存上下文 :包含
Inventory聚合,处理入库、出库、库存扣减等。 - 支付上下文 :包含
Payment聚合,处理支付确认、退款等。 - 通知上下文 :包含
Notification聚合,处理邮件、短信、站内信等。
事件风暴四步法流程图
图表主旨概括:该流程图直观地展示了事件风暴从模糊的业务需求出发,逐步推导出领域事件、命令、聚合,并最终聚类为限界上下文的四个结构化步骤。
逐层/逐元素分解:
- 输入层:最左端的业务需求是事件风暴的输入。
- 事件识别层:第一步,识别出所有过去式的业务事实,这是整个分析过程的"锚点"。
- 命令识别层:第二步,为每个事件找到其触发的源头------用户或外部系统的意图。
- 聚合抽象层:第三步,将事件和命令归属到具体的业务对象簇,形成聚合。
- 上下文边界层:第四步,也是最终目标,将关联的聚合聚类为限界上下文,划定清晰的业务边界。
设计原理映射:此流程的核心思想是"从果溯因",从最稳定、最能反映业务真相的"事件"出发,反向推导出系统的行为和结构,能有效避免过早陷入数据结构设计的陷阱。
工程联系与关键结论加粗 :事件风暴的每一个阶段都有明确的产出物,这些产出物是后续代码生成的直接输入。命令和事件可以直接映射为final class,聚合映射为@Entity,限界上下文映射为一个顶层包。这让分析与设计之间不再有鸿沟。
3.2 代码骨架生成规则
事件风暴的输出不是只供观赏的图表,而是可以按规则直接转化为代码骨架。这确保了模型与代码的一致性。
| 事件风暴元素 | 代码映射 | 关键特征 |
|---|---|---|
| 领域事件 (Domain Event) | public final class ...Event |
不可变类,private final 字段,全参构造器,getter 方法,描述已发生的事实。 |
| 命令 (Command) | public final class ...Command |
不可变类,private final 字段,全参构造器,getter 方法,描述用户意图。 |
| 聚合 (Aggregate) | @Entity public class ... |
聚合根用 @Entity 标识,拥有 @Id,包含业务行为。 |
| 值对象 (Value Object) | @Embeddable public final class ... |
不可变,无 @Id,通过 @Embeddable 嵌入实体,equals/hashCode 基于所有属性。 |
领域事件示例:
java
// 领域事件:订单已提交
public final class OrderPlacedEvent {
private final Long orderId;
private final Long userId;
private final LocalDateTime placedAt;
// 全参构造器
public OrderPlacedEvent(Long orderId, Long userId, LocalDateTime placedAt) {
this.orderId = orderId;
this.userId = userId;
this.placedAt = placedAt;
}
public Long getOrderId() { return orderId; }
public Long getUserId() { return userId; }
public LocalDateTime getPlacedAt() { return placedAt; }
}设计意图 :事件是过去式,一经发生便不可更改,因此设计为不可变对象(final class,private final 字段)。这保证了事件的完整性和线程安全性。
命令示例:
java
// 命令:下达订单
public final class PlaceOrderCommand {
private final Long userId;
private final List<OrderItemCommand> items;
private final Address deliveryAddress;
// 全参构造器
public PlaceOrderCommand(Long userId, List<OrderItemCommand> items, Address deliveryAddress) {
this.userId = userId;
this.items = Collections.unmodifiableList(new ArrayList<>(items));
this.deliveryAddress = deliveryAddress;
}
public Long getUserId() { return userId; }
public List<OrderItemCommand> getItems() { return items; }
public Address getDeliveryAddress() { return deliveryAddress; }
}设计意图:命令代表用户的意图,它也是一个值对象,不具备生命周期,因此也设计为不可变类。这有助于在分布式系统中传递命令而不产生副作用。
Spring 工程中的事件发布:聚合根是发布事件的最佳位置。
java
import org.springframework.data.domain.AbstractAggregateRoot;
@Entity
public class Order extends AbstractAggregateRoot<Order> {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long orderId;
// ... 其他字段
public Order place(Long userId, List<OrderItem> items, Address address) {
// ... 业务逻辑,验证,状态设置
OrderPlacedEvent event = new OrderPlacedEvent(this.orderId, userId, LocalDateTime.now());
// 使用 AbstractAggregateRoot 的方法注册事件
registerEvent(event);
return this;
}
}
// 在 ApplicationService 中保存实体并发布
@ApplicationService
public class OrderApplicationService {
private final OrderRepository orderRepository;
public OrderResponse placeOrder(PlaceOrderCommand command) {
Order order = new Order(); // ... 创建并调用 order.place()
order = orderRepository.save(order);
// Spring Data 会在 save 后自动发布 registerEvent 注册的所有事件
return OrderResponse.from(order);
}
}4. 限界上下文的验证规则与 ArchUnit 自动化检测
我们通过事件风暴推导出了初步的限界上下文,但这还是一个基于经验的草稿。我们需要一些启发式规则来验证其合理性,并使用自动化工具来守护其边界。
4.1 四大启发式验证规则
这四项规则从不同维度审视一个上下文边界是否合理。当一个上下文满足了所有这些条件,它就是强内聚的。
- 业务能力(Business Capability):该上下文是否能独立描述一个完整的、单一职责的业务能力?例如,"订单上下文"负责从下单到收货的整个订单生命周期管理,而不负责用户认证或商品详情。
- 组织边界(Organizational Boundary):该上下文是否能由一个跨职能团队(如一个包含产品、后端、前端、测试的Scrum团队)独立负责?如果上下文过大,团队协调成本会急剧上升。这体现了康威定律。
- 数据一致性(Data Consistency):该上下文内的核心业务操作是否能满足强一致性(ACID 事务)要求?上下文内部应由数据库事务来保证数据一致性,而上下文之间的数据一致性应通过最终一致性(如事件驱动)来实现。
- 变化频率(Change Frequency):该上下文内的业务需求变化频率是否与相邻上下文不同?将变化速率不同的模型分开,可以隔离变更的影响。例如,"订单核心流程"变化少,而"营销活动"变化极其频繁,它们应在不同的上下文中。
限界上下文四大启发式验证规则四维雷达图
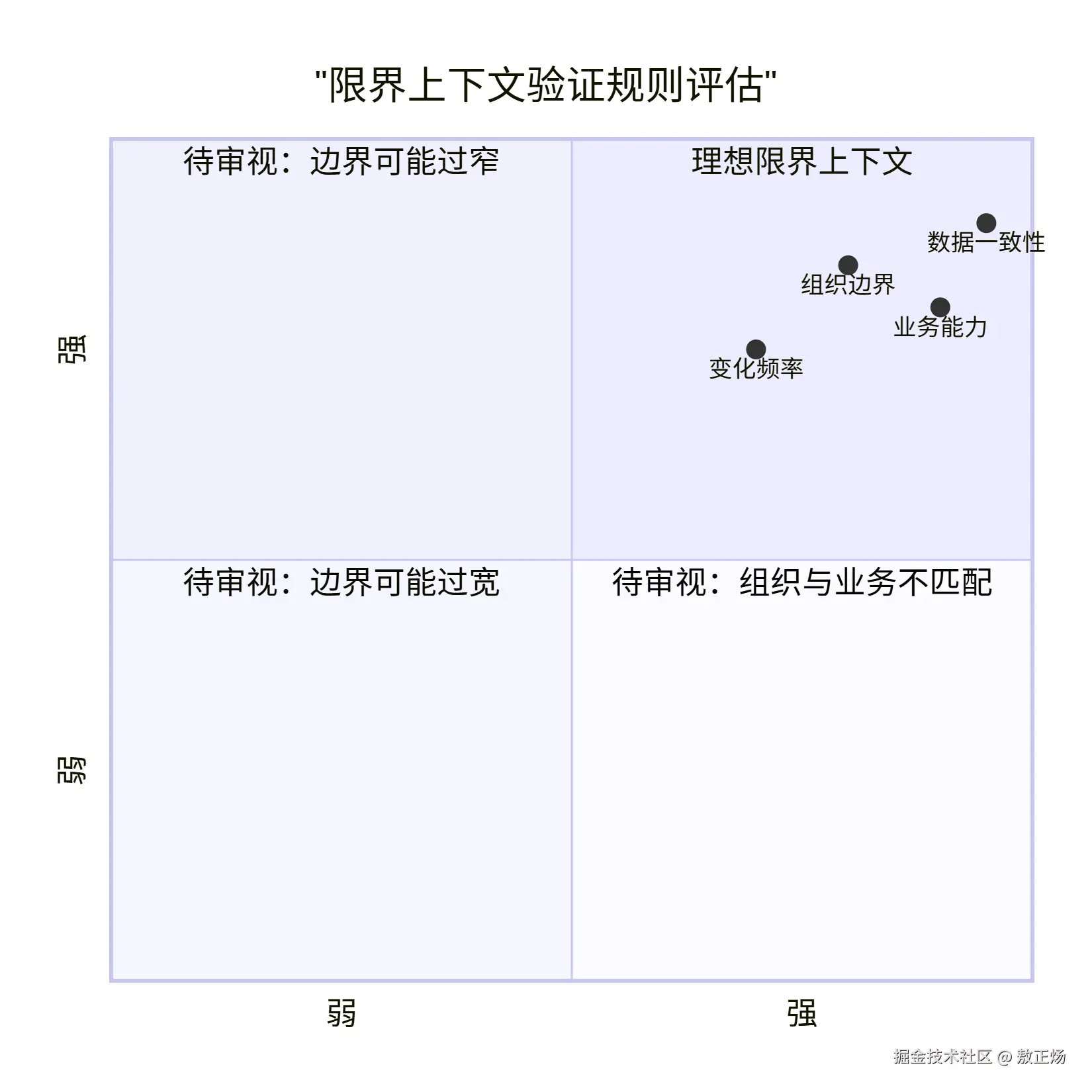
图表主旨概括:该雷达图展示了一个理想的限界上下文应在四个验证维度上都取得高分,任何一项的低分都可能是一个需要审视的边界问题信号。
逐层/逐元素分解:
- 四个坐标轴:分别代表业务能力、组织边界、数据一致性和变化频率四个评估维度。
- 图形面积:一个点的位置越靠近右上角(高分),说明在该维度上表现越好。理想的上下文会在图中形成一个占据右上角象限的较大面积。
- 异常分析:如果某个维度的得分明显偏低(例如"组织边界"得分低),说明该上下文的团队可能需要同时维护多个业务,协调成本高,可能需要进一步拆分。
设计原理映射:这四个规则是多维度高内聚低耦合原则在战略设计层面的具体体现。业务能力和数据一致性保障了"高内聚",组织边界和变化频率则是"低耦合"在组织和演进层面的延伸。
工程联系与关键结论加粗 :这四大规则不仅是设计时的检查清单,也是系统演进时的重构依据。当一个上下文开始违反某条规则时,就是你考虑拆分或合并限界上下文的信号。
4.2 ArchUnit 自动化检测
将验证规则写在白板上是不足以防止腐化的。我们需要使用ArchUnit这样的工具,将架构规则变成可执行的单元测试。鉴于本系列技术基线为JDK 8,Spring Modulith 需要 JDK 11+,我们将采用 ArchUnit 实现等价甚至更灵活的架构守护。
1. 检测包级分层规范 ArchUnit 可以强制一个限界上下文内部的领域层不被基础设施层污染。
java
// ArchUnit 架构测试
import com.tngtech.archunit.junit.AnalyzeClasses;
import com.tngtech.archunit.junit.ArchTest;
import com.tngtech.archunit.lang.ArchRule;
import static com.tngtech.archunit.lang.syntax.ArchRuleDefinition.classes;
@AnalyzeClasses(packages = "com.company.order")
public class OrderContextArchitectureTest {
@ArchTest
public static final ArchRule domain_layer_should_not_depend_on_infrastructure = classes()
.that().resideInAPackage("..order.domain..")
.should().onlyDependOnClassesThat()
.resideInAnyPackage("..order.domain..", "java..", "..shared..");
@ArchTest
public static final ArchRule application_service_naming = classes()
.that().haveSimpleNameEndingWith("ApplicationService")
.should().resideInAPackage("..order.application..");
}设计意图 :这条规则确保了 order.domain 包下的类(如 Order, OrderRepository 接口)不会依赖 order.infrastructure 包下的类(如 JpaOrderRepository)。这强制了依赖倒置原则(DIP),核心领域逻辑对技术实现细节的变化是隔离的。
2. 检测跨上下文非法依赖(自定义规则) 我们可以编写更复杂的规则来防止上下文间的非法耦合,例如订单上下文直接调用库存上下文的Repository。
java
// 一个自定义条件,判断一个类是否直接访问另一个上下文的Repository
DescribedPredicate<JavaClass> accessOtherContextRepository =
new DescribedPredicate<JavaClass>("直接访问其他上下文的Repository") {
@Override
public boolean test(JavaClass javaClass) {
// 复杂的逻辑:分析javaClass的方法调用,检查是否调用了
// 另一个包下的接口,且该接口命名以Repository结尾
return javaClass.getDirectDependenciesFromSelf().stream()
.anyMatch(dep -> dep.getTargetClass().getPackageName().startsWith("com.company.inventory.")
&& dep.getTargetClass().getSimpleName().endsWith("Repository"));
}
};
@ArchTest
public static final ArchRule no_cross_context_repository_access = ArchRuleDefinition.noClasses()
.that().resideInAPackage("com.company.order..")
.should(accessOtherContextRepository);设计意图:这个规则是防腐层(ACL)的自动化监督者。它确保了下游上下文不会绕过规定的接口,直接侵入上游上下文的数据存储,从而在代码层面巩固了上下文映射关系。
ArchUnit 规则检测示意图
图表主旨概括:该图展示了ArchUnit规则如何像哨兵一样,在编译或测试阶段就拦截掉违反架构原则的代码依赖,特别是领域层对基础设施层、以及一个上下文对另一个上下文基础设施层的直接依赖。
逐层/逐元素分解:
- 订单模块:展示了领域层、应用层和基础设施层的合理依赖关系。
- 合法的依赖 :
OrderService调用OrderApplicationService,后者调用JpaOrderRepository都是被允许的。 - 被拦截的依赖(内部) :
OrderService直接依赖JpaOrderRepository,这违反了DIP,规则会报错。 - 被拦截的依赖(跨上下文) :
OrderApplicationService直接调用另一个模块的JpaInventoryRepository,这违反了上下文边界,自定义规则会报错。
设计原理映射:ArchUnit将高内聚、低耦合、依赖倒置等架构原则从"口头约定"变成了"可执行的规约",是DDD战略设计落地的最后一道防线。
工程联系与关键结论加粗 :在JDK 8环境下,ArchUnit是实现架构自动化验证的不二之选。它的灵活性和强大的断言能力,完全可以替代Spring Modulith,为上下文边界和分层架构提供强有力的保障。
5. 上下文映射的六种模式与通信协议
识别出限界上下文后,下一步就是定义它们之间如何协作。上下文映射提供了一套关系模式,用于描述两个模型之间的关系。
5.1 六种上下文映射模式及通信协议
-
共享内核(Shared Kernel):两个(或多个)上下文共享一小部分共同的领域模型。任何对共享内核的变更都需要相关团队协商一致。
- 电商案例 :订单和支付上下文都需要使用
Money值对象。 - 通信协议 :共享 JAR 包。将
common-kernel作为独立模块发布,各服务的pom.xml引用。
- 电商案例 :订单和支付上下文都需要使用
-
客户-供应商(Customer-Supplier):上游是供应商,下游是客户。供应商定义接口,客户作为消费者进行适配。供应商在变更时会考虑客户的诉求,但主动权在供应商。
-
电商案例:订单上下文是客户,库存上下文是供应商。下单时需要校验库存。
-
通信协议:同步 RPC 或 REST API。
-
OpenAPI 3.0 契约示例 (由库存上下文提供):
yamlpaths: /api/v1/inventory/check: post: summary: 校验库存 requestBody: content: application/json: schema: type: object properties: skuId: { type: integer } quantity: { type: integer } responses: '200': description: 库存是否充足 content: application/json: schema: type: object properties: sufficient: { type: boolean }
-
-
防腐层(ACL):下游客户为保护自己的模型不受上游模型变更的影响,建立的一个翻译层。防腐层将上游的模型翻译成下游内部使用的模型。
-
电商案例 :订单上下文调用支付上下文发起支付。订单上下文内部有一个
PaymentAdapter实现了PaymentPort,它负责调用支付服务的Feign Client,并将返回的ExternalPaymentDTO翻译为订单上下文内部的领域概念。 -
通信协议:HTTP调用 + Adapter封装。
-
代码骨架示例 :
java// 订单上下文内部的防腐层 @Component class PaymentAdapter implements PaymentPort { private final PaymentFeignClient paymentClient; private final PaymentTranslator translator; @Override public PaymentConfirmation confirm(PaymentRequest paymentRequest) { ExternalPaymentDTO dto = paymentClient.pay(translator.toDto(paymentRequest)); return translator.toDomain(dto); // 关键翻译步骤 } }
-
-
开放主机服务(OHS):供应商为所有客户提供一套通用的、标准的、文档完善的API,而不为特定客户定制。
- 电商案例:订单上下文作为开放主机服务,为物流、售后、数据分析等多个下游上下文提供统一的订单查询API。
- 通信协议 :RESTful API + OpenAPI 3.0 文档。如
GET /api/v1/orders/{orderId}。
-
发布语言(PL):使用一种标准化的、独立于任何特定语言的文档格式(如XML Schema、Avro Schema)作为消息载体,使得多个上下文可以消费和理解同一份数据。
-
电商案例 :订单上下文产生
OrderPlaced事件,通过发布语言被库存、通知等多个上下文订阅。 -
通信协议:消息队列的发布-订阅模式。
-
Avro Schema 示例 :
avro{ "namespace": "com.company.order.avro", "type": "record", "name": "OrderPlacedEvent", "fields": [ {"name": "orderId", "type": "long"}, {"name": "userId", "type": "long"}, {"name": "totalAmount", "type": "string", "doc": "金额,用BigDecimal字符串表示以避免精度问题"}, {"name": "placedAt", "type": {"type": "long", "logicalType": "timestamp-millis"}} ] }Schema通常注册在Confluent Schema Registry等注册中心,确保生产者和消费者之间的版本兼容性。
-
-
各行其道(Separate Ways):两个上下文之间没有显著的协作收益,各自独立开发。这种决策是经过深思熟虑的,不是逃避集成。
- 电商案例:风控分析上下文与用户会员上下文之间可能没有直接的业务协作。
- 通信协议:无。
5.2 上下文映射六种模式示意图
图表主旨概括:该图以电商订单系统为例,清晰地展示了各个限界上下文之间不同的协作关系模式及其对应的具体通信协议。
逐层/逐元素分解:
- 中心节点:订单上下文是本系统的核心,与多个上下文存在集成关系。
- 客户-供应商(同步):订单上下文作为客户,依赖库存上下文提供的库存检查API。
- 防腐层(同步+翻译):订单上下文调用支付服务,通过防腐层进行模型翻译,隔离上游影响。
- 发布语言(异步):订单上下文发布领域事件,供通知等上下文异步消费。
- 共享内核(共享包) :订单和支付上下文通过共享JAR来确保
Money模型的一致性。 - 开放主机服务(提供API):订单上下文作为供应商,为物流等下游上下文提供标准化的订单查询API。
设计原理映射:上下文映射不仅仅是画线,更重要的是选择正确的协作模式,这决定了两个上下文之间的耦合度、通信风格和变更影响范围。明确这些关系,就制定了跨服务的"合同"。
工程联系与关键结论加粗 :每个上下文映射模式都对应着具体的工程实现和通信协议。在架构图上标明通信协议(如OpenAPI 3.0、Avro Schema Registry),能够使映射关系从抽象概念立刻变得可落地、可讨论、可治理。
6. 实体与值对象的精确区分与 Spring 实现
在识别出聚合并划定上下文边界后,我们需要深入聚合内部,精确地使用实体和值对象来建模。
6.1 实体与值对象的定义与判断标准
- 实体(Entity) :一个对象,不是因为其属性,而是因为其唯一且连续的标识(Identity) 而被区分。实体在其生命周期中,无论属性如何变化,其标识保持不变。
- 值对象(Value Object) :一个对象,它通过所有属性的值(Attribute) 来定义和区分。值对象没有概念上的标识,通常被设计为不可变的。
判断一个领域概念是实体还是值对象,可以问几个关键问题:
| 问题 | 如果是实体... | 如果是值对象... |
|---|---|---|
| 它是否有独立的生命周期? | 是,标识贯穿整个生命周期。 | 否,它作为其他对象的属性存在。 |
| 是否只关心它的属性值是什么? | 否,关心它是"哪一个"。 | 是,只关心它的值。 |
| 两个属性完全一样的实例是否是等价的? | 否,必须是同一个ID才等价。 | 是,属性相同则对象等价。 |
| 是否能被整体替换? | 否,替换后就是不同的对象。 | 是,可以像整数一样被新值替换。 |
6.2 Spring JPA 中的实体与值对象实现
实体(Entity)
java
import javax.persistence.*;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
@Entity
@Table(name = "t_order")
public class Order extends AbstractAggregateRoot<Order> {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long orderId; // 唯一标识
@Embedded
private OrderStatus status; // 值对象
@Embedded
private Address deliveryAddress; // 值对象
// 一对多,聚合内部的实体
@OneToMany(cascade = CascadeType.ALL, orphanRemoval = true)
@JoinColumn(name = "order_id")
private List<OrderItem> items = new ArrayList<>();
protected Order() {} // JPA 要求
// 业务行为方法
public void place() {
if (this.items.isEmpty()) {
throw new IllegalStateException("订单必须包含商品");
}
this.status = OrderStatus.PLACED;
registerEvent(new OrderPlacedEvent(this.orderId));
}
// equals 和 hashCode 仅基于ID
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Order)) return false;
Order order = (Order) o;
return orderId != null && orderId.equals(order.orderId);
}
@Override
public int hashCode() {
return getClass().hashCode();
}
// getters ...
}设计意图 :@Entity 和 @Id 是 Spring JPA 对实体的核心映射。关键点在于 equals 和 hashCode 方法必须且只能基于 @Id 字段,因为标识是实体的本质。
值对象(Value Object)------ JDK 8 不可变风格
java
import javax.persistence.Embeddable;
import java.math.BigDecimal;
import java.util.Objects;
@Embeddable
public final class Money {
private final BigDecimal amount;
private final String currency;
// 全参构造器,用于创建新实例
public Money(BigDecimal amount, String currency) {
this.amount = amount;
this.currency = currency;
}
// JPA 要求无参构造器,通常设为 protected 或 private
protected Money() {
this(BigDecimal.ZERO, "CNY");
}
// 工厂方法或行为方法,返回新实例,而非修改自身
public Money add(Money other) {
if (!this.currency.equals(other.currency)) {
throw new IllegalArgumentException("货币类型不匹配");
}
return new Money(this.amount.add(other.amount), this.currency);
}
// getter,不暴露 setter
public BigDecimal getAmount() { return amount; }
public String getCurrency() { return currency; }
// equals 和 hashCode 基于所有字段
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Money)) return false;
Money money = (Money) o;
return amount.equals(money.amount) && currency.equals(money.currency);
}
@Override
public int hashCode() {
return Objects.hash(amount, currency);
}
}设计意图:
@Embeddable注解使其能作为实体属性嵌入到同一个数据库表中。- 类被声明为
final,所有字段为private final。 - 没有 setter 方法 。任何改变值的操作(如
add)都会创建一个新的Money实例并返回。 equals和hashCode基于所有字段。因为值对象的身份由其所有属性值共同定义。- 无参构造器 :为了符合JPA规范,我们需要提供一个
protected的无参构造器,它仅仅是为了ORM框架内部使用,不应在业务代码中调用。
实体与值对象在Spring JPA中的类图对比
图表主旨概括 :该类图清晰地展示了在聚合内部,实体(Order, OrderItem)通过 @Id 维护其唯一性,而值对象(Money, Address)则以不可变的 @Embeddable 形式作为实体的属性存在。
逐层/逐元素分解:
- 实体层 :
Order和OrderItem拥有@Id标识,有独立的生命周期(虽然OrderItem的生命周期受Order聚合根管理)。 - 值对象层 :
Money和Address无@Id,属性为final,是不可变的从属对象。 - 关系表示 :实线菱形代表组合关系,
Order是OrderItem的聚合根,管理其生命周期。Money和Address作为属性被"拥有",它们一旦创建,自身状态不再改变。
设计原理映射:这种设计将"标识"与"值"区分开,精确地表达了业务含义。实体管理着事务与生命周期,而值对象则安全地在各处传递和使用,没有任何副作用,极大地降低了并发编程的复杂性。
工程联系与关键结论加粗 :在JDK 8环境下实现值对象的不变性,核心在于private final字段、全参构造器、无setter、以及返回新实例的行为方法。这比依赖JDK 14+的Record类型更需自律,但其带来的模型清晰度和代码安全性是相同的。
7. AI 辅助事件风暴的探索实践
大型语言模型(LLM)为事件风暴这个传统的手工工作坊注入了新的可能性。它可以作为团队的"超级助手",快速生成初稿,将宝贵的人工时间更多地用于复核和决策。
7.1 探索流程:Prompt → 输出 → 人工复核
第一步:设计 Prompt 关键在于清晰地向LLM下达指令,明确要求其扮演的角色、输入内容和期望的输出格式。
markdown
你是一位资深领域驱动设计(DDD)专家和事件风暴引导者。
你的任务是根据提供的业务需求描述,进行初步的事件风暴分析。
请严格按照以下步骤和格式输出:
**业务需求**:用户下单后,系统需要锁定库存。用户完成支付后,系统需要扣减库存并向用户发送订单确认通知。如果支付失败或超时,系统需要取消订单并释放锁定的库存。
markdown
**分析步骤**:
1. **领域事件**:以过去式短语列出所有重要的业务事实。
2. **命令**:列出触发每个事件的用户或系统动作(动词+名词)。
3. **候选聚合**:将关联的事件和命令聚类到候选聚合(名词簇)中。
**输出格式要求**:
- **领域事件**:['EventName1', 'EventName2', ...]
- **命令**:['CommandName1', 'CommandName2', ...]
- **候选聚合**:['AggregateName1', 'AggregateName2', ...]第二步:LLM 输出示例
markdown
- **领域事件**:['OrderPlaced', 'InventoryLocked', 'PaymentConfirmed', 'InventoryDeducted', 'NotificationSent', 'PaymentFailed', 'OrderCancelled', 'InventoryReleased']
- **命令**:['PlaceOrder', 'ConfirmPayment', 'DeductInventory', 'SendNotification', 'CancelOrder', 'ReleaseInventory']
- **候选聚合**:['Order', 'Inventory', 'Payment', 'Notification']第三步:人工复核原则
AI的输出绝对不能直接采用,必须经过严格的人工复核。复核是战略设计的核心,因为只有人才能真正理解业务上下文和权衡利弊。
- 验证事件的业务真实性 :
OrderPlaced,而不是OrderInfoCreated。AI有时会产生技术性而非业务性的术语。 - 验证命令的职责归属 :
DeductInventory是应由库存聚合处理,还是订单聚合处理?复核确保了聚合的事务边界正确。 - 验证事务边界 :AI可能会将
Order和Payment聚合成一个巨大的"交易"聚合。人工必须介入,根据数据一致性要求将其拆开。 - 鉴别"幻觉" :AI有时会创造出听上去合理但业务上不存在的聚合或事件,例如
ShoppingCart可能被错当成Order。
统一语言术语表也可以由AI根据输出自动生成草稿,再由团队修正。这极大提高了文档的编写效率。
AI辅助事件风暴的Prompt→输出→人工复核流程图
图表主旨概括:该流程图展示了AI作为一种辅助工具,如何加速事件风暴的初始阶段,但最终的决策权和模型的精确性仍牢牢掌握在业务专家和架构师手中。
逐层/逐元素分解:
- 输入与提示词:高质量的提示词是获得有用输出的前提,需要明确定义模型角色、任务和格式。
- LLM生成:AI快速处理文本,生成结构化的初步分析结果。
- 人工复核(核心环节):这是整个流程中价值最高的部分。专家的经验、对业务的理解在这里注入模型,修正AI的机械和可能的错误。
- 最终产出:经过人机协作产生的最终模型,既利用了AI的效率,也保证了模型的业务准确度。
设计原理映射:这种模式是"增强智能"而非"人工智能"的体现。工具自动化处理低价值、重复性的模式提取工作,将高价值的决策和验证工作留给人。
工程联系与关键结论加粗 :AI是加速器,不是替代者。在领域建模这种强认知、强上下文的活动中,LLM输出的价值等于其节省的"第一次打字"时间。模型的业务正确性、事务边界和最终形态,永远需要领域专家的最终确认。
8. 贯穿案例:电商订单系统的完整战略设计
现在,我们将前述所有概念串联起来,完整展示一个电商订单系统的战略设计过程。
8.1 业务需求描述
"用户可以浏览商品并下单。下单时,系统需校验商品库存是否充足。下单成功后,库存需被锁定。用户支付成功后,系统需确认支付、真实扣减库存,并发送订单确认通知。若支付失败或超时,系统需取消订单,并释放已锁定的库存。用户可以通过订单中心查询订单的实时状态。"
8.2 执行事件风暴
团队与业务专家一起,在白板上梳理出完整的业务流程。
领域事件列表:
OrderPlaced(订单已提交)InventoryLocked(库存已锁定)InventoryLockFailed(库存锁定失败)PaymentConfirmed(支付已确认)PaymentFailed(支付失败)PaymentTimeout(支付超时)InventoryDeducted(库存已扣减)OrderCancelled(订单已取消)InventoryReleased(库存已释放)NotificationSent(通知已发送)
命令列表:
PlaceOrder(提交订单)LockInventory(锁定库存)ConfirmPayment(确认支付)DeductInventory(扣减库存)ReleaseInventory(释放库存)CancelOrder(取消订单)SendNotification(发送通知)
聚合列表:
Order(订单)Inventory(库存)Payment(支付)Notification(通知)
限界上下文聚类:
- 订单上下文 :
Order聚合 - 库存上下文 :
Inventory聚合 - 支付上下文 :
Payment聚合 - 通知上下文 :
Notification聚合
8.3 定义上下文映射与通信协议
- 订单 → 库存 :客户-供应商 。订单服务调用库存服务API进行库存锁定和扣减。通信协议:同步 REST API + OpenAPI 3.0。
- 订单 → 支付 :防腐层 。订单服务通过支付适配器调用外部支付网关。通信协议:HTTP RPC + Adapter。
- 订单 → 通知 :发布语言 。订单服务发布
OrderPlaced,PaymentConfirmed,OrderCancelled等事件。通信协议:异步消息队列 + Avro Schema Registry。 - 订单与支付 :共享内核 。共享
Money值对象。
8.4 Spring Boot 工程实践
1. 项目包结构
scss
com.company
├── order
│ ├── domain
│ │ ├── Order.java (聚合根)
│ │ ├── OrderPlacedEvent.java
│ │ ├── Address.java (值对象)
│ │ └── OrderRepository.java (接口)
│ ├── application
│ │ └── OrderApplicationService.java
│ └── infrastructure
│ ├── JpaOrderRepository.java
│ └── PaymentAdapter.java (防腐层)
├── inventory
│ └── ... (类似结构)
├── payment
│ └── ...
└── shared-kernel
└── Money.java (共享内核)2. 核心实体与值对象实现 (Order 和 Money 的完整代码已在第 6 节展示,此处不再重复。)
3. 事件发布与消费流程 订单应用服务调用 Order.place(),该方法内部注册 OrderPlacedEvent,Spring Data JPA 在事务提交前自动通过 ApplicationEventPublisher 发布该事件。库存上下文和通知上下文的 @EventListener 监听到该事件后,执行各自的 lockInventory 和 sendNotification 命令。
4. ArchUnit 验证 编写 OrderContextArchitectureTest,验证 order.domain 不依赖 order.infrastructure,并添加自定义规则,检查 order 包下的类不应直接访问 inventory 或 payment 上下文下的 Repository 接口。
9. 与前后系列的衔接
- 承接"微服务与云原生架构系列"第 3 篇(微服务拆分策略):本文详细阐述了作为拆分核心依据的"限界上下文"是如何通过事件风暴从业务需求中推导出来的,回答了"边界从哪里来"的问题。
- 连接"分布式系统核心模型"总纲第 1 篇:本文中的"限界上下文"正是总纲模型中"业务能力域"在软件模型中的直接映射。订单、库存、支付、通知四个上下文,清晰地划分了电商系统的核心业务能力。
- 预告本系列第 2 篇(战术 DDD):本文将聚合作为一个整体识别出来,但并未深入其内部。第 2 篇将聚焦聚合根设计原则、资源库(Repository)和领域服务的详细实现,使领域模型更加丰满。
- 预告本系列第 14 篇(电商完整案例):本文的所有战略设计产出(事件、聚合、限界上下文、上下文映射),将在第 14 篇中被实现为一个完整、可运行的、包含所有单元测试和集成测试的 Spring Boot 项目。
10. 面试高频专题
10.1 什么是DDD中的统一语言?如何在代码中体现?
一句话回答:统一语言是团队与业务专家共享的、直接映射到代码中的业务术语,其核心是消除业务与技术之间的语言鸿沟。
详细解释 :统一语言(Ubiquitous Language)是DDD的基石,要求开发者和领域专家使用相同的词汇讨论业务,并将这些词汇精确地体现在代码的类名、方法名、包名和API路径上。例如,业务说"下单",代码中就应有 Order.place(),而不是 createOrder()。一个强健的统一语言还包含术语表,明确每个术语的定义和其所属的限界上下文。当"用户"这个词在订单上下文中仅指"下单者ID+姓名",而在用户画像上下文中代表"用户全量标签"时,它就在统一语言层面揭示了上下文边界。统一语言不是文档,而是代码中的词汇,它让代码读起来就像业务专家在描述需求,从而极大降低沟通成本和认知负荷。
多角度追问:
-
架构统一性追问 :如果团队已经存在大量使用VO、DTO后缀的遗留代码,如何逐步迁移到统一语言?
可以采取"绞杀者"模式,在新功能中强制执行统一语言,同时为每个Sprint分配技术债务时间,逐步重命名核心领域类。例如,将
OrderInfo重命名为Order,将createOrder()改为placeOrder(),并更新术语表。使用IDE的重构功能,结合ArchUnit添加包命名和类命名的检查规则,可以安全地进行。 -
性能权衡追问 :如果直接使用业务术语导致API路径或类名过长(例如
POST /api/v1/orders/order-items/{orderItemId}/return),如何处理?可以在术语表中引入约定俗成的缩写,如
Ret代表Return,但必须在术语表中明确定义并与业务专家达成一致。路径和类名在清晰表达业务意图的前提下可以适度简化,但不得引入与业务无关的技术词汇。 -
运维安全性追问 :统一语言的API路径是否会暴露核心业务模型,带来安全风险?
API路径反映的是接口模型,不一定是内部领域模型的完全暴露。我们可以通过防腐层或API网关对外提供更粗粒度、视角不同的模型。例如,对外API可以是
/v1/customer-orders,而内部订单上下文仍然是Order。内外模型可以有重叠但不应完全一致,这是一种有意的设计。
加分回答 :
Eric Evans在《领域驱动设计》中指出,统一语言的一个重要标志是:你能否用模型中的类和关系,顺畅地向业务专家解释软件正在做什么。如果出现 "把 DTO 转成 Entity" 这类语言,就已经偏离了统一语言。最佳实践是让业务专家参与代码评审,识别出他们看不懂的词汇并进行修正。此外,统一语言不仅体现在Java类上,还应体现在数据库列名(如 order_id)、消息队列的topic名(如 order-placed)以及UI标签上,形成全栈的统一。
10.2 事件风暴的四步流程是什么?如何从领域事件推导出限界上下文?
一句话回答:事件风暴通过"领域事件→命令→聚合→限界上下文"四步法,从业务事实反向推导出系统的业务边界。
详细解释 :事件风暴是一种以领域事件(已发生的业务事实)为核心的工作坊方法。第一步,在白板上贴橙色便签纸,识别所有领域事件,如 OrderPlaced。第二步,为每个事件找到触发它的命令,即用户或外部系统的意图,如 PlaceOrder。第三步,将相关的事件和命令归属到产生它们的聚合下,比如 Order 聚合负责处理 PlaceOrder 命令并产生 OrderPlaced。第四步,将职责相关、共同完成一个完整业务能力的聚合聚类,形成限界上下文(如订单上下文)。这个从结果向原因推导的过程,天然地避免了技术划分思维,确保边界与业务能力对齐。事件风暴完成后,我们便得到了一个业务人员也能看懂的领域模型初稿。
多角度追问:
-
架构边界追问 :如果一个事件会触发多个上下文的动作,比如"订单已支付"导致"库存扣减"和"通知发送",这个事件归谁所有?
事件属于产生它的聚合所在的上下文。所以
PaymentConfirmed事件属于支付上下文。订单上下文可以监听该事件并更新自身状态,但支付上下文作为事件的"生产者",拥有该事件的定义权和发布权。消费者上下文的反应逻辑不应反向影响生产者。 -
性能同步追问 :事件风暴在处理流程时没有考虑性能,但在高并发系统中,大量事件如何快速处理?
事件风暴是设计过程,不解决性能问题。但在实现阶段,我们可以引入事件驱动架构,通过消息队列(如Kafka)异步传递事件。生产者和消费者解耦,消费者可以水平扩展。如果某些环节需要严格同步(如库存锁定),则可以在事件风暴标注,并在实现时保留RPC调用,其余部分异步化。
-
安全与数据一致性追问 :如何保证跨上下文的事件最终一定能被消费,不会丢失?
事件一旦被持久化(发布到消息队列并确认),就具备了可靠性。消费者可以使用事务性消息和至少一次投递语义,并通过幂等处理消费端重复消息。对于关键流程,可以引入Saga模式和补偿机制,确保最终一致性。
加分回答 :
Alberto Brandolini 提出事件风暴时强调"不要过早进入数据模型"。事件是业务流程的骨架,如果直接去设计数据库表,就会被技术绑定。在实践中,我们可以使用"热点"聚合(hotspot)来标记争议点,这些争议点往往是边界划分的关键。此外,事件风暴的产出(领域事件和命令)如果使用 final class 建模,可以保证不可变性,这在分布式消息传递中至关重要。
10.3 限界上下文的四大验证规则是什么?ArchUnit如何自动化检测模块边界?
一句话回答:四大验证规则是业务能力、组织边界、数据一致性和变化频率;ArchUnit通过可执行的单元测试来检查包级依赖,强制架构规则。
详细解释:
- 业务能力:该上下文是否独立描述了一个完整的业务能力?如订单上下文处理从下单到收货的整个生命周期。
- 组织边界:该上下文能否由一个跨职能团队独立负责?如果团队需要频繁协调多个上下文,说明边界可能不当。
- 数据一致性:上下文内部的业务操作应满足ACID,而上下文之间应通过最终一致性协同。
- 变化频率:将变化速率不同的业务放在不同上下文,可隔离变更影响。
ArchUnit将这些规则转化为自动化测试。例如,我们可以编写规则检查 order.domain 包不依赖 order.infrastructure 包,防止领域层被基础设施污染;还可以自定义规则禁止订单上下文直接访问库存上下文的 Repository。这些规则集成在CI/CD流水线中,任何违反架构原则的提交都会导致构建失败,从而将架构治理从"人治"变为"法治"。
多角度追问:
-
架构演进追问 :如果现有系统已经严重违反这些规则,如何使用ArchUnit进行安全重构?
可以先引入ArchUnit规则,并将其设置为"警告"模式(通过
@ArchIgnore或自定义断言),只输出违规日志,不中断构建。然后团队在每个Sprint中逐步修复违规项,待全部修复后再将规则改为@ArchTest,成为强制红线。 -
性能追问 :在大型工程中,ArchUnit测试会扫描所有类,会不会严重影响CI/CD速度?
可以通过
@AnalyzeClasses(packages = "com.company.order")限定扫描范围,只扫描当前模块。还可以将架构测试放在单独的测试模块中,仅在架构变更时运行。对于Maven多模块项目,为每个限界上下文编写独立的ArchUnit测试是良好实践。 -
运维与安全追问 :ArchUnit能否检测运行时动态依赖,比如反射或序列化导致的非法依赖?
ArchUnit是静态字节码分析工具,无法检测运行时反射调用。对于反射,可以配合IDE插件或SonarQube规则禁止
setAccessible等方法。对于序列化,可以使用transient或@JsonIgnore限制敏感属性,并由安全审计工具检查。
加分回答 :
在JDK 8环境下,ArchUnit是实现架构自动化测试的黄金标准。Vaughn Vernon在《实现领域驱动设计》中强调,架构的腐化常常从一次"方便的"的跨包引用开始。ArchUnit的 layeredArchitecture() API能更简洁地描述分层规范,而我们的领域包结构恰好可以映射为层。此外,结合 FreezeingArchRule,你可以将当前违规"冻结"起来,只防止新的违规加入,这在遗留系统重构中非常有用。
10.4 上下文映射有哪些模式?客户-供应商和防腐层有什么区别?各对应什么通信协议?
一句话回答:客户-供应商是上下游直接协作关系,而防腐层是下游为隔离上游影响建立的翻译层;客户-供应商常用同步REST/OpenAPI,防腐层则封装了调用协议和模型翻译。
详细解释 :上下文映射的六种模式包括:共享内核、客户-供应商、防腐层、开放主机服务、发布语言和各行其道。客户-供应商 描述了一种上下游关系,上游(供应商)定义接口,下游(客户)适配。例如,订单上下文是客户,库存上下文是供应商,库存提供REST API,订单调用。这种关系下,供应商通常会考虑客户的诉求,但不能为每个客户定制。防腐层(ACL) 则是客户为了保护自己的模型而主动建立的隔离层。它不仅包含一个API客户端,更重要的是包含一个翻译器(Translator),将上游的外部模型转换成本地领域模型。如果上游API版本升级或模型变化,只需修改防腐层的翻译逻辑,内部领域模型不受影响。客户-供应商常用协议是OpenAPI 3.0定义的REST API;防腐层常用HTTP RPC,内部封装Feign Client,但关键在模型翻译。
多角度追问:
-
架构设计追问 :在微服务架构中,为什么说"一个下游一个防腐层"是好的实践?
每个下游对上游模型的关注角度不同。订单上下文需要支付结果,而财务上下文需要支付流水和费率。为每个下游建立独立的防腐层,可以按需翻译,避免模型污染。如果所有下游共享一个防腐层,该防腐层就会成为一个新的耦合点,变更影响范围会扩大。
-
性能优化追问 :防腐层里的数据翻译(DTO -> Domain)是否会造成性能开销?
在绝大多数业务中,这种内存转换的开销可以忽略不计。如果性能真的成为瓶颈(例如高并发支付回调),可以考虑使用对象映射框架(如MapStruct)生成编译时代码,避免反射,或直接操作JSON流。但切勿因性能过早牺牲模型清晰度。
-
安全与测试追问 :如何测试防腐层以保证翻译的正确性?
单元测试应覆盖翻译器的所有转换逻辑,验证上游DTO的每一个字段如何映射到领域对象。集成测试则使用WireMock模拟上游API,确保防腐层在真实HTTP环境下也能正常工作。同时,应该编写契约测试来约束上游服务的接口变化。
加分回答 :
防腐层(ACL)的概念源自企业集成模式,但在DDD中,Eric Evans赋予了它更深的领域含义。一个设计优秀的防腐层不仅要隔离技术实现,还应隔离领域概念。例如,ExternalPaymentDTO 中的 trans_status 可能被翻译成内部枚举 PaymentStatus,并在此过程中执行校验。防腐层通常实现一个领域内的端口(Port),这在六边形架构中正好是"端口-适配器"模式的应用,确保了领域层对基础设施的依赖反转。
10.5 实体和值对象的核心区别是什么?在Spring JPA中如何分别实现?
一句话回答 :实体拥有基于唯一标识的生命周期,通过 @Entity 和 @Id 实现;值对象没有标识,其相等性由所有属性值决定,通过 @Embeddable 和不可变设计实现。
详细解释 :实体的核心是"标识"(Identity),无论其属性如何变化,只要ID相同,就是同一个对象。值对象则完全由其属性的值来定义,两个值对象如果所有属性值都相同,则视为相等。在Spring JPA中,我们使用 @Entity 和 @Id 映射实体,并且 equals 和 hashCode 方法必须只基于ID。值对象使用 @Embeddable 映射,并且必须设计为不可变:类声明为 final,所有字段为 private final,不提供 setter;任何"修改"操作返回一个新的值对象实例。JPA要求值对象提供一个 protected 无参构造器,仅由框架使用。
多角度追问:
-
架构设计追问 :什么时候应该将一个值对象提升为实体?
当业务开始关心"那个"特定的事物,需要跟踪其历史和状态变化时。例如,"收货地址"开始时是值对象,但当系统需要分析"用户某个常用地址的修改历史"时,就需要将其建模为
UserAddress实体,赋予ID并管理生命周期。 -
性能与存储追问 :
@Embeddable值对象会导致实体表字段变多,是否影响查询性能?宽表可能会影响某些数据库的扫描性能,但通常是可接受的。如果值对象非常庞大或者被多个实体频繁共享,可以将其设计为独立实体,通过
@OneToOne关联,但这会引入复杂性和额外的JOIN。大多数情况下,保持嵌入是更简单的选择。 -
运维安全追问 :值对象的不可变性对调试和日志有什么好处?
不可变对象天生是线程安全的,可以安全地在日志、异常消息和多线程环境中共享,而无需担心状态被意外修改。在调试时,一个值对象的快照一旦打印出来,就代表了那个时刻的真实状态,不会随着程序运行而发生变化,极大地方便了问题定位。
加分回答 :
在JDK 14以上,Record 类型完美实现了不可变值对象。但在JDK 8中,我们通过手写 final class + private final 来模拟。为了进一步增强不可变性,对于集合类型的值对象属性,应在构造函数中进行防御性拷贝,并返回不可修改的视图,如 Collections.unmodifiableList()。此外,值对象还可以包含业务行为,如 Money.add(),这使得它不同于贫血模型的DTO,包含了领域逻辑,是富领域模型的重要体现。
10.6 JDK 8环境下如何实现值对象的不可变性?代码示例是怎样的?
一句话回答 :通过 private final 字段、全参构造器、无 setter 方法,并在"修改"行为中返回新实例来实现不可变值对象。
详细解释:实现要点包括:
- 类声明为
final,防止子类化。 - 所有字段声明为
private final。 - 提供一个包含所有字段的公共构造器。
- 不提供任何
setter方法。 - 任何需要改变值的方法(如
Money.add())必须返回一个新对象。 equals()和hashCode()基于所有字段。- 为JPA提供一个
protected无参构造器。
示例代码:
java
@Embeddable
public final class Address {
private final String province;
private final String city;
private final String street;
public Address(String province, String city, String street) {
this.province = province;
this.city = city;
this.street = street;
}
protected Address() {
this("", "", "");
}
public Address withCity(String newCity) {
return new Address(this.province, newCity, this.street);
}
public String getProvince() { return province; }
public String getCity() { return city; }
public String getStreet() { return street; }
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Address)) return false;
Address that = (Address) o;
return province.equals(that.province) && city.equals(that.city) && street.equals(that.street);
}
@Override
public int hashCode() {
return Objects.hash(province, city, street);
}
}多角度追问:
-
架构设计追问 :这种大量创建新对象的模式会不会给GC带来压力?
对于生命周期短的"临时"值对象,现代JVM的分代GC(如G1)能够高效回收。只有当对象创建频率极高(如每秒百万级)且长期存活时,才需关注GC影响,此时可考虑对象池或缓存,但会增加设计复杂度。
-
性能优化追问 :对于包含集合字段的值对象如何保证不可变性?
构造函数应进行防御性拷贝:
this.items = Collections.unmodifiableList(new ArrayList<>(items)),并且getter返回不可修改的视图,确保外部无法修改内部状态。如果使用JPA持久化集合,可以借助Hibernate的@Immutable注解。 -
安全追问 :不可变值对象能否有效防御"时间检查-时间使用"(TOCTOU)的竞态条件?
是的。因为对象状态在创建后不可改变,一个线程在检查到它之后,在使用之前,其状态不可能被其他线程篡改,从而天然避免了此类问题,这对于并发环境下的安全性非常有利。
加分回答 :
在领域驱动设计中,值对象的不可变性有助于构建"无副作用"的领域模型。结合Java 8的 Optional 和 Stream API,可以流畅地处理值对象的变换,而无需担心原始对象被修改。此外,可以在值对象中利用 assert 或自定义验证方法,在构造时确保对象处于合法状态,这称为"契约式设计",是提高代码健壮性的重要手段。
10.7 AI如何辅助事件风暴?LLM的输出需要哪些人工复核?
一句话回答:AI可以快速从文本中提取领域事件、命令和聚合的候选列表,但必须由领域专家人工复核其业务真实性、职责归属和事务边界。
详细解释:通过精心设计的Prompt,我们可以将PRD或用户故事输入给LLM,指示其扮演DDD专家并提取领域事件(过去式)、命令和候选聚合。AI能快速生成一个结构化的草稿,显著缩短建模准备时间。然而,人工复核不可或缺,因为:
- 业务真实性 :AI可能生成
UserCreated这样的技术性事件,而不是业务上准确的AccountRegistered,需要确认事件是否真实反映业务流程。 - 职责归属 :
DeductInventory命令到底由订单聚合还是库存聚合处理?这涉及事务边界,AI可能出错,必须由人基于数据一致性等原则决定。 - 事务边界 :AI可能会将
Order和Payment合并为一个巨大的"交易"聚合,需要领域专家根据数据一致性和并发性要求将其拆分开。 - 术语对齐:AI生成的术语可能与组织内部的约定俗成不符,需要人工校准并纳入统一语言术语表。
多角度追问:
-
架构设计追问 :如果一个新系统完全没有遗留文档,只有几次业务专家的访谈录音,如何利用AI?
可以先将访谈录音转为文本,然后让AI处理这些非结构化的对话,提取可能的领域事件和名词。尽管准确率会降低,但可以作为建模的起点,再由专家在事件风暴工作坊中逐步精化。
-
运维自动化追问 :能否将AI集成到CI/CD流程中,自动校验新增代码是否符合领域模型?
这是一个前沿方向。可以训练一个模型,使其理解术语表和事件模型。当PR中出现新的事件类或命令类时,自动检查其命名是否符合统一语言、是否属于已知的限界上下文,如果不一致则通知架构师评审。
-
安全追问 :使用外部LLM服务处理企业内部业务文档是否有数据泄露风险?
有重大风险。对于敏感业务,必须使用私有化部署的开源LLM(如Llama),并确保网络隔离。即便使用商业API,也应对输入Prompt进行脱敏处理,移除真实的用户数据和商业机密。
加分回答 :
在AI辅助的场景中,我们可以让LLM输出多种可能的模型划分方案,并进行对比分析,促使团队讨论不同方案的优劣。这类似于"生成式设计"。结合知识图谱,还可以让AI保持对术语表的一致性验证。不过,LLM的"幻觉"问题要求我们必须将它的角色定位为"启发式助手",最终决策权永远属于跨职能团队。
10.8 系统设计题:电商系统事件风暴与架构设计
题目:一个电商系统包含用户、商品、订单、库存、支付、物流、评价七个业务模块。请使用事件风暴方法:(1) 识别领域事件和命令;(2) 聚类限界上下文并说明理由;(3) 设计上下文映射关系及对应的通信协议;(4) 给出核心实体和值对象的Spring JPA实现。
回答:以下是一份详尽的架构设计方案,包含事件风暴、限界上下文、上下文映射及代码实现,并辅以架构图、时序图和业务流程图。
(1) 事件风暴:领域事件与命令
我们聚焦最核心的"用户下单并支付"流程,及其相关的周边流程。
核心流程领域事件:
- 订单相关:
OrderPlaced,OrderCancelled,OrderExpired - 库存相关:
InventoryLocked,InventoryLockFailed,InventoryDeducted,InventoryReleased - 支付相关:
PaymentInitiated,PaymentConfirmed,PaymentFailed,PaymentRefunded - 物流相关:
ShipmentCreated,ShipmentDispatched,ShipmentDelivered - 评价相关:
ReviewSubmitted,ReviewApproved - 用户/商品相关:
UserRegistered,ProductCreated
对应命令:
PlaceOrder,CancelOrderLockInventory,ReleaseInventory,DeductInventoryInitiatePayment,ConfirmPayment,RefundPaymentCreateShipment,DispatchShipment,ConfirmDeliverySubmitReview,ModerateReviewRegisterUser,CreateProduct
(2) 限界上下文聚类与理由
根据业务能力、数据一致性、组织边界和变化频率,我们将七个模块聚类为以下六个限界上下文:
| 上下文 | 包含聚合 | 核心职责 | 理由 |
|---|---|---|---|
| 订单上下文 | Order |
订单生命周期管理(创建、取消、状态跟踪) | 订单的核心业务能力,拥有独立的生命周期,变化频率中等。 |
| 库存上下文 | Inventory |
库存的锁定、扣减、释放、盘点 | 独立业务能力,强数据一致性(防超卖),需高性能。 |
| 支付上下文 | Payment |
对接第三方支付,支付记录,退款 | 与外部系统集成,变化频率低但安全要求高,需防腐层。 |
| 物流上下文 | Shipment |
发货、物流状态跟踪 | 独立业务,与第三方物流系统交互,变化频率中等。 |
| 用户评价上下文 | Review |
商品评价的收集、审核与展示 | 变化频率极高(运营活动驱动),与核心订单流程解耦。 |
| 基础数据上下文 | User, Product |
用户账户、商品信息的基础管理 | 偏基础数据,变化频率低,为其他上下文提供只读或简单查询服务。 |
将用户和商品合并为一个"基础数据上下文",是因为两者都属于运营后台管理的范畴,变化频率相似,业务能力上偏数据支撑。但也可以拆分为两个,取决于组织团队结构。此处假设为一个上下文。
(3) 上下文映射关系与通信协议
图表说明:
- 订单 → 库存:客户-供应商,订单调用库存API进行锁定和扣减。
- 订单 → 支付:防腐层(ACL),订单通过支付适配器隔离支付网关的模型。
- 订单 → 物流 :发布语言,订单支付成功后发布
OrderPaid事件,触发物流创建运单。 - 订单 → 评价 :发布语言,订单完成(已收货)后发布
OrderDelivered事件,触发评价邀请。 - 订单、支付、物流等 → 基础数据:客户-供应商,基础数据作为上游提供用户和商品信息。
- 共享内核 :
Money在订单和支付中共享,Address在订单和物流中共享。
(4) 核心业务流程与交互时序图
下单并支付成功流程(理想路径):
流程图说明:
- 用户发起
PlaceOrder命令。 - 订单上下文同步调用库存上下文的锁定API,获取预占。
- 锁定成功后,订单创建,状态置为"已提交",并发布
OrderPlaced事件。 - 订单上下文通过支付防腐层调用外部支付网关,获取支付结果。
- 支付成功后,订单状态更新为"已支付",并发布
PaymentConfirmed事件。 - 库存、物流、通知等下游上下文异步消费该事件,执行各自的业务逻辑(真扣减、创建运单、发消息)。
支付失败或超时的补偿流程:
- 如果支付失败或超时,订单上下文发布
PaymentFailed事件,库存上下文监听该事件,执行ReleaseInventory命令,释放锁定的库存,订单状态变为"已取消"。
(5) 核心实体与值对象的Spring JPA实现
仅展示订单上下文的核心代码,其他上下文类似。
订单聚合根 Order:
java
@Entity
@Table(name = "t_order")
public class Order extends AbstractAggregateRoot<Order> {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long orderId;
@Embedded
private Address deliveryAddress;
@Enumerated(EnumType.STRING)
private OrderStatus status;
@OneToMany(cascade = CascadeType.ALL, orphanRemoval = true, fetch = FetchType.LAZY)
@JoinColumn(name = "order_id")
private List<OrderItem> items = new ArrayList<>();
protected Order() {}
public static Order create(List<OrderItem> items, Address address) {
Order order = new Order();
order.items = items;
order.deliveryAddress = address;
order.status = OrderStatus.PLACED;
order.registerEvent(new OrderPlacedEvent(order.orderId));
return order;
}
public void confirmPayment() {
if (this.status != OrderStatus.PLACED) {
throw new IllegalStateException("订单状态不正确");
}
this.status = OrderStatus.PAID;
registerEvent(new PaymentConfirmedEvent(this.orderId));
}
// equals/hashCode 仅基于 orderId
}值对象 Address (不可变):
java
@Embeddable
public final class Address {
private final String province;
private final String city;
private final String detail;
public Address(String province, String city, String detail) {
this.province = province;
this.city = city;
this.detail = detail;
}
protected Address() { this("", "", ""); }
// getters, equals/hashCode on all fields...
}订单项实体 OrderItem:
java
@Entity
@Table(name = "t_order_item")
public class OrderItem {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long itemId;
private Long productId;
private Integer quantity;
@Embedded
private Money unitPrice;
// ...
}共享内核值对象 Money(见前文)。
(6) 架构验证 ArchUnit 规则
java
@AnalyzeClasses(packages = "com.company.order")
public class OrderContextTest {
@ArchTest
static final ArchRule domain_independent = classes()
.that().resideInAPackage("..order.domain..")
.should().onlyDependOnClassesThat().resideInAnyPackage(
"..order.domain..", "java..", "..shared..");
@ArchTest
static final ArchRule no_inventory_repo_access = noClasses()
.that().resideInAPackage("..order..")
.should().accessClassesThat().resideInAPackage("..inventory.infrastructure..");
}多角度追问:
-
架构演进追问 :如果后期需要增加"秒杀"功能,现有架构如何支持?
秒杀场景对性能和一致性要求极高,会冲击现有上下文。可以引入一个独立的"秒杀上下文",拥有独立的库存分配逻辑和异步下单流程,通过发布语言与主订单系统解耦。
-
性能数据一致性追问 :如何处理订单创建和库存锁定的分布式事务?
不能使用分布式事务(2PC)。应采用Saga模式:订单服务先创建订单(
OrderPlaced),然后发命令给库存服务进行锁定。若锁定失败,库存服务发布InventoryLockFailed事件,订单服务监听后进行取消订单的补偿操作,实现最终一致性。 -
安全设计追问 :支付上下文与外部支付网关交互,如何保证安全性?
支付防腐层是安全的关键点。所有与外部网关的通信必须基于HTTPS,并加入签名验证和IP白名单。内部领域模型不应包含任何卡信息,仅在防腐层进行脱敏和映射。防腐层本身不进行持久化存储。
加分回答 :
在本设计中,我们将用户和商品合并为基础数据上下文,这体现了限界上下文的"变化频率"原则。如果用户服务增加会员等级、积分等复杂功能,变化频率加快,就可以将其独立出来。上下文边界的划分是一个持续演进的过程,DDD建议我们每隔一段时间(如每个季度)就重新审视一次上下文映射和聚合边界,确保架构与业务对齐。这也是"演进式架构"的核心思想。
延伸阅读
- 《领域驱动设计:软件核心复杂性应对之道》(Eric Evans)第 1-7 章
- 《实现领域驱动设计》(Vaughn Vernon)第 1-4 章
- ArchUnit 官方文档:www.archunit.org/
- 《Event Storming》by Alberto Brandolini