前言
在前面的实验中,我们搭建的Hadoop集群都是单NameNode架构。但在生产环境中,NameNode作为HDFS的核心元数据管理节点,一旦发生故障,整个集群将陷入瘫痪。据统计,NameNode单点故障是Hadoop集群最常见的生产事故之一。
本文将从为什么需要HA 、HDFS HA的QJM机制 、YARN HA架构 、ZKFC自动故障转移四个维度,深入剖析Hadoop高可用架构的设计原理与生产实践。
一、为什么需要HA?单NameNode的致命缺陷
1.1 Hadoop 1.x时代的痛点
在Hadoop 1.x和伪分布式环境中,整个HDFS只有一个NameNode:
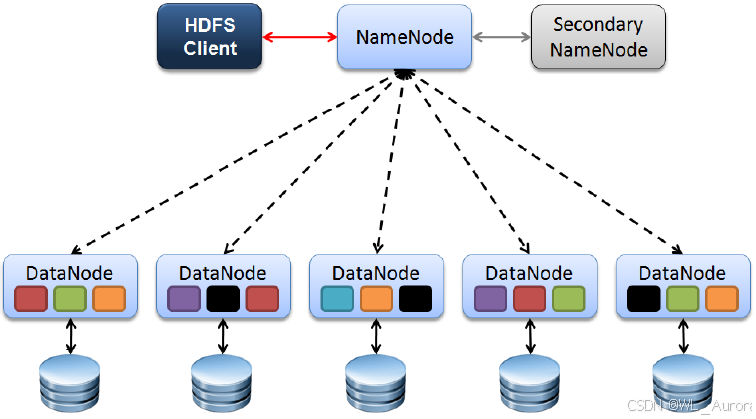
| 风险点 | 说明 |
|---|---|
| 单点故障 | NameNode宕机,整个集群不可用,无法读写数据 |
| 内存瓶颈 | 所有元数据加载在内存中,受单机内存限制 |
| 维护困难 | 升级或维护NameNode时必须停机 |
| SecondaryNameNode不是备份 | 只辅助合并FsImage和Edits,无法自动接管 |
1.2 生产环境的灾难场景
场景一:凌晨2点,NameNode服务器硬件故障宕机
→ 所有DataNode心跳超时,集群标记为不可用
→ 正在运行的ETL任务全部失败
→ 次日报表数据缺失,业务方投诉
场景二:NameNode进行版本升级
→ 必须停服维护,期间所有HDFS服务中断
→ 升级失败需回滚,停机时间不可控1.3 HA的核心目标
| 目标 | 说明 |
|---|---|
| 消除单点故障 | Active节点故障时,Standby自动接管 |
| 自动故障转移 | 无需人工干预,秒级切换 |
| 在线维护 | 滚动升级,业务不中断 |
| 数据零丢失 | 元数据实时同步,切换不丢数据 |
二、HDFS HA架构:QJM机制详解
2.1 HDFS HA整体架构
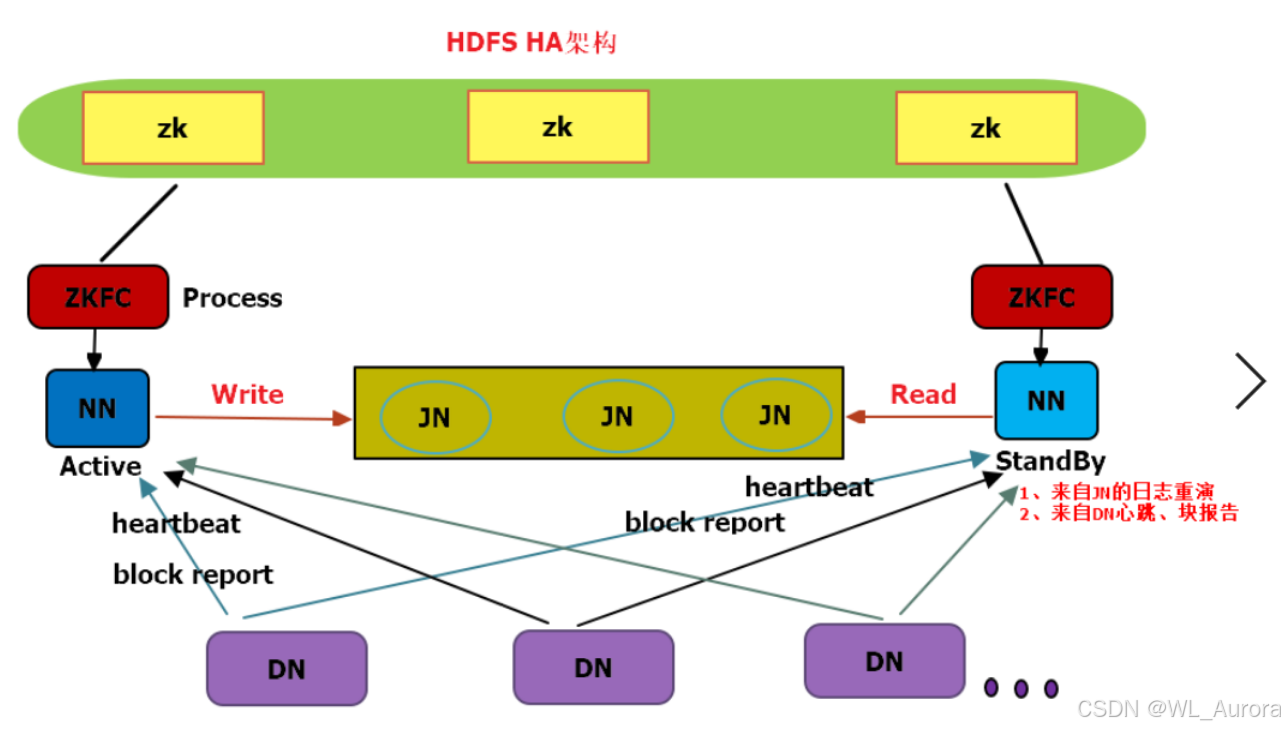
核心组件说明:
| 组件 | 数量 | 角色 |
|---|---|---|
| Active NameNode | 1 | 对外提供元数据读写服务 |
| Standby NameNode | 1 | 实时同步元数据,随时准备接管 |
| JournalNode | 3(奇数) | 共享存储Edits日志,实现元数据同步 |
| ZKFC | 2 | 监控NameNode健康状态,控制故障转移 |
| ZooKeeper | 3(奇数) | 协调ZKFC选举,存储HA状态 |
| DataNode | N | 同时向Active和Standby汇报块信息 |
2.2 QJM(Quorum Journal Manager)机制
QJM是Hadoop 2.x引入的基于Paxos算法的元数据共享方案,替代了早期依赖NFS共享存储的方案。
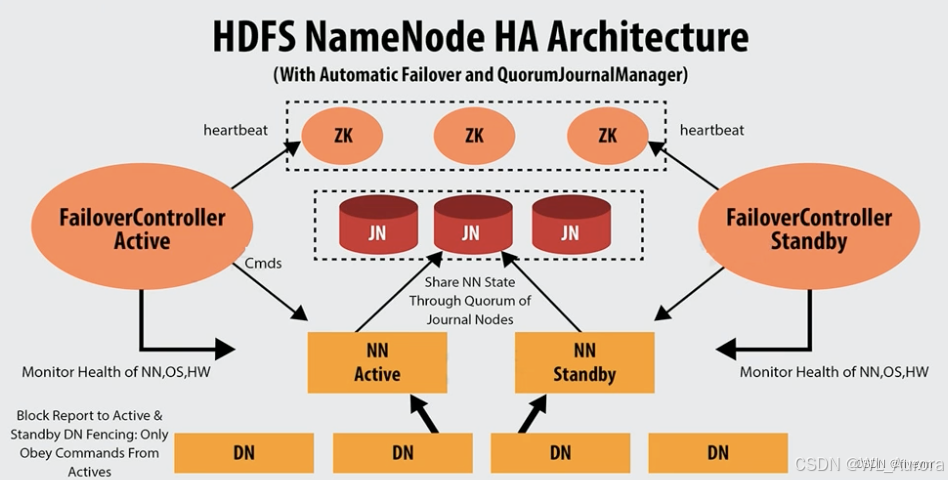
QJM写入流程:
Active NameNode 收到写请求
↓
写入本地Edits + 同时发送给JournalNode集群
↓
JournalNode收到后持久化到本地磁盘
↓
大多数JournalNode(≥N/2+1)确认写入成功
↓
Active NameNode 返回客户端写入成功
↓
Standby NameNode 从JournalNode读取Edits,回放更新内存元数据QJM的核心设计:
| 特性 | 说明 |
|---|---|
| 多数派写入 | 3个JournalNode中至少2个成功才算写入完成 |
| 防脑裂(Fencing) | 同一时刻只允许一个NameNode写入JournalNode |
| 无需共享存储 | 相比NFS方案,部署更简单,性能更高 |
| 异步读取 | Standby定期从JournalNode拉取Edits回放 |
2.3 FsImage与Edits的HA同步
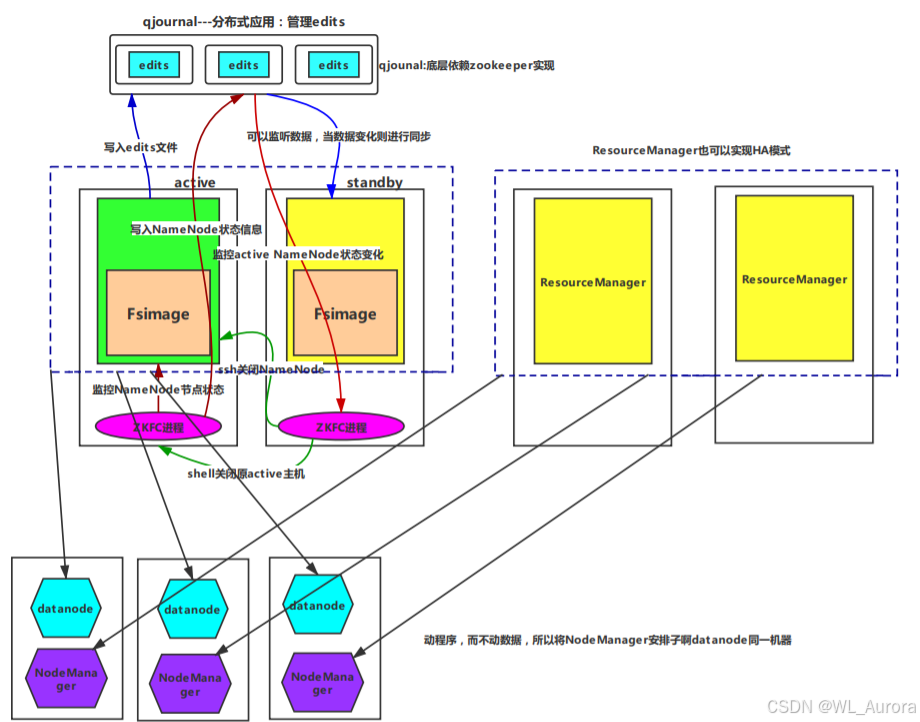
元数据同步的两种方式:
| 方式 | 路径 | 说明 |
|---|---|---|
| 实时同步(Edits) | Active → JournalNode → Standby | 通过QJM实时同步增量日志 |
| 定期同步(FsImage) | Standby自身合并 | Standby定期将Edits合并为FsImage |
Standby的元数据加载流程:
- 启动时从本地加载最新的FsImage
- 从JournalNode读取未回放的Edits
- 在内存中回放Edits,更新元数据
- 后续定期拉取新的Edits,保持与Active同步
2.4 DataNode的双向汇报
在HA架构中,DataNode需要同时向Active和Standby汇报块信息:
DataNode心跳 → Active NameNode(处理读写请求)
DataNode心跳 → Standby NameNode(保持块信息同步)为什么Standby也需要块信息?
- 当Standby切换为Active时,必须立即知道所有DataNode的块分布
- 否则无法响应客户端的读请求,也无法调度新的写操作
三、ZKFC与自动故障转移
3.1 ZKFC(ZooKeeper Failover Controller)
ZKFC是运行在NameNode服务器上的故障转移控制器,每个NameNode对应一个ZKFC进程。
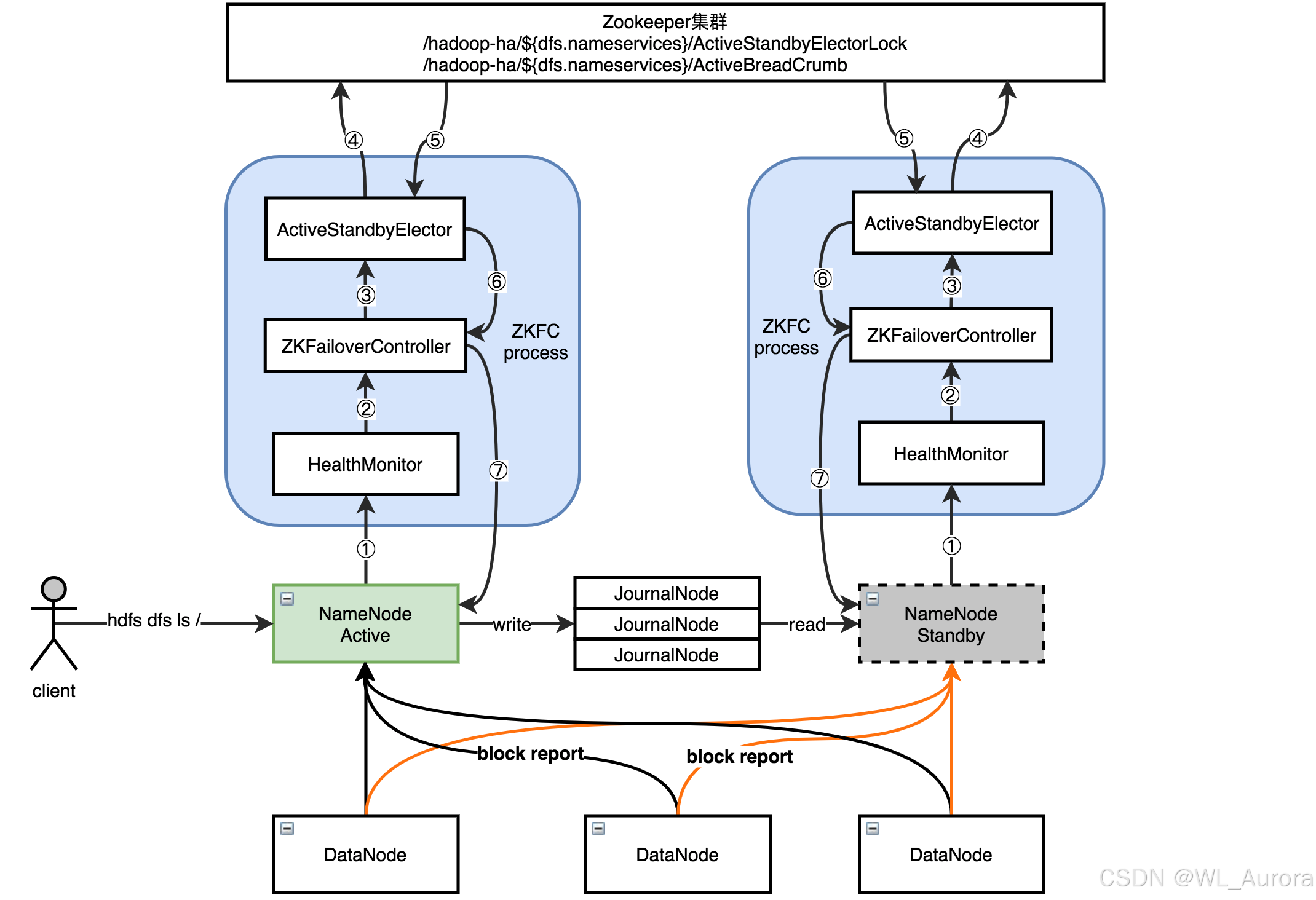
ZKFC的核心职责:
| 职责 | 说明 |
|---|---|
| 健康监控 | 定期ping本地NameNode,监控进程存活 |
| 状态管理 | 在ZooKeeper中创建临时节点,表示NameNode状态 |
| 选举协调 | 参与ZooKeeper选举,决定哪个NameNode为Active |
| 故障转移 | 触发Active到Standby的切换,执行fencing操作 |
3.2 自动故障转移流程
1. Active NameNode正常运行
└─ ZKFC在ZK中创建临时节点 /hadoop-ha/mycluster/ActiveBreadCrumb
2. Active NameNode宕机
└─ ZKFC无法ping通NameNode,判断为不健康
3. ZKFC删除ZK中的临时节点(会话超时)
└─ 其他ZKFC(Standby端)监听到节点变化
4. Standby ZKFC发起选举
└─ 在ZK中创建新的临时节点,竞争成为Active
5. 选举成功后,Standby ZKFC通知本地NameNode切换为Active
6. 原Active ZKFC恢复后,发现ZK中已有Active节点
└─ 自动切换为Standby状态3.3 Fencing机制:防止脑裂
脑裂场景:网络分区导致两个NameNode都认为自己是Active,同时向JournalNode写入,数据混乱。
Fencing(隔离)策略:
| 层级 | 机制 | 说明 |
|---|---|---|
| JournalNode层 | Epoch号机制 | 每个NameNode持有递增的Epoch号,旧Epoch的写入被拒绝 |
| DataNode层 | 命令隔离 | DataNode只执行最新Active NameNode的命令 |
| 系统层 | SSH Fencing | 通过SSH登录旧Active节点,执行kill -9强制终止 |
| 系统层 | Shell Fencing | 执行自定义脚本(如IP漂移、电源控制) |
Epoch号工作原理:
Active NN 持有 Epoch=5,向JN写入时携带 Epoch=5
Standby NN 切换为Active,Epoch递增为6
旧Active NN 仍尝试用Epoch=5写入 → JN拒绝(Epoch已过期)四、YARN HA架构
4.1 YARN HA整体架构
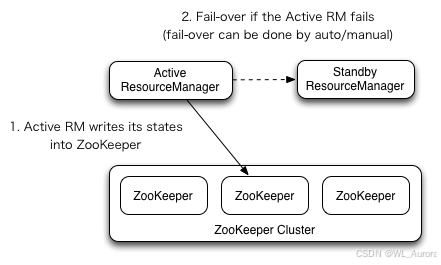
YARN的ResourceManager同样存在单点故障风险,Hadoop 2.4+支持RM的HA。
| 组件 | 数量 | 角色 |
|---|---|---|
| Active ResourceManager | 1 | 接收客户端请求,调度资源 |
| Standby ResourceManager | 1 | 同步状态,故障时接管 |
| ZooKeeper | 3 | 选举Active RM,存储状态 |
| NodeManager | N | 同时向两个RM注册,但只执行Active的命令 |
4.2 YARN HA与HDFS HA的差异
| 维度 | HDFS HA | YARN HA |
|---|---|---|
| 状态存储 | JournalNode(QJM) | ZooKeeper |
| 数据同步 | Edits实时同步 | 应用状态由ZK管理,NM重新注册 |
| 故障恢复 | Standby加载FsImage+Edits | Standby从ZK读取状态,NM重新上报 |
| 客户端影响 | 需要配置nameservice | 自动重试,对客户端透明 |
4.3 YARN自动故障转移流程
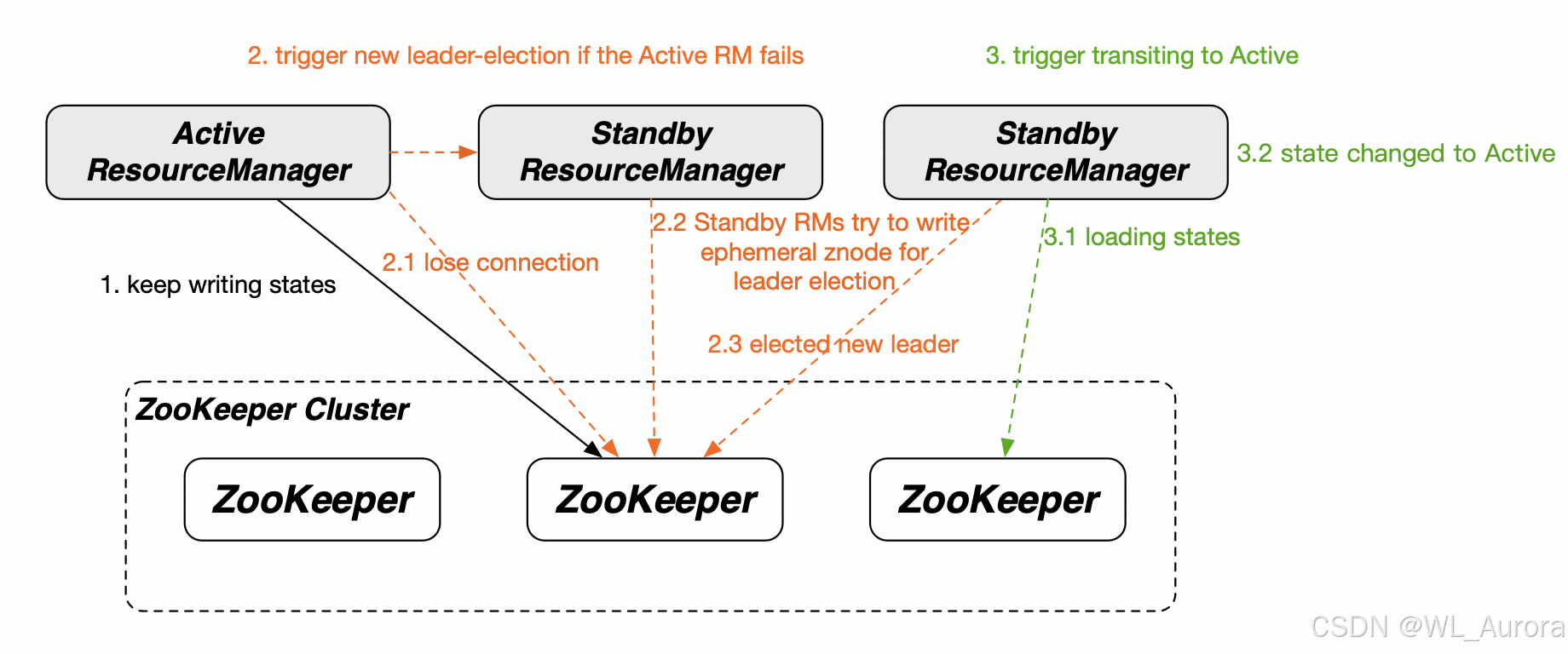
1. Active RM正常运行,定期向ZK写入状态
↓
2. Active RM宕机,ZK会话超时
↓
3. Standby RM检测到ZK中无Active节点,触发选举
↓
4. Standby RM当选为新的Active
↓
5. NodeManager心跳超时后,向新的Active RM重新注册
↓
6. 正在运行的Container继续执行,新任务由新RM调度关键设计 :YARN的故障转移不恢复正在运行的Application ,只保证新任务正常调度。如果需要恢复运行中的应用,需依赖YARN的Work Preserving Restart机制。
五、HA集群部署规划
5.1 典型3节点HA集群规划
| 节点 | 角色 | 服务 |
|---|---|---|
| hadoop102 | NameNode(Active) | NN, ZKFC, JournalNode, ZooKeeper, DataNode, NodeManager |
| hadoop103 | NameNode(Standby) | NN, ZKFC, JournalNode, ZooKeeper, DataNode, NodeManager, ResourceManager |
| hadoop104 | ResourceManager(Standby) | JournalNode, ZooKeeper, DataNode, NodeManager, ResourceManager |
JournalNode至少3个(奇数),保证多数派写入。ZK也需要3个节点。
5.2 核心配置文件
core-site.xml:
xml
<!-- 指定HDFS Nameservice名称 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 指定ZooKeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop102:2181,hadoop103:2181,hadoop104:2181</value>
</property>hdfs-site.xml:
xml
<!-- Nameservice配置 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- NameNode ID列表 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- 每个NameNode的RPC地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop102:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop103:8020</value>
</property>
<!-- JournalNode地址 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop102:8485;hadoop103:8485;hadoop104:8485/mycluster</value>
</property>
<!-- 启用自动故障转移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- ZKFC实现类 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- Fencing方法 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/atguigu/.ssh/id_rsa</value>
</property>yarn-site.xml:
xml
<!-- 启用RM HA -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- RM集群ID -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster-yarn1</value>
</property>
<!-- RM节点列表 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 每个RM的配置 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop103</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop104</value>
</property>
<!-- ZK地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop102:2181,hadoop103:2181,hadoop104:2181</value>
</property>六、HA集群启动与验证
6.1 启动顺序
bash
# 1. 启动ZooKeeper集群(每个ZK节点执行)
zkServer.sh start
# 2. 启动JournalNode(每个JN节点执行)
hdfs --daemon start journalnode
# 3. 格式化NameNode(仅在第一次部署时,hadoop102执行)
hdfs namenode -format
# 4. 同步元数据到Standby(hadoop103执行)
hdfs namenode -bootstrapStandby
# 5. 格式化ZKFC(仅在第一次部署时,hadoop102执行)
hdfs zkfc -formatZK
# 6. 启动HDFS(hadoop102执行)
start-dfs.sh
# 7. 启动YARN(hadoop103执行)
start-yarn.sh6.2 验证HA状态
bash
# 查看NameNode状态
hdfs haadmin -getServiceState nn1
# 输出: active
hdfs haadmin -getServiceState nn2
# 输出: standby
# 查看RM状态
yarn rmadmin -getServiceState rm1
# 输出: active
yarn rmadmin -getServiceState rm2
# 输出: standby
# 手动触发故障转移测试
hdfs haadmin -failover nn1 nn26.3 Web UI验证
| 服务 | 地址 | 说明 |
|---|---|---|
| Active NameNode | http://hadoop102:9870 | 显示"active"状态 |
| Standby NameNode | http://hadoop103:9870 | 显示"standby"状态 |
| Active RM | http://hadoop103:8088 | 显示集群资源 |
| Standby RM | http://hadoop104:8088 | 自动重定向到Active |
七、故障转移测试
7.1 模拟NameNode故障
bash
# 在hadoop102上kill Active NameNode进程
jps | grep NameNode
# 输出: 12345 NameNode
kill -9 12345
# 观察hadoop103的NameNode是否自动切换为Active
hdfs haadmin -getServiceState nn2
# 预期输出: active7.2 模拟ResourceManager故障
bash
# 在hadoop103上kill Active RM进程
jps | grep ResourceManager
kill -9 <pid>
# 观察hadoop104的RM是否自动切换
yarn rmadmin -getServiceState rm2
# 预期输出: active八、核心知识点总结
| 主题 | 核心要点 |
|---|---|
| HA必要性 | 消除NameNode/RM单点故障,实现7x24小时服务 |
| HDFS HA | Active+Standby双NameNode,QJM共享Edits,DataNode双向汇报 |
| QJM机制 | 多数派写入(≥N/2+1),Epoch号防脑裂,无需NFS |
| ZKFC | 监控NameNode健康,ZK选举协调,触发自动故障转移 |
| Fencing | 多层隔离:JournalNode Epoch、DataNode命令过滤、SSH kill |
| YARN HA | 双RM架构,状态存储在ZK,NM自动重新注册 |
| 部署要点 | JournalNode和ZK必须奇数节点,配置nameservice替代具体IP |
九、面试高频考点
Q1:Hadoop HA中,JournalNode的作用是什么?为什么需要奇数个?
A:JournalNode是Active和Standby NameNode之间的共享存储,用于同步Edits日志。采用多数派写入机制(≥N/2+1),3个JN中至少2个成功才算写入完成。奇数个是为了避免脑裂时无法形成多数派(如2个JN各1票,无法决策)。
Q2:ZKFC是如何实现自动故障转移的?
A:ZKFC通过ZooKeeper的临时节点和Watcher机制实现。Active NN的ZKFC在ZK中创建临时节点,宕机后会话超时节点删除,Standby的ZKFC监听到变化后发起选举,竞争成为新的Active,并通知本地NN切换状态。
Q3:什么是Fencing?Hadoop HA中有哪些Fencing机制?
A:Fencing是防止脑裂的隔离机制。Hadoop HA中有三层Fencing:①JournalNode通过Epoch号拒绝旧Active的写入;②DataNode只执行最新Active的命令;③系统层通过SSH或Shell脚本强制kill旧Active进程。
Q4:YARN HA与HDFS HA的状态同步方式有何不同?
A:HDFS HA通过QJM实时同步Edits日志,Standby加载FsImage+Edits恢复状态;YARN HA通过ZooKeeper存储RM状态,故障转移后Standby RM从ZK读取状态,NodeManager重新注册上报资源。
Q5:HA架构中,客户端如何知道哪个NameNode是Active?
A:客户端通过配置
fs.defaultFS为Nameservice名称(如hdfs://mycluster),而非具体IP。Hadoop客户端会连接所有配置的NameNode,通过RPC询问谁是Active,自动路由到Active节点。