目录
- 一、Linu线程概念
-
- [1.1 什么是线程?](#1.1 什么是线程?)
- [1.2 见一见线程](#1.2 见一见线程)
- 二、再谈虚拟地址空间
-
- [2.1 物理内存管理](#2.1 物理内存管理)
- [2.2 页表的本质](#2.2 页表的本质)
- 三、pthread库
- 四、线程补充
-
- [4.1 线程的优点](#4.1 线程的优点)
- [4.2 线程的缺点](#4.2 线程的缺点)
- [4.3 线程异常](#4.3 线程异常)
个人主页:矢望
个人专栏:C++、Linux、C语言、数据结构、Coze-AI、MySQL
一、Linu线程概念
1.1 什么是线程?
我们之前说进程=内核数据结构+代码和数据。
而线程是进程内部的执行分支。
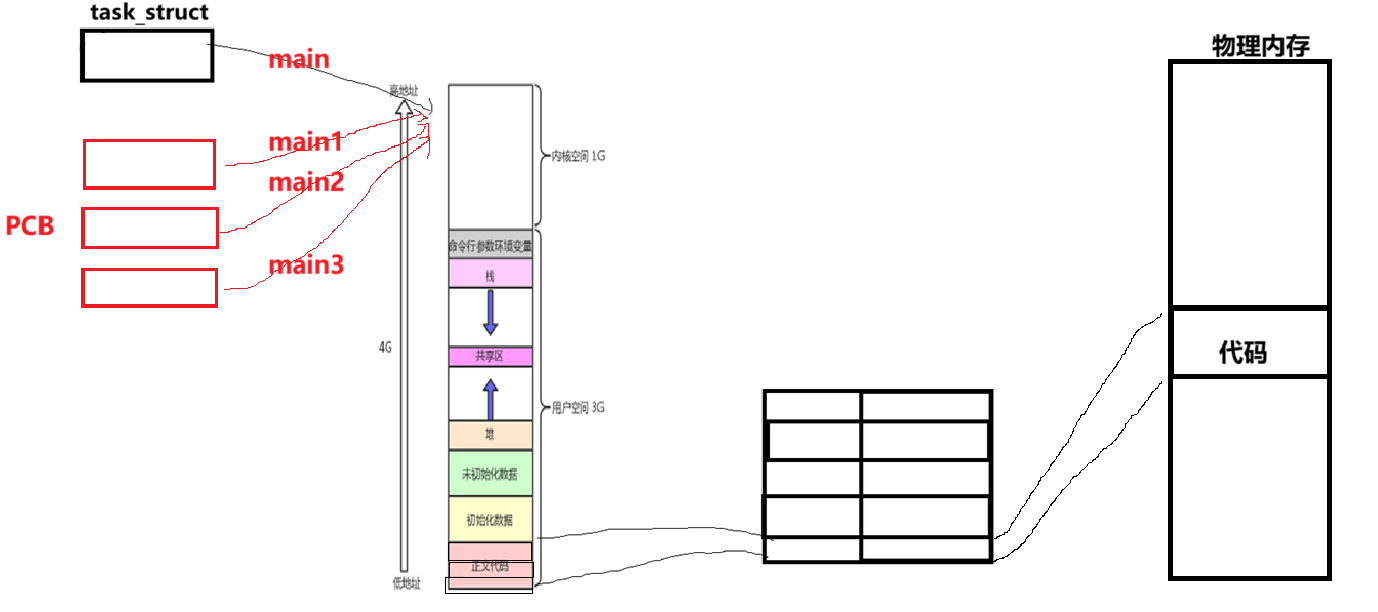
如上图,我们之前讲进程会有自己的PCB结构,会有虚拟地址空间等等资源。进程的正文代码段,当代码执行起来的时候,程序就会执行main方法,进而执行整个程序。
那么我们可以把进程的正文代码分为好几个部分,然后再在这个进程内部多创建几个PCB,这几个PCB共同使用进程的代码和数据,让这几个PCB分别执行进程正文代码的一部分,如上图所示。这几个PCB执行流我们就叫做线程。
所以 Linux下线程在进程的内部运行,本质是在进程的虚拟地址空间内部运行。
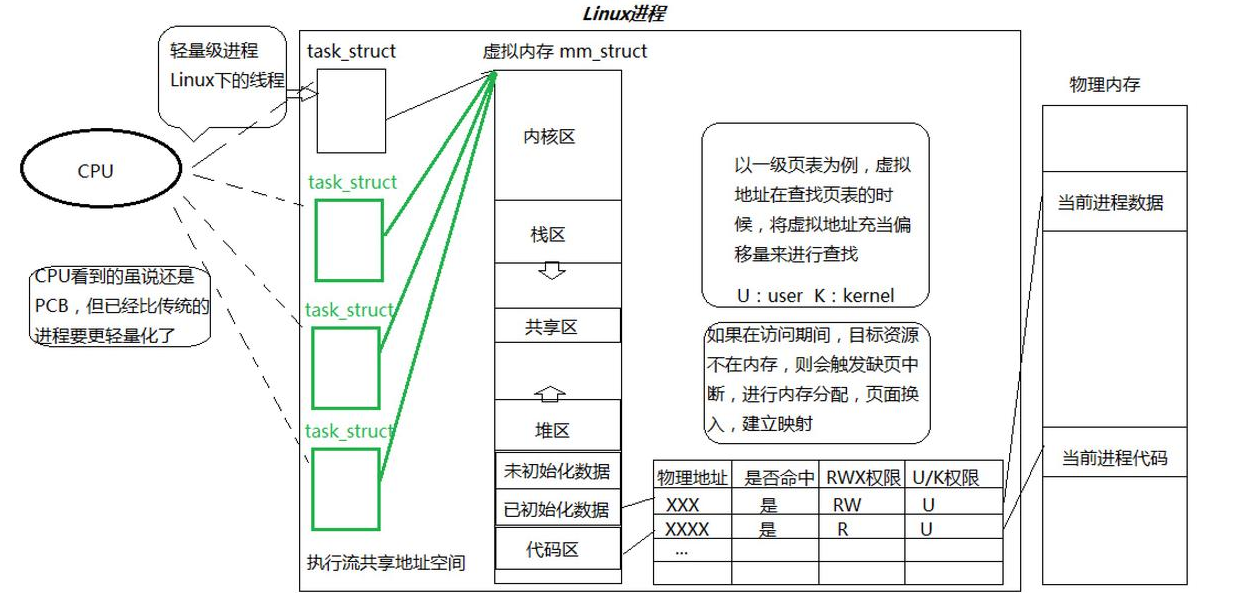
我们之前学习的进程的本质就是内部只有一个线程的情况。而进程内部可以同时存在一个或者多个线程 ,所以我们之前学习的进程是一种特殊情况。因此 进程=(多个线程+地址空间+页表)内核数据结构+代码和数据!
也就是创建进程就要预先申请一大批的资源,比如内存、CPU等。进程获取资源之后,进程就会分配资源给执行流线程使用。因此在操作系统视角:进程是承担分配系统资源的基本实体!线程属于操作系统调度的基本单位!
进程有对应的PCB,所以在操作系统学科中,线程也有TCB(Thread Ctrl Block)线程控制块存在。线程的TCB在设计上和PCB几乎完全一样。所以就有了实现线程的两种方式,一种是单独为线程设计TCB,另一种是复用PCB实现TCB。
在Windows操作系统上,它单独为线程设计了TCB;而在Linux操作系统上,Linux程序员复用了进程相关的数据结构,task_struct,使用进程内核数据结构模拟实现了线程的效果。
在CPU执行的时候,CPU不需要区分进程和线程,在CPU视角没有进程,只有执行流(线程)。具体到Linux系统上,执行流就是轻量级进程,Linux系统上线程不叫线程也不叫进程,叫做轻量级进程。进程=一个或者多个轻量级进程+其它资源。
1.2 见一见线程
在Linux操作系统上我们使用pthread_create函数来创建线程,它不是系统调用。

| 参数 | 说明 |
|---|---|
thread |
输出参数,成功返回后存储线程ID |
attr |
线程属性(栈大小、调度策略等),传NULL使用默认属性 |
start_routine |
线程入口函数,线程从此函数开始执行 |
arg |
传递给入口函数的参数 |
我们先编写一段代码:
cpp
#include <iostream>
#include <unistd.h>
#include <pthread.h>
void* ThreadRun(void *args) // 线程入口函数
{
while(true)
{
std::cout << "New thread is running..., pid: " << getpid() << std::endl;
sleep(1);
}
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, ThreadRun, nullptr); // 创建新线程
while(true)
{
std::cout << "Main thread is running..., pid: " << getpid() << std::endl;
sleep(1);
}
return 0;
}编译:

它说不认识这个函数。pthread_create等线程函数实现在libpthread.so中,这不是C++标准库/编译器默认链接的库,所以必须显式指定。
再次编译:

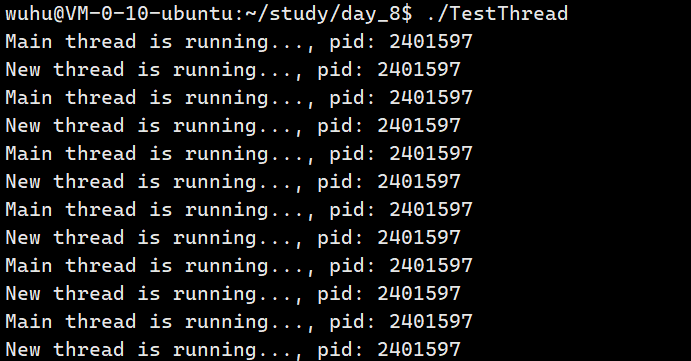
如上图,我们编译成功了,这个代码预期运行的结果是主线程创建了一个新线程,然后新线程跑去执行ThreadRun方法,主线程执行后面的代码。
运行:
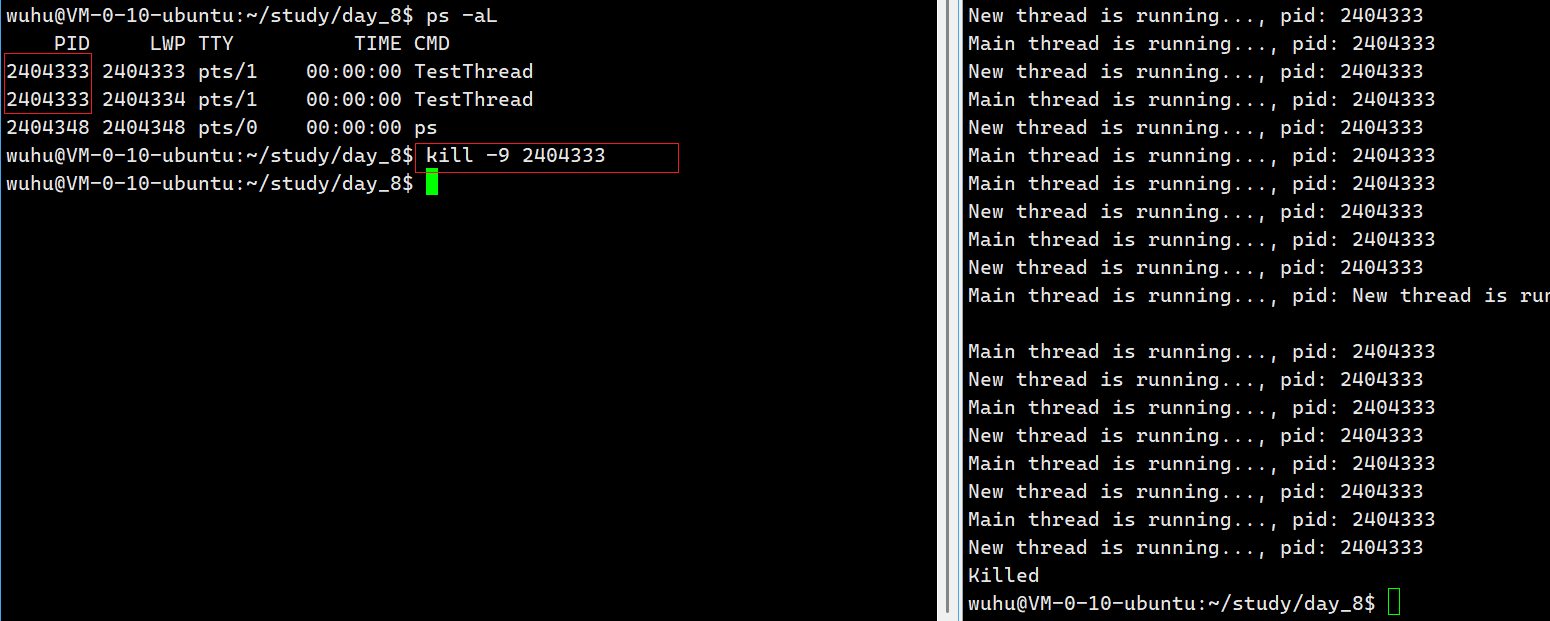
我们还要看到确实有两个线程在跑,使用ps -aL命令即可查看Linux系统中的轻量级线程LWP(Light weight Process)。
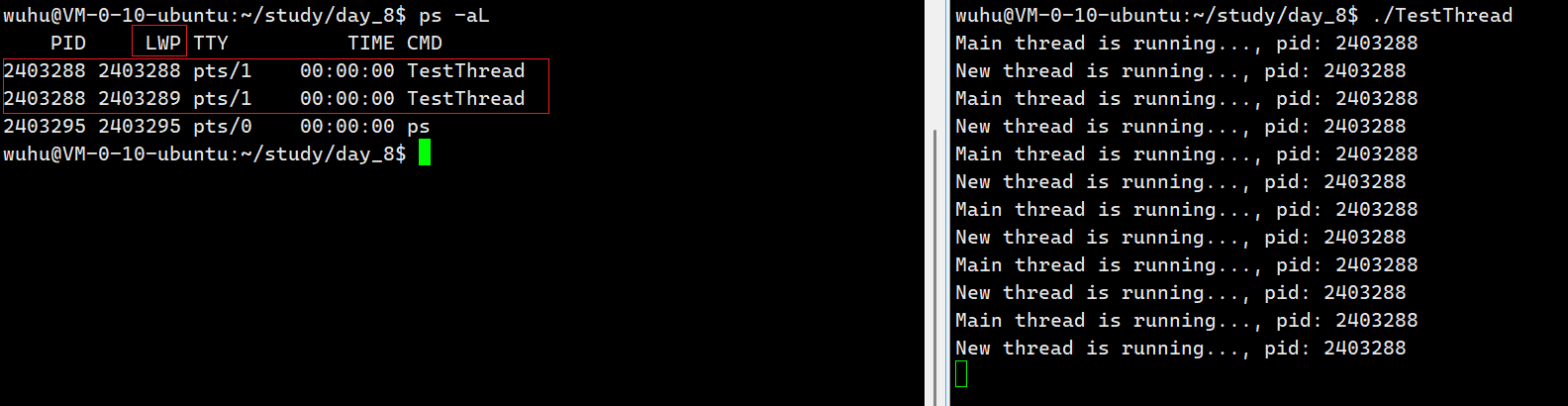
如上图,我们看到确实有两个进程在运行,它们的进程号pid都相同,但LWP的数值不同,CPU就是通过LWP来区分执行流的。
当你要杀掉进程的时候依旧要使用pid杀掉进程,并且杀掉之后,进程内部的所有执行流都会终止 。如下:
二、再谈虚拟地址空间
2.1 物理内存管理
物理内存是按照4KB的小空间进行细分的,将来磁盘和物理内存进行数据交换的最小单位就是4KB,物理内存中的这一个个4KB的内存块叫做页框或者页帧。
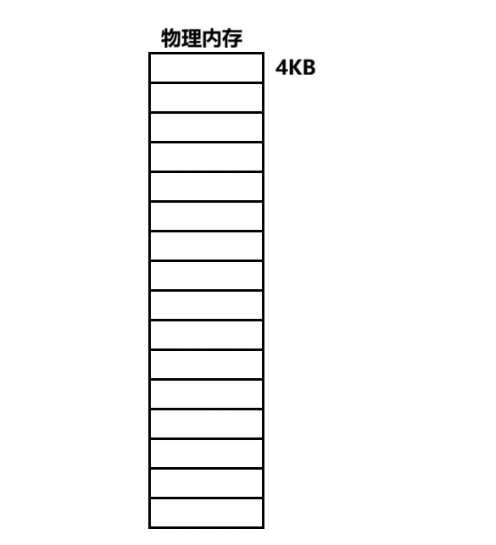
假设物理内存是4GB,那么它就会有如下图这么多个页框。

OS一定要对这么多的内存块做管理,管理页框的数据结构在内核中叫做Page,这个结构体中有很多的标志位。
cpp
struct Page
{
// 标志位
int flags; // 位图
}
cpp
struct page {
unsigned long flags; // 页框状态标志位
union {
struct list_head lru; // LRU链表(页面回收使用)
struct list_head slabs_list; // slab分配器使用
};
struct address_space *mapping; // 映射到哪个文件
unsigned long index; // 在映射中的偏移量
atomic_t _refcount; // 引用计数(谁在用这个页框)
unsigned int active; // 活动性计数
// ... 还有更多联合体字段
};将来这个Page结构体会被被这样组织起来:
cpp
struct Page mem[1048576]; 所以对页框进行管理就转化成了对mem数组进行管理!mem的数组下标乘以4KB就是具体的页框的地址!所以页框的物理地址和数组下标之间可以相互转化。
将来如果你要找40967地址的数据,就直接40967/4096取整,直接就可以转化成mem的数组下标,然后,通过mem[数组下标]就可以查找相关Page结构体中的数据!
所以页框内的任意一个地址都可以直接找到他所处的Page的属性!
对页框地址除以4096就是让地址的二进制数右移12位,4096是2的12次方。
2.2 页表的本质
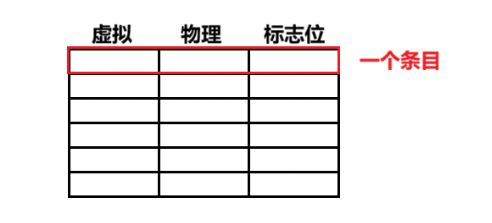
如上是我们理想状态下的页表,如果一个条目是10字节的话,一共有2的32次方个条目,那么单单一个页表就需要占用40GB的空间吗?! 很明显肯定不是这样的,那么它是怎样的呢?
实际上虚拟地址被分成了三个部分:
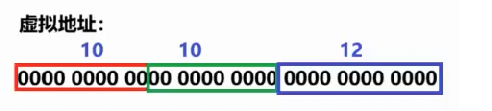
如上图,它被分为了高10位、中间10位、低12位。
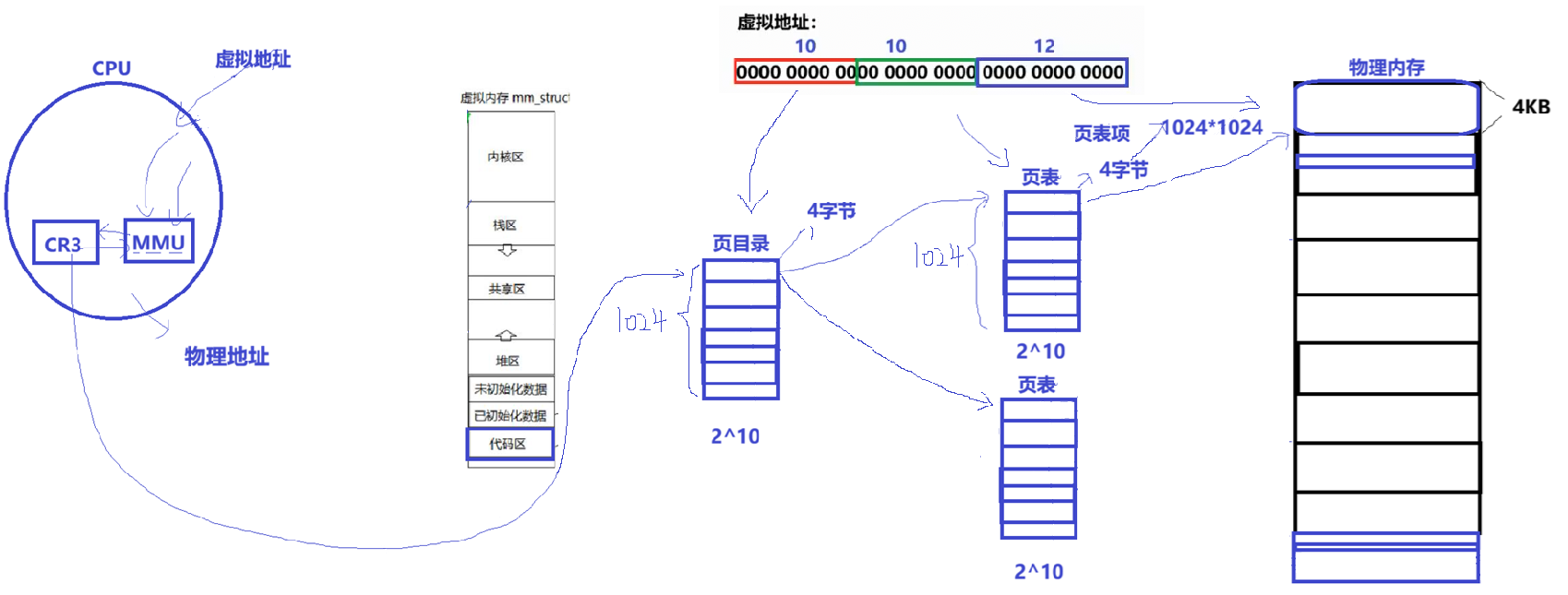
如上图,是实际上的页表,以及找页框的过程。
页目录有210项,也就是1024个,页表也是有210项,1024个,每一个页表项中存放着一个页框的物理地址,每一个页目录项中存放着一个页表的物理地址。所以会有1024个页表,每个页表有1024项,也就是每个页表会指向1024个页框,那么一共会有1024*1024=1,048,576个页框,也就是2的20次方个页框。
首先通过CPU中的CR3寄存器寻找到页目录的地址,然后利用虚拟地址的高10位去索引具体的页目录项,然后在这个页目录项中保存着要访问页表的地址,然后跳转到这个页表之后,再根据虚拟地址的中间10位去索引具体的页表项,在这个页表项中保存着要访问的页框的地址。然后我们跳转到具体的页框之后,再根据虚拟地址的低12位去索引我们要访问的数据在页框的哪个位置,这样就找到我们要访问的数据了。
注意 :上面我们说过页框的大小是4KB,212次方,也就是 虚拟地址空间的低12位就是给具体页框去索引具体数据预留的,严丝合缝!!! 硬件和软件在4KB这个粒度上达成了完美的一致。
在这整个过程中,虚拟地址的各个部位的作用始终是起到一个偏移量的作用,在页目录、页表、页框这几个结构中,偏移找到我们具体要访问的地方。页目录项中保存的是页表的物理地址,页表项中保存的是页框的物理地址 。
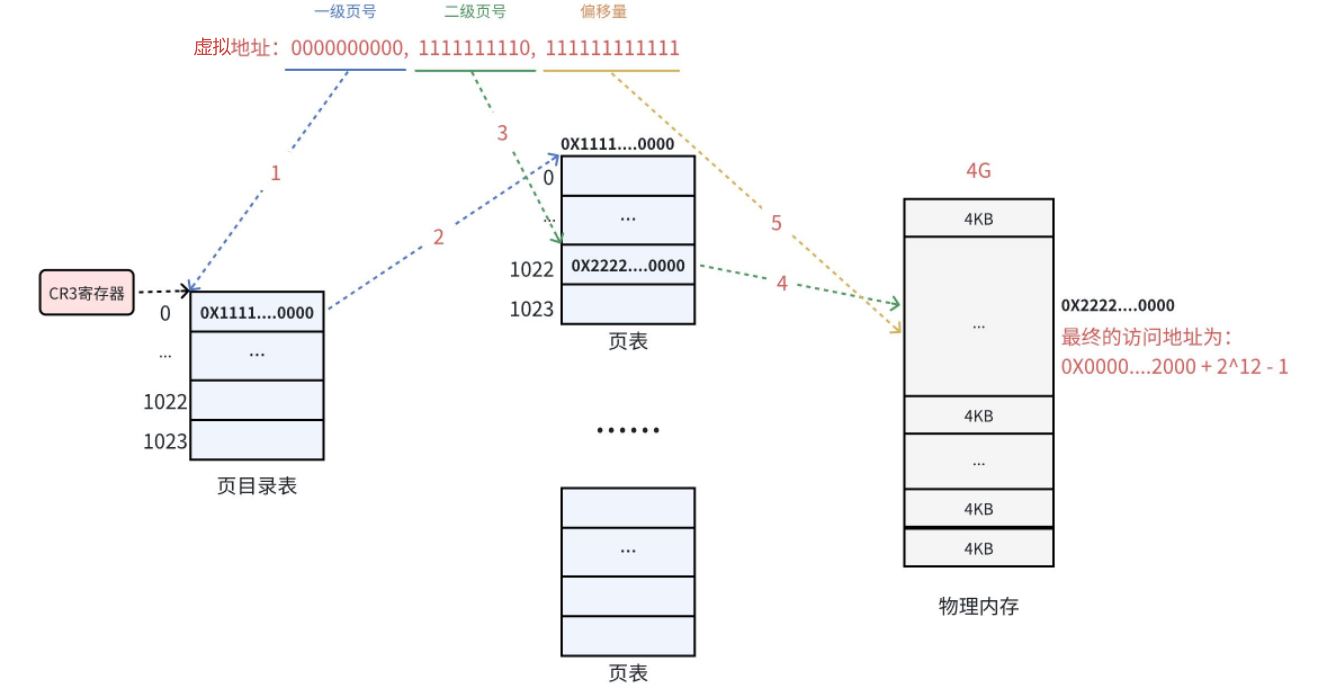
以上就是页表的结构,计算下来 页目录加上所有的页表一共1025个,一个页表中有2的10次方个位置,一个位置是4字节的数据,所以一个页目录/页表是4096字节,也就是4KB,1025*4KB=4MB+4KB,也就是说页表的真实大小只有4MB+的空间!
扩充 :页框的物理地址是4KB对齐的,它的二进制位低12位都是0。页目录和页表的地址也都是4KB对齐的,也就是说它们的物理地址的二进制低12位都是0,因为使用高20位就可以索引到页框的起始物理地址。因此,将来使用虚拟地址的前20位就可以找到任意一个页框的物理地址!另外,如果两个虚拟地址的前20位相同,说明它们在同一个页框上。
根据它们都是4KB对齐,我们也可以知道,页目录项/页表项中只有高20位代表物理地址,低12位是没有被使用的!那么这低12位就可以存放标志位!!!
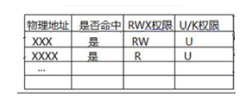
物理层面 (页框):物理内存被拆成 4KB 的页框(低12位地址为0)
虚拟层面 (页面):虚拟地址空间也被拆成 4KB 的页面(低12位就是页内偏移)
映射层面 (页表):页表项(PTE)正好用高20位存储物理页框号,低12位存放标志
CPU层面 (MMU):硬件强制要求页目录、页表、页框都按 4KB 对齐
| 组件 | 大小 | 地址位分配 | 作用 |
|---|---|---|---|
| 虚拟地址 | 32位 |
10(页目录) + 10(页表) + 12(偏移) |
CPU发出的地址 |
| 页目录项(PDE) | 4字节 |
高20位(页表基址) + 12位标志 |
指向页表 |
| 页表项(PTE) | 4字节 |
高20位(页框基址) + 12位标志 |
指向物理页框 |
| 物理地址 | 32位 |
高20位(页框号) + 12位(页内偏移) |
访问内存的最终地址 |
细节1 :单个进程不可能拥有全部的内存,一般情况下2张页表就够用了,所以当前进程的页表总数远远小于4MB!
细节2 :因为有懒加载机制,所以真正使用的页表只会更少。写时拷贝时会要被页表,在拷贝时是将变量所在的页框中所有4KB数据全部进行拷贝,由于局部性原理,所以这本质是一个一空间换时间的行为。
细节3 :任何一个页框的地址,用20个比特位表示就够了。
细节4 :上面的所有工作都由MMU硬件自动帮我们完成映射转换,如果发生了转换失败、不存在、权限问题等都会转换成异常中断通知CPU。
细节5 :CR3寄存器是页目录基址寄存器,它存储的是当前进程页目录的物理地址。CR3寄存器中存储的内容就是进程的上下文。如果要进行切换页表的工作,直接将CR3寄存器中的值切换成另一个进程的页目录物理地址即可,这样整个页表就都切换了!
扩充 :CR2寄存器中存储的是引起崩溃的地址。
串起来 :当CPU执行指令访问一个虚拟地址时,MMU 自动从 CR3 指向的页目录开始查表。如果页表项中的 20位物理页框号 有效且权限允许,就拼接 (虚拟地址)12位偏移 得到物理地址;否则触发异常,CR2记录出错地址,内核介入处理(如COW复制整个 4KB物理页、懒加载等)。进程切换时只需换 CR3 的值,整个页表就切换了。
拥有更多的物理地址就意味着拥有更多的内存,所以拥有更多的虚拟地址就意味着拥有更多的内存资源!因此只要我们把虚拟地址进行划分,本质就是划分物理内存!而执行流各自就是拥有一批虚拟地址,它们各自执行这一批虚拟地址!所以如何划分虚拟地址呢?
我们使用objdump -S反汇编我们上面写的代码生成TestThread.s文件。
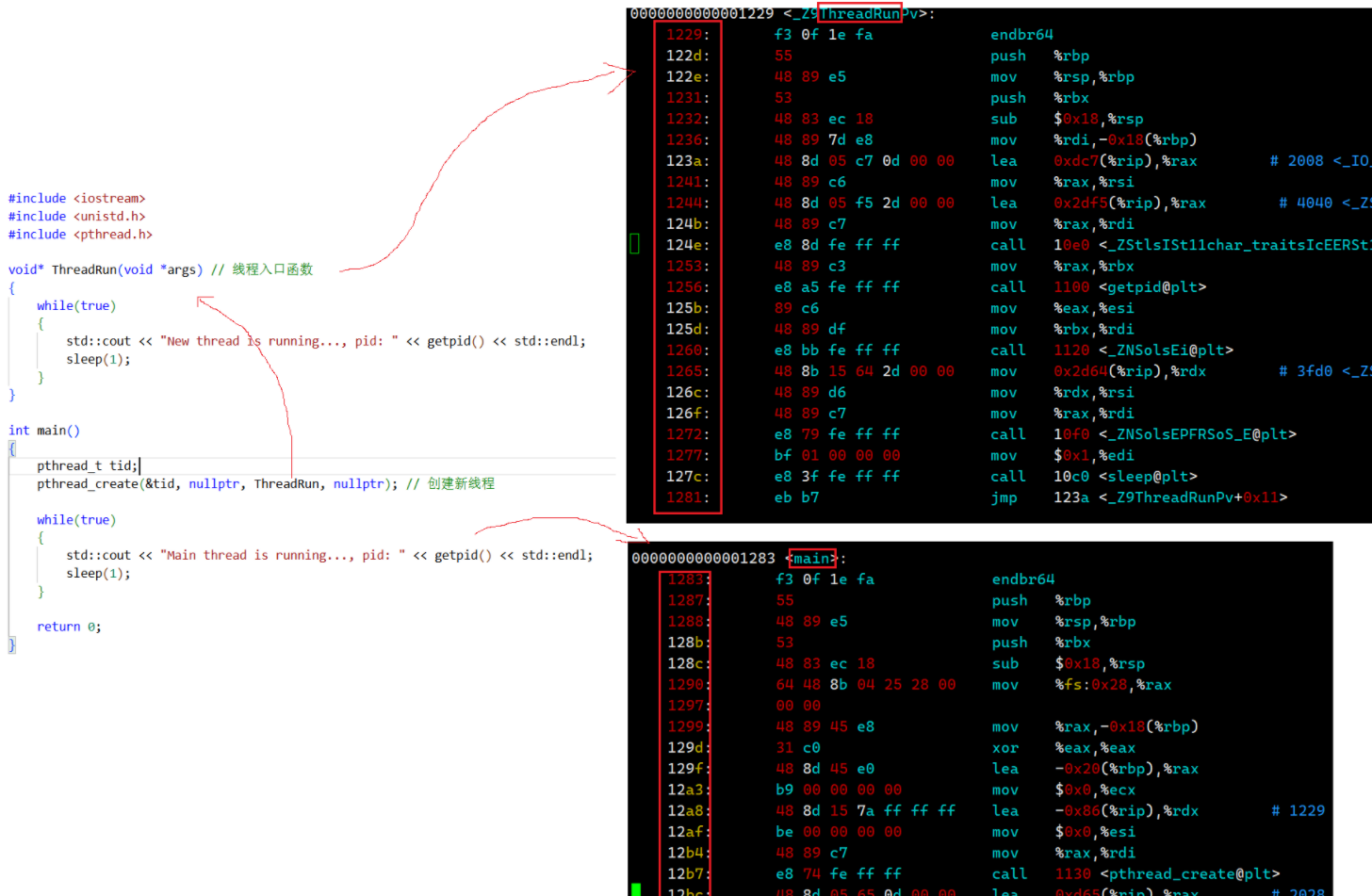
如上图,在反汇编代码中,我们可以看出主线程和新线程都各自拥有一批虚拟地址,所以虚拟地址是在编译阶段进行划分的!
让不同的PCB执行进程代码的一部分,执行不同的函数,本质就是让PCB执行不同的代码区对应的虚拟地址空间!
页表的本质是进程看到内存资源的窗口,拥有的虚拟地址越多,拥有的物理内存也就越多,划分区域本质就是划分虚拟地址!
三、pthread库
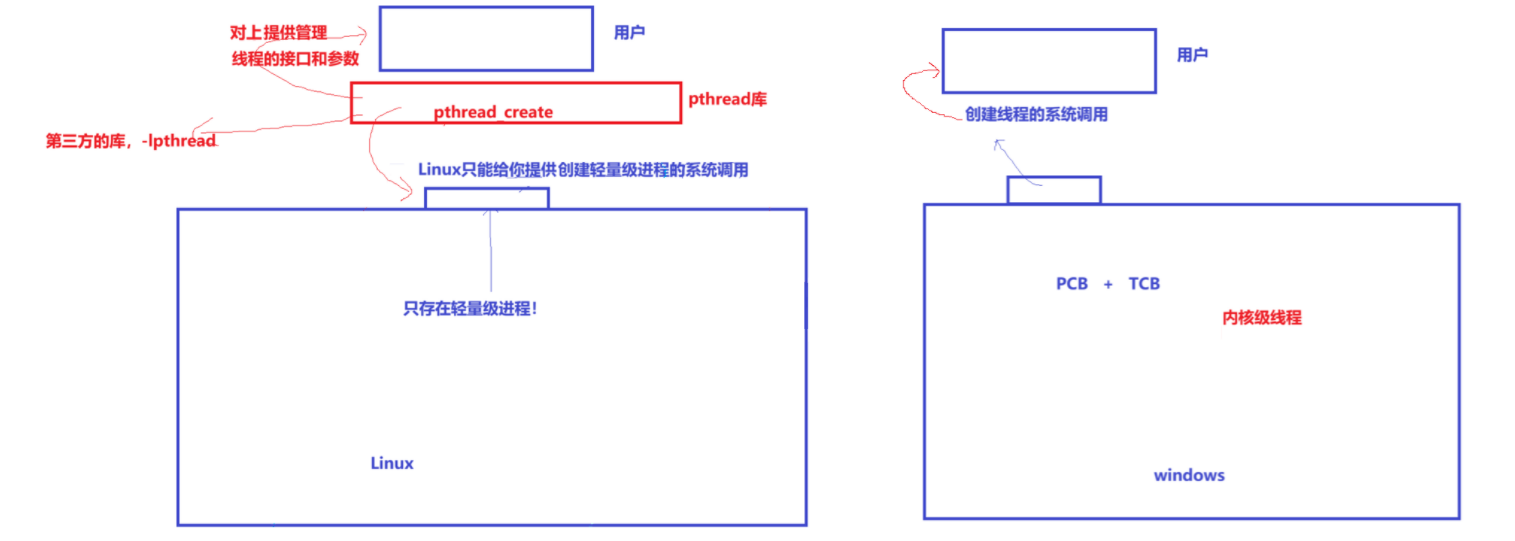
如上图,Windows上存在进程和线程,所以Windows会提供创建线程的系统调用,用户可以调用创建线程的系统调用创建线程。这个是内核级线程。
但Linux中没有线程的概念,只有轻量级进程,所以Linux只能给用户提供创建轻量级进程的系统调用。但是用户只知道线程,不知道Linux轻量级进程的概念,所以Linux为了消除这种差异性,就在上层提供了pthread库,使用这个库给用户提供管理线程的接口和参数,这个库就是用户级线程库。由于是第三方的库,也叫原生线程库,所以编译时必须加上-lpthread。
由于Linux下只有轻量级进程的概念,在它看来进程内部都是轻量级进程,所以只有创建轻量级进程的接口,叫做clone。
clone 是Linux内核提供的、用于创建新执行流(轻量级进程)的唯一底层系统调用 。
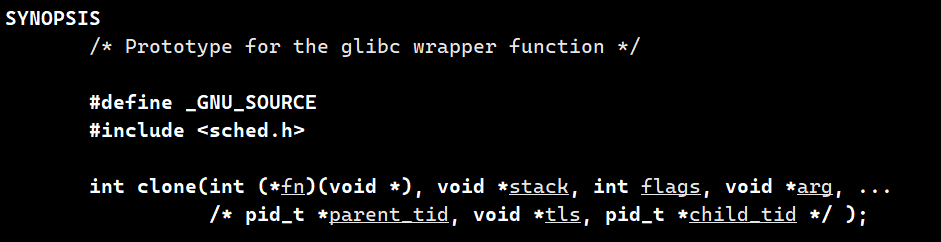
这个函数中有一个flags的参数,这个参数可以控制创建时要不要复制地址空间、页表等资源,如果要复制就是创建进程,如果不复制就是创建线程。
pthread_create、vfork底层都是调用clone,它们都是创建线程的,所以它们都不复制地址空间、页表等资源。vfork是Linux真正的创建轻量级进程的接口。
frok的底层也调用clone,不过它要复制地址空间、页表等资源。
轻量级进程共享虚拟地址空间,共享有效虚拟地址、页表,共享进程的大部分资源。进程是独立性,大部分资源独占。线程是共享性,大部分资源共享。
线程也有自己的"私有"数据:线程ID、一组寄存器,线程的上下文数据、栈、errno、信号屏蔽字、调度优先级。
四、线程补充
线程和进程的关系如下图:
4.1 线程的优点
创建/删除一个新线程的代价要比创建/删除一个新进程的代价小得多。
线程与进程相比,线程之间的切换需要操作系统做的工作要少的多 。
这里需要聊一聊一个硬件缓存,如下图:
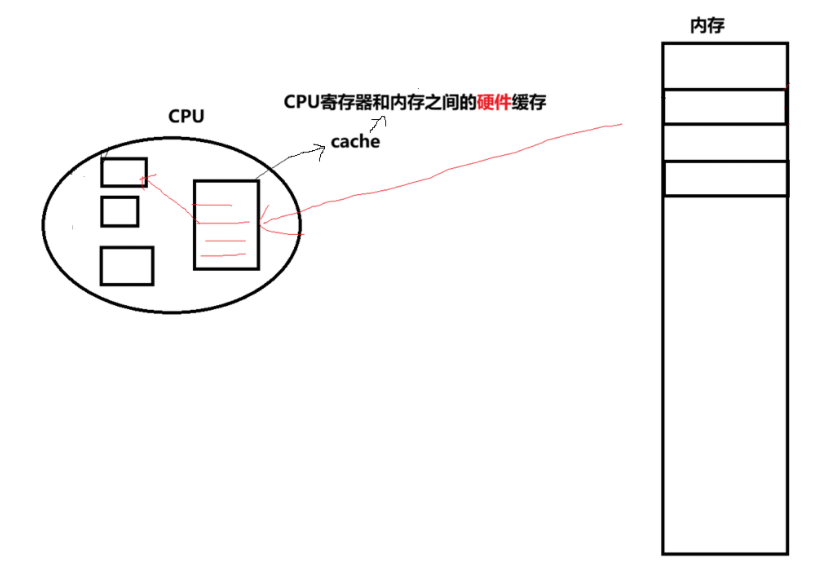
如上图,CPU与内存进行IO的时候是比较慢的,如果频繁的进行IO操作就会影响效率,所以就有了硬件cache这个硬件。
硬件缓存cache 是CPU与主存之间的高速小容量存储器,利用程序局部性原理(时间局部性:刚访问的数据很可能很快再访问;空间局部性:相邻数据很可能被访问)自动工作,对OS和用户程序透明。
这样 CPU执行的代码就可以提前缓存进入cache硬件缓存中,等到执行下面的代码时,先看看cache中有没有,如果有就直接读取,没有就从内存中获取,并且再次刷新cache中的数据。
所以同一个进程内的线程切换是不需要切换cache的;而不同的进程之间的切换是需要切换cache的,这个过程会丢弃cache重新进行命中缓存。因此线程之间的切换需要操作系统做的工作要少的多。
线程占用的资源要比进程少;能充分利用多处理器的可并行数量;在等待慢速I/O操作结束的同时,程序可执行其他的计算任务;计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现;I/O密集型应用,为了提⾼性能,将I/O操作重叠。线程可以同时等待不同的I/O操作。
合理的使用多线程,能提高CPU密集型程序的执行效率。
4.2 线程的缺点
-
性能损失
◦ 一个很少被外部事件阻塞的计算密集型线程往往无法与其它线程共享同一个处理器。如果计算密集型线程的数量比可用的处理器多,那么可能会有较大的性能损失,这里的性能损失指的是增加了额外的同步和调度开销,而可用的资源不变。
-
健壮性降低
◦ 编写多线程需要更全面更深入的考虑,在一个多线程程序⾥,因时间分配上的细微偏差或者因共享了不该共享的变量而造成不良影响的可能性是很大的,换句话说线程之间是缺乏保护的。
-
缺乏访问控制
◦ 进程是访问控制的基本粒度,在一个线程中调用某些
OS函数会对整个进程造成影响。
4.3 线程异常
单个线程如果出现除零,野指针问题导致线程崩溃,进程也会随着崩溃。线程是进程的执行分支,线程出异常,就类似进程出异常,进而触发信号机制,终止进程,进程终止,该进程内的所有线程也就随即退出。
总结:
以上就是本期博客分享的全部内容啦!如果觉得文章还不错的话可以三连支持一下,你的支持就是我前进最大的动力!
技术的探索永无止境! 道阻且长,行则将至!后续我会给大家带来更多优质博客内容,欢迎关注我的CSDN账号,我们一同成长!
(~ ̄▽ ̄)~