文章目录
- 前言
- SQL查询语句是如何执行的?
-
- [Select 执行流程](#Select 执行流程)
-
- [1. 客户端](#1. 客户端)
- [2. 连接器](#2. 连接器)
- 3.查询缓存
- [4. 分析器](#4. 分析器)
- [5. 优化器](#5. 优化器)
- [6. 执行器](#6. 执行器)
- [7. 存储引擎层](#7. 存储引擎层)
- 结语
前言
我们每天都在写SQL,但很少想过它背后的完整旅程。了解MySQL如何接收、解析、优化并执行一条查询,是区分"会用数据库"和"懂数据库"的关键一步。
SQL查询语句是如何执行的?
我们平时在写SQL语句时能直观感受到的就是,当我们写好一个查询语句之后就开始执行这条查询语句,然后回返回结果数据给我,这给我们的感受就是我们只是输入一条语句,返回一个结果,却不知道这条语句在MySQL中的执行过程。
Select 执行流程
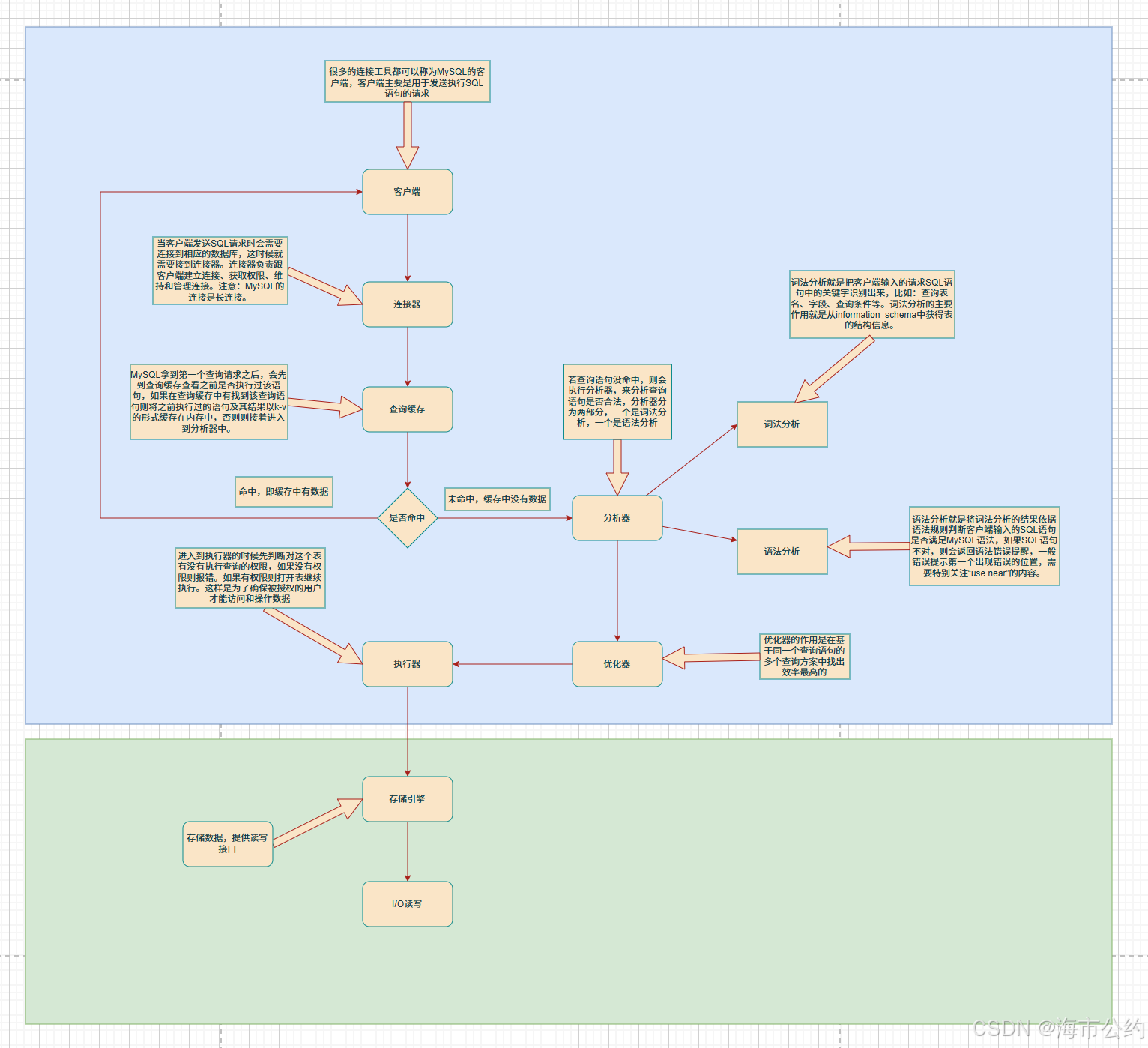
1. 客户端
- 定义:一切向MySQL服务端发起请求的外部工具或程序。
- 详细执行过程:
- 我们在实际开发中使用的终端命令行(CLI模式)、可视化管理工具(如:Navicat、SQLyog、DataGrip)或则程序代码(如Java通过JDBC连接、Python通过PyMySQL),在架构上都属于客户端。
- 客户端的核心职责是:包裹用户的SQL语句,通过网络协议向MySQL服务端发送执行请求。
2. 连接器
- 定义:MySQL服务端用来接待客户端的"前台门卫",负责管理连接、获取权限、维持和管理连接。
- 详细执行过程:
- TCP三次握手:客户端发起连接命令后(例如:
mysql -h$ip -P$port -u$user -p) ,连接器首先与客户端完成经典的 TCP 三次握手,建立起底层的网络通信管道 。 - 身份认证:握手成功后,连接器开始验证你输入的用户名和密码 。如果账号密码错误,会直接抛出著名的
Access denied for user错误并切断连接 。 - 权限快照读取:当认证通过后,连接器会立刻前往 MySQL 内部的系统权限表(如
mysql.user表)查出该用户目前拥有的所有权限 。- 关键底层逻辑:连接器在此刻读取到的权限会被缓存在当前连接对象中。这意味着,哪怕管理员在几秒后用另一个终端修改了该用户的权限,当前这个连接的权限也不会发生改变,必须断开重连才会生效 。
- 连接状态与超时维护:连接建立后,我们可以通过
SHOW PROCESSLIST查看到它的状态 。如果客户端太长时间没有发送任何 SQL(处于空闲状态Sleep),连接器并不会让它永久驻留,而是由参数wait_timeout(默认是 28800 秒,即 8 小时)进行倒计时 。超时后连接器会自动断开它 。 - 长连接与内存陷阱(OOM):
- 长连接指连接成功后持续复用同一个连接执行请求;短连接指执行几次查询就断开,下次重新建立 。频繁创建连接非常消耗性能,通常建议使用长连接或数据库连接池(如 Druid、HikariCP) 。
- 潜在问题:如果全部使用长连接,MySQL 的内存占用可能暴涨 。因为 MySQL 在执行过程中临时使用的内部内存是管理在连接对象里面的,这些资源只有在连接断开时才会彻底释放 。长连接累积过多可能导致系统触发 OOM(内存溢出)从而被强行杀掉,导致 MySQL 异常重启 。
- 解决办法:要么程序定期断开长连接并重连 ;要么在 MySQL 5.7+ 版本中,在执行完大查询后在代码中调用
mysql_reset_connection来重新初始化连接资源(该操作不需要重新握手和鉴权,但能把连接恢复到最初创建时的清爽状态) 。
- TCP三次握手:客户端发起连接命令后(例如:
3.查询缓存
- 定义:MySQL 内部为了加速查询而设计的一块内存 K-V 缓存结构 。
- 详细执行过程:
- 工作原理:当连接器把 SQL 放行后,如果数据库开启了查询缓存(MySQL 5.7 及以下版本) ,MySQL 会先拿这条 SQL 去缓存中碰碰运气 。
- 查询缓存是以 Key-Value(键值对) 的形式直接缓存在内存中 。Key 是整条 SQL 查询语句的字符串,Value 是对应的查询结果集 。如果当前输入的 SQL 字符串与缓存中的 Key 完全一致(哪怕多一个空格或大小写不同都会不匹配),MySQL 就会直接把 Value 结果返回给客户端,不再执行后续任何复杂的解析、优化与磁盘 I/O,效率极高 。
- 为什么建议关闭,甚至在 8.0 被彻底删除?
- 因为查询缓存的失效极其频繁,往往弊大于利 。在 MySQL 的设计中,只要一个表发生了一次更新(INSERT/UPDATE/DELETE),这个表上所有的查询缓存都会被在一瞬间全部清空 。
- 对于一个写压力稍微大一点的数据库,缓存刚放进去,表一更新就没了,导致命中率低得可怜,反而白白浪费了维护缓存的 CPU 算力 。
- 方案 :在 5.7 中,可以通过设置
query_cache_type = 2 (DEMAND)设为按需缓存 ,只有带SELECT SQL_CACHE * FROM ...的特殊语句才会被缓存 。而在 MySQL 8.0 版本中,官方索性直接剥离删除了整个查询缓存功能 。
4. 分析器
- 定义:当缓存未命中时,负责分析输入的 SQL 语句到底想要干什么,以及写得合不合法 。
- 详细执行过程:
分析器的工作主要拆分为两个核心子阶段:- 词法分析:
- MySQL 拿到的是一长串无意义的底层文本字符串,分析器首先要把这些字符串切碎,识别出里面的关键字 。
- 它会把
"select"识别出来代表"这是一条查询语句",把"user"识别成"表名 user",把"id"识别成"列名 id" - 底层细节 :词法分析阶段需要从系统元数据表
information_schema里面获得该表的完整结构信息,以此来对应和提取关键字 。
- 语法分析:
- 根据词法分析提取出来的各个词条,语法分析器会根据预设的 MySQL 语法规则树,来检查你这一行 SQL 的拼写和语序是否满足规范 。
- 如果你把
select错拼成了elect,语法分析就会罢工,直接向你抛出语法错误:ERROR 1064 (42000): You have an error in your SQL syntax。在这个错误提示中,你要特别关注 "use near" 后面的字符串,它通常精准标记了第一个出现语法错误的位置 。
- 词法分析:
5. 优化器
- 定义:MySQL 的"诸葛亮",负责在基于同一个查询语句的多个可行方案中,找出一条效率最高的执行路径 。
- 详细执行过程:
- 通过了分析器的体检后,SQL 语句格式合法了,但一条 SQL 在数据库里往往可以有多种逻辑等价的执行方式 。
- 化器的底层逻辑(CBO):MySQL 优化器采用了基于成本的优化模型(Cost-Based Optimizer)。它会结合索引统计信息、预估扫描行数、表大小等数据,算出一个"执行成本值",然后选择那个它认为执行成本最低、效率最高的方案 。
- 优化完成后,它会最终输出一份确定的执行计划(我们可以用
EXPLAIN前缀来查看这份计划) ,并将执行计划正式递交给执行器 。
6. 执行器
- 定义:真正的"大总管",负责按照优化器的方案去指挥、操作底层存储引擎,并收集返回结果 。
- 详细执行过程:
- 最终权限验证
- 在开始执行的这一刹那,执行器必须首先检查你对
user这张表到底有没有SELECT的查询权限 。如果没有,直接打回并报错ERROR 1142 (42000): SELECT command denied... - 为什么不在分析器就顺便把权限查干净? 因为有些 SQL 在运行期间会触发触发器(Trigger)或者复杂的存储过程,在字面语法解析时是无法预知运行时到底会关联和操作哪些隐藏表的 。所以,虽然语法分析时会有初步的预检查(Precheck) ,但最终的生死大权依然卡在执行器刚开始的这一步 。
- 在开始执行的这一刹那,执行器必须首先检查你对
- 逐行调用引擎接口:
- 如果通过了权限验证,执行器会根据优化器给的计划,去打开表,并一行行调用存储引擎开放的读写接口 。
- 以
SELECT * FROM user WHERE id = 10;为例(假设id是主键索引) :- 执行器调用引擎接口:"帮我查找
id=10的这行记录" 。 - 存储引擎层(如 InnoDB)收到指令,在其内部的 B+ 树索引结构中进行树搜索 。如果这行数据所在的数据页已经在内存(Buffer Pool)中了,就直接返回给执行器 ;如果在磁盘上,引擎负责将其从磁盘读入内存,再返回给执行器 。
- 如果是没有索引的普通条件遍历查询,执行器会循环调用"取第一行" -> "满足条件则存入结果集" -> "取下一行"的逻辑,直到引擎返回"读到表尾"的信号 。
- 执行器调用引擎接口:"帮我查找
- 结果集返回:执行器将遍历过程中从引擎那里捞出来的、所有满足条件的行记录组合成一个完整的结果集,最终通过网络交互源源不断地吐给客户端 。到这里,一条查询 SQL 的光荣使命正式宣告结束 。
- 最终权限验证
7. 存储引擎层
- 定义:MySQL 的"基建工人",负责数据的实际存储、索引构建和数据提取,提供标准的读写接口 。
- 详细执行过程:
- 插件化设计:MySQL 的存储引擎是高度模块化、插件式的 。也就是说,上层的连接器、分析器、优化器、执行器是所有人共享的公共 Server 层 ;而底层具体数据怎么在磁盘落盘、怎么建索引,可以根据表的不同需求选择不同的引擎 。
- InnoDB 引擎(默认):从 MySQL 5.5.5 版本开始,InnoDB 成为了系统的默认存储引擎 。它的底层极度复杂且强大,支持完整的 ACID 事务属性、行级锁定(并发能力高)和外键约束 。
- 引擎日志配合:InnoDB 内部维护了自己的两套核心日志:
redo log(重做日志,用来提供 Crash-safe 崩溃恢复能力,保证数据不丢失)和undo log(撤销日志,用来实现事务回滚和 MVCC 多版本并发控制) ,与上层 Server 层的统一归档日志binlog相互配合,保障了数据的绝对安全 。
总结:
palintext
[客户端] 发起请求
↓
[连接器] TCP握手 -> 账号密码认证 -> 缓存权限快照 -> 监控连接超时
↓
[查询缓存] (若8.0以下且开启) -> 命中则直接返回 ❌ (未命中/已关闭/8.0环境)
↓
[分析器] 词法分析 (拆词、对表结构) -> 语法分析 (建语法树、查错拼拼写)
↓
[优化器] CBO成本模型算法 -> 选出最优索引 -> 决定多表Join顺序 -> 生成执行计划
↓
[执行器] 运行时权限校验 -> 循环调用存储引擎层读写接口
↓
[存储引擎] (InnoDB) -> 查BufferPool内存/捞磁盘数据页 -> 返回满足条件的行
↓
[执行器] 组装结果集 -> 回传给客户端结束结语
从客户端发起请求到存储引擎返回数据,SQL的每一步都暗藏玄机。掌握这些底层机制,你不仅能精准定位性能瓶颈,更能在优化SQL时有的放矢,真正做数据库的主人。有关MySQL的一条SQL更新操作是如何执行的见我的这一篇文章继续学习。