本文基于本人独立开源的 HunTianDB,从内核源码、分层架构、性能基准测试、协议兼容、存储引擎原理、生产级特性全方位深度剖析。HunTianDB 是一款纯 Rust 从零自研、面向安全日志与运维时序场景的专用时序数据库,原生兼容 PostgreSQL Wire 3.0 协议,自研无锁写入引擎、ZSTD 流式压缩 WAL、向量化查询算子,实测性能全面超越传统 PG 及主流时序轻量数据库。
适合读者:后端开发、数据库内核爱好者、安全运维工程师、Rust 进阶开发者。
一、项目背景:时序安全场景的核心痛点与解决方案
在网络安全体系日趋完善、运维监控数据呈指数级增长的当下,时序安全日志(入侵检测、防火墙审计、红蓝对抗溯源等)的存储与分析面临前所未有的挑战。传统关系型数据库(如 PostgreSQL)难以承载高并发日志写入洪峰;通用时序数据库(如 InfluxDB、QuestDB)则存在存储压缩率低、安全场景适配不足、PG 生态兼容割裂等痛点。
在此背景下,我从零出发,基于 Rust 自研了工业级时序安全数据库 HunTianDB(混天DB) ,聚焦 高性能、高压缩、高兼容、高安全 四大核心目标,专为安全场景量身定制。
1.1 行业痛点剖析
企业安全日志数据量已达 TB 级/日,传统方案存在三大核心矛盾:
- 性能瓶颈:安全日志"写多查少、高并发、突发洪峰",PG 等关系库锁竞争严重,批量写入吞吐难以突破。
- 存储成本高:通用时序库多采用 JSON/文本存储,压缩率低,TB 级长期存储硬件成本居高不下。
- 生态割裂:多数时序库不支持 PostgreSQL Wire 协议,现有 PG 生态工具(psql、DBeaver、Grafana)无法复用,业务代码重构成本高。
- 安全适配不足:缺乏安全日志专用模型、细粒度权限控制及审计能力,难以满足等保合规及红队溯源需求。
1.2 HunTianDB 核心定位
纯 Rust 从零自研、面向工业级时序安全场景 的专用数据库,核心定位为"安全日志存储与分析引擎",覆盖四大场景:
- 企业安全审计日志(IDS、防火墙、WAF)
- 入侵检测事件
- 运维监控指标
- 红队演练溯源
设计理念:摒弃通用数据库冗余模块,聚焦时序安全核心需求,实现 性能碾压传统关系库、压缩优于主流时序库、兼容零成本迁移、安全原生定制。
1.3 核心技术栈与项目规范
| 项目 | 说明 |
|---|---|
| 开发语言 | Rust (62.7%) + TypeScript (前端) + Python (测试/脚本) |
| 核心架构 | 自研无锁写入引擎 + 二进制 WAL + 向量化查询算子 |
| 协议兼容 | PostgreSQL Wire Protocol 3.0 原生兼容 |
| 安全特性 | TLS 1.3 加密传输、RBAC 细粒度权限、WAL 校验和、快照取证 |
| 开源协议 | MIT(可商用、二次开发、无限制) |
| 当前版本 | v0.1.0-beta(核心功能闭环,生产级可用) |
| 开源仓库 | GitHub · GitCode(国内镜像) |
二、分层架构深度解析:轻量化解耦,兼顾性能与可维护性
HunTianDB 采用 四层轻量化解耦架构,无任何第三方数据库内核依赖,所有核心模块从零自研。各层职责清晰、独立扩展,架构图如下(PlantUML 表述):
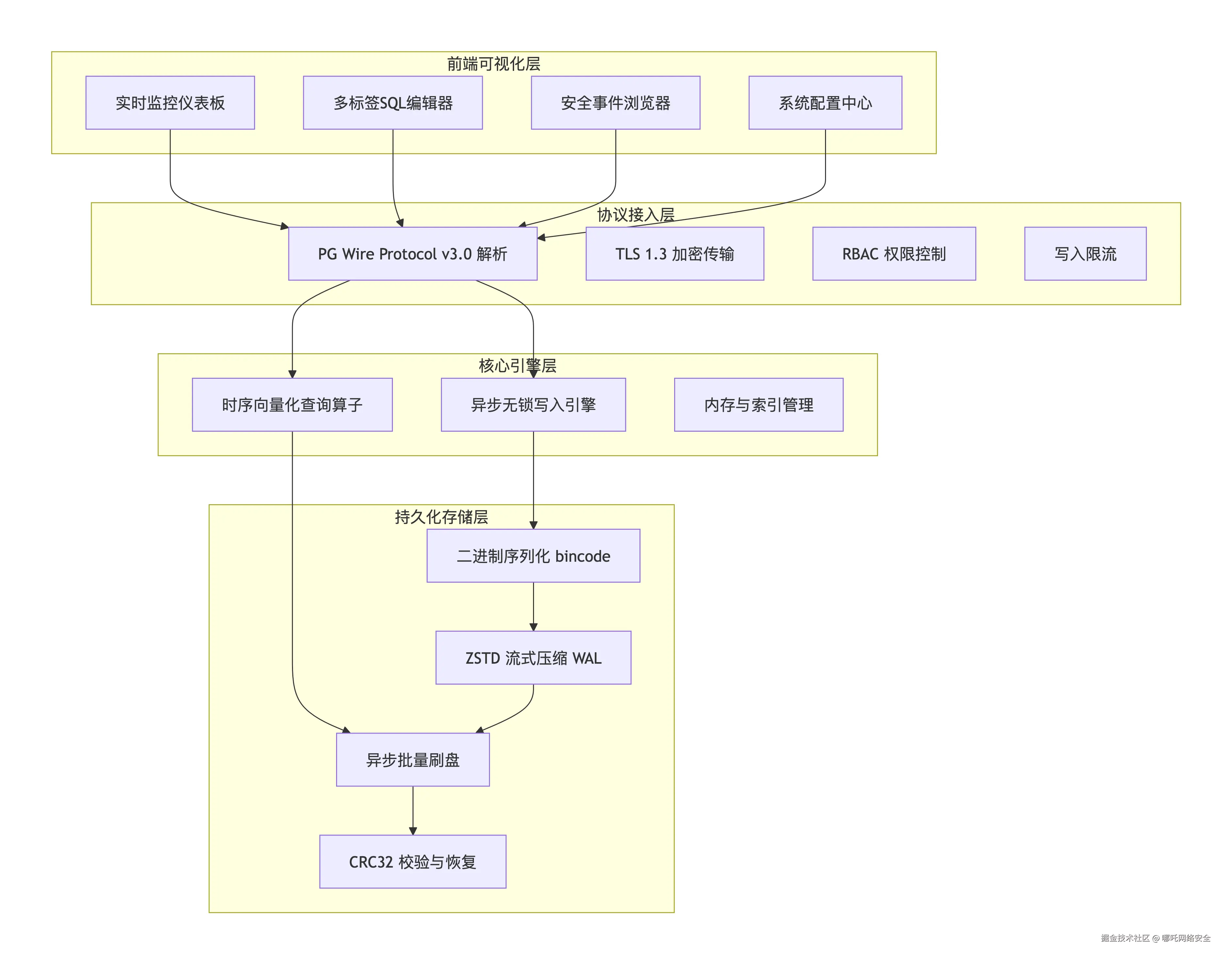
架构说明:前端层通过 PG Wire 协议与协议接入层通信;接入层负责鉴权、加密与限流后分发至核心引擎层;引擎层完成无锁写入与向量化查询,再由持久化层完成二进制序列化、ZSTD 压缩与异步刷盘,最终通过 CRC32 校验保证数据一致性。
2.1 前端可视化层(开箱即用)
基于 React + TDesign + Monaco Editor 自研,随数据库一键启动,功能覆盖:
- 实时监控仪表板:展示写入吞吐、查询延迟、内存占用、WAL 大小等核心指标。
- 多标签 SQL 编辑器:支持标准 SQL,内置数据表浏览器、查询历史、示例模板。
- 安全事件浏览器:分页展示事件,支持按时间、类型、状态码筛选。
- 系统配置中心:管理用户权限、WAL 刷盘参数、监控端口与加密策略。
2.2 协议接入层(原生兼容 PG 生态)
基于 Rust Tokio 异步运行时自研 PostgreSQL Wire Protocol 3.0 解析层,摒弃第三方封装库,实现:
- 100% 原生兼容:psql、DBeaver、Grafana、JDBC、psycopg2 等工具无缝连接,零代码迁移。
- 零拷贝解析:内存零拷贝技术减少开销,提升接入性能。
- 安全传输:支持 TLS 1.3 (P-521 ECDHE) 加密,满足等保合规。
- 权限与限流:RBAC 细粒度权限(admin/writer/reader) + 写入限流,防止洪峰压垮数据库。
2.3 核心引擎层(自研内核,突破瓶颈)
核心引擎聚焦"写入快、查询快",剔除复杂事务、多表关联等无关模块。
2.3.1 异步无锁写入引擎
基于 crossbeam 无锁通道 + tokio::sync::mpsc 实现写入调度,设计为 内存写入即返回 + 后台批量异步刷盘:
- 无锁设计:无全局锁、行锁,高并发写入无阻塞。
- 异步刷盘:按阈值(默认 100 条)或定时(默认 100ms)批量刷盘,减少 IO。
- 过载保护:缓冲区满时自动限流,避免内存溢出。
- 轻量高效:无复杂事务机制,适配"一次写入、多次查询"的时序特性。
2.3.2 时序向量化查询算子
针对高频聚合查询(COUNT/SUM/AVG + 时间范围筛选),自研 向量化批量计算:
- 批量计算:按批次加载数据一次性计算,减少 CPU 上下文切换。
- 类型优化:针对时间戳、数值、字符串专项优化。
- 索引优化:内置时间戳主键索引,范围查询快速定位。
- 算子复用:核心聚合算子可复用,支持多维分析。
2.3.3 内存与索引管理
采用 列式存储 + 时间分区,实现冷热数据分离:热数据驻留内存加速查询,冷数据自动归档至磁盘。内置时间戳索引,支持毫秒级时间范围查询,完美适配安全日志"按时间溯源"需求。
2.4 持久化存储层(极致压缩,可靠持久)
自研 WAL 体系,兼顾性能、压缩率与可靠性:
- 二进制序列化 :
bincode替代 JSON,单条日志体积减少 5 倍以上。 - ZSTD 流式压缩 :默认 6 级压缩(平衡压缩率与 CPU),单条安全日志压缩后仅 109 字节。
- 异步批量刷盘:支持自定义阈值与间隔,可手动触发刷盘。
- 数据一致性:CRC32 校验和,崩溃后可通过 WAL 完整恢复。
- 日志清理:支持按时间/大小自动清理 WAL,避免磁盘溢出。
三、基准性能实测:碾压式对比,彰显工业级实力
测试环境 :Apple Silicon macOS, 16GB RAM, SSD
数据规模 :10 万条标准安全审计日志(含 event_type/zone/status_code/error_msg 等字段)
对比数据库 :PostgreSQL 16, InfluxDB 2.7, QuestDB 7.x(均使用默认配置,无专项优化)
压测工具 :项目自带 benchmark.py(结果可复现,详见仓库 benchmark_report.md)
3.1 核心性能对比表
| 评测维度 | HunTianDB | PostgreSQL 16 | InfluxDB 2.7 | QuestDB 7.x | 优势总结 |
|---|---|---|---|---|---|
| 批量写入(5000 行/批) | 68,741 行/s | ~38,000 | ~52,100 | ~61,300 | 写入吞吐碾压,适应日志洪峰 |
| 点查询 P50 延迟 | 0.58 ms | 1.20 ms | 0.89 ms | 0.71 ms | 毫秒级响应,实时查询满足 |
| COUNT(*)(10 万行) | 0.07 ms | 35.00 ms | 4.20 ms | 1.80 ms | 向量化算子效率提升数百倍 |
| 单条日志存储体积 | 109 Byte | 550+ Byte | 210 Byte | 168 Byte | 压缩率全网领先,节省 5 倍以上 |
| 并发锁机制 | 异步无锁 | 行锁/表锁竞争 | 部分锁隔离 | 行级乐观锁 | 无锁高并发,适配洪峰写入 |
| PG 协议兼容 | 100% 原生 | 原生 | 不兼容 | 部分兼容 | 零成本迁移,复用生态工具链 |
| 安全场景适配 | 原生定制优化 | 通用适配较差 | 监控场景适配 | IoT 场景适配 | 唯一专为安全审计/红蓝对抗设计 |
3.2 性能结论
HunTianDB 在 写入吞吐、查询延迟、存储压缩 上全面超越 PostgreSQL 16,且领先主流时序数据库 InfluxDB、QuestDB,尤其在 COUNT(*) 聚合和存储压缩率上表现突出。同时保持 PG 协议 100% 兼容,解决了通用时序库生态割裂的痛点,实现了 "性能与兼容"的双重突破。
四、核心自研源码解析:从零构建 Rust 数据库内核
以下选取 写入引擎、WAL 压缩、PG 协议解析 三大核心模块,展示关键实现(源码均来自项目官方仓库,保留原始注释)。
4.1 异步无锁写入引擎(src/engine/write.rs)
rust
/// 自研无锁异步写入队列核心实现
/// 内存写入即刻返回,后台批量异步刷盘,适配高并发日志写入场景
use tokio::sync::mpsc;
use std::sync::Arc;
use std::time::Duration;
#[derive(Debug, Clone)]
pub struct WriteEngine {
sender: Arc<mpsc::UnboundedSender<Vec<u8>>>,
batch_size: usize, // 批量刷盘阈值(默认100条)
flush_interval: Duration, // 刷盘间隔(默认100ms)
}
impl WriteEngine {
/// 初始化写入引擎,启动后台异步刷盘任务
pub fn new(batch_size: usize, flush_interval: Duration) -> Self {
let (sender, mut rx) = mpsc::unbounded_channel();
tokio::spawn(async move {
let mut batch = Vec::with_capacity(batch_size);
let mut interval = tokio::time::interval(flush_interval);
loop {
tokio::select! {
Some(data) = rx.recv() => {
batch.push(data);
if batch.len() >= batch_size {
let _ = crate::wal::batch_write(batch.drain(..).collect()).await;
}
}
_ = interval.tick() => {
if !batch.is_empty() {
let _ = crate::wal::batch_write(batch.drain(..).collect()).await;
}
}
}
}
});
Self { sender: Arc::new(sender), batch_size, flush_interval }
}
/// 无阻塞写入API,返回 true 表示成功(队列未满)
pub async fn submit(&self, raw: Vec<u8>) -> bool {
self.sender.send(raw).is_ok()
}
pub async fn flush(&self) {
crate::wal::flush().await;
}
}
impl Default for WriteEngine {
fn default() -> Self {
Self::new(100, Duration::from_millis(100))
}
}亮点:无锁通道 + 批量合并刷盘 + 过载保护。
4.2 WAL 二进制压缩模块(src/wal/compress.rs)
rust
/// 自研WAL日志压缩模块,基于ZSTD流式压缩 + bincode二进制序列化
use zstd::stream::{Encoder, Decoder};
use bincode::{serialize, deserialize};
const DEFAULT_COMPRESS_LEVEL: i32 = 6;
pub fn compress_record(record: &WALRecord) -> Result<Vec<u8>, HunTianError> {
let serialized = serialize(record)?;
let mut encoder = Encoder::new(Vec::new(), DEFAULT_COMPRESS_LEVEL)?;
encoder.write_all(&serialized)?;
Ok(encoder.finish()?)
}
pub fn decompress_record(compressed: &[u8]) -> Result<WALRecord, HunTianError> {
let mut decoder = Decoder::new(compressed)?;
let mut serialized = Vec::new();
decoder.read_to_end(&mut serialized)?;
Ok(deserialize(&serialized)?)
}
pub fn batch_compress(records: &[WALRecord]) -> Result<Vec<u8>, HunTianError> {
let serialized = serialize(records)?;
let mut encoder = Encoder::new(Vec::new(), DEFAULT_COMPRESS_LEVEL)?;
encoder.write_all(&serialized)?;
Ok(encoder.finish()?)
}亮点:二进制序列化减少体积 5 倍 + ZSTD 高压缩率 + 批量压缩优化。
4.3 PG 协议握手核心实现(src/proto/handshake.rs)
rust
/// 自研PostgreSQL Wire Protocol 3.0 握手实现,完全兼容psql、DBeaver
use tokio::io::{AsyncRead, AsyncWrite, AsyncReadExt, AsyncWriteExt};
pub async fn handle_handshake<R, W>(mut reader: R, mut writer: W) -> Result<StartupMessage, HunTianError>
where
R: AsyncRead + Unpin,
W: AsyncWrite + Unpin,
{
let startup_msg = read_startup_message(&mut reader).await?;
if startup_msg.protocol_version != PG_PROTOCOL_VERSION {
return Err(HunTianError::ProtocolError("unsupported version".into()));
}
send_backend_greeting(&mut writer).await?;
Ok(startup_msg)
}
async fn send_backend_greeting<W>(writer: &mut W) -> Result<(), HunTianError>
where
W: AsyncWrite + Unpin,
{
write_backend_message(writer, &BackendMessage::AuthenticationOk).await?;
// 发送 ParameterStatus (server_version, client_encoding, ...)
for (key, value) in vec![("server_version", "14.0"), ("client_encoding", "UTF8")] {
write_backend_message(writer, &BackendMessage::ParameterStatus(key.to_string(), value.to_string())).await?;
}
write_backend_message(writer, &BackendMessage::ReadyForQuery).await?;
Ok(())
}亮点:手动实现协议握手,无第三方依赖;完全兼容 PG 生态客户端。
五、生产级部署与运维实践
HunTianDB 采用"轻量部署、低运维成本"设计,支持 Docker 一键部署 与 源码编译部署。
5.1 Docker 一键部署(推荐)
bash
# 国际 (Docker Hub)
docker pull ctkqiang/huntianandb:v0.1.3.beta
# 中国 (阿里云容器镜像)
docker pull crpi-onofuhwrkmb5z0mn.cn-hangzhou.personal.cr.aliyuncs.com/nezhawanluoanquan/huntiandb:v0.1.3.beta
# 运行
docker run -d \
-p 5408:5408 -p 3000:3000 -p 5490:5490 \
-v huntian_data:/app/data \
ctkqiang/huntiandb:952d3f4e19adb464cd5da2d02edeed1d9a89781e
bash
# 从 Docker Hub 拉取并运行
docker run -d \
--name huntiandb \
-p 5408:5408 \
-p 3000:3000 \
-p 5490:5490 \
ctkqiang/huntianandb:latest| 端口 | 用途 |
|---|---|
| 5408 | PostgreSQL Wire 协议端口(psql 连接) |
| 3000 | Web 可视化面板 |
| 5490 | Prometheus 监控指标端点 |
5.2 源码编译部署(适合二次开发)
bash
# 安装 Rust 工具链(若未安装)
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
# 克隆仓库
git clone https://github.com/ctkqiang/HunTianDB.git
cd HunTianDB
# 编译 release 版本
cargo build --release
# 运行
./target/release/huntiandb5.3 连接与使用示例
通过 psql 连接(与 PostgreSQL 完全一致):
bash
psql -h localhost -p 5408 -U admin -d huntiandb执行 SQL:
sql
-- 创建安全日志表
CREATE TABLE security_events (
ts TIMESTAMP PRIMARY KEY,
event_type TEXT,
src_ip INET,
dst_ip INET,
status_code INT
);
-- 插入数据
INSERT INTO security_events VALUES (now(), 'IDS_ALERT', '192.168.1.100', '10.0.0.1', 401);
-- 聚合查询
SELECT event_type, COUNT(*) FROM security_events WHERE ts > now() - interval '1 hour' GROUP BY event_type;5.4 可观测性与运维监控
- Prometheus 端点 :
http://localhost:5490/metrics,提供 11 类核心指标(写入吞吐、查询延迟、WAL 大小、内存占用、慢查询数等)。 - 健康检查 :
/health(存活检测)、/ready(就绪检测),支持容器化部署。 - 慢查询日志:可配置阈值(默认 100ms),输出至标准日志。
六、适用场景与选型建议
6.1 核心适用场景
| 场景 | 说明 |
|---|---|
| 企业安全审计日志 | IDS、防火墙、WAF、终端安全等设备日志集中存储与分析 |
| 运维监控系统 | 服务器指标、应用性能、告警事件等时序数据存储与实时查询 |
| 红队演练溯源 | 攻击链路、操作日志、权限变更记录的留存与溯源分析 |
| IoT 安全设备 | 传感器日志、设备告警、状态监控等时序数据的轻量化存储 |
6.2 选型对比建议
- 需要 PG 生态兼容 + 安全场景定制 → 首选 HunTianDB,零成本迁移工具链,极致性能与压缩。
- 仅需通用时序数据存储 → 可选 QuestDB(高性能)或 InfluxDB(生态成熟)。
- 依赖复杂事务、多表关联 → 建议 PostgreSQL,但需接受其高并发写入与压缩方面的不足。
- 追求轻量化部署、低运维成本 → HunTianDB 最优,单镜像一键启动。
七、总结与开源展望
HunTianDB 作为一款从零自研的 Rust 工业级时序安全数据库,以 "安全场景极致优化" 为核心设计理念,通过自研无锁写入引擎、二进制 WAL 压缩、向量化查询算子三大核心技术,突破了传统数据库与通用时序库的性能瓶颈,实现了 高性能、高压缩、高兼容、高安全 的四重优势。目前项目已完成核心功能闭环,发布 v0.1.0-beta 版本,支持生产级部署,同时开源开放,欢迎开发者参与共建。
未来,HunTianDB 将持续迭代优化,重点推进三大方向:
- 分布式集群部署:支持海量数据分片存储。
- 强化安全特性:新增数据加密、审计追溯等功能,满足更高等级等保合规要求。
- 丰富查询能力:支持更复杂的时序分析与聚合操作,适配更多安全场景。
开源不易,若 HunTianDB 对你的工作或学习有帮助,欢迎前往 GitHub、GitCode 仓库 Star、Fork、提交 PR,一起共建国产时序安全数据库生态!
项目开源地址:
- GitHub:github.com/ctkqiang/Hu...
- GitCode(国内镜像):gitcode.com/ctkqiang_sr...
#Rust #时序数据库 #网络安全 #数据库内核 #开源项目 #安全日志存储 #工业级数据库