Harness 到底指什么
一、Harness 的定义
业界几个权威定义
"Harness Engineering" 这个说法 2026 年走红,但 "harness" 这个词被用得越来越泛。先把几个一手出处摆出来,再说我的理解。
OpenAI 在 Harness engineering: leveraging Codex in an agent-first world(2026-02,Ryan Lopopolo)把 harness 定义为:
"the full environment of scaffolding, constraints, and feedback loops that surrounds the agent."
OpenAI 这套口径里,Codex harness 就是 codex-core 这个 Rust 共享库------agent loop、thread lifecycle、config / auth、sandboxed tool execution 都在里面。UI 外壳(VS Code 插件、CLI)不算 harness。
Anthropic 在 Building agents with the Claude Agent SDK 说:
"the agent harness that powers Claude Code (the Claude Code SDK) can power many other types of agents, too."
2025-11 那篇 Effective harnesses for long-running agents 把 harness 当作一个独立的工程对象讨论:context compaction、structured handoff、tool sandboxing 都被列为 harness 的关键设计。
Simon Willison 在 How coding agents work 用得最宽:
"A coding agent is a piece of software that acts as a harness for an LLM, extending that LLM with additional capabilities that are powered by invisible prompts and implemented as callable tools."
他把整个 Claude Code、Cursor、Codex CLI 一起算 harness,包括 UI 外壳。
LangChain 那篇 The Anatomy of an Agent Harness 提出公式:
"Agent = Model + Harness."
模型是引擎,harness 是把引擎包装成能持续工作的载具。
这几个定义的重合点 很清楚:harness 是模型外的那一层运行时机制------scaffolding、约束、反馈循环、工具调用、上下文与记忆管理、agent loop。差异在范围:OpenAI 把 harness 收得最紧(只算 SDK / core),Simon 用得最宽(含 UI surface),Anthropic 在两者之间。
我的理解
本文采用偏 OpenAI 派的狭义口径,做以下一句话定义:
Harness 是 Coding Agent 平台层------上下文管理、记忆、subagent 编排、skill 机制、工具调用、hook、运行闭环------这一层。业务工程建在它之上,不应去改它。
为什么用狭义?因为这篇要讨论的边界问题------"什么是 harness、什么是业务工程"------只有在狭义口径下才说得清。如果把整个 CLI 都算 harness,业务工程的边界就跑到 CLI 外面去了,没什么好讨论的;反过来如果 harness 只算 LLM 调用接口,那 context / memory / tool 全成了业务工程的事,又把工程纪律全部下放给业务方,这也不现实。折中点就是:Coding Agent 的 SDK / core 这一层。
SDD ≠ Harness Engineering,Spec ≠ Harness
这两组概念经常被混在一起,但定位完全不同。
SDD(Spec-Driven Development) 由 OpenAI 的 Sean Grove 在 The New Code 等场合推广,关注的是业务侧的工程范式 :用 spec 而不是直接 code 作为人和 AI 协作的主要产物------需求 spec、设计 spec、验收 spec 一路串下来,code 是 spec 的派生物。SDD 谈的是 what to build。
Harness Engineering 由 OpenAI 的 Ryan Lopopolo 在 2026-02 那篇博文正式命名,关注的是 agent 平台层的工程范式 :怎么设计 context compaction、怎么管 agent loop、怎么做 sandbox、怎么在长会话里保持稳定。Harness Engineering 谈的是 how the agent runs。
两者关系:SDD 是上层范式,Harness Engineering 是下层范式。SDD 关心"业务交付要写什么 spec",Harness Engineering 关心"Coding Agent 要怎么稳定地执行这些 spec"。没有 harness,spec 跑不起来;没有 spec,harness 跑得再稳也只是空转。
Spec 和 Harness 也是两回事 。Spec 是业务工程的产物------工作流主干、阶段契约、原子工具、领域知识,这些业务自己写的东西都是 spec 的不同形态。Harness 是 spec 跑起来所依赖的平台。两者关系是"业务的 spec 调用 harness 的能力",不是 "spec 是 harness 的一部分",也不是 "harness 是 spec 的一种"。
把这两层混在一起,"什么是业务该做的、什么是平台该做的"就再也说不清楚。
二、Harness 是 Coding Agent 平台层
我现在用的是 Claude Code 和 Codex。这两者在工程视角上差别不大:本地 CLI 入口 + 远端模型 + 一套让模型可控完成任务的运行时机制。这套运行时机制就是 harness。
下面 7 项是我以 Claude Code / Claude Agent SDK 为主要参照系归纳的。"skill" 和 "hook" 是 Claude 生态的命名,Codex 一侧对应概念叫 "permissions / sandbox / agent loop hooks",本质相同,叫法不同。这 7 项不是官方分法,是我从实际编排经验里整理出来的,能解释大多数会遇到的 agent 行为。
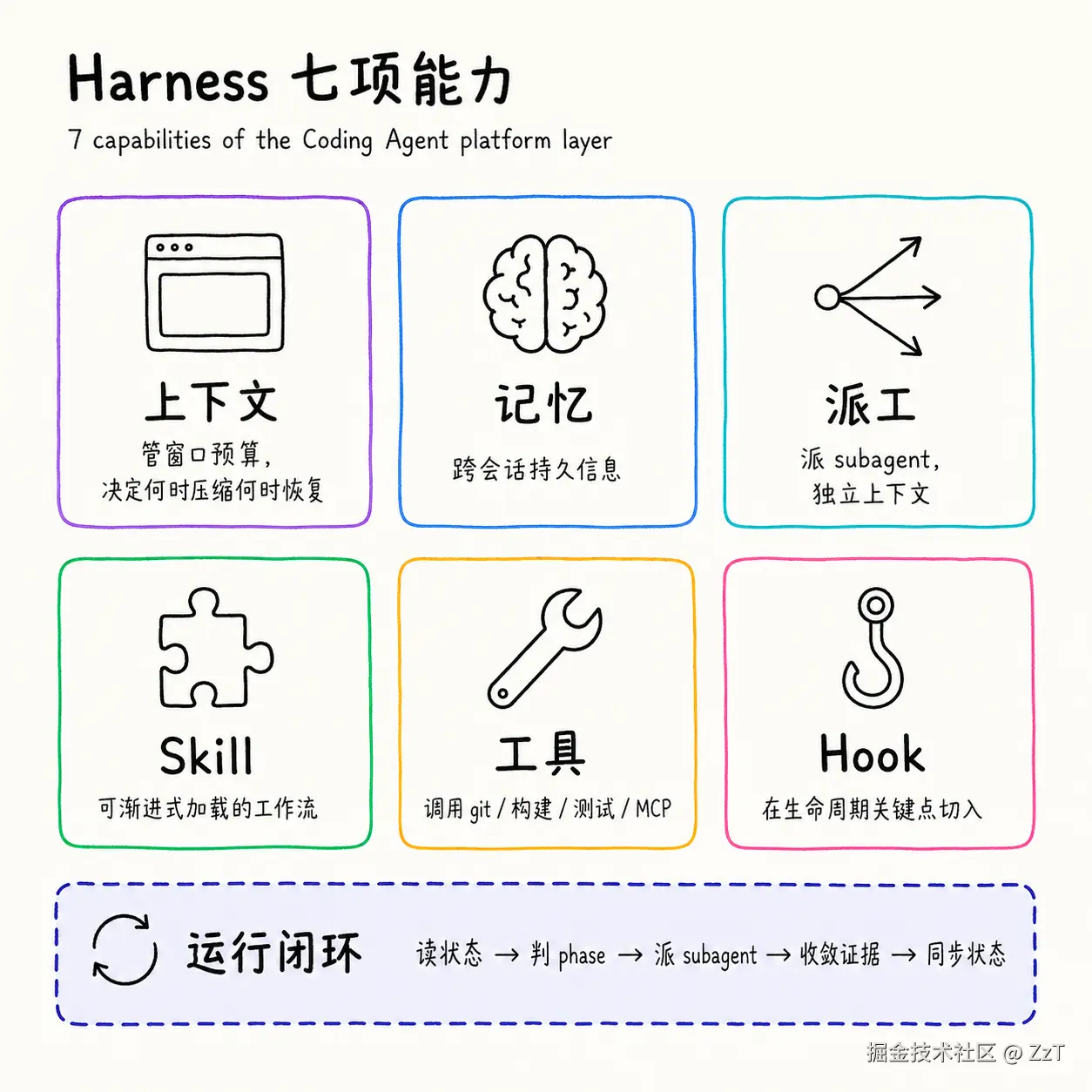
1. 窗口上下文管理。 决定哪些信息进入当前对话窗口,什么时候压缩、什么时候截断、什么时候恢复历史现场。当一个 run 跨越多个阶段,harness 负责把过期的细节挪走,把当前阶段需要看的事实留下。模型本身只看到当前窗口,看不到背后的取舍。
2. 记忆管理。 跨 run 的持久信息:项目规则、用户偏好、可复盘证据。CLAUDE.md、AGENTS.md、.inbox、run state 这些都属于记忆基础设施。harness 决定什么时候把它们注入窗口,业务工程决定它们里面写什么。
3. spawn subagent。 入口 agent 不亲自做具体活,它把任务拆给独立上下文的 subagent,自己只做编排、收敛证据、关门。这件事很关键:subagent 是 harness 提供的原语,业务工程只能"派",不能去重新发明派工机制。
4. Skill 机制。 Claude Code 的 skill、Codex 的 plugin / preset,本质都是同一个东西------一个带触发条件、输入约束、输出契约和风险标记的可装载行为单元。harness 决定一个 skill 怎么被发现、怎么被加载、怎么被组合,业务工程决定一个 skill 里写什么。
5. 工具调用。 git、worktree、shell、构建命令、测试命令、MCP server、第三方 SaaS------所有副作用都通过工具调用发生。harness 负责协议层(怎么注册、怎么调度、超时怎么处理、输出怎么截断),业务工程负责"哪些工具该被注册进来"。
6. Hook 机制。 SessionStart、Stop、PreCompact、PostCompact 这些钩子是 harness 给业务留的"在生命周期关键点切入"的口子。注入 .inbox、在结束前做工作流闭环检查、在压缩前保留关键证据------这些都靠 hook。
7. 运行闭环。 这是把前六项串起来的元能力:读状态 → 判断阶段 → 派 subagent → 收敛证据 → 同步状态 → 决定继续或阻塞。一个成熟的 harness 会保证这个闭环永远是收敛的,不会出现"做完一半 silently 走开"的情况。
这七项的共同点是:它们都是 Coding Agent 团队(Anthropic / OpenAI)已经在不断打磨的事情,不是你做业务该去重写的事情。 你的项目可以决定怎么"用"这些能力,但不应该绕过它们去自己实现一份。
三、业务工程是什么:一组建在 harness 之上的 spec
回到第一节那条线索:业务工程的产物,本质上是一组 spec------可执行的、可派发给 agent 的工程契约。Spec 跑起来靠 harness;harness 跑什么,靠 spec 写清楚。
这组 spec 在仓库里怎么分层、怎么组织、文件怎么放,值得单独一篇讲,这里不展开。本节只想抽象地说清楚:一套完整的业务 spec 通常要覆盖哪几类内容,或者说要回答以下几个问题。
这次交付从哪开始、走过哪些阶段、什么时候算结束? 这是工作流主干。它本身不"思考",只声明:当前在哪个阶段、下一步该派谁、卡在什么条件就停。整个项目通常只需要一份主干 spec,它是入口编排者,但本身不是 agent------真正"思考"的还是 harness 提供的 subagent。
每个阶段做什么、产出什么、什么时候放行? 这是阶段契约。每个阶段都有显式的输入、输出、放行条件、阻塞规则。阶段之间是声明式衔接,不互相偷跑------这是 SDD 跟传统 agent loop 在工程纪律上最大的差异。具体切几个阶段、怎么切,因项目而异。"需求分析 / 设计 / 实现 / 评审 / 测试 / 发布" 是常见骨架,但不是唯一组合。
阶段做事时会用到哪些原子能力? 这是工具箱:仓库扫描、证据抽取、构建命令、E2E 跑测、视觉 diff、任务系统对接......每一个原子能力只对自己的输入输出负责,不应该知道自己在哪个阶段被调用------这样才能被多个阶段复用而不绑死。
spec 在做判断时依靠什么背景? 这是领域知识:业务架构、踩坑禁区、参考实现。这一类内容不直接被 invoke,但所有其他 spec 都隐式依赖它来做"这是不是好设计""这有没有踩坑""reference 实现长什么样"的判断。
这四类内容加起来,定义了"业务工程在一个项目里要写些什么"。它们有几个共同特征:
- 全部是业务自己写的------它们是项目仓库的一部分,跟随项目演进。
- 全部通过 harness 暴露的原语跑起来------业务侧自己不实现 agent loop、不实现上下文管理、不实现 subagent 调度,这些都调 harness。
- 彼此通过引用关系组织------主干引用阶段、阶段引用工具、所有的都引用背景知识。
写到这里就能看清楚了:业务工程 = 写好这套 spec;harness = 让这套 spec 跑起来的运行时。 两者的关系是"调用与被调用",不是"修改与被修改"。
四、为什么不该去改 harness
我见过一些项目,遇到问题的第一反应是"我能不能改一下 Claude Code 的 ×× 机制":自己接管上下文压缩、自己做一套 subagent 调度、绕过 hook 写一个外挂注入器。这些想法都来自一个朴素的工程直觉:我有更具体的业务需求,平台默认行为不够好。
但绕过 harness 几乎都得不偿失,原因有三个。
第一,harness 本身一直在迭代。 Claude Code 这一年改了多少东西自己心里有数:上下文压缩策略、skill graph、subagent 隔离、hook 调用时机、工具结果瘦身......每一次升级你都白嫖,前提是你没在它上面打补丁。一旦打了补丁,每次升级都要重新评估兼容性,原本三秒升级变成三小时排查。
第二,harness 的复杂度远超直觉。 上下文管理这件事看着简单,实际涉及窗口预算、cache hit、压缩算法、信息保真度、跨 run 一致性。"我自己写一个简化版"听上去 200 行代码,跑起来发现一个 corner case 接一个 corner case。这是平台层和应用层永恒的不对称------你看到的是平台默认行为,看不到的是它绕过的几百种边界情况。
今天就碰到一个例子。有人在自己的项目里做了一套"记忆机制":仓库里维护一个 memory/ 目录,每次 agent 会话启动,hook 把 memory/ 里的所有文件全量注入上下文。表面上是"自建记忆系统",跑几次之后 context window 直接爆,跑到一半被截断,重要信息被挤出去。
这是典型的"乱改 harness"。
记忆管理本来就是 harness 的七项能力之一。Anthropic 那篇 Effective harnesses for long-running agents 花了整篇讲他们怎么做:进度文件结构化交接、compaction 策略、必要信息保留与冗余剔除,核心目标就是不让窗口爆。Claude Code 也提供了 CLAUDE.md、.inbox、run state 这些原语,注入有取舍:什么进窗口、什么压缩、什么截断、什么放外存延迟加载,都有规则。
memory/ 全量注入跳过了所有这些取舍,相当于把一个平台团队反复打磨过的能力,用一行 hook 简化成"管你窗口多大、全塞进来"。结果是 harness 已经帮你处理好的窗口预算问题,重新拽回到自己身上,还没有平台层那套压缩/恢复机制兜底。
同一件事,用 harness 的原语去做(往 CLAUDE.md 写项目规则、用 hook 在合适时机注入 .inbox、用 run state 跨 phase 同步必要事实),代价是几行配置;自己重写一份,代价是 context window 爆 + 失去平台升级红利 + 后续维护负担。专业的事情交给专业的人做,业务不该改 harness 的机制------这不是说教,是工程经济学。
第三,绕开 harness 你就不在 SDD 的轨道上了。 SDD 的工程纪律来自 harness 暴露的几个硬约束:subagent 不能跨上下文偷信息、阶段不能跨 gate 偷跑、tool 调用要落证据。一旦你为了某个业务需求绕开 harness,这些约束就一起塌掉了。短期看是绕开了一个限制,长期看是把整个工程纪律的地基拆了。
正确的做法是:遇到平台层不够好的地方,先想能不能在业务 spec 这一侧兜住。
再举一个正向例子。我做 sailor-harness 的时候,遇到过这样的场景:模型在跨阶段时偶尔会"想多走一步"------明明只该出需求证据,模型顺手就要去设计。最初的想法是"能不能 patch 一下 subagent 调度,强制它只做当前阶段的事"。后来意识到这件事其实在业务 spec 这一侧就能解决:在阶段契约里把当前阶段的边界写死,再加一个 gate 检查,subagent 该收口的时候用 hook 强行收敛。Harness 没动,行为就被约束住了。
这种"用业务工程兜住平台限制"的能力,是 SDD 工程师最该练的肌肉。
五、记住一句话
业务工程的工作 = 写好这套 spec,组合 harness 暴露的原语;不要去改 harness 本身。
这句话有两个含义。
往上看:把 harness 给你的原语用全。上下文管理、subagent、skill、hook、工具调用,这些是免费的"工程能力外挂",平台团队比你更懂怎么实现它们。
往下看:你的业务交付的差异化,体现在 spec 怎么写、怎么组合,而不是 harness 改得多深。两个团队做同类项目,spec 长得不一样,差异在于各自的阶段切分、原子工具选型、领域知识积累------而不是某一边自己魔改了 Claude Code 的内核。
这是我做 Harness Engineering 这段时间最强烈的一个直觉:克制是工程纪律的核心。 不改不该改的东西,省下来的力气全部投在该做的事上:把业务侧的 spec 写好、写准。
下一篇会展开讲两个相关问题:spec 到底要写些什么?skill 怎么分层? 把工作流主干、阶段契约、原子工具、领域知识各自该放在哪、彼此之间怎么引用,落到具体项目里的可执行结构上。
关于作者:某大厂研发,做 SDD / Harness Engineering 工程实践。本文是该系列的第一篇。