目录
[1.1 客户端](#1.1 客户端)
[1.2 服务端整体架构](#1.2 服务端整体架构)
[1.3 连接器](#1.3 连接器)
[1.4 查询缓存](#1.4 查询缓存)
[1.5 分析器](#1.5 分析器)
[1.6 优化器](#1.6 优化器)
[1.7 执行器](#1.7 执行器)
[4.1 undo log 回滚日志(InnoDB引擎独有)](#4.1 undo log 回滚日志(InnoDB引擎独有))
[4.2 redo log 重做日志(InnoDB引擎独有)](#4.2 redo log 重做日志(InnoDB引擎独有))
[4.3 binlog 二进制归档日志(Server层通用日志)](#4.3 binlog 二进制归档日志(Server层通用日志))
[6.1 设计目的](#6.1 设计目的)
[6.2 核心执行顺序](#6.2 核心执行顺序)
[6.3 宕机场景数据一致性验证](#6.3 宕机场景数据一致性验证)
[6.4 最终总结](#6.4 最终总结)
一、前置知识介绍
在全面理解MySQL架构前,我们需要熟悉客户端、服务端以及服务端内部五大核心组件:连接器、查询缓存、分析器、优化器、执行器。
1.1 客户端
Navicat、DataGrip、代码程序等都属于MySQL客户端,核心作用就是向MySQL服务端发送SQL执行请求。
1.2 服务端整体架构
MySQL服务端整体划分为Server层 和存储引擎层两大模块,采用插件式引擎设计。
- Server层
统一实现MySQL通用核心功能,是所有存储引擎共用层级,包含连接器、查询缓存、分析器、优化器、执行器,同时实现权限校验、SQL解析、语句优化、内置函数、存储过程、视图、触发器等通用功能。
Server层独有日志:binlog二进制归档日志,仅记录增删改数据变更语句,不记录查询语句,主要用于数据备份恢复与主从复制。 - 存储引擎层
专门负责数据持久化存储与数据读取检索,支持InnoDB、MyISAM、Memory等多款引擎。
目前MySQL5.5.5及以上默认引擎为InnoDB ,支持事务、行锁、外键,同时拥有自身专属日志:redo log重做日志、undo log回滚日志。
- redo log:保障事务持久性,实现数据库宕机数据恢复
- undo log:保障事务原子性,实现事务回滚与MVCC多版本并发控制
1.3 连接器
负责客户端与服务端建立TCP连接、完成账号密码身份校验、权限判定,同时负责连接维持与连接管理。
- 长连接:建立连接后持续复用,减少频繁创建销毁开销,生产环境推荐使用
- 短连接:执行少量SQL立即断开,频繁使用性能较差
- 企业开发中普遍使用数据库连接池统一管理连接,提升并发能力
1.4 查询缓存
MySQL接收到查询SQL后,优先在内存缓存中匹配语句,以SQL语句为key、查询结果为value进行存储。
- 缓存命中:直接返回结果,跳过后续所有解析执行流程
- 缓存未命中:向下流转执行完整流程,执行结束后存入缓存
注意:MySQL8.0正式彻底移除查询缓存,更新频繁业务命中率极低,实用性极差。
1.5 分析器
主要分为词法分析 与语法分析两步:
- 词法分析:拆分SQL关键字、表名、字段名、查询条件等语法元素
- 语法分析:校验SQL语句是否符合MySQL语法规范,语法错误直接抛出异常提示
解析完成后生成结构化语法树,交由优化器处理。
1.6 优化器
在多条可行执行方案中,自动选择执行效率最优方案,核心工作:
- 多索引场景下选定最优索引
- 多表关联查询确定表连接顺序
- 等价SQL重写优化,最大限度降低查询开销
1.7 执行器
接收优化后的执行计划,首先校验当前用户是否拥有数据表操作权限,无权限直接拒绝访问;权限校验通过后,调用对应存储引擎接口,完成最终数据读写操作。
二、一条SQL查询语句执行流程
示例SQL
sql
SELECT * FROM user WHERE id = 10;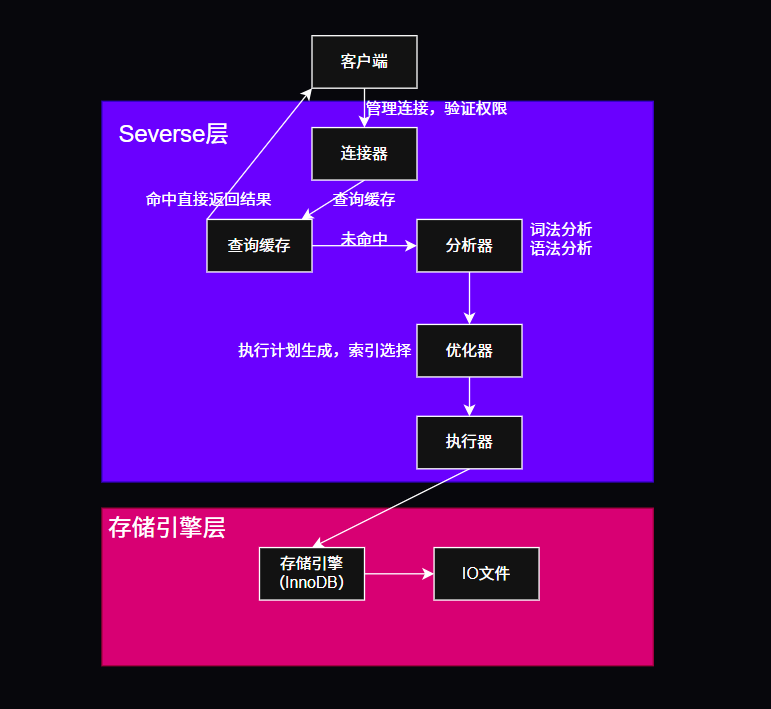
- 客户端→连接器:建立连接、身份认证、权限校验,建立会话通道
- 连接器→查询缓存:优先匹配缓存,命中直接返回结果,未命中进入下一流程
- 查询缓存→分析器:完成词法、语法解析,生成语法树
- 分析器→优化器:制定最优执行计划,选定查询索引
- 优化器→执行器:校验操作权限,调用存储引擎接口发起数据读取
- 执行器→InnoDB存储引擎:优先从缓冲池读取数据,内存无数据则发起磁盘IO加载数据页
- 数据逐层向上返回,最终由服务端整理结果响应给客户端
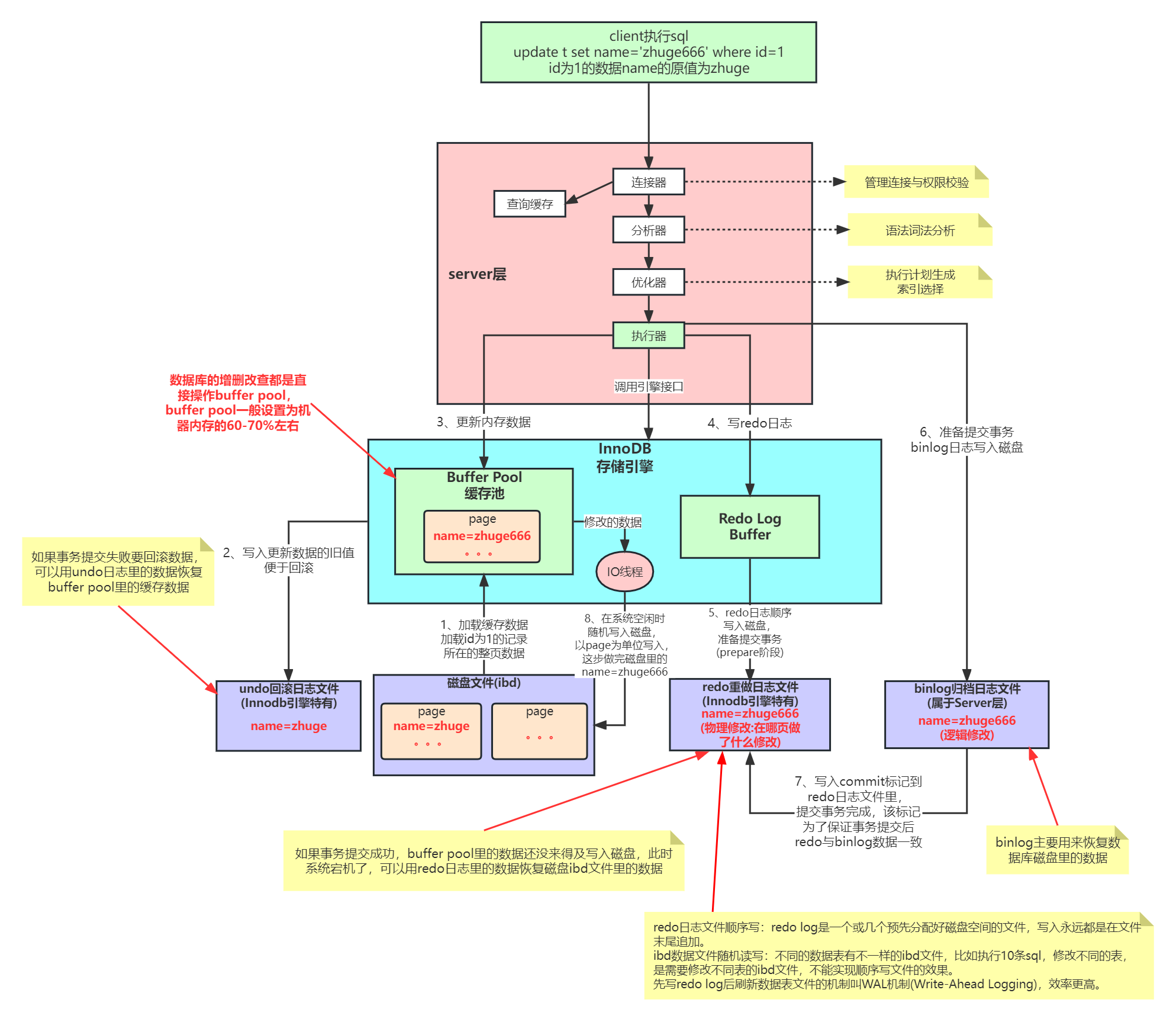
三、一条SQL更新语句执行流程
示例SQL
sql
UPDATE user SET name = '张三' WHERE id = 10;更新语句不走查询缓存,整体流程:
- 客户端请求经过连接器完成身份与权限校验
- 进入分析器完成SQL解析,生成语法树
- 优化器生成最优更新执行计划
- 执行器调用InnoDB引擎接口定位目标数据
- InnoDB引擎内部执行更新逻辑,联动三大日志完成事务管控
- 事务提交完成后异步刷盘,最终返回执行结果
四、MySQL三大日志完整详解
4.1 undo log 回滚日志(InnoDB引擎独有)
作用
- 实现事务原子性,支持事务失败手动回滚
- 实现MVCC多版本并发控制,实现读写互不阻塞
工作原理
执行增删改操作前,优先将修改前原始旧数据写入undo log;
- 事务失败/回滚:通过undo log恢复数据至修改前状态
- 事务正常提交:系统后台自动清理无用undo log日志
特点
事务级别日志,仅InnoDB支持,只存放数据历史版本信息。
4.2 redo log 重做日志(InnoDB引擎独有)
产生背景
直接修改磁盘数据存在大量磁盘寻址IO,写入性能极低,为此InnoDB引入WAL预写日志机制 ,核心思想:先写日志,后刷磁盘。
工作流程
- 更新操作优先修改内存缓冲池数据,生成脏页
- 优先写入redo log日志,业务直接返回更新成功
- 数据库系统空闲时,后台线程批量将脏页异步刷入磁盘
日志特点
- 属于物理日志,记录数据页层面物理修改行为
- 采用循环写入,日志文件大小固定,写满后从头循环覆盖
- 两大标识位
-
- write pos:日志实时写入位置
- checkpoint:日志落盘清理位置,清理前必须完成数据刷盘
核心能力
实现crash-safe崩溃安全,数据库意外宕机重启后,依靠redo log重做已提交事务,保证数据不丢失。
安全配置
innodb_flush_log_at_trx_commit=1
每次事务提交强制将redo log持久化刷入磁盘,数据安全性最高。
4.3 binlog 二进制归档日志(Server层通用日志)
归属层级
属于MySQL服务层日志,所有存储引擎均可使用,并非InnoDB独有。
诞生原因
早期MyISAM引擎无事务与宕机恢复能力,仅依靠binlog完成数据归档;InnoDB专注事务安全,binlog专注数据备份与集群同步,二者分工协作。
日志特点
- 属于逻辑日志,记录SQL执行逻辑与行数据变更内容
- 采用追加写入,日志文件写满自动新建文件,永久保留历史日志,不会覆盖
- 日志格式:statement、row、mixed
核心作用
- 实现全量数据备份与精准时间点数据恢复
- MySQL主从架构数据同步核心依赖
安全配置
sync_binlog=1
每次事务提交立即将binlog刷入磁盘,保障主从节点数据一致。
三大日志汇总对比表
| 日志名称 | 所属层级 | 日志类型 | 写入方式 | 核心作用 |
|---|---|---|---|---|
| undo log | InnoDB引擎层 | 版本日志 | 事务生成 | 事务回滚、实现MVCC |
| redo log | InnoDB引擎层 | 物理日志 | 循环写入 | 提升写入性能、宕机数据恢复 |
| binlog | Server服务层 | 逻辑日志 | 追加写入 | 数据归档备份、主从数据同步 |
五、更新事务完整日志执行流程(含两阶段提交)
- 执行器定位需要更新的数据,InnoDB优先加载数据至缓冲池
- 写入undo log,保存修改前数据,预留事务回滚能力
- 修改缓冲池内存数据,生成内存脏页
- 第一阶段提交 :写入redo log,状态标记为
prepare预提交 - Server层同步写入binlog归档日志,完成日志持久化
- 第二阶段提交 :将redo log状态修改为
commit正式提交,两阶段提交完成 - 事务正式提交成功,后台线程异步将内存脏页刷新至磁盘
- 系统自动清理失效undo log,释放日志空间
六、两阶段提交核心详解
6.1 设计目的
统一管控redo log与binlog事务状态,保证两份日志事务状态完全一致,避免数据库宕机出现一成功一失败,最终导致主从数据不一致、数据错乱问题。
6.2 核心执行顺序
- redo log 预提交(prepare)
- 完整写入binlog日志
- redo log 正式提交(commit)
6.3 宕机场景数据一致性验证
- prepare阶段之前宕机:事务直接回滚,数据无变更
- prepare完成、binlog未写完宕机:事务判定失败,执行回滚
- binlog写完、redo未完成commit宕机:重启数据库自动补全redo提交状态,事务正常完成
6.4 最终总结
两阶段提交严格遵循先预写redo、再落盘binlog、最后提交redo原则,完美兼顾InnoDB本地事务安全与MySQL集群主从同步一致性,是MySQL更新事务最核心的设计机制。