
打通 "2D 单图→3D 世界→具身仿真" 全链路
------数百米级大场景
目录
[01 长程3D生成的两大死穴](#01 长程3D生成的两大死穴)
[02 核心创新:解耦设计+自增强](#02 核心创新:解耦设计+自增强)
[03 实验验证](#03 实验验证)
[04 应用落地:从单图到仿真,打通生成式3D全链路](#04 应用落地:从单图到仿真,打通生成式3D全链路)
[05 思考:生成式3D世界的下一步](#05 思考:生成式3D世界的下一步)
单图三维场景重建技术长期以来始终存在应用层面的明显瓶颈,业内此前完成的单图 3D 生成研究,大多仅可完成近距小尺度场景构建,无法实现全域空间信息统一联动,在连续漫游、长路径视角推演等实操场景中存在明显局限性。
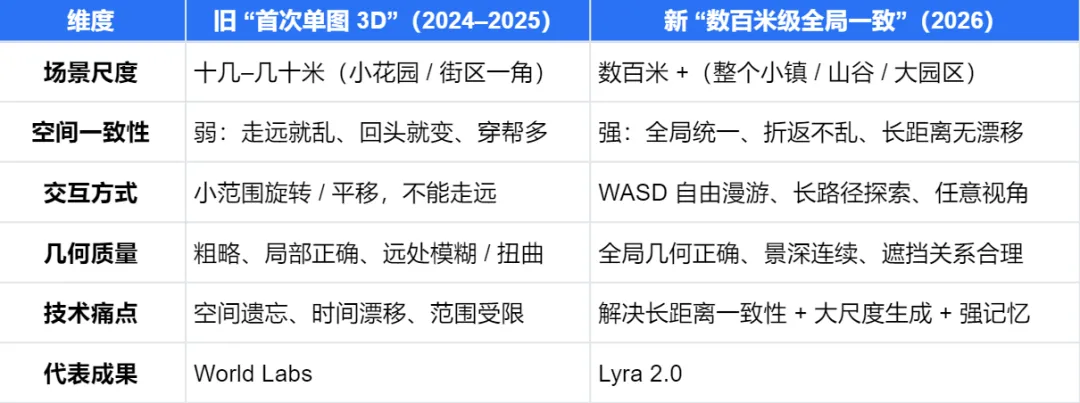
▲关键区别
NVIDIA发布的Lyra 2.0,用解耦几何跟踪与像素合成、自增强训练修正漂移 两套核心机制,首次实现单图生成数百米级、全局一致、可交互探索的 3D 场景,生成的 3D 高斯和网格模型可直接导入具身智能模拟器。
打通 "2D 单图→3D 世界→具身仿真" 全链路,突破传统方法场景规模、一致性和实用性三重限制。
01 长程3D生成的两大死穴
在Lyra 2.0之前,相机可控视频扩散驱动的3D重建,已经完成了从"单帧补全"到"短程漫游"的跨越,但迈向大规模真实场景时,行业普遍遇到无法绕开的瓶颈。
空间遗忘:长程探索的"记忆断层"
视频扩散模型的自回归特性,决定其存在固定的时序上下文窗口。
当相机持续移动,早期观测的区域会逐渐脱离窗口范围。一旦用户重访该区域,模型无法调取有效历史信息,只能凭空生成内容,直接破坏全局布局一致性。
为解决这一问题,常通过这两条路径:
一是构建全局3D表示(如点云、NeRF)作为持续记忆,但生成内容自带的瑕疵会不断污染3D几何,形成"误差放大循环";
二是将历史帧直接加入上下文,依靠自注意力推理几何对应关系,但大视角变化下极易失效。

▲计算机渲染 3D 图像的示例
但是两种方案都无法在长程探索中保持稳定。
时序漂移:自回归生成的"误差累积"
自回归生成的每一步都基于上一步的输出,微小的色彩偏移、结构扭曲会随帧数增加不断叠加,最终导致场景完全失真。
更关键的是训练与推理的分布差异:训练时模型以完美真值帧为条件,推理时却要面对自身生成的瑕疵帧,这种偏差让模型无法主动修正误差,只能持续传播。
即便通过FramePack等技术压缩历史帧、延长有效上下文,也只能缓解漂移,无法消除根源性的分布不匹配。

这使得现有方法在生成数百帧以上的长视频时,3D一致性几乎完全崩溃,难以支撑实际场景的3D重建。
02 核心创新:解耦设计+自增强
Lyra 2.0的核心价值,正是针对前面这两个行业共性难题,给出了轻量化、可扩展、不牺牲生成质量的系统性解决方案,而非局部优化。
Lyra 2.0的整体框架是迭代式检索-生成-更新闭环:
输入单张图像与用户定义的相机轨迹,模型先检索历史信息,再生成视频片段,最后更新空间记忆,逐步扩展场景。
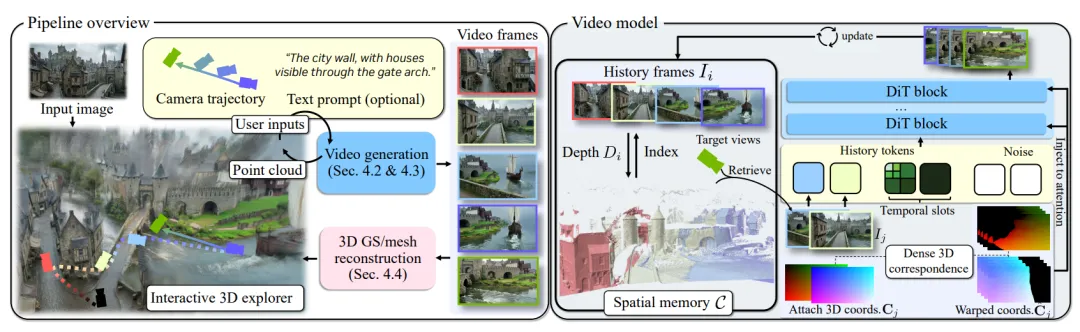
▲Lyra 2.0 方法总览
其创新并非单点突破,而是一套完整的机制设计,可拆解为三大核心模块。
抗遗忘机制:解耦几何路由与外观合成
这是Lyra 2.0解决空间遗忘的关键,彻底分开"几何信息路由"和"外观像素生成",不把3D几何作为硬约束,仅用其做信息检索与对应匹配。
- 逐帧3D缓存构建
模型为每一生成帧独立存储深度图、相机参数与降采样点云,不融合为全局点云。
这种设计避免了深度估计误差在全局结构中累积,从根源切断误差放大链。缓存随生成过程动态增长,支持任意长程轨迹的信息存储。
- 几何感知检索
针对目标相机视角,模型计算每帧历史点云的可见性分数,优先选择覆盖目标区域最多的历史帧。
即便相隔数百帧,重访区域也能精准匹配到对应历史信息,突破时序上下文窗口限制。
- 规范坐标注入
不直接扭曲RGB图像作为条件(避免空洞、拉伸 artifact),而是对历史帧的规范坐标做前向扭曲,仅传递几何对应关系,外观生成完全交给扩散模型的先验。这种设计既保证空间对齐,又不干扰生成质量。
这一整套设计,让模型在长程探索中始终"记得"去过的地方,重访时结构完全一致,同时保留视频扩散模型的高视觉保真度。
抗漂移机制:自增强训练弥合训练-推理差异
针对时序漂移的根源:训练用真值帧、推理用瑕疵帧 ,Lyra 2.0提出轻量级自增强训练策略,让模型提前适应推理时的误差分布。
训练过程中,模型以一定概率对历史隐变量加噪,模拟推理时的瑕疵输出,再让模型从被污染的条件中还原干净目标帧。
核心流程可简化为:
-
对历史隐变量
按流匹配规则加噪,得到
-
模型单步去噪得到近似重建
-
用
这种方式无需复杂的双向注意力与多步去噪,计算开销极低,却能让模型学会主动修正误差而非传播误差。
配合FramePack历史压缩,双重保障长程生成的外观与结构稳定。
前馈3D重建:适配生成数据的高质量资产化
生成的长视频并非终点,Lyra 2.0将其转化为可直接用于仿真的3D资产,核心采用3D高斯溅射(3DGS)+网格提取 pipeline。
- 基于Depth Anything V3做前馈3DGS预测,修改头结构降采样特征图,压缩高斯数量4倍,适配实时渲染;
- 在模型生成的视频数据上微调,提升对多视角轻微不一致的鲁棒性;
- 基于OpenVDB实现分层稀疏网格的大规模网格提取,近景精细、远景粗糙,平衡精度与效率。
最终输出的3DGS与网格资产,可直接导入NVIDIA Isaac Sim等具身智能仿真引擎,完成机器人导航、交互等下游任务。
03 实验验证
Lyra 2.0在DL3DV、Tanks-and-Temples两大数据集上,与GEN3C、Yume1.5、CaM、VMem、SPMem等主流方法做了定量与定性对比。
长视频生成性能
在SSIM、LPIPS、FID等客观指标,以及主观质量、风格一致性、相机可控性、重投影误差等专属指标上,Lyra 2.0均取得最优成绩。
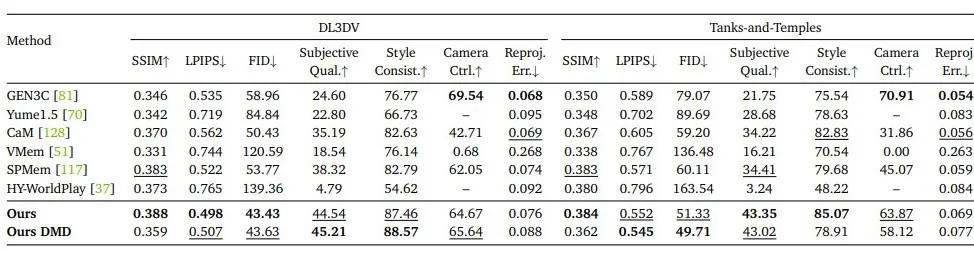
▲单视图到长视频生成定量对比
- 风格一致性指标大幅领先,证明漂移被有效抑制;
- 相机可控性与重投影误差表现优异,说明几何精度稳定;
- 主观质量评分最高,兼顾3D一致性与视觉保真度。
对比基线中,GEN3C依赖深度扭曲约束导致生成质量下降,CaM/SPMem缺乏精准相机控制,VMem长程完全崩溃,Yume1.5无空间记忆易漂移,而Lyra 2.0同时实现高质量、强可控、长程一致。

▲视频生成效果对比
3D场景重建性能
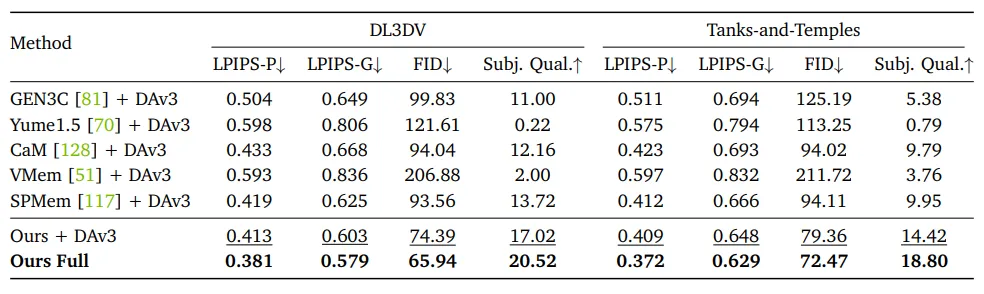
▲3D 场景重建效果定量对比
将各方法生成的视频结合DAv3重建3D场景,Lyra 2.0在LPIPS-G、FID、主观质量上全面超越所有基线,LPIPS-P(视频-渲染一致性)显著更低,证明其生成视频的3D一致性最高,重建资产更干净、无漂浮物、结构完整。

▲3D 高斯溅射重建场景渲染对比
消融实验

▲核心模块消融效果对比
- **移除逐帧缓存改用全局点云:**相机可控性暴跌,重访出现结构错误;
- **移除自增强训练:**长程风格一致性大幅下降,误差快速累积;
- **移除FramePack:**时序锚点缺失,漂移现象明显;
- **改用显式几何融合:**相机控制精度降低,无法适配噪声深度。

▲Tanks-and-Temples 数据集消融实验
实验充分验证,抗遗忘、抗漂移两大机制是长程3D一致生成的必要条件,缺一不可。
蒸馏加速:交互式场景的工程化落地
Lyra 2.0基于分布匹配蒸馏(DMD)得到轻量化版本,将去噪步骤从35步压缩至4步,推理速度提升约13倍,单步生成仅需15秒,同时保持核心视觉质量与3D一致性,完全满足交互式探索的实时性需求。
04 应用落地:从单图到仿真,打通生成式3D全链路
Lyra 2.0并非实验室原型,而是具备完整落地能力的系统,已验证三大核心应用场景:
1、 交互式3D探索器
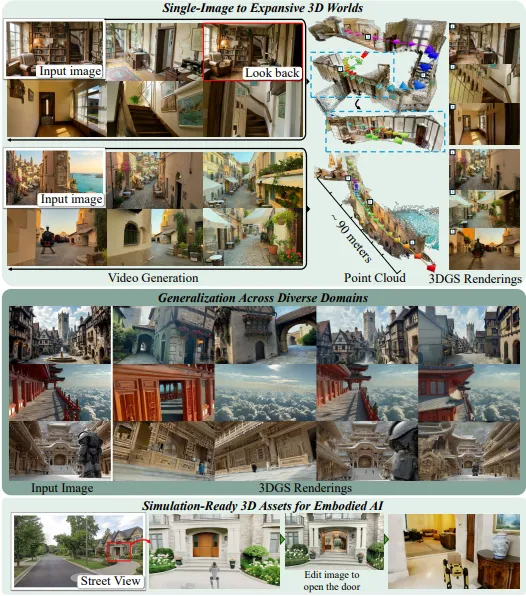
▲Lyra 2.0 单图驱动长程 3D 场景生成与跨领域泛化效果展示
提供GUI界面,用户可在3D缓存中规划相机轨迹,实时生成、扩展场景,支持多轨迹组合生成复杂环境,尺度可达90米级。
2、 野外场景规模化生成

▲野外图像场景生成与 3DGS 重建效果
突破训练数据分布限制,对室内、街景、自然景观等任意单图输入,均可生成全局一致的长视频与3D资产,泛化能力极强。
3、 具身智能仿真

▲交互式 GUI、曲面网格重建、Isaac Sim 仿真应用
3DGS与网格资产直接导入物理引擎,支持机器人在生成环境中完成导航、交互等物理仿真,无需真实世界3D采集,大幅降低仿真环境构建成本。
这意味着,Lyra 2.0真正打通了**"单张图像→可控长视频→高质量3D资产→仿真交互"的全流程**,为游戏、VR/AR、机器人仿真等领域提供了标准化的大规模3D内容生产方案。
05 思考:生成式3D世界的下一步
尽管Lyra 2.0实现了里程碑式突破,但仍存在明确的局限性:
1、仅支持静态场景
模型未建模动态物体,无法处理人物、车辆等运动元素,动态世界建模是下一阶段核心目标。
2、光度一致性依赖数据
训练数据的曝光差异会被模型学习,导致生成视频存在光度波动,影响3D重建质量,需更纯净的光度一致数据集或内置光度校正机制。
3、极端大场景效率待优化
随场景扩展,3D缓存与检索开销会线性增长,需进一步优化内存占用与检索速度,支撑公里级场景生成。
Lyra 2.0是生成式3D世界从"短程演示"走向"长程可用"的关键工作。
它以解耦几何路由与外观生成解决空间遗忘,以自增强训练根治时序漂移,配合适配生成数据的前馈3D重建,首次实现单张图像到百米级、可重访、3D一致的大规模场景生成,同时通过蒸馏技术满足交互式实时需求。

相较于一味追求模型规模与生成范式创新的同类工作,Lyra 2.0输出的3D资产可直接落地于具身智能仿真、沉浸式内容创作等场景。
Ref
论文标题:Lyra 2.0: Explorable Generative 3D Worlds