快速了解部分
基础信息:
- 题目: DATA SCALING LAWS IN IMITATION LEARNING FOR ROBOTIC MANIPULATION
- 时间: 2025.01 (ICLR 2025)
- 机构: Tsinghua University, Shanghai Qi Zhi Institute, Shanghai Artificial Intelligence Laboratory
- 3个英文关键词: Data Scaling Laws, Imitation Learning, Generalization
1句话通俗总结本文干了什么事情
作者通过收集海量机器人操作数据,发现并验证了数据 scaling law,证明了只要收集足够多样的环境和物体数据,简单的模仿学习就能让机器人学会零样本泛化。
研究痛点:现有研究不足 / 要解决的具体问题
现在的机器人策略往往缺乏"零样本泛化"能力,即在一个实验室环境里学会了倒水,换个杯子或者换个房间就废了。业界不知道如何像NLP领域那样,通过扩大数据规模来系统性地提升机器人的泛化能力。
核心方法:关键技术、研究设计(简要)
作者没有发明新模型,而是使用 Diffusion Policy ,系统性地改变训练数据的三个维度(环境数量、物体数量、演示次数),通过超过4万次真实世界实验,总结出了机器人泛化的"幂律定律"。
深入了解部分
作者想要表达什么
作者想表达的核心观点是:在机器人模仿学习中,数据的"多样性"远比单纯的"数量"重要。 只要你在足够多样的环境(比如32个)和物体(比如32种)上收集数据,哪怕每个场景只做几十次演示,机器人也能学会在全新的环境里操作没见过的物体。
相比前人创新在哪里
前人往往在单一环境或少量物体上训练,或者追求"多任务"泛化。本文的创新在于:
- 聚焦单任务深挖: 证明了单任务策略也能通过数据 scaling 实现强大的"域外泛化"。
- 量化了泛化能力: 找到了环境、物体数量与泛化成功率之间的幂律关系,给出了具体的"配方"(如32个环境+32个物体)。
- 强调多样性: 证明了增加新环境/新物体带来的收益,远高于在同一个环境里反复练习。
解决方法/算法的通俗解释
这就像是教小孩倒水。传统方法是让小孩在一个固定位置练1000次。本文的方法是:带小孩去10个不同的厨房(环境),用10种不同的瓶子(物体),各练5次。作者发现,后者更能培养出"换个厨房也能倒水"的能力。
解决方法的具体做法
- 硬件采集: 使用手持式 UMI 设备,在各种真实环境中(办公室、厨房等)收集人类操作视频。
- 变量控制: 固定任务(如倒水、整理鼠标),系统性地增加训练用的环境数(M)、物体数(N)和演示次数(K)。
- 模型训练: 使用 Diffusion Policy 训练策略,并在从未见过的环境和物体上测试。
- 总结定律: 拟合数据,得出"性能随环境/物体数量呈幂律增长,但随演示次数增长会饱和"的结论。
基于前人的哪些方法
- UMI : 手持采集设备,用于低成本获取大规模真实数据。
- Diffusion Policy: 动作生成模型,用于将视觉输入转化为机械臂动作。
- DINOv2: 视觉编码器,用于提取更鲁棒的视觉特征。
实验
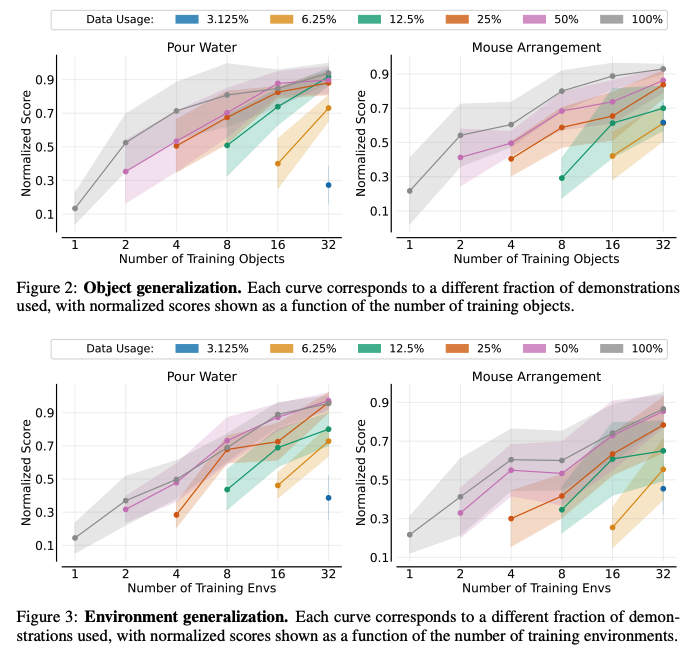
exp1: 物体泛化实验
设置:固定环境,改变训练物体数量(从1个到32个),测试在没见过的物体上的表现。
数据:倒水和整理鼠标两个任务,每个物体收集120次演示。
结论:物体泛化很容易,只要训练物体达到8个,得分就超过0.8;达到32个,得分超0.9。
exp2: 环境泛化实验
设置:固定物体,改变训练环境数量(从1个房间到32个房间),测试在新房间的表现。
数据:同样收集了数千次演示。
结论:环境泛化比物体泛化难,但依然遵循幂律。增加环境数量显著提升泛化能力,但增加演示次数带来的提升会很快饱和。
exp3: 联合泛化与策略验证
设置:在32个不同环境-物体对上收集数据(每个环境一个独特物体),验证高效采集策略。
数据:每个任务收集约1600次演示(32环境 x 50次)。
结论:仅用4个采集员一下午的时间,训练出的策略在新任务(叠毛巾、拔充电器)上达到了约90%的成功率。
提到的同类工作
Scaling Laws for Neural Language Models(2020)基础理论参考
OpenX-Embodiment(2023)数据集规模对比
RT-1 / RT-2(2022/2023)VLA模型对比
和本文相关性最高的3个文献
Dinov2: Learning robust visual features without supervision(2023)作为本文视觉编码器的基础
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion(2023)作为本文策略模型的基础
Universal Manipulation Interface: In-the-wild Robot Teaching without in-the-wild Robots(2024)作为本文数据采集方法的基础
我的
- 数据的多样性(训练环境数和物体数)比单纯的数据量(演示次数)更重要。
- 在未见过的物体和环境里,也达到了90%成功率。