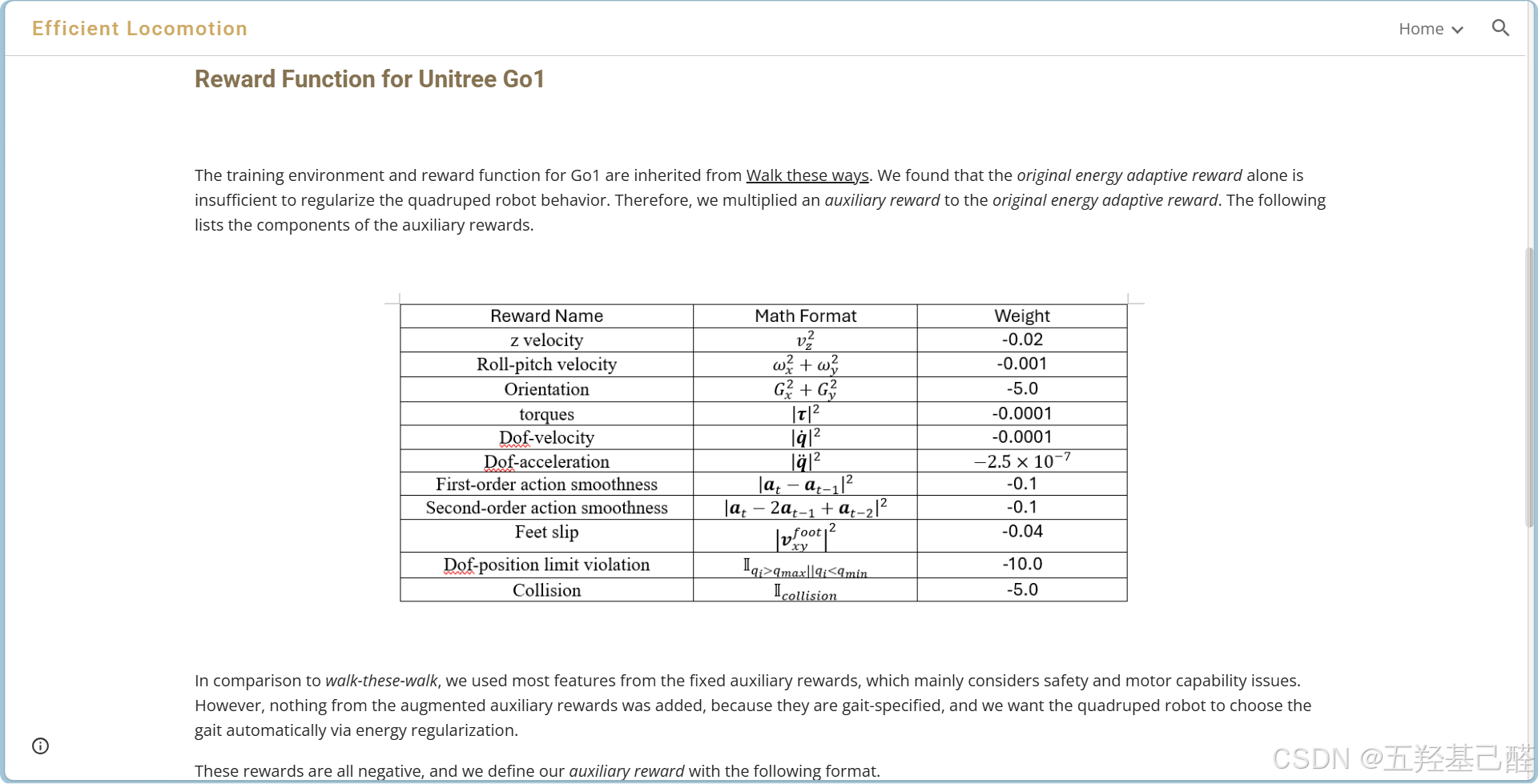
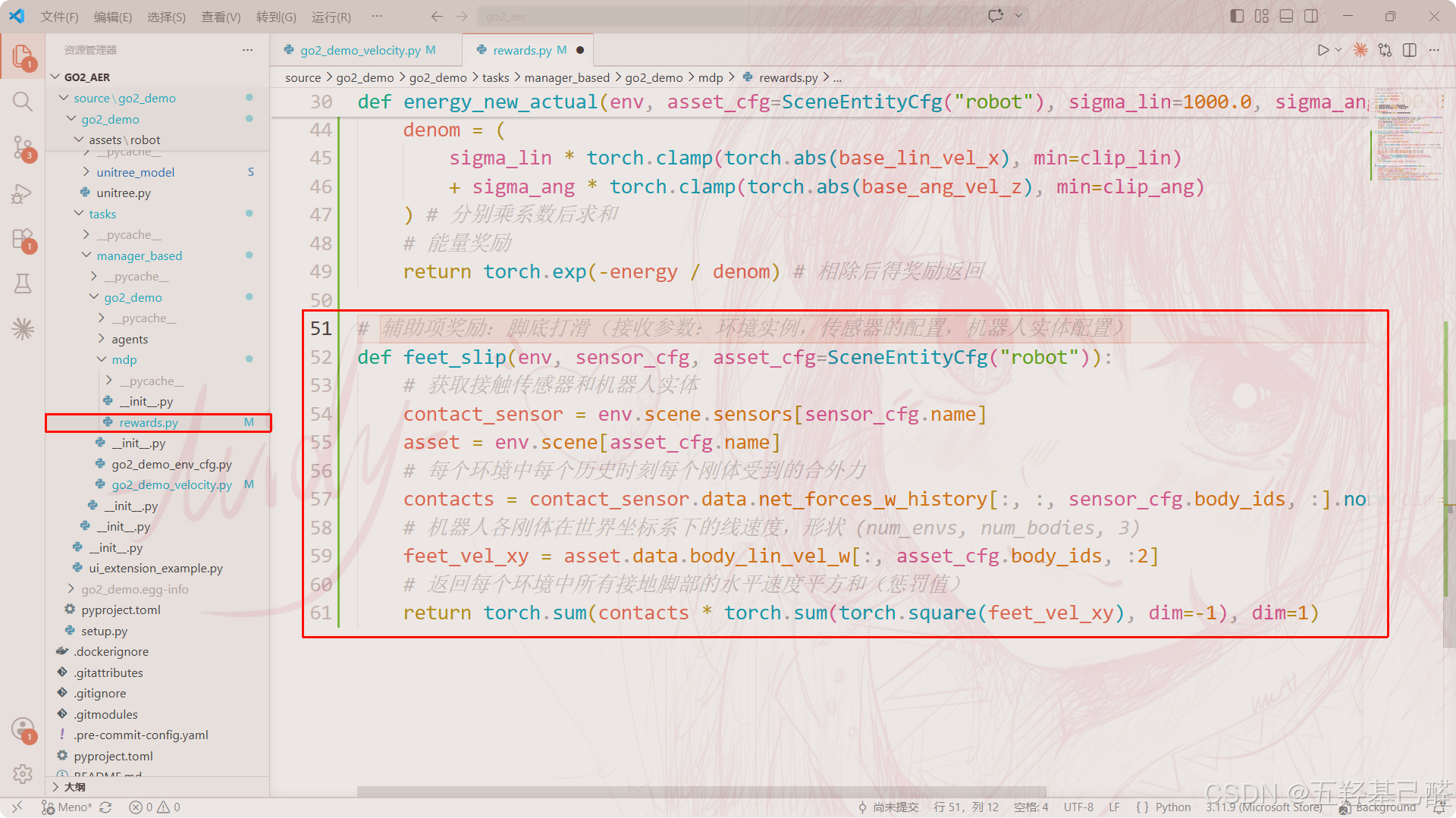
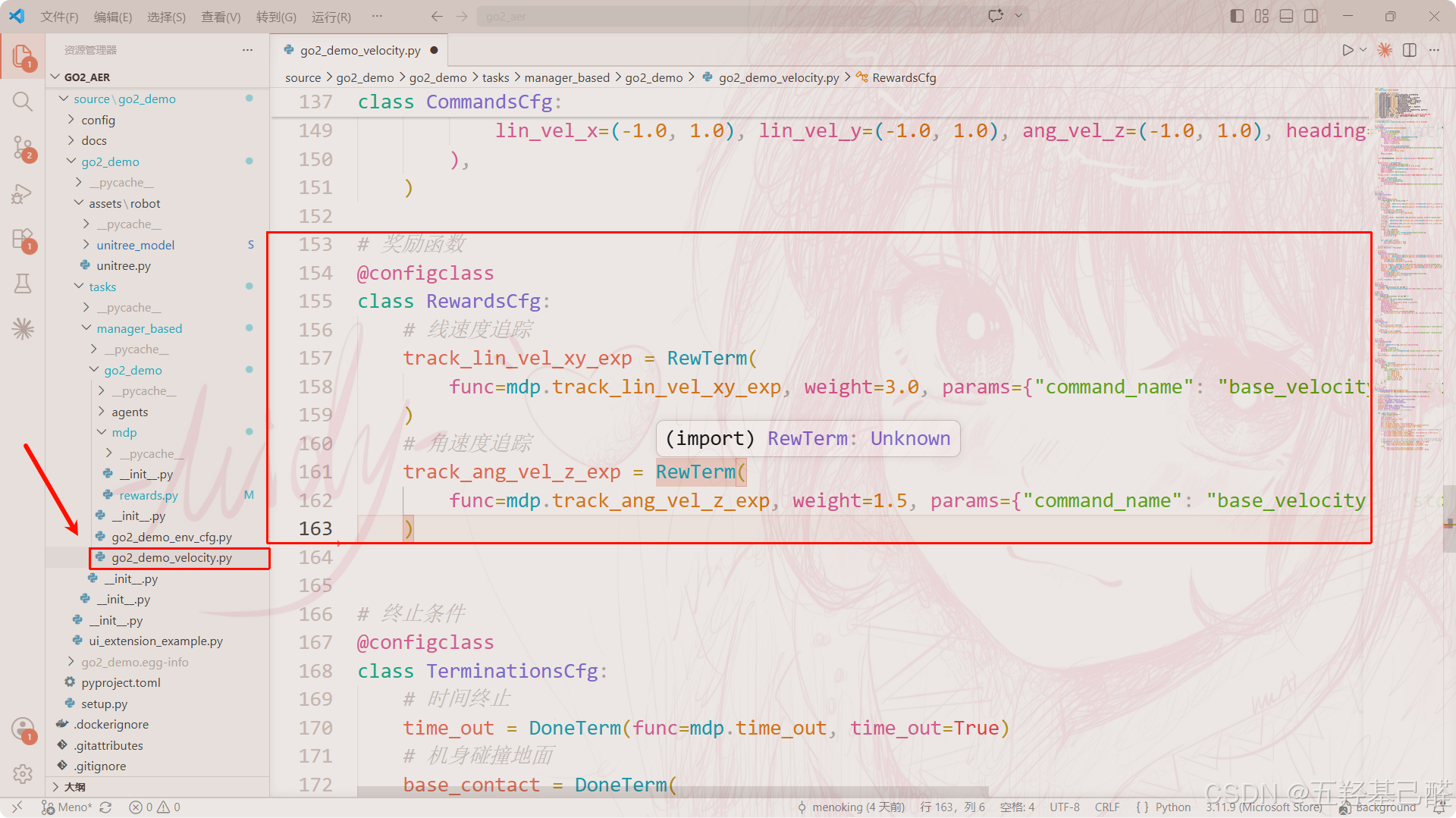
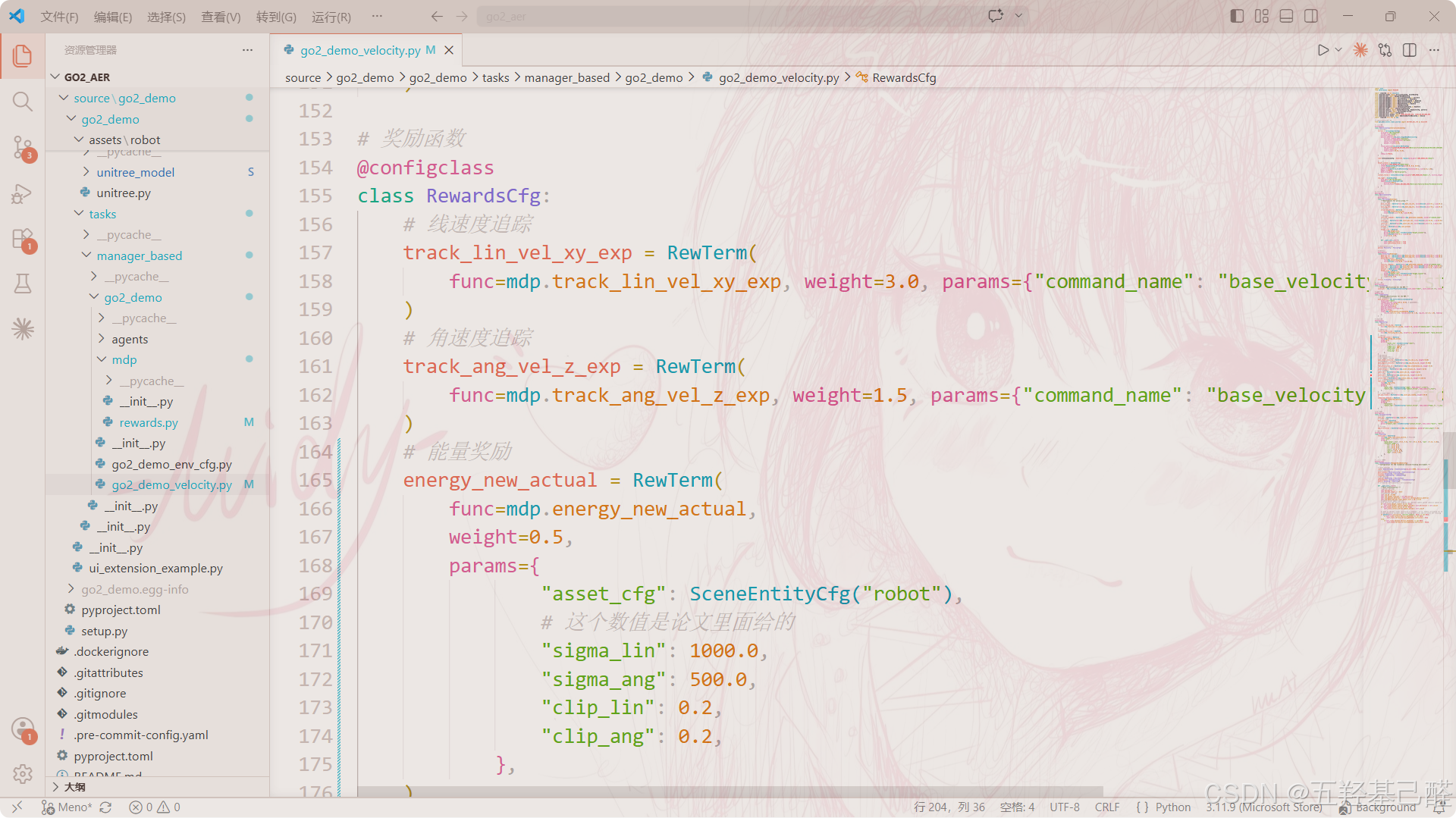
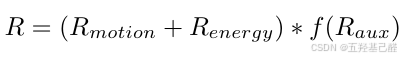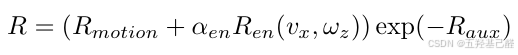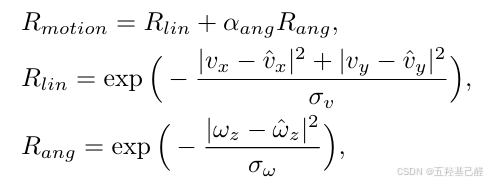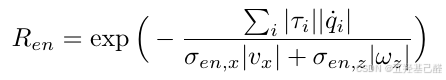# commands.py
from __future__ import annotations
from dataclasses import MISSING
from isaaclab.envs.mdp import UniformVelocityCommandCfg
from isaaclab.utils import configclass
@configclass
class UniformLevelVelocityCommandCfg(UniformVelocityCommandCfg):
limit_ranges: UniformVelocityCommandCfg.Ranges = MISSING
导包收尾
mdp\init.py
在mdp目录下的__init__.py中导入包:
python复制代码
# Copyright (c) 2022-2026, The Isaac Lab Project Developers (https://github.com/isaac-sim/IsaacLab/blob/main/CONTRIBUTORS.md).
# All rights reserved.
#
# SPDX-License-Identifier: BSD-3-Clause
"""This sub-module contains the functions that are specific to the environment."""
# Observations
from isaaclab.envs.mdp import base_lin_vel
from isaaclab.envs.mdp import base_ang_vel
from isaaclab.envs.mdp import projected_gravity
from isaaclab.envs.mdp import generated_commands
from isaaclab.envs.mdp import joint_pos_rel
from isaaclab.envs.mdp import joint_vel_rel
from isaaclab.envs.mdp import last_action
from isaaclab.envs.mdp import height_scan
# Actions
from isaaclab.envs.mdp import JointPositionActionCfg
# Commands
from isaaclab.envs.mdp import UniformVelocityCommandCfg
# Rewards
from isaaclab.envs.mdp import track_lin_vel_xy_exp
from isaaclab.envs.mdp import track_ang_vel_z_exp
from isaaclab.envs.mdp import lin_vel_z_l2
from isaaclab.envs.mdp import ang_vel_xy_l2
from isaaclab.envs.mdp import flat_orientation_l2
from isaaclab.envs.mdp import joint_torques_l2
from isaaclab.envs.mdp import joint_vel_l2
from isaaclab.envs.mdp import joint_acc_l2
from isaaclab.envs.mdp import action_rate_l2
from isaaclab.envs.mdp import joint_pos_limits
from isaaclab.envs.mdp import undesired_contacts
# Terminations
from isaaclab.envs.mdp import time_out
from isaaclab.envs.mdp import illegal_contact
from isaaclab.envs.mdp import bad_orientation
# Events
from isaaclab.envs.mdp import reset_root_state_uniform
# Custom modules
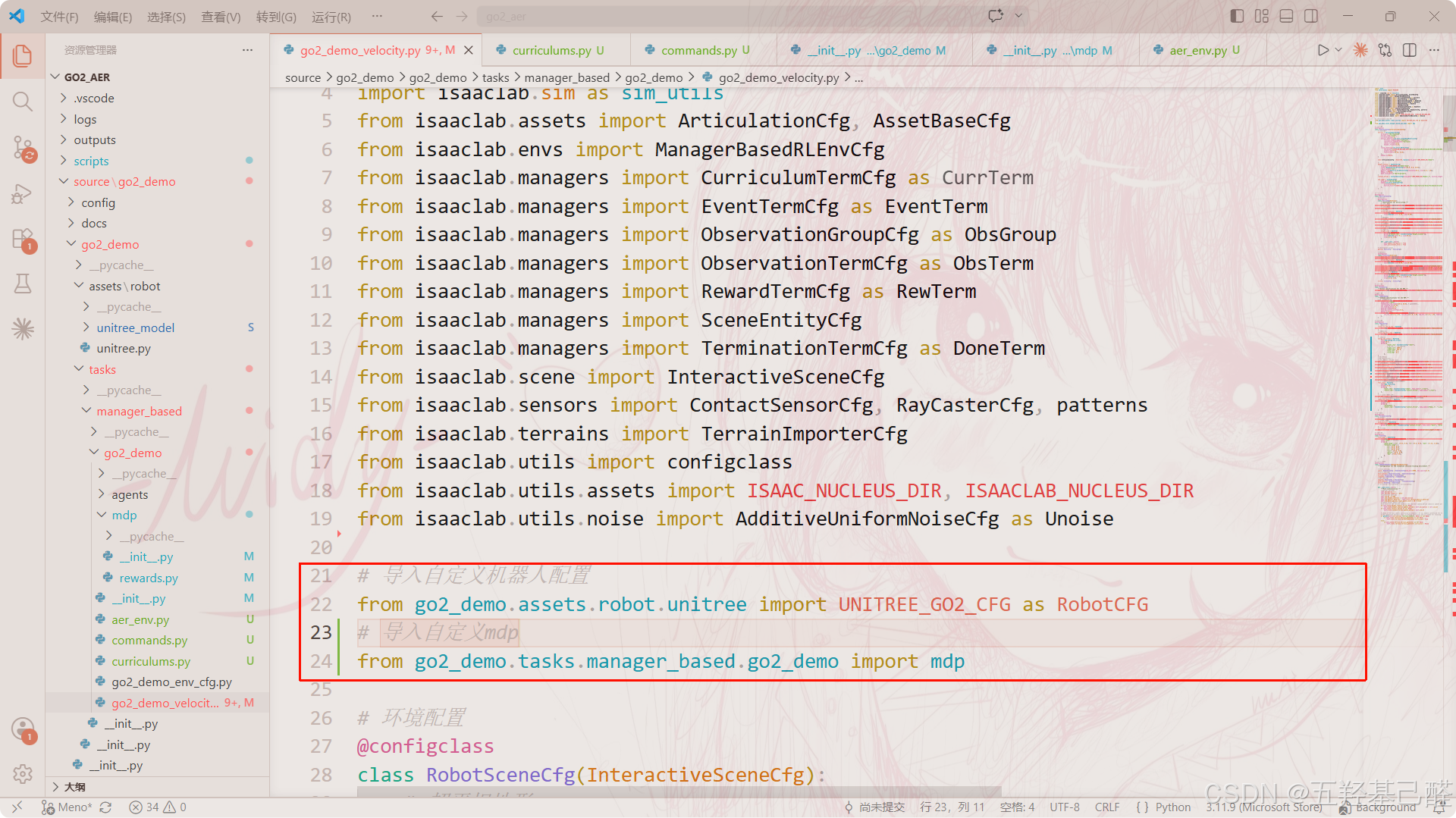
from .curriculums import * # noqa: F401
from .commands import * # noqa: F401, F403
from .rewards import * # noqa: F401, F403
go2_demo_velocity.py
在go2_demo_velocity.py中导入包:
并将课程学习部分添加进去:
python复制代码
# go2_demo_velocity.py
import math
from dataclasses import MISSING
import isaaclab.sim as sim_utils
from isaaclab.assets import ArticulationCfg, AssetBaseCfg
from isaaclab.envs import ManagerBasedRLEnvCfg
from isaaclab.managers import CurriculumTermCfg as CurrTerm
from isaaclab.managers import EventTermCfg as EventTerm
from isaaclab.managers import ObservationGroupCfg as ObsGroup
from isaaclab.managers import ObservationTermCfg as ObsTerm
from isaaclab.managers import RewardTermCfg as RewTerm
from isaaclab.managers import SceneEntityCfg
from isaaclab.managers import TerminationTermCfg as DoneTerm
from isaaclab.scene import InteractiveSceneCfg
from isaaclab.sensors import ContactSensorCfg, RayCasterCfg, patterns
from isaaclab.terrains import TerrainImporterCfg
from isaaclab.utils import configclass
from isaaclab.utils.assets import ISAAC_NUCLEUS_DIR, ISAACLAB_NUCLEUS_DIR
from isaaclab.utils.noise import AdditiveUniformNoiseCfg as Unoise
'''
中间代码不变,省略...
'''
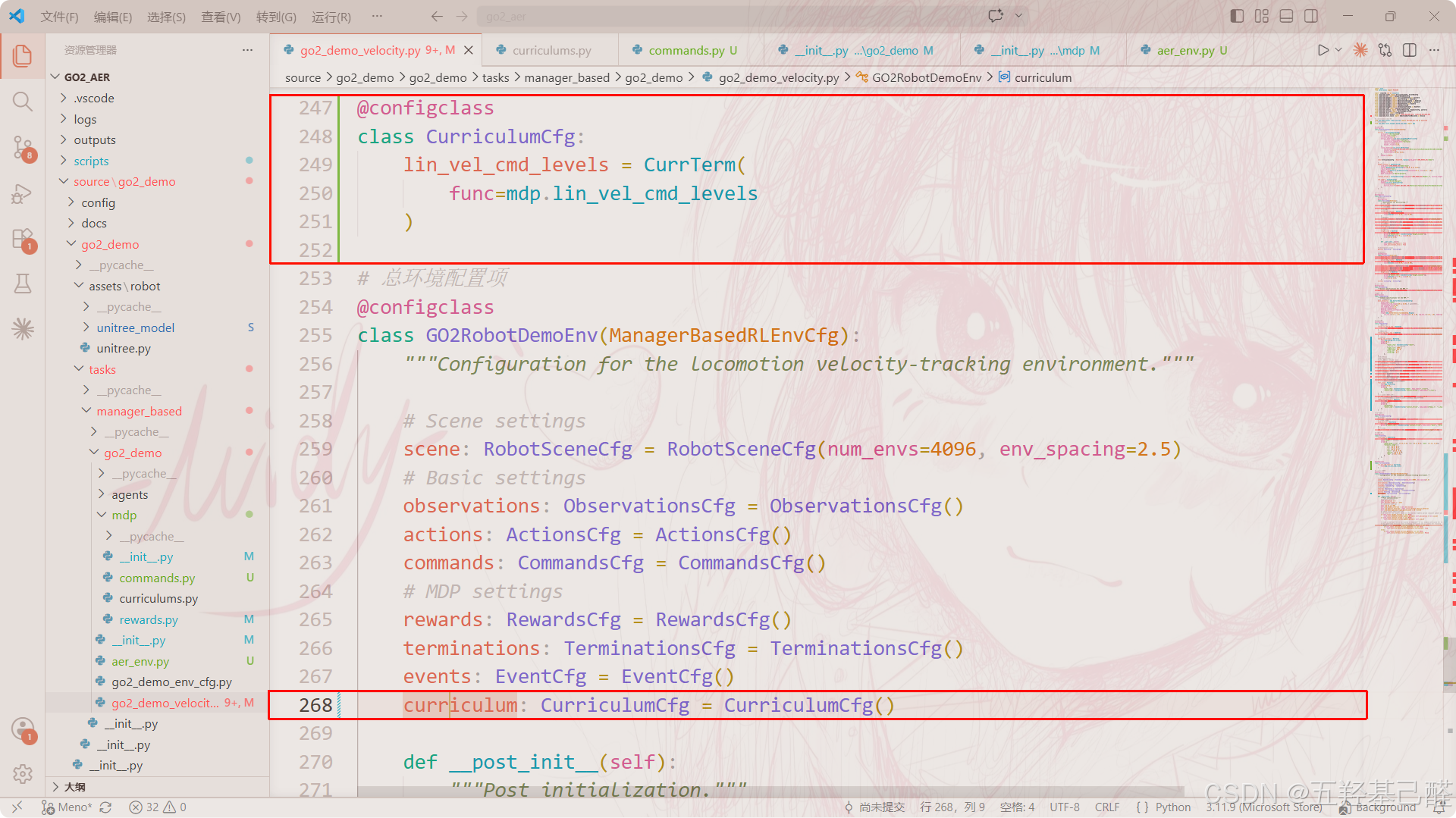
@configclass
class CurriculumCfg:
lin_vel_cmd_levels = CurrTerm(
func=mdp.lin_vel_cmd_levels
)
# 总环境配置项
@configclass
class GO2RobotDemoEnv(ManagerBasedRLEnvCfg):
"""Configuration for the locomotion velocity-tracking environment."""
# Scene settings
scene: RobotSceneCfg = RobotSceneCfg(num_envs=4096, env_spacing=2.5)
# Basic settings
observations: ObservationsCfg = ObservationsCfg()
actions: ActionsCfg = ActionsCfg()
commands: CommandsCfg = CommandsCfg()
# MDP settings
rewards: RewardsCfg = RewardsCfg()
terminations: TerminationsCfg = TerminationsCfg()
events: EventCfg = EventCfg()
curriculum: CurriculumCfg = CurriculumCfg()
def __post_init__(self):
"""Post initialization."""
# general settings
self.decimation = 4
self.episode_length_s = 20.0
# simulation settings
self.sim.dt = 0.005
self.sim.render_interval = self.decimation
self.sim.physics_material = self.scene.terrain.physics_material
self.sim.physx.gpu_max_rigid_patch_count = 10 * 2**15
# update sensor update periods
# we tick all the sensors based on the smallest update period (physics update period)
if self.scene.height_scanner is not None:
self.scene.height_scanner.update_period = self.decimation * self.sim.dt
if self.scene.contact_forces is not None:
self.scene.contact_forces.update_period = self.sim.dt
# check if terrain levels curriculum is enabled - if so, enable curriculum for terrain generator
# this generates terrains with increasing difficulty and is useful for training
if getattr(self.curriculum, "terrain_levels", None) is not None:
if self.scene.terrain.terrain_generator is not None:
self.scene.terrain.terrain_generator.curriculum = True
else:
if self.scene.terrain.terrain_generator is not None:
self.scene.terrain.terrain_generator.curriculum = False