ABot-M0: VLA Foundation Model for Robotic Manipulation with Action Manifold Learning
📄 arXiv: arXiv:2602.11236 | 🏷️ VLA模型 | ⭐ 评分: 8.7/10
🔑 论文笔记 VLA模型 跨本体学习 具身智能 机器人操作 Flow-Matching DiT 动作流形学习 3D感知 双臂操作 ABot-M0 UniACT-dataset Qwen3-VL VGGT pi0 pi0.5 OpenVLA-OFT GR00T-N1
文章目录
- [ABot-M0: VLA Foundation Model for Robotic Manipulation with Action Manifold Learning](#ABot-M0: VLA Foundation Model for Robotic Manipulation with Action Manifold Learning)
-
- 核心信息
- 摘要翻译
- 研究背景与动机
- 研究问题
- 方法概述
- 实验结果
-
- 实验目标
- 数据集
- 主要结果
-
- LIBERO
- LIBERO-Plus(零样本鲁棒性)
- [RoboCasa GR1 桌面任务](#RoboCasa GR1 桌面任务)
- RoboTwin2.0
- 消融实验
- 深度分析
- 与相关论文对比
-
- 对比论文选择依据
- [Being-H0.5 - Scaling Human-Centric Robot Learning for Cross-Embodiment Generalization](#Being-H0.5 - Scaling Human-Centric Robot Learning for Cross-Embodiment Generalization)
- [π₀ / π₀.5 - Physical Intelligence](#π₀ / π₀.5 - Physical Intelligence)
- [Open X-Embodiment - 数据基础](#Open X-Embodiment - 数据基础)
- 对比总结
- 技术路线定位
- 未来工作建议
- 我的综合评价
- 我的笔记
- 相关论文
- 外部资源
核心信息
- 论文ID:arXiv:2602.11236
- 作者:Yang Yandan, Zeng Shuang, Lin Tong et al.
- 机构:Amap (高德地图) 团队
- 发布时间:2026-02-11
- 会议/期刊:预印本
- 链接 :arXiv | PDF
- VLM骨干:Qwen3-VL 4B
- 动作专家:DiT 0.16B
摘要翻译
英文摘要
We introduce ABot-M0 (Amap VLA Foundation Model for Robotic Manipulation), a unified approach that jointly optimizes data processing and model architecture. We first construct the UniACT-dataset, combining six major open-source datasets to form a mixed training set of over 6 million trajectories spanning 9500+ hours and 20+ embodiments, which is currently the largest collection within the non-private domain. To resolve inconsistencies in action format, coordinate system, and sampling rate, we define a standardized preprocessing pipeline. Building on this unified data foundation, we construct the ABot-M0 model based on a VLM followed by an action expert. We propose the "Action Manifold Hypothesis": successful actions lie on a low-dimensional, smooth manifold shaped by physics, task goals, and environmental constraints. Based on this, we design the Action Manifold Learning (AML) mechanism, where the DiT backbone directly predicts clean action sequences. We also design a dual-stream feature interaction with an optional 3D spatial module. Our model achieves average success rates of 98.6%, 80.5%, 58.3% and 81.2% on LIBERO, LIBERO-Plus, RoboCasa GR1 Tabletop Tasks and RoboTwin2.0.
中文翻译
我们提出了 ABot-M0(高德VLA基础模型),一种联合优化数据处理和模型架构的统一方法。我们首先构建了 UniACT-dataset,整合了六个主要开源数据集,形成超过600万条轨迹、9500+小时、20+本体的混合训练集,这是目前非私有领域最大的数据集合。为解决动作格式、坐标系和采样率的不一致性,我们定义了标准化预处理流水线。在此统一数据基础上,我们构建了基于VLM+动作专家的ABot-M0模型。我们提出"动作流形假设":成功的动作位于由物理、任务目标和环境约束塑造的低维平滑流形上。基于此,我们设计了动作流形学习(AML)机制,DiT骨干直接预测干净的动作序列。我们还设计了带可选3D空间模块的双流特征交互架构。模型在LIBERO、LIBERO-Plus、RoboCasa GR1桌面任务和RoboTwin2.0上分别达到98.6%、80.5%、58.3%和81.2%的平均成功率。
核心要点提炼
- 研究背景:具身智能面临数据规模不足、数据质量缺乏标准化、预训练范式不匹配三大障碍
- 研究动机:能否将全球开源数据整合为统一基础,无需依赖私有数据即可训练高性能VLA?
- 核心方法:动作流形学习(AML)直接预测干净动作 + UniACT-dataset统一数据 + 可选3D空间模块
- 主要结果:LIBERO 98.6%,LIBERO-Plus 80.5%,RoboCasa 58.3%,RoboTwin2.0 81.2%
- 研究意义:证明了通过系统工程(而非私有数据)可构建高性能、可泛化的具身智能
研究背景与动机
领域现状
VLA模型是当前通用机器人策略的主流范式,但现有工作面临三堵"隐形高墙":
- 数据规模未达临界点:具身数据需要精确动作标注,采集成本高且耗时
- 数据质量参差不齐:动作表示、坐标系、控制频率在不同数据集中各不相同
- 预训练范式不匹配:VLM视觉编码器侧重语义识别,而非3D结构或物理动态
现有方法的局限性
- 噪声预测范式低效:主流扩散/流模型预测噪声(ε-pred)或速度(v-pred),这些目标本质上是高维且离流形的,浪费模型容量
- 跨本体数据难以整合:不同数据集格式不一致(LeRobot v2/v3、RLDS等),直接混合训练引入噪声
- VLM空间感知不足:2D视觉编码器无法提供毫米级空间推理,且CoT等方法只作用于推理层而不增强感知表征
研究动机
核心问题:能否在不依赖私有数据的情况下,通过整合全球开源数据构建高性能VLA?这指向一种新方向------具身智能可通过公共知识的聚合和能力的逐步积累而发展。
研究问题
核心研究问题
- 如何将分散的开源数据集整合为统一、高质量的预训练语料?
- 如何设计更高效的VLA动作预测范式(替代噪声预测)?
- 如何弥补VLM在3D空间感知上的不足?
- 如何平衡数据规模、质量和多样性?
方法概述
核心思想
三个正交维度的系统性改进:数据标准化 → 动作流形学习(AML)→ 3D空间感知注入。三者收益可叠加,无需私有数据即可达到SOTA。
方法框架
整体架构
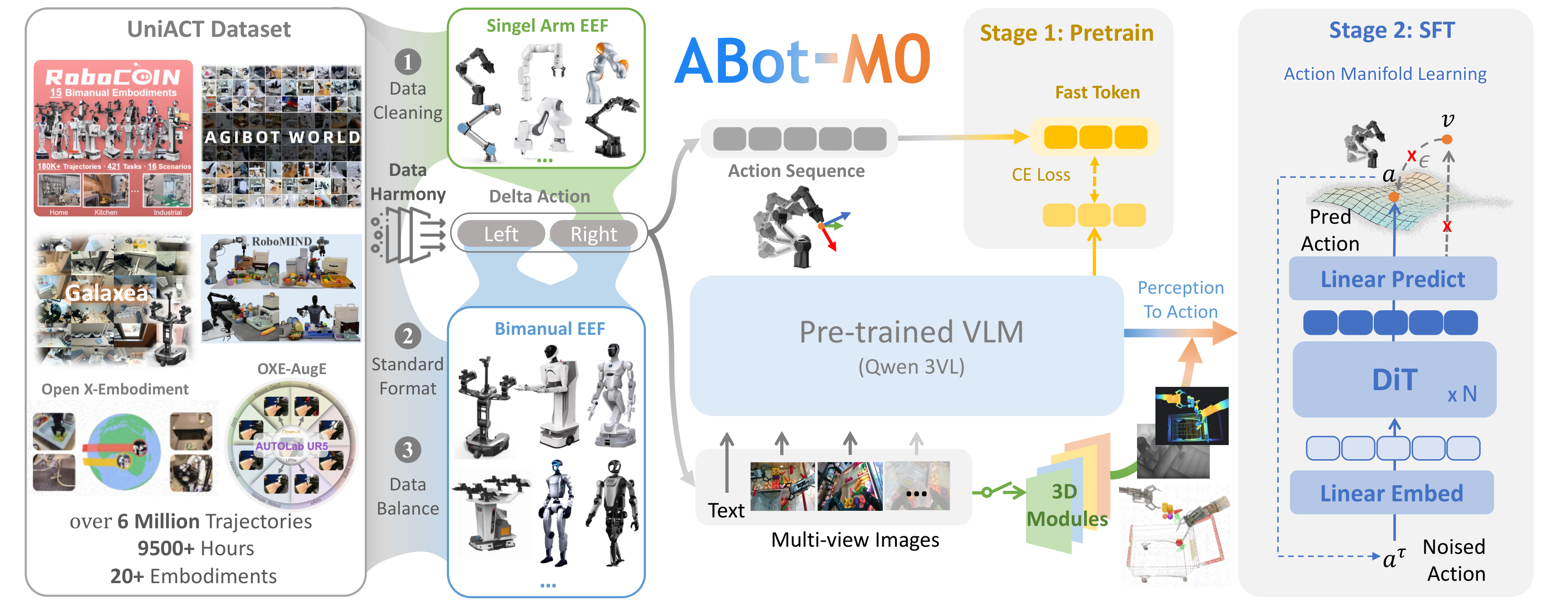
图1:ABot-M0模型架构。VLM+动作专家两组件架构,AML直接预测动作,双流特征交互+可选3D模块增强空间推理。
各模块详细说明
模块1:UniACT-dataset 统一数据集
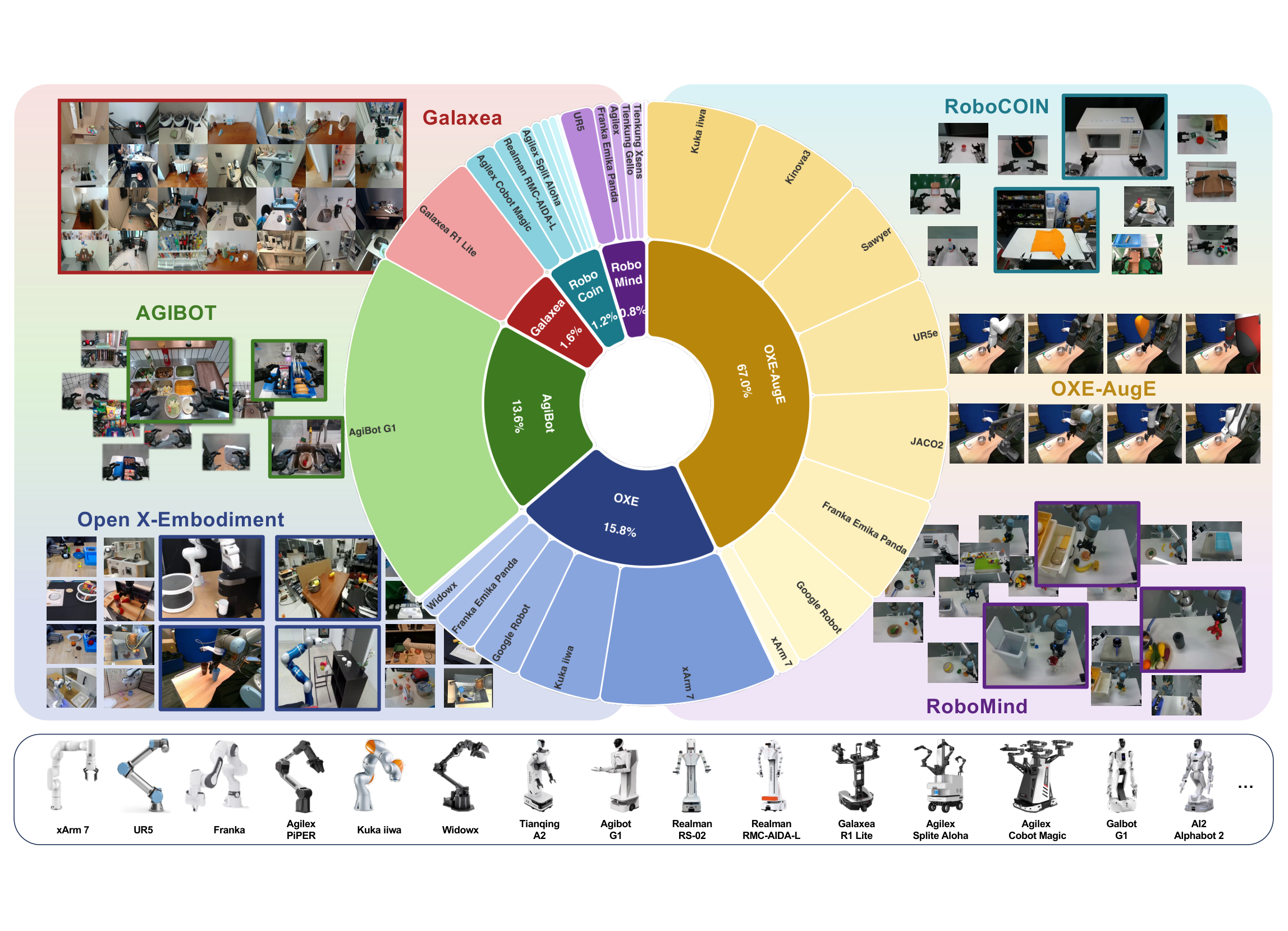
图2:UniACT-dataset概览,600万+轨迹,9500+小时,20+机器人本体。
- 功能:整合6个开源数据集,提供统一的预训练语料
- 规模:600万+轨迹,9500+小时,20+本体(非私有领域最大)
- 数据来源:OXE、OXE-AugE、AgiBot-Beta、RoboCoin、RoboMind、Galaxea
- 数据清洗 :多阶段流水线,约16%轨迹被剔除
- 无效指令过滤(非英语、乱码、空字段)
- 帧-指令对齐修复
- 视觉异常过滤(全黑、模糊、遮挡)
- 异常动作序列过滤
- 不完整/歧义动作剔除
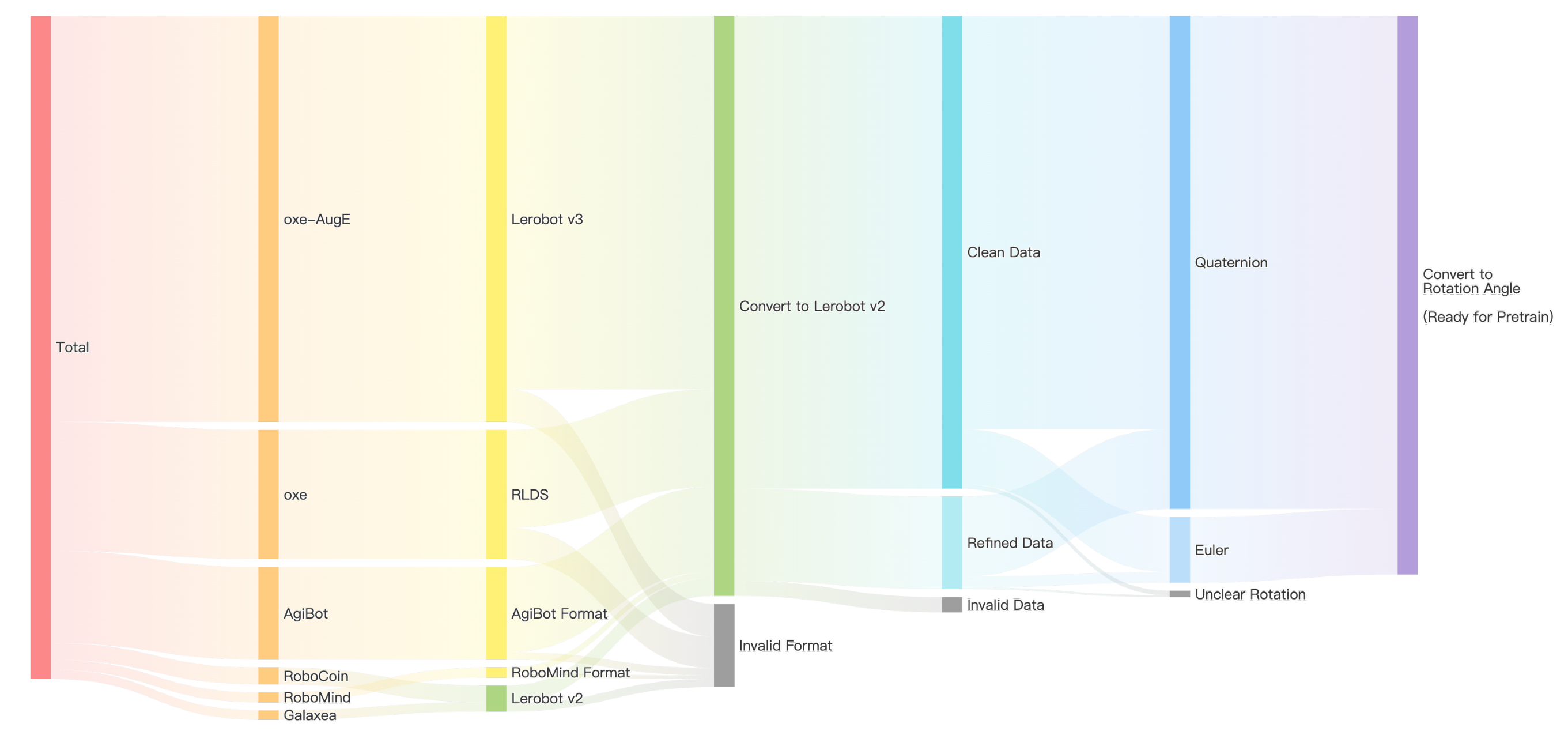
图3:数据清洗和预处理流水线。
模块2:标准化数据格式
- 动作表示 :末端执行器(EEF)坐标系下的delta动作,旋转用旋转向量(axis-angle)统一编码
- 单臂: Δ x , Δ y , Δ z , r , g r i p p e r ∈ R 7 \\Delta x, \\Delta y, \\Delta z, \\bm{r}, gripper \in \mathbb{R}^7 Δx,Δy,Δz,r,gripper∈R7
- 双臂: R 14 \mathbb{R}^{14} R14
- Pad-to-Dual策略:单臂数据零填充至双臂格式,统一视为右臂执行,实现单/双臂训练统一
- 采样策略:Task-Uniform采样(按任务均匀采样),在构型多样性和技能覆盖之间取得最佳折中
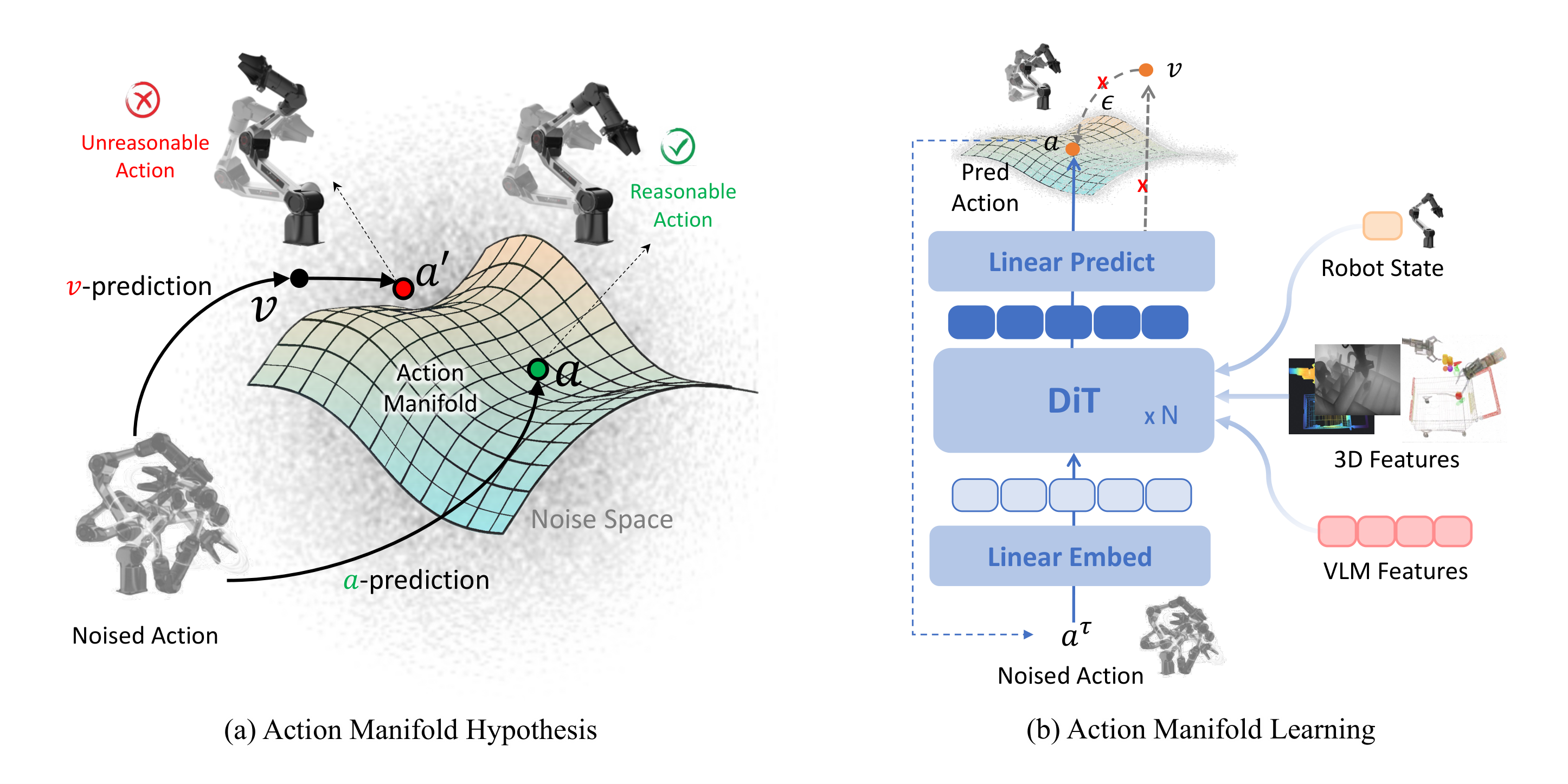
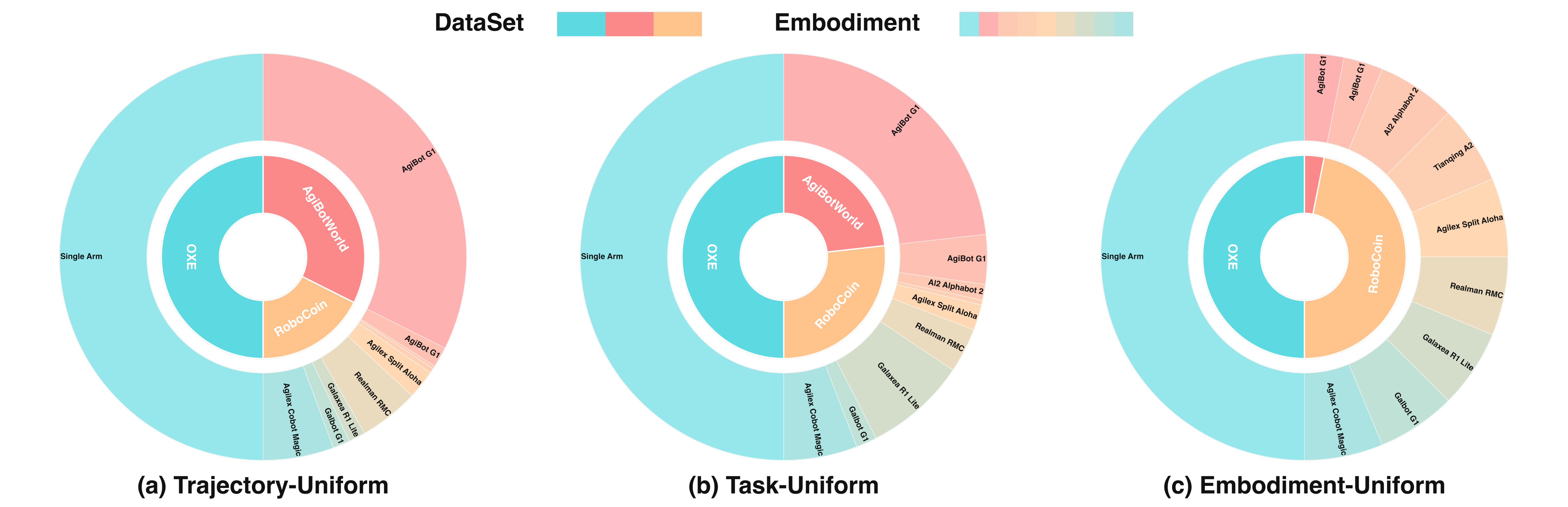
图4:不同采样策略下的本体分布。
模块3:Action Manifold Learning (AML) --- 核心创新

图5:动作流形假设。有效动作位于低维流形上,传统噪声/速度预测目标是高维且离流形的;AML直接预测干净动作。
- 动作流形假设:成功的动作不随机散布,而是位于由物理定律、任务目标和环境约束塑造的低维平滑流形上
- 核心转变:从预测噪声/速度(ε-pred/v-pred)→ 直接预测干净动作(a-pred)
- 预测公式:
\\hat{A}*t = V*\\theta(\\phi_t, A\^\\tau_t, q_t)
其中 A t τ = τ A t + ( 1 − τ ) ϵ A^\tau_t = \tau A_t + (1 - \tau)\epsilon Atτ=τAt+(1−τ)ϵ 为加噪动作
- 损失函数:虽预测动作,但损失计算在速度空间上(与JiT一致):
\\mathcal{L}(\\theta) = \\mathbb{E}\\left\[ w(\\tau) \| V_\\theta(\\phi_t, A\^\\tau_t, q_t) - A_t \|\^2 \\right\]
权重 w ( τ ) = 1 ( 1 − τ ) 2 w(\tau) = \frac{1}{(1 - \tau)^2} w(τ)=(1−τ)21,高噪声时权重小(大幅去噪),低噪声时权重大(精细微调)
- 推理过程:标准ODE求解,从纯噪声出发迭代去噪
- 优势:减少输出不确定性,提升解码速度和策略稳定性,特别适合高维动作空间(如人形机器人29 DoF)
模块4:VLM特征交互
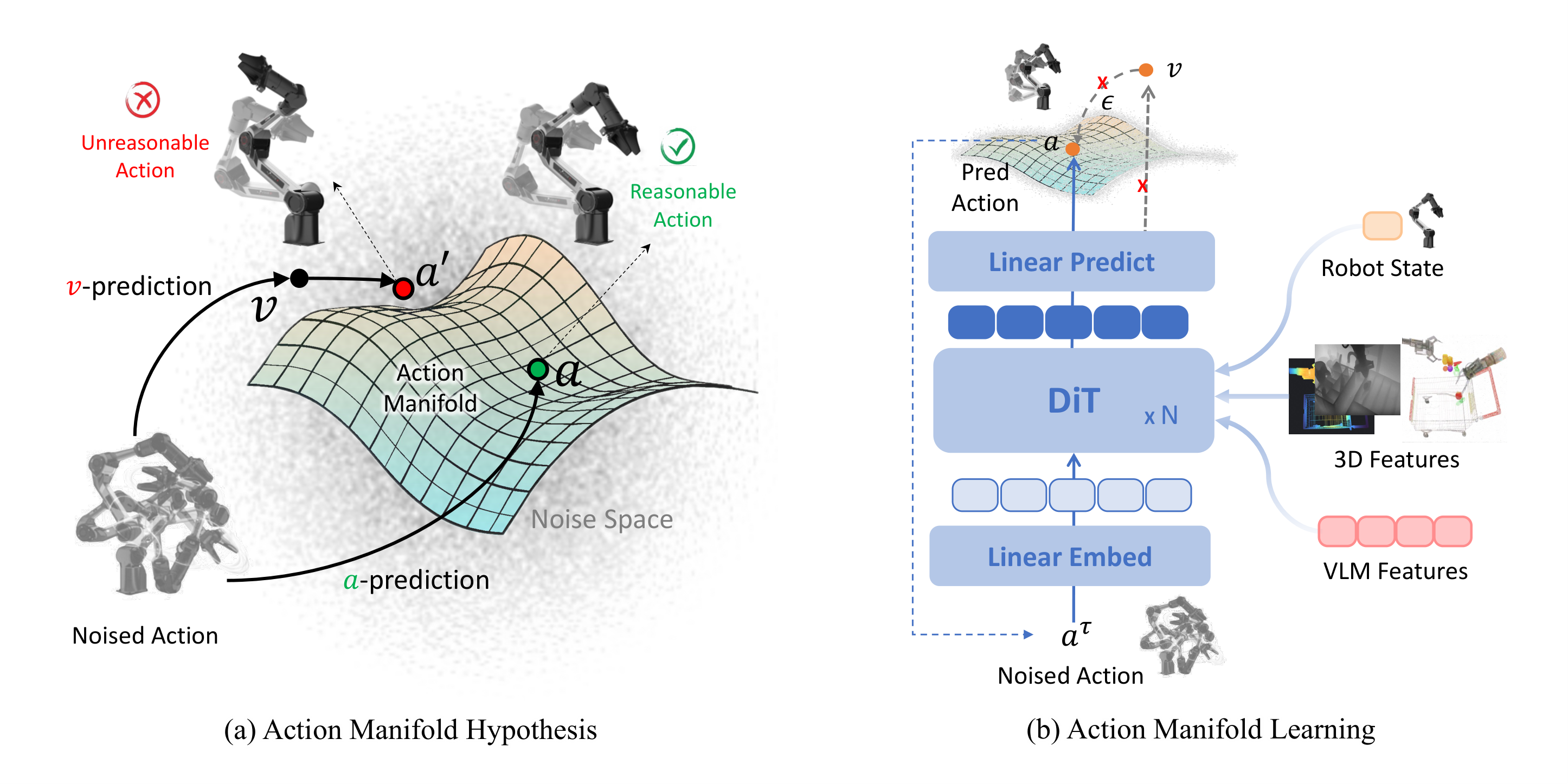
图6:VLM特征交互方案对比。
- 关键发现 (消融实验):
- 直接使用VLM原始特征 > 拼接Action Query
- 深层特征 > 浅层/中间层特征
- 多层特征聚合 ≈ 单层最终特征(无显著提升)
- 结论:VLA预训练后的VLM已内化动作空间语义,最后一层特征最有效,无需额外Action Query适配
模块5:3D空间信息注入
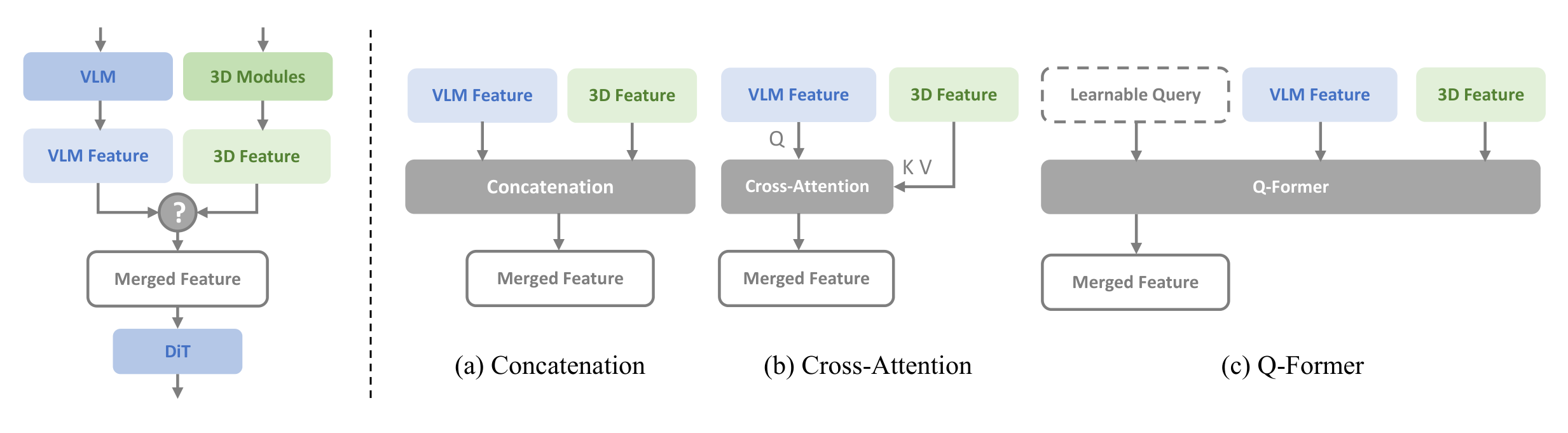
图7:3D信息注入模块。左:VLM+3D特征融合流水线;右:三种融合策略对比。
- 功能:弥补VLM的2D空间感知不足
- 双源3D感知 :
- VGGT(单图3D特征):从单张RGB图像推断3D环境结构
- Qwen-Image-Edit(隐式多视角):合成额外视角,通过视角一致性隐式捕捉3D场景布局
- 融合策略:Cross-Attention最优(VLM特征作Query,3D特征作Key/Value)
- 完全模块化:可按需开关或组合,无需重训核心VLM
模块6:两阶段训练范式
- 阶段1(大规模预训练) :在UniACT-dataset上学习跨任务、跨本体的通用操作先验
- Task-Uniform采样平衡分布
- 快速token头 + 动作分类损失加速收敛
- 阶段2(空间感知SFT) :注入3D空间先验,提升高精度任务表现
- 低学习率联合微调VLM+动作专家
- Dropout + 动作噪声扰动增强鲁棒性
- 不破坏已有通用能力
实验结果
实验目标
验证AML、数据标准化、3D注入三个正交改进的独立和叠加效果。
数据集
| 基准 | 任务数 | 特点 | 评估方式 |
|---|---|---|---|
| LIBERO | 130任务/5套 | 桌面单臂操作 | 50 trials/task |
| LIBERO-Plus | 同LIBERO | 7维扰动(视觉/语言) | 零样本评估 |
| RoboCasa GR1 | 24任务 | 双臂+灵巧手+腰部,29 DoF | 50 rollouts/task |
| RoboTwin2.0 | 50任务 | 仿真双臂,Clean+Randomized | 多任务训练 |
主要结果
LIBERO
| 方法 | L-Spatial | L-Object | L-Goal | L-Long | Average |
|---|---|---|---|---|---|
| OpenVLA | 84.7 | 88.4 | 79.2 | 53.7 | 76.5 |
| π₀ | 98.0 | 96.8 | 94.4 | 88.4 | 94.4 |
| π₀.5 | 98.8 | 98.2 | 98.0 | 92.4 | 96.9 |
| GR00T-N1.6 | 97.7 | 98.5 | 97.5 | 94.4 | 97.0 |
| OpenVLA-OFT | 97.6 | 98.4 | 97.9 | 94.5 | 97.1 |
| X-VLA | 98.2 | 98.6 | 97.8 | 97.6 | 98.1 |
| ABot-M0 | 98.8 | 99.8 | 99.0 | 96.6 | 98.6 |
LIBERO-Plus(零样本鲁棒性)
| 方法 | Average |
|---|---|
| OpenVLA | 15.6% |
| OpenVLA-OFT | 67.9% |
| ABot-M0 | 80.5% |
在7维扰动下零样本评估,ABot-M0大幅超越OFT +12.6%,展现出极强的内在鲁棒性。
RoboCasa GR1 桌面任务
| 方法 | Average |
|---|---|
| GR00T-N1.6 | 47.6% |
| Qwen3OFT | 48.8% |
| ABot-M0 | 58.3% |
29 DoF高维动作空间(双臂+灵巧手+腰部),ABot-M0比GR00T-N1.6高+10.7%,验证AML在高维动作空间的优越性。
RoboTwin2.0
| 方法 | Clean | Randomized |
|---|---|---|
| π₀.5 | 43.0% | 43.8% |
| X-VLA | 72.8% | 72.8% |
| ABot-M0 | 86.1% | 85.1% |
消融实验
Action Manifold Learning 消融
| 配置 | GR00T (ε-pred) | ABot-M0 (a-pred/AML) |
|---|---|---|
| 4步, chunk=8 | 基线 | +1.7% |
| 2步, chunk=8 | 下降明显 | 更稳定 |
| chunk=30 | 下降23.6% | 仅降至62.8% |
关键发现:在极端配置(少步数/大chunk)下,AML远优于噪声预测。大chunk=30时GR00T暴跌23.6%,而AML仅温和下降,验证了动作流形假设。
VLM特征消融
| 特征类型 | LIBERO-Plus SR |
|---|---|
| 最后一层hidden | 71% |
| 中间层hidden | 较低 |
| 所有层concat | ≈最后一层 |
| Action Query | 低于原始特征 |
| Query+hidden concat | 最低 |
结论:VLA预训练后VLM最后一层特征已充分对齐动作空间,无需额外适配模块。
3D注入消融
- VGGT单图3D特征:LIBERO +1.8%,LIBERO-Plus +2-4%
- 多视角合成:视角扰动子集+14%
- 最优融合策略:Cross-Attention > Concatenation > Q-Former
深度分析
研究价值评估
理论贡献
-
贡献1:动作流形假设(Action Manifold Hypothesis)
- 创新点:将流形假设从视觉/语言扩展到机器人动作域,理论解释了为什么直接预测动作优于预测噪声
- 学术价值:为VLA动作预测范式提供了新理论框架
- 影响范围:所有基于扩散/流的VLA模型
-
贡献2:Task-Uniform采样策略的系统性分析
- 创新点:从构型分布和技能采样统计两个维度系统比较三种采样策略
- 学术价值:提供了数据工程的最佳实践指南
- 影响范围:跨本体VLA预训练
-
贡献3:VLM特征选择的经验法则
- 创新点:证明VLA预训练后最后一层特征最有效,Action Query反而有害
- 学术价值:简化了VLM到动作专家的特征传递设计
- 影响范围:VLA架构设计
实际应用价值
-
应用场景1:开源数据驱动的VLA训练
- 适用性:无需私有数据即可达到SOTA,降低研究门槛
- 优势:完整的数据处理和训练代码将开源
- 潜在影响:推动社区协作式VLA发展
-
应用场景2:高维动作空间控制
- 适用性:AML在29 DoF(RoboCasa)上验证有效
- 优势:chunk=30时仍保持62.8%成功率,而GR00T暴跌
- 潜在影响:为人形机器人全身控制提供可行方案
领域影响
- 短期影响:AML可能成为扩散VLA的新训练范式,替代传统ε-pred/v-pred
- 中期影响:推动开源数据标准化(LeRobot v2格式统一)
- 长期影响:证明"系统工程 > 私有数据"路线的可行性
方法优势详解
优势1:AML的动作预测范式
- 描述:直接预测干净动作而非噪声/速度,学习目标更高效
- 技术基础:动作流形假设 + 重加权速度损失
- 实验验证:极端配置(2步/大chunk)下远超噪声预测
- 对比分析:比Being-H0.5的Flow-Matching更直接,比π₀的ε-pred更高效
优势2:完全开源数据路线
- 描述:600万+轨迹全部来自6个开源数据集,无任何私有数据
- 技术基础:系统性数据清洗+标准化+Task-Uniform采样
- 实验验证:多基准SOTA,与依赖私有数据的模型可比
- 对比分析:Being-H0.5用35K小时含私有数据,ABot-M0用9.5K小时纯开源数据
优势3:模块化3D感知
- 描述:VGGT+Qwen-Image-Edit即插即用,按需开关
- 技术基础:Cross-Attention融合 + 多视角合成
- 实验验证:视角扰动子集+14%,且不破坏基线性能
- 对比分析:比Being-H0.5的纯RGB方案更灵活,但需额外模型推理
局限性分析
局限1:缺少真实机器人实验
- 描述:所有评估均在仿真环境中进行,未在真实机器人上验证
- 原因:仿真与真实之间存在domain gap
- 影响:AML在真实环境中的鲁棒性未知
- 可能的解决方案:增加真实机器人部署实验
局限2:动作空间统一方式较简单
- 描述:仅用EEF delta + 旋转向量 + pad-to-dual,未像Being-H0.5那样设计语义对齐的槽位空间
- 原因:依赖EEF表示简化了问题,但牺牲了关节空间信息
- 影响:某些需要关节空间控制的任务可能受限
- 可能的解决方案:增加关节空间动作表示作为补充
局限3:3D模块增加推理延迟
- 描述:VGGT和Qwen-Image-Edit的额外推理可能影响实时性
- 原因:多模型串联推理
- 影响:高频率控制场景可能受影响
- 可能的解决方案:3D特征缓存、模型蒸馏
适用性与场景分析
适用场景
-
场景1:仿真环境下的跨本体VLA研究
- 适用原因:纯开源数据+仿真基准SOTA
- 预期效果:可直接复现和比较
- 注意事项:真实部署需额外验证
-
场景2:高维动作空间(灵巧手/人形)的VLA训练
- 适用原因:AML在大chunk和高DoF下优势显著
- 预期效果:比传统ε-pred更稳定
- 注意事项:需确认EEF表示可覆盖目标平台
不适用场景
- 场景1 :需要关节空间精确控制的工业应用
- 不适用原因:仅EEF表示可能不够
- 替代方案:Being-H0.5的统一动作空间包含关节位置
与相关论文对比
对比论文选择依据
选择在AML动作预测范式、开源数据整合、3D感知注入等维度上最相关的工作。
Being-H0.5 - Scaling Human-Centric Robot Learning for Cross-Embodiment Generalization
方法对比
| 对比维度 | Being-H0.5 | ABot-M0 |
|---|---|---|
| 数据来源 | 35K小时,含16K人类数据+私有数据 | 9.5K小时,纯开源6数据集 |
| 动作空间 | 统一语义对齐槽位空间 | EEF delta + 旋转向量 + pad-to-dual |
| 动作预测 | Flow-Matching (v-pred) | Action Manifold Learning (a-pred) |
| 3D感知 | 纯RGB | 可选VGGT+多视角合成 |
| 部署鲁棒性 | MPG+UAC | 未涉及 |
| 真实机器人 | 5种平台 | 无 |
| VLM骨干 | InternVL-3.5 | Qwen3-VL 4B |
性能对比
| 基准 | Being-H0.5 | ABot-M0 |
|---|---|---|
| LIBERO | 98.9% | 98.6% |
| RoboCasa | 53.9% | 58.3% |
关系分析
- 关系类型:对比/互补
- Being-H0.5优势:人类数据预训练+真实机器人部署+MPG/UAC部署鲁棒性
- ABot-M0优势:AML动作预测范式更高效+3D感知模块+纯开源数据+RoboCasa更高
- 互补性:AML可替换Being-H0.5的v-pred;Being-H0.5的MPG/UAC可补足ABot-M0的部署缺失
π₀ / π₀.5 - Physical Intelligence
方法对比
| 对比维度 | π₀/π₀.5 | ABot-M0 |
|---|---|---|
| 动作预测 | ε-pred/v-pred | a-pred (AML) |
| 数据 | 私有数据 | 纯开源 |
| 3D感知 | 无 | 可选VGGT |
关系分析
- 关系类型:改进
- 本文改进:AML范式替代ε-pred/v-pred,开源数据替代私有数据
Open X-Embodiment - 数据基础
关系分析
- 关系类型:继承/扩展
- OXE是UniACT-dataset的核心组成部分(67%数据量),ABot-M0在其基础上增加数据清洗和标准化
对比总结
ABot-M0的核心差异化在于动作流形学习(AML)范式 和纯开源数据路线。AML在理论上有力地论证了直接预测动作的优越性,在极端配置下的消融实验提供了强实证。但在真实机器人部署和统一动作空间的深度设计上不及Being-H0.5。
技术路线定位
所属技术路线
本文属于开源数据驱动的系统工程VLA技术路线,核心特点是:
- 特点1:纯开源数据整合,无需私有数据
- 特点2:动作流形学习(AML),直接预测动作替代噪声预测
- 特点3:模块化3D感知注入,即插即用
- 特点4:数据工程+架构设计+训练策略三正交改进
技术路线发展历程
RT-1/RT-2 (2023) → OpenVLA (2024) → π₀ (2024) → GR00T-N1 (2025) → ABot-M0 (2026)
OXE数据训练 开源VLA ε-pred范式 v-pred范式 a-pred/AML范式
Flow-Matching DiT+Flow 直接预测动作本文在技术路线中的位置
- 承上:继承了π₀/GR00T的DiT+Flow-Matching架构,吸收了JiT的直接预测思想
- 启下:AML范式可能成为扩散VLA的新标准,特别是在高维动作空间场景
- 关键节点:首次系统性论证"预测动作 > 预测噪声"并在多基准验证
具体子方向
本文主要关注动作预测范式革新,该子方向的研究重点是:
- 重点1:如何设计更高效的VLA动作预测目标
- 重点2:如何在高维动作空间中保持策略稳定性
- 重点3:如何通过系统工程弥补数据差距
未来工作建议
作者建议的未来工作
- 扩展到更多传感器模态 :触觉反馈、力传感等
- 可行性:高(模块化架构支持)
- 价值:提升精细操作能力
- 难度:数据采集成本
基于分析的未来方向
-
方向1:AML + 真实机器人部署
- 动机:当前仅在仿真中验证,真实部署是关键缺口
- 可能的方法:结合Being-H0.5的MPG/UAC机制
- 预期成果:AML在真实环境中的鲁棒性验证
- 挑战:仿真到真实迁移
-
方向2:AML与统一语义动作空间结合
- 动机:当前仅用EEF delta,缺少关节空间和语义对齐
- 可能的方法:将AML与Being-H0.5的槽位空间结合
- 预期成果:更强大的跨本体泛化
- 挑战:两种范式的设计冲突
-
方向3:3D模块的轻量化
- 动机:VGGT+Qwen-Image-Edit增加推理延迟
- 可能的方法:3D特征蒸馏到VLM内部
- 预期成果:保持3D感知但减少延迟
- 挑战:知识蒸馏效果
改进建议
-
改进1:增加真实机器人实验
- 当前问题:仅有仿真结果,无法验证真实部署
- 改进方案:在Franka等常见平台上验证
- 预期效果:增强论文说服力
-
改进2:AML与v-pred的更深入对比
- 当前问题:消融仅对比GR00T,未与π₀.5/Being-H0.5的v-pred对比
- 改进方案:统一骨干下对比AML vs v-pred
- 预期效果:更公正的范式比较
我的综合评价
价值评分
总体评分
8.7/10 --- AML动作预测范式是重要创新,纯开源数据路线降低了VLA研究门槛。但缺少真实机器人实验和深层动作空间设计是明显短板。
分项评分
| 评分维度 | 分数 | 评分理由 |
|---|---|---|
| 创新性 | 8/10 | AML动作流形假设新颖且有理论支撑,3D注入模块化设计好。扣分:整体架构仍基于VLM+DiT范式 |
| 技术质量 | 8/10 | AML数学推导清晰,数据工程系统性。扣分:真实部署机制缺失,动作空间设计较简单 |
| 实验充分性 | 8/10 | 4个仿真基准全面评估,消融覆盖AML/VLM/3D三维度。扣分:无真实机器人实验 |
| 写作质量 | 9/10 | 结构清晰,中英双语注释便于理解,图表质量高 |
| 实用性 | 9/10 | 完全开源+纯开源数据,可复现性极强。AML在大chunk下优势显著有实用价值 |
重点关注
值得关注的技术点
- AML的动作流形假设------可能改变扩散VLA的训练范式
- chunk=30时AML vs GR00T的对比------强实证支持动作预测优越性
- VLM最后一层特征最有效------简化了VLA特征传递设计
- Task-Uniform采样------跨本体数据工程的最佳实践
需要深入理解的部分
- AML重加权损失 w ( τ ) = 1 ( 1 − τ ) 2 w(\tau) = \frac{1}{(1-\tau)^2} w(τ)=(1−τ)21 的理论推导
- Pad-to-Dual策略对双臂协调学习的影响
- VGGT 3D特征与VLM特征的Cross-Attention融合细节
- 数据清洗流水线中16%剔除率的具体分布
我的笔记
%% 用户可以在这里添加个人阅读笔记 %%
相关论文
直接相关
- Being-H0.5 - 同期最强跨本体VLA,v-pred vs a-pred范式对比,互补关系
- π₀.5 - ε-pred/v-pred基线,AML直接改进对象
- GraspVLA - 同为开源数据路线,合成数据 vs 真实开源数据
背景相关
- Open X-Embodiment - UniACT-dataset的核心数据来源
- AgiBot World - UniACT-dataset的高质量数据来源
- RoboTwin 2.0 - 评估基准之一
后续工作
- Qwen-VLA - 同期跨本体VLA,不同架构路线
- BORA - RL后训练可能增强AML在真实环境的表现
外部资源
- 开源代码(承诺发布,待确认链接)
💡 关键启示
动作流形假设指出:有效的机器人动作位于低维流形上,直接预测动作比预测噪声更高效------这为高维动作空间(灵巧手/人形)的VLA训练提供了新范式。
⚠️ 注意事项
- 所有实验仅在仿真环境中完成,无真实机器人验证
- 动作空间统一仅用EEF delta+旋转向量,不如Being-H0.5的语义对齐槽位空间深入
- 3D模块(VGGT+Qwen-Image-Edit)增加推理延迟,实时性影响未量化
📌 推荐指数
⭐⭐⭐⭐ 推荐阅读!AML动作流形学习是VLA训练范式的重要创新,纯开源数据路线降低了研究门槛。但需注意真实部署验证的缺失。
📝 本文为论文深度解读笔记,基于对原论文的系统性分析和思考撰写。
🏷️ 相关标签:论文笔记 VLA模型 跨本体学习 具身智能 机器人操作 Flow-Matching DiT 动作流形学习 3D感知 双臂操作 ABot-M0 UniACT-dataset Qwen3-VL VGGT pi0 pi0.5 OpenVLA-OFT GR00T-N1
💬 欢迎在评论区讨论交流!如果觉得有帮助,请点赞收藏~