1.图的基本概念
图是由顶点集合及顶点间的关系组成的一种数据结构:G=(V, E)。其中:
- 顶点集合V={x | x属于某个数据对象集}是有穷非空集合;
- E={(x,y)| x,y属于V }或者E={<x, y> | x,y 属于V && Path(x,y)}是顶点间关系的有穷集合,也叫做边的集合。
- (x, y)表示x到y的一条双向通路,即(x, y)是无方向的;Path(x, y)表示从x到y的一条单向通路,即Path(x,y)是有方向的。
顶点和边:图中的结点称为顶点,第i个顶点记作vi。两个顶点vi和vj相关联称作顶点vi和顶点vj之间有一条边,图中的低k条边记作ek,ek=(vi, vj)或<vi, vj>。
有向图和无向图:在有向图中,顶点对<x,y>是有序的,顶点对<x,y>称为顶点x到顶点y的一条边,<x,y>和<y,x>是两条不同的边,比如下图G3和G4为有向图。在无向图中,顶点对(x,y)是无序的,顶点对(x,y)称为顶点x和顶点y相关联的一条边,这条边没有特定方向,(x,y)和(y,x)是同一条边,比如下图G1和G2为无向图。无向边(x,y)等于有向边<x,y>和<y ,x>
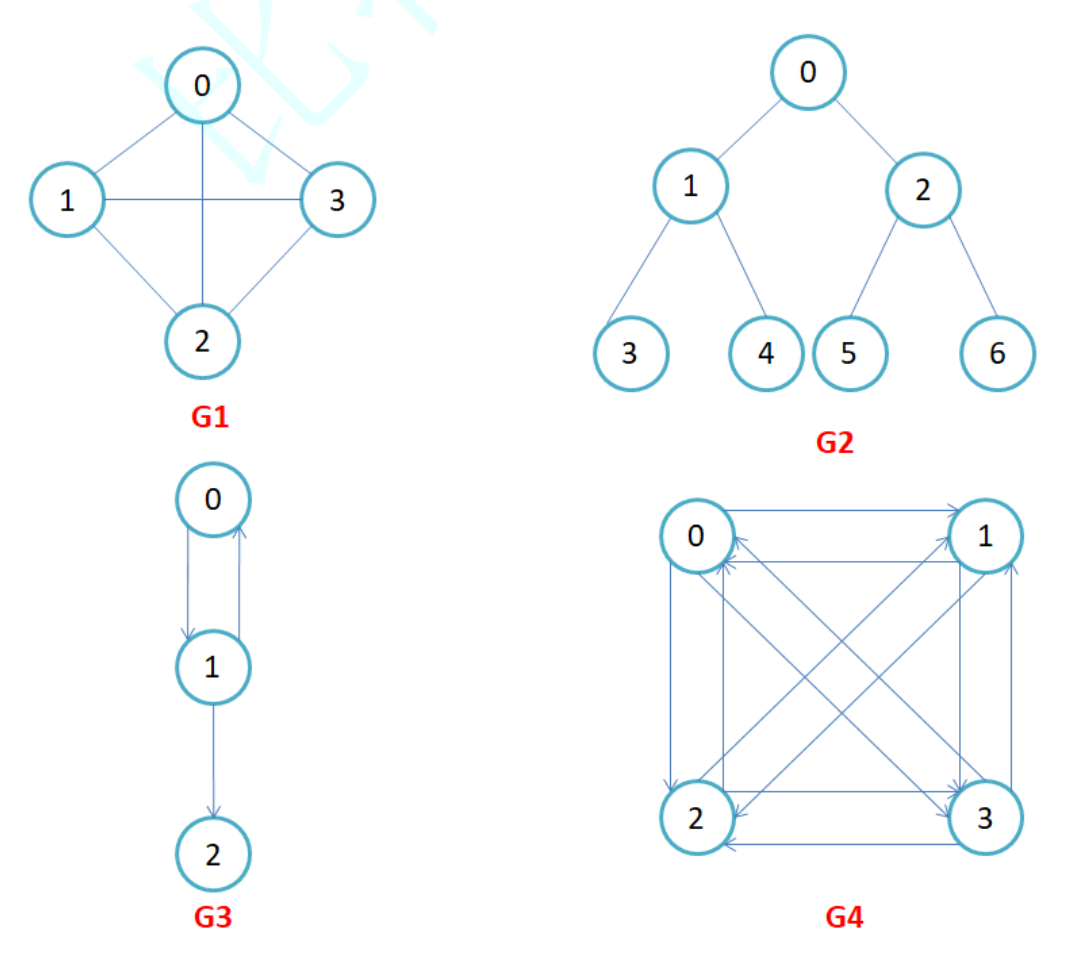
完全图:在n个顶点的无向图中,若有n*(n-1)/2条边,即任意两个顶点之间有且仅有一条边,则称此图为无向完全图,比如上图G1;在n个顶点的有向图中,若有n*(n-1)条边,即任意两个顶点之间有且仅有方向相反的边,则称此图为有向完全图,如上图G4。
邻接顶点:在无向图G中,若(u,v)是E(G)中的一条边,则称u和v互为邻接顶点,并称边(u,v)依附于顶点u和v;在有向图G中,若<u,v>是E(G)中的一条边,则称顶点u邻接到了v,顶点v邻接自顶点u,并称边<u,v>与顶点u和顶点v相关联。
顶点的度 :顶点v的度是指与它相关联的边的条数,记作deg(v)。在有向图中 ,顶点的度等于该顶点的入度和出度之和,其中顶点v的入度是以v为终点的有向边的条数,记作indev(v);顶点v的出度是以v为起始点的有向边的条数,记作outdev(v)。因此:dev(v) = indev(v) + outdev(v)。注意:对于无向图,顶点的度就是与该顶点相关联的边的条数。
路径:在图G=(V, E)中,若从顶点vi出发有一组边使其可到达顶点vj,则称顶点vi到顶点vj的顶点序列从顶点vi到顶点vj的路径。
路径长度:对于不带权的图,一条路径的长度是指该路径上的边的条数;对于带权的图一条路径的路径长度是指该路径上各个边权值的总和。
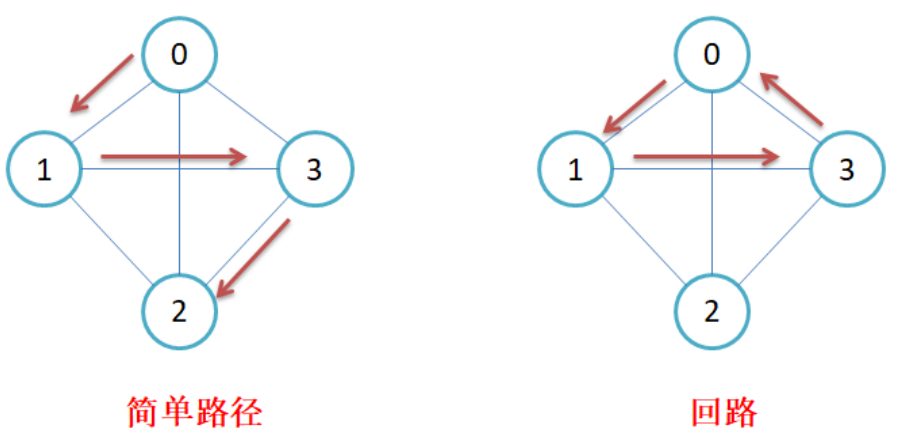
简单路径与回路:若路径上各顶点v1,v2,v3...vm均不重复,则称这样的路径为简单路径。若路径上第一个顶点v1和最后一个顶点vm重合,则称这样的路径为回路或环。
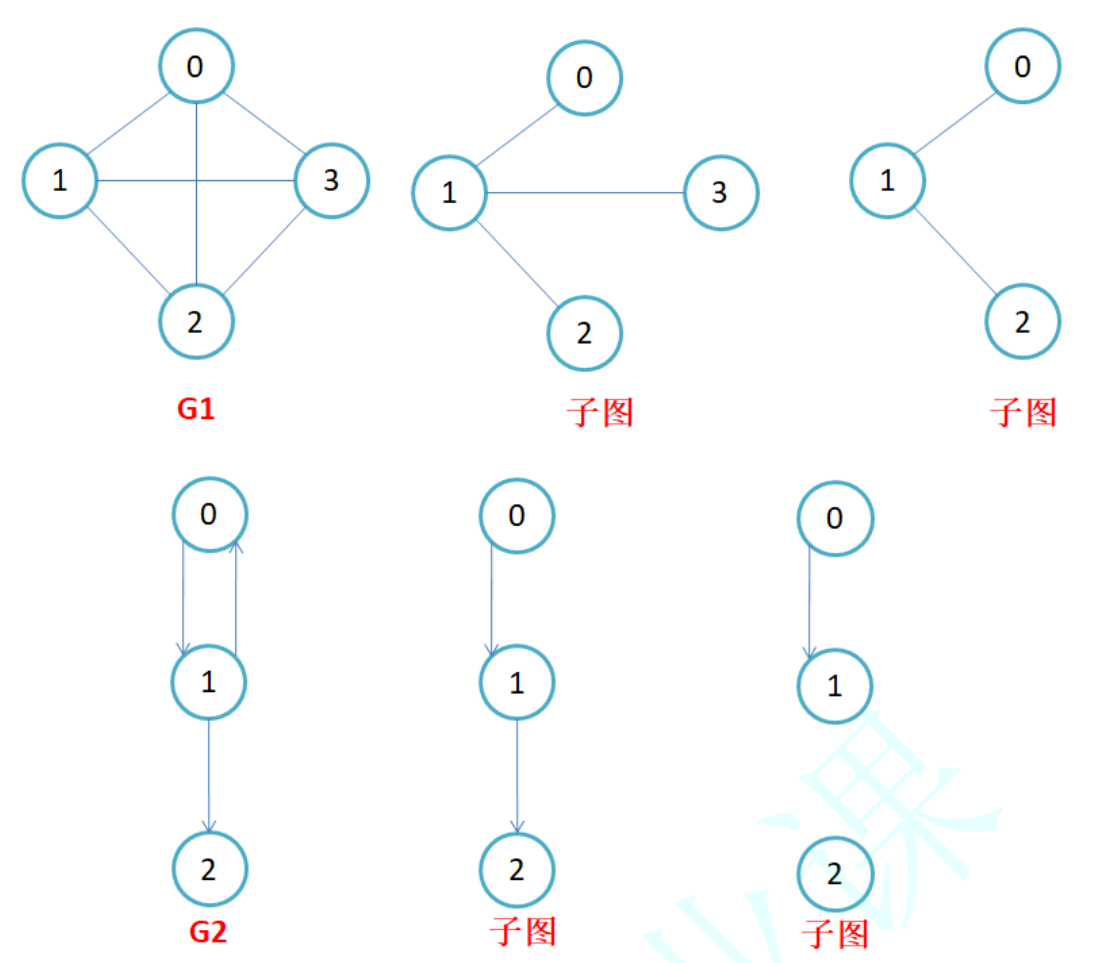
子图:设图G={V,E}和图G1={V1, E1},若V1属于V且E1属于E,则称G1是G的子图。
连通图:在无向图中,若从顶点v1到顶点v2有路径,则称顶点v1与v2是联通的。如果图中任意一对顶点都是连通的,则称此图为连通图。
强连通图:在有向图中,若在每一对顶点vi和vj之间都存在一条从vi到vj的路径,也存在一条vj到vi的路径,则称此图是强连通图。
生成树: 一个连通图的包含所有顶点的最小连通子图称作该图的生成树。有n个顶点的连通图的生成树有n个顶点和n-1条边。
2.图的存储结构
因为图中既有节点又有边,因此,在图的存储中只需要保存:节点和边的关系即可。节点保存比较简单,只需要一段连续空间即可,那边关系该怎么保存呢?
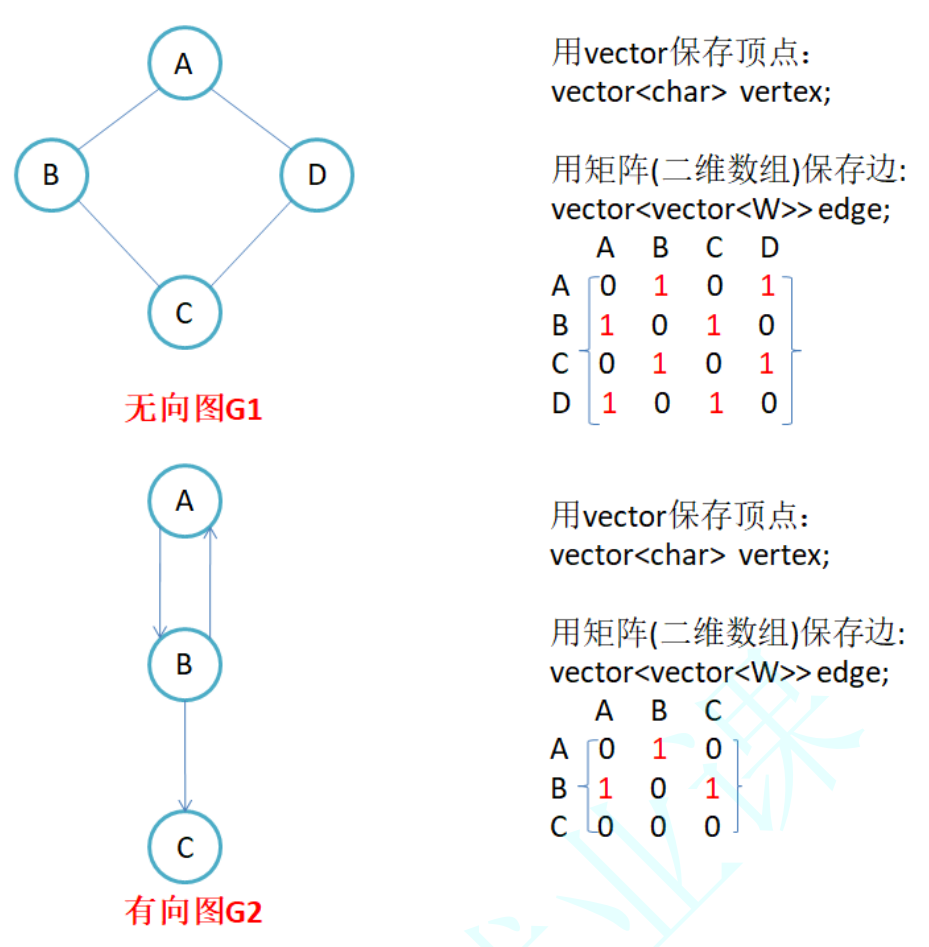
2.1 邻接矩阵
因为节点与节点之间1的关系就是连通与否,即为0或者1,因此邻接矩阵(二维数组)即使:先用一个数组将顶点保存,然后采用矩阵来表示节点与节点之间的关系。
注意:
- 无向图的邻接矩阵是对称的,第i行(列)元素之和,就是顶点i的度。有向图的邻接矩阵则不一定是对称的,第i行(列)元素之后就是顶点i的出(入)度。
- 如果边带有权值,并且两个节点之间是连通的,上图中的边的关系就用权值代替,如果两个顶点不通,则用无穷大代替。
- 用邻接矩阵存储图的优点是快速知道两个顶点是否连通,缺点是如果顶点比较多,边比较少时,矩阵中存储了大量的0成为系数矩阵,比较浪费空间,并且要求两个节点之间的路径不是很好求。
下面是写的邻接矩阵的代码:
cpp
#pragma once
#include<iostream>
#include<vector>
#include<map>
using namespace std;
namespace matrix//邻接矩阵
{
template<class V, class W, W MAX_W = INT_MAX, bool Direction = false>//V是节点的类型,W是边的权值的类型,MAX_W是定义两个节点不通,
class Graph //Direction是有向图还是无向图
{
public:
typedef Graph<V, W, MAX_W, Direction> Self;
Graph() = default;
Graph(const V* a, size_t n)//n个顶点初始化
{
_vertexs.reserve(n);
for (size_t i = 0; i < n; i++)
{
_vertexs.push_back(a[i]);//顶点
_indexMap[a[i]] = i; //顶点映射下标
}
_matrix.resize(n);//给邻接矩阵开辟空间,不能预留
for (size_t i = 0; i < _matrix.size(); i++)
{
_matrix[i].resize(n, MAX_W);//初始化所有顶点不可达
}
}
size_t GetVertexIndex(const V& v)//查找这个元素在顶点集合中的下标
{
auto it = _indexMap.find(v);
if (it != _indexMap.end())
{
return it->second;
}
else
{
throw invalid_argument("顶点不存在");//不存在就抛异常
return -1;
}
}
//以加边的方式写入到邻接矩阵中
void _AddEdge(size_t srci, size_t dsti, const W& w)
{
_matrix[srci][dsti] = w;
//如果矩阵是无向图对称的地方也得加权值
if (Direction == false)
{
_matrix[dsti][srci] = w;
}
}
void AddEdge(const V& src, const V& dst, const W& w)
{
size_t srci = GetVertexIndex(src);//获取元素顶点对应的下标
size_t dsti = GetVertexIndex(dst);
_AddEdge(srci, dsti, w);
}
void Print()
{
//顶点
for (size_t i = 0; i < _vertexs.size(); i++)
{
cout << "[" << i << "]" << "->" << _vertexs[i] << endl;
}
cout << endl;
//矩阵
//横下标
cout << " ";
for (size_t i = 0; i < _vertexs.size(); i++)
{
printf("%4d", i);
}
cout << endl;
for (size_t i = 0; i < _matrix.size(); i++)
{
//打印竖下标
cout << i << " ";
for (size_t j = 0; j < _matrix[i].size(); j++)
{
if (_matrix[i][j] == MAX_W)
{
printf("%4c", '*');
}
else
{
printf("%4d", _matrix[i][j]);
}
}
cout << endl;
}
cout << endl;
}
private:
vector<V> _vertexs; //顶点的集合
map<V, size_t> _indexMap; //顶点映射下标
vector<vector<W>> _matrix; //存储边集合的矩阵
};
void TestGraph1()
{
Graph<char, int, INT_MAX, true> g("0123", 4);
g.AddEdge('0', '1', 1);
g.AddEdge('0', '3', 4);
g.AddEdge('1', '3', 2);
g.AddEdge('1', '2', 9);
g.AddEdge('2', '3', 8);
g.AddEdge('2', '1', 5);
g.AddEdge('2', '0', 3);
g.AddEdge('3', '2', 6);
g.Print();
}
}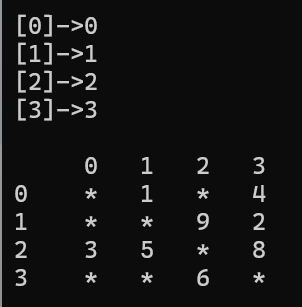
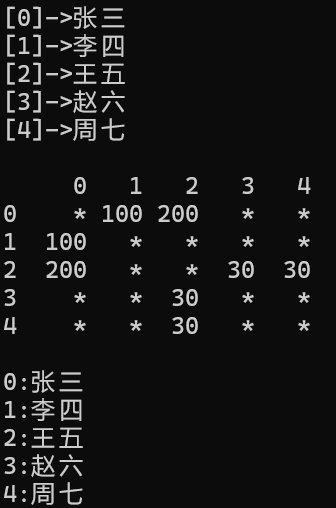
测试的结果如图所示
2.2 邻接表
邻接表:使用数组表示顶点的集合,使用链表表示边的关系。
- 无向图邻接表存储
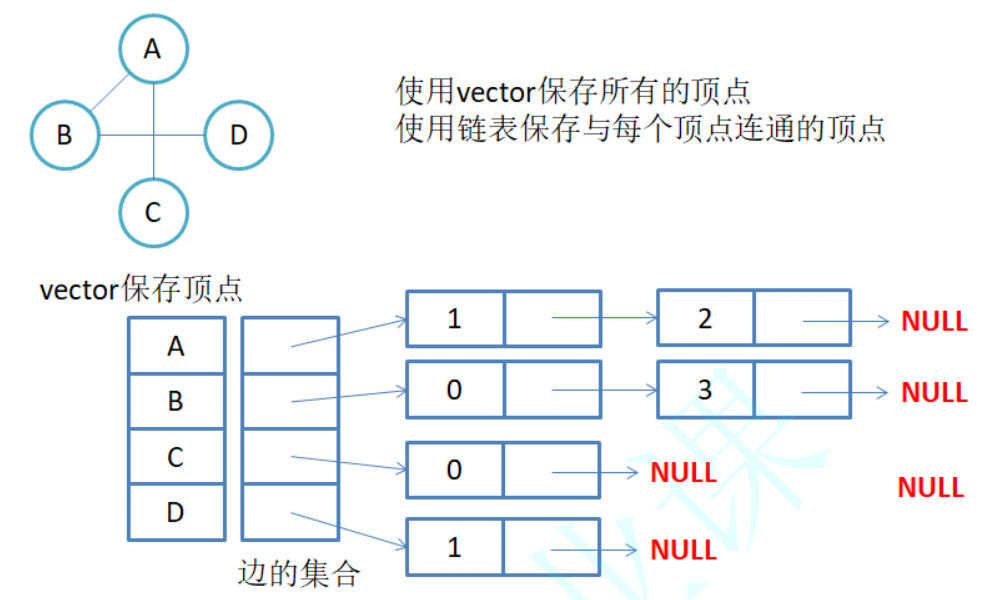
注意:无向图中同一条边在邻接表中出现了两次,如果想知道顶点vi的度,只需要知道顶点vi边链表集合中结点的数目即可。
- 有向图邻接表存储
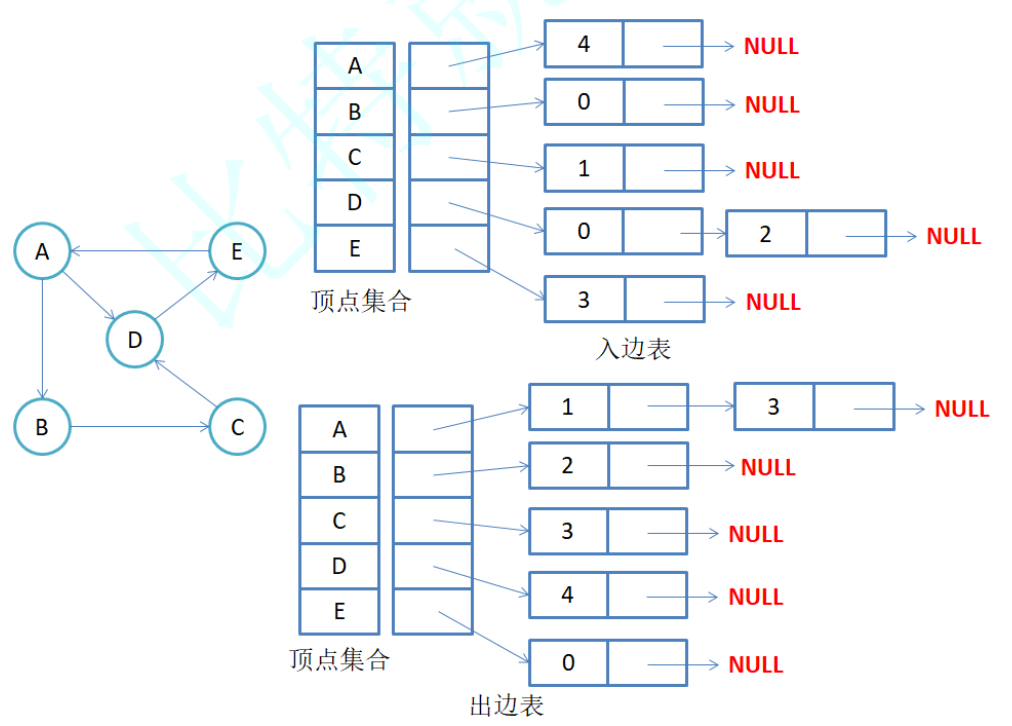
注意:有向图中每条边在邻接表中只出现一次,与顶点vi对应的邻接表所含结点的个数就是该顶点的出度,也称出度表,要得到vi顶点的入度,必须检测其他所有顶点对应的边链表,看有多少边顶点的dst取值是i。
cpp
namespace LinkTable
{
template<class W>//W权值的类型
struct Edge//存储边,其实就是邻接表的节点
{
int _dsti; //目标点的下标
W _w; //权值
Edge<W>* _next;
Edge(int dsti, const W& w)
:_dsti(dsti)
,_w(w)
,_next(nullptr)
{}
};
template<class V, class W, bool Direction = false>
class Graph
{
typedef Edge<W> Edge;
public:
Graph(V* a, size_t n)
{
_vertexs.reserve(n);
for (size_t i = 0; i < n; i++)
{
_vertexs.push_back(a[i]);
_indexMap[a[i]] = i;
}
_tables.resize(n, nullptr);
}
size_t GetVertexIndex(const V& v)
{
auto it = _indexMap.find(v);
if (it != _indexMap.end())
{
return it->second;
}
else
{
throw invalid_argument("顶点不存在");
return -1;
}
}
void AddEdge(const V& src, const V& dst, const W& w)
{
size_t srci = GetVertexIndex(src);
size_t dsti = GetVertexIndex(dst);
//头插
Edge* eg = new Edge(dsti, w);//目标点和权值创建一条边
eg->_next = _tables[srci];
_tables[srci] = eg;
//无向图
if (Direction == false)
{
Edge* eg1 = new Edge(srci, w);
eg1->_next = _tables[dsti];
_tables[dsti] = eg1;
}
}
void Print()
{
//顶点
for (size_t i = 0; i < _vertexs.size(); ++i)
{
cout << "[" << i << "]" << _vertexs[i] << endl;
}
cout << endl;
for (size_t i = 0; i < _tables.size(); i++)
{
cout << _vertexs[i] << "[" << i << "]->";
Edge* cur = _tables[i];
while (cur)
{
cout << "[" << _vertexs[cur->_dsti] << ":" << cur->_dsti << ":" << cur->_w << "]->";
cur = cur->_next;
}
cout << "nullptr " << endl;
}
}
private:
vector<V> _vertexs; //顶点的集合
map<V, size_t> _indexMap; //顶点映射下标
vector<Edge*> _tables; //邻接表
};
void TestGraph()
{
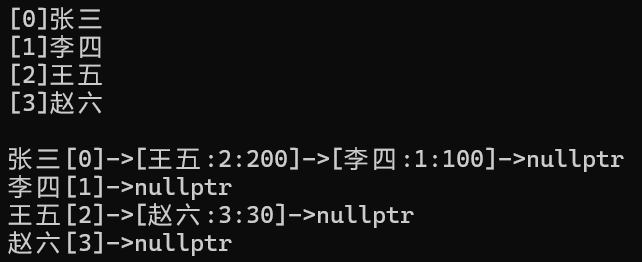
string a[] = { "张三", "李四", "王五", "赵六" };
Graph<string, int, true> g1(a, 4);
g1.AddEdge("张三", "李四", 100);
g1.AddEdge("张三", "王五", 200);
g1.AddEdge("王五", "赵六", 30);
g1.Print();
}
}
3.图的遍历
给定一个图G和其中任意一个顶点v0,从v0出发,沿着图中各边访问图中的所有顶点,且每个顶点仅被遍历一次。"遍历"即对结点进行某种操作的意思。
3.1 图的广度优先遍历
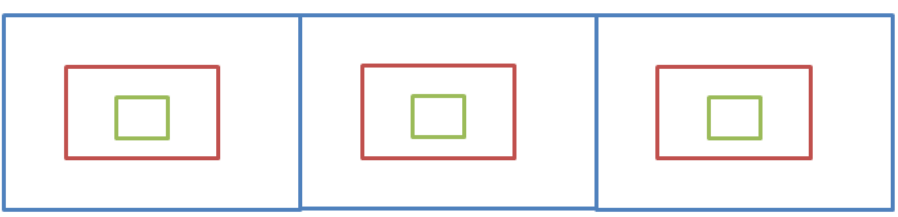
比如现在要找东西,假设有三个抽屉,东西在那个抽屉不清楚,现在要将其找到,广度优先遍历的做法是:
- 先将三个抽屉打开,在最外层找一遍
- 将每个抽屉中红色盒子打开,再找一遍
- 将红色盒子中绿色盒子打开,再找一遍
直到找完所有的盒子,每个盒子只能找一次,不能重复找
cpp
void BFS(const V& src)
{
size_t srci = GetVertexIndex(src);
//队列和标记数组
queue<int> q;
vector<bool> visited(_vertexs.size(), false);
q.push(srci);
visited[srci] = true;
size_t n = _vertexs.size();
while (!q.empty())
{
int front = q.front();
q.pop();
cout << front << ":" << _vertexs[front] << endl;
for (size_t i = 0; i < n; i++)
{
if (_matrix[front][i] != MAX_W && visited[i] == false)
{
q.push(i);
visited[i] = true;
}
}
}
cout << endl;
}
void TestBDFS()
{
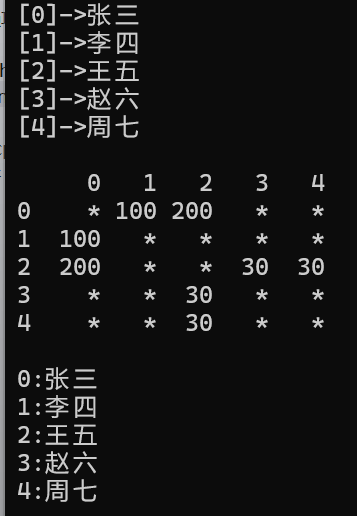
string a[] = { "张三", "李四", "王五", "赵六", "周七" };
Graph<string, int> g1(a, sizeof(a) / sizeof(string));
g1.AddEdge("张三", "李四", 100);
g1.AddEdge("张三", "王五", 200);
g1.AddEdge("王五", "赵六", 30);
g1.AddEdge("王五", "周七", 30);
g1.Print();
g1.BFS("张三");
}
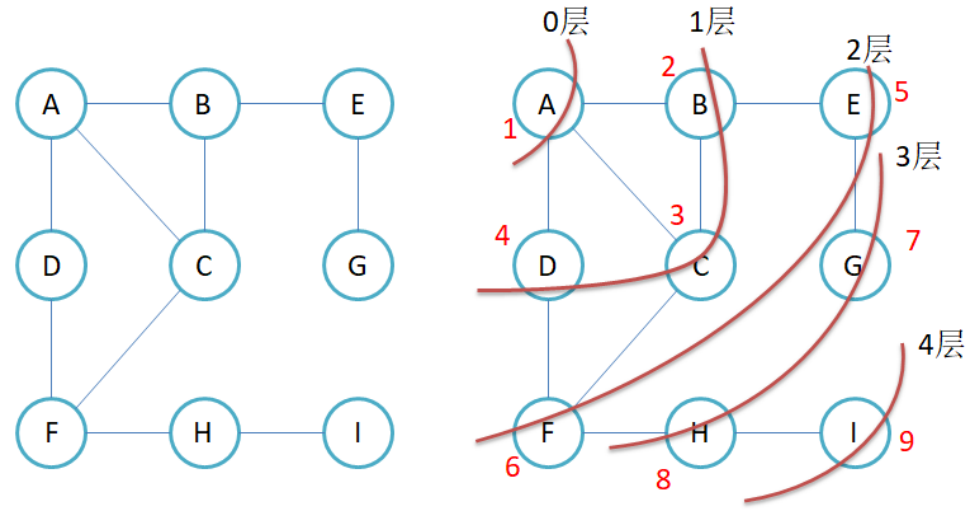
上面所示就是BFS的代码,下面有一道美团2020年的笔试题,六度人脉理论
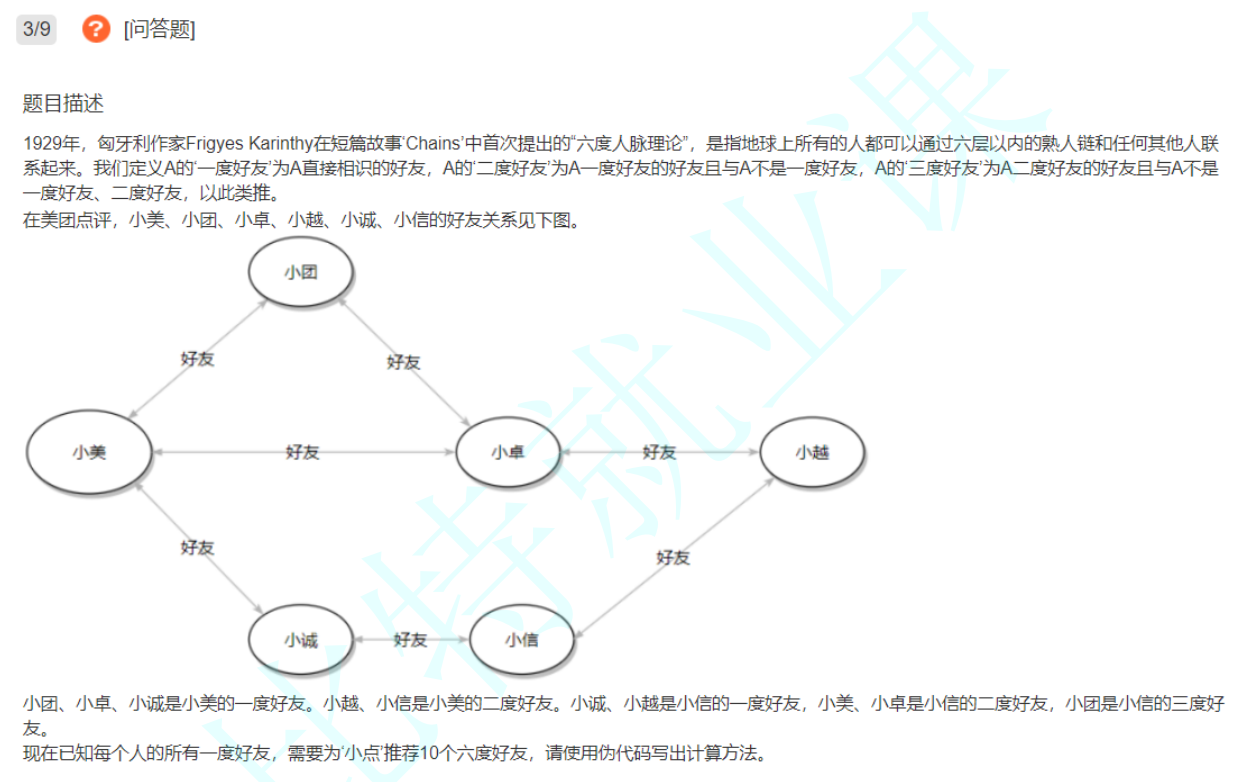
六度人脉的写法,控制层数为6层
cpp
//六度人脉理论使用BFS
void BFS(const V& src)
{
size_t srci = GetVertexIndex(src);
//队列和标记数组
queue<int> q;
vector<bool> visited(_vertexs.size(), false);
int levelsize = 1;//每一层的个数
int level = 0;//控制六层
q.push(srci);
visited[srci] = true;
size_t n = _vertexs.size();
while (!q.empty() && level < 6)
{
//一层一层的出
for (int i = 0; i < levelsize; i++)
{
int front = q.front();
q.pop();
cout << front << ":" << _vertexs[front] << " ";
for (size_t i = 0; i < n; i++)
{
if (_matrix[front][i] != MAX_W && visited[i] == false)
{
q.push(i);
visited[i] = true;
}
}
}
cout << endl;
levelsize = q.size();
level++;
}
cout << endl;
}3.2 图的深度优先遍历

比如现在要找东西,假设有三个抽屉,东西在那个抽屉不清楚,现在要将其找到,深度优先遍历的做法是:将一个抽屉一次性遍历完(包括抽屉中包含的小盒子),再去递归遍历其他盒子。
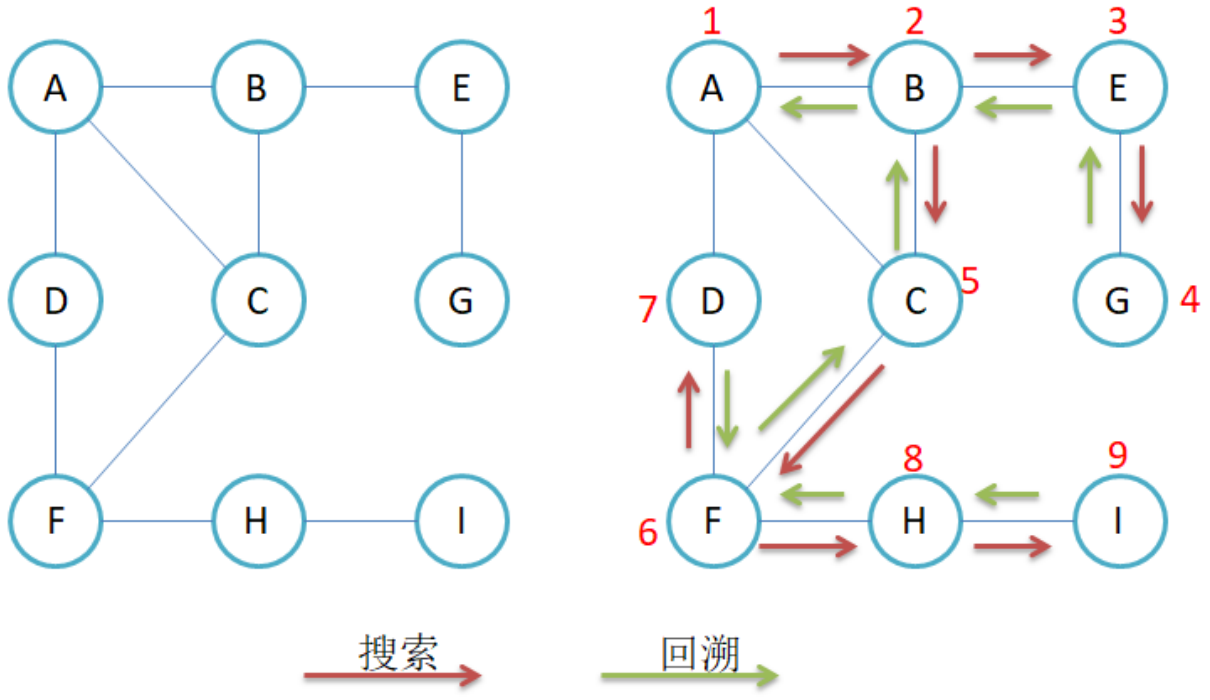
cpp
void _DFS(size_t srci, vector<bool>& visited)
{
cout << srci << ":" << _vertexs[srci] << endl;
visited[srci] = true;
//找一个srci相邻的没有访问过的结点,深度遍历
for (size_t i = 0; i < _vertexs.size(); i++)
{
if (_matrix[srci][i] != MAX_W && visited[i] == false)
{
_DFS(i, visited);
}
}
}
void DFS(const V& src)
{
size_t srci = GetVertexIndex(src);
vector<bool> visited(_vertexs.size(), false);
_DFS(srci, visited);
}
4.最小生成树
连通图中的每一棵生成树,都是原图的一个极大无环子图,即:从其中删去任何一条边,生成树就不在连通;反之,在其中引入任何一条新边,都会形成一条回路。
若连通图由n个顶点组成,则其生成树必定含有n个顶点和n-1条边。因此构造最小生成树的准则有三条:
- 只能使用图中的边来构造最小生成树
- 只能使用恰好n-1条边来连接图中的n个顶点
- 选用的n-1条边不能构成回路
构造最小生成树的方法:Kruskal和Prim算法。这两个算法都采用了逐步求解的贪心策略。
贪心算法:是指在问题求解时,总是做出当前看起来最好的选择。也就是说贪心算法做出的不是整体最优的选择,而是某种意义上的局部最优解。贪心算法不是对所有的问题都能得到整体最优解。
4.1 Kruskal算法
任给一个有n个顶点的连通网络N={V, E},
首先构造一个由着n个顶点组成,不含任何边的图G={V , NULL},其中每个顶点自成一个连通分量,其次不断从E中取出权值最小的一条边(若有多条任取其一),若该边的两个顶点来自不同的连通分量,则将此边加入到G中。如此重复,直到所有顶点在同一个连通分量上为止。
核心:每次迭代时,选出一条具有最小权值,且两端点不在同一连通分量上的边,加入生成树。
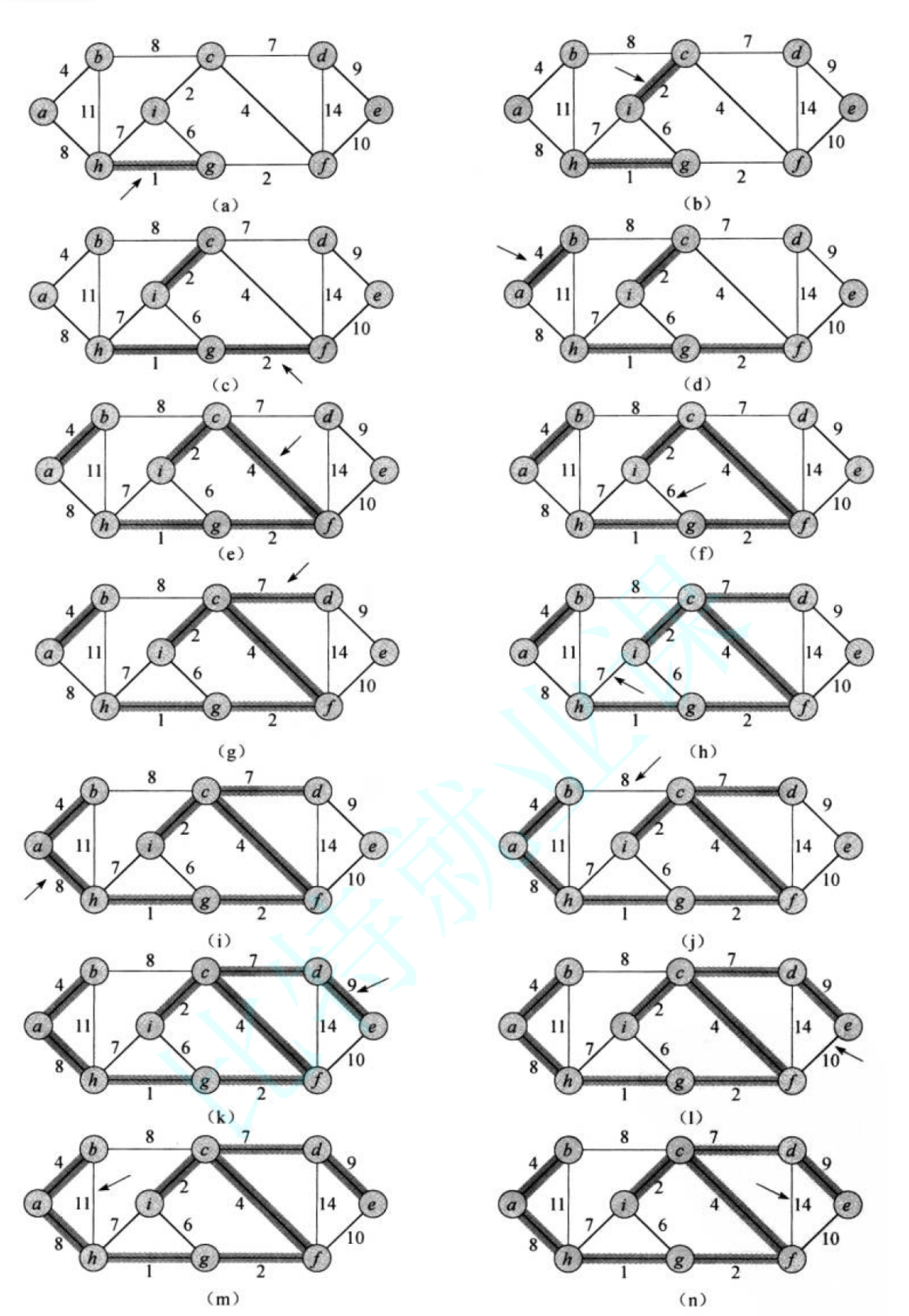
执行Kruskal算法的过程。加了阴影的边属于不断增长的森林A。该算法按照边的权重大小依次进行考虑。箭头指向的边是算法每一步所考察的边。如果该条边将两棵不同的树连接起来,它就被加入到森林里,从而完成对两棵树的合并。
cpp
struct Edge
{
size_t _srci;
size_t _dsti;
W _w;
Edge(size_t srci, size_t dsti, const W& w)
:_srci(srci)
,_dsti(dsti)
,_w(w)
{}
bool operator>(const Edge& e) const//重载>,使用堆来存放最小值
{
return _w > e._w;
}
};
W Kruskal(Self& mintree)
{
size_t n = _vertexs.size();
mintree._vertexs = _vertexs;
mintree._indexMap = _indexMap;
mintree._matrix.resize(n);
for (size_t i = 0; i < n; i++)
{
mintree._matrix[i].resize(n, MAX_W);//每行开n个空间,并用MAX_W初始化
}
priority_queue<Edge, vector<Edge>, greater<Edge>> minque;
for (size_t i = 0; i < n; i++)
{
for (size_t j = 0; j < n; j++)
{
if (i < j && _matrix[i][j] != MAX_W)
{
minque.push(Edge(i, j, _matrix[i][j]));//将边入优先级队列中选出最小的边
}
}
}
UnionFind ufs(n);
size_t size = 0;
W totalW = W();//默认值
while (!minque.empty())
{
Edge top = minque.top();
minque.pop();
if (!ufs.InSet(top._srci, top._dsti))//如果这两个节点不在同一个并查集中就加入这条边
{
cout << _vertexs[top._srci] << "->" << _vertexs[top._dsti] << ":" << top._w << endl;
mintree._AddEdge(top._srci, top._dsti, top._w);
ufs.Union(top._srci, top._dsti);
size++;
totalW += top._w;
}
else
{
cout << "构成环:" << _vertexs[top._srci] << "->" << _vertexs[top._dsti] << ":" << top._w << endl;
}
}
if (size == n - 1)
{
return totalW;
}
else
{
return W();
}
}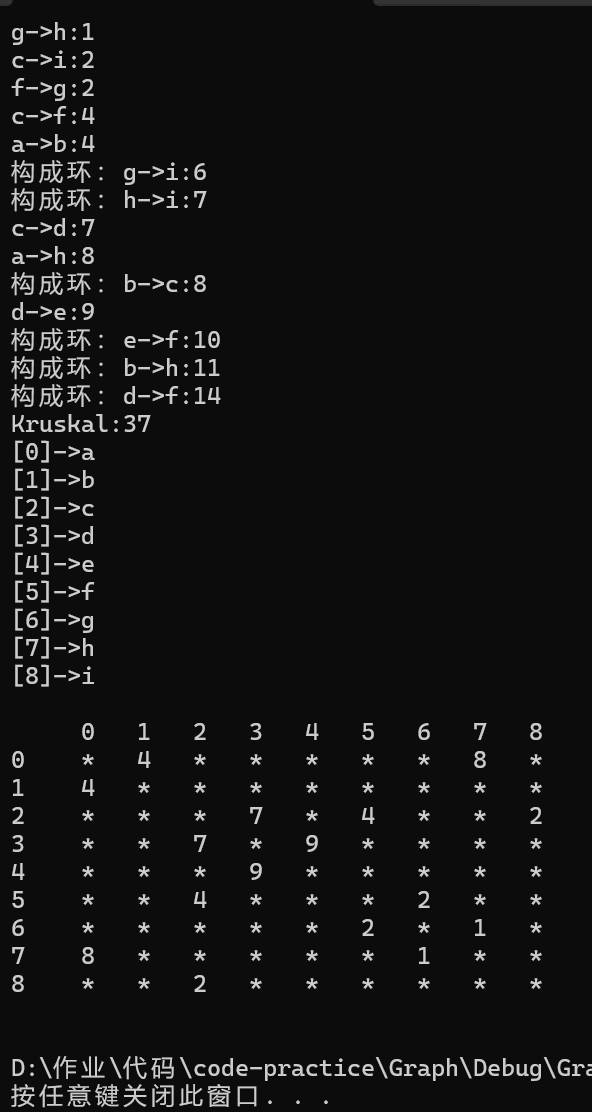
核心思想:全局贪心,每次从所有边种选择权值最小的边,只要不构成环就加入最小生成树,直到选满n-1条边。
关键问题:判环,使用并查集实现。
4.2 Prim算法
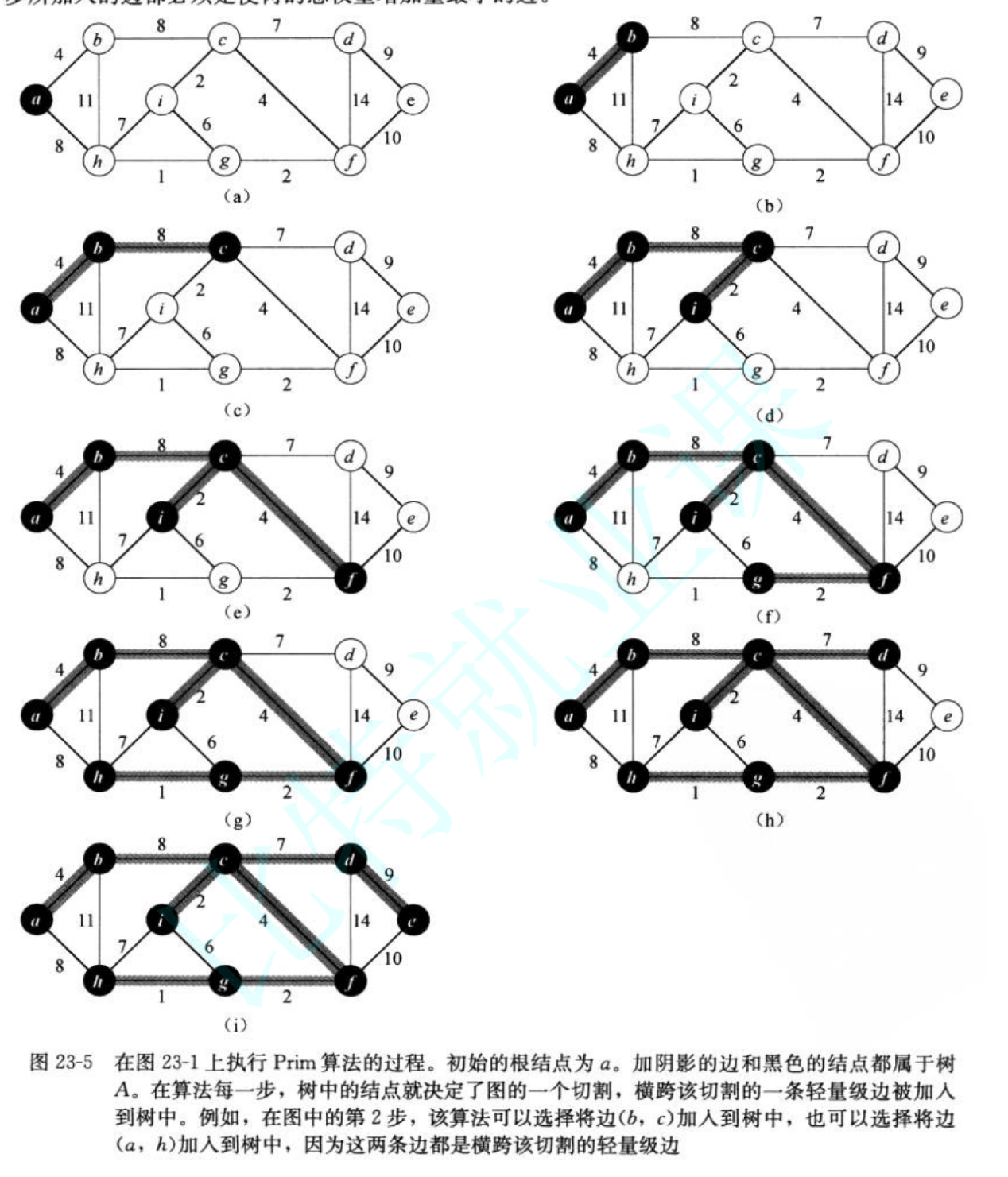
与Kruskal算法类似,Prim算法也是最小生成树算法的一个特例。Prim算法的工作原理与Dijkstra的最短路径算法相似。Prim算法所具有的一个性质是集合A中的边总是构成一棵树。这棵树从一个任意的根节点r开始,一直长大覆盖V中的所有结点为止。算法每一步在连接集合A和A之外的结点的所有边中,选择一条轻量级的边加入到A中。这条规则所加入的边都是对A安全的边。因此,当算法终止时,A中的边形成一棵最小生成树。本策略也属于贪心策略,因为每一步所加入的边都必须是使树的总权重增量最小的边。
cpp
W Prim(Self& mintree, const V& src)//Prim最小生成树
{
size_t n = _vertexs.size();
size_t srci = GetVertexIndex(src);
mintree._vertexs = _vertexs;
mintree._indexMap = _indexMap;
mintree._matrix.resize(n);
for (size_t i = 0; i < n; i++)//初始化
{
mintree._matrix[i].resize(n, MAX_W);
}
vector<bool> X(n, false);
vector<bool> Y(n, true);
X[srci] = true;//从这个点开始入X中
Y[srci] = false;//将Y中的点删去
//从X->Y集合中连接的边里面选出最小的边
priority_queue<Edge, vector<Edge>, greater<Edge>> minq;
for (size_t i = 0; i < n; i++)
{
if (_matrix[srci][i] != MAX_W)
{
//将srci连接的边加入队列中
minq.push(Edge(srci, i, _matrix[srci][i]));
}
}
cout << "Prim开始选边" << endl;
size_t size = 0;//记录多少个节点在X中
W total = W();//记录总权值
while (!minq.empty())
{
Edge min = minq.top();
minq.pop();
//最小的边的目标节点在X集合,则构成环
if (X[min._dsti] == true)
{
cout << "构成环:";
cout << _vertexs[min._srci] << "->" << _vertexs[min._dsti] << ":" << min._w << endl;
}
else
{
mintree._AddEdge(min._srci, min._dsti, min._w);//将最小的边加到生成树中
cout << _vertexs[min._srci] << "->" << _vertexs[min._dsti] << ":" << min._w << endl;
X[min._dsti] = true;
Y[min._dsti] = false;
total += min._w;
size++;
if (size == n - 1)
break;
for (size_t i = 0; i < n; i++)
{
if (_matrix[min._dsti][i] != MAX_W && Y[i] != false)//入队列的边存在,并且Y中的点还没有入队列
{
minq.push(Edge(min._dsti, i, _matrix[min._dsti][i]));
}
}
}
}
if (size == n - 1)
return total;
else
return W();
}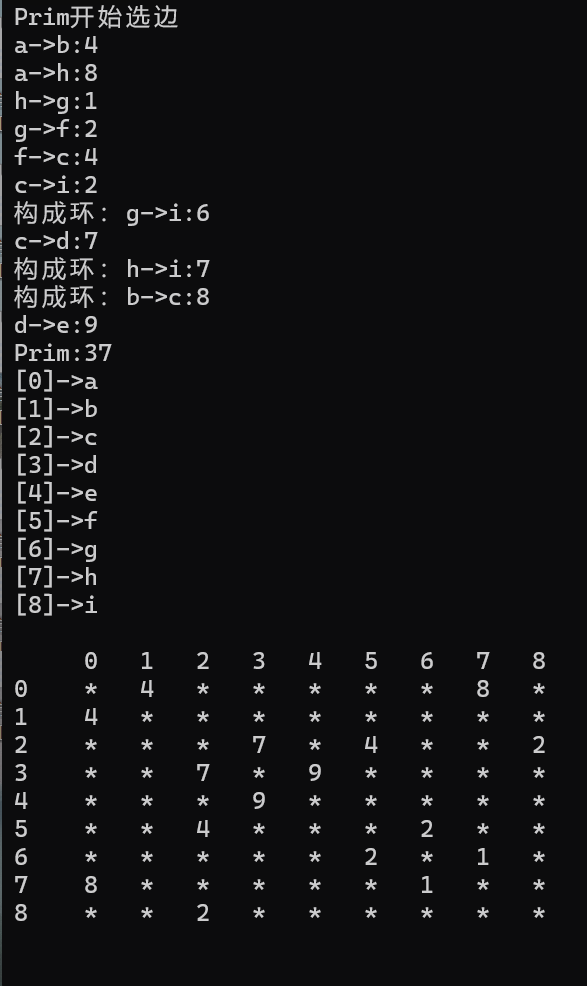
核心思想:局部贪心,将顶点分为两个集合:
- X集合:已加入最小生成树的顶点
- Y集合:未加入最小生成树的顶点
每次选择X和Y两个集合之间权值最小的边,将对应的Y集合顶点加入X集合,直到X集合包含所有顶点。
两个算法的对比
|-------|-------------------------|------------------------|
| 对比维度 | Prim算法 | Kruskal算法 |
| 贪心策略 | 局部贪心(两集合间选最小边) | 全局贪心(所有边中选最小边) |
| 操作对象 | 顶点 | 边 |
| 判环方式 | 天然无环,无需额外数据结构 | 必须使用并查集判环 |
| 适用场景 | 稠密图(边多) | 稀疏图(边少) |
| 时间复杂度 | 邻接矩阵O(n²),邻接表+堆O(mlogn) | 排序O(mlogm),并查集O(mα(n)) |
5.最短路径
最短路径问题:从在带权有向图G中的某一顶点出发,找到一条通往另一顶点的最短路径,也就是沿路径各边的权值总和到达最小。
5.1单源最短路径------Dijkstra算法
单源最短路径问题:给定一个图G=(V,E),求源节点sV到图中每个节点v
V的最短路径。Dijkstra算法适用于带权重的有向图上的单元最短路径问题,同时要求图中所有边的权重非负。一般在求解最短路径的时候都是已知一个起点和一个终点,所以使用Dijkstra算法求解后也就得到了所需起点到终点的最短路径。
针对一个带权有向图G,将所有结点分为两组S和Q,S是已经确定最短路径的结点集合,在初始时为空(初始时就可以将源节点s放入),Q为其余未确定最短路径的结点集合,**每次从Q中找出一个起点到该结点代价最小的节点u,将u从Q中移出,并放入S中,对u的每一个相邻结点v进行松弛操作。**松弛即对每一个相邻结点v,判断源节点s到结点u的代价与u到v的代价之和是否比原来s到v的代价更小,若代价比原来小则要将s到v的代价更新为s到u与u到v的代价之和,否则维持原样。如此循环直至集合Q为空,即所有结点都已经查找个一遍并且确定了最短路径,至于一些起点到达不了的结点在算法循环后其代价仍为初始设定的值,不发生变化。Dijkstra算法每次都是选择V-S中最小的路径节点来进行更新,并加入S中,所有该算法使用的是贪心策略。
Dijkstra算法存在的问题是不支持图中带负权路径,如果带有负权路径,则可能找不到一些路径的最短路径。
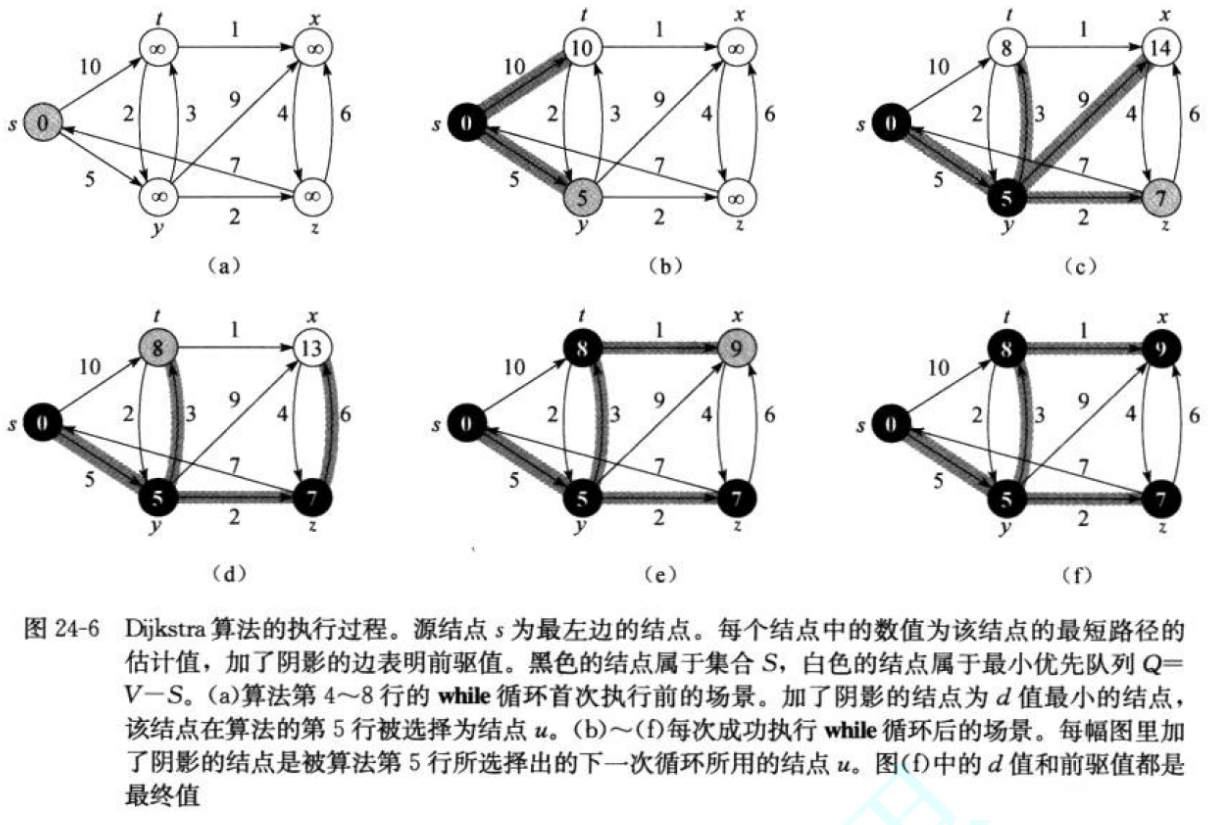
代码中需要有一个dist数组来存放这个点到其他点的最小路径,和一个ParentPath来存放这个节点的父节点下标。
cpp
void Dijkstra(const V& src, vector<W>& dist, vector<int>& ParentPath)
{
size_t srci = GetVertexIndex(src);
size_t n = _vertexs.size();
dist.resize(n, MAX_W);//记录当前点到其他点的最短距离
ParentPath.resize(n, -1);//记录父节点下标
dist[srci] = 0;//当前点到当前点的距离默认为0
ParentPath[srci] = srci;
//已经确定最短路径的顶点集合
vector<bool> S(n, false);
for (size_t i = 0; i < n; i++)//循环n次将n个点选入S中
{
//选最短路径顶点且不在S中更新其他路径
int u = 0;//选出路径最小的节点
W min = MAX_W;
for (size_t i = 0; i < n; i++)
{
if (S[i] == false && dist[i] < min)
{
u = i;
min = dist[i];
}
}
S[u] = true;//将选出的点放入S中
//松弛操作更新u链接的顶点v,srci->u + u->v 小于 srci->v 就更新
for (size_t v = 0; v < n; v++)
{
//当u连接的点不在S中,并且srci->u + u->v 小于 srci->v
if (S[v] == false && _matrix[u][v] != MAX_W && dist[u] + _matrix[u][v] < dist[v])
{
dist[v] = dist[u] + _matrix[u][v];
ParentPath[v] = u;
}
}
}
cpp
void TestGraphDijkstra()
{
const char* str = "syztx";
Graph<char, int, INT_MAX, true> g(str, strlen(str));
g.AddEdge('s', 't', 10);
g.AddEdge('s', 'y', 5);
g.AddEdge('y', 't', 3);
g.AddEdge('y', 'x', 9);
g.AddEdge('y', 'z', 2);
g.AddEdge('z', 's', 7);
g.AddEdge('z', 'x', 6);
g.AddEdge('t', 'y', 2);
g.AddEdge('t', 'x', 1);
g.AddEdge('x', 'z', 4);
vector<int> dist;
vector<int> parentPath;
g.Dijkstra('s', dist, parentPath);
g.PrintShortPath('s', dist, parentPath);
}
5.2单源最短路径------Bellman-Ford算法
Dijkstra算法只能用来解决正权图的单源最短路径问题,但是有些题目会出现负权图。这时这个算法就不能帮助我们解决问题了,而bellman-ford算法可以解决负权图的单源最短路径问题。它的优点时可以解决负权边的单源最短路径问题,而且可以用来判断是否有负权回路。它也有明显的缺点,它的时间复杂度O(N*E)(N是点数,E是边数)普遍是要高于Dijkstra算法的。像这里如果我们使用邻接矩阵实现,那么遍历所有边的数量的时间复杂度就是
,这里也可以看出Bellman-Ford就是一种暴力求解更新。
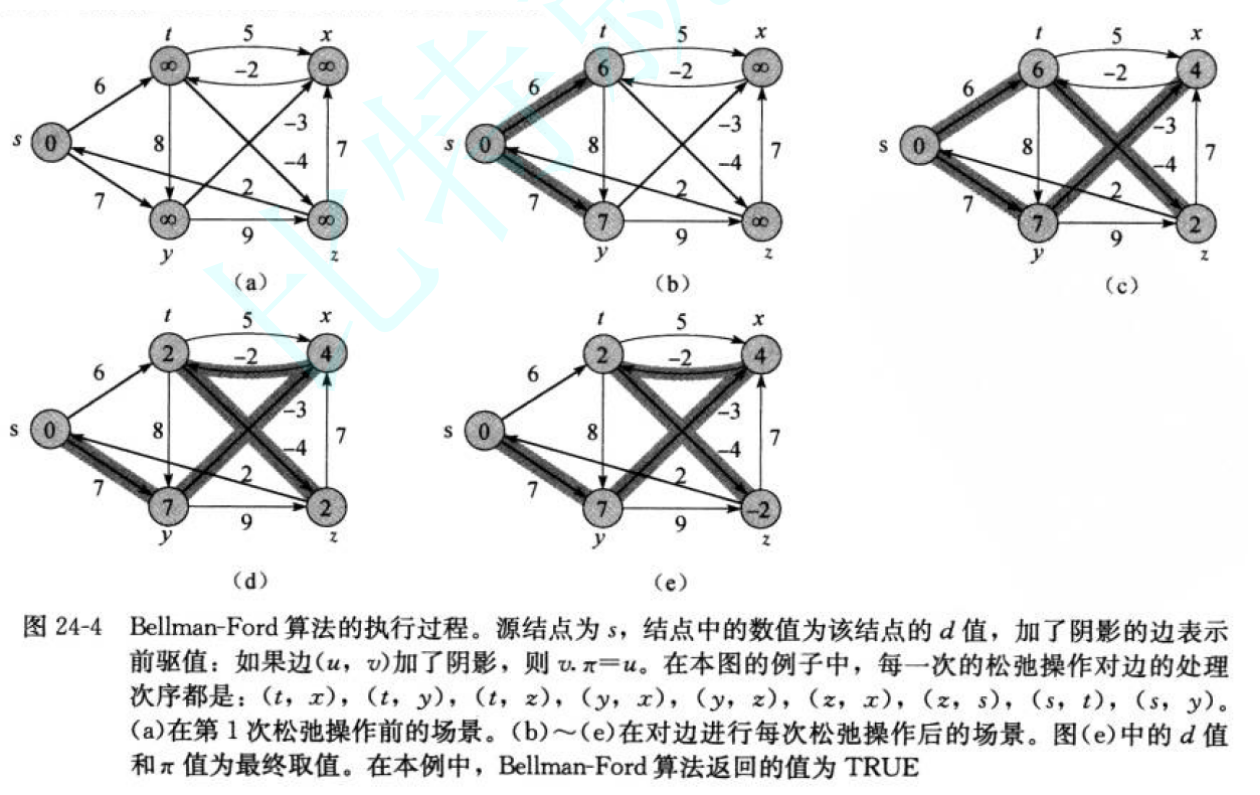
核心思想:暴力松弛,放弃贪心策略,对图中所有边进行多轮松弛更新。
原理:任意两点之间的最短路径,最多包含n-1条边。若超过n-1条边说明路径存在环。
cpp
//如果图中存在负权回路就返回false
bool BellmanFord(const V& src, vector<W>& dist, vector<int>& ParentPath)
{
size_t srci = GetVertexIndex(src);
size_t n = _vertexs.size();
dist.resize(n, MAX_W);
ParentPath.resize(n, -1);
//先更新srci->srci为最小值
dist[srci] = W();
for (size_t k = 0; k < n; k++)
{
bool update = false;//优化如果update在下面代码执行完后仍为false说明没有更新
for (size_t i = 0; i < n; i++)
{
for (size_t j = 0; j < n; j++)
{
if (_matrix[i][j] != MAX_W && dist[i] + _matrix[i][j] < dist[j])
{
dist[j] = dist[i] + _matrix[i][j];
ParentPath[j] = i;
update = true;
}
}
}
if (update == false)
return true;
}
//如果还能更新就是带负权回路
for (size_t i = 0; i < n; i++)
{
for (size_t j = 0; j < n; j++)
{
if (_matrix[i][j] != MAX_W && dist[i] + _matrix[i][j] < dist[j])
{
return false;
}
}
}
return true;
}
cpp
void TestGraphBellmanFord()
{
const char* str = "syztx";
Graph<char, int, INT_MAX, true> g(str, strlen(str));
g.AddEdge('s', 't', 6);
g.AddEdge('s', 'y', 7);
g.AddEdge('y', 'z', 9);
g.AddEdge('y', 'x', -3);
g.AddEdge('z', 's', 2);
g.AddEdge('z', 'x', 7);
g.AddEdge('t', 'x', 5);
g.AddEdge('t', 'y', 8);
g.AddEdge('t', 'z', -4);
g.AddEdge('x', 't', -2);
vector<int> dist;
vector<int> parentPath;
if (g.BellmanFord('s', dist, parentPath))
{
g.PrintShortPath('s', dist, parentPath);
}
else
{
cout << "存在负权回路" << endl;
}
}
优点:能处理负权边,可以检测负权回路
缺点:时间复杂度高于迪杰斯特拉,效率低。
5.3多源最短路径------Floyd-Warshall算法
Floyd-Warshall算法是解决任意两点间的最短路径的一种算法、
Floyd算法考虑的是一条最短路径的中间节点,即简单路径p={v1, v2,......,vn}上除了v1和vn的任意节点。
设 k 是 p 的一个中间节点,那么从i到j的最短路径p就被分成i到k和k到j的两段最短路径p1,p2。p1是从i到k且中间节点属于{1,2,......,k-1}取得的一条最短路径。p2是从k到j且中间节点属于{1,2,......,k-1}取得的一条最短路径。
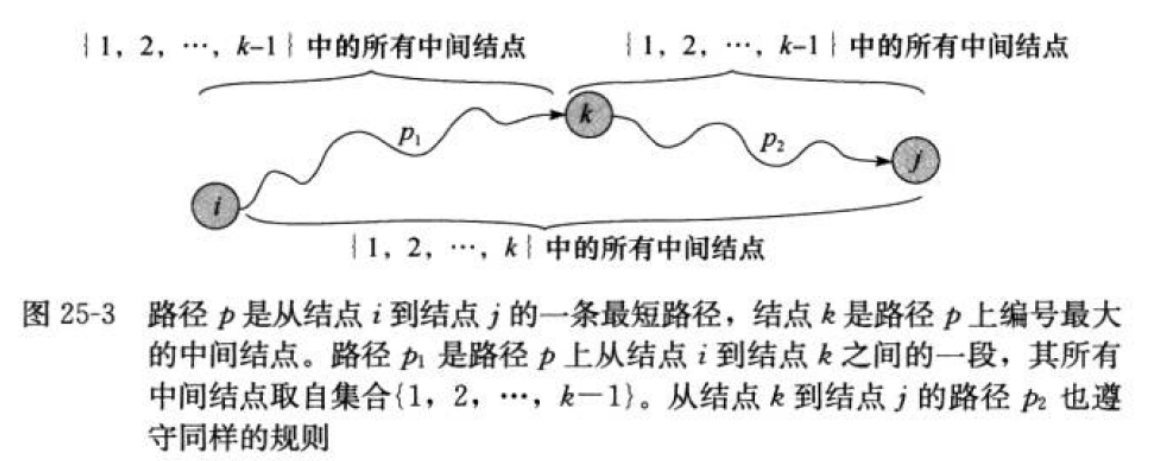
原理:Floyd-Warshall算法的原理是动态规划。
设为从i到j的只以(1,k)集合中的节点为中间节点的最短路径的长度。
- 若最短路径经过点k,则
=
- 若最短路径不经过k,则
因此 = min(
+
,
)。
在实际算法中,为了节省空间,可以直接在原来空间上进行迭代,这样空间可以降至二维。
即Floyd算法本质是三维动态规划,Dijk表示从点i到点j只经过0到k个点最短路径,然后建立起转移方程,然后通过空间优化,优化掉最后一个维度,变成一个最短路径的迭代算法,最后即得到所有点的最短路。
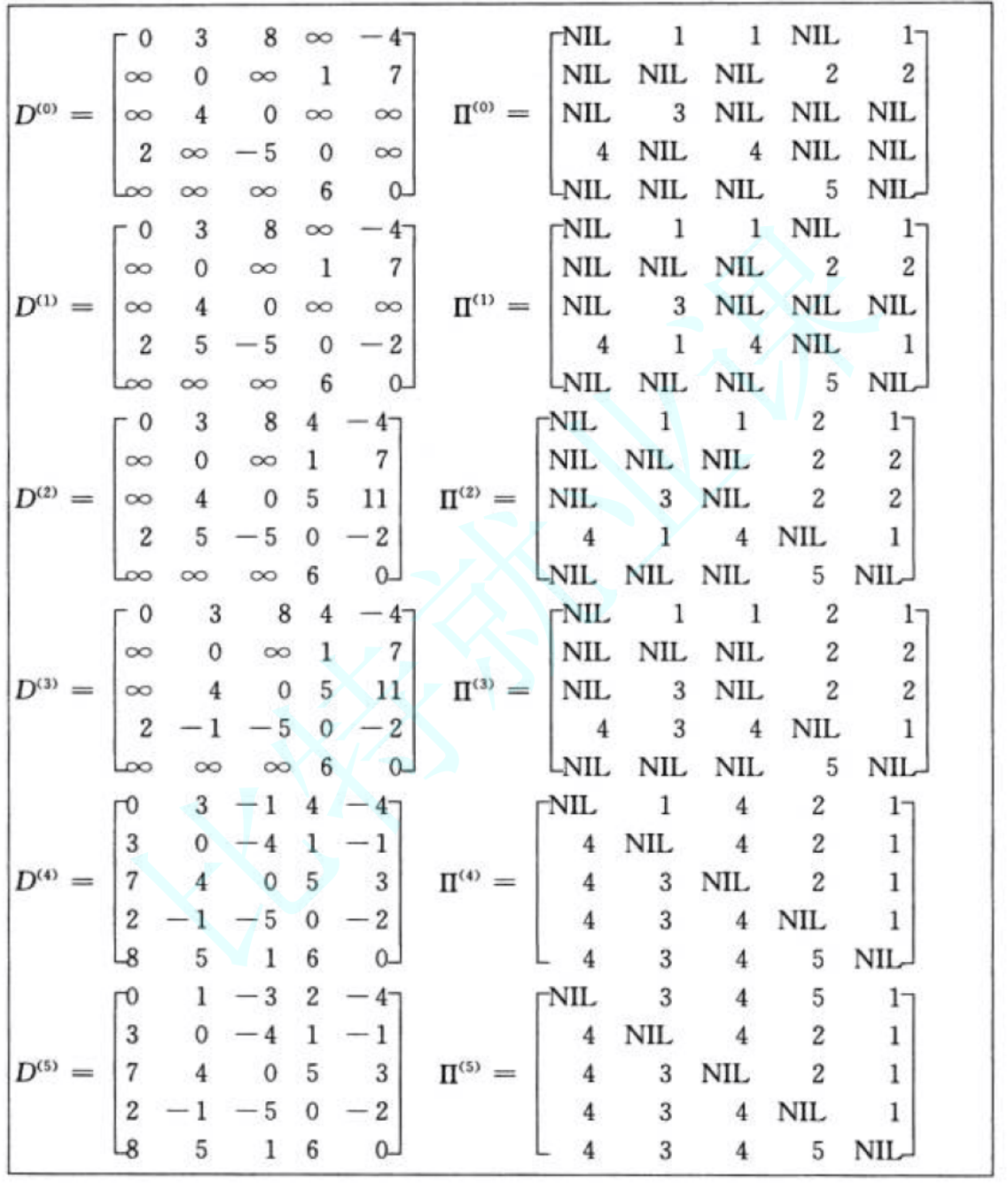
核心思想:动态规划解决多源最短路径问题。
- 状态定义:distkij表示从 i 到 j ,经过编号不超过 k 的结点的最短路径
- 状态转移:distij = min(distij, distik + distkj)(要么不经过k,要么经过k,取两者最小值)
cpp
void FloydWarshall(vector<vector<W>>& dist, vector<vector<int>>& ParentPath)
{
size_t n = _vertexs.size();
dist.resize(n);
ParentPath.resize(n);
//初始化
for (size_t i = 0; i < n; i++)
{
dist[i].resize(n, MAX_W);
ParentPath[i].resize(n, -1);
}
for (size_t i = 0; i < n; i++)
{
for (size_t j = 0; j < n; j++)
{
if (_matrix[i][j] != MAX_W)
{
dist[i][j] = _matrix[i][j];
ParentPath[i][j] = i;
}
if (i == j)
{
//i = j意味着 自己到自己的距离,为缺省值
dist[i][j] = W();
}
}
}
//最短路径的更新i -> {其他节点} ->j
for (size_t k = 0; k < n; k++)
{
for (size_t i = 0; i < n; i++)
{
for (size_t j = 0; j < n; j++)
{
if (dist[i][k] != MAX_W && dist[k][j] != MAX_W && dist[i][j] > dist[i][k] + dist[k][j])
{
dist[i][j] = dist[i][k] + dist[k][j];
//j的父节点置为k
ParentPath[i][j] = ParentPath[k][j];
}
}
}
}
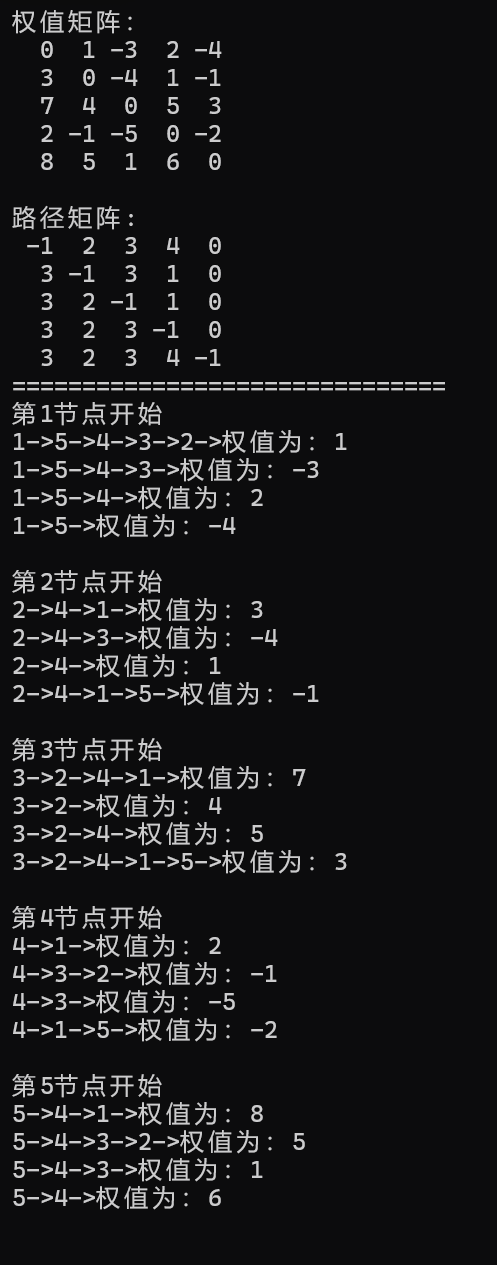
//打印权值和路径矩阵观察数据
for (size_t i = 0; i < n; i++)
{
for (size_t j = 0; j < n; j++)
{
if (dist[i][j] == MAX_W)
{
printf("%3c", '*');
}
else
{
printf("%3d", dist[i][j]);
}
}
cout << endl;
}
cout << endl;
for (size_t i = 0; i < n; i++)
{
for (size_t j = 0; j < n; j++)
{
printf("%3d", ParentPath[i][j]);
}
cout << endl;
}
cout << "===============================" << endl;
}
cpp
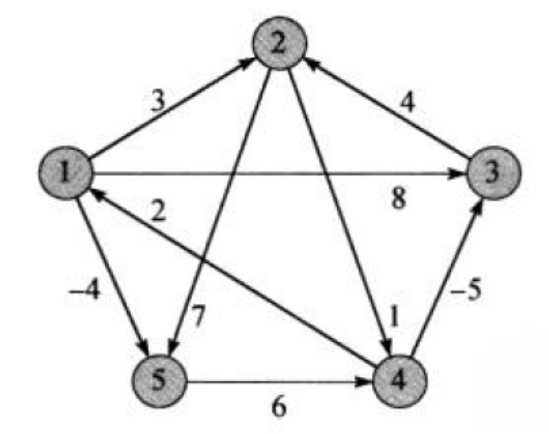
void TestFloydWarShall()
{
const char* str = "12345";
Graph<char, int, INT_MAX, true> g(str, strlen(str));
g.AddEdge('1', '2', 3);
g.AddEdge('1', '3', 8);
g.AddEdge('1', '5', -4);
g.AddEdge('2', '4', 1);
g.AddEdge('2', '5', 7);
g.AddEdge('3', '2', 4);
g.AddEdge('4', '1', 2);
g.AddEdge('4', '3', -5);
g.AddEdge('5', '4', 6);
vector<vector<int>> vvDist;
vector<vector<int>> vvParentPath;
g.FloydWarshall(vvDist, vvParentPath);
// 打印任意两点之间的最短路径
for (size_t i = 0; i < strlen(str); ++i)
{
g.PrintShortPath(str[i], vvDist[i], vvParentPath[i]);
cout << endl;
}
}
优点:代码及其简洁,能处理负权边,一次性求出所有点对的最短路径。
缺点:时间复杂度高,不适合大规模图。