越来越多开发者开始探索 AI 面试官场景,基于大模型搭建的文本交互方案虽能完成基础问答,却始终存在体验短板。候选人面对纯文本对话框沟通,全程缺乏真实交互感,更像单向信息查询,难以还原真实面试的氛围与压迫感。
行业内多数数字人方案体验不佳,要么响应延迟极高,要么画面质感粗糙,难以落地真实交互场景。而依托具身智能技术,仅需短时间即可完成升级,将纯文本 AI 面试官迭代为 3D 具身面试官,体验实现质的飞跃。
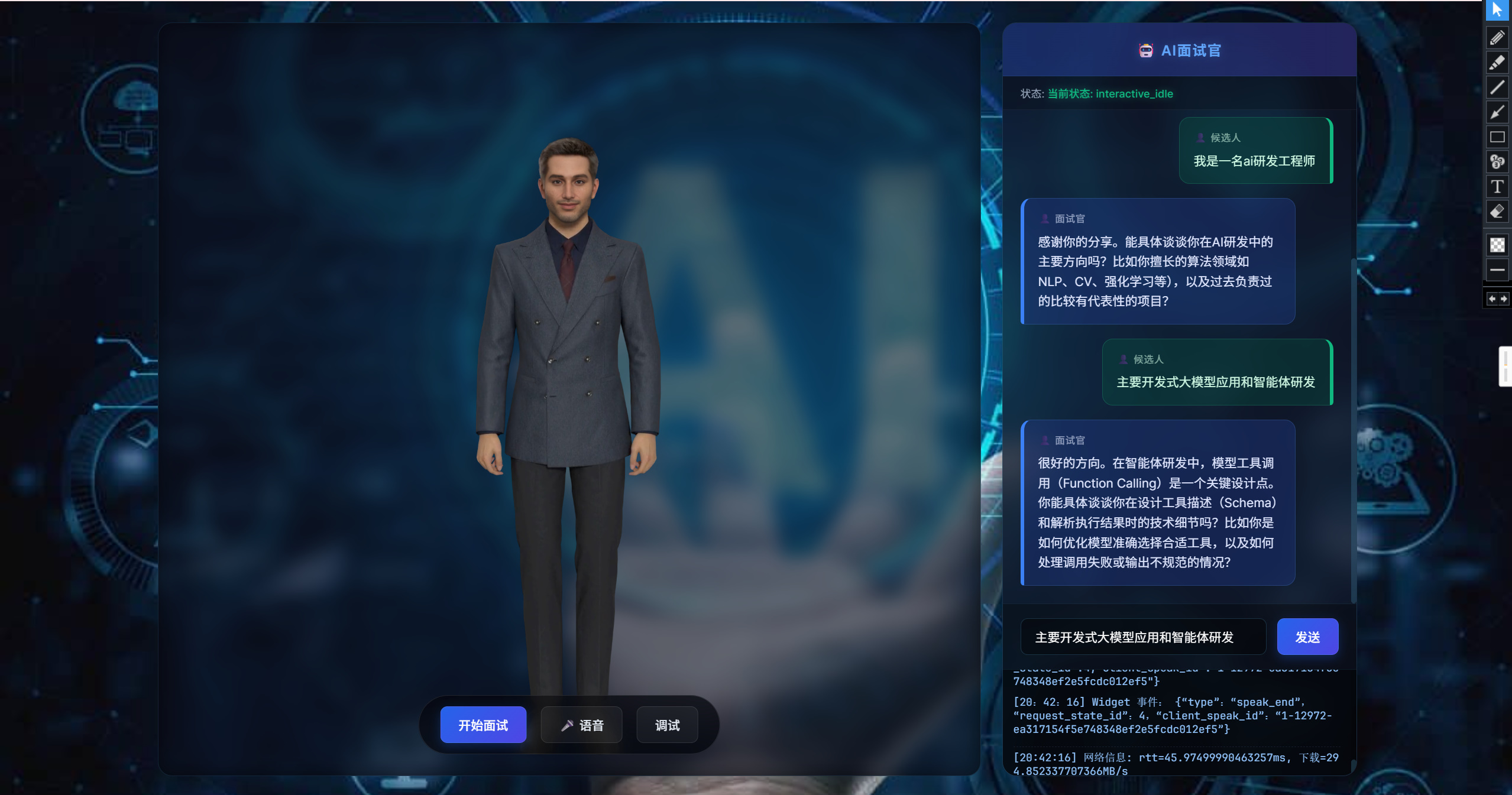
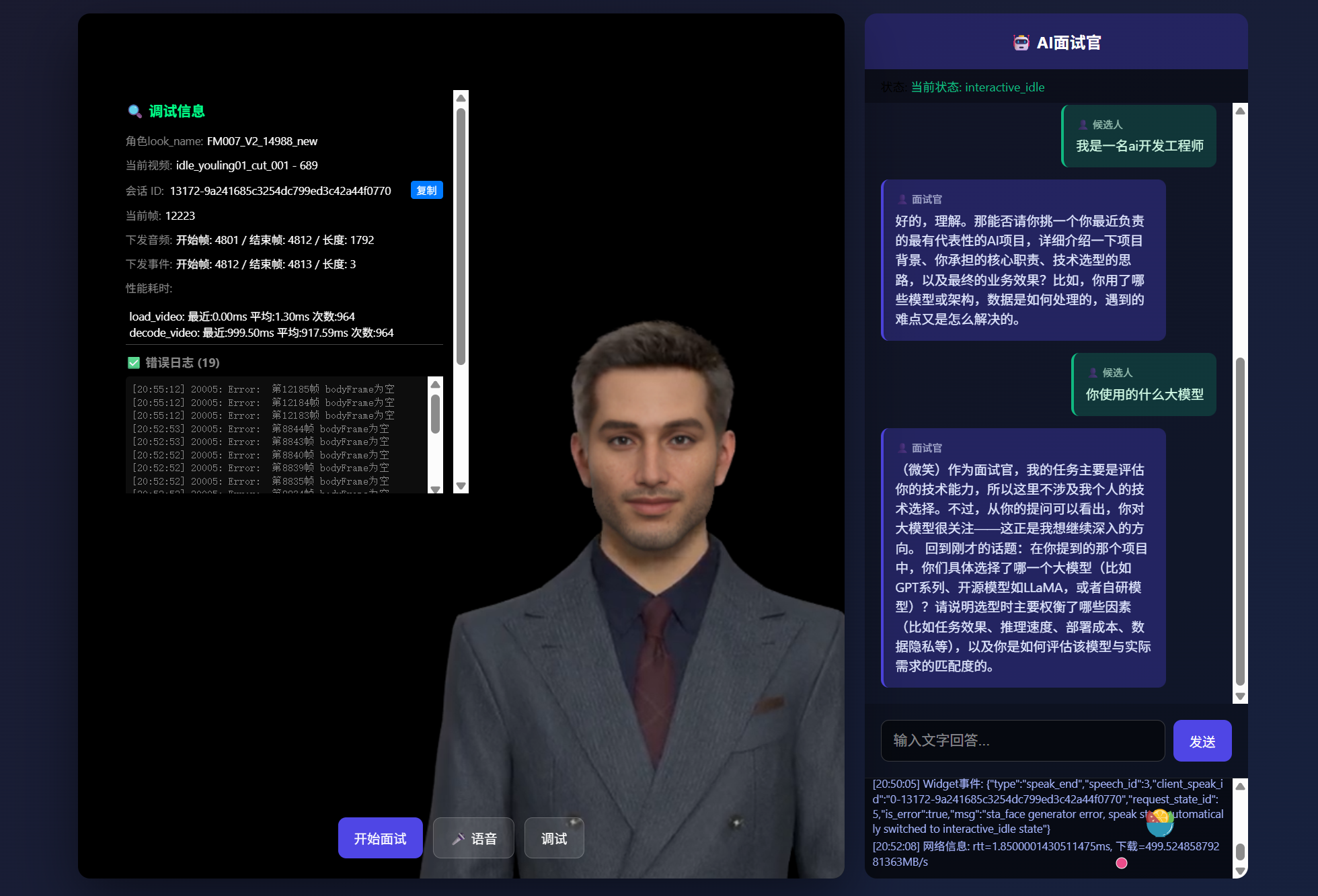
【 先给大家兰最终成品效果,展示AI面试官的交互效果】
AI
2026 年,Agent 赛道竞争白热化,行业共识逐渐清晰:Chat 时代已落幕,具身 Agent 才是未来十年的核心方向。
但行业始终存在一个核心短板:多数 Agent 项目过度聚焦认知能力,感知、理解、执行层持续优化,却几乎忽略表达层建设。
即便 Agent 具备极强的逻辑推理能力,用户接触到的仍只是冰冷对话框 ------ 如同精心装修的别墅,却缺少对外标识,价值难以被用户感知,成为规模化落地的核心阻碍。
魔珐星云的技术路径与行业传统方案截然不同深入研究其技术体系可知,平台依托AI 端渲与端侧解算 、自研文生 3D 多模态大模型,重构交互底层逻辑:云端仅下发轻量级驱动指令,由终端本地完成实时渲染。
具体而言,云端将文本解析为音频、肢体动作、面部表情、交互事件四类轻量级指令,通过 WebSocket 传输至终端,由本地设备实时渲染生成 3D 形象。数据传输量大幅降低,端到端响应约 500ms,较传统方案提升 2-4 倍,支持随时打断交互,百元级芯片即可流畅运行,部署成本显著降低。
传统数字人的核心短板
往多数传统数字人虽具备基础对话交互能力,但普遍陷入行业认知误区:将云端延迟式应答等同于完整智能交互,核心采用云端集中渲染技术路线,难以实现实时双向自然交互。
用户发起提问后,云端依次完成语音识别、文本生成、语音合成、画面渲染,再将完整画面下发终端,整条链路叠加延迟高达 2‑5 秒,无法实现即时响应;且架构上无法支持实时打断,违背真人自然对话逻辑。
同时,云端渲染持续占用 GPU 算力,部署成本高昂、并发承载弱、老旧终端无法适配,规模化下沉落地难度大。传统数字人仅可完成基础被动应答,表情动作依赖预设模板、交互僵硬,难以适配真实场景实时交互需求。
好了,开始动手
理论说够了,下面是完整的实操过程。
第一步,注册账号
打开魔珐星云官网 xingyun3d.com,点击右上角注册。
注册流程很常规,手机号加验证码,设置密码就完事了。注册成功之后账号里会有100积分,可以用来体验平台功能。
如果你是通过征文活动注册的,记得用邀请码 JTGA8IUSZM,这样会额外充值1000积分,够你折腾很久了。
第二步,逛一圈体验中心
注册完别急着创建应用,先去体验中心看看。
导航栏里有几个入口,体验中心、应用管理、文档中心。先点体验中心。
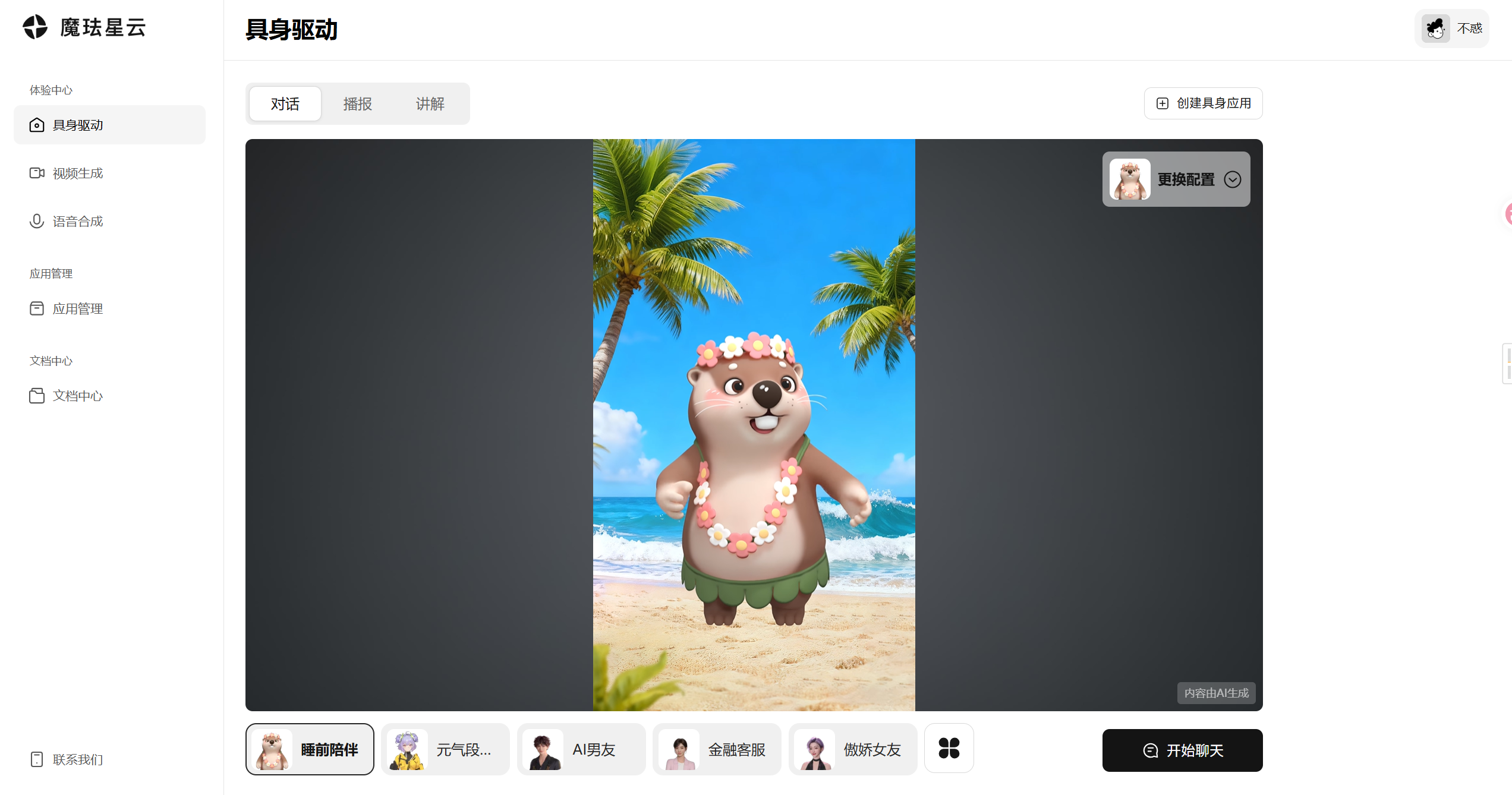
体验中心分三个板块,具身驱动、视频生成、语音合成。
具身驱动是最核心的功能,你可以直接跟一个超写实的3D数字人对话。支持文字输入和语音输入两种方式。我第一次体验的时候确实被惊艳到了,数字人的微表情和动作同步非常流畅,说话的时候会根据语义调整手势和表情,完全没有那种机械的点头摇头。
视频生成可以把文本或者PPT转成数字人视频,适合做内容创作。语音合成就是把文字转成自然语音,支持很多种音色。
建议你每个功能都点进去试试,感受一下参数流驱动和传统视频流的区别。尤其是具身驱动,试着在数字人说话的时候突然打断它,你会明白我前面说的随时打断是什么意思。
第三步,创建你的第一个驱动应用
体验完之后,回到导航栏,点击应用管理。
你会看到三个分类标签,驱动应用、视频应用、语音应用。我们要做的是具身Agent,所以选驱动应用。
点击创建新应用,会弹出一个配置面板。
首先给应用起个名字,比如我起的叫 AI面试官实验室。备注可以随便写,方便你自己区分就行。
然后是最有意思的部分,选择数字人形象。平台提供了很多种风格,超写实、卡通、美型、机器人、二次元都有。做面试官的话我选了一个超写实的商务形象,看起来比较专业。
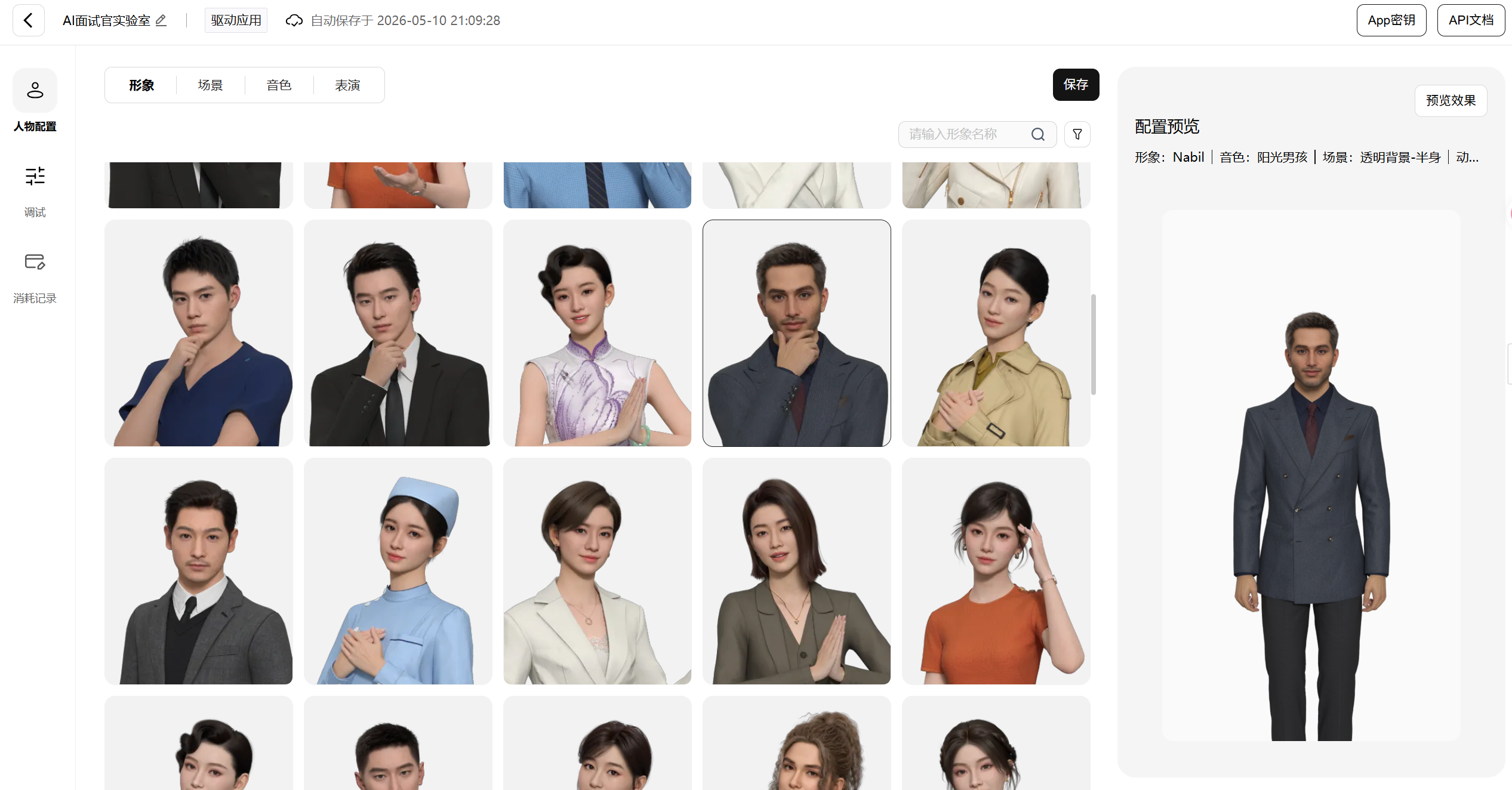
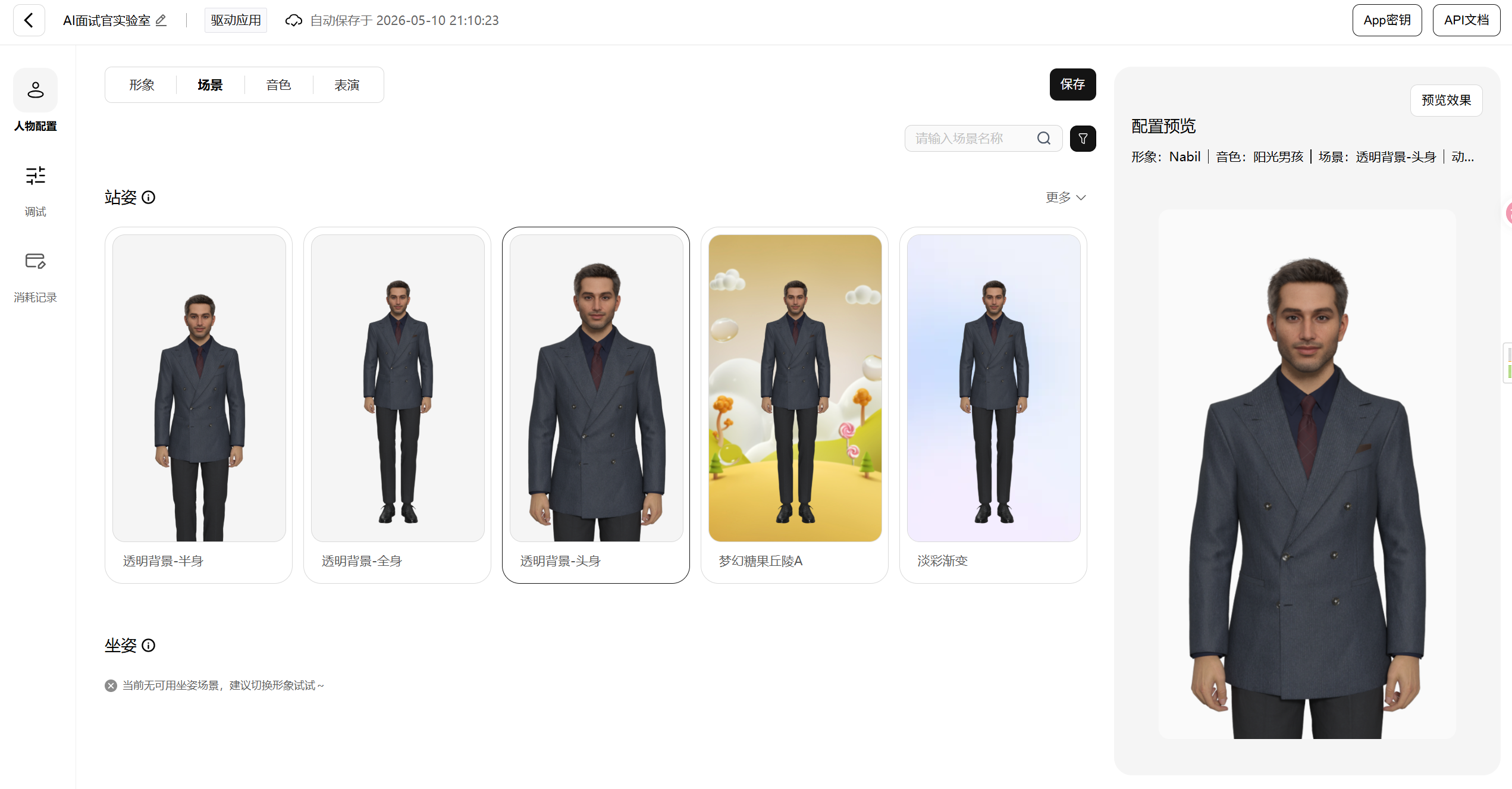
接下来选场景和音色。场景是数字人身后的背景,有办公室、演播室、简约风等可选。音色方面平台提供了超过30种,男声女声都有,我选了一个沉稳的男声,比较符合面试官的设定。
表演风格这个选项挺有意思的,它控制数字人说话时的肢体语言幅度。有内敛型、自然型、活泼型等。面试官场景选自然型比较合适,太活泼了不像话,太内敛了又显得呆板。
全部选好之后点保存,应用就创建完成了。
第四步,拿到你的密钥
应用创建好之后,在应用列表里找到你刚创建的那个,点击进入详情页。
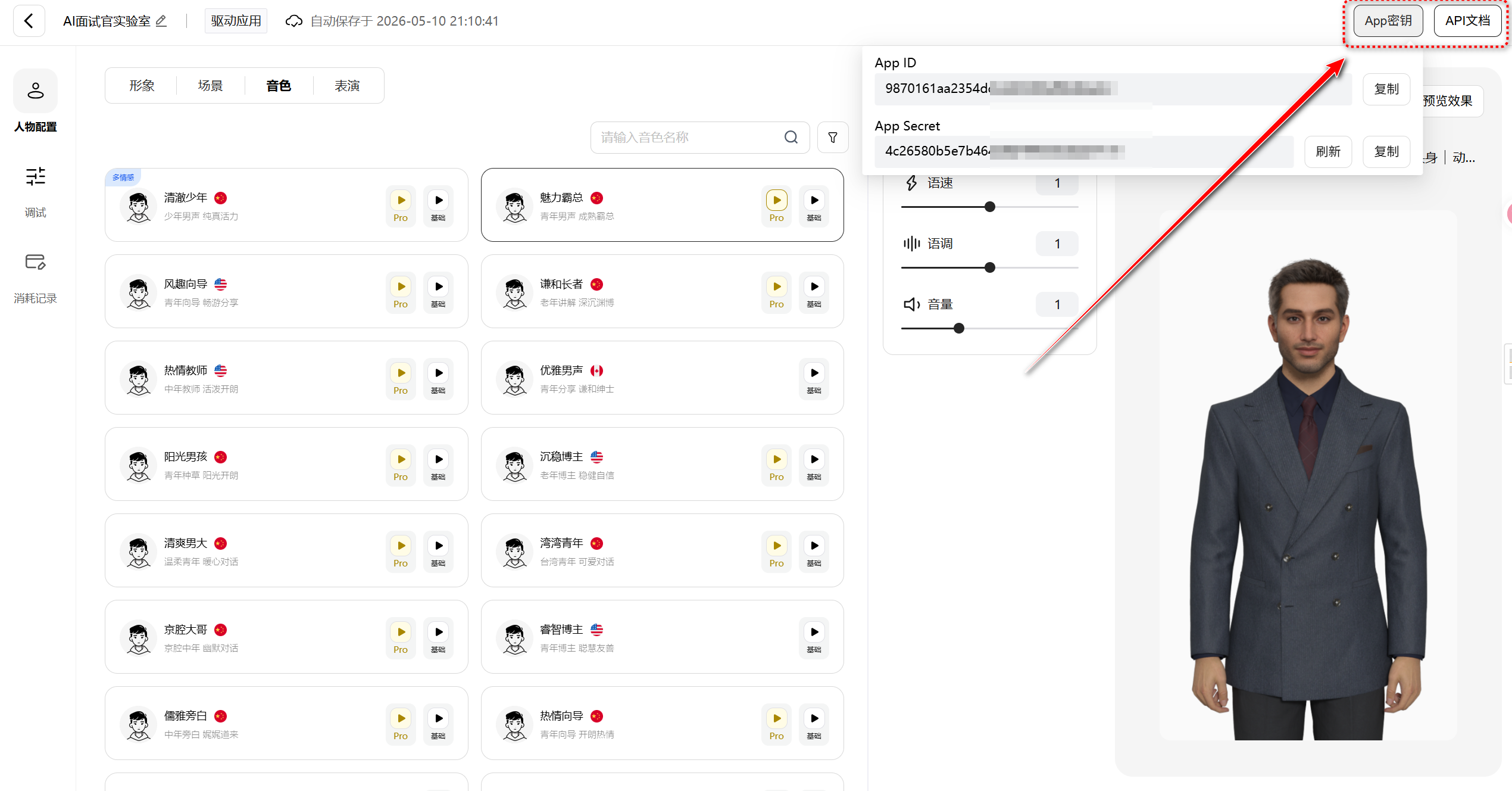
找到 App密钥 这个选项,点进去就能看到你的 App ID 和 App Secret。这两个东西后面写代码要用到,先复制保存好。
注意,App Secret 不要泄露出去,相当于你的应用访问凭证。
第五步,搭建开发环境
接下来开始写代码。我选的是Web端,因为最简单,打开浏览器就能跑。
你需要一个代码编辑器,推荐VS Code或者Cursor。如果你用Cursor的话,还可以配合魔珐星云提供的AI Coding Skill文件,让AI自动帮你写代码,这个后面再说。
先创建一个项目文件夹,里面放一个 index.html 文件。
项目结构非常简单,
interview-agent/
└── index.html对,就一个文件。这就是参数流架构的威力,不需要安装任何依赖,不需要npm install,不需要配置Webpack,一个HTML文件搞定。
但有一个坑必须提前说,SDK只能在 localhost 或者 https 环境下运行,不能直接用 file:// 协议打开,也不能用 http + IP地址的方式。所以你需要一个本地服务器。
最简单的方式是用VS Code的Live Server插件,装好之后右键index.html选 Open with Live Server 就行了。
第六步,写代码,核心就十行
打开 index.html,先把基础结构写好,
<div id="app">
<div id="sdk"></div>
<div class="status" id="status">初始化中...</div>
<div class="log-container" id="log"></div>
<div class="controls">
<button class="btn btn-primary" onclick="startInterview()">开始面试</button>
<button class="btn btn-secondary" onclick="sendMessage()">发送消息</button>
<button class="btn btn-secondary" onclick="toggleDebug()">调试信息</button>
</div>
</div>
<script src="https://media.xingyun3d.com/xingyun3d/general/litesdk/xmovAvatar@latest.js"></script>SDK通过CDN引入,一行script标签就搞定了。不需要安装任何包。
接下来是核心的初始化代码,把你在上一步拿到的 App ID 和 App Secret 填进去,
<script>
let sdkInstance = null;
let isDebugVisible = false;
document.addEventListener('DOMContentLoaded', function() {
function log(msg) {
const logDiv = document.getElementById('log');
const p = document.createElement('p');
const time = new Date().toLocaleTimeString();
p.textContent = `[${time}] ${typeof msg === 'object' ? JSON.stringify(msg) : msg}`;
logDiv.appendChild(p);
logDiv.scrollTop = logDiv.scrollHeight;
}
function updateStatus(text, color = '#10b981') {
const statusDiv = document.getElementById('status');
statusDiv.textContent = text;
statusDiv.style.color = color;
}
function toggleDebug() {
if (isDebugVisible) {
sdkInstance && sdkInstance.hideDebugInfo();
} else {
sdkInstance && sdkInstance.showDebugInfo();
}
isDebugVisible = !isDebugVisible;
}
function startInterview() {
if (sdkInstance) {
sdkInstance.speak('<speak><ue4event><type>ka</type><data><action_semantic>Hello</action_semantic></data></ue4event>您好,欢迎参加本次面试。我是您的AI面试官,我们将进行一场轻松愉快的交流。请您简单介绍一下自己。</speak>', true, false);
}
}
function sendMessage() {
if (sdkInstance) {
const messages = [
'我是一名全栈开发工程师,有5年的开发经验。',
'我擅长使用JavaScript和Python进行开发。',
'我最近在学习人工智能相关的技术。',
'我对应聘这个岗位很感兴趣。'
];
const randomMsg = messages[Math.floor(Math.random() * messages.length)];
sdkInstance.speak(`<speak>${randomMsg}</speak>`, true, true);
}
}
sdkInstance = new XmovAvatar({
containerId: '#sdk',
appId: '9870161aa2354dcba90289ef8648adcc',
appSecret: 'c765c4cfbb114514912d8e14ef4ef0af',
gatewayServer: 'https://nebula-agent.xingyun3d.com/user/v1/ttsa/session',
headers: {},
hardwareAcceleration: 'prefer-hardware',
onWidgetEvent: function(data) {
log('Widget事件: ' + JSON.stringify(data));
},
proxyWidget: {
'widget_slideshow': function(data) {
log('轮播事件: ' + JSON.stringify(data));
},
'widget_video': function(data) {
log('视频事件: ' + JSON.stringify(data));
}
},
onNetworkInfo: function(networkInfo) {
log('网络信息: rtt=' + networkInfo.rtt + 'ms, 下载=' + networkInfo.downlink + 'MB/s');
},
onMessage: function(m) {
log('SDK消息: ' + JSON.stringify(m));
},
onStateChange: function(state) {
log('状态变化: ' + state);
updateStatus('当前状态: ' + state);
},
onStatusChange: function(status) {
log('SDK状态: ' + JSON.stringify(status));
},
onStateRenderChange: function(state, duration) {
log('渲染状态变化: ' + state + ', 耗时: ' + duration + 'ms');
},
onVoiceStateChange: function(status) {
log('语音状态: ' + status);
if (status === 'voice_start') {
updateStatus('正在说话...', '#f59e0b');
} else if (status === 'voice_end') {
updateStatus('等待输入', '#10b981');
}
},
enableLogger: false
});
sdkInstance.init({
onDownloadProgress: function(p) {
log('资源下载进度: ' + p + '%');
if (p < 100) {
updateStatus('加载中... ' + p + '%', '#f59e0b');
} else {
updateStatus('就绪', '#10b981');
log('初始化完成,可以开始面试');
}
}
});
log('AI面试官已初始化');
updateStatus('初始化中...', '#f59e0b');
});
</script>就这些。真的就这些。
调用 init 之后,SDK会自动从云端下载数字人的3D模型、材质、骨骼动画等资源。下载完成后,你的页面上就会出现一个完整的3D数字人。
第一次加载可能需要十几秒,因为要下载模型资源。后续访问会有缓存,加载会快很多。
第七步,让数字人开口说话
数字人出现在页面上之后,下一步就是让它说话。
最简单的调用方式,
sdk.speak("你好,欢迎参加今天的面试,请先做一个自我介绍。", true, true);speak 方法接收三个参数。第一个是要说的文本内容,第二个 is_start 标记一段完整对话的开始,第三个 is_end 标记结束。
当你调用这行代码的时候,数字人会立刻开始说话,同时配合面部表情和手势动作。注意观察它的口型,跟语音内容完全实时同步,完全没有对嘴型的假同步感。
第八步,对接大模型,实现真正的Agent
光能说固定台词还不够,我们要的是一个能根据候选人回答进行追问的AI面试官。
这里我用DeepSeek做后端,你也可以换成GPT、Claude或者任何你喜欢的LLM。切换模型只需要改一个函数,数字人端不需要改任何代码,这就是参数流架构解耦的好处。
核心逻辑是这样的,
// 面试官的系统提示词
const SYSTEM_PROMPT = `你是一位资深的技术面试官。
面试流程如下:
1. 先请候选人做自我介绍
2. 根据候选人的介绍,针对项目经验进行深入追问
3. 考察技术栈的掌握深度
4. 询问解决过的最有挑战的技术问题
5. 最后让候选人提问
要求: 每次只问一个问题,语气专业但友善。`;
// 调用大模型API
async function callLLM(userInput, conversationHistory) {
const response = await fetch("https://api.deepseek.com/chat/completions", {
method: "POST",
headers: {
"Content-Type": "application/json",
"Authorization": "Bearer 你的DeepSeek API Key"
},
body: JSON.stringify({
model: "deepseek-chat",
messages: [
{ role: "system", content: SYSTEM_PROMPT },
...conversationHistory,
{ role: "user", content: userInput }
],
stream: true
})
});
return response.body;
}关键来了。大模型返回的是流式数据,我们需要把流式文本实时喂给数字人SDK。魔珐星云的 speak 方法天然支持流式调用,
// 流式驱动数字人说话
class AvatarBridge {
constructor(sdk) {
this.sdk = sdk;
this.buffer = "";
this.isFirst = true;
}
feed(textDelta) {
this.buffer += textDelta;
// 按标点符号切片,遇到句号问号感叹号就喂一段
var match = this.buffer.match(/^[^。!?;.!?]*[。!?;.!?;]/);
if (match) {
this.sdk.speak(match[0], this.isFirst, false);
this.isFirst = false;
this.buffer = this.buffer.slice(match[0].length);
}
}
end() {
// 把剩余的文本也发出去
if (this.buffer.length > 0) {
this.sdk.speak(this.buffer, this.isFirst, true);
}
}
}这段代码做的事情很简单,把大模型一个个token吐出来的文本,按标点符号切成小段,每攒够一句话就喂给SDK。这样数字人就能做到边生成边说话,不需要等大模型把整段回复都写完。
实际体验下来,这种流式驱动的方式非常自然。数字人说话的速度略慢于大模型输出的速度,所以不会出现等文本的情况,整个过程非常流畅。
0511-3
第九步,加上语音识别,完成闭环
文字输入的面试体验还是差点意思,我们再加上语音识别,让候选人可以直接开口回答。
这里我用的是浏览器自带的Web Speech API,零成本,不需要申请任何API Key,
var recognition = new (window.SpeechRecognition || window.webkitSpeechRecognition)();
recognition.lang = "zh-CN";
recognition.continuous = true;
recognition.interimResults = true;
recognition.onresult = function(event) {
var finalTranscript = "";
for (var i = event.resultIndex; i < event.results.length; i++) {
if (event.results[i].isFinal) {
finalTranscript += event.results[i][0].transcript;
}
}
if (finalTranscript) {
// 把语音转文字的结果发给大模型
processUserInput(finalTranscript);
}
};
recognition.start();现在整个链路就通了。
候选人说话,浏览器语音识别转文字,发给DeepSeek,流式返回面试官回复,实时驱动3D数字人表达。一气呵成。
从候选人说完话到数字人开始回应,整个过程延迟大概在2到3秒左右。其中大模型推理占1到2秒,数字人首帧渲染占1.3秒。考虑到这是一个完整的理解加表达链路,这个延迟完全可以接受。
0511-4
第十步,利用SSML让面试官更生动
魔珐星云的 speak 方法支持SSML格式,这意味着你可以精细控制数字人的表现。
比如,你想让面试官在某个问题之后停顿一下,制造一点压迫感,
sdk.speak("请描述一下你解决过的<break time='1500ms'/>最有挑战的技术问题。", true, true);又或者,你想让面试官在说话的时候做一个特定的动作,
sdk.speak("这个回答很有深度。<action_semantic>nod</action_semantic>我们接着往下聊。", false, false);还可以通过KA指令触发预设的技能动作,
sdk.speak("<ka_intent>Greeting</ka_intent>欢迎来到今天的面试。", true, true);这些细节看似不起眼,但积累起来会让整个面试体验的真实感提升一个档次。面试官会在适当的时机点头、停顿、变换手势,这些都是纯文本Agent做不到的。
进阶技巧,用Cursor + AI Coding Skill零代码搭建
如果你不想手写代码,魔珐星云还提供了一个更懒的方式。
他们提供了一个叫 AI Coding Skill 的规则文件,本质上是一个 .mdc 格式的配置文件。你把它放到Cursor编辑器的 .cursor/rules/ 目录下,Cursor就能自动理解魔珐星云SDK的所有用法。
配置好之后,你只需要在Cursor里用自然语言描述你想要的效果,比如,
创建一个AI面试官页面,数字人用商务形象,背景用办公室场景,接入DeepSeek大模型,支持语音对话
Cursor就会根据Skill文件里的规则,自动生成完整的代码。你只需要把App ID和App Secret填进去就能跑。
我试了一下,生成的代码质量还不错,核心逻辑和手写的差不多。对于不太熟悉前端开发的开发者来说,这个功能确实能省不少时间。
一些我踩过的坑
整个搭建过程中我遇到了几个坑,这里分享出来希望能帮你省点时间。
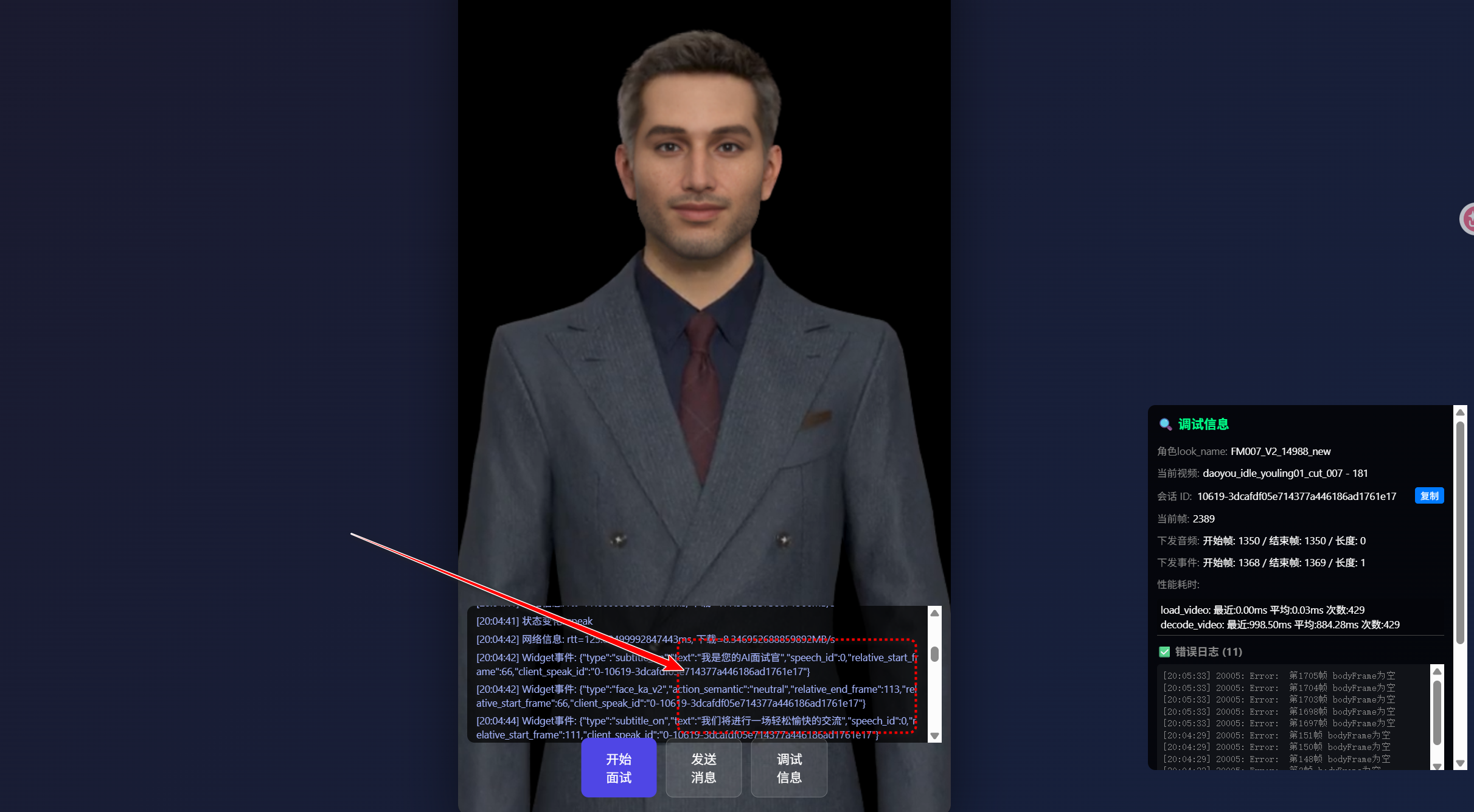
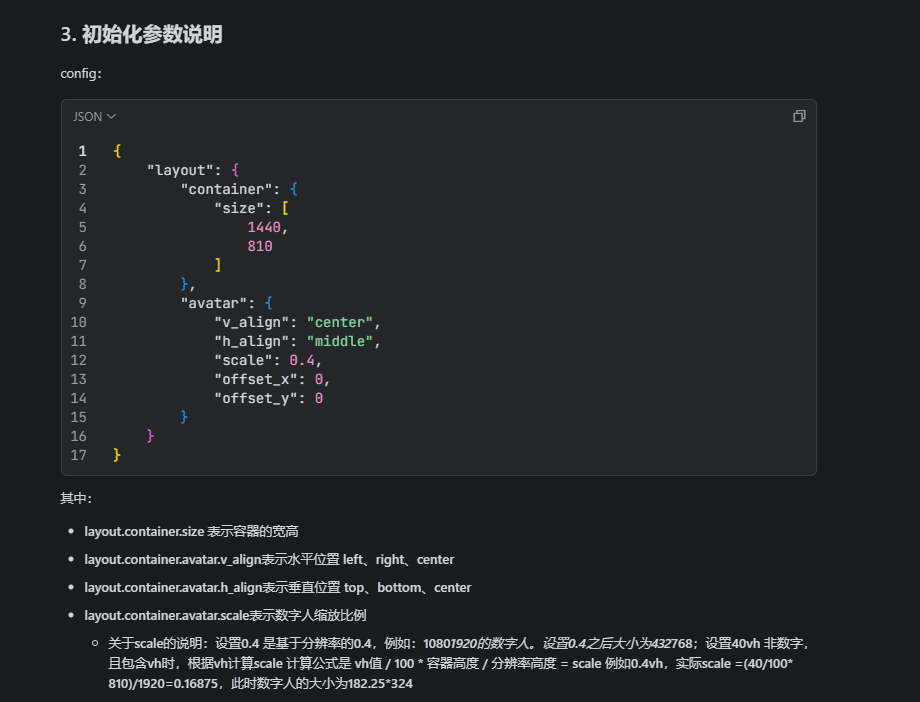
第一个坑,容器比例问题。SDK要求容器的宽高比必须和控制台里选的应用类型一致。如果你在控制台选的是横屏应用,但页面上给了一个竖屏的容器,数字人会变形或者显示异常。这个在文档里有提到,但我一开始没注意,调试了半天才发现。详细配置可以参考图片内容
第二个坑,localhost限制。前面也提了,SDK只能在localhost或者https下运行。如果你用 http://192.168.x.x 这种方式访问,WebSocket连接会直接失败。用Live Server或者nginx配一个本地https就行。
第三个坑,speak方法的调用节奏。SDK不允许连续多次调用speak而不做状态切换。如果你在流式调用的时候喂文本太快,可能会导致队列堆积。建议在每次speak之间稍微留一点间隔,或者用interactive_idle方法做状态切换。
第四个坑,init的Promise处理。init方法返回的是一个Promise,资源下载和鉴权都可能失败,一定要加 .catch() 处理错误。我第一次写的时候忘了加,资源下载失败后页面就卡死了,没有任何提示。
说点真实的体验感受
折腾了一个周末,我的AI面试官项目算是完成了。从纯文本对话框升级到3D具身交互,这个体验上的提升是质的。
我找了几位朋友试用,反馈出奇地好。有人说面对数字人面试官比面对纯文字对话框紧张多了,会下意识地整理衣服和坐姿。还有人说数字人在追问的时候微微前倾身体那个动作,压迫感拉满,跟真实面试几乎一样。
这就是具身表达的力量。
纯文本Agent传递的只有信息本身,但具身Agent传递的是信息加上情感和态度。一个点头、一个停顿、一个手势,这些非语言信息占了人类沟通的绝大部分。你的Agent再聪明,如果只能通过文字输出,那它就丢失了沟通中最重要的一部分。
从技术角度看,魔珐星云的AI 端渲与端侧解算确实解决了真实痛点。它把表达层从云端搬到端侧,用指令驱动替代传统方案,在保证质量的前提下把延迟和成本压到合理范围。。SDK的接入也足够简单,核心代码就十来行,不需要3D开发经验。
当然也有一些不足的地方。比如SDK目前只支持Web、Android、iOS和Unity平台,桌面端的原生支持还不够完善。再比如数字人的形象虽然选择不少,但自定义程度有限,如果你想用自己设计的形象,可能需要走企业定制流程。还有就是语音识别目前需要自己对接,如果平台能内置ASR能力就更完美了。
但总体来说,这是一个让我愿意继续深入探索的平台。
如果你也在做Agent相关的项目,我真心建议你花两个小时试试魔珐星云。它让我看到了Agent落地的另一种可能性。也许未来每一块屏幕背后,都有一个具身智能体在等着和你对话。
那个未来,好像已经不远了。
魔珐星云-具身智能数字人开放平台:https://xingyun3d.com/?utm_campaign=daily&utm_source=jixinghuiKoc120
文章出自:不惑_
原文链接:https://blog.csdn.net/u012263509/article/details/161090198