摘要
逻辑回归是机器学习中最经典的二分类算法 之一。它在线性回归的基础上通过 Sigmoid 函数 将输出映射为类别概率,并使用交叉熵损失函数进行优化。本文从极大似然估计出发,完整推导了交叉熵损失的梯度,分别使用梯度下降法和牛顿法求解最优参数,并在威斯康星乳腺癌数据集上与sklearn进行对比验证。
引言
在上一篇文章中,我们使用线性回归解决了连续值的预测问题 。但当面对"这封邮件是垃圾还是正常""这个肿瘤是良性还是恶性"这样的二分类问题 时,线性回归的输出范围 (−∞,+∞) 就力不从心了。逻辑回归通过在线性模型之上叠加一个 Sigmoid 函数,将无界的输出压缩到 (0,1) 之间,天然适合作为分类概率。
与KNN通过距离投票进行分类不同,逻辑回归是一种参数化的概率分类器------它假设数据是线性可分的,并输出每个样本属于正类的概率值。这种"软分类"特性使它在医疗诊断、信用评分等需要概率置信度的场景中不可替代。
本文将按照"模型 → 损失 → 梯度 → 牛顿法 → 代码 → 前沿"的路径完整展开。
核心原理
逻辑回归 就是基于线性回归和sigmoid函数 解决二分类问题。
线性回归
线性回归 是根据数据集样本的分布情况计算线性回归方程 y=wTx,新样本数据代入该线性方程即可实现标签预测。
具体实现可参考线性回归:从高尔顿的回归到梯度下降,手写一个完整的线性模型。
sigmoid 函数
线性回归预测的结果是连续的,值域为 (-∞,+∞) 。而二分类问题需要的结果值域为 (0 , 1) ,通常设置中间阈值为 0.5 ,预测结果大于 0.5 结果是正类别 1 ,反则为负类别 0 。
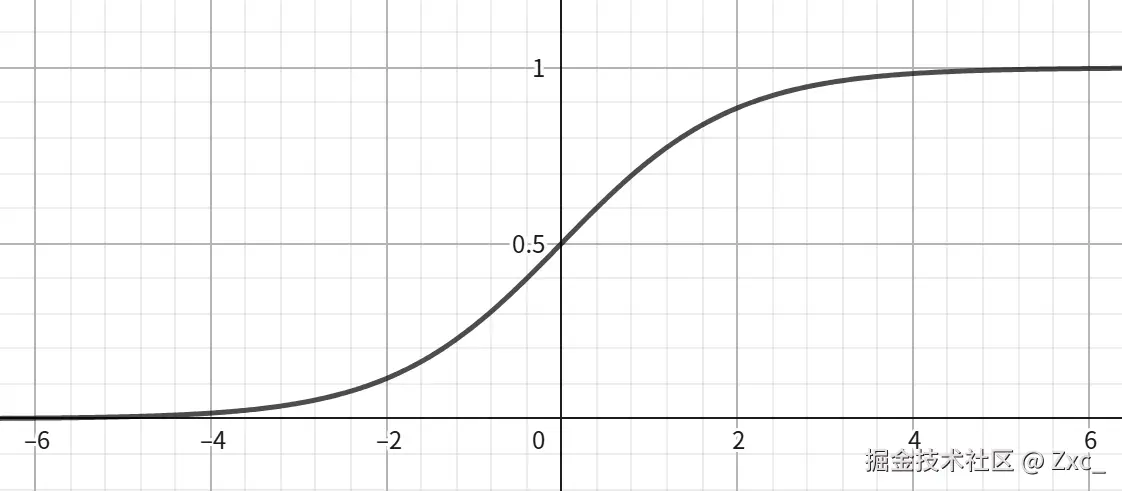
sigmoid 函数(激活函数)的作用就是将 (-∞,+∞) 映射到 (0 , 1),数学公式为:
σ(x)=1+e−x1
sigmoid 函数自变量 x 是线性回归预测结果 y=wTx,而这个 x 是数据集样本。
如图所示 sigmoid 函数将(-∞,+∞) 映射到了 (0 , 1)。
损失函数
损失函数衡量模型效果的指标 ,如线性回归的 SSE、 MAE 、 MSE,其计算的核心都是预测值与真实值之间的差距,差距越大损失函数越大,差距越小则损失函数越小。
逻辑回归的真实值结果只有 0 和 1,常用的损失函数为交叉熵损失函数:
J(w)=−n1i=1∑n(yilnpi+(1−yi)ln(1−pi)),pi=1+e−wTxi1
其中的 yi 是该样本的标签(0或者1), pi 是 sigmoid 函数的计算结果。
逻辑回归损失函数最终要求的是其底层线性回归函数的 w 和 b ,寻找最优的 w 和 b 使得损失函数值最小即模型准确率最高,损失函数的具体推导如下:
Step1:极大似然估计函数
这个损失函数源自概率论的极大似然估计函数 ,根据已知的数据(数据集样本)去寻找最优的一组参数( w 和 b)使得已知数据的发生率最高,公式表达为:
L(w)=i=1∏npiyi(1−pi)1−yi
其中 pi=σ(zi)=1+e−wTxi1 。
Step2:取对数化简计算
累乘的计算比较复杂,通常优化操作为取对数,由于 L(w) 单调所以取对数并不影响求最值:
lnL(w)=i=1∑n(yilnpi+(1−yi)ln(1−pi))
Step3:引入负号与均值构建损失函数
极大似然估计函数的核心原理是最大化已知数据的发生概率即求 L(w) 最大值,而损失函数通常是求最小值,因此在极大似然估计函数前添加负号 并除以数据集样本总量消除样本规模对损失函数的影响,最终得到交叉熵损失函数:
J(w)=−n1lnL(w)=−n1i=1∑m(yilnpi+(1−yi)ln(1−pi))
最小化 J(w) 与最大化 L(w) 在数学上完全等价。
梯度
Step4:求梯度
已知损失函数了,为了计算最优参数 w ,需要计算 J(w) 对 w 的梯度,
已知 J(w) 是关于 pi 的函数, pi 是关于 zi 的, zi 是关于 w 的,根据链式法则有:
∂w∂J=∂pi∂J⋅∂zi∂pi⋅∂w∂zi
- 第一部分:损失函数 J 对预测概率 pi 求导:
∂pi∂J=−(piyi−1−pi1−yi)=pi(1−pi)pi−yi
- 第二部分:损失函数 pi=σ(zi)=1+e−zi1 对预测概率 zi 求导:
∂zi∂pi=pi(1−pi)
- 第三部分:损失函数 zi=wTxi 对预测概率 w 求导:
∂w∂zi=xi
- 第四部分:汇总计算梯度
∂w∂J=pi(1−pi)pi−yi⋅pi(1−pi)⋅xi=(pi−yi)xi
- 第五部分:计算全局梯度
∂w∂J=n1i=1∑n(pi−yi)xi
Step5:转换为矩阵形式
已知损失函数的梯度表达,但是在计算机中使用的多为矩阵形式:
数据集矩阵 x 大小为 (n,d) ,展开求和公式:
i=1∑n(pi−yi)xi=(p1−y1) x11x12⋮x1d +(p2−y2) x21x22⋮x2d +⋯+(pn−yn) xn1xn2⋮xnd
转化为矩阵计算方式:
i=1∑n(pi−yi)xi= x11x12⋮x1dx21x22⋮x2d......⋱...xn1xn2⋮xnd d×n p1−y1p2−y2⋮pn−yn n×1=XT(P−Y)
最后总结公式为:
∂w∂J=n1XT(P−Y)
与线性回归的损失函数梯度 ∂w∂J=n2∗XT(Xw−Y) 高度相似,两者都是"预测值与真实值之差"乘以"输入特征"的均值,区别仅在于线性回归的预测值是 Xw(线性函数),而逻辑回归的预测值是 σ(Xw)(sigmoid 后的概率)。这体现了广义线性模型的统一框架。
算法流程
已知损失函数的梯度为 ∂w∂J=n1XT(P−Y) ,由于 P 使用 sigmoid 函数计算且是非线性的,所以无法使用正规方程法直接求最优参数 w 和 b。
梯度下降法
梯度下降法根据梯度方向是函数上升最快的方向,取反方向就是函数下降最快的方向:
wk+1=wk−α∂w∂J(w)=wk−α⋅n1⋅XT(P−Y)
α 是学习率用于控制步长,具体细节可看线性回归。
牛顿法
梯度下降法使用 梯度(一阶导数) 来控制方向,使用学习率 α 决定步长 , α 设置的大小不同产生的结果也会出现差异 ,过大可能会梯度爆炸,过小可能无法走到最优值。
牛顿法 则是使用 Hessian 矩阵(二阶导数)同时决定步长和方向,
Step1:泰勒展开
将 J(w) 进行二阶泰勒展开:
J(w)≈J(wk)+∇J(wk)T(w−wk)+21(w−wk)TH(wk)(w−wk)
多元函数的泰勒展开公式与一元的存在多出不同
- J(w):损失函数值,是标量
- ∇J(wk):一阶梯度向量,大小(n,1),为了这项结果为标量添加转置大小为(1,n)
- H(wk):Hessian 矩阵,对梯度再次求导结果,大小为(n,n),而前后夹击 (w−wk)满足泰勒展开同时转化该项为标量。
Step2:求导
对泰勒展开后的 J(w) 求导并令其为 0 求最值:
∂w∂J(w)≈∇J(wk)+H(wk)(w−wk)=0
具体求导过程可以将 J(w) 先展开再对 w 求导即可。
Step3:移项计算
需要求的参数是 w ,将其移至一侧:
wk+1=wk−H(wk)−1∇J(wk)
将其与梯度下降法公式对比 wk+1=wk−α⋅∇J(wk) ,牛顿法使用 Hessian 矩阵进行动态的步长和方向调整,它乘以梯度 ∇J(w) 后,不仅自动调整了每一个特征的专属学习率 (对陡峭的方向给小步长,对平缓的方向给大步长),还纠正了更新方向,让参数不再盲目沿着梯度下坡,而是直奔谷底。
Step4:计算 H(w)
一阶梯度向量 ∇J(w)=n1XT(P−Y), H(w)就是在其基础上对 w 求导:
H(w)=n1XTRX
一阶梯度向量中只有 P 是关于 w 的,根据上面的计算链式求导中有提到:
∂w∂P=P(1−P)X
最终汇总 R 是大小为(n,n)的对角矩阵,内容为概率方差 pi(1−pi)。
Step5:汇总
最终牛顿法的矩阵计算公式如下:
wk+1=wk−(XTRkX)−1XT(Pk−Y)
- 优点 :牛顿法使用 Hessian 矩阵更加精准的控制下降的方向和步长
- 缺点 :计算的复杂度大大提升
梯度下降法在遇到'峡谷'形状的损失表面时容易发生反复震荡,而牛顿法利用了二阶曲率信息,能够实现'曲率修正',近乎直线地直奔谷底。 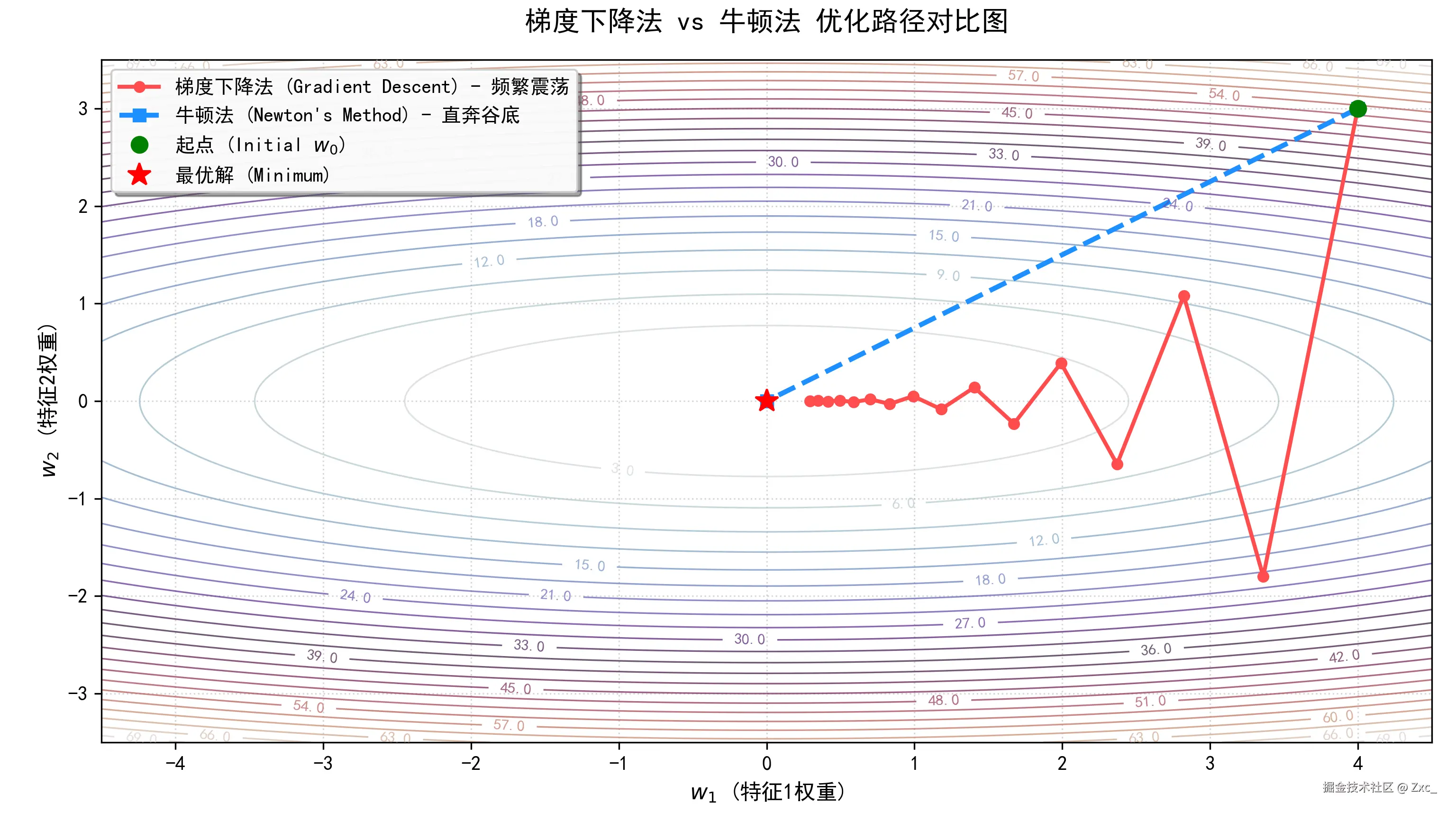
手写逻辑回归
按照上面逻辑回归的介绍,核心步骤为:
- 计算数据集线性回归的预测结果数据
- 将预测结果通过 sigmoid 函数转化为概率值
- 计算记录交叉熵损失值
- 计算梯度( w 方向和 b 方向)
- 更新参数(梯度下降法 w−=grad,牛顿法 w−=Hessian∗grad)
- 预测类别,将预测概率大于 0.5 的归于类别 1
梯度下降法
梯度下降法的核心公式为:
wk+1=wk−α⋅n1⋅XT(P−Y)
需要计算的只有 P ,计算线性回归预测值然后通过 sigmoid 函数即可计算。
python
"""手写机器学习逻辑回归
1.梯度下降法(实现)
先通过线性回归计算预测值,
再使用sigmoid函数计算概率值,
再根据梯度下降公式更新权重。
2.牛顿法
"""
import numpy as np
from sklearn.model_selection import train_test_split
class LogisticRegressionGradientDescent:
"""逻辑回归梯度下降法实现
公式:w_k+1 = w_k − α·1/n·X^T(P−Y)
"""
def __init__(self, eta0=0.01, max_iter=1000, tolerance=1e-6):
self.weights = None # 权重
self.intercept = None # 偏置
self.eta0 = eta0 # 学习率
self.max_iter = max_iter # 迭代次数
self.tolerance = tolerance # 收敛阈值
self.loss_history = None # 损失值历史
self.is_fitted = False # 是否已训练
self.feature_mean = None # 特征均值(用于标准化)
self.feature_std = None # 特征标准差(用于标准化)
def _normalize_features(self, X):
"""特征标准化(Z-Score Normalization)"""
if self.feature_mean is None:
# 训练时:计算均值和标准差
self.feature_mean = np.mean(X, axis=0)
self.feature_std = np.std(X, axis=0)
# 防止除以0
self.feature_std[self.feature_std == 0] = 1.0
# 标准化
return (X - self.feature_mean) / self.feature_std
def _compute_loss(self, y, y_prob):
"""计算交叉熵损失"""
epsilon = 1e-15
y_prob = np.clip(y_prob, epsilon, 1 - epsilon)
return -np.mean(y * np.log(y_prob) + (1 - y) * np.log(1 - y_prob))
def _sigmoid(self, z):
"""激励函数(真实值->概率值)"""
z = np.clip(z, -500, 500)
return 1 / (1 + np.exp(-z))
def fit(self, X, y):
"""训练逻辑回归模型
使用梯度下降法计算最优参数
Args:
X: 训练特征矩阵,形状为 (n, d)
y: 目标值向量,形状为 (n,)
Returns:
self: 返回训练好的模型实例
"""
# 特征标准化,避免梯度爆炸
X_normalized = self._normalize_features(X)
# 初始化参数
n_samples, n_features = X_normalized.shape
self.weights = np.zeros(n_features)
self.intercept = 0
self.loss_history = []
loss_prev = np.inf
for i in range(self.max_iter):
# 1.计算线性回归预测值
linear_res = X_normalized.dot(self.weights) + self.intercept
# 2.sigmoid函数计算概率
y_prob = self._sigmoid(linear_res)
# 3.计算损失
loss = self._compute_loss(y, y_prob)
self.loss_history.append(loss)
# 4.计算梯度
errors = y_prob - y
grad_w = (1 / n_samples) * X_normalized.T.dot(errors)
grad_b = (1 / n_samples) * np.sum(errors)
# 5.收敛判断
if np.linalg.norm(grad_w) < self.tolerance:
print(f'梯度足够小,已收敛,迭代次数:{i}')
break
if abs(loss_prev - loss) < self.tolerance:
print(f'损失变化足够小,已收敛,迭代次数:{i}')
break
# 6.更新参数
loss_prev = loss
self.weights -= self.eta0 * grad_w
self.intercept -= self.eta0 * grad_b
self.is_fitted = True
return self
def predict_proba(self, X):
"""预测概率"""
if not self.is_fitted:
raise RuntimeError("模型尚未训练,请先调用 fit() 方法进行训练")
X_normalized = self._normalize_features(X)
return self._sigmoid(X_normalized.dot(self.weights) + self.intercept)
def predict(self, X):
"""预测类别"""
y_prob = self.predict_proba(X)
return (y_prob >= 0.5).astype(int)
def score(self, X, y):
"""准确率计算"""
if not self.is_fitted:
raise RuntimeError("模型尚未训练,请先调用 fit() 方法进行训练")
y_pre = self.predict(X)
return np.mean(y_pre == y)结果对比实验:
使用威斯康星乳腺癌数据集进行实验,并于 sklearn 的实现进行结果对比。
python
import pandas as pd
from sklearn.linear_model import LogisticRegression
if __name__ == '__main__':
# 癌症数据集
# 1.数据加载
cancer_data = pd.read_csv("./data/breast-cancer-wisconsin.csv")
# cancer_data.info()
# 2.数据预处理
cancer_data.replace("?", np.nan, inplace=True)
cancer_data.dropna(inplace=True)
# cancer_data.info()
# 3.特征工程
X = cancer_data.iloc[:, 1:-1]
y = cancer_data.iloc[:, -1]
y = y.map({2: 0, 4: 1})
y = y.astype(int)
X = X.apply(pd.to_numeric)
x_train, x_test, y_train, y_test = train_test_split(X, y,
test_size=0.2,
random_state=42,
stratify=y)
# -----------------------------手写效果展示-----------------------------
# 4.模型训练
estimator = LogisticRegressionGradientDescent()
estimator.fit(x_train,y_train)
# 5.模型预测
y_predict = estimator.predict(x_test)
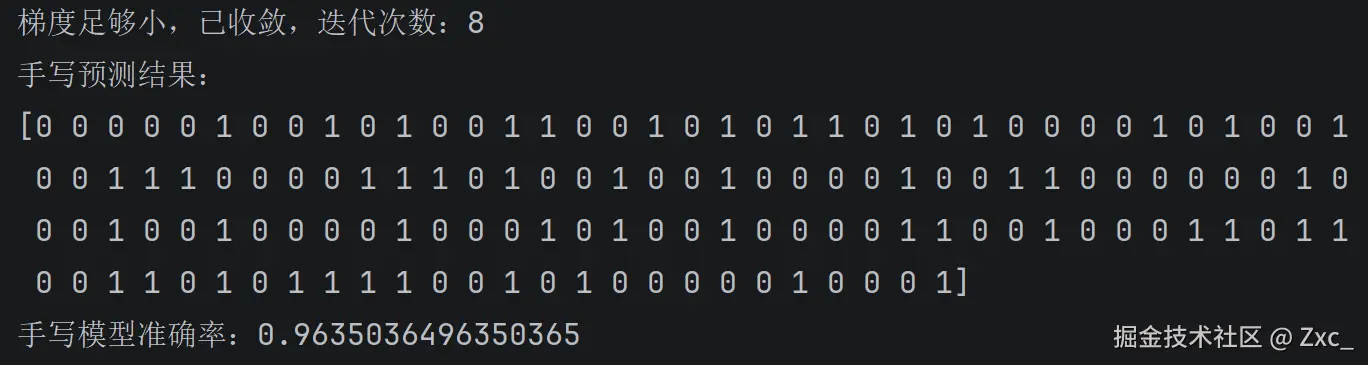
print(f'手写预测结果:\n{np.array(y_predict)}')
# 6.模型评估
score = estimator.score(x_test, y_test)
print(f'手写模型准确率:{score}')
# -----------------------------sklearn效果展示-----------------------------
# 4.模型训练
estimator = LogisticRegression()
estimator.fit(x_train,y_train)
# 5.模型预测
y_predict = estimator.predict(x_test)
print(f'sklearn预测结果:\n{np.array(y_predict)}')
# 6.模型评估
score = estimator.score(x_test, y_test)
print(f'sklearn模型准确率:{score}')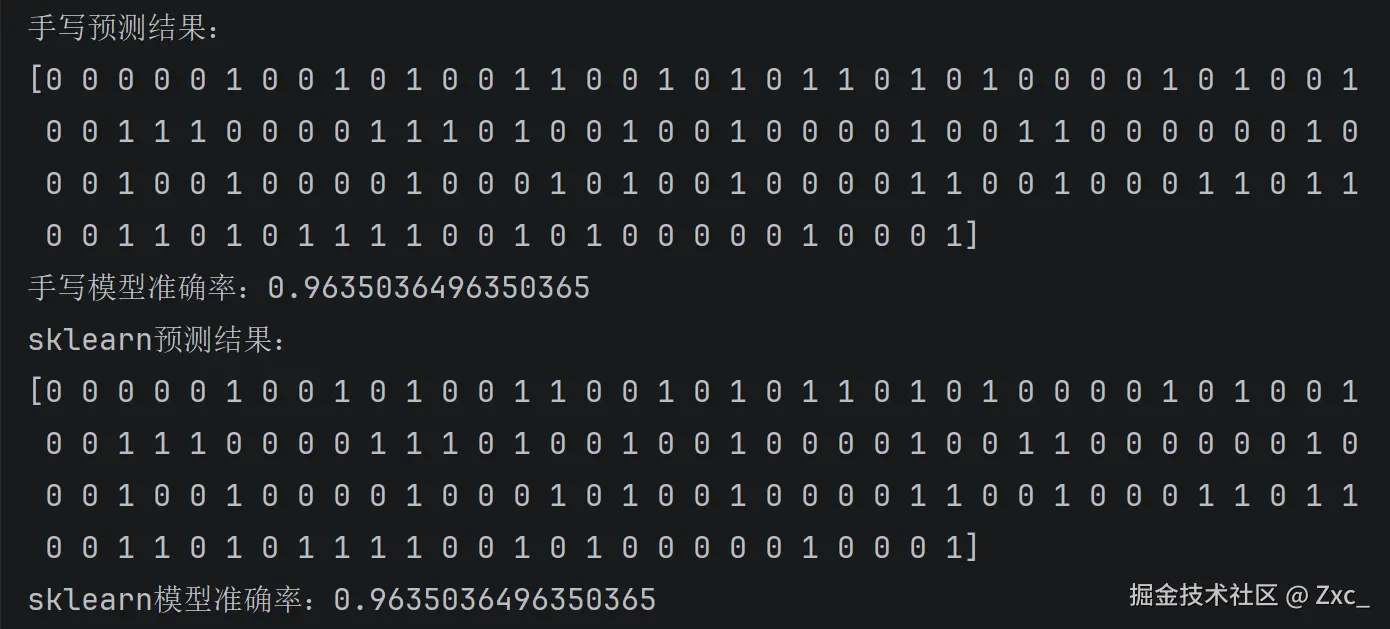
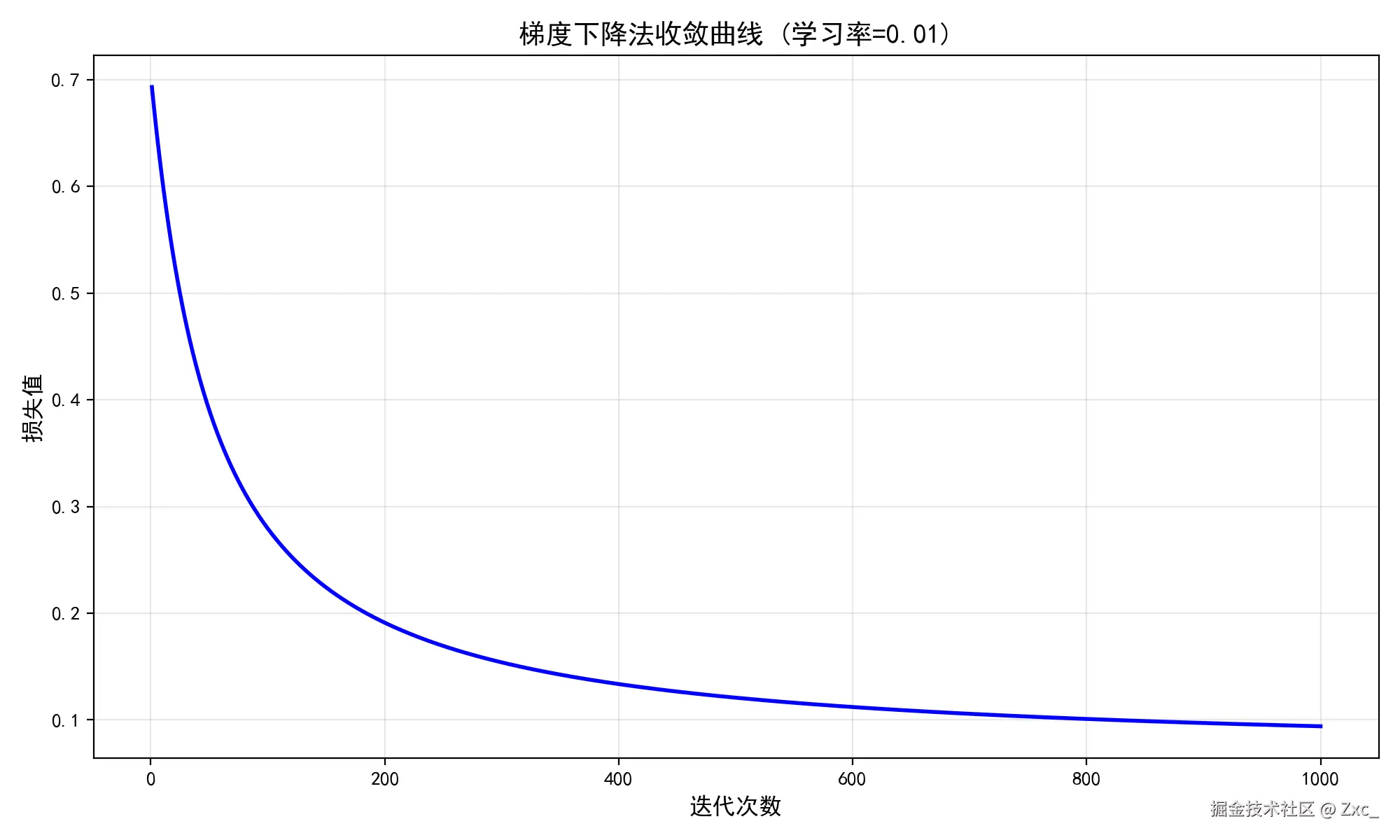
梯度下降法损失曲线:
python
import matplotlib.pyplot as plt
def plot_convergence_curve(self):
"""绘图函数-图一
损失值随迭代次数变化图
"""
if not self.loss_history:
raise RuntimeError("没有损失历史数据,请先调用 fit() 方法进行训练")
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(10, 6))
plt.plot(range(1, len(self.loss_history) + 1), self.loss_history, linewidth=2, color='blue')
plt.xlabel('迭代次数', fontsize=12)
plt.ylabel('损失值', fontsize=12)
plt.title(f'梯度下降法收敛曲线 (学习率={self.eta0})', fontsize=14)
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()梯度下降法的损失值下降的非常慢,直到1000轮时其损失值依旧没有达到收敛条件,可能是学习率设置太小导致步长太短。
牛顿法
牛顿法的核心公式为:
wk+1=wk−(XTRkX)−1XT(Pk−Y)
不仅需要求预测值,还需要求 Hessian 矩阵,其中 R 为方差对角矩阵大小为 (n,n),
此时如果数据集样本为 10000 行,就需要创建一个 (10000,10000)的稀疏矩阵,浪费内存。
利用NumPy广播机制,r_vector[:, np.newaxis] * X_bias 中 (n, 1) 自动扩展为 (n, d+1),实现了逐列加权,等价于对角矩阵乘法但无需显式构造 n×n 矩阵。
python
"""手写机器学习逻辑回归
1.梯度下降法
2.牛顿法(实现)
先通过线性回归计算预测值,
再使用sigmoid函数计算概率值,
再根据牛顿法公式更新权重。
"""
import numpy as np
from sklearn.model_selection import train_test_split
class LogisticRegressionNewtonMethod:
"""逻辑回归牛顿法实现
公式:w_k+1 = w_k − (X^T · R · X)^-1 · X^T · (P−Y)
"""
def __init__(self, max_iter=1000, tolerance=1e-6):
self.weights = None # 权重,包含偏置
self.max_iter = max_iter # 迭代次数
self.tolerance = tolerance # 收敛阈值
self.loss_history = None # 损失值历史
self.is_fitted = False # 是否已训练
self.feature_mean = None # 特征均值(用于标准化)
self.feature_std = None # 特征标准差(用于标准化)
def _normalize_features(self, X):
"""特征标准化(Z-Score Normalization)"""
if self.feature_mean is None:
# 训练时:计算均值和标准差
self.feature_mean = np.mean(X, axis=0)
self.feature_std = np.std(X, axis=0)
# 防止除以0
self.feature_std[self.feature_std == 0] = 1.0
# 标准化
return (X - self.feature_mean) / self.feature_std
def _compute_loss(self, y, y_prob):
"""计算交叉熵损失"""
epsilon = 1e-15
y_prob = np.clip(y_prob, epsilon, 1 - epsilon)
return -np.mean(y * np.log(y_prob) + (1 - y) * np.log(1 - y_prob))
def _sigmoid(self, z):
"""激励函数(真实值->概率值)"""
z = np.clip(z, -500, 500)
return 1 / (1 + np.exp(-z))
def fit(self, X, y):
"""训练逻辑回归模型
使用牛顿法计算最优参数
Args:
X: 训练特征矩阵,形状为 (n, d)
y: 目标值向量,形状为 (n,)
Returns:
self: 返回训练好的模型实例
"""
# 特征标准化,避免梯度爆炸
X_normalized = self._normalize_features(X)
# 初始化参数
n_samples, n_features = X_normalized.shape
self.weights = np.zeros(n_features + 1)
self.loss_history = []
loss_prev = np.inf
# 拼接偏置项
b = np.ones((n_samples, 1))
X_bias = np.concatenate((b, X_normalized), axis=1)
for i in range(self.max_iter):
# 1.计算线性回归预测值
linear_res = X_bias.dot(self.weights)
# 2.sigmoid函数计算概率
y_prob = self._sigmoid(linear_res)
# 3.计算损失
loss = self._compute_loss(y, y_prob)
self.loss_history.append(loss)
# 4.计算梯度
errors = y_prob - y
grad_w = (1 / n_samples) * X_bias.T.dot(errors)
# 5.计算 Hessian 矩阵
r_vector = y_prob * (1 - y_prob)
r_vector = np.clip(r_vector, 1e-10, 1.0)
# r_matrix = np.diag(r_vector)
# Hessian = (1 / n_samples) * X_bias.T.dot(r_matrix).dot(X_normalized)
Hessian = (1 / n_samples) * X_bias.T.dot(r_vector[:, np.newaxis] * X_bias)
# 5.收敛判断
if np.linalg.norm(grad_w) < self.tolerance:
print(f'梯度足够小,已收敛,迭代次数:{i}')
break
if abs(loss_prev - loss) < self.tolerance:
print(f'损失变化足够小,已收敛,迭代次数:{i}')
break
# 6.更新参数
loss_prev = loss
self.weights -= np.linalg.pinv(Hessian).dot(grad_w)
self.is_fitted = True
return self
def predict_proba(self, X):
"""预测概率"""
if not self.is_fitted:
raise RuntimeError("模型尚未训练,请先调用 fit() 方法进行训练")
X_normalized = self._normalize_features(X)
n_samples = X_normalized.shape[0]
b = np.ones((n_samples, 1))
X_bias = np.concatenate((b, X_normalized), axis=1)
return self._sigmoid(X_bias.dot(self.weights))
def predict(self, X):
"""预测类别"""
y_prob = self.predict_proba(X)
return (y_prob >= 0.5).astype(int)
def score(self, X, y):
"""准确率计算"""
if not self.is_fitted:
raise RuntimeError("模型尚未训练,请先调用 fit() 方法进行训练")
# 1.预测
y_pre = self.predict(X)
return np.mean(y_pre == y)结果对照:
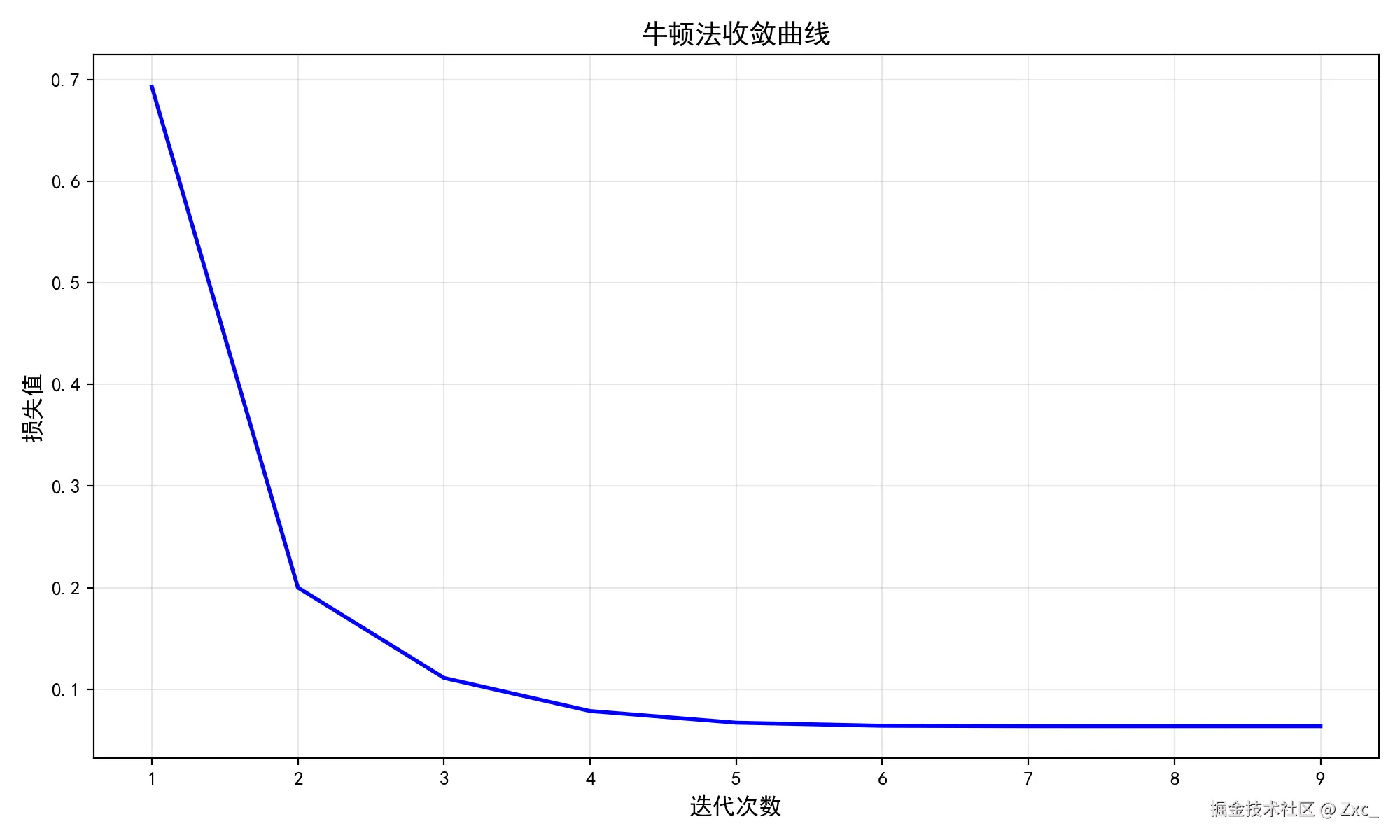
最后的准确率并没有优化,因为这个数据集的线性关系非常的强,最明显的就是 牛顿法在第 8 次迭代时已经达到收敛条件 ,非常符合 Hessian 矩阵控制步长和方向产生的结果。
正则化
正则化的核心就是为了避免过拟合,在线性回归讲得非常清晰,在逻辑回归中使用正则化与线性回归中的唯一差别只有损失函数的不同。
以下展示梯度下降中添加正则化的部分代码:
python
class LogisticRegressionGradientDescent:
def __init__(self, eta0=0.01, max_iter=100, tolerance=1e-4, penalty=None, lambda_=1.0):
# ...
self.penalty = penalty # 正则化类型
self.lambda_ = lambda_ # 惩罚系数
def fit(self, X, y):
# ...
for i in range(self.max_iter):
# ...
# 3.计算损失
reg_loss = 0.0
reg_grad = 0.0
if self.penalty is not None:
if self.penalty == 'l1':
reg_loss = self.lambda_ * np.sum(np.abs(self.weights))
reg_grad = self.lambda_ * np.sign(self.weights)
elif self.penalty == 'l2':
reg_loss = (self.lambda_ / 2) * np.sum(self.weights ** 2)
reg_grad = self.lambda_ * self.weights
loss = self._compute_loss(y, y_prob) + reg_loss
self.loss_history.append(loss)
# 4.计算梯度
errors = y_prob - y
grad_w = (1 / n_samples) * X_normalized.T.dot(errors) + reg_grad
grad_b = (1 / n_samples) * np.sum(errors)由于威斯康星乳腺癌数据集本身线性关系较强,在本实验中正则化的效果不明显。但在高维稀疏数据上,L1正则化的特征选择作用会非常显著。
sklearn 实现
sklearn 实现的 LogisticRegression 支持多分类,安全性更高,支持的正则化类型更全。
python
class LogisticRegression(LinearClassifierMixin, SparseCoefMixin, BaseEstimator):
def __init__(
self,
penalty="deprd",
*,
C=1.0,
l1_ratio=0.0,
dual=False,
tol=1e-4,
fit_intercept=True,
intercept_scaling=1,
class_weight=None,
random_state=None,
solver="lbfgs",
max_iter=100,
verbose=0,
warm_start=False,
n_jobs=None,
)
def fit(self, X, y, sample_weight=None):
# 1.超长篇幅的正则化类型选择
if self.penalty == "deprecated":
if self.l1_ratio == 0 or self.l1_ratio is None:
penalty = "l2"
if self.l1_ratio is None:
# 警告 ...
elif self.l1_ratio == 1:
penalty = "l1"
else:
penalty = "elasticnet"
if self.C == np.inf:
penalty = None
else:
penalty = self.penalty
# 警告 ...
solver = _check_solver(self.solver, penalty, self.dual)
if penalty != "elasticnet" and (
self.l1_ratio is not None and 0 < self.l1_ratio < 1
):
# 警告 ...
if (self.penalty == "l2" and self.l1_ratio != 0) or (
self.penalty == "l1" and self.l1_ratio != 1
):
# 警告 ...
if penalty == "elasticnet" and self.l1_ratio is None:
raise ValueError("l1_ratio must be specified when penalty is elasticnet.")
if penalty is None:
if self.C != 1.0: # default values
# 警告 ...
C_ = np.inf
penalty = "l2"
else:
C_ = self.C
msg = (
"'n_jobs' has no effect since 1.8 and will be removed in 1.10. "
f"You provided 'n_jobs={self.n_jobs}', please leave it unspecified."
)
if self.n_jobs is not None:
warnings.warn(msg, category=FutureWarning)
if solver == "lbfgs":
_dtype = np.float64
else:
_dtype = [np.float64, np.float32]
# 2.数据安全检查与对齐
X, y = validate_data(
self,
X,
y,
accept_sparse="csr",
dtype=_dtype,
order="C",
accept_large_sparse=solver not in ["liblinear", "sag", "saga"],
)
n_features = X.shape[1]
check_classification_targets(y)
self.classes_ = np.unique(y)
n_classes = len(self.classes_)
is_binary = n_classes == 2
# 3.求解器分流与执行
if solver == "liblinear": # 传统坐标轴下降法
if not is_binary: # 不支持多分类
# 报错 ...
if np.max(X) > 1e30:
# 报错 ...
self.coef_, self.intercept_, self.n_iter_ = _fit_liblinear(
X,
y,
self.C,
self.fit_intercept,
self.intercept_scaling,
self.class_weight,
penalty,
self.dual,
self.verbose,
self.max_iter,
self.tol,
self.random_state,
sample_weight=sample_weight,
)
return self
if solver in ["sag", "saga"]:
max_squared_sum = row_norms(X, squared=True).max()
else:
max_squared_sum = None
if n_classes < 2:
# 报错 ...
if self.warm_start:
warm_start_coef = getattr(self, "coef_", None)
else:
warm_start_coef = None
if warm_start_coef is not None and self.fit_intercept:
warm_start_coef = np.append(
warm_start_coef, self.intercept_[:, np.newaxis], axis=1
)
n_threads = 1
# 拟牛顿法与随机平均梯度法分流
coefs, _, n_iter = _logistic_regression_path(
X,
y,
classes=self.classes_,
Cs=[C_],
l1_ratio=self.l1_ratio,
fit_intercept=self.fit_intercept,
tol=self.tol,
verbose=self.verbose,
solver=solver,
max_iter=self.max_iter,
class_weight=self.class_weight,
check_input=False,
random_state=self.random_state,
coef=warm_start_coef,
penalty=penalty,
max_squared_sum=max_squared_sum,
sample_weight=sample_weight,
n_threads=n_threads,
)
self.n_iter_ = np.asarray(n_iter, dtype=np.int32)
# 4.高维矩阵反解与偏置项剥离
self.coef_ = coefs[0]
if self.fit_intercept:
if is_binary:
self.intercept_ = self.coef_[-1:]
self.coef_ = self.coef_[:-1][None, :]
else:
self.intercept_ = self.coef_[:, -1]
self.coef_ = self.coef_[:, :-1]
else:
if is_binary:
self.intercept_ = np.zeros(1, dtype=X.dtype)
self.coef_ = self.coef_[None, :]
else:
self.intercept_ = np.zeros(n_classes, dtype=X.dtype)
return self前沿进展
多分类扩展:
逻辑回归原生是二分类模型。对于多分类问题,sklearn通过一对多(OvR)策略自动扩展:训练时对每个类别分别训练一个二分类器,预测时选择概率最高的类别。此外,Softmax回归(又称多项逻辑回归)将Sigmoid替换为Softmax函数,可直接输出多类别概率分布。
类别不平衡处理:
当正负样本比例悬殊时,模型会倾向预测多数类。sklearn中的
class_weight='balanced'参数会自动按样本比例调整各类别的权重,使少数类获得更高的错分代价。
逻辑回归在大模型(LLM)时代的现代角色:
在现代大语言模型(如全连接层、MoE 的 Gating 网络或工业界大规模推荐系统如双塔模型)的末端,逻辑回归(或其多分类形式 Softmax)依然作为最终的概率对齐和分类输出层。此外,在现代指令微调(SFT)和人类反馈强化学习(RLHF)的奖励模型(Reward Model)中,评估两段回答优劣的 Bradley-Terry 模型,其本质上也是一个逻辑回归公式。
群体智能优化:
逻辑回归的正则化强度C和特征子集选择可视为组合优化问题。利用遗传算法(GA)或粒子群算法(PSO)进行自动超参数整定和特征选择,可大幅减少传统网格搜索的计算开销。
总结
从Sigmoid函数将线性输出压缩为概率,到极大似然估计自然引出交叉熵损失,再到梯度下降与牛顿法两种优化路径------逻辑回归用简洁的数学模型,实现了机器学习中最优雅的二分类方案之一。它的概率输出和强可解释性,使其在医疗、金融等需要"置信度"的领域中至今不可替代。
参考文献
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning: Data Mining, Inference, and Prediction (2nd ed.). Springer Science & Business Media.
- Nocedal, J., & Wright, S. J. (2006). Numerical Optimization (2nd ed.). Springer Science & Business Media.
- Fan, R. E., Chang, K. W., Hsieh, C. J., Wang, X. R., & Lin, C. J. (2008). LIBLINEAR: A library for large linear classification. Journal of Machine Learning Research, 9, 1871-1874.
- Cox, D. R. (1958). The regression analysis of binary sequences. Journal of the Royal Statistical Society: Series B (Methodological) , 20(2), 215-242.