一个令人意外的事实
一个刚出厂的大模型,所有参数都是随机数。你问它"法国的首都是",它可能输出"skdfj23#@!"------完全不知所云。
训练之后,同样的模型输出"巴黎"。中间只做了一件事:不断猜测下一个词,然后根据猜对了还是猜错了,微调所有参数。
就这么简单。但规模达到几十亿个参数、几万亿条训练数据之后,简单的机制产生了奇怪的效果。
一、从"猜词游戏"开始
大模型最初是怎么"看"语言的?
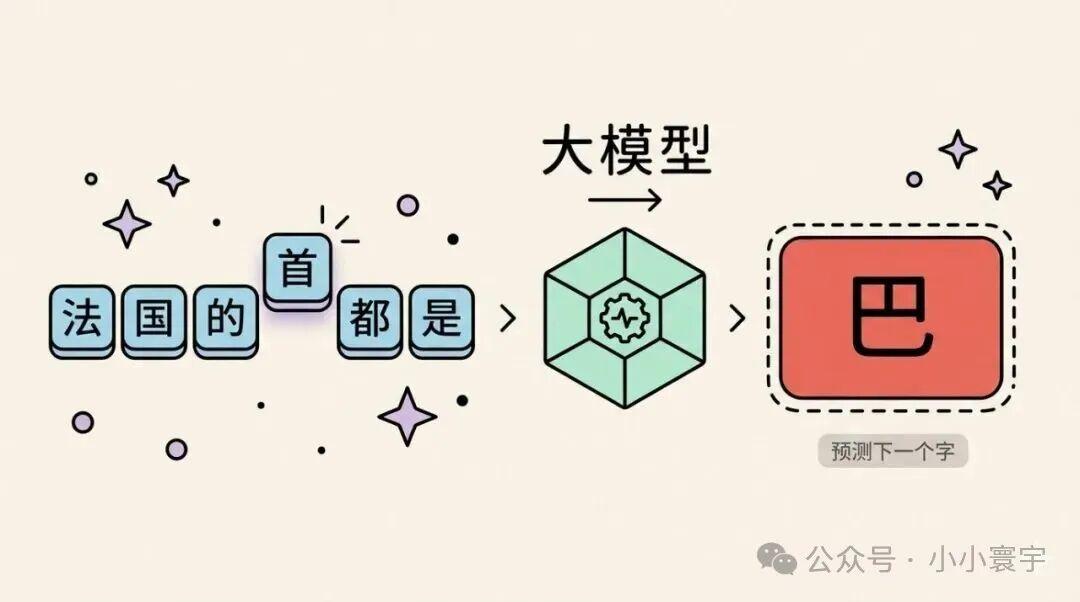
它做的事情叫下一个词预测(Next Token Prediction):给定一段文字,猜下一个最可能出现的字或词。
比如:
- • 输入"法国的首都是",模型输出"巴"→ 猜对了一个字
- • 输入"Thank you very",模型输出"much"→ 猜对一个词
一开始,模型随机猜测,每个词的概率差不多,就像闭着眼睛掷骰子。
如果把这件事重复几万亿次,模型会慢慢发现:"法国的首都是"后面跟"巴黎"的次数远远超过其他词,于是把"巴"和"黎"的概率逐渐调高。
这个过程,就是训练。训练的目标不是"教模型知识",而是让预测越来越准。
二、训练的四个步骤:大厨做菜的比喻
大模型有几十亿个参数。你可以把它想象成一个超级大厨:面前有几十亿种配料,每种放多少完全靠猜。
每个训练周期做四件事。
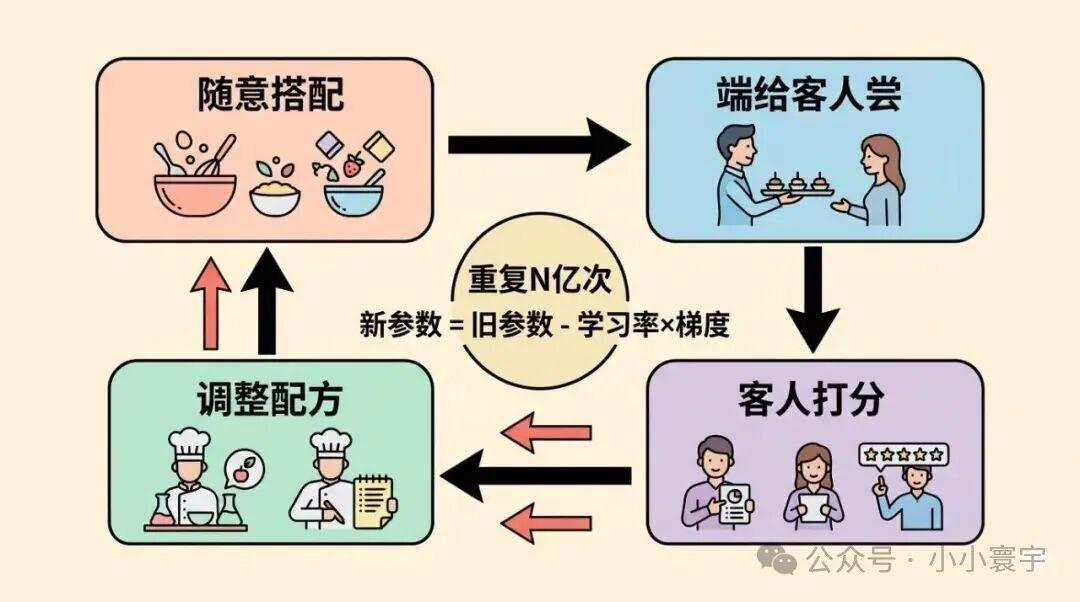
随意搭配------随机初始化。 大厨第一次做菜,配料随便加,做出来的东西难以下咽。
端给客人尝------用当前参数做预测。 把一段文字喂进去,让模型预测下一个词。它输出的完全是随机乱码。
客人打分------算误差(Loss)。 客人尝了一口,给出一个难吃程度的分数。Loss 越大,说明这次做得越离谱。
调整配方------更新参数。 大厨记住:盐放多了下次少放,糖不够下次多放。每个配料都微调一点点,方向是让"难吃程度"降低。学习率控制每次调整的幅度------改太多会矫枉过正,改太少进步太慢。
然后用下一段文字再来一轮。重复几十亿次之后,大厨的配方越来越精准,做出来的菜越来越好。模型从随机乱码变成了能流畅对话的智能助手。
三、什么是 Loss?
"算误差"有一个专门的名字:Loss(损失函数)。
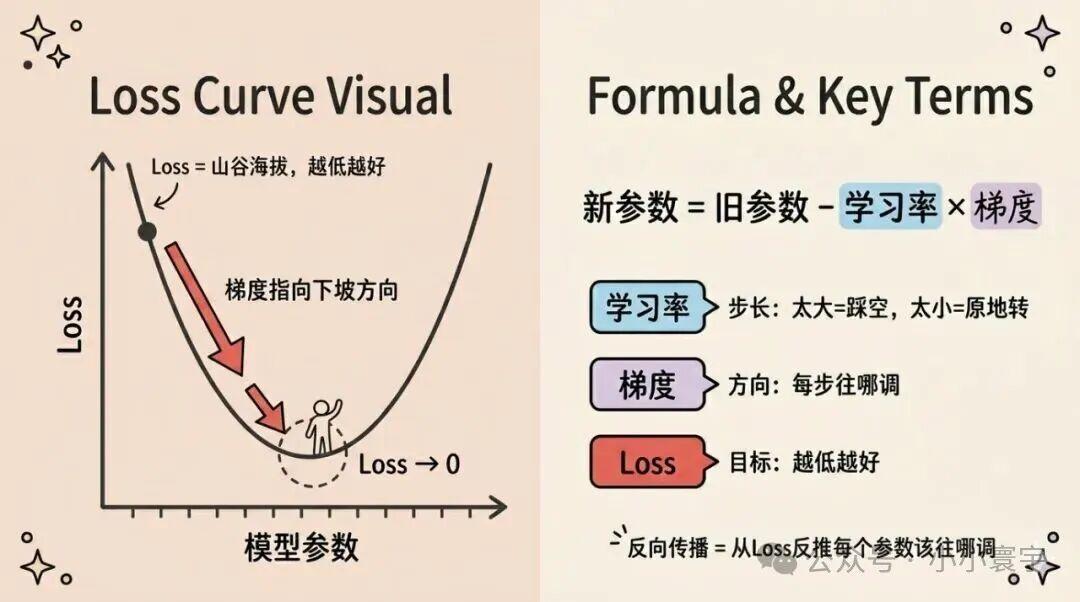
Loss 就是模型的"错误程度"。模型猜错了整个句子,Loss 就大;只猜错一个词,Loss 就小;全猜对,Loss = 0。
训练的目标不是"让 Loss 变成 0"(因为数据总有噪声),而是让 Loss 越来越小,越来越接近零但永远达不到零。
Loss 越低,模型的预测就越准。
四、模型是怎么知道"该往哪调"的?
大厨有几十亿种配料,他怎么知道每种该加多少?
答案是梯度(Gradient)。
梯度告诉你:每种配料对"难吃程度"的"贡献方向"。盐放多了会让菜变咸,糖少了会让菜不够甜------梯度就是这张"方向地图"。
算出梯度之后,用梯度下降来更新参数:
Loss 是山谷的"海拔",越低越好。梯度指明下坡方向,学习率决定步长。每走一步都离山谷更低处近一点。
但这里有一个问题:走到谷底,是全局最低的 Loss 吗?会不会只是某个小山坳,真正的全局最低还在别处?
在几十亿维的参数空间里,这个问题比想象中轻微。
参数空间极高维,大部分"凹进去"的地方同时也连接着通往更低点的路径------就像连绵起伏的山地,没有哪个山谷是完全封死的。随机梯度下降的大规模噪声反而帮助模型跳出不够好的局部最优。
加上训练初期用大学习率快速探索,后期用小学习率精细调整,大学习率阶段天然有"跳出小坑"的能力。实际经验也表明:只要数据质量够好、训练足够充分,最终模型的能力主要取决于数据量和参数量,而不是"运气好找到了哪个坑"。
从 Loss 反推到每个参数该往哪调的过程,叫反向传播(Backpropagation),是深度学习最核心的算法之一。
五、大模型的三个训练阶段
真实的大模型训练分为三个阶段,每个阶段解决不同问题。
预训练------海量读书
让模型学会语言本身:语法、知识、推理能力。
做法很简单:把整个互联网的文本喂给模型,让它继续做"预测下一个词"这件事。通常需要 1 万亿到 15 万亿个 Token(一个 Token 约等于 0.75 个英文单词或 0.5 个汉字),用几千到上万张 GPU 训练数周到数月,费用从几百万到几千万美元不等。
预训练完成后,模型已经能生成非常流畅的文本,知道大量事实,能做简单推理。但它有一个明显问题:不太会回答问题。
你问它"法国的首都是什么",它可能续写网页内容("法国的首都是什么网站..."),而不是直接给出答案------因为在训练数据里,文本后面跟的通常是另一段文本,不是"回答"。
SFT------对话培训
教模型"怎么回答问题"。
做法是人工编写高质量的问答对话数据(通常几万到几十万条),然后像预训练一样继续做"预测下一个词"的训练------只是把普通文本换成了对话格式。
效果立竿见影:模型从"续写机器"变成"能回答问题的助手"。
RLHF------人类偏好对齐
让回答更有帮助、更安全、更符合人类期望。
第一步,训练一个"打分模型":让模型对同一个问题生成两个回答 A 和 B,请人类标注员判断哪个更好,用大量这种偏好数据训练打分模型。
第二步,用打分模型来指导语言模型的优化:生成回答 → 打分 → 把分数作为奖励信号调整参数 → 模型越来越倾向于生成高分回答。
ChatGPT 之所以让人觉得"有温度",很大程度来自这个阶段。
三阶段的效果对比
bash
随机模型: "skdfj23#@!" ← 随机噪声
预训练后: "...the capital of this..." ← 流畅续写,但不会回答问题
SFT后: "巴黎是法国的首都。" ← 能回答了,但质量参差不齐
RLHF后: "法国的首都是巴黎。巴黎位于..." ← 回答详细、有帮助、安全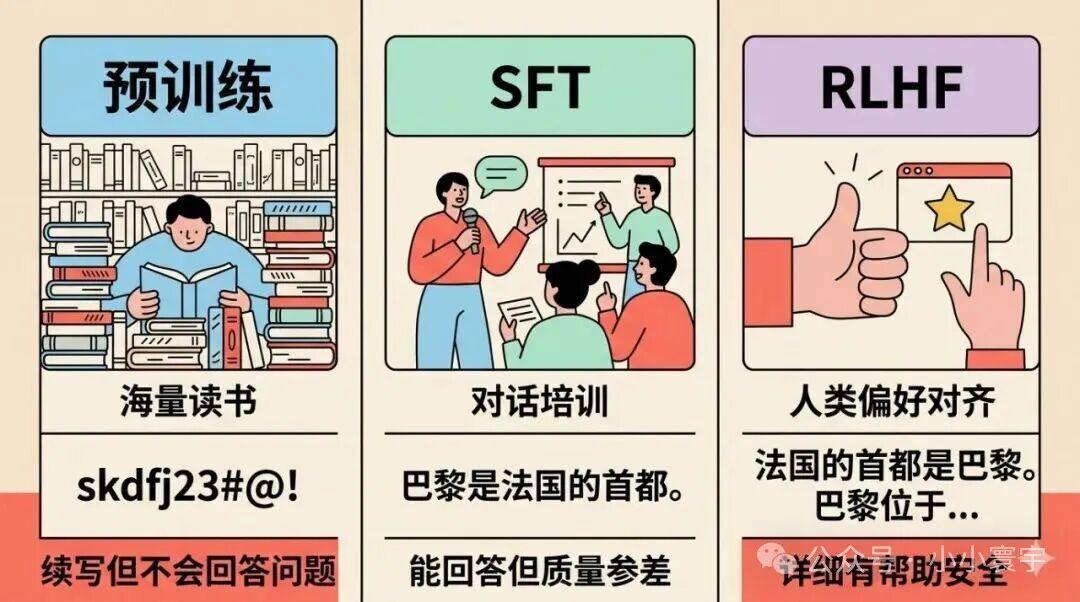
六、训练到底改变了什么?
模型里的参数经过训练后,究竟发生了什么变化?
Embedding 向量:训练前,所有词的向量都是随机数。训练后,语义相近的词在向量空间里自动变得接近------"法国"和"巴黎"的向量距离很近,"猫"和"狗"的向量距离也很近,甚至"国王 - 男人 + 女人"的向量运算结果接近"女王"。
Attention 权重:训练后,"Thank you" 这个搭配被学会了。当模型看到 "Thank you very" 时,注意力机制自动把更多权重分配给 "Thank" 和 "you"------因为在训练数据里,这种搭配模式出现过无数次。
FFN 权重:训练后,FFN 层存储了知识和事实。看到 "Thank you very" 会自动激活 "much",看到 "法国的首都是" 自动激活 "巴黎"------没有人告诉模型这些知识,它从几万亿次预测中自动发现了这些规律。
残差连接:这是一种"备份"机制。每层输出的结果 = 该层的处理结果 + 上层的结果。就像登山时每隔一段就拍一张照片留作备份,防止在后面摔倒时忘记登顶时的景色。
七、大模型训练的难题
原理不复杂,工程上极难。
显存是第一个瓶颈。 一个 70 亿参数的模型,训练时需要存储:参数(28GB)+ 梯度(28GB)+ 优化器状态(56GB)+ 激活值(数十GB),远超单张 GPU 的容量(通常 80GB)。当显存装不下时,要么减少 batch size,要么换更大显存的 GPU。
大模型必须用分布式训练------把模型切分到几千张 GPU 上协同工作。GPU 之间通过高速网络通信,每次迭代需要大量通信开销。这也是为什么训练一次大模型要花几百万甚至几千万美元,大部分成本来自硬件和电费。
数据质量比数量更重要。 预训练数据来自互联网,充满了重复内容、垃圾页面、隐私信息、错误知识。直接喂给模型,它会学到这些坏习惯。所以训练前要做大量数据清洗:去重、过滤、平衡语言和领域比例。数据配比是各家的核心秘密,不同公司训练数据质量不同,直接决定了模型能力的差异。
训练不稳定。 几十亿个参数同时更新,很容易出现梯度爆炸或消失------Loss 突然变成无穷大,整个训练报废。
梯度爆炸就像步子迈太大,直接踩空从山崖上摔下去;梯度消失就像步子太小,在山谷里转来转去找不到出口。常用梯度裁剪来限制最大梯度值,用精细的初始化和 LayerNorm 来防止消失。大模型训练过程中需要持续监控 Loss 曲线、梯度分布、GPU 利用率等指标,一旦发现异常要立即干预,否则可能烧掉数周的计算资源和数百万经费。
结语
大模型训练的本质很简单:预测下一个词 → 算误差 → 调参数 → 重复。
复杂的不是算法,而是规模。几十亿个参数、几万亿个 Token、数千张 GPU、数月时间。把这个简单过程推到极致,就产生了看起来像"理解语言"的智能。
它的"聪明",不是来自有人教它知识,而是来自无数次猜词练习中自动发现的统计规律。
首发于 「小小寰宇」