LLaDA2.0-Uni: Unifying Multimodal Understanding and Generation with Diffusion Large Language Model ,这是一篇非常全面且具有前瞻性的多模态大模型(Multimodal Foundation Model)研究论文。论文介绍了 LLaDA2.0-Uni,这是一个基于离散扩散模型(Discrete Diffusion LLM)的统一多模态框架,成功地将"图像理解"和"图像生成/编辑"任务统一到了同一个原生架构中。
以下是对这篇论文的详细深度解读:
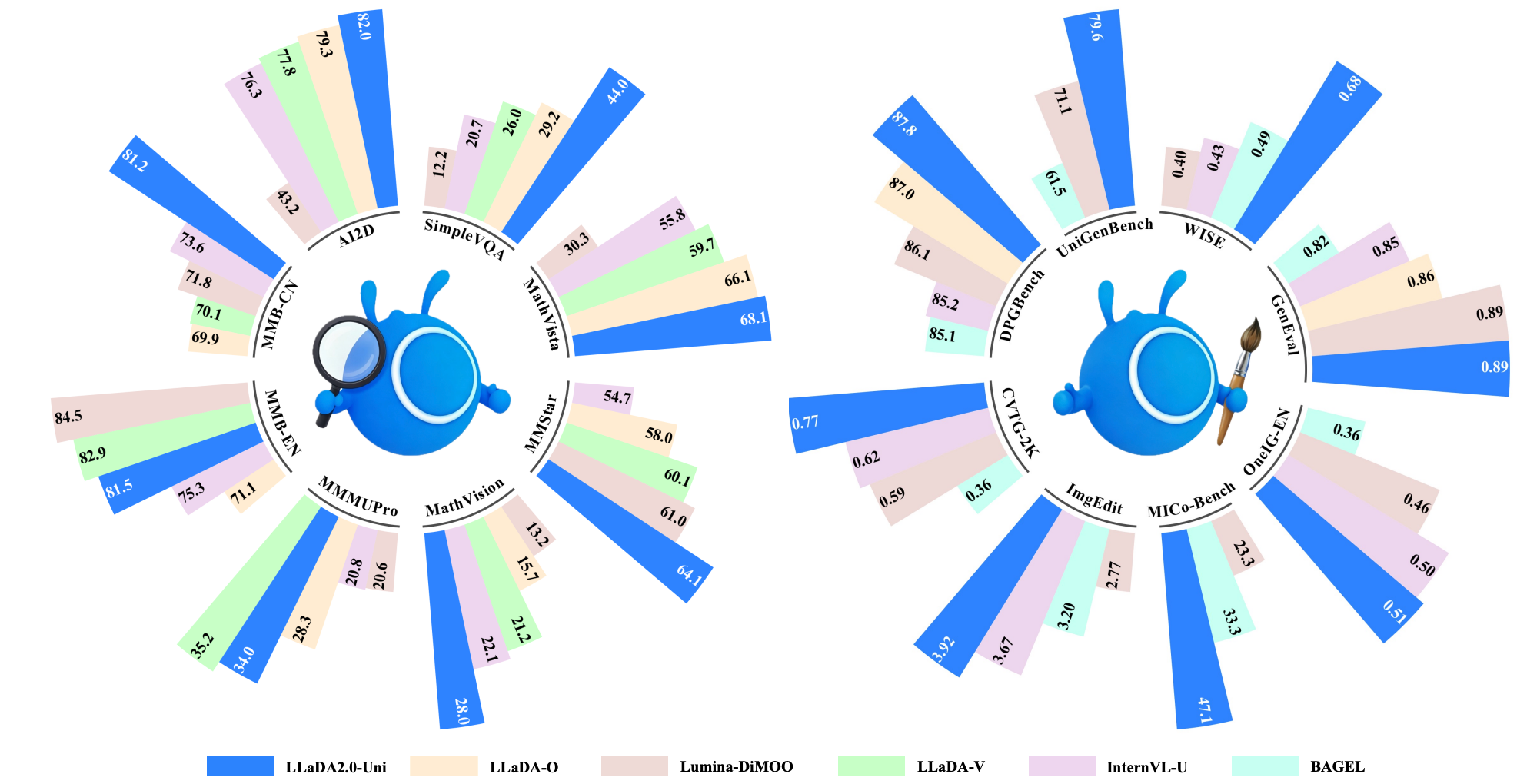
基准评估
一、 核心贡献
LLaDA2.0-Uni 摒弃了传统的自回归(AR)或"文本自回归+图像扩散"的混合范式,采用纯离散扩散架构(dLLM),通过纯语义的视觉分词器(SigLIP-VQ)将文本和图像统一为离散的语义Token,在单个模型内实现了顶级的多模态理解、高质量图像生成、复杂的图像编辑,并率先跑通了"图文交错推理与生成(Interleaved Generation and Reasoning)"。
三大核心贡献:
- 全新统一架构:SigLIP-VQ(语义分词) + 16B MoE dLLM(离散扩散主干) + Diffusion Decoder(扩散解码器)。
- 图文交错与推理:不仅能生成图文,还能进行链式思考(CoT),例如看图下象棋、解决物理题并配合生图。
- 高效推理:提出了无需训练的 SPRINT 加速算法和解码器蒸馏技术,大幅缓解了扩散模型推理慢的痛点。

LLaDA2.0-Uni 架构总览。该框架集成了 SigLIP‑VQ 分词器与语言模型解码器,用于处理文本、图像和视频等多模态输入。h和w分别代表image的高和宽。
二、 研究背景与现有痛点
当前统一图文理解与生成的模型主要有两类,但都存在明显缺陷:
- 自回归模型(如 Janus, Lumina-mGPT) :使用重建型 VQ-VAE 将图片压缩为离散 Token。痛点: 这种 Token 缺乏高级语义信息,导致"理解"能力差;且高压缩率导致"生成"质量受损。
- 混合模型(如 OmniGen2, Hunyuan Image) :文本用自回归,生图用连续扩散。痛点: 架构割裂,训练目标不一致,难以相互促进。
- 现有的离散扩散模型(如 LLaDA-o):虽然采用了扩散架构,但为了兼顾生成和理解,被迫使用了两套视觉模块(ViT用于理解,VAE用于生成),破坏了统一性。(这种分割架构还有BAGEL)
LLaDA2.0-Uni 的破局思路:"让理解和生成共用一套完全离散的、纯语义的 Token。"
三、 核心架构设计 (Model Design)
模型由三个核心组件构成(对应论文 Figure 4):
1. SigLIP-VQ 语义分词器 (Semantic Discrete Tokenizer)
- 做法 :不同于传统的 VQ-VAE(致力于像素级重建),它基于 SigLIP2-g 训练,将连续图像转换为离散的语义 Token。
- 优势 :极大保留了图像的高级语义和逻辑关系,使得模型的理解能力飙升。
- 代价:因为它全是语义,没有像素细节,所以无法直接"反切"回图片,必须外接一个专门的解码器。
2. 16B MoE 离散扩散大语言模型 (dLLM Backbone)
- 骨干:基于 LLaDA-2.0-mini(16B MoE 架构)。通过扩展词表,把视觉 Token 当作外语单词一样输入进去。
- 注意力机制 :采用了 Block-wise Attention(块级注意力)。因为 SigLIP-VQ 的 Token 带有自回归偏置,纯双向注意力会破坏性能。块级注意力在保证并行解码速度的同时,兼顾了训练稳定性。
- 训练目标 :文本和图像的生成/理解,全部统一为 "块级掩码预测(Block-wise Mask Prediction)"。
3. Diffusion Decoder (连续扩散解码器)
- 做法:因为主干网络吐出的是"语义视觉 Token",论文引入了一个基于 Z-Image-Base 的 6B 文本到图像扩散模型作为解码器。
- 创新 :这里的条件输入只有主干生成的视觉 Token,不再需要冗余的文本 Prompt。
- 加速 :通过流匹配(Flow Matching)和一致性蒸馏(Consistency Distillation),将原本需要 50 步的生图过程压缩到了 8步无分类器引导(CFG-free) 推理。
CFG 的全称是 Classifier-Free Guidance(无分类器引导)。 在用扩散模型(比如 Midjourney、Stable Diffusion)画图时,我们通常希望画出来的图和我们给的提示词(Prompt)高度一致。为了达到这个目的,发明了 CFG技术。
它的工作原理是:在生成图片的每一个去噪步骤中,模型都要算两次: 第一次(条件生成):带着你给的提示词(比如"一只猫")算一次。
第二次(无条件生成):什么提示词都不带(空文本),瞎算一次。然后,算法会把这两次的结果做一个数学上的"外推"(拉大差距),从而强行逼迫生成的图片更符合"一只猫"的特征。
四、 数据与训练策略 (Data & Training)
论文构建了非常庞大且精细的数据飞轮(三阶段训练):
- Stage 0(图文对齐):用 100B Token 的图文对和文本数据,让模型认图。
- Stage 1(多任务预训练):210B Token。加入 OCR、目标检测、视频数据、图像编辑指令等,建立强大的跨模态连接。
- Stage 2(SFT 监督微调):80B Token。分两步,先在 8K 上下文训练基础指令遵循,再扩展到 16K 上下文进行复杂的视觉推理和长序列图文交错生成。
训练优化亮点:
- Mask Token Reweighting(掩码重加权):多模态任务长度差异巨大(文本极短,生图极长),论文提出了重加权损失函数,防止长序列主导梯度。
- Data Packing(数据打包):将短序列拼成固定长序列(如下图),极大提高了 GPU 训练效率。
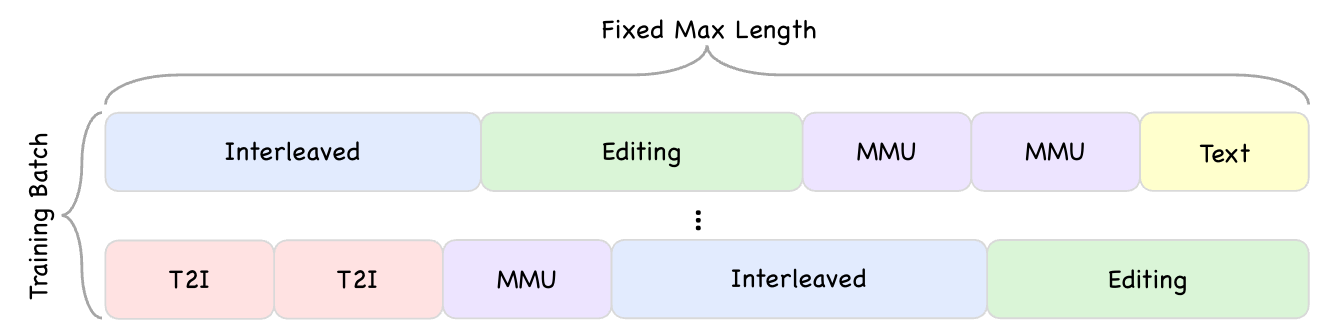
用于高效训练的数据打包策略。将多个较短样本拼接成固定长度的序列,最大限度减少填充标记,提升GPU利用率。
五、 推理加速 (SPRINT)
扩散 LLM 最大的缺点是推理慢(需要多次 Forward pass)。论文提出了 SPRINT (Sparse Prefix Retention with Inference-time Non-uniform Token Unmasking) 免训练加速算法:
- 稀疏前缀保留 (Sparse Prefix Retention) :
- 在解码时,KV Cache 越积越大。SPRINT 会根据 Attention 分数和预测置信度,动态丢弃不重要的 KV Cache。
- 模态感知:图像空间冗余大,丢弃 20% 的 KV Cache;文本逻辑性强,完全保留(100%)。
- 非均匀 Token 解码 (Non-uniform Token Unmasking) :
- 标准扩散模型每步解开固定数量的 Token。SPRINT 会计算每个 Token 的置信度,置信度高(>0.93)的直接一步解开,把计算算力留给那些"难生成"的部位(如 OCR 文字部分)。
- 效果 :在几乎不掉点的情况下,推理速度提升了 1.6 倍。
六、 核心能力与实验表现
1. 多模态理解 (Understanding)
- 全面超越了现有的统一模型(Lumina-DiMOO, LLaDA-o)。
- 在 MMStar、MMMU、MathVista 等困难推理基准上,性能甚至比肩或超越了顶尖的专门理解模型(如 Qwen2.5-VL-7B)。证明了纯语义离散 Token 路线的巨大成功。
2. 图像生成 (Generation)
- 在 GenEval(空间/组合生成)、DPG 等榜单上,击败了所有统一模型,并且逼近了闭源的专门生图模型。
- 文本渲染(CVTG-2k) 极强,这是很多扩散模型的弱项。
3. 图像编辑 (Image Editing)
- 支持极复杂的指令编辑。在多参考图编辑(MICo-Bench)上取得了 47.1 的 SOTA 成绩,远超 OmniGen2 (33.8)。
4. 图文交错与推理 (Interleaved Generation & Reasoning) - 全篇最大亮点
- 提出新榜单 InterGen:填补了业界缺乏图文交错基准的空白,包含故事生成、菜谱、动作预测等。LLaDA2.0-Uni 击败了 Emu3.5。
- 真正的"边想边画" :模型能够进行长逻辑链条的推理。例如:
- 给它一个象棋残局,它能像 AlphaZero 一样分析每一步的利弊,最后输出答案的图像。
- 给它一个物理滑轮图,它能先画出受力分析图,列出牛顿第二定律公式,最后算出张力。
七、 总结与启发
论文的战略意义:
LLaDA2.0-Uni 证明了 "离散化扩散(Discrete Diffusion)" 是通向 AGI 多模态大模型的一条极具竞争力的路线。过去人们认为,生成高质量图片必须用连续扩散(去噪),理解必须用自回归(预测下一个词)。LLaDA2.0-Uni 通过 "语义分词器 + MoE离散扩散主干 + 扩散解码器" 的解耦架构,完美地吃到了两者的红利。
未来演进方向(论文指出的不足):
- 语义分词器(SigLIP-VQ)目前会丢失细粒度的像素细节,这对极其精细的图像编辑有影响。
- 交错数据的规模还需要进一步扩大。
- 探索基于这种统一离散架构的强化学习(RL),以进一步提升多模态逻辑推理能力。