前言
在MapReduce生产环境中,数据倾斜是最常见也最致命的性能杀手 。一个看似完美的分布式程序,可能因为某个ReduceTask处理的数据量远超其他任务,导致整个作业卡死数小时甚至失败。本文将从倾斜现象识别 、根因分析 、六大解决方案 到实战案例,手把手教你彻底攻克数据倾斜。
一、什么是数据倾斜?
1.1 理想 vs 现实的ReduceTask
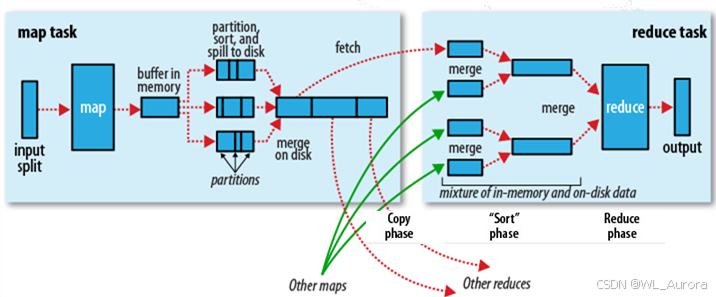
理想情况:所有ReduceTask处理的数据量均匀分布,并行高效。
现实情况:某个ReduceTask(如Reduce-0)处理了80%的数据,其他ReduceTask早早完成却空闲等待。
1.2 数据倾斜的核心定义
数据倾斜:MapReduce作业中,大量数据集中分配到少数几个ReduceTask,导致这些任务执行时间远长于其他任务,拖慢整个作业进度。
1.3 倾斜的典型症状
| 症状 | 说明 |
|---|---|
| 作业进度卡在99% | 大部分ReduceTask已完成,仅剩1-2个长时间运行 |
| YARN界面显示某Container内存溢出 | 单个ReduceTask数据量过大,内存不足 |
| 某些ReduceTask处理记录数是其他的100倍 | Counter统计中Reduce input records严重不均 |
| Shuffle阶段耗时占比超过80% | 大量数据集中到少数节点传输 |
二、数据倾斜的根因分析
2.1 倾斜发生的本质
数据倾斜发生在Shuffle阶段 ,核心原因是Key的分布不均匀:
Map输出 → 按Key的hashCode分区 → 相同Key进入同一个ReduceTask
↓
如果某个Key出现频率极高 → 该分区数据量暴增 → ReduceTask过载2.2 常见倾斜场景
| 场景 | 典型案例 | 原因 |
|---|---|---|
| 热点Key | 空值(null)、默认值、热门商品ID | 大量记录共享同一个Key |
| 数据本身特性 | 幂律分布(如社交网络中的大V) | 少数Key天然高频 |
| 业务逻辑导致 | 按省份统计,北京上海数据量远超其他 | 业务数据分布不均 |
| 小文件合并不当 | CombineTextInputFormat设置不合理 | 切片不均导致Map端倾斜 |
| HQL转MapReduce | Hive中Join on字段有大量重复值 | SQL层面未做优化 |
2.3 倾斜的量化识别
通过YARN Counter识别:
bash
# 查看Reduce输入记录数
hadoop job -counter <job_id> org.apache.hadoop.mapreduce.TaskCounter REDUCE_INPUT_RECORDS
# 或者查看YARN Web UI的Counter页面判断标准: 如果最大ReduceTask的输入记录数是最小的10倍以上,即可判定存在数据倾斜。
三、解决方案一:Map端预聚合(Combiner)
3.1 原理
在Map端先对相同Key进行局部聚合,减少传输到Reduce端的数据量。
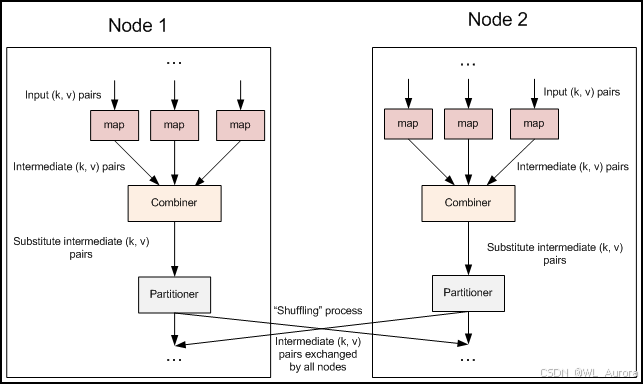
效果对比:
无Combiner:Map输出 (hello,1) × 10000次 → Reduce接收10000条记录
有Combiner:Map本地聚合为 (hello,10000) → Reduce接收1条记录3.2 适用场景
- 求和、计数、最大值、最小值等满足结合律的操作
- 不适合:求平均值、去重计数等不满足结合律的场景
3.3 代码实现
java
// 在Driver中启用Combiner
job.setCombinerClass(WordCountReducer.class);
// 或者自定义Combiner
public class WordCountCombiner extends Reducer<Text, LongWritable, Text, LongWritable> {
private LongWritable result = new LongWritable();
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context)
throws IOException, InterruptedException {
long sum = 0;
for (LongWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}3.4 局限性
Combiner只能解决Map端输出阶段的倾斜,如果单个Key的数据量本身就极大(如某个Key有上亿条记录),Combiner无法打散到多个ReduceTask,倾斜仍会发生在Reduce端。
四、解决方案二:加盐打散(随机前缀)
4.1 原理
对热点Key添加随机前缀,将其分散到多个ReduceTask处理,最后再聚合结果。
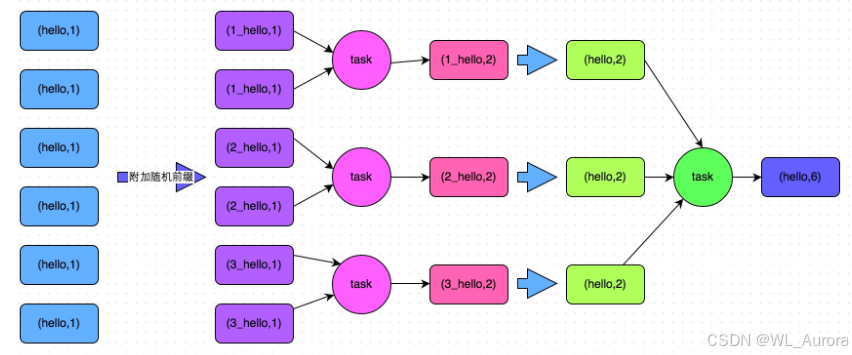
两阶段聚合流程:
第一阶段(加盐打散):
原始Key: hello → 随机前缀: 1_hello, 2_hello, 3_hello
分散到3个ReduceTask分别聚合
第二阶段(去盐聚合):
将 1_hello, 2_hello, 3_hello 的结果再次聚合为 hello4.2 代码实现
java
/**
* 第一阶段Mapper:对热点Key加盐
*/
public class SaltMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
private Text outKey = new Text();
private LongWritable one = new LongWritable(1);
private Random random = new Random();
private int saltNum = 3; // 盐的数量,即分散的ReduceTask数
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String word = value.toString();
// 对热点Key加盐(假设"hello"是热点)
if ("hello".equals(word)) {
int salt = random.nextInt(saltNum); // 0, 1, 2
outKey.set(salt + "_" + word); // 0_hello, 1_hello, 2_hello
} else {
outKey.set(word);
}
context.write(outKey, one);
}
}
/**
* 第一阶段Reducer:局部聚合
*/
public class SaltReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
private LongWritable result = new LongWritable();
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context)
throws IOException, InterruptedException {
long sum = 0;
for (LongWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result); // 输出: 0_hello 3333
} // 1_hello 3333
} // 2_hello 3334
/**
* 第二阶段Mapper:去盐
*/
public class UnsaltMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
private Text outKey = new Text();
private LongWritable outValue = new LongWritable();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] fields = line.split("\t");
String saltedKey = fields[0]; // 如 "0_hello"
long count = Long.parseLong(fields[1]);
// 去掉盐前缀
if (saltedKey.contains("_")) {
String realKey = saltedKey.split("_")[1]; // "hello"
outKey.set(realKey);
} else {
outKey.set(saltedKey);
}
outValue.set(count);
context.write(outKey, outValue);
}
}
/**
* 第二阶段Reducer:最终聚合
*/
public class UnsaltReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
private LongWritable result = new LongWritable();
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context)
throws IOException, InterruptedException {
long sum = 0;
for (LongWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result); // 最终输出: hello 10000
}
}4.3 优缺点
| 优点 | 缺点 |
|---|---|
| 彻底解决热点Key倾斜 | 需要两趟MapReduce,作业数翻倍 |
| 通用性强,适用于任何聚合场景 | 非热点Key也会被打散,增加 overhead |
| 可灵活控制盐的粒度 | 需要预先知道热点Key |
五、解决方案三:自定义Partitioner
5.1 原理
默认的HashPartitioner按key.hashCode() % numReduceTasks分区,如果Key分布不均,可以自定义分区逻辑,将数据均匀分配。
5.2 适用场景
- 已知倾斜原因,如按省份统计时北京上海数据过多
- 可以预先定义分区规则
5.3 代码实现
java
/**
* 自定义Partitioner:将热点Key均匀分散
*/
public class SkewPartitioner extends Partitioner<Text, LongWritable> {
@Override
public int getPartition(Text key, LongWritable value, int numPartitions) {
String word = key.toString();
// 对热点Key "hello" 特殊处理,分散到多个分区
if ("hello".equals(word)) {
// 使用随机数分散,确保每次运行均匀
return (word.hashCode() + new Random().nextInt(100)) % numPartitions;
}
// 其他Key使用默认Hash分区
return Math.abs(word.hashCode() % numPartitions);
}
}
// Driver中设置
job.setPartitionerClass(SkewPartitioner.class);
job.setNumReduceTasks(10); // 确保分区数足够5.4 局限性
- 随机分散后,相同Key可能进入不同ReduceTask,破坏聚合语义
- 仅适用于无需全局聚合的场景(如数据清洗、过滤)
六、解决方案四:两阶段聚合(局部聚合+全局聚合)
6.1 原理
将聚合操作拆分为两个阶段:
- 第一阶段:在Map端或Combiner中进行局部聚合
- 第二阶段:Reduce端进行全局聚合
6.2 与加盐的区别
| 维度 | 加盐打散 | 两阶段聚合 |
|---|---|---|
| 阶段数 | 两趟MR | 一趟MR(Map端+Reduce端) |
| Key处理 | 修改Key(加前缀) | 保持Key不变 |
| 适用场景 | 极端热点Key | 一般性倾斜 |
6.3 代码实现
java
/**
* Map端局部聚合 + Reduce端全局聚合
*/
public class TwoPhaseMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
private Map<String, Long> localMap = new HashMap<>(); // 内存局部聚合
@Override
protected void map(LongWritable key, Text value, Context context) {
String word = value.toString();
localMap.put(word, localMap.getOrDefault(word, 0L) + 1);
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
// Map任务结束前,输出局部聚合结果
for (Map.Entry<String, Long> entry : localMap.entrySet()) {
context.write(new Text(entry.getKey()), new LongWritable(entry.getValue()));
}
}
}七、解决方案五:调整并行度
7.1 增加ReduceTask数量
java
// 默认1个,增加到100个
job.setNumReduceTasks(100);原理:增加分区数,让数据更分散。但如果热点Key只有一个,增加分区数无效。
7.2 调整MapTask并行度
java
// 调整切片大小,增加MapTask数量
// 切片变小 → MapTask增多 → 每个Map处理数据减少
conf.set("mapreduce.input.fileinputformat.split.minsize", "67108864"); // 64MB7.3 适用场景
- 轻度倾斜:增加并行度即可缓解
- 重度倾斜:需结合其他方案
八、解决方案六:过滤倾斜Key
8.1 原理
如果倾斜Key是异常数据(如null、空字符串、测试数据),可以直接过滤。
8.2 代码实现
java
public class FilterMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) {
String word = value.toString().trim();
// 过滤空值和异常数据
if (word == null || word.isEmpty() || "null".equals(word)) {
return; // 直接丢弃
}
context.write(new Text(word), new LongWritable(1));
}
}8.3 适用场景
- 倾斜由脏数据导致
- 业务上允许丢弃部分数据
九、六大方案对比总结
| 方案 | 适用场景 | 优点 | 缺点 | 复杂度 |
|---|---|---|---|---|
| Combiner预聚合 | 求和/计数/最值 | 简单高效,一趟MR | 仅缓解Map端,无法解决Reduce端热点 | 低 |
| 加盐打散 | 极端热点Key | 彻底解决倾斜 | 两趟MR, overhead大 | 高 |
| 自定义Partitioner | 已知倾斜原因 | 灵活控制分区 | 可能破坏聚合语义 | 中 |
| 两阶段聚合 | 一般性倾斜 | 保持Key不变 | 内存压力大 | 中 |
| 调整并行度 | 轻度倾斜 | 简单快捷 | 对单Key热点无效 | 低 |
| 过滤倾斜Key | 脏数据导致 | 最简单 | 可能丢失数据 | 低 |